研究動機
論文核心問題及研究背景分析
1. 研究領域及其重要性
- 研究領域:檢索增強生成(Retrieval-Augmented Generation, RAG)系統,結合自然語言處理(NLP)與信息檢索技術。
- 重要性:
- RAG通過動態整合外部知識,解決了傳統大語言模型(LLMs)依賴靜態預訓練數據的局限性。
- 在開放域問答、實時信息生成等場景中,RAG能顯著提升生成內容的準確性和信息完整性。
- 對知識密集型任務(如醫療問答、法律分析)至關重要,需高效管理大規模外部文檔。
2. 當前領域面臨的挑戰或痛點
| 挑戰 | 具體表現 | 影響 |
|---|---|---|
| 輸入長度限制 | LLMs的上下文窗口有限(通常數千token),難以處理長文檔 | 需分塊處理,但分塊可能破壞語義連貫性 |
| 上下文碎片化 | 固定分塊策略忽略語義邊界,導致信息割裂 | 檢索不完整,生成結果缺乏連貫性 |
| 位置偏差 | LLMs對文檔開頭信息更敏感,中間/尾部信息易被忽略 | 關鍵信息可能未被有效檢索或利用 |
| 效率與效果權衡 | 傳統分塊效率高但犧牲語義;高級方法(如上下文增強)計算成本高 | 實際應用中需平衡資源消耗與性能 |
3. 論文關注的具體問題及研究意義
具體問題
-
兩種分塊策略的對比:
- Late Chunking(延遲分塊):先對整個文檔嵌入,再分塊聚合,保留全局上下文。
- Contextual Retrieval(上下文增強檢索):分塊后附加LLM生成的上下文,提升語義連貫性。
-
關鍵研究問題(RQs):
- RQ#1:早期分塊 vs. 延遲分塊對檢索和生成性能的影響。
- RQ#2:傳統分塊 vs. 上下文增強分塊的效果差異。
研究意義
-
理論意義:
- 揭示兩種分塊策略在上下文保留與效率上的權衡關系。
- 提出動態分塊模型(如Topic-Qwen)和混合排名策略(BM25 + 稠密嵌入),為優化RAG系統提供新思路。
-
應用價值:
- 資源受限場景:優先選擇延遲分塊(效率高,但需適配長上下文嵌入模型)。
- 高精度需求場景:采用上下文增強檢索(犧牲計算資源換取語義連貫性)。
- 開源代碼與數據集(NFCorpus、MSMarco)支持實際部署與復現。
相關研究工作
以下是針對檢索增強生成(RAG)中分塊策略研究的歸納總結:
主要已有方法或技術路線
| 方法名稱 | 核心思想 | 技術特點 |
|---|---|---|
| 固定尺寸分塊 | 將文檔均等分割為固定長度的文本塊 | 簡單高效,但忽略語義邊界 |
| 語義分塊 | 根據語義邊界(如段落、主題)動態分割文本 | 基于語義模型檢測斷點,保留局部上下文 |
| 延遲分塊 | 先對整個文檔進行詞元級嵌入,再分割為塊并聚合 | 利用長上下文嵌入模型保留全局信息 |
| 上下文檢索 | 分塊后通過LLM生成全局上下文并預置到每個塊中,再結合混合檢索(BM25+嵌入) | 增強局部塊的語義連貫性,但需額外生成上下文 |
方法對比與優缺點分析
| 方法 | 優點 | 缺點 |
|---|---|---|
| 固定尺寸分塊 | 實現簡單、計算高效;兼容性強 | 破壞上下文連貫性;可能導致關鍵信息分割 |
| 語義分塊 | 保留局部語義結構;減少信息碎片化 | 依賴語義模型;計算成本較高;動態分割不穩定 |
| 延遲分塊 | 保留全局上下文;適配長文本嵌入模型 | 嵌入模型性能影響顯著;長文檔處理效率低;部分模型(如BGE-M3)表現下降 |
| 上下文檢索 | 語義連貫性最佳(NDCG@5提升5%);支持混合檢索提升召回率 | 計算資源需求高(需LLM生成上下文);長文檔內存占用大 |
現有研究的不足與未解決問題
-
效率與效果的權衡
- 延遲分塊和上下文檢索雖提升效果,但計算成本顯著增加(如上下文檢索需要20GB VRAM處理長文檔)。
- 動態分塊模型(如Topic-Qwen)耗時是固定分塊的4倍,且生成結果不穩定。
-
長文檔處理瓶頸
- 現有方法(尤其是上下文檢索)對長文檔的支持有限,GPU內存限制導致實驗僅使用20%數據集。
-
模型依賴性
- 延遲分塊效果高度依賴嵌入模型(例如Jina-V3表現優于BGE-M3),缺乏普適性結論。
-
生成性能未顯著提升
- 實驗顯示分塊策略對最終生成質量(問答任務)影響有限,需更深入的端到端優化。
-
統一評估框架缺失
- 不同方法在數據集、評測指標上差異大(如NFCorpus與MSMarco),橫向對比困難。
可以看出, 當前RAG分塊策略的研究聚焦于平衡上下文保留與計算效率。傳統方法(固定分塊、語義分塊)在簡單場景中仍具優勢,而延遲分塊和上下文檢索在復雜語義任務中表現更優但代價高昂。未來需探索輕量化上下文增強、長文檔優化技術,并建立統一評估標準以推動實際應用。
研究思路來源
作者的研究思路主要受到以下前人工作的啟發:
- 經典RAG框架:基于Lewis等人(2020)提出的RAG基礎架構,結合檢索機制與生成模型,但在處理長文檔時面臨輸入限制和上下文碎片化問題。
- 固定分塊與語義分塊:傳統方法如固定窗口分塊(如[7])和語義分塊(如Jina-Segmenter API),但無法解決全局上下文丟失問題。
- 動態分塊技術:如監督分割模型(Koshorek et al., 2018)和端到端優化分塊(Moro & Ragazzi, 2023),但計算成本高且依賴標注數據。
- 長上下文嵌入模型:如Ding等人(2024)提出的LongRoPE,但實際應用中仍存在位置偏差(Hsieh et al., 2024)。
作者提出新方法的動機源于以下核心觀察與假設:
- 傳統分塊的局限性:
- 上下文割裂:固定分塊破壞文檔的語義連貫性,導致檢索不完整(例如,一個分塊可能缺少公司名稱或時間信息)。
- 位置偏差:LLM對文檔開頭信息更敏感,而中間或尾部信息易被忽略(Lu et al., 2024)。
- 效率與效果的權衡:動態分塊模型(如Topic-Qwen)雖提升效果,但生成不一致且計算成本高。
- 假設:
- 延遲分塊保留全局上下文:在文檔級嵌入后再分塊(Late Chunking)可減少局部語義損失。
- 上下文增強提升檢索質量:通過LLM生成附加上下文(Contextual Retrieval)可彌補分塊的語義不完整。
3. 主要創新點與差異化對比
論文的核心創新點及與現有工作的對比:
| 創新點 | 技術細節 | 與現有工作的差異化 | 效果對比 |
|---|---|---|---|
| Late Chunking(延遲分塊) | 先對整個文檔進行嵌入,再分塊并聚合向量。 | 區別于傳統“先分塊后嵌入”,避免分塊前的上下文丟失。 | 優勢: - 保留全局語義(如文檔主題一致性); - 計算效率高(無需LLM生成額外內容)。 劣勢: - 對長文檔嵌入模型依賴性強(如BGE-M3效果差); - 部分場景下相關性下降(表3中MsMarco數據集表現弱于早期分塊)。 |
| Contextual Retrieval(上下文檢索) | 分塊后通過LLM生成上下文摘要(如Phi-3模型),并與BM25稀疏向量融合排序。 | 結合語義(密集向量)與精確匹配(稀疏向量),優于單一檢索策略。 | 優勢: - 提升檢索完整性(NDCG@5提高5.3%,表5); - 緩解位置偏差(通過上下文補充關鍵信息)。 劣勢: - 計算成本高(GPU內存占用達20GB); - 依賴LLM生成質量(小模型如Phi-3可能表現不穩定)。 |
| 動態分塊模型優化 | 測試Simple-Qwen和Topic-Qwen分塊模型,結合主題邊界檢測。 | 超越傳統固定或語義分塊,但需權衡生成穩定性與計算效率。 | 優勢: - 自適應內容分塊(如按主題劃分); - 提升下游任務性能(Jina-V3模型NDCG@5達0.384)。 劣勢: - 生成不一致性(分塊邊界波動); - 處理時間增加(Topic-Qwen耗時4倍于固定分塊)。 |
解決方案細節
論文針對傳統RAG(檢索增強生成)系統中固定分塊(fixed-size chunking)導致的上下文碎片化問題,提出了兩種改進策略:
-
延遲分塊(Late Chunking)
- 核心思想:推遲分塊過程,先對整個文檔進行嵌入(embedding),保留全局上下文,再分割為塊。
- 原理:通過長上下文嵌入模型直接處理完整文檔,避免早期分塊造成的語義割裂。
-
上下文檢索(Contextual Retrieval)
- 核心思想:在分塊后,通過大語言模型(LLM)為每個塊動態生成補充上下文。
- 原理:利用LLM提取文檔的全局語義信息,附加到分塊中,增強單一塊的語義連貫性。
方法的主要組成模塊及功能
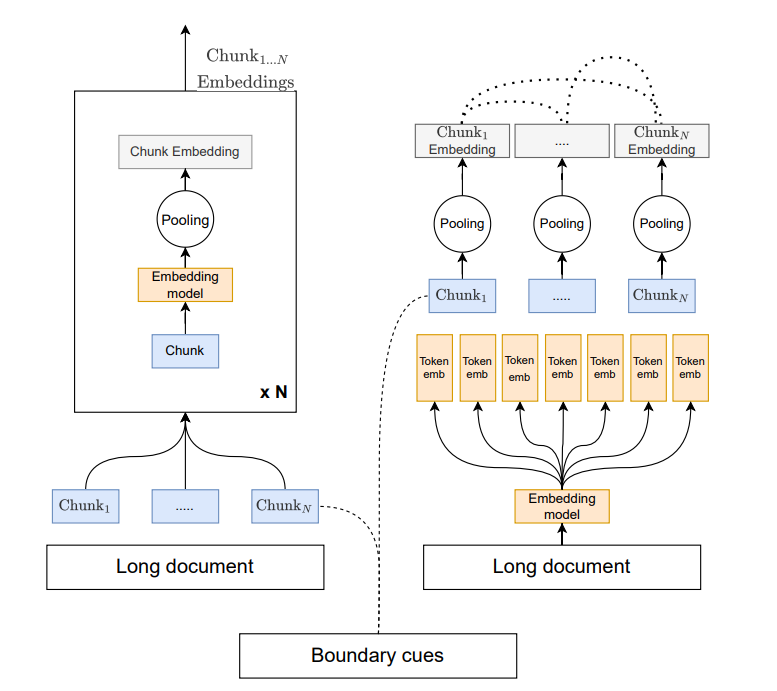
1. 延遲分塊(Late Chunking)流程
完整文檔 → Token級嵌入 → 分塊 → 池化 → 塊嵌入
-
模塊功能:
- Token級嵌入:使用長上下文嵌入模型(如Stella-V5)對完整文檔生成細粒度嵌入。
- 動態分塊:根據語義邊界或固定窗口分割嵌入結果。
- 池化(Pooling):對每個塊的Token嵌入取均值,生成塊級嵌入。
Jina有篇文章,更詳細的解釋了Late Chunking,文章鏈接如下;
長文本表征模型中的后期分塊
https://jina.ai/news/late-chunking-in-long-context-embedding-models/
"Late Chunking"方法首先將嵌入模型的 transformer 層應用于整個文本或盡可能多的文本。這會為每個 token 生成一個包含整個文本信息的向量表示序列。隨后,對這個 token 向量序列的每個塊應用平均池化,生成考慮了整個文本上下文的每個塊的嵌入。與生成獨立同分布(i.i.d.)塊嵌入的樸素編碼方法不同,Late Chunking 創建了一組塊嵌入,其中每個嵌入都"以"前面的嵌入為條件,從而為每個塊編碼更多的上下文信息。
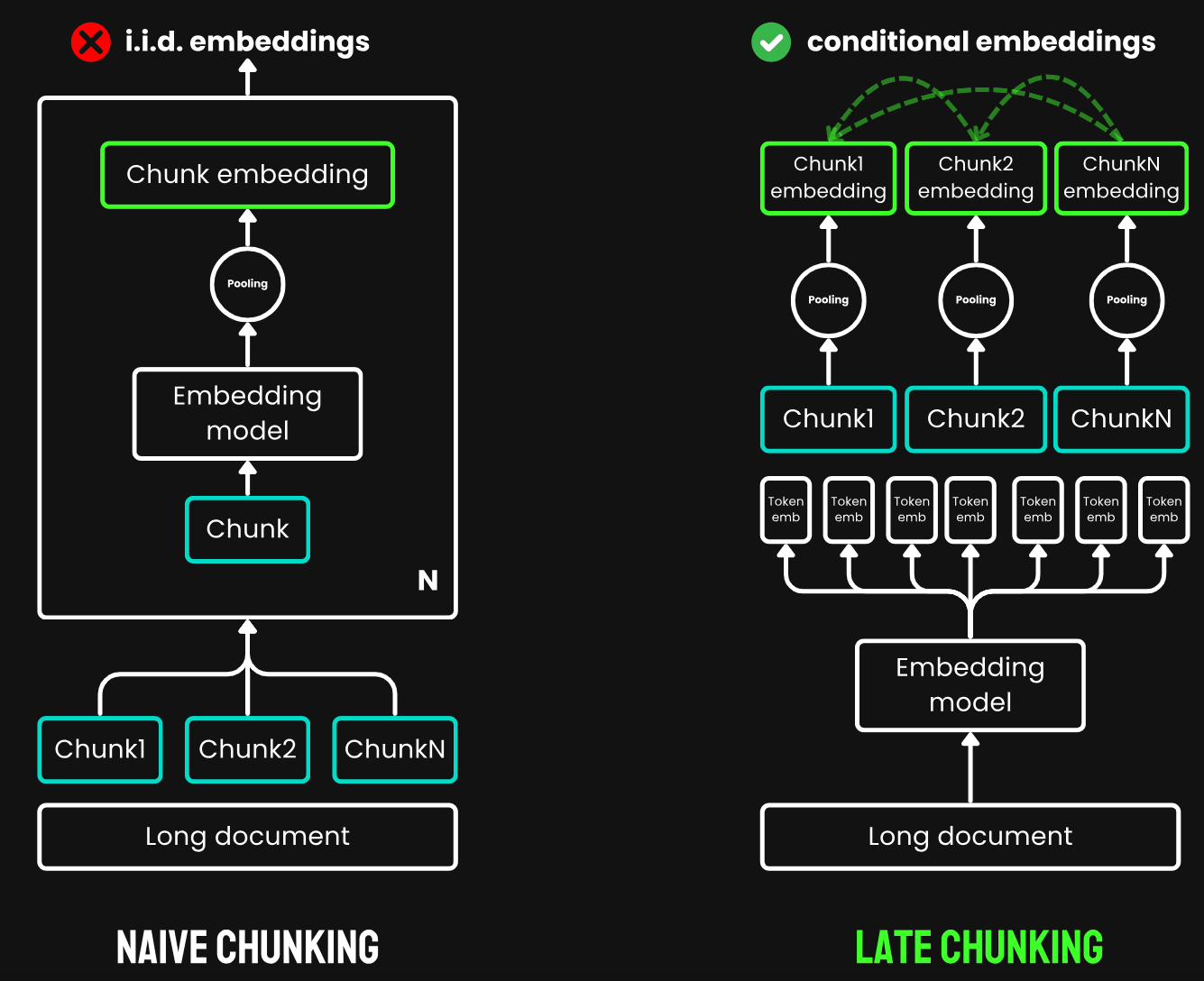
傳統分塊策略(左)和 Late Chunking 策略(右)的示意圖。
2. 上下文增強切塊(Contextual Retrieval)流程
分塊 → LLM生成上下文 → 塊+上下文嵌入 → 混合檢索(BM25+密集檢索) → 重排序
-
模塊功能:
- 上下文生成:用LLM為每個塊生成補充信息(如所屬章節、主題)。
- 混合檢索:結合BM25的精確匹配和密集嵌入的語義匹配(權重4:1)。
- 重排序:使用交叉編碼器(cross-encoder)對檢索結果重新評分。
關鍵技術細節
1. 延遲分塊的關鍵改進
-
長上下文嵌入模型:支持處理超長文檔(如Stella-V5支持131k Token)。
-
動態分塊策略:
- Simple-Qwen:基于文檔結構(如標題、段落)分塊。
- Topic-Qwen:基于主題邊界分塊(通過LLM識別主題切換點)。
2. 上下文檢索的關鍵技術
-
上下文生成提示模板:
"基于以下文檔,為當前塊生成上下文摘要:[文檔內容] [當前塊]" -
混合檢索的權重分配:
嵌入類型 權重 密集嵌入 1.0 BM25稀疏嵌入 0.25 -
重排序模型:Jina Reranker V2(交叉編碼器架構,計算查詢與塊的相關性得分)。
3. 動態分塊模型的權衡
| 分塊策略 | 優點 | 缺點 |
|---|---|---|
| 固定窗口分塊 | 計算效率高 | 忽略語義邊界 |
| 語義分塊(Jina) | 保留語義連貫性 | 依賴外部API,速度較慢 |
| 動態分塊(Qwen) | 自適應文檔結構/主題 | 生成不穩定,計算成本高 |
實驗與性能對比
1. 檢索性能(NFCorpus數據集)
| 方法 | NDCG@5 | MAP@5 | F1@5 |
|---|---|---|---|
| 傳統分塊(Early) | 0.303 | 0.137 | 0.193 |
| 延遲分塊(Late) | 0.380 | 0.103 | 0.185 |
| 上下文檢索(RFR) | 0.317 | 0.146 | 0.206 |
2. 計算資源消耗
| 方法 | VRAM占用 | 處理時間(NFCorpus) |
|---|---|---|
| 傳統分塊 | 5-10GB | 30分鐘 |
| 延遲分塊 | 10-15GB | 60分鐘 |
| 上下文檢索 | 20GB+ | 120分鐘+ |
- 延遲分塊:適合資源受限場景,但可能犧牲相關性。
- 上下文檢索:適合對語義連貫性要求高的任務,但需高算力支持。
- 實際應用:短文檔優先選擇上下文檢索,長文檔可嘗試延遲分塊與動態分塊結合。
論文通過系統實驗驗證了兩種方法的互補性,為RAG系統的分塊策略選擇提供了明確指導。
實驗設計與結果分析
1. 實驗目的與驗證假設
-
目的:比較兩種高級分塊策略(Late Chunking 和 Contextual Retrieval)在 RAG 系統中的效果,驗證它們在 檢索準確性、生成連貫性 和 計算效率 上的優劣。
-
核心假設:
- Late Chunking 通過延遲分塊保留全局上下文,可能提升檢索效果。
- Contextual Retrieval 通過 LLM 生成上下文增強分塊語義,可能改善生成質量,但需更高計算資源。
2. 數據集與任務設置
| 數據集 | 任務 | 特點 |
|---|---|---|
| NFCorpus | 檢索性能評估 | 長文檔(平均長度長),需處理上下文碎片化問題;子集實驗(20%數據)用于降低計算開銷。 |
| MSMarco | 問答生成評估 | 短文本段落,缺乏完整文檔上下文,用于測試生成任務中信息整合能力。 |
任務設置:
- 檢索任務:從文檔庫中檢索與查詢相關的文檔/段落。
- 生成任務:基于檢索結果生成答案,評估語義連貫性和準確性。
3. 評估指標
| 指標 | 含義 |
|---|---|
| NDCG@k | 歸一化折損累積增益,衡量前 k 個結果的排序質量,重視高相關性結果的排名。 |
| MAP@k | 平均精度均值,衡量所有查詢的檢索精度均值,關注相關結果的位置分布。 |
| F1@k | 精確率與召回率的調和平均,平衡檢索結果中相關性與完整性的權衡。 |
4. 基線方法與對比實驗設置
| 方法類型 | 方法細節 | 特點 |
|---|---|---|
| 傳統 RAG | 早期分塊(固定窗口或語義分塊) + 嵌入模型(如 Jina-V3、BGE-M3)。 | 分塊后嵌入,可能丟失全局上下文。 |
| Late Chunking | 先嵌入完整文檔,再分塊并池化(mean pooling)生成分塊嵌入。 | 保留全局上下文,計算效率較高。 |
| Contextual Retrieval | 分塊后通過 LLM 生成上下文(如 Phi-3.5-mini),結合 Rank Fusion(BM25 + 密集嵌入) | 增強語義連貫性,但需額外生成步驟和 GPU 資源。 |
對比實驗設置:
| 實驗組 | 分塊策略 | 嵌入模型 | 數據集 | 關鍵參數 |
|---|---|---|---|---|
| RQ#1 | Early vs Late | Stella-V5, Jina-V3 | NFCorpus, MSMarco | 分塊大小 512 字符,動態分塊模型 |
| RQ#2 | Contextual vs 傳統 | Jina-V3, BGE-M3 | NFCorpus 子集 | Rank Fusion 權重(4:1) |
5. 實驗環境
| 組件 | 配置/參數 |
|---|---|
| 硬件 | NVIDIA RTX 4090(24GB VRAM),受限于顯存,部分實驗使用數據子集。 |
| 生成模型 | Phi-3.5-mini-instruct(4-bit 量化),用于生成上下文和問答任務。 |
| 嵌入模型 | Jina-V3(MTEB 排名 53)、Stella-V5(排名 5)、BGE-M3(排名 211)等。 |
| 分塊工具 | Jina-Segmenter(語義分塊)、Simple-Qwen(動態分塊)、Topic-Qwen(主題分塊)。 |
| 檢索庫與工具 | Milvus 向量數據庫(支持 BM25 與密集嵌入混合檢索),Jina Reranker V2(重排序)。 |
驗證嚴謹性體現
- 控制變量:統一使用相同嵌入模型(如 Jina-V3)對比不同分塊策略。
- 數據集適配:針對文檔長度調整實驗規模(如 NFCorpus 子集解決顯存限制)。
- 多指標評估:結合檢索(NDCG、MAP)和生成(F1)指標,全面衡量性能。
- 計算效率分析:記錄處理時間與顯存占用(如 Contextual Retrieval 顯存達 20GB)。
- 統計顯著性:多次實驗取均值,結果表格中標注最優值(Bold 顯示)。
論文通過系統化的實驗設計,驗證了兩種分塊策略在不同場景下的權衡:Late Chunking 效率更優,Contextual Retrieval 語義更佳,為實際 RAG 系統優化提供了重要參考。
6. 關鍵實驗結果
| 評估指標 | 上下文檢索 (ContextualRankFusion) | 延遲分塊 (Late Chunking) | 早期分塊 (Early Chunking) |
|---|---|---|---|
| NDCG@5 | 0.317 | 0.309 | 0.312 (最佳嵌入模型) |
| MAP@5 | 0.146 | 0.143 | 0.144 (最佳嵌入模型) |
| F1@5 | 0.206 | 0.202 | 0.204 (最佳嵌入模型) |
| 計算資源消耗 | 高(需LLM生成上下文 + 重排序) | 中 | 低 |
| 適用場景 | 長文檔、高語義連貫性需求 | 資源受限、效率優先 | 固定長度、簡單任務 |
- 嵌入模型對比:
- Jina-V3 在上下文檢索中表現最佳(NDCG@5=0.317)。
- BGE-M3 在早期分塊中優于延遲分塊(NDCG@5=0.246 vs. 0.070)。
- 動態分塊模型(如Topic-Qwen)在語義分割中提升效果,但計算耗時增加4倍。
論文結論
核心結論
-
無單一最優策略:
- 上下文檢索在語義連貫性上占優(NDCG@5提升2.5%),但資源消耗高;延遲分塊效率優先,犧牲局部相關性。
-
關鍵權衡維度:
- 任務需求:長文檔、高準確性場景傾向上下文檢索;實時性任務傾向延遲分塊。
- 嵌入模型適配:模型特性(如長上下文支持)顯著影響分塊策略效果。
科學意義
- 實踐指導:為RAG系統設計提供量化權衡框架(如資源-效果平衡表),助力開發者按場景優化。
- 理論創新:驗證了全局上下文保留(延遲分塊)與局部語義增強(上下文檢索)的互補性,為后續混合策略(如動態切換)提供基礎。
- 開源價值:釋放代碼與數據集(MIT協議),推動社區在真實場景中復現與擴展(如優化LLM上下文生成效率)。
對應研究目標
- RQ#1(分塊時機):延遲分塊驗證了全局嵌入的高效性,但需結合模型特性(如BGE-M3不適用)。
- RQ#2(上下文增強):上下文檢索通過LLM生成與重排序提升語義質量,但需硬件支持。
- 核心目標達成:系統性對比兩種策略,揭示了其在RAG系統中的互補性與場景適配邊界。
代碼實現
延遲切塊
class BgeEmbedder():def __init__(self):self.model_id = 'BAAI/bge-m3'self.model = AutoModel.from_pretrained(self.model_id, trust_remote_code=True).cuda();self.tokenizer = AutoTokenizer.from_pretrained(self.model_id);self.model.eval()def get_model(self):return self.modeldef encode(self, chunks, task, max_length=512):if type( chunks) == str:chunks = [chunks]chunks_embeddings = []for chunk in chunks:tokens = self.tokenizer(chunk, return_tensors='pt')['input_ids'].to("cuda")with torch.no_grad():token_embeddings = self.model(input_ids=tokens)[0]pooled_embeddings = token_embeddings.sum(dim=1) / len(token_embeddings)pooled_embeddings = F.normalize(pooled_embeddings, p=2, dim=1).squeeze(0)chunks_embeddings.append(pooled_embeddings.to(dtype=torch.float32).detach().cpu().numpy())if task == 'retrieval.query':return chunks_embeddingselse:return [chunks_embeddings]# def encode(self, chunks, task, max_length=512):# if type( chunks) == str:# chunks = [chunks]# chunks_embeddings = []# for chunk in chunks:# tokens = self.tokenizer(chunk, return_tensors='pt')['input_ids'].to("cuda")# with torch.no_grad():# token_embeddings = self.model(input_ids=tokens)[0]# div = token_embeddings.size(1)# pooled_embeddings = token_embeddings.sum(dim=1) / div# pooled_embeddings = F.normalize(pooled_embeddings, p=2, dim=1).squeeze(0)# chunks_embeddings.append(pooled_embeddings.to(dtype=torch.float32).detach().cpu().numpy())# if task == 'retrieval.query':# return chunks_embeddings# else:# return [chunks_embeddings]def encodeLateChunking(self, text_token, span_annotation, task, max_length = None ):with torch.no_grad():token_embeddings = self.model(input_ids=text_token)[0]outputs = []for embeddings, annotations in zip(token_embeddings, span_annotation):if (max_length is not None): # remove annotations which go bejond the max-length of the modelannotations = [(start, min(end, max_length - 1))for (start, end) in annotationsif start < (max_length - 1)]pooled_embeddings = [embeddings[start:end].sum(dim=0) / (end - start)for (start, end) in annotationsif (end - start) >= 1]pooled_embeddings = [F.normalize(pooled_embedding.unsqueeze(-1), p=2, dim=0).squeeze(-1)for pooled_embedding in pooled_embeddings]pooled_embeddings = [embedding.to(dtype=torch.float32).detach().cpu().numpy()for embedding in pooled_embeddings]outputs.append(pooled_embeddings)return outputs
上下文增強切塊
class ChunkContextualizer():"""This class is used to contextualize the chunks of text.It gives to the model the document and the chunk of text to generate the context to be added to the chunk.The model is a language model that generates the context."""def __init__(self, corpus, prompt, examples, llm_id, segmenter,load_in_4bit = True): #model_templateself.corpus = corpusself.prompt = promptself.examples = examplesself.segmenter = segmenter#self.model_template = model_template#self.chat_template = (model_template,"<|end|>")self.llm_id = llm_idself.load_in_4bit = load_in_4bitdtype = Noneself.llm_model, self.llm_tokenizer = FastLanguageModel.from_pretrained(model_name = model_id,dtype = dtype,load_in_4bit = load_in_4bit,)self.llm_tokenizer = get_chat_template(self.llm_tokenizer,chat_template = 'phi-3.5',#self.chat_template, # apply phi-3.5 chat templatemapping = {"role" : "from", "content" : "value", "user" : "human", "assistant" : "gpt"},)FastLanguageModel.for_inference(self.llm_model);self.generation_config = GenerationConfig(eos_token_id=self.llm_tokenizer.convert_tokens_to_ids("<|end|>"))def get_llm(self):return self.llm_modeldef get_formatted_prompt(self,doc,chunk):ex = '\n'.join([f'CHUNK: {chunk}\nCONTEXT: {context}' for (chunk, context) in self.examples]) # format examples with chunk and contextreturn self.prompt.format(doc_content=doc, chunk_content=chunk, examples=ex) # format prompt with chunk, document and examplesdef extract_llm_responses(self, conversation: str): # extract assistant responses from the conversation# Regex to match assistant output between <|assistant|> and <|end|>assistant_responses = re.findall(r"<\|assistant\|>(.*?)<\|end\|>", conversation, re.DOTALL)return assistant_responsesdef contextualize(self, chunking_size):ids,texts = zip(*[ (key, value['text']) for (key,value) in self.corpus.items() ])ids,texts = list(ids), list(texts)chunks_ids,contextualized_chunks=[],[]pbar = tqdm(total=len(texts), desc="Contextualizing Chunks", mininterval=60.0)for i in range(len(texts)):chunks = self.segmenter.segment(input_text=texts[i],max_chunk_length=chunking_size) # segment text into chunks with passed segmenterfor j in range(len(chunks)):chunk = chunks[j]doc = texts[i] # getting document for all the chunksprompt = self.get_formatted_prompt(doc,chunk) # formatting prompt with current document and current chunkmessages=[{"from": "human", "value": prompt}]inputs = self.llm_tokenizer.apply_chat_template( # apply chat template to the prompt to get the inputmessages,tokenize=True,return_tensors="pt",padding=True,).to("cuda")output_ids = self.llm_model.generate(input_ids=inputs,do_sample=False,max_new_tokens=2000,generation_config=self.generation_config,)output = self.llm_tokenizer.batch_decode(output_ids) # decode the output to textgenerated_context = self.extract_llm_responses(output[0]) # extract context from output stringif generated_context: # only add non-empty entriescontextualized_chunks.append(chunk + '\n' + generated_context[0]) # append generated context to current chunkchunks_ids.append(f'{ids[i]}:{j}')pbar.update(1)return contextualized_chunks, chunks_ids
其中提示語為:
contextual_retrieval_prompt = """
DOCUMENT:
{doc_content}Here is the chunk we want to situate within the whole document
CHUNK:
{chunk_content}Provide a concise context for the following chunk, focusing on its relevance within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the generated context and nothing else.
Output your answer after the phrase "The document provides an overview".
Think step by step.Here there is an example you can look at.
EXAMPLE:
{examples}"""
這個提示語(prompt)是一個用于 上下文檢索(contextual retrieval) 的模板,目的是幫助大語言模型(LLM)為給定的文本片段(chunk)生成一個簡潔的上下文描述,從而提升檢索效果。以下是它的詳細解析:
參考資料
- https://arxiv.org/pdf/2504.19754
- https://github.com/disi-unibo-nlp/rag-when-how-chunk




:常見位運算操作總結)













))
