DQN on MountainCar
引言
在本次實驗里,我構建了DQN和Dueling DQN,并在Gymnasium庫的MountainCar環境中對它們展開測試。我通過調整訓練任務的超參數,同時設計不同的獎勵函數及其對應參數,致力于獲取更優的訓練效果。最后,將訓練結果進行可視化處理并加以比較。
DQN實現流程
實現方法
- 實現了DQN類。
- 實現了經驗回放緩沖區(Buffer)類。
- 編寫了訓練流程。
- 將所有超參數集中配置在一處。
- 設計了程序運行參數,具體如下:
--train:訓練模式。--test:測試模式。--resume:斷點續訓模式。--checkpoint:指定用于斷點續訓或測試模式加載的模型。--task_name:確定任務名稱,該名稱與保存日志的路徑相關。--visualize_train:開啟Gym環境的可視化功能。--dueling:使用Dueling DQN網絡。--stop_threshold:早停閾值。
遇到的難題
難題一
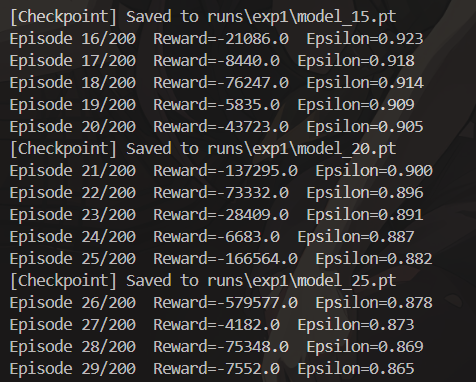
在進行DQN訓練時,進程常常在第20多輪(episode)時卡住。起初,我考慮可能是超參數設計的問題,但后來懷疑并非是訓練超參數設置不當所致。我了解到Gym環境設定了停止條件,要么是完成任務,要么是達到最大步數。鑒于進程一直卡在第29輪不動,按常理應該早就達到了200步的上限,觸發停止條件。然而,我在本地保存的日志文件,其TensorBoard日志文件大小卻持續變化,似乎訓練仍在進行。由此推測,可能是DQN算法中的經驗回放緩沖區部分存在問題,導致緩沖區占用內存過大。
經過更為細致的分析,我發現編寫循環終止條件時,僅設置了到達終點這一條件,而未考慮步數達到上限的情況。這就使得每次獎勵值都為負幾萬。因此,應判定每個回合在步數達到上限時也停止。
修改終止條件后,訓練能夠以正常速度推進。
難題二
由于Gym中封裝的MountainCar環境每走一步獎勵值為 -1,小車很難學會先向左再向右沖刺的策略。
我先后嘗試了多種獎勵設計方法:
- 提取狀態( s t a t e state state)中的位置信息( p o s i t i o n position position),在該環境中, p o s i t i o n position position 取值范圍為 [ ? 1.2 , 0.6 ] [-1.2, 0.6] [?1.2,0.6]。若 p o s i t i o n ≥ 0.4 position \geq 0.4 position≥0.4,則 r e w a r d reward reward 加 1,以此獎勵小車到達更靠右的位置。
- 為獎勵小車盡可能到達更靠右的位置,直接設計一個關于 p o s i t i o n position position 的一次多項式,即 r e w a r d + = α ( p o s i t i o n + 0.5 ) reward += \alpha(position + 0.5) reward+=α(position+0.5),加 0.5 是因為小車初始位置約為 -0.5。
- 獎勵小車向右的速度,公式為 r e w a r d + = α ( p o s i t i o n + 0.5 ) + β v e l o c i t y reward += \alpha(position + 0.5) + \beta velocity reward+=α(position+0.5)+βvelocity。
- 為激勵小車更多地探索先向左再向右的路徑,設計了一個勢能獎勵函數,采用二次多項式形式,即 r e w a r d + = α 2 ( p o s i t i o n + 0.5 ) 2 + α 1 ( p o s i t i o n + 0.5 ) + β v e l o c i t y reward += \alpha_2(position + 0.5)^2 + \alpha_1(position + 0.5) + \beta velocity reward+=α2?(position+0.5)2+α1?(position+0.5)+βvelocity。
經過逐步設計與嘗試,最終發現第四種方案最為完善。經過參數調整后,成功訓練小車到達山頂。
Dueling DQN實現流程
使用DQN的改進版本Dueling DQN,只需在DQN網絡基礎上拆分為兩個子網絡,并進行優勢函數的計算。
遇到的難題
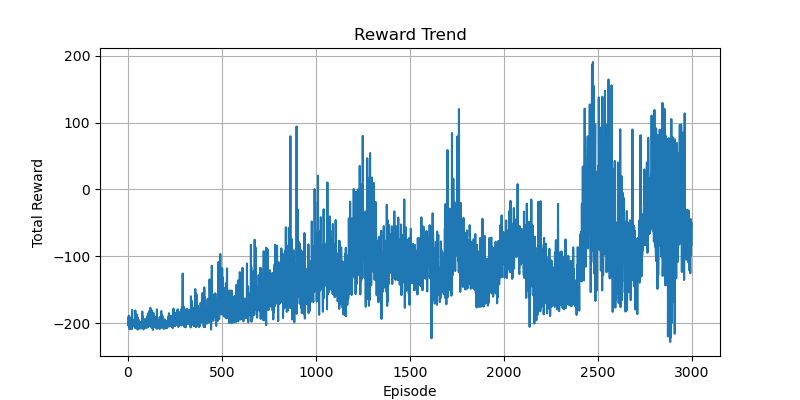
最初,網絡結構設定為 2->128->128->128->3,訓練結果難以收斂。我推測可能是網絡結構過于復雜,導致權重參數極為稀疏。于是,我去掉了兩個隱藏層,將網絡結構改為 2->128->3,訓練效果得到顯著提升。

兩種方法訓練結果對比
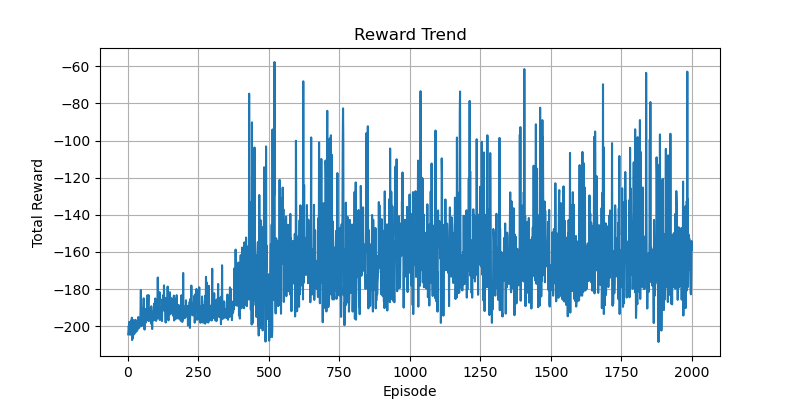
訓練曲線比較
我在代碼中添加了保存TensorBoard日志的功能,這樣可以通過TensorBoard查看不同訓練任務的曲線變化。
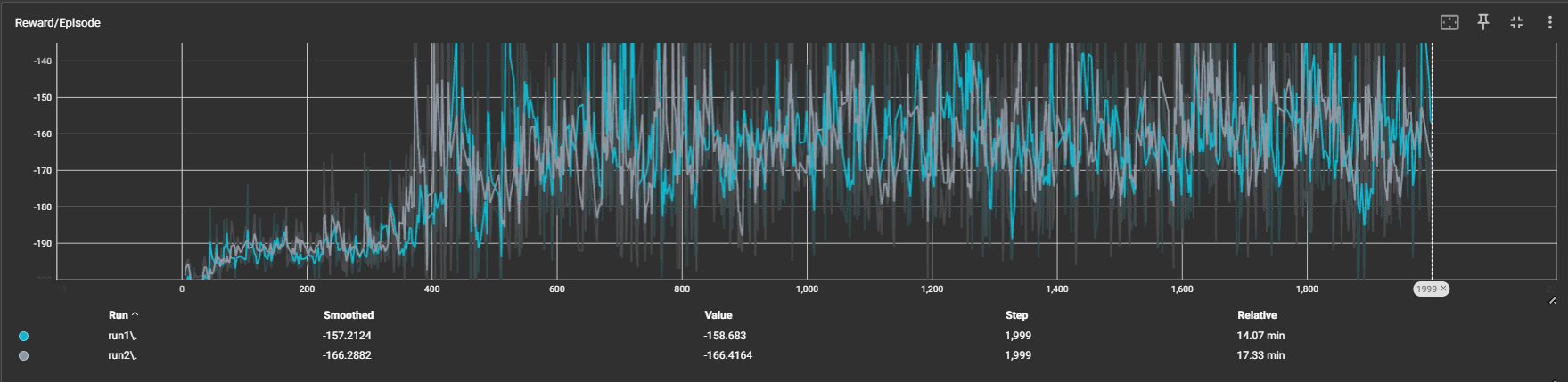
從圖中可以看出,在同一套獎勵函數和參數設置下,兩種方法的訓練速度和收斂速度相近。
最終策略比較
通過測試功能,可以觀察到兩種方法訓練出的策略。兩種方法都能讓小車成功到達山頂,但獎勵表現存在些許差異。可以發現,Dueling DQN的訓練結果得分更高,策略變化的波動更小。
[檢查點] 從 runs/Dueling_exp6/model_final.pt 加載模型:回合數 = 2000,探索率(epsilon) = 0.600
進行 10 個回合的測試...測試 #1:獎勵值 = -113.00測試 #2:獎勵值 = -113.00測試 #3:獎勵值 = -113.00測試 #4:獎勵值 = -113.00測試 #5:獎勵值 = -113.00測試 #6:獎勵值 = -112.00測試 #7:獎勵值 = -113.00測試 #8:獎勵值 = -113.00測試 #9:獎勵值 = -92.00測試 #10:獎勵值 = -115.00
10 個回合的平均獎勵值:-111.00 ± 6.37[檢查點] 從 runs/exp6/model_final.pt 加載模型:回合數 = 2000,探索率(epsilon) = 0.600
進行 10 個回合的測試...測試 #1:獎勵值 = -119.00測試 #2:獎勵值 = -121.00測試 #3:獎勵值 = -186.00測試 #4:獎勵值 = -160.00測試 #5:獎勵值 = -158.00測試 #6:獎勵值 = -115.00測試 #7:獎勵值 = -160.00測試 #8:獎勵值 = -158.00測試 #9:獎勵值 = -89.00測試 #10:獎勵值 = -119.00
10 個回合的平均獎勵值:-138.50 ± 28.30
最后提供代碼:
import os
import time
import argparse
import random
import numpy as np
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from collections import deque
import matplotlib.pyplot as plt# ---------- 參數配置區域 ----------
EPISODES = 2000 # 最大訓練輪數
BATCH_SIZE = 64 # 批次大小
GAMMA = 0.99 # 折扣因子
LR = 1e-3 # 學習率
EPS_START, EPS_END = 1.0, 0.6 # ε-greedy 起始/最小
EPS_DECAY = 0.995 # ε 衰減
TARGET_UPDATE = 10 # (已廢棄,按步數更新)
TARGET_UPDATE_STEPS = 500 # 梯度更新步數間隔更新目標網絡
REPLAY_BUFFER_SIZE = 10000 # Replay Buffer 容量
SAVE_INTERVAL = 50 # Checkpoint 保存間隔 (episodes)
RENDER_DELAY = 0.01 # 渲染延遲(秒)
ALPHA = 6 # reward 參數(未用)
ALPHA2 = 2
ALPHA1 = 1
BETA = 1
# ----------------------------device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ---------- 標準 DQN ----------
class DQN(nn.Module):def __init__(self, obs_dim, action_dim):super().__init__()self.net = nn.Sequential(nn.Linear(obs_dim, 128), nn.ReLU(),# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, action_dim))def forward(self, x):return self.net(x)# ---------- Dueling DQN ----------
class DuelingDQN(nn.Module):def __init__(self, obs_dim, action_dim):super().__init__()# 共享特征層self.feature = nn.Sequential(nn.Linear(obs_dim, 128), nn.ReLU(),# nn.Linear(128, 128), nn.ReLU())# Advantage 分支self.advantage = nn.Sequential(# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, action_dim))# Value 分支self.value = nn.Sequential(# nn.Linear(128, 128), nn.ReLU(),nn.Linear(128, 1))def forward(self, x):x = self.feature(x)adv = self.advantage(x) # [B, A]val = self.value(x) # [B, 1]# Q(s,a) = V(s) + (A(s,a) - mean_a A(s,a))q = val + adv - adv.mean(dim=1, keepdim=True)return qclass ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size):batch = random.sample(self.buffer, batch_size)state, action, reward, next_state, done = map(np.array, zip(*batch))return state, action, reward, next_state, donedef __len__(self):return len(self.buffer)def save_checkpoint(path, policy_net, target_net, optimizer, episode, epsilon, rewards):os.makedirs(os.path.dirname(path), exist_ok=True)torch.save({'episode': episode,'epsilon': epsilon,'policy_state': policy_net.state_dict(),'target_state': target_net.state_dict(),'optim_state': optimizer.state_dict(),'episode_rewards': rewards,}, path)print(f"[Checkpoint] Saved to {path}")def load_checkpoint(path, policy_net, target_net, optimizer):data = torch.load(path, map_location=device)policy_net.load_state_dict(data['policy_state'])target_net.load_state_dict(data['target_state'])optimizer.load_state_dict(data['optim_state'])print(f"[Checkpoint] Loaded from {path}: episode={data['episode']}, epsilon={data['epsilon']:.3f}")return data['episode'], data['epsilon'], data['episode_rewards']def train(args):base_dir = os.path.join('runs', args.task_name)env = gym.make("MountainCar-v0", render_mode="human") if args.visualize_train else gym.make("MountainCar-v0")obs_dim = env.observation_space.shape[0]action_dim = env.action_space.n# 根據命令行參數選擇網絡net_cls = DuelingDQN if args.dueling else DQNpolicy_net = net_cls(obs_dim, action_dim).to(device)target_net = net_cls(obs_dim, action_dim).to(device)target_net.load_state_dict(policy_net.state_dict())target_net.eval()optimizer = optim.Adam(policy_net.parameters(), lr=LR)buffer = ReplayBuffer(REPLAY_BUFFER_SIZE)writer = SummaryWriter(base_dir)episode_rewards = []epsilon = EPS_STARTstart_ep = 0update_steps = 0if args.resume and args.checkpoint and os.path.isfile(args.checkpoint):start_ep, epsilon, episode_rewards = load_checkpoint(args.checkpoint, policy_net, target_net, optimizer)print("Start training...")for episode in range(start_ep, EPISODES):state, _ = env.reset()state = np.array(state, dtype=np.float32)total_r = 0.0done = Falsewhile not done:if args.visualize_train:env.render()time.sleep(RENDER_DELAY)# ε-greedyif random.random() < epsilon:action = env.action_space.sample()else:with torch.no_grad():qv = policy_net(torch.from_numpy(state).unsqueeze(0).to(device))action = qv.argmax(dim=1).item()next_s, r, terminated, truncated, _ = env.step(action)done = terminated or truncatednext_s = np.array(next_s, dtype=np.float32)position, velocity = next_sshaped_r = rshaped_r += (ALPHA2 * (position + 0.5)**2 + ALPHA1 * (position + 0.5)) + BETA * velocity# if (position >= 0.4):# shaped_r += 1buffer.push(state, action, shaped_r, next_s, done)state = next_stotal_r += shaped_r# 學習更新if len(buffer) >= BATCH_SIZE:s, a, r_b, s2, d = buffer.sample(BATCH_SIZE)s_t = torch.from_numpy(s).to(device)a_t = torch.from_numpy(a).long().unsqueeze(1).to(device)r_t = torch.from_numpy(r_b).float().unsqueeze(1).to(device)s2_t = torch.from_numpy(s2).to(device)d_t = torch.from_numpy(d.astype(np.float32)).unsqueeze(1).to(device)q_curr = policy_net(s_t).gather(1, a_t)with torch.no_grad():q_next = target_net(s2_t).max(1)[0].unsqueeze(1)q_target = r_t + GAMMA * q_next * (1 - d_t)loss = nn.functional.mse_loss(q_curr, q_target)optimizer.zero_grad()loss.backward()optimizer.step()writer.add_scalar("Loss/Train", loss.item(), episode)# 按步數更新目標網絡update_steps += 1if update_steps % TARGET_UPDATE_STEPS == 0:target_net.load_state_dict(policy_net.state_dict())# 每集結束后的記錄epsilon = max(EPS_END, epsilon * EPS_DECAY)episode_rewards.append(total_r)writer.add_scalar("Reward/Episode", total_r, episode)writer.add_scalar("Epsilon", epsilon, episode)print(f"Episode {episode+1}/{EPISODES} Reward={total_r:.2f} Epsilon={epsilon:.3f}")# 早停檢查if args.stop_threshold is not None and len(episode_rewards) >= 10:last10_avg = np.mean(episode_rewards[-10:])if last10_avg > args.stop_threshold:print(f"[Early Stop] Last 10 episodes avg reward = {last10_avg:.2f} > threshold {args.stop_threshold}")break# 定期保存if (episode+1) % SAVE_INTERVAL == 0:ckpt = os.path.join(base_dir, f"model_{episode+1}.pt")save_checkpoint(ckpt, policy_net, target_net, optimizer,episode+1, epsilon, episode_rewards)# 保存最后一版模型final_ckpt = os.path.join(base_dir, "model_final.pt")save_checkpoint(final_ckpt, policy_net, target_net, optimizer,episode+1, epsilon, episode_rewards)env.close()writer.close()# 畫訓練曲線plt.figure(figsize=(8,4))plt.plot(range(1, len(episode_rewards)+1), episode_rewards)plt.xlabel("Episode")plt.ylabel("Total Reward")plt.title("Reward Trend")plt.grid(True)plt.savefig(os.path.join(base_dir, "training_rewards.png"))plt.show()return policy_netdef test(policy_net, episodes=10):env = gym.make("MountainCar-v0", render_mode="human")rewards = []print(f"Testing over {episodes} episodes...")for i in range(episodes):state, _ = env.reset()state = np.array(state, dtype=np.float32)done = Falsetotal_r = 0.0while not done:env.render()with torch.no_grad():action = policy_net(torch.from_numpy(state).unsqueeze(0).to(device)).argmax(1).item()state, r, terminated, truncated, _ = env.step(action)done = terminated or truncatedstate = np.array(state, dtype=np.float32)total_r += rtime.sleep(0.02)rewards.append(total_r)print(f" Test #{i+1}: Reward = {total_r:.2f}")env.close()mean_r = np.mean(rewards)std_r = np.std(rewards)print(f"Average Reward over {episodes} episodes: {mean_r:.2f} ± {std_r:.2f}")if __name__ == "__main__":parser = argparse.ArgumentParser(description="DQN / DuelingDQN MountainCar with Early Stop & Step-wise Target Update")parser.add_argument("--train", action="store_true")parser.add_argument("--test", action="store_true")parser.add_argument("--resume", action="store_true")parser.add_argument("--checkpoint", type=str, default=None)parser.add_argument("--task_name", type=str, default="default")parser.add_argument("--visualize_train",action="store_true")parser.add_argument("--dueling", action="store_true", help="Use Dueling DQN instead of standard DQN")parser.add_argument("--stop_threshold", type=float, default=None,help="Early stop if avg reward over last 10 eps > this")args = parser.parse_args()model = Noneif args.train:model = train(args)if args.test:net_cls = DuelingDQN if args.dueling else DQNif not model:dummy = net_cls(2, 3).to(device)opt = optim.Adam(dummy.parameters(), lr=LR)ckpt = args.checkpoint or os.path.join('runs', args.task_name, "model_final.pt")if os.path.isfile(ckpt):_, _, _ = load_checkpoint(ckpt, dummy, dummy, opt)model = dummyif model:test(model)






)


)

)

:打破創業幻想,擁抱數據驅動)




