作者:來自 Elastic?Kofi Bartlett

探索 Elasticsearch 堆內存使用情況和 JVM 垃圾回收,包括最佳實踐以及在堆內存使用過高或 JVM 性能不佳時的解決方法。
堆內存大小是分配給 Elasticsearch 節點中 Java 虛擬機的 RAM 數量。
從 7.11 版本開始,Elasticsearch 默認會根據節點的角色和總內存自動設置 JVM 堆內存大小。對于大多數生產環境,推薦使用默認配置。然而,如果你希望手動設置 JVM 堆內存大小,一般規則是將 -Xms 和 -Xmx 設置為相同的值,該值應為系統總可用內存的 50%,但最大不應超過大約 31GB。
較大的堆內存可以為節點提供更多用于索引和搜索操作的內存。但節點也需要內存用于緩存,因此使用 50% 可以在兩者之間保持健康的平衡。出于同樣的原因,在生產環境中應該避免在與 Elasticsearch 相同的節點上運行其他高內存占用的進程。
通常,堆使用率會呈鋸齒狀波動,在最大堆使用量的 30% 到 70% 之間。這是因為 JVM 會逐漸增加堆使用率,直到垃圾回收過程釋放出內存。當垃圾回收過程無法跟上時,就會出現高堆使用率。一個高堆使用率的跡象是垃圾回收無法將堆使用率降低到大約 30%。
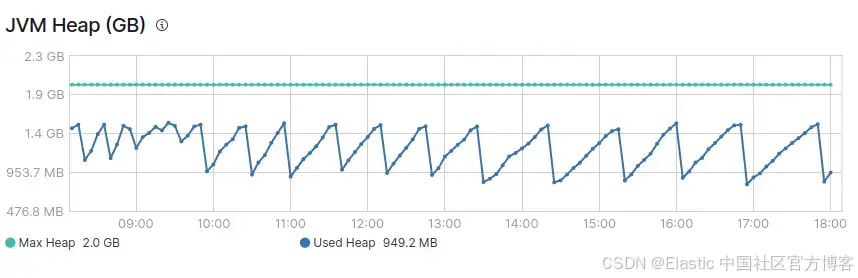
在上面的圖像中,你可以看到 JVM 堆的正常鋸齒狀變化。
你還會看到有兩種類型的垃圾回收:年輕代(young) GC 和老年代(old)?GC。
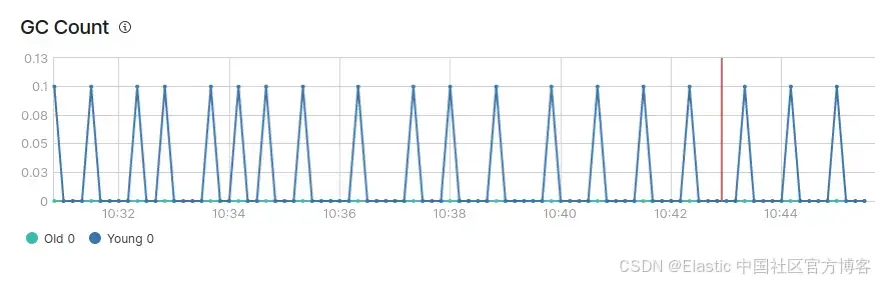
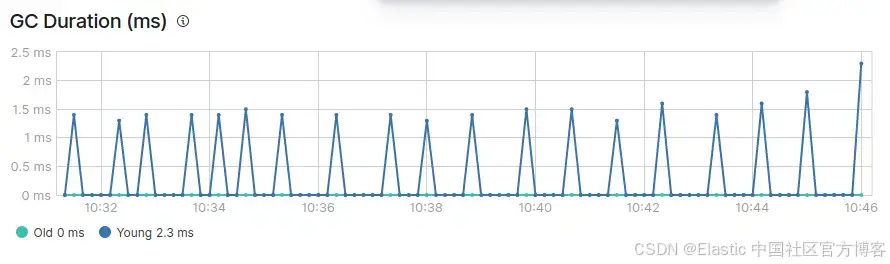
在健康的 JVM 中,垃圾回收理想情況下應滿足以下條件:
- 年輕代?GC 處理速度快(在 50 毫秒內完成)。
- 年輕代 GC 執行頻率不高(大約每 10 秒一次)。
- 老年代 GC 處理速度快(在 1 秒內完成)。
- 老年代 GC 執行頻率不高(每 10 分鐘或更久一次)。
當堆內存使用過高或 JVM 性能不佳時的解決方法
堆內存使用增加可能由多種原因引起:
分片過多( Oversharding )
請在這里參閱關于分片過多的文檔。
聚合數據量過大( Large aggregation sizes )
為了避免聚合數據量過大,請在查詢中盡量減少聚合桶( size )的數量。
GET /_search
{"aggs" : {"products" : {"terms" : {"field" : "product","size" : 5}}}
}你可以使用慢查詢日志( slow logs ),并通過以下方式在特定索引上啟用它:
PUT /my_index/_settings
{"index.search.slowlog.threshold.query.warn": "10s","index.search.slowlog.threshold.query.info": "5s","index.search.slowlog.threshold.query.debug": "2s","index.search.slowlog.threshold.query.trace": "500ms","index.search.slowlog.threshold.fetch.warn": "1s","index.search.slowlog.threshold.fetch.info": "800ms","index.search.slowlog.threshold.fetch.debug": "500ms","index.search.slowlog.threshold.fetch.trace": "200ms","index.search.slowlog.level": "info"
}執行時間長的查詢很可能是資源密集型的操作。
批量索引請求過大( Excessive bulk index size )
如果你發送的是大型請求,這可能導致堆內存消耗過高。嘗試減小批量索引請求的大小。
映射問題( Mapping issues )
特別是當你使用了 fielddata: true 時,這可能會大量占用 JVM 堆內存。
堆內存大小設置不當( Heap size incorrectly set )
你可以通過設置環境變量手動定義堆內存大小:
ES_JAVA_OPTS="-Xms2g -Xmx2g"在你的 Elasticsearch 配置目錄中編輯 jvm.options 文件:
-Xms2g
-Xmx2g環境變量設置優先于文件設置。
需要重啟節點才能使設置生效。
JVM 新代比例設置不當( JVM new ratio incorrectly set )
通常不需要手動設置這個值,因為 Elasticsearch 默認會設置此值。這個參數定義了 JVM 中 “新生代” 和 “老年代” 對象可用空間的比例。
如果你發現老年代 GC 變得非常頻繁,可以嘗試在 Elasticsearch 配置目錄中的 jvm.options 文件中專門設置這個值。
-XX:NewRatio=3在大型 Elasticsearch 集群中管理堆內存使用和 JVM 垃圾回收的最佳實踐是什么?
在大型 Elasticsearch 集群中管理堆內存使用和 JVM 垃圾回收的最佳實踐是確保堆內存大小設置為可用內存的 50% 的最大值,并根據特定用例優化 JVM 垃圾回收設置。監控堆內存大小和垃圾回收指標以確保集群運行在最佳狀態是非常重要的。具體來說,重要的是監控 JVM 堆內存大小、垃圾回收時間和垃圾回收暫停時間。此外,還需要監控垃圾回收周期的數量以及在垃圾回收中花費的時間。通過監控這些指標,可以識別堆內存或垃圾回收設置的潛在問題,并在必要時采取糾正措施。
想要獲得 Elastic 認證嗎?了解下一期 Elasticsearch 工程師培訓的時間!
Elasticsearch 包含了許多新功能,幫助你為特定用例構建最佳的搜索解決方案。深入我們的示例筆記本,了解更多內容,開始免費云試用,或者立即在本地機器上嘗試 Elastic。
原文:Elasticsearch heap size usage and JVM garbage collection - Elasticsearch Labs

:常見位運算操作總結)













))



