這是對Twitter 工作原理|架構解析|社交APP邏輯_嗶哩嗶哩_bilibili的學習,感謝up小凡生一
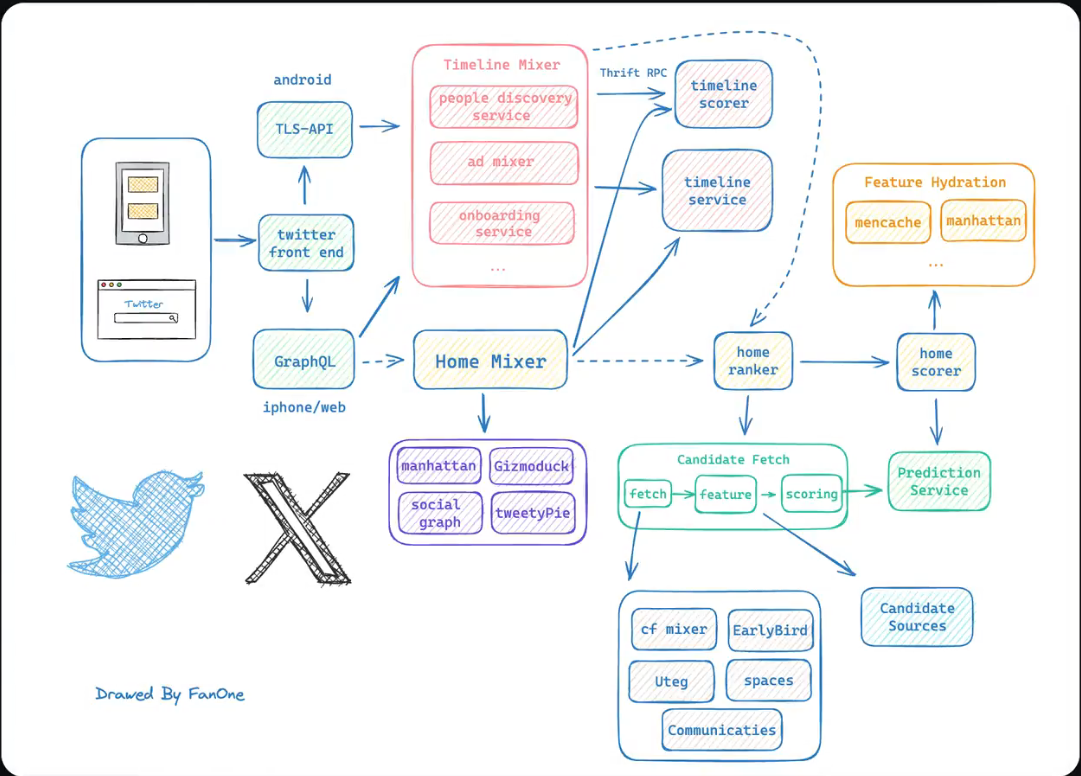
?在兩年半前,埃隆·馬斯克收購了Twitter,并且進行了一系列重大改革。今天我們來解析一下這個全球知名社交平臺的架構。首先,我們根據馬斯克兩年前曬出的草圖來繪制一個大體的框架圖。按照草圖,Twitter的前端頁面會根據來源判斷,以不同方式向后端發送請求。如果是安卓設備,就通過T2S API請求后端;如果是蘋果設備或Web端,就直接基于Web SQL發送請求給后端。Web SQL是一個類似JSON的數據結構。
T2S API有兩種解釋:一種說法是Twitter的經典傳輸層,安全的API網關系統,也就是沿用了HTTPS;另一種說法是T2S是Twitter系統的縮寫,即Twitter的最初主業務。馬斯克曾提到,可能會淘汰T2S API,因為只有當安卓應用程序使用超過一年后,才需要使用這個API。

?接下來,我們來看Twitter的兩個主要模塊:“For you”和“Following”。這兩個模塊對應著以前的“Home”和“Letters”。“For you”模塊根據用戶平時瀏覽的內容推薦相似內容,也會有一些“Following”的內容。這樣做的目的是為了提高留存率,因為“For you”大部分是推薦內容,如果推薦的內容不感興趣,可能會導致點擊率低,從而影響留存率。所以在召回時,會召回一些“Following”的內容,以保持留存率,并根據算法推送可能感興趣的內容,來調整推薦和關注內容的比例。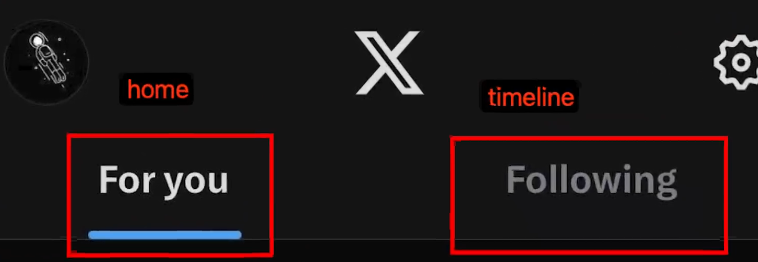
?“Following”模塊主要是關注的人發布的推文。我們了解了這兩個模塊后,來分析這兩個模塊。“Following”是時間軸模塊,而時間軸模塊是Twitter的核心模塊,位于草圖中間偏上的位置。時間軸上60%的推文來自于關注的人,推薦內容占20%,廣告也占20%,然后基于此進行調整。

我們逐個分析小模塊:
-
People discover:關注的人所發推文的服務。
-
Reservers:需要召回的廣告,并且是該用戶可能感興趣的廣告。這是Twitter主要的變現手段,馬斯克也有補充,廣告混合器可以大大提高相關性,并且用更少的曝光獲取更多的點擊。
-
On boring server:基于所關注的人去推薦新內容來擴展內容板塊,也就是引流。
-
Ta scholar:對召回的推文廣告新內容做打分進行排序,來決定展示在用戶面前的順序。排序非常重要,排在前面意味著有更高的曝光,可能帶來更大的收益。
-
這幾個小模塊之間都是以微服務的形式做調用關系,多個微服務之間用的是Free RPC做RPC調用,主要由阿帕奇社區做維護。
總體來說,Twitter的架構和大部分推薦系統的架構相似。接下來我們來看Home頁面,這部分其實和時間線也有類似的召回計算排序,只是召回和計算的重點不一,重點更多的放在了推薦上。不過這部分的計算要比探探模塊要快,因為歷史原因,導致它耐模塊很難做變動,畢竟Home模塊是比較新的模塊。
接著來介紹一下存儲介質:
-
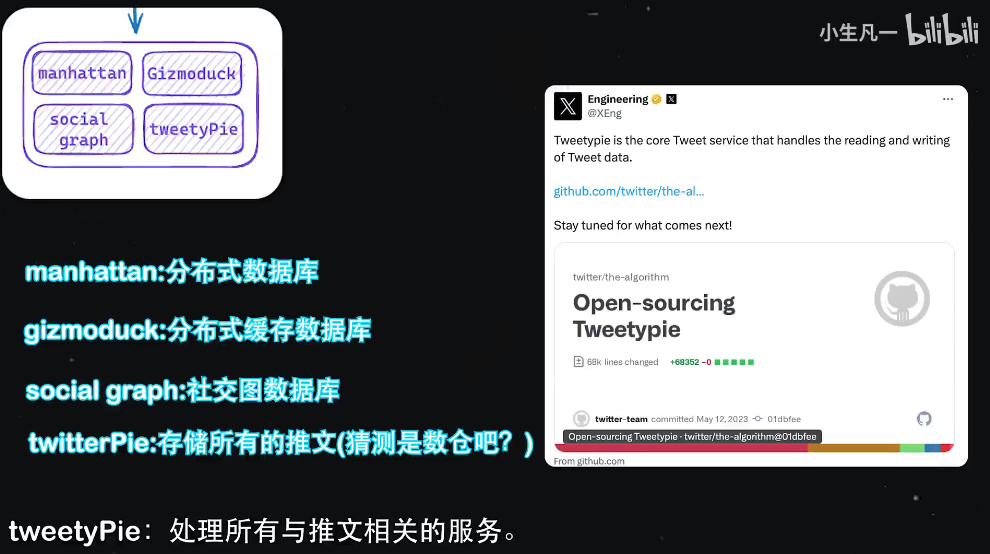
Manhattan:Twitter的分布式數據庫,類似于一個分布式的MySQL。
-
GIS:Twitter的分布式緩存,類似于Redis。
-
Show show gap:我猜測是一個存儲社交圖數據庫,存儲用戶和用戶之間的聯系,這樣就不需要每一次召回的時候都計算一次用戶和用戶之間的關系了。
?
Twitter處理所有與推文相關的服務,然后到了推薦模塊,這個模塊在草圖的右下角。推薦模塊包括召回動作,盡可能的召回數據,然后進行特征提取,做特征工程,輸出的特征是后續推薦系統的輸入,也就是推薦系統會推出具備這些特征的內容,而這些內容是符合用戶特征的,盡可能的留住用戶。這些特征會根據fit的數據來做權重比例,而這個權重比例就會在下一個score環節做計算,來決定最終的排序。
-
Publication service:對用戶特征進行預測,預測出可能會對哪一些特征感興趣。
-
Future hydration:其實就是將用戶的特征進行存儲,方便快速調用。
 ?
?









))





刪邊?鄰接矩陣/鏈表/十字鏈對比)



