一、技術背景
隨著大型語言模型(LLM)的蓬勃發展,其在 Kubernetes (K8s) 環境下的訓練和推理對資源調度與管理提出了前所未有的挑戰。這些挑戰主要源于 LLM 對計算資源(尤其是 GPU)的巨大需求、分布式任務固有的復雜依賴性、多租戶環境下的公平性保障以及對資源利用率(特別是昂貴的 GPU 資源)的極致追求。標準的 Kubernetes 調度器 kube-scheduler 主要面向無狀態服務設計,在處理大規模、緊密耦合、資源密集型的批處理工作負載(如 LLM 訓練)時顯得力不從心。
Volcano 作為云原生計算基金會(CNCF)的首個也是目前唯一的容器批量計算項目,旨在彌補 Kubernetes 在批處理和高性能計算(HPC)領域的短板。它不僅僅是一個調度器,更是一個完整的批處理系統,引入了如 VolcanoJob、PodGroup 等關鍵抽象。Volcano 通過提供 Gang Scheduling(成組調度)、多種 Fair-share(公平共享)策略、先進的隊列管理(包括分層隊列和彈性隊列)、拓撲感知(網絡拓撲和 NUMA)以及優先級與搶占等核心功能,直接應對 LLM 場景下的資源管理難題。
1.1 Kubernetes 管理大模型(LLM)資源面臨的核心挑戰
-
極端規模與動態需求 (Extreme Scale & Dynamic Needs): LLM 的訓練和推理需要海量的計算(數千 GPU/TPU)、存儲(TB 級數據)資源,且需求波動巨大。這超出了傳統 Kubernetes 資源管理和彈性伸縮的常規能力范圍。
-
缺乏原子性調度 (Lack of Atomic Scheduling / Gang Scheduling): 分布式訓練任務(如參數服務器和 Worker 組)要求所有組件同時啟動(All-or-Nothing)。Kubernetes 默認以 Pod 為單位調度,缺乏對“任務組”的原生支持,易導致部分 Pod 啟動后等待,造成資源死鎖和 GPU 等昂貴資源的閑置浪費。
-
多租戶公平性 (Multi-Tenant Fairness): 在共享集群中,如何在多個用戶、團隊或不同優先級任務間公平分配稀缺資源(尤其是 GPU)是一個難題。默認調度機制簡單,易導致資源分配不均和“資源饑餓”現象。
-
GPU 利用率低下與碎片化 (GPU Underutilization & Fragmentation): 最大化昂貴的 GPU 利用率至關重要。靜態分配、I/O 等待以及調度不當導致的 GPU 碎片化(集群總 GPU 充足但單個節點不足)普遍存在,難以維持高資源利用率。管理異構 GPU 增加了復雜性。
-
網絡瓶頸與拓撲感知缺失 (Network Bottlenecks & Lack of Topology Awareness): 分布式訓練對節點間通信帶寬和延遲高度敏感。默認調度器通常不感知網絡拓撲,可能將需要頻繁通信的 Pod 分散部署,導致通信開銷劇增,嚴重影響訓練效率。
-
推理延遲 (Inference Latency): 滿足 LLM 實時推理的低延遲要求,在 Kubernetes 的網絡和服務抽象層下存在挑戰,需要高效的路由和可能的邊緣部署策略。
這些挑戰主要源于 Kubernetes 默認調度器的設計側重:它為微服務(數量多、相對獨立、長周期)而非 LLM 類批處理任務(規模大、強依賴、資源密集、周期相對短)優化。其以 Pod 為中心、缺乏作業整體性和拓撲感知的調度邏輯難以滿足 LLM 需求。
解決這些問題不僅關乎技術效率,更具經濟與戰略價值。提升 GPU 利用率、縮短訓練時間、實現公平共享,能顯著降低 AI 成本、加速創新并提升投資回報。
因此,LLM 的興起迫切需要超越 K8s 默認能力的云原生批處理調度方案,這推動了 Volcano、YuniKorn、Koordinator 等旨在彌補 K8s 在高性能計算與大數據處理方面短板的項目的發展。
1.2. Volcano 簡介
Volcano是CNCF 下首個也是唯一的基于Kubernetes的容器批量計算平臺,主要用于高性能計算場景。它提供了Kubernetes目前缺 少的一套機制,這些機制通常是機器學習大數據應用、科學計算、特效渲染等多種高性能工作負載所需的。作為一個通用批處理平臺,Volcano與幾乎所有的主流計算框 架無縫對接,如Spark 、TensorFlow 、PyTorch 、 Flink 、Argo 、MindSpore 、 PaddlePaddle,Ray等。它還提供了包括異構設備調度,網絡拓撲感知調度,多集群調度,在離線混部調度等多種調度能力。Volcano的設計 理念建立在15年來多種系統和平臺大規模運行各種高性能工作負載的使用經驗之上,并結合來自開源社區的最佳思想和實踐。
a) 基礎概念
VolcanoJob (vcjob): 是Volcano自定義的Job資源類型。區別于Kubernetes Job,vcjob提供了更多高級功能,如可指定調度器、支持最小運行pod數、 支持task、支持生命周期管理、支持指定隊列、支持優先級調度等。Volcano Job更加適用于機器學習、大數據、科學計算等高性能計算場景
PodGroup: 一組強關聯pod的集合,主要用于批處理工作負載場景,比如Tensorflow中的一組ps和worker。它是volcano自定義資源類型。
Queue: 是容納一組podgroup的隊列,也是該組podgroup獲取集群資源的劃分依據
NetworkTopology : 允許描述集群的網絡結構,以支持網絡拓撲感知調度,優化分布式任務的通信效率
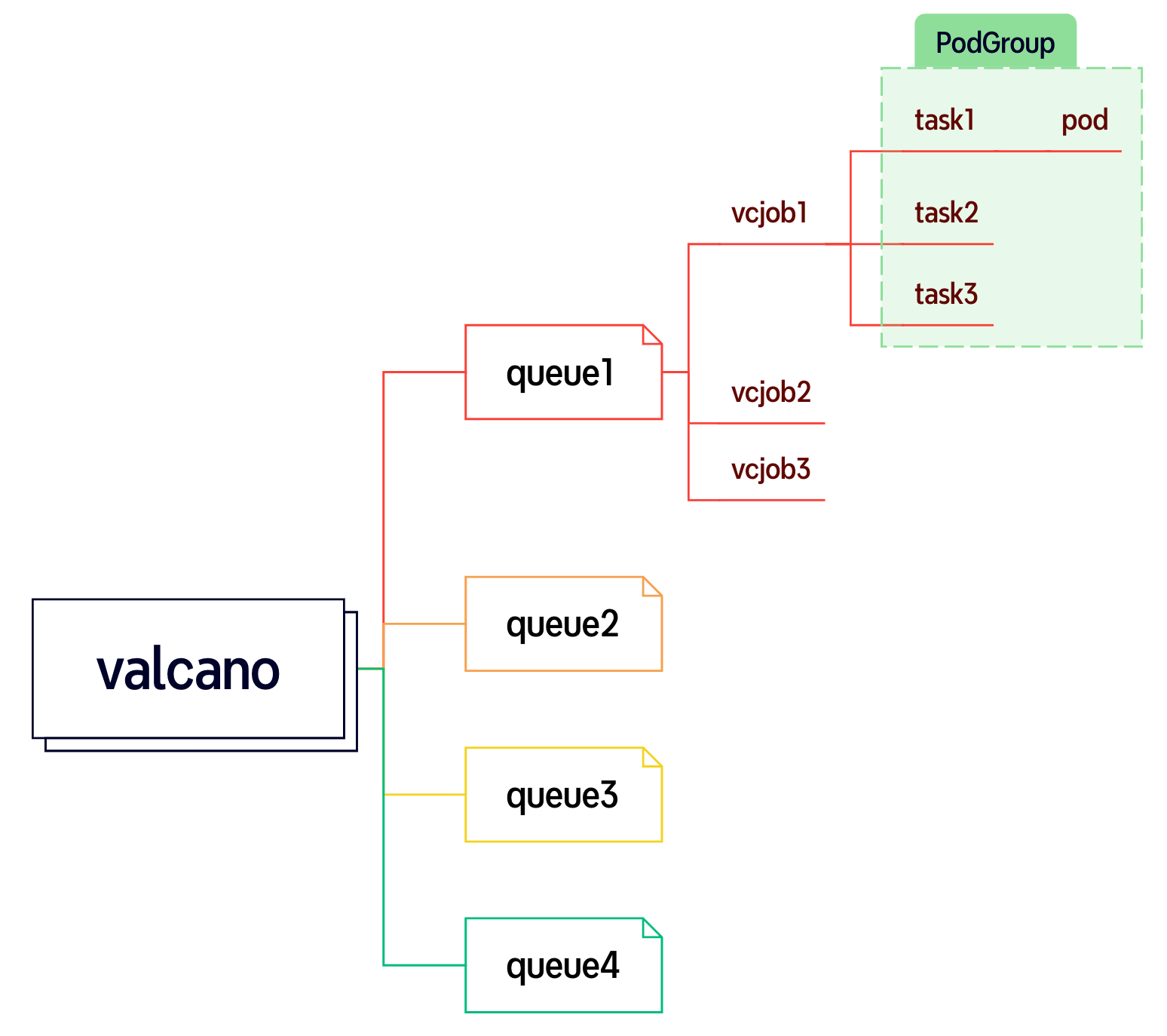
b) 關鍵特性概覽: Volcano 提供了一系列針對批處理和高性能計算優化的核心特性,主要包括:

1.3 生態支持:

二、環境搭建
2.1 基礎環境
k3d 搭建輕量化k8s環境。當前也可以采用 kind,minkube 等等。這個就看個人習慣了。
mac 和 windows 都是可以的。不過前提安裝好容器環境,windows11 提前配置好 wsl ubuntu22.04虛擬化環境。如果要測試大模型并行訓練則需要帶 GPU 的k8s環境
## 安裝k3d
brew install k3d## k3d 創建k8s
k3d cluster create k8s-volcano \--servers 1 \--agents 2 \--k3s-arg "--disable=traefik@server:0" \--port "8080:80@loadbalancer" \--port "8443:443@loadbalancer" \--api-port 6550# 查看當前的k8s集群
k3d cluster list# 刪除指定的k8s集群
k3d cluster delete k8s-***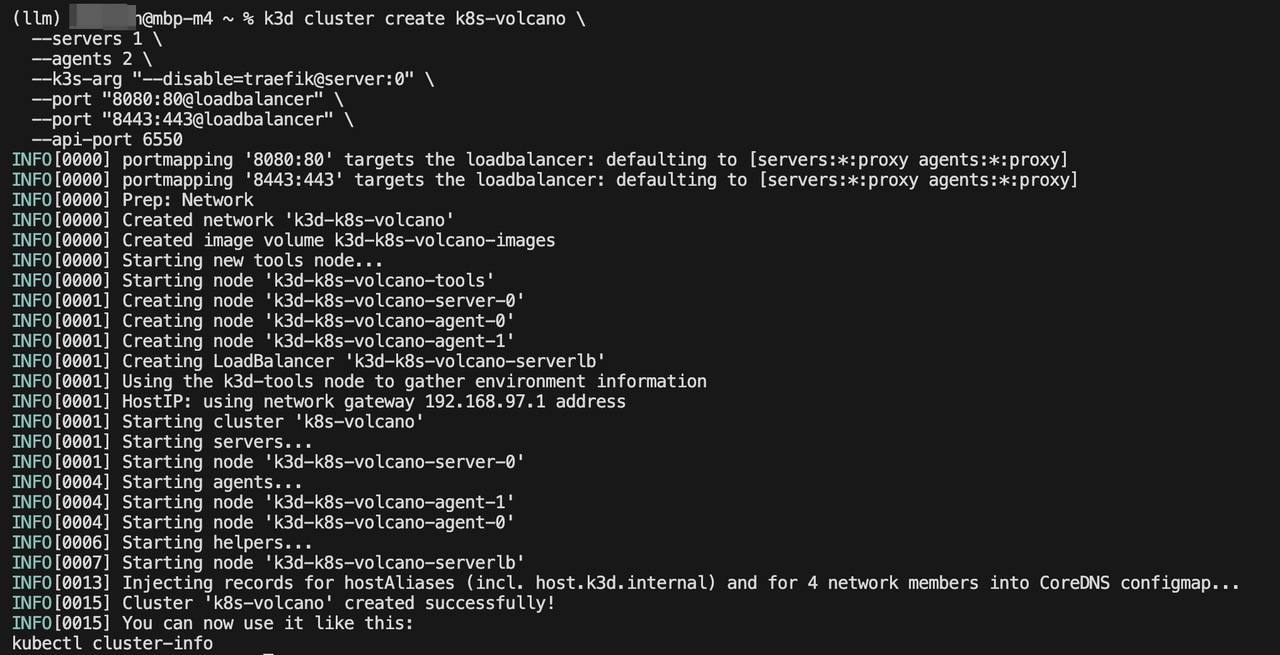

2.2 Volcano部署
## 直接安裝
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
## 或者 通過helm安裝
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts
helm repo update
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace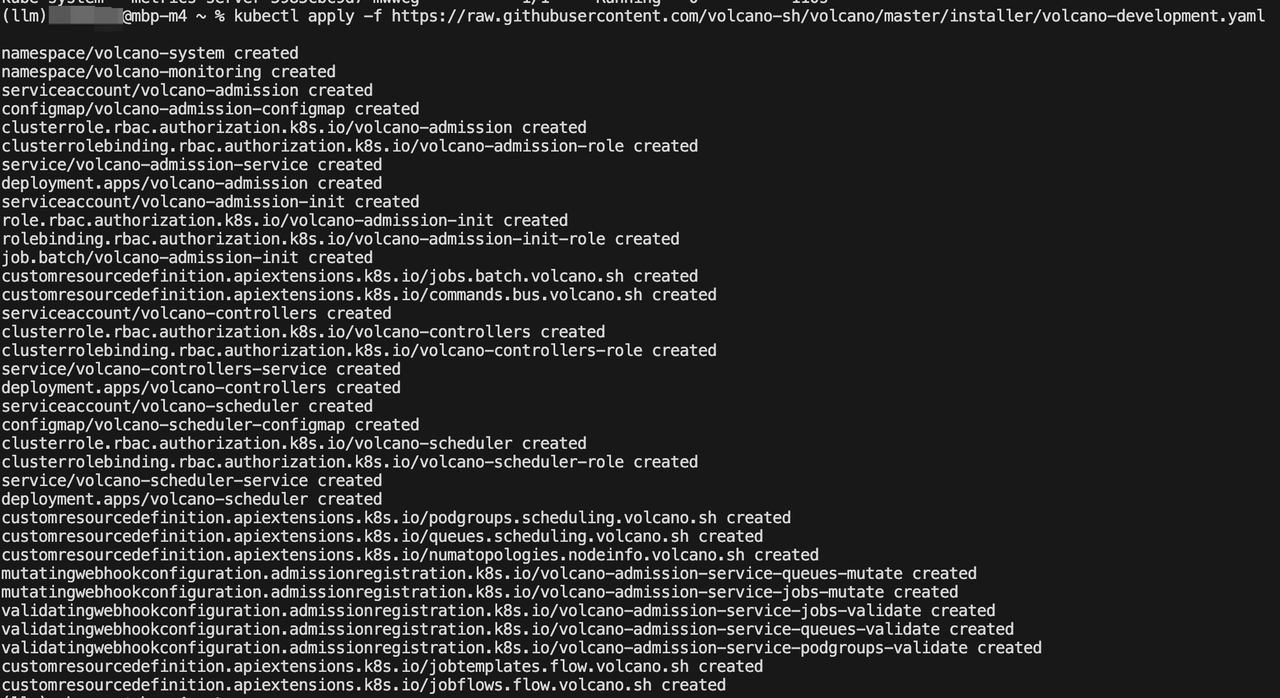
2.3 安裝volcano-dashboard
### 直接安裝
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/dashboard/main/deployment/volcano-dashboard.yaml通過 nodeport 方式暴露服務?

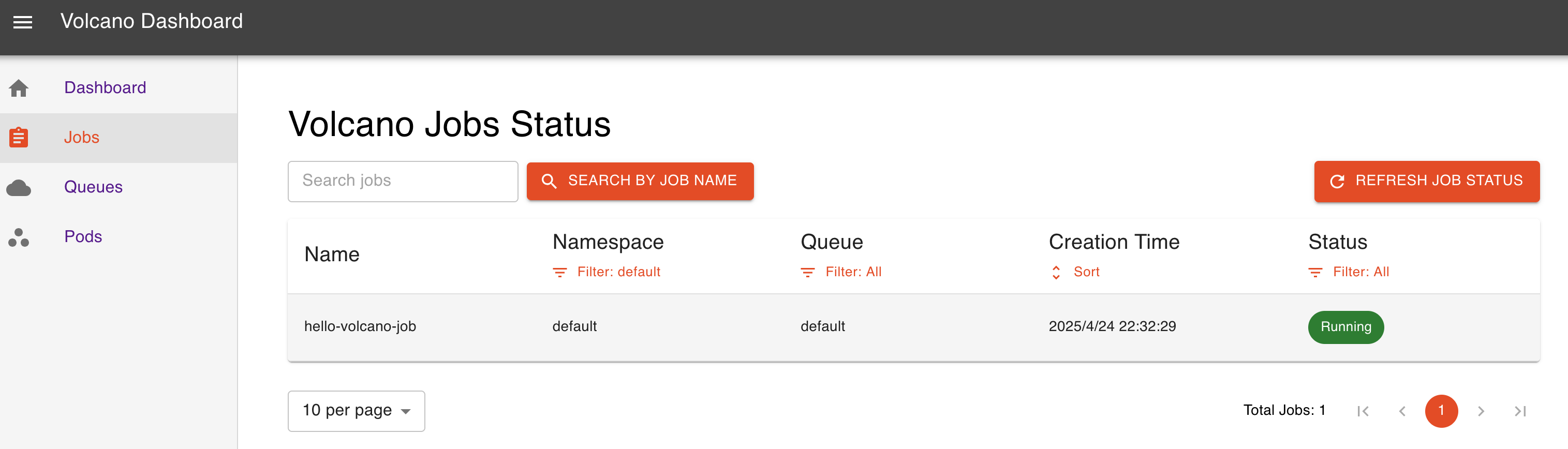
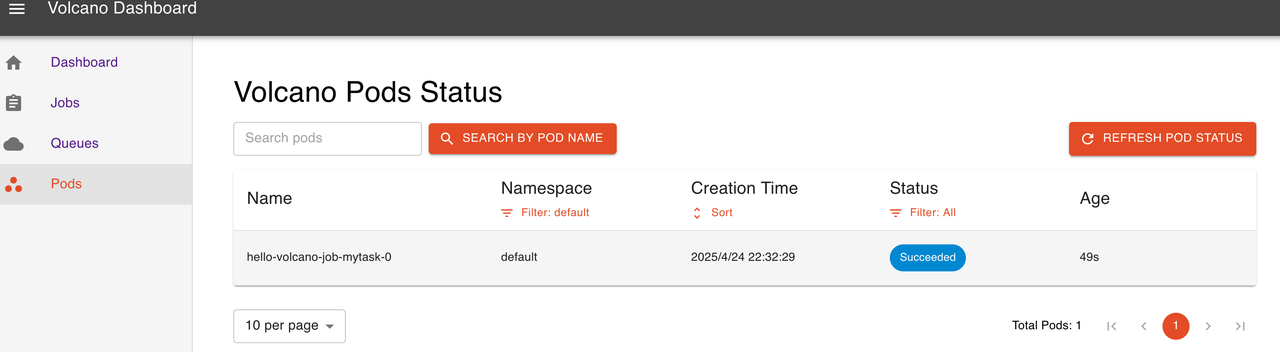
2.4 簡單運行 demojob
cat <<EOF | kubectl apply -f -
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: hello-volcano-job
spec:schedulerName: volcanominAvailable: 1tasks:- name: mytaskreplicas: 1template:spec:containers:- name: hello-containerimage: busyboxcommand: ["sh", "-c", "echo 'Hello Volcano!' && sleep 300"]imagePullPolicy: IfNotPresentrestartPolicy: Never
EOF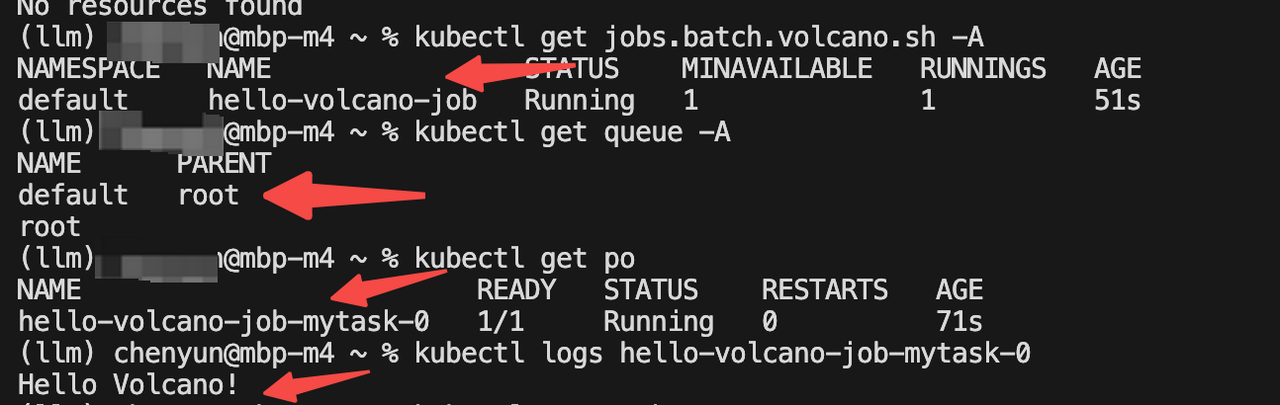
schedulerName: volcano
調度器指定volcano,這樣在調度 job 的 Pod 時會使用volcano而不是默認的 Kubernetes 的調度器。
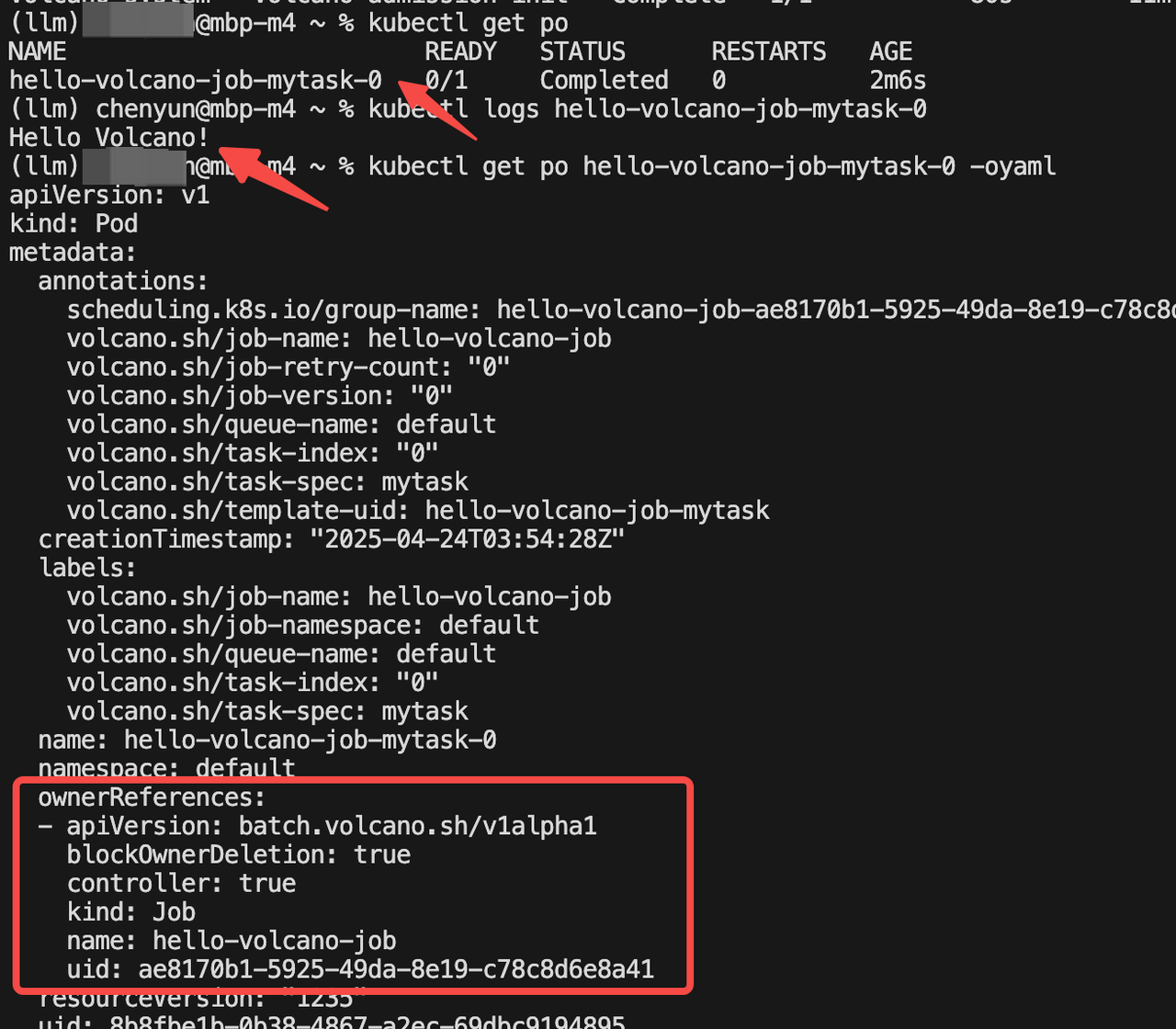
## 刪除 job
kubectl get vcjob -A
kubectl delete vcjob hello-volcano-job 三、Volcano 基礎功能實戰
3.1 queue 資源管理
a) 部署兩個不同權重隊列
cat <<EOF | kubectl apply -f -
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:name: queue-a
spec:weight: 1
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:name: queue-b
spec:weight: 2
EOFkubectl get queues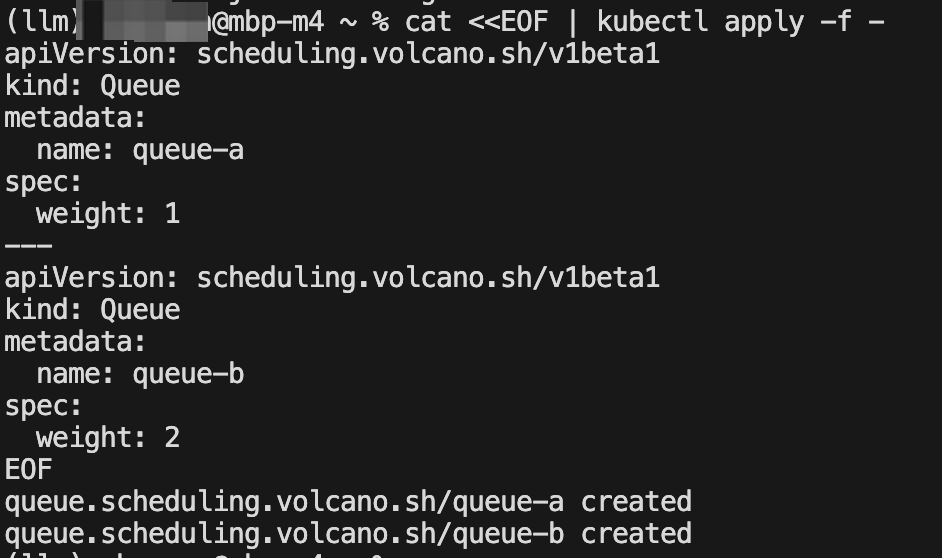
b) 部署job觀察調度
# weight-test-job-template.yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: job-a-1
spec:schedulerName: volcanoqueue: queue-aminAvailable: 1tasks:- name: maintaskreplicas: 1template:spec:containers:- name: cpu-eaterimage: busyboxcommand: ["sh", "-c", "echo 'Starting CPU load...'; i=0; while [ $i -lt 300 ]; do i=$((i+1)); : ; done & PID=$!; sleep 300; kill $PID; echo 'Finished.'"]resources:requests:cpu: "500m" memory: "100Mi" imagePullPolicy: IfNotPresentrestartPolicy: Never## 按照上述模型創建job 觀察資源 調度優先級。
queue-a [job-a-1,job-a-2,job-a-3,job-a-4,job-a-5,job-a-6]
queue-b [job-b-1,job-b-2,job-b-3,job-b-4,job-b-5,job-b-6]queue-b應該會優先獲得資源。不過需要多觀察一些時間。
3.2 Gang Scheduling 調度
嘗試調度配置(min=20)
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: job-a-1
spec:schedulerName: volcanoqueue: queue-aminAvailable: 20tasks:- name: maintaskreplicas: 20template:spec:containers:- name: cpu-eaterimage: busyboxcommand: ["sh", "-c", "echo 'Starting CPU load...'; i=0; while [ $i -lt 300 ]; do i=$((i+1)); : ; done & PID=$!; sleep 300; kill $PID; echo 'Finished.'"]resources:requests:cpu: "4" imagePullPolicy: IfNotPresentrestartPolicy: Never

可以觀察沒有調度
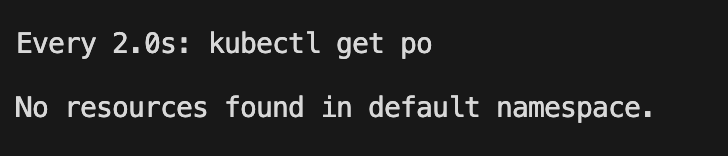
將 minAvailable 條件縮小到 4 個就可以發現已經在調度了
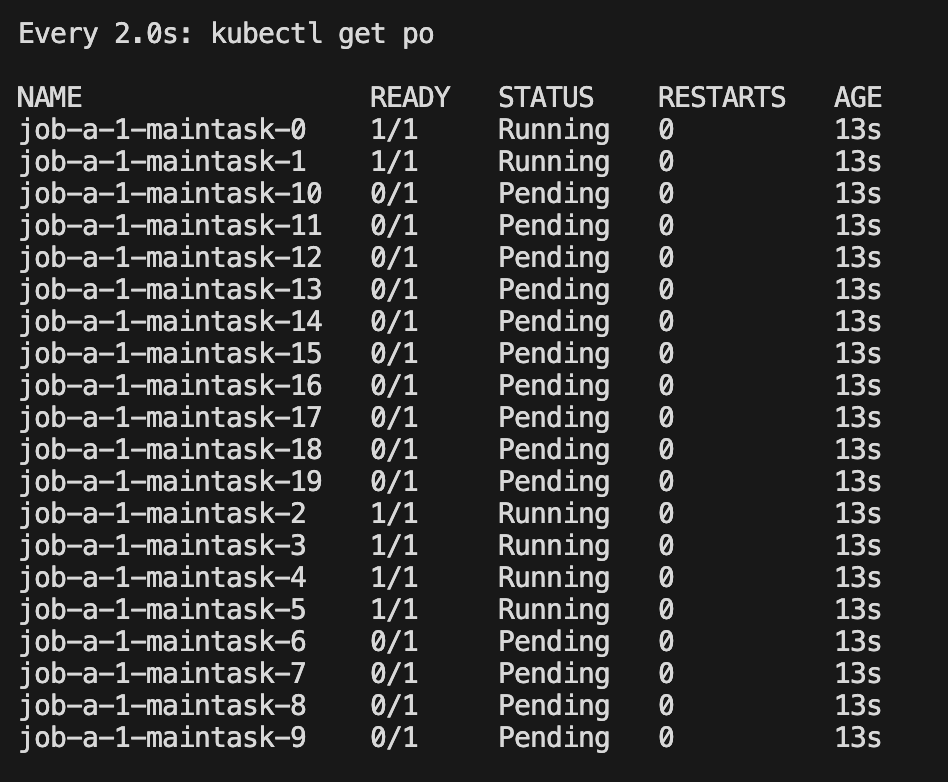

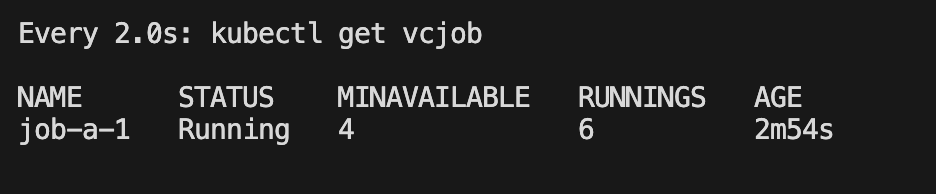
3.3?作業前后依賴
需要等task-a 調度完畢了才會調度task-b
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:name: workflow-job
spec:schedulerName: volcanoqueue: defaultminAvailable: 1tasks:- name: task-a replicas: 1template:spec:containers:- name: task-a-containerimage: busyboxcommand: ["sh", "-c", "echo 'Task A: Starting process...' && sleep 100 && echo 'Task A: Process finished successfully!'"]imagePullPolicy: IfNotPresentrestartPolicy: OnFailure - name: task-breplicas: 1dependsOn: name: ["task-a"]template:spec:containers:- name: task-b-containerimage: busyboxcommand: ["sh", "-c", "echo 'Task B: Starting process (triggered after Task A)...' && sleep 20 && echo 'Task B: Process finished.'"]imagePullPolicy: IfNotPresentrestartPolicy: OnFailure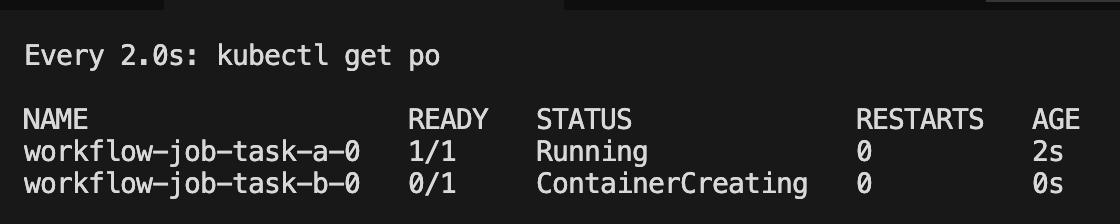

如果想要嘗試高級 flow 調度需要再額外安裝 flowjob 組件才可以實現更多 靈活 精細的 flow 策略
四、Volcano 進階功能實戰
這部分內容放到第二篇
4.1?MPI分布式訓練
4.2?網絡拓撲感知調度
4.3?負載感知調度
4.4?離線混部調度
4.5?多集群調度
4.6?多種策略綜合調度
五、小結
volcano 使用起來復雜度不高,只要實現有想要調度的策略目標找到對應的文檔配置即可。不過當前只是簡單場景的復刻測試。復雜的生產項目不知道會不會別的坑或者問題。下篇 測試網絡拓撲調度,負載感知重調度,多集群調度等。
參考:
Volcano![]() https://volcano.sh/zh/
https://volcano.sh/zh/
https://github.com/volcano-sh/volcano![]() https://github.com/volcano-sh/volcanohttps://github.com/kubeflow/mpi-operator
https://github.com/volcano-sh/volcanohttps://github.com/kubeflow/mpi-operator![]() https://github.com/kubeflow/mpi-operator
https://github.com/kubeflow/mpi-operator









![[特殊字符] 分布式事務中,@GlobalTransactional 與 @Transactional 到底怎么配合用?](http://pic.xiahunao.cn/[特殊字符] 分布式事務中,@GlobalTransactional 與 @Transactional 到底怎么配合用?)
)








