一、簡介
????????在機器學習領域,數據的特征維度往往較高,這不僅會增加計算的復雜度,還可能導致過擬合等問題。主成分分析(Principal Component Analysis,簡稱 PCA)作為一種經典的降維技術,能夠在保留數據主要信息的前提下,有效降低數據維度,提升模型訓練效率與性能。本文將結合 Python 代碼,以電信客戶流失數據為例,深入講解 PCA 的原理與實戰應用。
二、PCA 原理概述
????????PCA 的核心思想是通過正交變換將原始的高維數據轉換到一個新的坐標系下,使得數據在新坐標系下的方差盡可能大,這些方差較大的方向就被稱為主成分。通俗來講,PCA 就是尋找數據中最具有代表性的幾個方向,將數據投影到這些方向上,從而實現降維。

主要分為以下步驟:
????????數據標準化:對原始數據進行標準化處理,使得每個特征的均值為 0,方差為 1 ,消除不同特征量綱的影響。?
????????計算協方差矩陣:根據標準化后的數據計算協方差矩陣,協方差矩陣描述了各個特征之間的相關性。?
????????計算特征值和特征向量:對協方差矩陣進行特征分解,得到特征值和特征向量。特征值表示了數據在對應特征向量方向上的方差大小,特征值越大,說明該方向上的數據變化越大,包含的信息越多。?
????????選擇主成分:按照特征值從大到小的順序對特征向量進行排序,選取前 k 個特征向量作為主成分。k 的選擇可以根據具體需求,比如保留一定比例的方差(如 90%),或者指定具體的維度。?
????????數據轉換:將原始數據投影到選取的主成分上,得到降維后的數據
 ?
?
三、案例實現?
????????本文將通過Python代碼實現,探討決策樹模型在電信客戶流失預測中的應用,并結合PCA降維技術優化模型性能,同時對比降維前后的模型效果。
from sklearn.decomposition import PCA
import pandas as pd
data = pd.read_excel('C:\CODE\機器學習\決策樹算法\電信客戶流失數據.xlsx')
# 數據劃分
X = data.iloc[:, :-1]
y = data.iloc[:, -1]????????導入庫:首先從sklearn.decomposition模塊導入PCA類,用于執行主成分分析進行數據降維;導入pandas庫并簡寫成pd,用于數據的讀取和處理。?
????????讀取數據:使用pd.read_excel()函數讀取本地路徑'C:\CODE\機器學習\決策樹算法\電信客戶流失數據.xlsx'下的 Excel 文件,并將數據存儲在data變量中。這里需要注意,如果文件路徑中包含空格或特殊字符,可能會導致讀取失敗,可使用原始字符串(在字符串前加r)或者對路徑中的特殊字符進行轉義處理 。?
????????數據劃分:通過iloc方法對數據進行劃分。X = data.iloc[:, :-1]表示選取data中除最后一列以外的所有列,作為特征矩陣,即包含客戶的各種屬性信息;y = data.iloc[:, -1]表示選取data中的最后一列,作為目標變量,即表示客戶是否流失。
pca = PCA(n_components=0.90) # 實例化PCA對象
pca.fit(X) #進行訓練,不需要傳入y
print('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)
print('PCA降維后數據:')
new_x = pca.transform(X)
print(new_x) # 數據X在主成分空間中的表示,具體來說,這個方法將數據X從原始特征空間轉換到主成分空間?
????????實例化 PCA 對象:創建PCA類的實例pca,并設置參數n_components=0.90,這意味著模型會自動選擇能夠保留原始數據 90% 方差的主成分數量,以此來確定降維后的維度。?
????????模型訓練:調用pca.fit(X)方法,使用特征矩陣X對PCA模型進行訓練。在這個過程中,模型會計算數據的協方差矩陣、特征值和特征向量等,以確定主成分的方向和重要性。這里不需要傳入目標變量y,因為PCA是一種無監督學習方法,僅依賴數據本身的特征結構進行降維 。?
????????查看方差信息:通過pca.explained_variance_ratio_屬性獲取每個主成分所解釋的方差比例。sum(pca.explained_variance_ratio_)計算所有選取主成分解釋方差的總和,并打印輸出 “特征所占百分比”,幫助我們了解降維后的數據保留了多少原始數據的信息。同時,單獨打印pca.explained_variance_ratio_,展示每個主成分具體的方差解釋比例。?
????????數據降維:調用pca.transform(X)方法,將原始特征矩陣X轉換到主成分空間,得到降維后的數據new_x。此時,new_x的維度已經根據之前設定的保留 90% 方差的條件進行了縮減,包含了數據在主成分方向上的投影信息。
from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest = train_test_split(new_x, y, test_size=0.2, random_state=0)
xtrain1,xtest1,ytrain1,ytest1 = train_test_split(X, y, test_size=0.2, random_state=0)?????????導入函數:從sklearn.model_selection模塊導入train_test_split函數,該函數用于將數據集劃分為訓練集和測試集。?
????????劃分降維后的數據:使用train_test_split(new_x, y, test_size=0.2, random_state=0)將降維后的數據new_x和對應的目標變量y進行劃分。其中,test_size=0.2表示測試集占總數據集的 20%,random_state=0用于設置隨機種子,確保每次運行代碼時劃分的數據集是相同的,方便結果的復現和對比 。劃分后得到訓練集特征xtrain、測試集特征xtest、訓練集目標變量ytrain和測試集目標變量ytest。?
????????劃分原始數據:同樣使用train_test_split(X, y, test_size=0.2, random_state=0)對原始特征矩陣X和目標變量y進行劃分,得到另一組訓練集和測試集xtrain1、xtest1、ytrain1、ytest1,用于后續與降維后數據訓練的模型進行對比。
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier1 = LogisticRegression()
classifier.fit(xtrain,ytrain)
classifier1.fit(xtrain1,ytrain1)????????導入模型:從sklearn.linear_model模塊導入LogisticRegression類,即邏輯回歸模型,這是一種常用的分類模型,適用于二分類問題,在本案例中用于預測客戶是否流失。?
????????實例化模型:分別創建兩個LogisticRegression類的實例classifier和classifier1,后續將使用它們分別對降維后的數據和原始數據進行訓練。?
????????模型訓練:調用classifier.fit(xtrain,ytrain)使用降維后的訓練集xtrain和對應的訓練集目標變量ytrain對classifier模型進行訓練;調用classifier1.fit(xtrain1,ytrain1)使用原始訓練集xtrain1和ytrain1對classifier1模型進行訓練。在訓練過程中,模型會根據輸入的特征和目標變量,學習特征與目標之間的關系,調整模型的參數。
# 訓練測試集
from sklearn import metrics
train_pred = classifier.predict(xtrain)
print(metrics.classification_report(ytrain, train_pred))test_pred = classifier.predict(xtest)
print(metrics.classification_report(ytest, test_pred))
print(classifier.score(xtest, ytest))train1_pred = classifier1.predict(xtrain1)
print(metrics.classification_report(ytrain1, train1_pred))test1_pred = classifier1.predict(xtest1)
print(metrics.classification_report(ytest1, test1_pred))
print(classifier1.score(xtest1, ytest1))????????導入評估指標模塊:從sklearn庫導入metrics模塊,該模塊提供了多種用于評估分類模型性能的指標和函數。?
????????評估降維后模型在訓練集上的性能:使用classifier.predict(xtrain)讓訓練好的classifier模型對降維后的訓練集xtrain進行預測,得到預測結果train_pred。然后通過metrics.classification_report(ytrain, train_pred)生成分類報告,展示模型在訓練集上的精確率(precision)、召回率(recall)、F1 值(f1-score)等指標,用于評估模型在訓練數據上的表現 。?
????????評估降維后模型在測試集上的性能:使用classifier.predict(xtest)對降維后的測試集xtest進行預測,得到測試集預測結果test_pred。同樣通過metrics.classification_report(ytest, test_pred)生成測試集的分類報告,并使用classifier.score(xtest, ytest)計算模型在測試集上的準確率(accuracy),即預測正確的樣本數占總樣本數的比例,綜合評估模型的泛化能力。?
????????評估原始數據模型在訓練集和測試集上的性能:對基于原始數據訓練的classifier1模型,重復上述步驟。使用classifier1.predict(xtrain1)和classifier1.predict(xtest1)分別對原始訓練集xtrain1和測試集xtest1進行預測,通過metrics.classification_report和classifier1.score評估模型在原始數據訓練集和測試集上的性能,最后對比兩組模型的性能指標,分析 PCA 降維對模型性能的影響。
完整代碼:
from sklearn.decomposition import PCA
import pandas as pddata = pd.read_excel('C:\CODE\機器學習\決策樹算法\電信客戶流失數據.xlsx')# 數據劃分
X = data.iloc[:, :-1]
y = data.iloc[:, -1]pca = PCA(n_components=0.90) # 實列化PCA對象
pca.fit(X) #進行訓練,不需要傳入yprint('特征所占百分比:{}'.format(sum(pca.explained_variance_ratio_)))
print(pca.explained_variance_ratio_)print('PCA降維后數據:')
new_x = pca.transform(X)
print(new_x) # 數據X在主成分空間中的表示,具體來說,這個方法將數據X從原始特征空間轉換到主成分空間from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest = train_test_split(new_x, y, test_size=0.2, random_state=0)
xtrain1,xtest1,ytrain1,ytest1 = train_test_split(X, y, test_size=0.2, random_state=0)from sklearn.linear_model import LogisticRegressionclassifier = LogisticRegression()
classifier1 = LogisticRegression()
classifier.fit(xtrain,ytrain)
classifier1.fit(xtrain1,ytrain1)# 訓練測試集
from sklearn import metrics
train_pred = classifier.predict(xtrain)
print(metrics.classification_report(ytrain, train_pred))test_pred = classifier.predict(xtest)
print(metrics.classification_report(ytest, test_pred))
print(classifier.score(xtest, ytest))train1_pred = classifier1.predict(xtrain1)
print(metrics.classification_report(ytrain1, train1_pred))
test1_pred = classifier1.predict(xtest1)
print(metrics.classification_report(ytest1, test1_pred))
print(classifier1.score(xtest1, ytest1))運行結果:
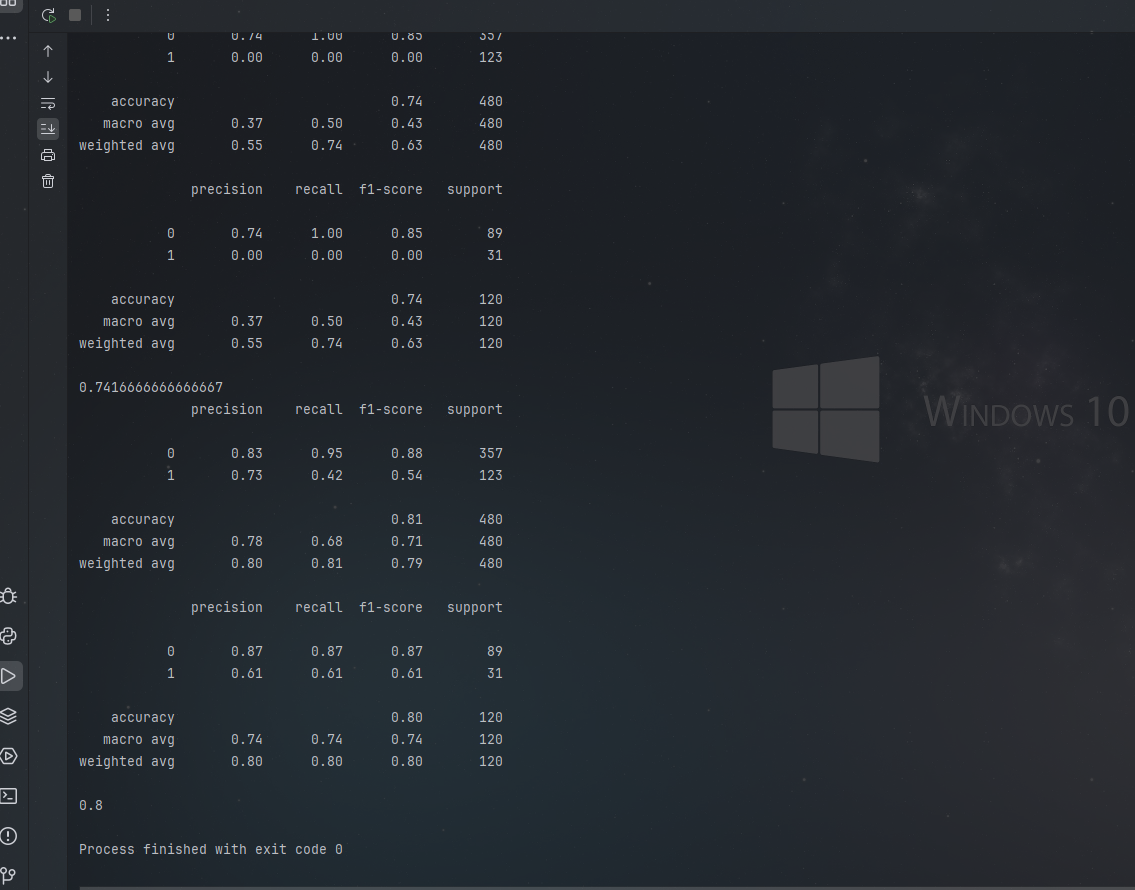
????????通過運行上述代碼,我們可以得到降維前后邏輯回歸模型在訓練集和測試集上的性能指標。對比這些指標,我們可以觀察到 PCA 降維對模型性能的影響。在實際應用中,PCA 降維可能會提高模型的泛化能力,減少過擬合現象,同時降低計算復雜度,提高訓練效率。當然,具體的效果還需要根據數據特點和模型類型進行綜合分析。
四、總結
????????本文詳細介紹了 PCA 降維的原理,并通過 Python 代碼在電信客戶流失數據上進行了實戰演示。PCA 作為一種強大的降維工具,在機器學習和數據分析中有著廣泛的應用。通過合理使用 PCA,可以有效處理高維數據,提升模型的性能和效率。希望本文的內容能夠幫助讀者更好地理解和應用 PCA 降維技術,在實際項目中發揮其優勢。
?
?
?


——初步了解以及QuickStart樣例)




含萬字詳細文檔)











