作者:Xuan Luo, Weizhi Wang, Xifeng Yan
Department of Computer Science, UC Santa Barbara
xuan_luo@ucsb.edu, weizhiwang@ucsb.edu, xyan@cs.ucsb.edu
1. 引言與動機
1.1 背景
- LLM 的成功與挑戰:
- 大型語言模型 (LLMs) 在翻譯、代碼生成、推理等任務上取得巨大成功。
- 核心問題: 當前LLM在生成每個token時,通常需要通過所有Transformer層進行完整的前向傳播。
- 計算資源浪費:
- 這種統一的計算分配 (Uniform Allocation) 與直覺相悖:簡單的任務/token(如重復詞、常見短語)理應需要更少的計算資源,而復雜的任務/token(如推理、生成新信息)需要更多。
- 導致計算效率低下, 過擬合等。
1.2 研究問題與貢獻
- 現有方法的局限:
- 已有的層跳過 (Layer-skipping) 或早退 (Early-Exit) 方法雖然能減少計算量,但大多忽略了一個根本問題:
- “不同 Token 的生成,其計算需求是如何變化的?” (How do computational demands vary across the generation of different tokens?)
- 已有的層跳過 (Layer-skipping) 或早退 (Early-Exit) 方法雖然能減少計算量,但大多忽略了一個根本問題:
- 本文動機:
- 深入探究Token生成過程中的計算需求異質性。
- 提出一種能在預訓練LLM上實現自適應層跳過的方法,且不修改原始模型參數。
- 主要貢獻:
- 提出 FlexiDepth: 一個動態調整Transformer層數的即插即用 (plug-in) 方法。
- 在 Llama-3-8B 上實現顯著層跳過(跳過8/32層)同時保持100%基準性能。
- 揭示了LLM計算需求與Token類型顯著相關(如重復Token vs. 計算密集型Token)。
- 開源了 FlexiDepth 模型 和 FlexiPatterns 數據集 (記錄層分配模式)。
2. 相關工作
- 層跳過/效率提升方法分類:
- 基于統計信息跳過層: 利用層輸入輸出差異等信息判斷并跳過不重要層 (如 ShortGPT [26])。
- 早退 (Early-Exit): 在中間層設置判斷點,若置信度足夠高則直接輸出,跳過后續所有層 (如 [37, 18, 34])。
- 從頭訓練動態深度模型: 在訓練時就加入路由機制,動態決定每層是否執行 (如 MoD [31], SkipLayer [41], Duo-LLM [2])。缺點:需要大量計算資源重新訓練。
- Encoder中的條件計算: 如 PoWER-BERT [11], CoDA [21], COLT5 [1] 等,在Encoder中根據token重要性/復雜度分配不同計算路徑。缺點:非因果性,不直接適用于Decoder-only模型。
- 預訓練模型中的跳過: MindSkip [12] 可以在預訓練模型上跳過,但主要探索跳過Attention,且本文作者認為其性能或方式有別。
- FlexiDepth 的定位:
- 專注于Decoder-only的預訓練LLM。
- 逐層 (Layer-wise) 動態決策,而非早退。
- 通過輕量級插件實現,凍結原始模型參數。
- 不僅提升效率,更旨在理解和利用計算需求的變化規律。
3. FlexiDepth
3.1 整體架構
-
核心思想: 在預訓練LLM的每個(或部分,如下文所述,通常是后半部分)Transformer Decoder層,增加決策和適配機制,動態決定每個Token是完整處理還是跳過該層核心計算。
-
FlexiDepth Block (圖 2):
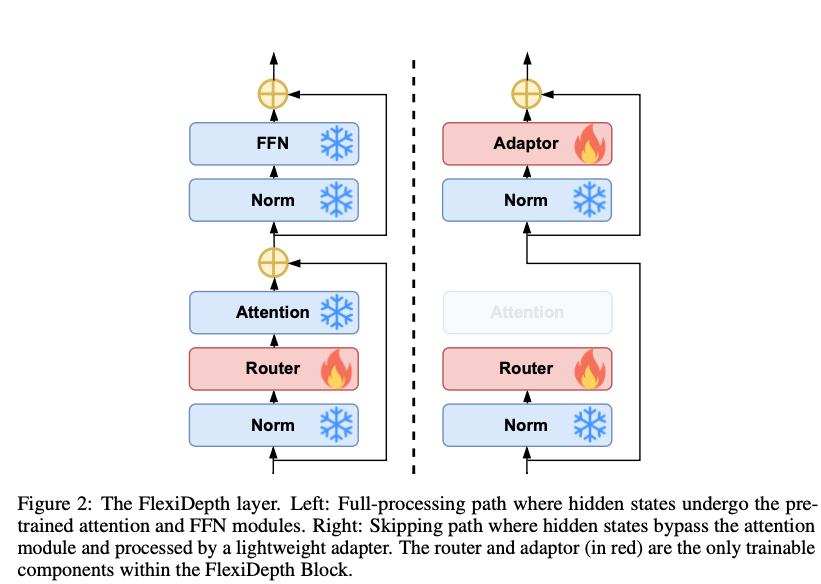
- 輸入: Hidden State (X)。
- 兩個并行路徑:
- 完整處理路徑 (Full-processing Path, 圖2 左):
- Token 通過標準的 Attention 和 FFN 模塊。
- 輸出 = g * Original_Layer(X) (g 為路由得分)。
- 跳過路徑 (Skipping Path, 圖2 右):
- Token 繞過 Attention 和 FFN 模塊。
- 通過一個輕量級的 Adapter 進行處理。
- 輸出 = (1-g) * Adapter(Norm(X))。
- 完整處理路徑 (Full-processing Path, 圖2 左):
- 核心組件 (可訓練):
- Router: 決定Token走哪條路徑 (計算得分 g)。
- Adapter: 處理走跳過路徑的Token,解決表征不匹配問題。
- 輸出: 兩條路徑的輸出加權合并。
-
關鍵特性: 原始LLM的Attention和FFN參數保持凍結。只訓練Router和Adapter。
3.2 Router 設計
-
目標: 為每個輸入Token x_i 計算一個門控分數 g_i ∈ (0, 1),表示其通過完整路徑的傾向。
-
輸入: 經過 RMSNorm 標準化的 Hidden State z = Norm(X)。
-
Router 結構 (Eq 2):
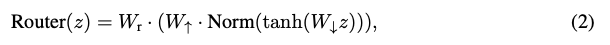
- 為什么不用簡單的線性層? (消融實驗會證明) 簡單的線性層不足以捕捉路由決策所需的復雜模式,尤其是在凍結主干模型時。Bottleneck結構在參數高效的同時提供了足夠的表達能力。
-
輸出: Gating Score G = σ(Router(z)) (Eq 1),其中 σ 是 Sigmoid 函數。
-
路由決策: 使用預定義閾值 τ。若 g_i > τ,走完整路徑;若 g_i <= τ,走跳過路徑。
3.3 Attention Skipping 與 KV Cache
-
問題: 如果完全跳過Attention層,那么該Token對應的Key (K) 和 Value (V) 就不會被計算。對于自回歸模型,后續的Token將無法Attention到這個被跳過的Token,導致上下文信息丟失,嚴重影響生成質量 (如圖3 中間的 ‘No KV Cache’ 所示)。
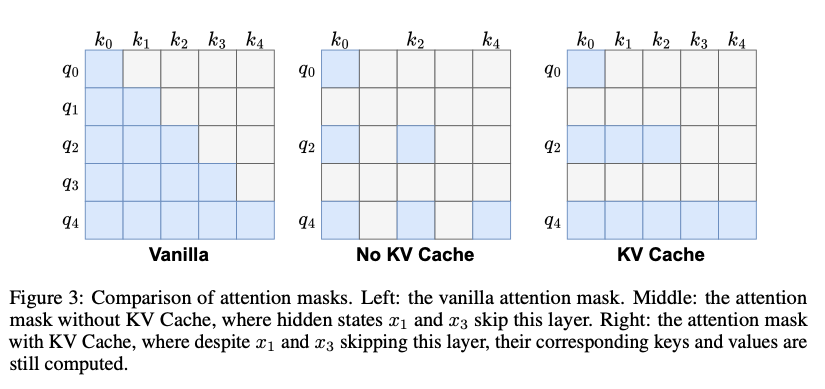
-
FlexiDepth 的解決方案 (圖3 右側 ‘KV Cache’):
- 對于決定跳過Attention模塊的Token (即 g_i <= τ):
- 仍然計算其對應的 Key (K) 和 Value (V) 并存入KV Cache。
- 跳過 Query (Q) 的計算以及后續的點積注意力計算 (Scaled Dot-Product Attention)。
- 對于決定跳過Attention模塊的Token (即 g_i <= τ):
-
好處:
- 保留了完整的上下文信息,確保后續Token可以Attention到所有歷史Token。
- 依然節省了Query計算和主要的Attention矩陣計算開銷。
- 這是維護自回歸生成完整性的關鍵設計。
3.4 FFN Skipping 與 Adapter
- 問題: FFN層包含非線性變換,直接跳過FFN會導致:
- 表征不匹配 (Representation Mismatch): 經過FFN處理的Token和直接跳過的Token處于不同的表示空間。
- 性能顯著下降: (消融實驗會證明) 簡單跳過FFN效果很差。
- FlexiDepth 的解決方案 (圖2 右側):
- 引入一個輕量級 Adapter。
- 結構: 與原始FFN類似 (MLP結構),但中間維度顯著減小 (例如,論文中提到減少16倍)。
- 功能: 對跳過FFN的Token進行變換,使其表示與經過完整FFN處理的Token對齊 (align)。
- 好處:
- 在計算開銷很小的情況下,有效彌合了跳過FFN帶來的表征差異。
- 是保證性能的另一個關鍵組件。
3.5 損失函數
-
目標: 平衡 生成質量 和 計算效率 (層跳過率)。
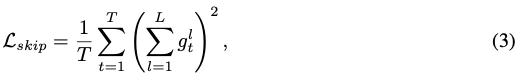

-
總損失 (Total Loss, Eq 4):
- L_lm: 標準的下一個Token預測損失 (Language Modeling Loss)。
- L_skip: 層跳過損失 (Layer-skipping Loss)。
- α: 平衡系數,控制層跳過損失的權重。
-
層跳過損失 (L_skip, Eq 3): L_skip = (1/T) * Σ_t (Σ_l g_tl)2 (原文公式似乎有誤,應該是類似懲罰“使用層數”的平方和,更可能是 (1/T) * Σ_t Σ_l (g_tl)2 或者類似含義,需確認。但核心思想是懲罰使用的層數。)
- 懲罰每個Token使用的門控分數 (g) 的總和的平方 (或者各層g的平方和)。
- 為什么用平方? 對使用更多層的Token施加更大的懲罰,鼓勵模型跳過層;同時避免模型陷入全跳或全不跳的極端。有助于穩定訓練。
-
訓練細節 (Section 3.1):
- 只在模型的后半部分層 (如 Llama-3-8B 的后16層) 應用FlexiDepth。原因:先前研究表明跳過早期層對性能影響更大。
- Router的Bottleneck維度 (dr = d/16),Adapter的中間層維度縮小16倍。
- 使用 Tulu-v2 數據集訓練,AdamW優化器
4. 實驗設置
- 基礎模型: Llama-3-8B-Instruct (32層)。
- 評估基準 (Benchmarks):
- 單Token生成: MMLU, HellaSwag, Winogrande (考察知識、常識、推理)。
- 多Token生成: GSM8K (數學推理), HumanEval (代碼生成), CoQA (對話式問答)。區分這兩類很重要,因為性能差異在多Token任務上更明顯。
- 評估指標 (Metrics): Accuracy (acc), Normalized Accuracy (acc_norm), Exact Match (EM), Pass@1, F1 score (根據不同任務選擇)。
- 對比基線 (Baselines):
- Vanilla (原始 Llama-3-8B-Instruct)。
- LayerSkip [9] (早退最后k層 + 推測解碼)。
- ShortGPT [26] (基于輸入輸出差異剪枝k層)。
- LaCo [39] (層合并,減少k層)。
- MindSkip [12] (探索Attention/FFN/Layer跳過,論文采用其Layer Skipping設置)。
- 公平比較: 所有基線方法都應用于 Llama-3-8B,并配置為跳過相同數量 (k=4 或 k=8) 的層進行比較 (通過調整FlexiDepth的α實現近似跳過層數)。
5. 主要結果與分析
5.1 基準性能比較
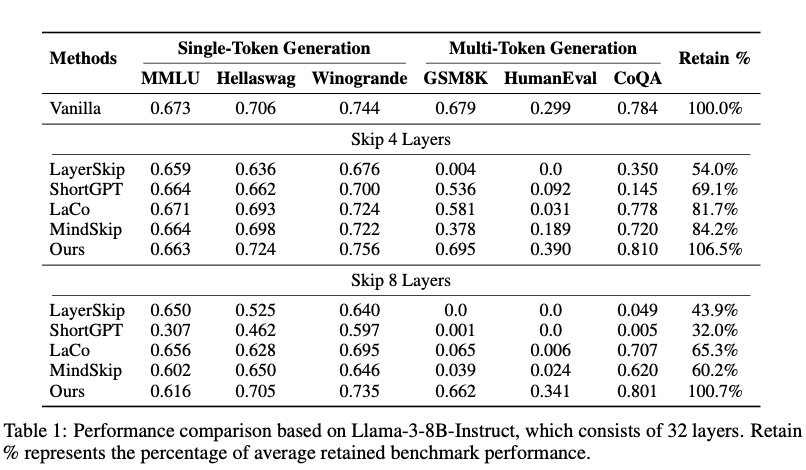
- 核心發現: FlexiDepth 在跳過層數(k=4, k=8)的情況下,顯著優于所有基線方法,尤其是在多Token生成任務 (GSM8K, HumanEval) 上。
- Skip 8 Layers:
- 基線方法在 GSM8K 和 HumanEval 上性能幾乎崩潰 (接近0)。
- FlexiDepth 保持了接近100% (100.7%) 的平均性能。
- 性能甚至略有提升?
- 在某些任務上,FlexiDepth 性能甚至略微超過了原始模型 (Retain % > 100%)。
- 假設: 作者推測這可能源于自適應跳過帶來的隱式正則化 (implicit regularization) 效果,跳過了不信息或噪聲參數。與完全微調的模型對比 (allenai/llama-3-tulu-2-8b),FlexiDepth在GSM8K/HumanEval上表現更好,說明提升不完全來自訓練數據。
- 結論: FlexiDepth 可以在大幅減少計算(跳過8層)的同時,幾乎無損甚至略微提升模型在各種任務上的性能,尤其擅長處理需要復雜推理的長序列生成任務。
5.2 跨模型尺寸表現
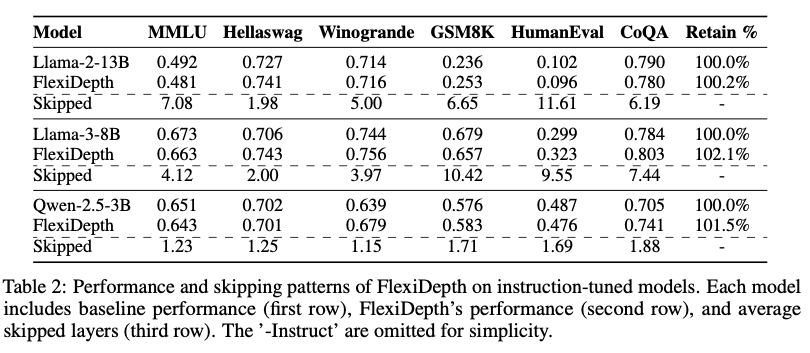
- 實驗: 在不同尺寸的指令微調模型上應用FlexiDepth (Llama-2-13B, Llama-3-8B, Qwen-2.5-3B)。
- 發現:
- 模型越大,跳過的層數越多。
- Llama-2-13B: 平均跳過約 6-7 層。
- Llama-3-8B: 平均跳過約 6 層 (這里跳過層數比Table 1的8層少,可能是α取值不同)。
- Qwen-2.5-3B: 平均只跳過 1-2 層。
- 模型越大,跳過的層數越多。
- 解釋:
- 這表明更大的模型固有地擁有更高的冗余度 (redundancy)。
- 因此,自適應層跳過方法在更大規模的LLM上具有更大的潛力。
5.3 層分配模式

- 主要發現:
-
任務依賴性

- Summarization (總結): 平均使用更多層 (e.g., 28.65層)。需要深入理解和抽象。
- Extractive QA (抽取式問答) / Copying (復制): 平均使用較少層 (e.g., 復制 21.95層)。依賴檢索和直接輸出。
- Continuation (續寫): 使用最多層 (e.g., 30.27層)。需要創造性和上下文連貫性。
-
Token 類型依賴性

- 重復/簡單復制: 如重復數字列表、公式左側的數字,使用較少層。
- 計算/推理/高不確定性: 如數學運算的結果、總結或續寫中的新信息,需要更多層。
-
- 結論: LLM的計算需求確實不是均勻的,而是與任務復雜度和當前Token的功能(是復制、計算還是生成新信息)密切相關。FlexiDepth的自適應機制能夠捕捉并利用這種模式。
6. 消融實驗
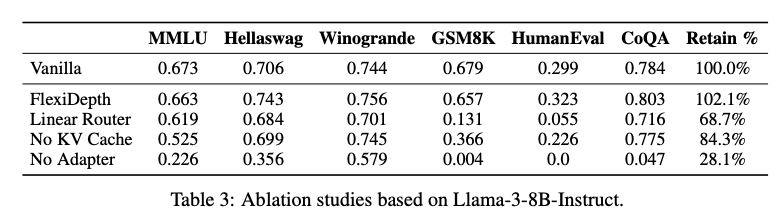
- 目的: 驗證FlexiDepth中各個設計選擇的必要性。基于Llama-3-8B進行。
- 實驗設置:
- Linear Router: 將 MLP Router 替換為簡單的線性層 + Sigmoid。
- No KV Cache: 跳過Attention時,不計算和存儲 K, V。
- No Adapter: 跳過FFN時,移除Adapter。
- 結果:
- Linear Router: 性能顯著下降 (Retain 68.7%),尤其在 GSM8K (0.657 -> 0.131)。說明復雜路由機制是必要的。
- No KV Cache: 性能大幅下降 (Retain 84.3%)。證明為跳過Token保留KV Cache對于維護上下文至關重要。
- No Adapter: 性能災難性下降 (Retain 28.1%)。凸顯Adapter在對齊跳過FFN的Token表征方面的關鍵作用。
- 結論: FlexiDepth 中的 Router、KV Cache 保留策略、以及 FFN Adapter 都是不可或缺的設計,共同保證了模型在層跳過時的性能。
7. 局限性與未來工作
- 主要局限性 (Limitation):
- 理論FLOPs減少 vs. 實際吞吐量提升: 當前實現未能在現有GPU硬件上帶來顯著的推理速度提升。
- 原因:
- 控制流開銷 (Control-flow overhead): 同一個batch內的樣本可能走不同的計算路徑 (一些Token跳過,一些不跳過),需要復雜的管理。
- 不規則內存訪問 (Irregular memory access): 不同的執行路徑導致訪存模式不規則,降低GPU并行效率。
- 未來工作 (Future Work):
- 硬件感知優化: 需要研究專門的優化技術來克服上述瓶頸,例如:
- Token Grouping [30]: 將計算需求相似的Token分組處理。
- Expert Sharding / Load Balancing [30, 15]: 在多GPU或專用硬件上更有效地分配計算負載。
- 深入研究正則化效應: 探索自適應跳過是否真的能作為一種有效的正則化手段。
- 將FlexiDepth應用于更廣泛的模型和任務。
- 硬件感知優化: 需要研究專門的優化技術來克服上述瓶頸,例如:
8. 結論
- 核心貢獻: 提出 FlexiDepth,一種在預訓練LLM上實現動態自適應層跳過的方法,無需修改原始模型參數。
- 關鍵成果:
- 在保持SOTA性能(甚至略有超越)的同時,實現了顯著的層跳過(如Llama-3-8B跳過8/32層)。
- 顯著優于現有兼容預訓練模型的層跳過方法,尤其在復雜生成任務上。
- 重要洞見:
- 首次系統地揭示并量化了LLM中Token生成的計算需求異質性,發現其與任務類型和Token功能強相關。
- 驗證了更大模型具有更高冗余度,為自適應方法提供了更大空間。
- 價值: 提供了一種有效的方法來提升LLM效率(潛力巨大,待硬件優化),并為理解LLM內部計算動態提供了新的視角和工具 (FlexiPatterns數據集)。
9. 代碼
https://huggingface.co/xuan-luo/FlexiDepth-Llama-3-8B-Instruct/blob/main/modeling_ddllama.py








)


)

)

:打破創業幻想,擁抱數據驅動)



