目錄
一、環境準備
? 第一步:安裝并準備 Conda 環境
? 第二步:創建 Whisper 專用的 Conda 虛擬環境
? 第三步:安裝 GPU 加速版 PyTorch(適配 RTX 4060)
? 第四步:安裝 Whisper 和 FFMPEG 依賴
? 補充:可以切換到國內鏡像(加速)
二、編寫代碼實現語音轉文本功能
? 第一步:創建并運行 Whisper 腳本
? 第二步:轉錄完成!🎉
? 注意事項:
1. import whisper
2. file_path = r"..."
3. model = whisper.load_model("medium")
4. result = model.transcribe(file_path, verbose=True)
5. print("📄 識別內容:") 和 print(result["text"])
總結底層流程:
三、TXT格式美化
四、例句對照翻譯
五、常見報錯
? 解決方法:給 Python 顯式指定 ffmpeg.exe 的路徑
六、更高級的功能——使用PyQt添加GUI
一、環境準備
? 第一步:安裝并準備 Conda 環境
如果你還沒裝 Conda(Anaconda 或 Miniconda),請先下載安裝:
推薦下載 Miniconda(輕量):
👉 Miniconda 官網下載地址
下載 Windows 64-bit 安裝版并安裝(默認設置即可)。
? 第二步:創建 Whisper 專用的 Conda 虛擬環境
打開 Anaconda Prompt 或 CMD 命令行,依次輸入以下命令:
# 創建一個新環境,名字叫 whisper_env,使用 Python 3.10
conda create -n whisper_env python=3.10 -y# 進入這個環境
conda activate whisper_env
? 第三步:安裝 GPU 加速版 PyTorch(適配 RTX 4060)
也可以對照自己的設備安裝其他版本或CPU版本。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
這個命令會安裝支持 CUDA 11.8 的 PyTorch,完美適配 RTX 4060,自動使用 GPU 加速。
? 第四步:安裝 Whisper 和 FFMPEG 依賴
pip install git+https://github.com/openai/whisper.git
pip install ffmpeg-python
? 補充:可以切換到國內鏡像(加速)
如果你還是下載慢或失敗,也可以加上清華源:
pip install -U openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
安裝成功后你可以驗證一下:
python -c "import whisper; print(whisper.__version__)"
?確認沒有報錯即可。
還需要你手動安裝 ffmpeg 可執行文件(一次性操作):
Windows 下安裝 FFmpeg:
-
訪問:https://www.gyan.dev/ffmpeg/builds/
-
下載 “Release full” 版本(Zip 文件)
-
解壓到任意文件夾,例如:
C:\ffmpeg -
把
C:\ffmpeg\bin添加到系統環境變量 Path 中:-
搜索“環境變量” → 編輯系統變量 → 找到
Path→ 添加C:\ffmpeg\bin
-
驗證成功:打開新的命令行窗口,輸入:
ffmpeg -version
二、編寫代碼實現語音轉文本功能
? 第一步:創建并運行 Whisper 腳本
-
在當前目錄創建
whisper_transcribe_gpu.py,填入以下代碼:
import whisper
import osdef transcribe_audio(file_path, model_size="large"):if not os.path.isfile(file_path):print("? 找不到文件:", file_path)returnprint(f"🎯 加載 Whisper 模型({model_size})...")model = whisper.load_model(model_size)print(f"🧠 正在識別音頻:{file_path}")result = model.transcribe(file_path, fp16=True) # 使用 GPU 加速print("\n📄 識別內容:\n")print(result["text"])output_file = os.path.splitext(file_path)[0] + "_transcription.txt"with open(output_file, "w", encoding="utf-8") as f:f.write(result["text"])print(f"\n? 轉錄已保存至:{output_file}")# 舉例用法
if __name__ == "__main__":transcribe_audio("7 Test4.Section1.mp3", model_size="large")
-
將你的 MP3 文件(比如
7 Test4.Section1.mp3)放到這個腳本同目錄下。 -
運行腳本:
python whisper_transcribe_gpu.py
? 第二步:轉錄完成!🎉
你將會在終端看到轉錄內容,并且自動保存為 .txt 文本文件。
? 注意事項:
使用ffmpeg轉換文件格式:
CMD輸入:
ffmpeg -i "D:\xx\Programs\VS_Py_AudiosConvertText\audios\_7Test4_Section1.mp3" -ar 16000 -ac 1 -c:a pcm_s16le "D:\xxx\Programs\VS_Py_AudiosConvertText\audios\_7Test4_Section1.wav"文件路徑格式:
“xxx\xxx.mp3”
“xxx\xxx.wav”
“xxx\xxx.m4a”(錄音文件)
……
import whisperfile_path = "audios\錄音.m4a"
model = whisper.load_model("medium")result = model.transcribe(file_path, verbose=True)print("📄 識別內容:")
print(result["text"])output_txt_path = "results\錄音.txt"
with open(output_txt_path, "w", encoding="utf-8") as f:f.write(result["text"])
1. import whisper
-
這是導入 OpenAI 的 Whisper 語音識別庫的 Python 模塊。
-
Whisper 底層是一個基于 Transformer 架構的端到端語音識別模型,支持多種語言的語音轉文字。
2. file_path = r"..."
-
指定要識別的音頻文件的路徑。
-
r""是Python的原始字符串表示法,避免路徑中的反斜杠被誤解析。
3. model = whisper.load_model("medium")
-
調用 Whisper 的
load_model函數加載一個預訓練的模型,這里選用的是"medium"版本。 -
Whisper 提供多種模型大小(tiny, base, small, medium, large),不同模型準確度和運行速度不同。
-
這個加載過程會在后臺從本地緩存或網絡下載模型權重文件,初始化模型結構。
-
加載后模型就可以接受音頻輸入,做后續識別。
4. result = model.transcribe(file_path, verbose=True)
-
這里調用了模型的
transcribe方法,傳入音頻文件路徑,執行音頻識別任務。 -
transcribe內部做了以下步驟:-
音頻預處理:將音頻文件解碼成統一采樣率的波形數據(通常是16kHz單聲道)。
-
特征提取:將音頻波形轉換成聲學特征(如梅爾頻譜),這是模型輸入的格式。
-
模型推理:通過 Transformer 模型進行前向計算,解碼出對應的文本序列。
-
解碼:模型輸出的是概率分布,結合語言模型概率,使用貪心或beam search方法確定最終的文字。
-
可選參數 verbose=True 會在識別過程中打印詳細的日志,幫助調試和觀察進度。
-
-
返回結果
result是一個字典,至少包含"text"字段,是識別出來的文本內容。
5. print("📄 識別內容:") 和 print(result["text"])
-
這兩行是將識別結果文本打印到控制臺。
6. 保存識別結果到txt文件:
output_txt_path = r"..."
with open(output_txt_path, "w", encoding="utf-8") as f:f.write(result["text"])
總結底層流程:
-
加載預訓練模型(初始化模型參數和結構)
-
讀取并預處理音頻數據
-
使用模型進行聲學特征提取和文本解碼
-
輸出文字識別結果
-
將結果保存到文件。
三、TXT格式美化
import whisperfile_path = "audios\_7Test4_Section1.wav"
model = whisper.load_model("large")# 進行轉錄
result = model.transcribe(file_path, verbose=True)# 輸出路徑
output_txt_path = "results\result_output.txt"# 保存為純文本格式(無時間戳)
with open(output_txt_path, "w", encoding="utf-8") as f:f.write("Detecting language using up to the first 30 seconds. Use `--language` to specify the language\n")f.write(f"Detected language: {result['language'].capitalize()}\n")f.write(result["text"].strip()) # 寫入識別結果的純文本部分print("? 文本文件保存完成(無時間戳)!路徑如下:")
print(output_txt_path)
四、例句對照翻譯
使用 whisper 提取的英文文本,再用 Google Translate 或 deep-translator 這類工具翻譯成中文,然后生成如下格式的中英對照文本:
🛠 安裝依賴(只需一次):?
pip install deep-translator
? 腳本代碼:
import whisper
from deep_translator import GoogleTranslator
import os
# 添加 ffmpeg 路徑到系統環境變量中(你之前寫的)
os.environ["PATH"] += os.pathsep + r"D:\LiuYanhong\Apps\Ffmpeg\ffmpeg-7.1.1-full_build\ffmpeg-7.1.1-full_build\bin"file_path = "audios\_7Test4_Section1.mp3"model = whisper.load_model("small", device='cpu') # 使用 CPU 進行轉錄,避免內存不足問題# 轉錄音頻
result = model.transcribe(file_path, verbose=True, fp16=False) # 使用 CPU 進行轉錄,避免內存不足問題# 提取文本,按句子拆分
text = result["text"].strip()
sentences = [s.strip() for s in text.split('.') if s.strip()]
# 補上句號
sentences = [s + '.' for s in sentences]# 翻譯
translator = GoogleTranslator(source='en', target='zh-CN')translated_sentences = [translator.translate(s) for s in sentences]# 確保保存目錄存在
output_dir = "results"
os.makedirs(output_dir, exist_ok=True)# 生成保存路徑
base_name = os.path.splitext(os.path.basename(file_path))[0]
output_txt_path = os.path.join(output_dir, f"{base_name}_transcription.txt")# 寫入中英對照內容
with open(output_txt_path, "w", encoding="utf-8") as f:f.write("Detecting language using up to the first 30 seconds. Use `--language` to specify the language\n")f.write(f"Detected language: {result['language'].capitalize()}\n\n")for en, zh in zip(sentences, translated_sentences):f.write(en + "\n")f.write(zh + "\n\n")print("? 中英對照文本文件保存完成!路徑如下:")
print(output_txt_path)
五、常見報錯
FileNotFoundError: [WinError 2] 系統找不到指定的文件。
這個錯誤 [WinError 2] 系統找不到指定的文件。 明確是因為 Whisper 在底層調用 ffmpeg 時找不到 ffmpeg 可執行文件。
雖然你可以在命令行中用 ffmpeg 成功轉換音頻,但是 Python 中的 Whisper 并不會使用你系統 PATH 中的 ffmpeg,它會調用 ffmpeg 命令,要求它能在 Python 環境里被找到。
最常見的一個報錯:
? 解決方法:給 Python 顯式指定 ffmpeg.exe 的路徑
你只需要把 ffmpeg.exe 所在的文件夾加入到 Python 腳本的環境變量中。操作如下:
import os
# 添加 ffmpeg 路徑到系統環境變量中(你之前寫的)
os.environ["PATH"] += os.pathsep + r"D:\LiuYanhong\Apps\Ffmpeg\ffmpeg-7.1.1-full_build\ffmpeg-7.1.1-full_build\bin"
六、更高級的功能——使用PyQt添加GUI
import sys
import os
from PyQt5.QtWidgets import (QApplication, QWidget, QLabel, QPushButton,QVBoxLayout, QFileDialog, QTextEdit, QMessageBox,QComboBox, QCheckBox
)
from PyQt5.QtCore import QThread, pyqtSignal
import whisper
from deep_translator import GoogleTranslator# 添加 ffmpeg 路徑
os.environ["PATH"] += os.pathsep + r"D:\LiuYanhong\Apps\Ffmpeg\ffmpeg-7.1.1-full_build\ffmpeg-7.1.1-full_build\bin"# Whisper 模型
model = whisper.load_model("small", device="cpu")# 可選語言映射
LANGUAGES = {"英語 (English)": "en","中文 (Chinese)": "zh-CN","日語 (Japanese)": "ja","韓語 (Korean)": "ko","法語 (French)": "fr","德語 (German)": "de","西班牙語 (Spanish)": "es","俄語 (Russian)": "ru"
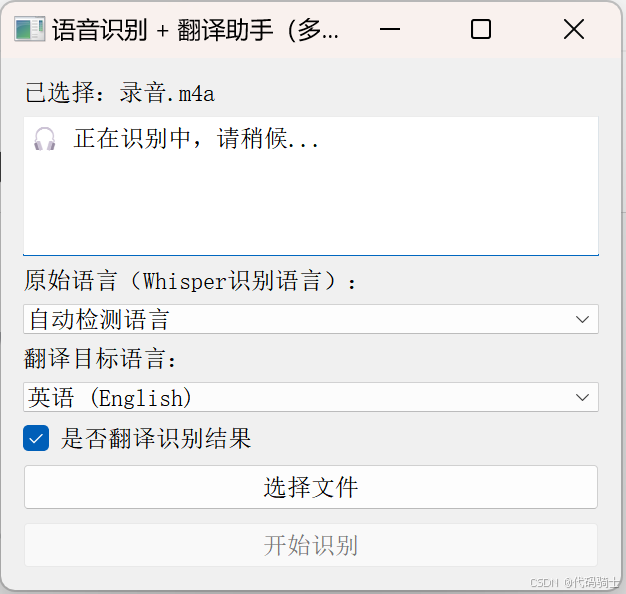
}class TranscriptionWorker(QThread):finished = pyqtSignal(str, str)error = pyqtSignal(str)def __init__(self, file_path, source_lang, target_lang, translate_enabled=True):super().__init__()self.file_path = file_pathself.source_lang = source_langself.target_lang = target_langself.translate_enabled = translate_enableddef run(self):try:result = model.transcribe(self.file_path,language=self.source_lang if self.source_lang != "auto" else None,verbose=False,fp16=False)text = result["text"].strip()sentences = [s.strip() for s in text.split('.') if s.strip()]sentences = [s + '.' for s in sentences]output = f"Detected language: {result['language']}\n\n"if self.translate_enabled:translator = GoogleTranslator(source='auto', target=self.target_lang)translated_sentences = [translator.translate(s) for s in sentences]for en, zh in zip(sentences, translated_sentences):output += f"{en}\n{zh}\n\n"else:output += "\n".join(sentences)# 保存結果output_dir = "results"os.makedirs(output_dir, exist_ok=True)base_name = os.path.splitext(os.path.basename(self.file_path))[0]output_path = os.path.join(output_dir, f"{base_name}_transcription.txt")with open(output_path, "w", encoding="utf-8") as f:f.write(output)self.finished.emit(output, output_path)except Exception as e:self.error.emit(str(e))class TranscriptionApp(QWidget):def __init__(self):super().__init__()self.setWindowTitle("語音識別 + 翻譯助手(多線程+語言選擇)")self.setGeometry(300, 300, 620, 500)self.layout = QVBoxLayout()self.label = QLabel("請選擇音頻/視頻文件:")self.layout.addWidget(self.label)self.result_box = QTextEdit()self.result_box.setReadOnly(True)self.layout.addWidget(self.result_box)# 源語言選擇self.source_lang_box = QComboBox()self.source_lang_box.addItem("自動檢測語言", "auto")for name, code in LANGUAGES.items():self.source_lang_box.addItem(name, code)self.layout.addWidget(QLabel("原始語言(Whisper識別語言):"))self.layout.addWidget(self.source_lang_box)# 目標語言選擇self.target_lang_box = QComboBox()for name, code in LANGUAGES.items():self.target_lang_box.addItem(name, code)self.target_lang_box.setCurrentText("中文 (Chinese)")self.layout.addWidget(QLabel("翻譯目標語言:"))self.layout.addWidget(self.target_lang_box)# 是否翻譯的復選框self.translate_checkbox = QCheckBox("是否翻譯識別結果")self.translate_checkbox.setChecked(True)self.layout.addWidget(self.translate_checkbox)self.select_button = QPushButton("選擇文件")self.select_button.clicked.connect(self.select_audio)self.layout.addWidget(self.select_button)self.transcribe_button = QPushButton("開始識別")self.transcribe_button.clicked.connect(self.transcribe_and_translate)self.layout.addWidget(self.transcribe_button)self.setLayout(self.layout)self.audio_path = Noneself.worker = Nonedef select_audio(self):path, _ = QFileDialog.getOpenFileName(self, "選擇音頻/視頻文件", "", "音頻/視頻文件 (*.mp3 *.wav *.m4a *.flac *.mp4)")if path:self.audio_path = pathself.label.setText(f"已選擇:{os.path.basename(path)}")self.result_box.setPlainText("")def transcribe_and_translate(self):if not self.audio_path:QMessageBox.warning(self, "警告", "請先選擇一個文件!")returnsource_lang = self.source_lang_box.currentData()target_lang = self.target_lang_box.currentData()translate_enabled = self.translate_checkbox.isChecked()self.result_box.setPlainText("🎧 正在識別中,請稍候...")self.transcribe_button.setEnabled(False)self.worker = TranscriptionWorker(self.audio_path, source_lang, target_lang, translate_enabled)self.worker.finished.connect(self.on_result)self.worker.error.connect(self.on_error)self.worker.start()def on_result(self, result_text, save_path):self.result_box.setPlainText(result_text)self.transcribe_button.setEnabled(True)QMessageBox.information(self, "完成", f"? 操作完成,已保存到:\n{save_path}")def on_error(self, error_msg):self.result_box.setPlainText("")self.transcribe_button.setEnabled(True)QMessageBox.critical(self, "錯誤", f"? 錯誤:\n{error_msg}")if __name__ == "__main__":app = QApplication(sys.argv)window = TranscriptionApp()window.show()sys.exit(app.exec_())
?



)


)
)
)









![[特殊字符] 分布式事務中,@GlobalTransactional 與 @Transactional 到底怎么配合用?](http://pic.xiahunao.cn/[特殊字符] 分布式事務中,@GlobalTransactional 與 @Transactional 到底怎么配合用?)
)