參考:Redis系列24:Redis使用規范 - Hello-Brand - 博客園
1 背景
在我們的《Redis高可用之戰:主從架構》篇章中,介紹了Redis的主從架構模式,可以有效的提升Redis服務的可用性,減少甚至避免Redis服務發生完全宕機的可能。
它主要包含如下能力:
1. 故障隔離和恢復:無論主節點或者從節點宕機,其他節點依然可以保證服務的正常運行,并可以手動或自動切換主從。
- 如果Slave庫故障,則讀寫操作全部走到Master庫中
- 如果Master庫故障,則將Slave轉成Master庫,僅丟失Master庫來不及同步到Slave的小部分數據
2. 讀寫隔離:Master 節點提供寫服務,Slave 節點提供讀服務,分攤流量壓力,均衡流量的負載。
3. 提供高可用保障:主從模式是高可用的最基礎版本,也是 sentinel 哨兵模式和 cluster 集群模式實施的前置條件。
主從架構模式雖然很強大,但依然存在一些的問題,我們知道,在衡量系統可用性這方面有個指標叫做MTTR,即平均修復時間。雖然主從模式支持手動切換,但是我們從接收到服務故障預警到手動切換止損到恢復,這可能是一個比較長的過程。這期間的損失將難以計量,對于超高并發大系統是一個絕對災難。所以我們需要系統能自動的感知到Master故障,并選擇一個 Slave 切換為 Master,實現故障自動轉移的能力,提升RTO指數。這時候哨兵模式就可以支棱起來了。
平均修復時間(Mean time to repair,MTTR),是描述產品由故障狀態轉為工作狀態時修理時間的平均值。
復原時間目標(Recovery Time Objective,RTO):是描述產品從故障到恢復原狀的時間,優質架構要求我們盡量在1分鐘左右恢復,一線互聯網大廠的高并發場景0容忍。
2 什么是哨兵模式
在實際生產環境中,服務器難免會遇到一些突發狀況:服務器宕機,停電,硬件損壞等等,一旦發生,后果不堪設想。
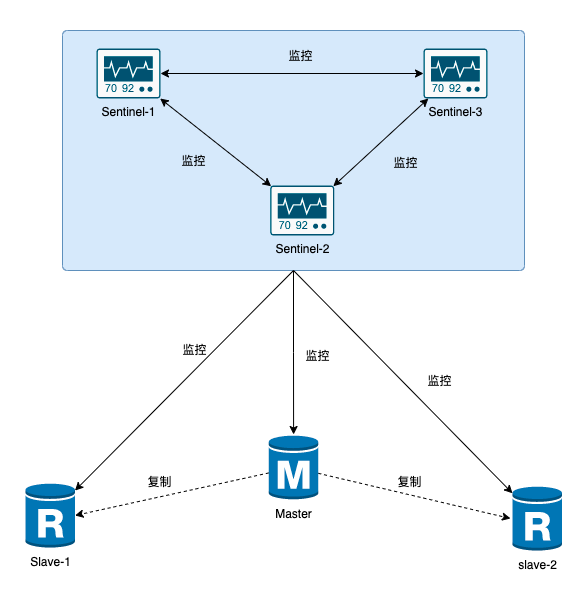
哨兵模式的核心還是主從模式的演變,只不過相對于主從模式,在主節點宕機導致不可寫的情況下,多了探活,以及競選機制:從所有的從節點競選出新的主節點,然后自動切換。競選機制的實現,是依賴于在系統中啟動Sentinel進程,對各個服務器進行監控。如下圖所示:
3 哨兵模式的職責能力
哨兵模式作為Redis高可用的一種運行機制,專注于對 Redis 實例(master、slaves)運行狀態進行監控,并能夠在主節點發生故障時通過一系列的操作,實現新的master競選、主從切換、故障轉移,確保整個 Redis 服務的可用性。
整體來說它有如下能力:
- 集群監控
- 故障監測與通知
- 自動故障轉移(主從切換)
3.1 集群監控
哨兵模式的主要任務之一是監控Redis主從復制集群中的各個節點。它會定期檢查主節點和從節點的健康狀態,確保它們都在正常運行。
3.1.1 前置知識
1. 主觀下線(sdown):
- sdown(主觀不可用)是單個哨兵自己主觀上檢測到的關于Master的狀態,從哨兵的角度來看,如果發送PING心跳后,在一定的時間內沒有得到應有的回復,就達到了sdown的條件。
- 哨兵配置文件
sentinel.conf中down-after-milliseconds屬性設置了判斷主觀下線的回復時間。
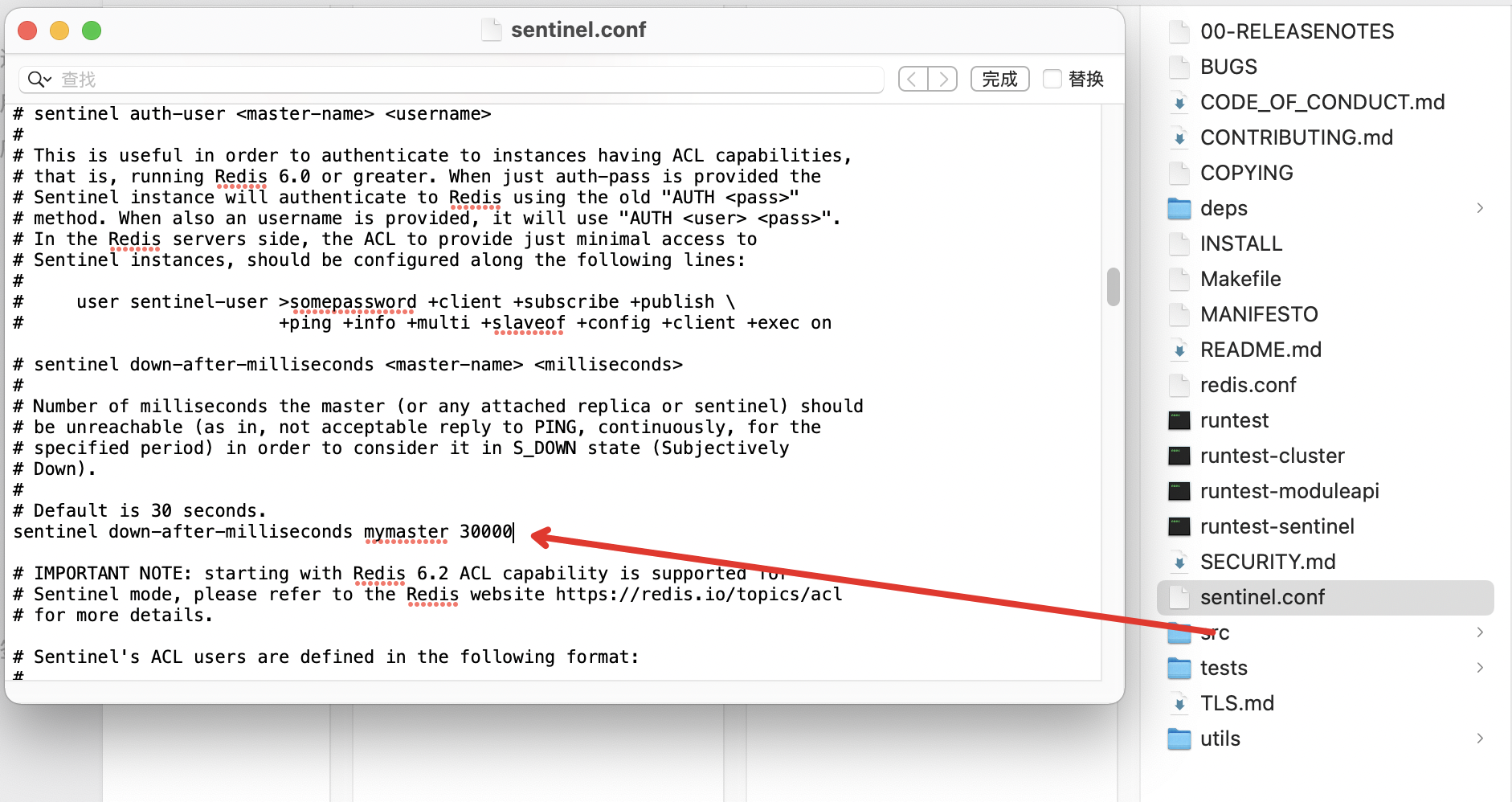
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-bash"><span style="color:#008000"># sentinel down-after-milliseconds mymaster 30000 默認30s</span>
sentinel down-after-milliseconds <masterName> <<span style="color:#0000ff">timeout</span>>
</code></span></span>這種機制是為了保證多個哨兵實例可以一起綜合判斷,避免單個哨兵(因為自身請求超時、網絡抖動等問題)的誤判,導致主庫被下線。
2. 客觀下線 (odown):
上面說了,Master是否下線不是單個Sentinel能夠決定的,一般來說需要一定數量的哨兵,多個哨兵達成一致意見才能認為一個Master客觀上已經宕機了。
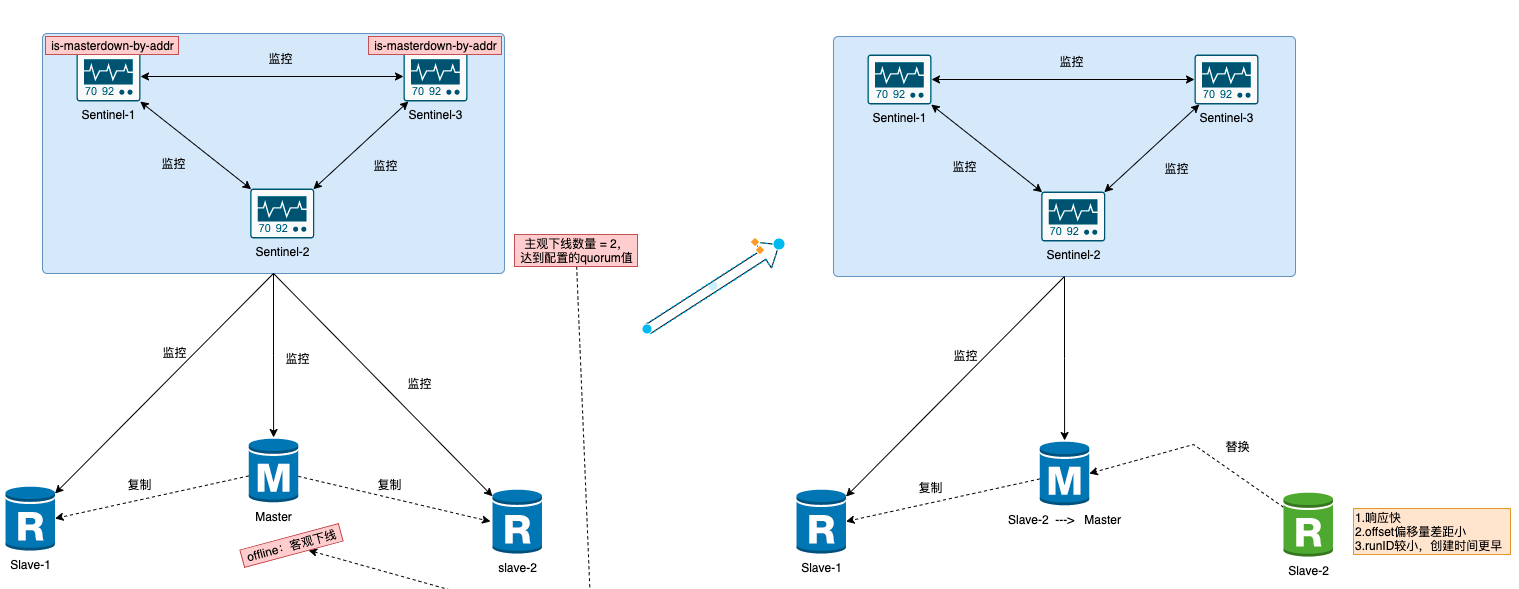
上面的圖可以看到,我們一般會有個Sentinel集群 ,這時候這個集群就發揮作用了,通過投票機制,超過指定數量(一般為半數)的Sentinel 都判斷了『主觀下線』 ,這時候我們就把 Master 標記為『客觀下線』,代表它確實不可用了。
投票判定的數量是通過sentinel.conf配置的:
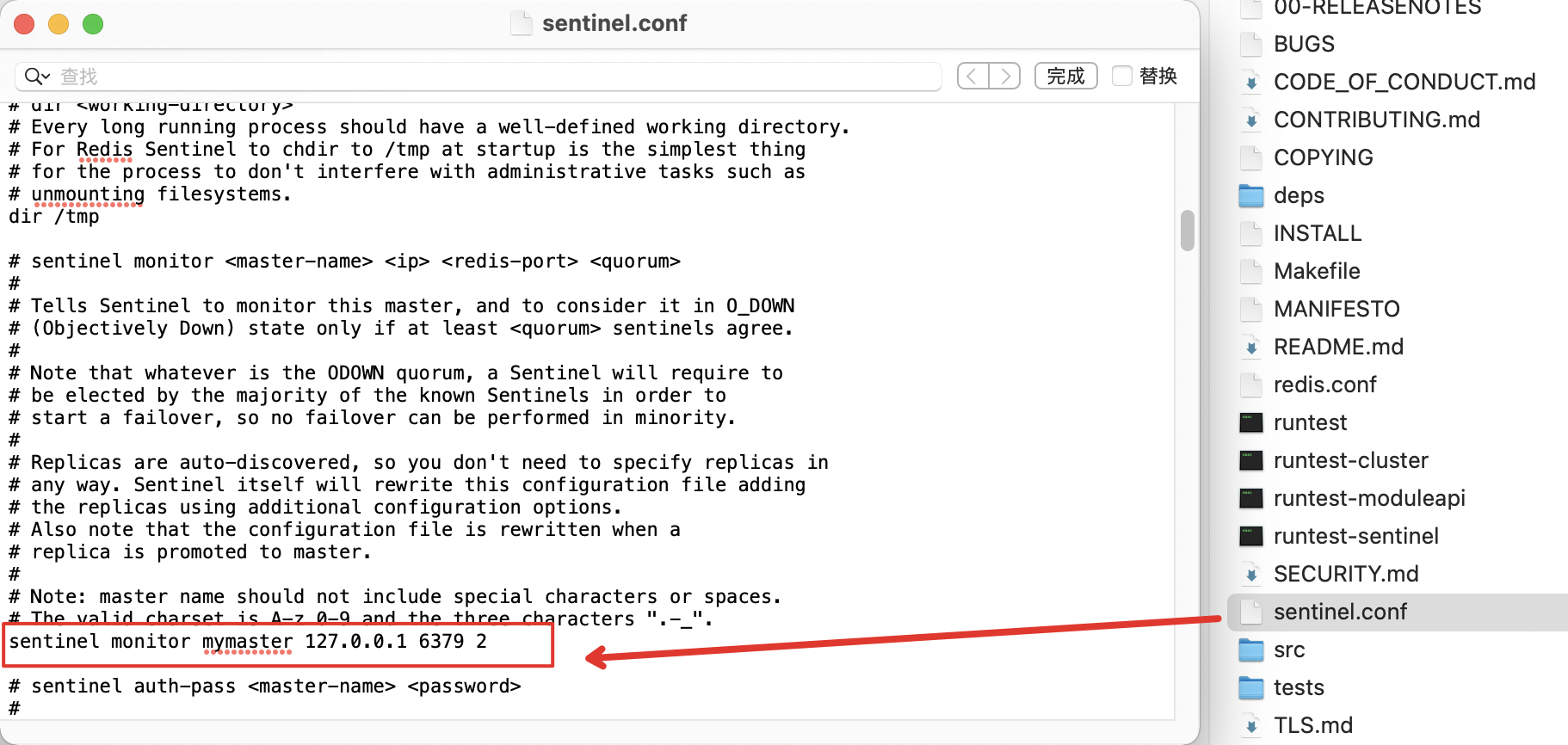
<span style="color:#000000"><span style="background-color:#ffffff"><code class="language-cpp"><span style="color:#2b91af"># sentinel monitor <span style="color:#3388aa"><master-name></span> <span style="color:#3388aa"><master-host></span> <span style="color:#3388aa"><master-port></span> <span style="color:#3388aa"><quorum></span></span>
# 舉例如下:
sentinel monitor master <span style="color:#880000">127.0</span><span style="color:#880000">.0</span><span style="color:#880000">.1</span> <span style="color:#880000">6379</span> <span style="color:#880000">2</span>
</code></span></span>這條配置項用于告知哨兵需要監聽的主節點:
1、sentinel monitor:監控標識
2、mymaster:這邊可以放上主節點的名稱
3、192.168.11.128 6379:代表監控的主節點 ip,port。6379是redis常規端口。
4、2:判定的sentinel數量,果你有3個 Sentinel,并且 quorum 設置為 2,那么至少需要有2個 Sentinel 認定 Master 節點不可用時(sdown),才會觸發故障轉移,執行 failover 操作。
3.1.2 監控和通信邏輯
1. 哨兵(Sentinel)與主節點(Master)之間
- Sentinel通過定期(1s一次心跳包)向主節點發送PING命令來檢查其狀態
- Sentinel啟動后根據配置向Master發送?
INFO?指令,獲取并保存所有哨兵(Sentinel)狀態,主節點(Master)和從節點(Slave)信息。 - 主節點(Master)會記錄所有從節點(Slave)和與它連接的哨兵(Sentinel)實例的信息。
2. 哨兵(Sentinel)與從節點(Slave)之間
- 從上面得知,Sentinel向Master發送?
INFO?命令,并獲取所有Slave的信息 - Sentinel 根據 Master 返回的 Slave 列表,逐個與 Salve 建立連接,同樣的定期向從節點發送PING命令來檢查它們的狀態
3. 集群中的哨兵(sentinel)之間實現通信
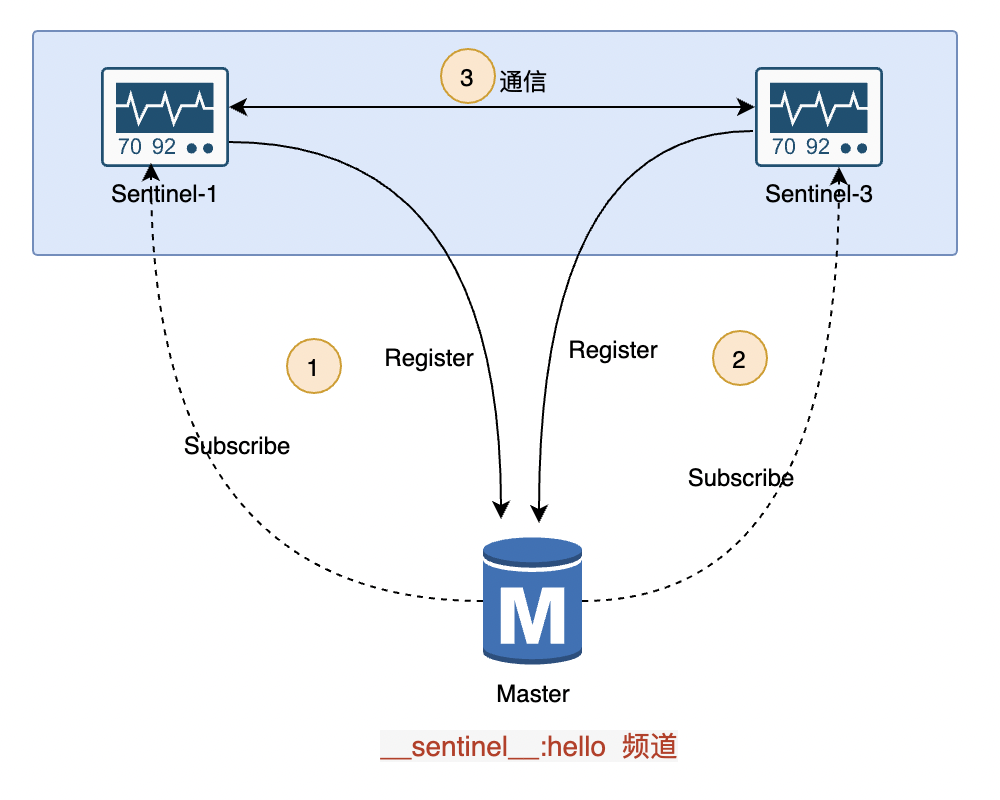
使用Redis的pub/sub 訂閱能力實現哨兵間通信 和 Slave 發現。
哨兵之間可以相互通信,主要歸功于 Redis 的 pub/sub (發布/訂閱)機制。Master 有一個?__sentinel__:hello?的專用通信通道,用于哨兵之間發布和訂閱消息。哨兵與 Master 建立通信之后,就可以利用 Master 提供發布/訂閱機制發布自己的IP、Port等信息,同時訂閱其他Sentinel發布的Name、IP、Port消息。
- Sentinel 建立與 Master 的通信
- 通過訂閱Master的
__sentinel__:hello頻道,當自身節點啟動或更新其狀態時,重新發布自己的當前狀態和信息(Name、IP、Port消息) - 同時訂閱其他哨兵發布的Name、IP、Port消息
- 互相發現之后建立起了連接,后續的消息通信就可以直接進行交互
★ 有沒有覺得套路很熟悉,這個與微服務中的服務注冊與發現,以及RPC通信類似的做法。請理解清楚圖中1、2、3步驟。
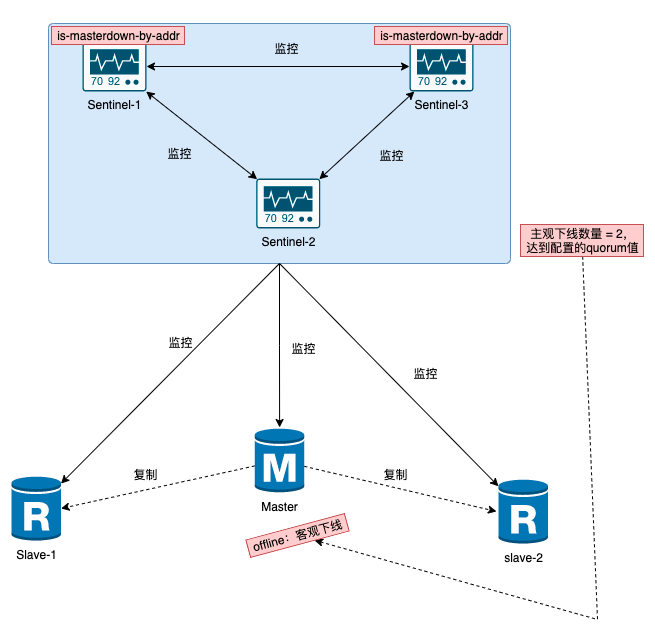
4. 標記下線的過程
我們上面說過了,Sentinel進程啟動之后,會定期(1s一次心跳包)向主節點發送PING命令來檢查其狀態,檢查看狀態是否正常響應。
- 如果Slave 沒有在規定的時間內響應 Sentinel 的 PING 命令 , Sentinel 會認為該實例已經掛了,將它tag為下線狀態(offline)。
- 同理,如果Master 沒有在規定時間響應 Sentinel 的 PING 命令,也會被判定為 offline 狀態,為后續的主從自動切換做好準備工作。
3.2 主從動態切換(故障轉移)
當master出現故障之后,Sentinel 的一個很核心的作用,就是從多個Slave中選舉出一個新的Master,以達到故障轉移的目的。核心步驟如下:
- 哨兵會心跳包定時給主節點發送?
publish sentinel :hello,如果超時不響應則標記 主觀下線(sdown)。超時時間配置?down-after-milliseconds前面說過了。 - 哨兵標記主節點 sdown 只是單個哨兵行為,需要往Sentinel集群發布消息說明這個主節點掛了,發送的指令
sentinel is-master-down-by-address-port。 - 其余的哨兵接收到指令后,也對Master進行探活,如果收不到響應同樣標記?
sdown,同時發送指令?sentinel is-master-down-by-address-port?到Sentinel內網,這樣哨兵內部群會再收到 Master 掛了的消息。 - 匯總計票,超過半數(通過
quorum配置)就認為Master節點確實不行了,然后修改其狀態為?odown, 既客觀下線。注意哨兵總數盡量為單數,避免『腦裂』。 - 一旦認為主節點
odown后,哨兵就會進行選舉新Master的工作,這很重要。 - 選舉新的Master,由指定的哨兵進行選舉。選舉條件:
- 響應慢的過濾掉,Sentinel會給所有的Redis從節點發送信息,響應速度慢的就會被優先過濾掉,說明健壯性不夠。
- 判斷 offset 偏移量,選擇數據偏移量差距最小的,即
slave_repl_offset與?master_repl_offset?的進度差距,其實就是比較 Slave 與 原 Master 復制進度差距。 假如 slave2 的 offset 為90, slave1 偏移量 為100 那么哨兵就會認為slave2的網絡不佳,優先選擇slave1為新的主節點。 - slave runID,在優先級和復制進度都相同的情況下,選用runID最小的,runID越小說明創建時間越早,優先選為Master,先來后到原則。
等這幾個條件都評估完,我們就會選擇出最合適的Slave,把他推舉為新的Master。
3.3 信息通知
等推選出最新的Master之后,后續所有的寫操作都會進入這個Master中。所以需要盡快廣播通知到所有的Slave,讓他們重新?replacaof?到 Master上,重新建立runID和slave_repl_offset?,來保證數據的正常傳輸和主從一致性。
4 總結
Redis 哨兵機制是實現 Redis 高可用的核心手段,相比之前的《Redis高可用之戰:主從架構》更具自動化和時效性。
它的核心功能職責如下:
- 集群監控:哨兵模式的主要任務之一是監控Redis主從復制集群中的各個節點。它會定期檢查主節點和從節點的健康狀態,確保它們都在正常運行。
- 故障檢測與通知:當檢測到主節點出現故障或不可用時,哨兵會立即發送報警通知給其他哨兵。這有助于及時發現并處理潛在的問題。
- 自動故障轉移:在檢測到主節點故障后,哨兵會自動觸發故障轉移機制。它會選擇一個健康的從節點,將其提升為新的主節點,并通知其他從節點更新復制目標。這樣,整個系統可以在主節點故障時保持可用性。
- 配置更新與通知:在故障轉移完成后,哨兵會更新相關配置,并將新的主節點地址通知給客戶端。這確保了客戶端可以連接到新的主節點并繼續進行操作。



)













與其他常用評估指標)

