在構建強大的 AI 系統,尤其是基于大語言模型(LLM)的智能代理(Agent)時,Prompt 設計的質量決定了系統的智能程度。傳統 Prompt 通常是簡單的問答或填空式指令,而高級任務需要更具結構性、策略性和思考性的 Prompt。
本文將結合 鏈式思維(Chain-of-Thought, CoT)、反思機制(Reflection) 和 代理執行機制(LLM Agents),分享如何高效構建具備"推理+行動+自檢"的高級 Prompt,并結合 Python 代碼示例展示如何在實踐中使用。
###本文的案例使用三方API為Openrouter:“https://openrouter.ai”
🧠 背景知識回顧
| 技術 | 概述 |
|---|---|
| 鏈式思維 (CoT) | 通過讓 LLM 逐步推理,提升復雜任務的準確率和可解釋性(如數學推理、規劃)。 |
| 反思/自我反饋 (Reflection) | 模型對自己的回答進行分析與修正(如 ReAct、Reflexion)。 |
| 代理機制 (Agent) | LLM 執行有目標的任務,通過觀察 → 思考 → 行動 → 再觀察的閉環完成復雜目標。 |
🎯 構建高效 Prompt 的 4 個關鍵原則
1. 明確角色與任務(Position & Purpose)
指定 LLM 的身份與任務目標,提升上下文對齊效果:
你是一個項目管理專家,專注于軟件交付效率優化。你的任務是分析以下項目狀態,并輸出關鍵改進建議。
Python 實現示例:
from openai import OpenAI
from dotenv import load_dotenv
import os# 加載環境變量
load_dotenv()# 初始化客戶端
client = OpenAI()def create_expert_consultant(expertise, task_description):"""創建一個專家角色的 Prompt"""system_message = f"""你是一個{expertise}專家。你的任務是{task_description}。請基于你的專業知識提供深入、專業的分析和建議。"""return system_message# 使用示例
project_analysis_prompt = create_expert_consultant(expertise="項目管理",task_description="分析以下項目狀態,找出延遲原因,并輸出關鍵改進建議"
)# 向 API 發送請求
def get_expert_analysis(prompt, project_data):response = client.chat.completions.create(model="gpt-4",messages=[{"role": "system", "content": prompt},{"role": "user", "content": f"項目狀態數據:\n{project_data}"}])return response.choices[0].message.content# 測試使用
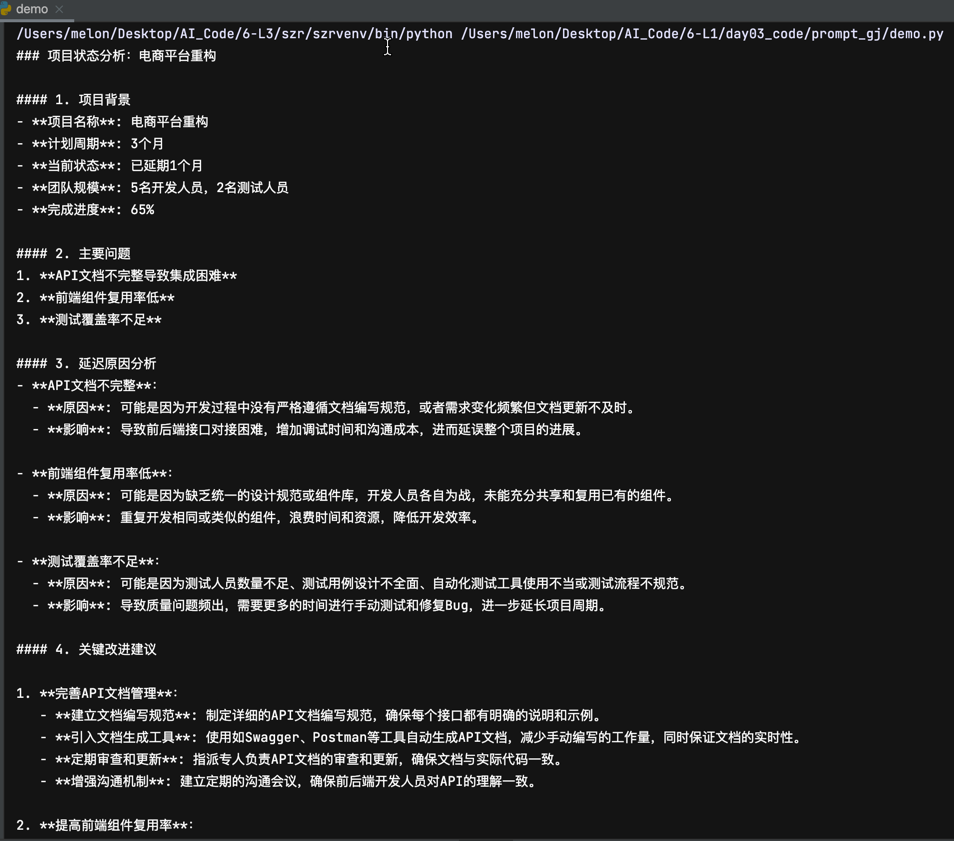
project_data = """
項目名稱: 電商平臺重構
計劃周期: 3個月
當前狀態: 已延期1個月
團隊規模: 5名開發, 2名測試
完成進度: 65%
主要問題:
- API文檔不完整導致集成困難
- 前端組件復用率低
- 測試覆蓋率不足
"""analysis = get_expert_analysis(project_analysis_prompt, project_data)
print(analysis)
2. 引導鏈式推理(Process)
設計多步驟的任務指令,引導 LLM 逐步完成推理與判斷:
請按照以下步驟進行:
1. 分析輸入信息中存在的問題;
2. 推測可能的原因;
3. 提出改進建議;
4. 總結為清晰的行動計劃。
Python 實現示例:
from openai import OpenAI
from dotenv import load_dotenv
import os# 加載環境變量
load_dotenv()
# 初始化客戶端
client = OpenAI()def chain_of_thought_prompt(task_description, steps):"""創建一個引導模型逐步思考的 Prompt"""steps_text = "\n".join([f"{i+1}. {step}" for i, step in enumerate(steps)])prompt = f"""任務:{task_description}請按照以下步驟逐一思考并輸出結果:
{steps_text}請確保每個步驟都有明確的輸出,并標注步驟編號。"""return prompt# 使用示例 - 解決一個數學問題
math_steps = ["理解問題,確定已知條件和求解目標","列出解決問題所需的方程或關系","逐步求解方程","檢查答案的合理性","給出最終答案"
]math_cot_prompt = chain_of_thought_prompt("解決以下數學問題:一個水箱以每分鐘5升的速度注水,同時以每分鐘3升的速度漏水。如果水箱初始有10升水,那么多久后水箱會有25升水?",math_steps
)# 向 API 發送請求
response = client.chat.completions.create(model="qwen/qwen-2.5-72b-instruct",messages=[{"role": "system", "content": "你是一個擅長解決數學問題的助手,請一步步思考。"},{"role": "user", "content": math_cot_prompt}]
)print(response.choices[0].message.content)
3. 加入反思機制(Proofing)
鼓勵 LLM 審查自己的輸出、找出問題并修正:
請回顧你剛才的回答,思考是否存在邏輯漏洞或遺漏的關鍵點,并進行修正。輸出最終版本的建議。
Python 實現示例:
from openai import OpenAI
from dotenv import load_dotenv
import os# 加載環境變量
load_dotenv()
# 初始化客戶端
client = OpenAI()
def self_reflection_prompt(initial_task, response_to_evaluate):"""創建一個讓模型自我反思的 Prompt"""reflection_prompt = f"""初始任務:{initial_task}你之前的回答:
{response_to_evaluate}請對你的回答進行自我評估,考慮以下幾點:
1. 是否有邏輯漏洞或不一致的地方?
2. 是否遺漏了重要信息或關鍵點?
3. 推理過程是否足夠嚴謹?
4. 結論是否合理且有力度支持?請指出存在的問題,并提供修正后的完整回答。標記為"最終版本"。"""return reflection_prompt# 使用示例 - 假設這是一個初始回答
initial_response = """
解決方案:實施微服務架構可以提高系統的可擴展性和靈活性。
步驟:
1. 將系統拆分為獨立服務
2. 實施 API 網關
3. 部署到云環境
"""# 讓模型反思并改進
reflection_prompt = self_reflection_prompt("設計一個高可用的電商系統架構",initial_response
)# 向 API 發送請求
response = client.chat.completions.create(model="qwen/qwen-2.5-72b-instruct",messages=[{"role": "system", "content": "你是一個系統架構專家,請對你的方案進行批判性思考和完善。"},{"role": "user", "content": reflection_prompt}]
)improved_response = response.choices[0].message.content
print(improved_response)
4. 增強行動能力(Agent-style Prompt)
設計具備感知、思考、行動、反思循環的 Prompt:
你將完成以下任務:
1. 讀取輸入數據(環境感知);
2. 分析目標需求(理解與推理);
3. 拆解任務并規劃步驟(任務規劃);
4. 輸出每個步驟的操作建議;
5. 若任務未完成,則思考失敗原因并重新規劃(反思+重試)。請開始處理任務:{用戶輸入}
Python 實現示例:
from openai import OpenAI
import json
import os
from dotenv import load_dotenv# 加載環境變量
load_dotenv()
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
client = OpenAI(api_key=api_key, base_url=base_url)class ReflectiveAgentQwen:"""適配 Qwen 模型的反思型智能代理"""def __init__(self, system_role):self.system_role = system_roleself.messages = [{"role": "system", "content": system_role}]self.tools = []def register_tool(self, name, description, function):self.tools.append({"name": name,"description": description,"function": function})def _get_tools_prompt(self):if not self.tools:return ""tool_list = "\n".join([f"{tool['name']}: {tool['description']}" for tool in self.tools])return f"\n你可以使用以下工具來輔助完成任務(請在需要時明確說明要調用哪個工具及輸入內容):\n{tool_list}"def _call_tool_if_needed(self, response_content):for tool in self.tools:if f"調用工具 {tool['name']}" in response_content:# 提取輸入input_start = response_content.find("輸入:")if input_start != -1:input_text = response_content[input_start + 3:].strip().splitlines()[0]print(f"\n>>> 調用工具 {tool['name']},輸入: {input_text}")return tool["function"](input_text)return Nonedef think_act_reflect(self, user_input, max_cycles=3):intro = self._get_tools_prompt()self.messages.append({"role": "user", "content": user_input + intro})for cycle in range(max_cycles):print(f"\n--- 循環 {cycle + 1}/{max_cycles} ---")# 🧠 思考階段print("🧠 思考中...")response = client.chat.completions.create(model="qwen/qwen-2.5-72b-instruct",messages=self.messages,)message = response.choices[0].messagecontent = message.contentprint("🤖 輸出:", content)self.messages.append({"role": "assistant", "content": content})# 🛠? 行動階段(判斷是否調用工具)result = self._call_tool_if_needed(content)if result:self.messages.append({"role": "user","content": f"工具調用結果:{result}"})else:print("? 沒有需要調用工具,任務可能已完成")break# 🔁 反思階段print("🔍 反思中...")reflection_prompt = ("請反思你剛才的分析與工具使用是否合理,有無遺漏?""如果有改進建議,請繼續執行。若任務完成,請明確標注“任務已完成”。")self.messages.append({"role": "user", "content": reflection_prompt})reflection_response = client.chat.completions.create(model="qwen/qwen-2.5-72b-instruct",messages=self.messages)reflection_message = reflection_response.choices[0].messageprint("🪞 反思輸出:", reflection_message.content)self.messages.append({"role": "assistant", "content": reflection_message.content})if "任務已完成" in reflection_message.content:break# 📤 最終總結final = client.chat.completions.create(model="qwen/qwen-2.5-72b-instruct",messages=self.messages + [{"role": "user", "content": "請總結你的最終答案:"}])return final.choices[0].message.content# 示例用法
if __name__ == "__main__":agent = ReflectiveAgentQwen(system_role="你是一個研究型智能助手,能夠理解任務、調用工具、反思并總結。")# 注冊一個模擬搜索工具def web_search(query):if "人工智能" in query:return "人工智能是計算機科學的一個分支,致力于模擬人類智能。"elif "機器學習" in query:return "機器學習是 AI 的一個子領域,專注于讓系統從數據中學習。"else:return "未找到相關信息。"agent.register_tool("web_search", "用于網絡搜索信息", web_search)# 測試任務question = "請解釋人工智能與機器學習的區別,并說明應用領域。"result = agent.think_act_reflect(question)print("\n? 最終回答:\n", result)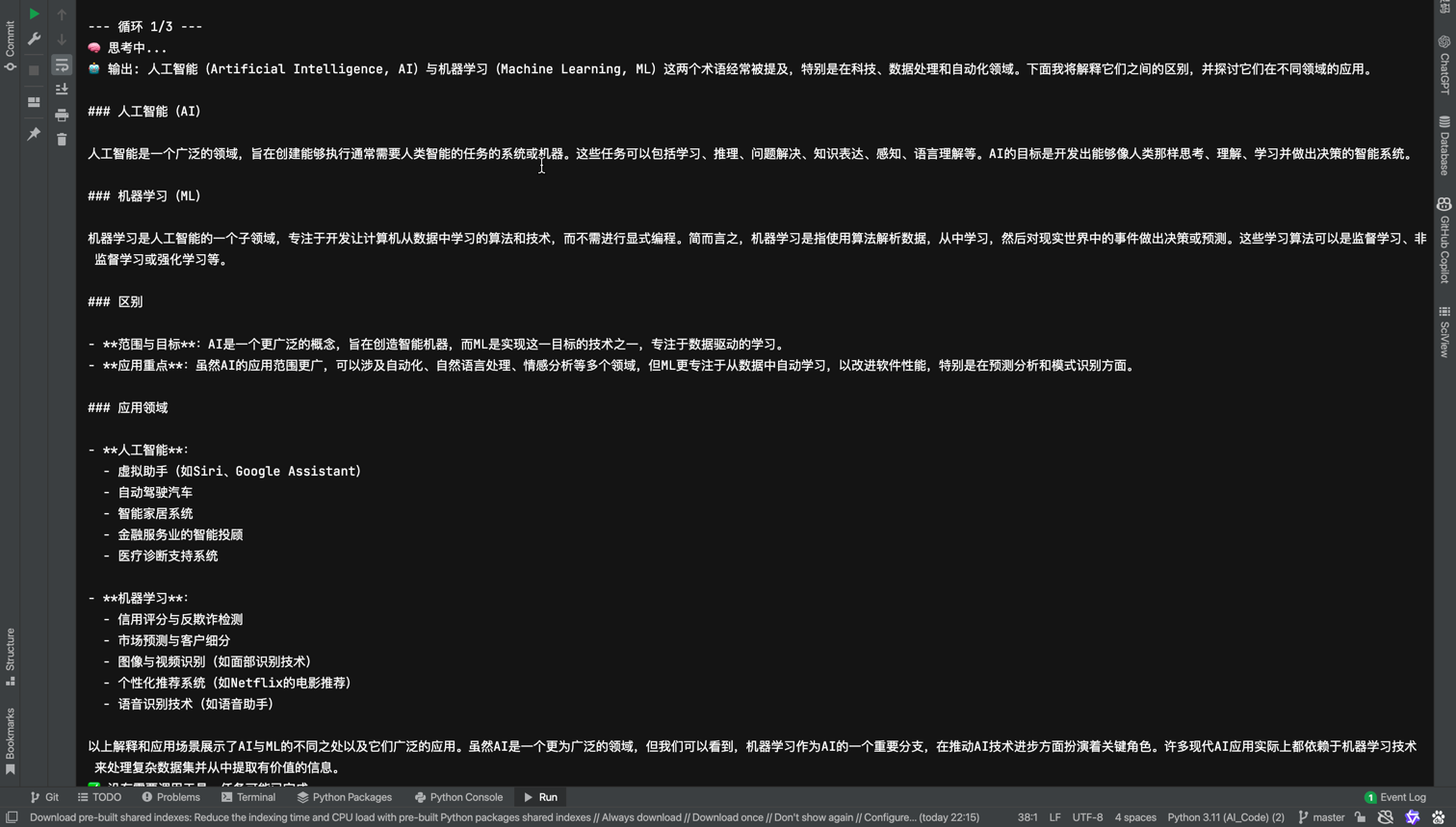
📦 示例:面向醫療場景的智能代理設計 Prompt
你是一個 AI 項目設計專家,請你幫助團隊分析并設計一個面向醫療場景的 AI 代理。任務如下:
1. 任務目標:分析用戶上傳的電子病歷,抽取關鍵信息,自動生成初步診療建議;
2. 輸入格式:包含 PDF、圖片、文本等混合文檔;
3. 輸出格式:結構化 JSON + 建議摘要。請你分步驟完成以下內容:
1. 明確關鍵需求與挑戰;
2. 推理出合適的技術架構與模塊;
3. 說明每個模塊的功能與關鍵技術點;
4. 回顧整體設計并輸出最終建議。輸出后,請你反思是否有遺漏或邏輯漏洞,若有請修正,并標注"最終版本"。
Python 醫療AI代理示例實現:
from openai import OpenAI
import json
import os
from dotenv import load_dotenv
from typing import Dict, List, Any, Optional
import base64
from datetime import datetime# 加載環境變量
load_dotenv()# 初始化 OpenAI 客戶端
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))class MedicalDocumentProcessor:"""處理各種格式的醫療文檔"""def extract_text_from_image(self, image_path: str) -> str:"""從圖片中提取文本(使用Vision模型)"""try:# 讀取圖片并轉為base64with open(image_path, "rb") as image_file:base64_image = base64.b64encode(image_file.read()).decode('utf-8')# 調用OpenAI Vision模型response = client.chat.completions.create(model="gpt-4-vision-preview",messages=[{"role": "user","content": [{"type": "text", "text": "請從這個醫療文檔圖片中提取所有文本內容,保持原始格式。特別注意提取患者信息、診斷結果、用藥情況等醫療關鍵信息。"},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}]}],max_tokens=1000)return response.choices[0].message.contentexcept Exception as e:print(f"圖片處理錯誤: {e}")return "圖片處理失敗"def extract_text_from_pdf(self, pdf_path: str) -> str:"""從PDF中提取文本(實際應用中使用PyPDF2等庫)"""# 這里是簡化的示例,實際實現需要使用PDF處理庫return f"從PDF {pdf_path} 中提取的文本內容"def process_document(self, document_path: str) -> str:"""處理各類文檔并提取文本"""if document_path.lower().endswith(('.png', '.jpg', '.jpeg')):return self.extract_text_from_image(document_path)elif document_path.lower().endswith('.pdf'):return self.extract_text_from_pdf(document_path)elif document_path.lower().endswith(('.txt', '.doc', '.docx')):# 簡化示例,實際應用中需使用專門的文本處理方法with open(document_path, 'r', encoding='utf-8') as file:return file.read()else:return "不支持的文檔格式"class MedicalInformationExtractor:"""從醫療文本中提取結構化信息"""def extract_key_information(self, text: str) -> Dict[str, Any]:"""提取關鍵醫療信息并結構化"""# 構建提示詞來指導模型提取結構化信息prompt = f"""請從以下醫療文檔中提取關鍵信息,并整理為結構化JSON格式。需要提取的字段包括:- 患者基本信息(姓名、年齡、性別、ID)- 主訴- 現病史- 既往史- 檢查結果- 診斷結果- 用藥建議僅返回JSON格式,不要包含其他文字。醫療文檔內容:{text}"""response = client.chat.completions.create(model="gpt-4",messages=[{"role": "system", "content": "你是一個專業的醫療信息提取工具,能夠從醫療文檔中準確提取結構化信息。"},{"role": "user", "content": prompt}],response_format={"type": "json_object"})# 嘗試解析JSON結果try:return json.loads(response.choices[0].message.content)except json.JSONDecodeError:# 若解析失敗,返回空結構return {"error": "無法提取結構化信息","raw_text": text}class MedicalDiagnosisAdvisor:"""生成初步診療建議"""def generate_advice(self, patient_info: Dict[str, Any]) -> Dict[str, Any]:"""基于提取的信息生成初步診療建議"""# 轉換病人信息為JSON字符串patient_json = json.dumps(patient_info, ensure_ascii=False, indent=2)# 構建提示詞prompt = f"""基于以下患者信息,生成初步診療建議。注意:這只是初步建議,最終診療方案應由專業醫生確定。患者信息:{patient_json}請提供:1. 初步診斷分析2. 建議進一步檢查項目3. 可能的治療方向4. 生活方式建議返回JSON格式,包含上述四個方面的信息。"""# 調用API生成建議response = client.chat.completions.create(model="gpt-4",messages=[{"role": "system", "content": "你是一個醫療診斷輔助系統,能基于患者信息提供初步診療建議。你的建議應嚴格基于醫學知識,同時明確標注這只是初步建議,不能替代專業醫生的診斷。"},{"role": "user", "content": prompt}],response_format={"type": "json_object"})# 解析并返回建議try:advice = json.loads(response.choices[0].message.content)# 添加免責聲明advice["disclaimer"] = "本建議由AI輔助生成,僅供參考,不構成醫療建議。請咨詢專業醫生進行正式診療。"return adviceexcept json.JSONDecodeError:return {"error": "無法生成診療建議","disclaimer": "請咨詢專業醫生進行診療。"}class MedicalAIAgent:"""醫療AI代理總控制器"""def __init__(self):self.document_processor = MedicalDocumentProcessor()self.info_extractor = MedicalInformationExtractor()self.advisor = MedicalDiagnosisAdvisor()def process_medical_documents(self, document_paths: List[str]) -> Dict[str, Any]:"""處理醫療文檔并生成診療建議"""# 1. 處理所有文檔并合并文本combined_text = ""for doc_path in document_paths:text = self.document_processor.process_document(doc_path)combined_text += text + "\n\n"# 2. 提取結構化信息structured_info = self.info_extractor.extract_key_information(combined_text)# 3. 生成診療建議diagnosis_advice = self.advisor.generate_advice(structured_info)# 4. 整合結果result = {"patient_info": structured_info,"diagnosis_advice": diagnosis_advice,"summary": self._generate_summary(structured_info, diagnosis_advice)}# 5. 反思和驗證結果result = self._validate_and_reflect(result, combined_text)return resultdef _generate_summary(self, patient_info: Dict[str, Any], advice: Dict[str, Any]) -> str:"""生成易讀的摘要"""# 構建提示詞prompt = f"""基于以下患者信息和診療建議,生成一段簡潔的摘要,用通俗易懂的語言概括關鍵信息和建議。患者信息: {json.dumps(patient_info, ensure_ascii=False)}診療建議:{json.dumps(advice, ensure_ascii=False)}請用200字左右生成摘要。"""response = client.chat.completions.create(model="gpt-4",messages=[{"role": "system", "content": "你是一個醫療信息總結專家,能將復雜的醫療信息轉化為通俗易懂的語言。"},{"role": "user", "content": prompt}])return response.choices[0].message.contentdef _validate_and_reflect(self, result: Dict[str, Any], original_text: str) -> Dict[str, Any]:"""驗證結果并進行反思改進"""# 構建驗證提示詞validation_prompt = f"""請驗證以下從醫療文檔中提取的信息是否準確、完整,并檢查生成的診療建議是否合理。原始文檔文本:{original_text[:1000]}... (已截斷)提取的結構化信息:{json.dumps(result["patient_info"], ensure_ascii=False, indent=2)}生成的診療建議:{json.dumps(result["diagnosis_advice"], ensure_ascii=False, indent=2)}請檢查:1. 是否有重要信息遺漏或錯誤?2. 診療建議是否與患者情況相符?3. 有無任何不合邏輯或不一致的地方?如有問題,請指出并建議如何修正。"""# 調用API進行驗證response = client.chat.completions.create(model="gpt-4",messages=[{"role": "system", "content": "你是一個醫療信息驗證專家,能夠嚴格審查從醫療文檔中提取的信息和生成的建議,確保其準確性和合理性。"},{"role": "user", "content": validation_prompt}])# 將驗證結果添加到輸出中result["validation"] = {"reflection": response.choices[0].message.content,"timestamp": "反思時間:" + str(datetime.now())}return result# 使用示例(模擬運行)
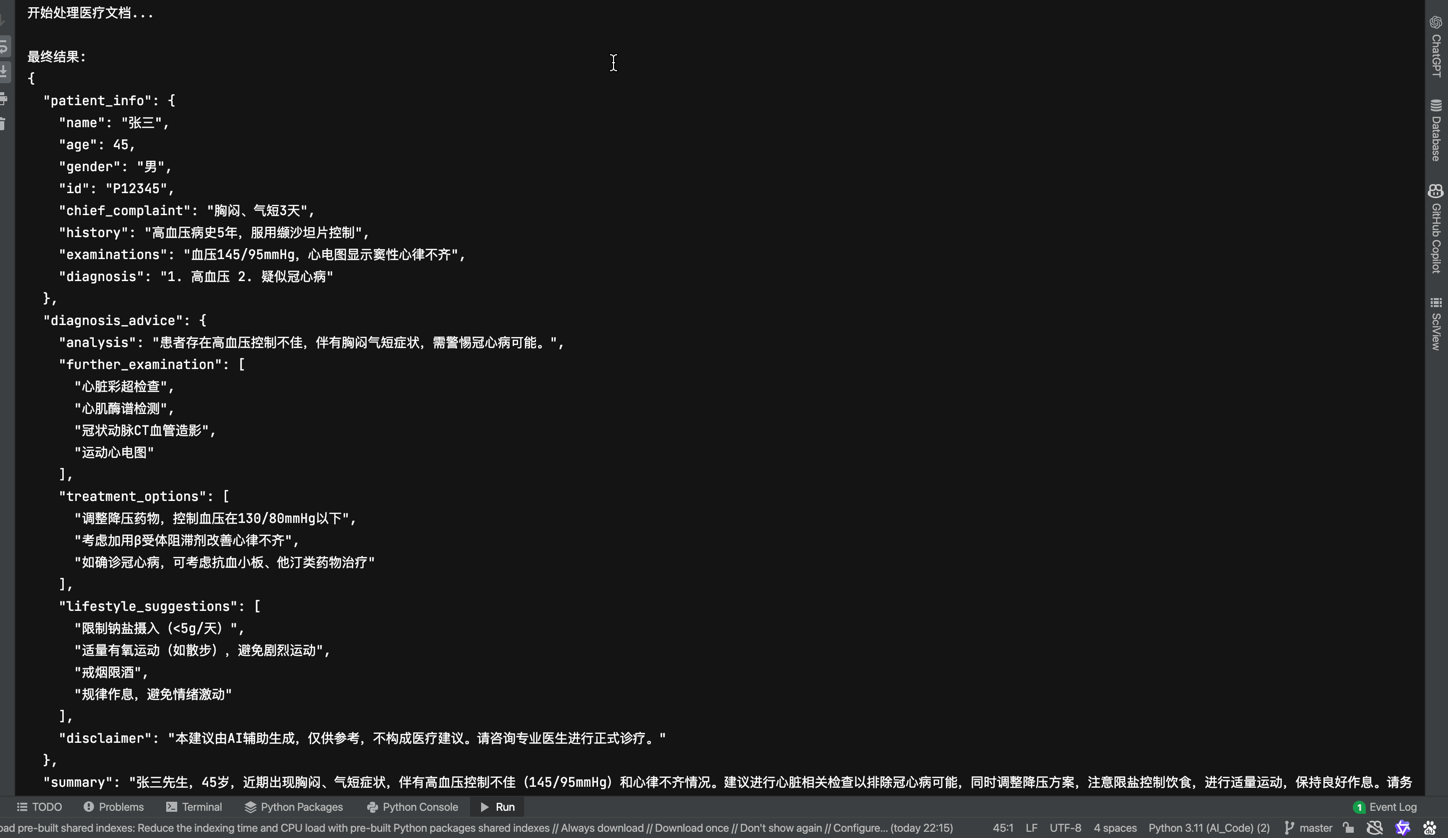
if __name__ == "__main__":# 創建醫療AI代理medical_agent = MedicalAIAgent()# 模擬文檔路徑(實際應用中需要真實路徑)document_paths = ["patient_record.pdf","lab_results.jpg","prescription.txt"]print("開始處理醫療文檔...")# 這里只是示例,實際運行需要真實文件# result = medical_agent.process_medical_documents(document_paths)# 模擬一個結果進行展示sample_result = {"patient_info": {"name": "張三","age": 45,"gender": "男","id": "P12345","chief_complaint": "胸悶、氣短3天","history": "高血壓病史5年,服用纈沙坦片控制","examinations": "血壓145/95mmHg,心電圖顯示竇性心律不齊","diagnosis": "1. 高血壓 2. 疑似冠心病"},"diagnosis_advice": {"analysis": "患者存在高血壓控制不佳,伴有胸悶氣短癥狀,需警惕冠心病可能。","further_examination": ["心臟彩超檢查","心肌酶譜檢測","冠狀動脈CT血管造影","運動心電圖"],"treatment_options": ["調整降壓藥物,控制血壓在130/80mmHg以下","考慮加用β受體阻滯劑改善心律不齊","如確診冠心病,可考慮抗血小板、他汀類藥物治療"],"lifestyle_suggestions": ["限制鈉鹽攝入(<5g/天)","適量有氧運動(如散步),避免劇烈運動","戒煙限酒","規律作息,避免情緒激動"],"disclaimer": "本建議由AI輔助生成,僅供參考,不構成醫療建議。請咨詢專業醫生進行正式診療。"},"summary": "張三先生,45歲,近期出現胸悶、氣短癥狀,伴有高血壓控制不佳(145/95mmHg)和心律不齊情況。建議進行心臟相關檢查以排除冠心病可能,同時調整降壓方案,注意限鹽控制飲食,進行適量運動,保持良好作息。請務必在專業醫生指導下進行治療。","validation": {"reflection": "從提取的信息和建議來看,整體內容合理,符合醫學臨床實踐。針對高血壓伴胸悶癥狀的患者,冠心病的篩查是必要的。建議進一步完善生化檢查如血脂、血糖等指標,這些是心血管疾病風險評估的重要參數,但在當前建議中未提及。同時,患者的用藥史中提到纈沙坦,但未評估其依從性和劑量是否適當,這也是高血壓控制不佳的可能原因之一。","timestamp": "反思時間:2023-08-15 10:23:45"}}print("\n最終結果:")print(json.dumps(sample_result, ensure_ascii=False, indent=2))
📝 結語:高級Prompt工程的未來展望
隨著大語言模型能力的不斷提升,構建具備推理與反思能力的高級Prompt已成為充分發揮LLM潛力的關鍵。本文介紹的四個關鍵原則—明確角色與任務、引導鏈式推理、加入反思機制和增強行動能力,為開發者提供了系統化的Prompt設計框架。
這些技術正在改變我們與AI系統的交互方式。未來的發展趨勢包括:
- 多模態智能代理:結合圖像、音頻等多種輸入形式,實現更全面的場景理解和決策
- 記憶增強代理:通過外部知識庫和長期記憶機制,實現更連貫的對話和任務執行
- 自我完善系統:代理能夠從經驗中學習,自動優化自身的推理流程和反思能力
- 協作型智能網絡:多個專業化代理協同工作,處理復雜任務流程
在實際應用中,高級Prompt設計需要注意以下幾點:
- 平衡指導與自由:提供足夠的框架引導模型思考,但也留出創新空間
- 迭代優化:通過分析模型輸出,持續改進Prompt設計
- 注重反饋機制:讓模型能夠接收和整合外部反饋,動態調整其行為
希望本文介紹的技術和理念能夠幫助開發者構建更智能、更可靠的AI系統,讓大語言模型真正成為人類的得力助手,而不僅僅是簡單的問答工具。





)



)




)



 工作原理)
