作者:來自 Elastic?Costin Leau
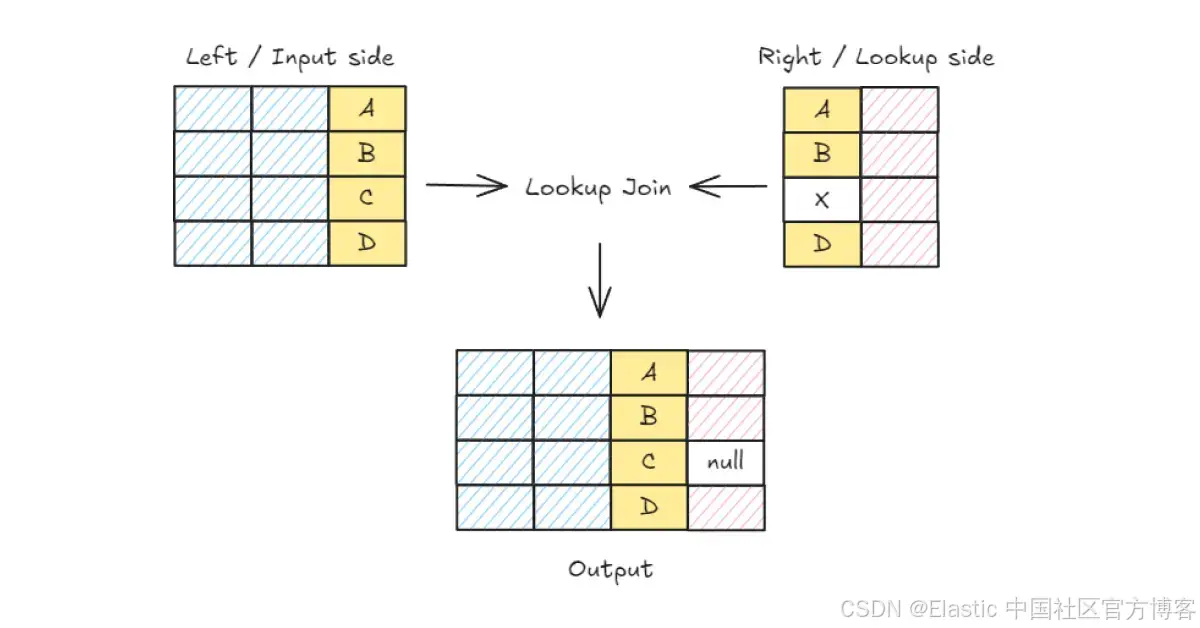
探索 LOOKUP JOIN,這是一條在 Elasticsearch 8.18 的技術預覽中提供的新 ES|QL 命令。
很高興宣布 LOOKUP JOIN —— 這是一條在 Elasticsearch 8.18 的技術預覽中提供的新 ES|QL 命令,旨在執行左?joins 以進行數據增強。通過 ES|QL,用戶可以根據定義如何在 Elasticsearch 中本地配對文檔的標準,將來自一個索引的文檔與來自另一個索引的文檔查詢和組合。這種方法通過在查詢時動態關聯跨多個索引的文檔,從而減少了重復數據,提高了數據管理效率。
例如,以下查詢將來自一個索引的員工數據與另一個索引中對應的部門信息連接,使用共享的字段鍵名稱:
FROM employees
| LOOKUP JOIN departments ON dep_id正如其名稱所示,LOOKUP JOIN 在查詢時執行一個補充的或左(外部)連接,連接任何常規索引(employees 索引)—— 左側和任何查找索引(departments 索引)—— 右側。左側的所有行將與右側的相應行(如果有的話)一起返回。
查找側的索引模式必須設置為 lookup。這意味著底層索引只能有一個分片。當前的解決方案解決了連接一側的基數挑戰,以及像 Elasticsearch 這樣的分布式系統所遇到的問題,這些問題將在下一節中詳細說明。
除了使用 lookup 索引模式外,對源數據或使用的命令沒有限制。此外,無需進行數據準備。
連接可以在過濾之前或之后執行:
// associate employees hired in the last year in departments in US and sort by department name
FROM employees
| WHERE hire_date > now() - 1 year
| LOOKUP JOIN departments ON dep_id
| WHERE dep_location == "US"
| KEEP last_name, dep_name, dep_location
| SORT dep_name與聚合混合使用:
// count employees per country
FROM employees
| STATS c = COUNT(*) BY country_code
| LOOKUP JOIN countries ON country_code
| KEEP c, country_name
| SORT country_name或與另一個 join 結合使用:
// find the error messages in the last hour alongside their source host name and error description
FROM logs
| WHERE message_type :"error"
| LOOKUP JOIN message_types ON err_code
| LOOKUP JOIN host_to_ips ON src_ip
| WHERE log_date > now() - 1 hour
| KEEP log_date, log_type, err_description, host_name執行 Lookup Join
讓我們通過查看一個不包含其他命令(如 filter)的基本查詢來說明運行時會發生什么。這將使我們能夠專注于執行階段,而不是規劃階段。
FROM employees
| LOOKUP JOIN departments ON dep_id
| KEEP last_name, dep_name, dep_location邏輯計劃(logical plan)是一個表示數據流和必要轉換的樹狀結構,是上述查詢翻譯后的結果。這個邏輯計劃以查詢的語義為核心。
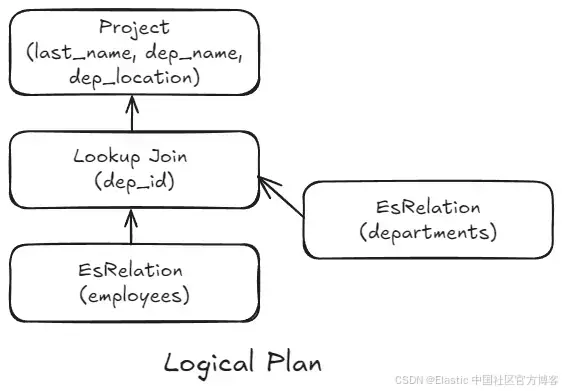
為了確保高效擴展,標準的 Elasticsearch 索引會被分成多個分片,并分布在整個集群中。在 join 場景中,如果左側 (L) 和右側 (R) 都進行分片,將會產生 L*R 個分區。為了盡量減少數據移動的需求,lookup join 要求右側(提供增強數據的一方)只有一個分片,類似于 enrich 索引,其副本數量由索引設置決定(默認是 1)。
這減少了執行 join 所需的節點數量,從而縮小了問題空間。因此,LR 變為 L1,也就是 L。
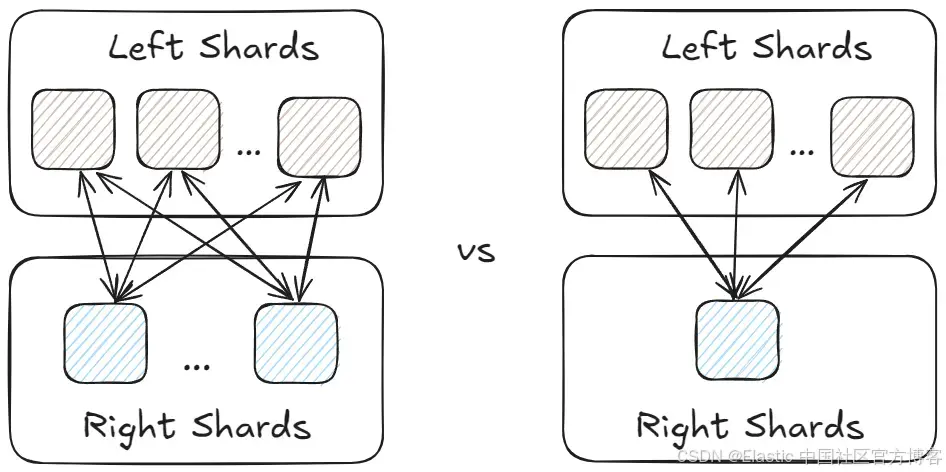
因此,協調節點只需將計劃分發到左側的數據節點,在本地使用 lookup(右側)索引執行 hash join,通過右側構建底層哈希映射,而左側則用于批量 “探測” 匹配的鍵。
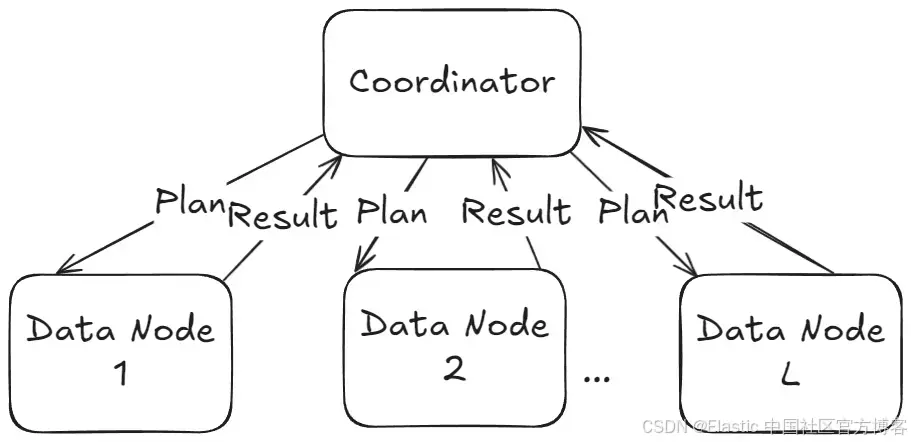
生成的分布式物理計劃(physical?plan),專注于查詢的分布式執行,結構如下:
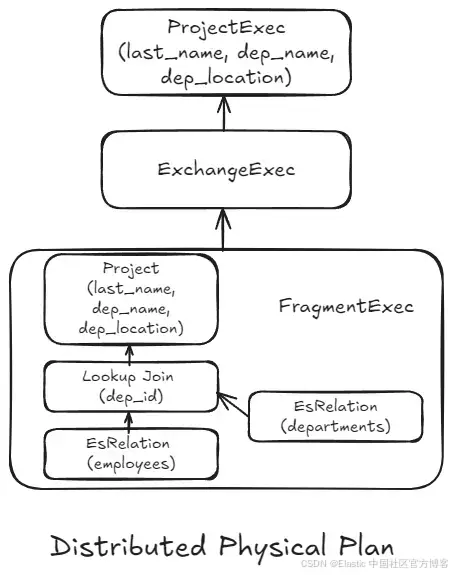
該計劃由兩個主要部分或子計劃組成:一個是在協調節點上執行的物理計劃(通常是接收并負責完成查詢的節點),另一個是計劃片段,在數據節點(存儲數據的節點)上執行。由于協調節點本身不包含數據,它會將一個計劃片段發送到相關的數據節點進行本地執行。執行結果隨后會返回給協調節點,由其計算最終結果。
兩個實體之間的通信通過 Exchange 塊在計劃中表示。對于這個查詢來說,協調節點的工作量不大,因為大部分處理都發生在數據節點上。
該片段封裝了邏輯子計劃,從而可以根據每個分片數據的具體特性進行優化(例如缺失字段、本地的最小值和最大值)。這種本地重新規劃還有助于在節點間或節點與協調節點之間的代碼存在差異(例如在集群升級期間)時進行管理。
本地物理計劃(local physical plan)大致如下:
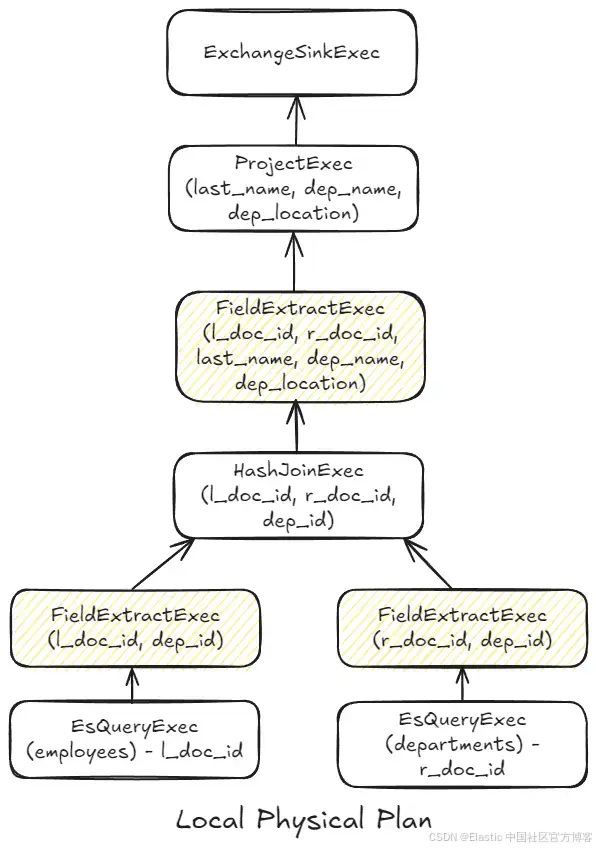
該計劃旨在通過高效的數據提取方式減少 I/O。樹底部的兩個節點作為根節點,為上層節點提供數據。每個節點輸出對底層 Elasticsearch 文檔(doc_id)的引用。這種設計是有意為之,用于盡可能延遲加載列(字段)或文檔,直到通過指定的提取節點(圖中為黃色)進行處理。在這個特定的計劃中,加載操作發生在執行每一側 hash join 之前,以及最終 project 操作之前,此時僅使用 join 后的結果數據將其輸出到節點之外。
未來工作
限定符 -?Qualifiers
目前,lookup join 的語法要求兩個表中的鍵名稱相同(類似于某些 SQL 方言中的 JOIN USING)。這個限制可以通過 RENAME 或 EVAL 來解決:
FROM employees_new
| RENAME dep AS dep_id // align the names of the group key
| LOOKUP JOIN departments ON dep_id這是一個不必要的不便,我們正在通過引入(源)限定符在不久的將來解決這個問題。
之前的查詢可以重寫為(語法正在開發中):
FROM employees_new e
| LOOKUP JOIN departments ON e.dep == departments.dep_id請注意,join key 被替換為一個等式比較,其中每一側都使用字段名稱限定符,限定符可以是隱式的(departments)或顯式的(e)。
更多連接類型和性能
我們目前正在改進 lookup join 算法,以更好地利用數據拓撲,專注于利用 Lucene 中的底層搜索結構和統計信息進行數據跳過的優化。
從長遠來看,我們計劃支持更多的連接類型,如內連接(或交集,結合兩側具有相同字段的文檔)和全外連接(或并集,即使沒有共同鍵,也結合兩側的文檔)。
反饋
Elasticsearch 對原生 JOIN 支持的道路漫長,追溯到 0.90 版本。早期的嘗試包括?nested?和 _parent 字段類型,后者最終在 2.0 版本中被重寫,在 5.0 版本中被棄用,并在 6.0 版本中由 join 字段替代。
更近期的功能,如 Transforms(7.3)和 Enrich 數據攝取管道(7.5)也旨在解決類似連接的用例。在更廣泛的 Elasticsearch 生態系統中,Logstash 和 Apache Spark(通過 ES-Hadoop 連接器)提供了替代解決方案。Elasticsearch SQL,自 6.3.0 版本推出以來,也值得一提,因為其語法相似:雖然它支持廣泛的 SQL 功能,但原生 JOIN 支持一直沒有實現。
所有這些解決方案都有效并繼續得到支持。然而,我們認為,ES|QL 由于其查詢語言和執行引擎,顯著簡化了用戶體驗!
ESQL Lookup join 目前處于技術預覽階段,在 Elasticsearch 8.18 和 Elastic Cloud 中免費提供 —— 試試看,并告訴我們它對你有何幫助!
Elasticsearch 擁有眾多新功能,幫助你為你的用例構建最佳搜索解決方案。深入了解我們的示例筆記本,開始免費云試用,或立即在本地機器上試用 Elastic。
原文:Native joins available in Elasticsearch 8.18 - Elasticsearch Labs
)

)

)




選擇排序 堆排序 歸并排序)
![Vue3 + TypeScript,關于item[key]的報錯處理方法](http://pic.xiahunao.cn/Vue3 + TypeScript,關于item[key]的報錯處理方法)




)


