概述
平均精度均值(mAP)是目標檢測領域中最為流行且復雜的重要評估指標之一。它廣泛用于綜合總結目標檢測器的性能。許多目標檢測模型會輸出類似以下的參數結果:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.309
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.519
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.327
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.173
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.462
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.547
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.297
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.511
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.376
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.686
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.686
這是 COCO 數據集的 mAP 版本(或他們稱之為 AP)。但這些數字到底是什么意思?這些符號又代表什么呢?
一、如何選擇目標檢測器
當衡量目標檢測器的質量時,主要想評估兩個標準:
- 模型是否正確預測了目標的類別。
- 預測的邊界框是否足夠接近真實框。
當將兩者結合起來時,事情開始變得復雜。與其他機器學習任務(如分類)相比,目標檢測沒有一個明確的“正確預測”的定義。這在邊界框標準中尤為明顯。
如下面的圖像,可以看出正確與不正確檢測框的區別:

在目標檢測領域,決策的制定往往充滿挑戰,尤其是在面對復雜多變的評估需求時。目標檢測器的性能評估并非一成不變,其表現可能因目標的大小而異。例如,某些檢測器在處理大型目標時表現出色,但在檢測小型目標時卻顯得力不從心;而另一些檢測器雖然在整體性能上并不突出,但在小型目標的檢測上卻具有獨特的優勢。此外,模型同時檢測到的目標數量也是一個重要的考量因素。這些因素相互交織,使得評估過程變得異常復雜。
COCO評估指標的出現,正是為了解決這一難題。它提供了一套標準化的評估體系,能夠在多種已確立的場景下,全面衡量目標檢測器的性能。COCO評估指標不僅關注目標檢測的準確性,還綜合考慮了檢測器在不同目標大小下的表現,以及模型同時檢測到的目標數量等多個維度。通過這種多維度的評估方式,COCO評估指標能夠更準確地反映目標檢測器在實際應用中的表現。
值得注意的是,COCO評估指標的應用范圍遠不止于目標檢測。它還涵蓋了分割、關鍵點檢測等多個領域,為這些領域的研究提供了統一的評估標準。然而,這些內容已經超出了當前討論的范疇,值得在后續的研究中進一步深入探討。
二、交并比
理解 mAP 的旅程從 IoU 開始。交并比(Intersection over Union) 是衡量兩個邊界框對齊程度的一種方法。它通常用于衡量預測框與真實框的質量。
正如其名稱所示,IoU 定義為兩個框的交集除以它們的并集:
I o U = A ∩ B A ∪ B IoU = \frac{A \cap B}{A \cup B} IoU=A∪BA∩B?
從圖上來看,交集和并集可以理解為:

左:原始預測。中:并集。右:交集。
在目標檢測任務中,評估預測框與真實框之間的匹配程度是一個關鍵的指標。這正是交并比(Intersection over Union,IoU)發揮作用的地方。IoU 是通過計算預測框與真實框的交集面積與它們的并集面積之比來定義的。這個比值提供了一個介于 0 和 1 之間的數值,用以衡量兩個框之間的重疊程度。
首先,我們來分析一下 IoU 公式的幾個關鍵點:
- 并集與交集的關系:并集總是大于或等于交集。這是因為并集包含了兩個框中所有的點,而交集只包含兩個框共有的點。
- 非重疊情況:如果兩個框不重疊,它們的交集將為零。在這種情況下,IoU 的值將為 0,表示兩個框之間沒有重疊。
- 完美重疊情況:如果兩個框完美重疊,它們的交集將與并集相等。在這種情況下,IoU 的值將為 1,表示兩個框完全匹配。
- IoU 的取值范圍:IoU 總是一個介于 0 和 1 之間的值,包括 0 和 1。這個范圍內的值表示了兩個框之間重疊程度的大小。
- IoU 的優化目標:在目標檢測任務中,IoU 越大越好。一個高的 IoU 值意味著預測框與真實框之間的重疊程度更高,這通常表示模型的預測更加準確。
除了 IoU,有時可能會聽到 Jaccard Index 或 Jaccard Similarity 這兩個術語。在目標檢測的上下文中,它們與 IoU 是相同的。Jaccard Index 是一種更通用的數學形式,用于比較兩個有限集之間的相似性。它通過計算兩個集合交集的大小與它們并集的大小之比來定義。在目標檢測中,我們通常將預測框和真實框視為兩個集合,因此 IoU 和 Jaccard Index 在這種情況下是等價的。
IoU 是一個重要的評估指標,用于衡量目標檢測模型的預測準確性。通過計算預測框與真實框之間的交集與并集之比,IoU 提供了一個介于 0 和 1 之間的數值,用以表示兩個框之間的重疊程度。一個高的 IoU 值通常表示模型的預測更加準確。
在 Python 中,IoU 可以這樣計算:
def iou(bbox_a, bbox_b):ax1, ay1, ax2, ay2 = bbox_abx1, by1, bx2, by2 = bbox_b# 計算交集的坐標ix1 = max(ax1, bx1)iy1 = max(ay1, by1)ix2 = min(ax2, bx2)iy2 = min(ay2, by2)# 計算交集矩形的面積intersection = max(0, ix2 - ix1) * max(0, iy2 - iy1)# 計算兩個邊界框的面積box1_area = (ax2 - ax1) * (ay2 - ay1)box2_area = (bx2 - bx1) * (by2 - by1)# 最后計算兩個面積的并集union = box1_area + box2_area - intersectionreturn intersection / union
IoU 的值介于 0 和 1 之間,其中 1 表示完美匹配,0 表示沒有重疊。但是,我們需要確定一個閾值,當 IoU 低于這個閾值時,我們就會認為預測是不準確的,從而放棄這個預測。
三、IoU 作為檢測閾值
再看看貓的預測示例。很明顯,最右邊的那個是錯誤的,而左邊的那個是可以接受的。我們的大腦是如何如此快速地做出這個決定的呢?中間的那個呢?如果我們比較模型的性能,我們不能讓這個決定主觀化。

3.1 IoU 作為閾值的定義與應用
IoU(交并比)不僅可以衡量預測邊界框與真實框的匹配程度,還可以作為閾值來決定是否接受一個預測。在目標檢測領域,IoU 閾值的設定是評估模型性能的關鍵因素之一。
具體來說,當 IoU 閾值被指定為 IoU@0.5 時,這意味著只有當預測框與真實框的 IoU 大于或等于 0.5(即 50%)時,該預測框才被視為正確匹配。換句話說,如果預測框與真實框的重疊面積不足 50%,則認為該預測是不準確的,從而被舍棄。
3.2 常見的 IoU 閾值及其含義
在學術文獻和實際應用中,常見的 IoU 閾值包括:
- IoU@0.5:這是最常用的閾值,表示預測框與真實框的重疊面積至少為 50% 時,預測才被視為正確。
- IoU@0.75:這是一個更高的閾值,要求預測框與真實框的重疊面積至少為 75%,通常用于評估更嚴格的匹配標準。
- IoU@0.95:這是一個非常嚴格的閾值,要求預測框與真實框的重疊面積至少為 95%,通常用于評估模型在極端情況下的性能。
3.3 多個 IoU 閾值的表示方法
除了單一的 IoU 閾值,有時我們還會遇到表示多個閾值的表達式,例如 IoU@[0.5:0.05:0.95]。這個表達式表示從 0.5 到 0.95,以 0.05 為步長的所有 IoU 閾值。具體來說,它涵蓋了以下 10 個不同的 IoU 閾值:
- IoU@0.5
- IoU@0.55
- IoU@0.6
- IoU@0.65
- IoU@0.7
- IoU@0.75
- IoU@0.8
- IoU@0.85
- IoU@0.9
- IoU@0.95
這種表示方法在 COCO 數據集的評估中非常流行,因為它能夠全面評估模型在不同嚴格程度下的性能。通過計算模型在這些不同閾值下的平均性能(如平均精度,AP),可以更全面地反映模型的魯棒性和準確性。
3.4 關于簡寫和默認值
在目標檢測的文獻中,作者有時會省略步長,簡單地寫成 IoU@[0.5:0.95]。雖然這種簡寫可能會引起一些混淆,但通常可以推斷出作者指的是從 0.5 到 0.95,步長為 0.05 的 10 個 IoU 閾值。
此外,當評估目標檢測器時,如果作者沒有明確指定 IoU 閾值,通常默認為 IoU=0.5。這是因為 IoU@0.5 是最常用的標準,能夠提供一個基本的性能評估。
四、真正例、假正例、真負例和假負例
接下來需要理解的概念是 TP(真正例)、FP(假正例)、TN(真負例)和 FN(假負例)。這些術語是從二元分類任務中借來的。下表是一個假設的蘋果分類器的總結:
| Object | Prediction | Category | Explanation |
|---|---|---|---|
| 🍎 | ? | TP | 該物體被正確分類為蘋果。 |
| 🍌 | ? | FP | 該物體被錯誤地分類為蘋果。 |
| 🍎 | ? | FN | 該物體被錯誤地分類為非蘋果。 |
| 🍌 | ? | TN | 該物體被正確分類為非蘋果。 |
一個好的分類器會有大量的真正例和真負例,同時盡量減少假正例和假負例。
4.1 多類分類器
上面提到的概念并不完全適用于多類分類器。二元分類器回答的是“這個對象是否屬于這個類別?”而多類分類器回答的是“這個對象屬于這些類別中的哪一個?”幸運的是,我們可以使用“一對一”或“一對多”的方法將其擴展。想法很簡單:我們分別評估每個類別,并將其視為一個二元分類器。那么,以下內容成立:
- 正例:正確預測了該類別屬于目標對象。
- 負例:預測了其他類別屬于目標對象。
以下是從蘋果(🍎)類別角度出發的相同總結表。
| Object | Prediction | Category | Explanation |
|---|---|---|---|
| 🍎 | 🍎 | TP | 該物體被正確分類為蘋果。 |
| 🍌 | 🍎 | FP | 該物體被錯誤地分類為蘋果。 |
| 🍎 | 🍌 | FN | 該物體被錯誤地分類為香蕉(即未被正確分類為蘋果)。 |
| 🍎 | 🥭 | FN | 該物體被錯誤地分類為芒果(即未被正確分類為蘋果)。 |
在談論多類模型時,很少使用“真負例”這個術語,但它可以理解為“正確識別為其他類別的樣本”。
現在,讓我們從香蕉(🍌)的角度做一個類似的練習。
| Object | Prediction | Category | Explanation |
|---|---|---|---|
| 🍌 | 🍌 | TP | 該物體被正確分類為香蕉。 |
| 🍌 | 🍎 | FN | 該物體被錯誤地分類為蘋果(即未被正確分類為香蕉)。 |
| 🍎 | 🍌 | FP | 該物體被錯誤地分類為香蕉。 |
從蘋果類別的角度來看,(🍌,🍎)組合是一個 FP,但從香蕉類別的角度來看,它是一個 FN。類似的情況也發生在(🍎,🍌)組合上,它從蘋果類別的角度來看是一個 FN,但從香蕉類別的角度來看是一個 FP。這種重疊是多類模型中預期和典型的!
4.2 應用
剩下的問題是:如何將上述概念應用到目標檢測器中?檢測器通常是多類分類器,但也有目標定位的因素。幸運的是,我們已經有 IoU 指標可供使用!
在這里,我們可以直接跳到總結。假設 IoU=50%。
真正例(True Positive)
- 預測邊界框與真實框的 IoU 高于 50%。并且
- 預測類別與真實類別匹配。
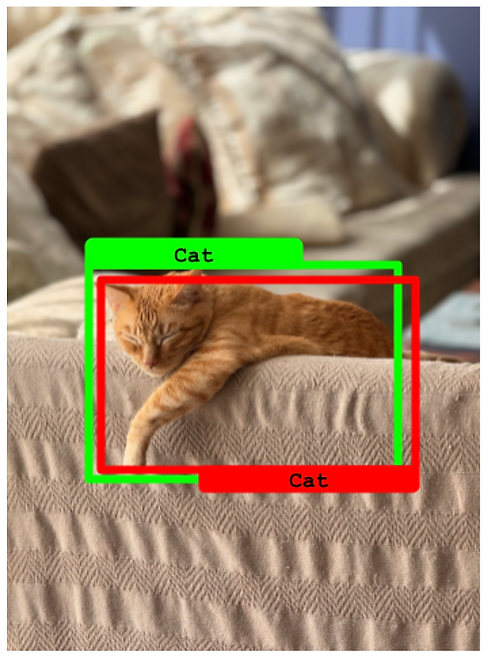
目標檢測中的真正例示例。
假正例(False Positive)
- 預測邊界框與真實框的 IoU 低于 50% 或者
- 沒有對應的真實框 或者
- 預測類別與真實類別不匹配。

目標檢測中的假正例示例。左:IoU 低于 50%。中:缺少真實框。右:錯誤的類別。
假負例(False Negative)
- 每一個沒有匹配預測的真實框。
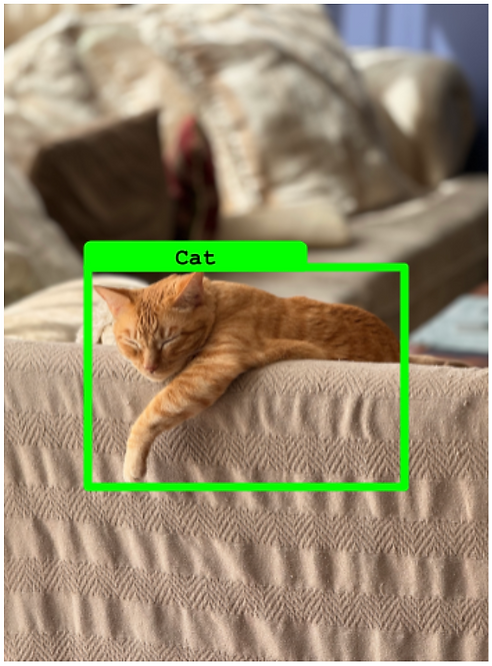
目標檢測中的假負例示例(對于某個真實框沒有預測)。
4.3 模糊的例子
在下圖中,有兩個真實框,但只有一個預測框。在這種情況下,預測框只能歸屬于其中一個真實框(IoU 超過 50%)。不幸的是,另一個真實框變成了一個 假負例。
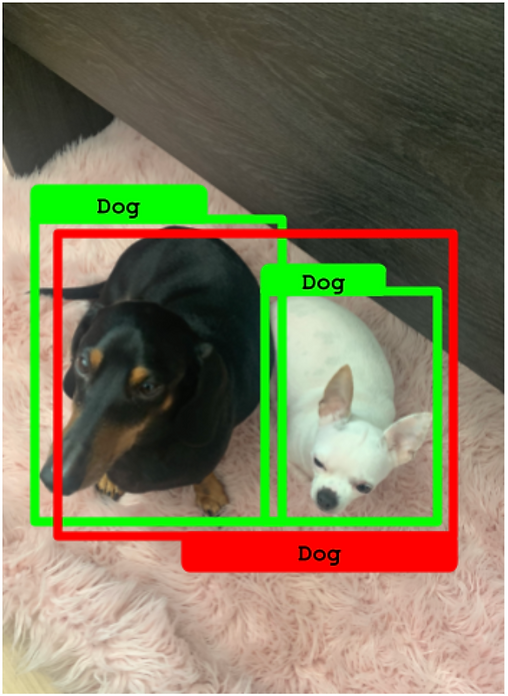
預測框只能歸屬于一個真實框。另一個真實框變成了假負例。
在下一個例子中,對同一個真實框做出了兩個預測。然而,這兩個預測的 IoU 都低于 50%。在這種情況下,這兩個預測都被算作 假正例,而孤立的真實框是一個 假負例。
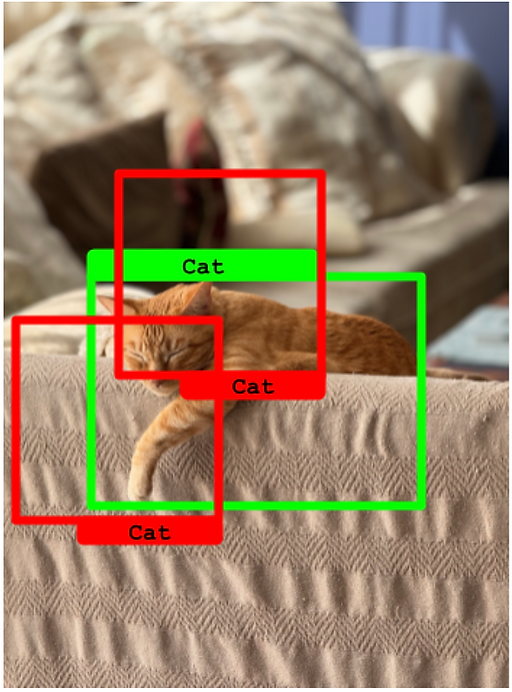
兩個預測的 IoU 都低于 50%。它們變成了假正例,而真實框變成了假負例。
在最后一個例子中,我們有一個類似的場景,但兩個預測的 IoU 都很好(超過 50%)。在這種情況下,IoU 最好的那個被算作一個 真正例,而另一個變成了一個 假正例。
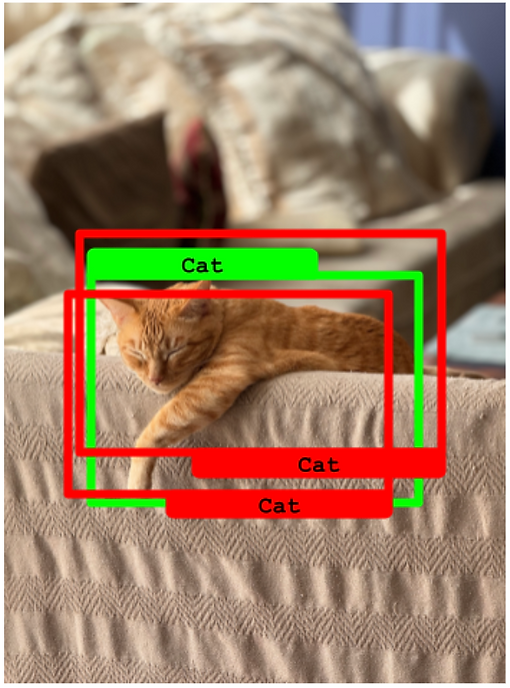
兩個預測的 IoU 都超過 50%。一個變成真正例,另一個變成假正例。
五、精確率、召回率和 F1 分數
現在我們知道了如何將 TP、FP、TN 和 FN 應用于目標檢測器,我們可以從分類器中借鑒其他指標。這些是 精確率(Precision)、召回率(Recall) 和 F1 分數(F1 Score)。同樣,這些指標是按類別衡量的。下表總結了它們:
| 指標 | 公式 | 概念 |
|---|---|---|
| 精確率(Precision) | ( P = \frac{TP}{TP + FP} ) | 對于一個類別所做的所有預測中,實際正確的預測所占的百分比。 |
| 召回率(Recall) | ( R = \frac{TP}{TP + FN} ) | 在一個類別的所有物體中,被正確預測的物體所占的百分比。 |
| F1值(F1) | ( F1 = 2 \cdot \frac{P \cdot R}{P + R} ) | 精確率和召回率的幾何平均值。 |
5.1 精確率(Precision)
對于一個給定的類別,精確率告訴我們該類別預測中實際屬于該類別的比例是多少。下圖顯示了一個檢測器的結果,其中有 3 個真正例和 1 個假正例,精確率為:
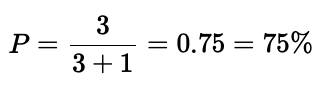

3 個人物,但只有 3 次人物檢測。
如果你關心模型不產生假正例,就要關注精確率。例如:錯過股市上漲總比錯誤地將上漲預測為下跌要好。
敏銳的讀者可能已經注意到,精確率公式沒有考慮假負例。只關注精確率可能會非常誤導人。如下例所示:
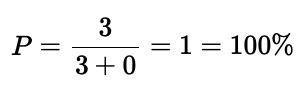

雖然只有 3 次檢測,但它們的類別都是正確的,因此精確率是 100%。
正如你所見,精確率指標達到了 100%,但模型表現不佳,因為它有很多假負例。
不要單獨測量精確率,因為沒有考慮假負例。
5.2 召回率(Recall)
對于一個給定的類別,召回率(或靈敏度)告訴我們實際類別實例中有多少被正確預測了。從同一張圖來看,檢測器正確預測了 3 個類別實例(真正例),但有 3 個實例完全沒有被預測到(假負例):
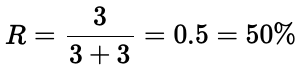

6 個面包中只檢測到了 3 個。
如果你希望避免假負例,就要關注召回率。例如:誤診癌癥總比錯誤地將患者預測為健康要好。
同樣,可以注意到召回率沒有考慮假正例,因此如果單獨測量也會誤導人:
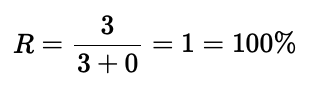
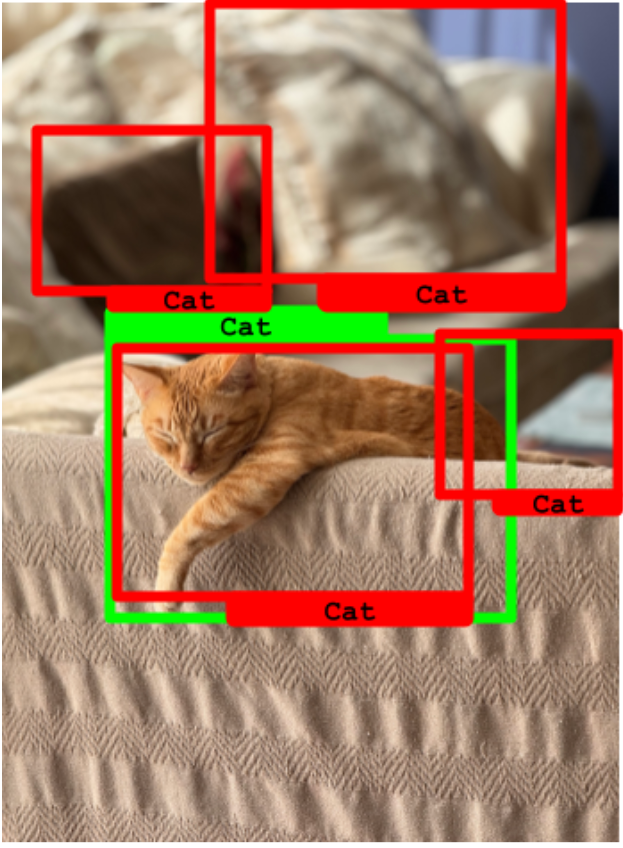
圖中的一只貓被成功檢測到,但還有 3 個假正例。
正如你所見,召回率指標達到了 100%,但模型表現不佳,因為它有很多假正例。
不要單獨測量召回率,因為沒有考慮假正例。
5.3 F1 分數(F1 Score)
F 分數或 F1 分數是一個結合了精確率和召回率的指標,為我們提供了一個平衡。再次使用上面的同一張圖,模型將返回一個 F1 分數為:
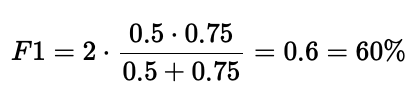
F1 分數衡量了精確率和召回率之間的平衡。
六、PR(精確率 - 召回率)曲線
到目前為止,我們已經看到精確率和召回率描述了模型的不同方面。在某些場景中,擁有更高的精確率更方便,而在其他場景中,擁有更高的召回率更方便。你可以通過調整檢測器的目標置信度閾值來調整這些指標。
事實證明,有一種非常方便的方法可以直觀地展示模型對特定類別的響應在不同分類閾值下的表現。這就是精確率 - 召回率曲線,如下圖所示:
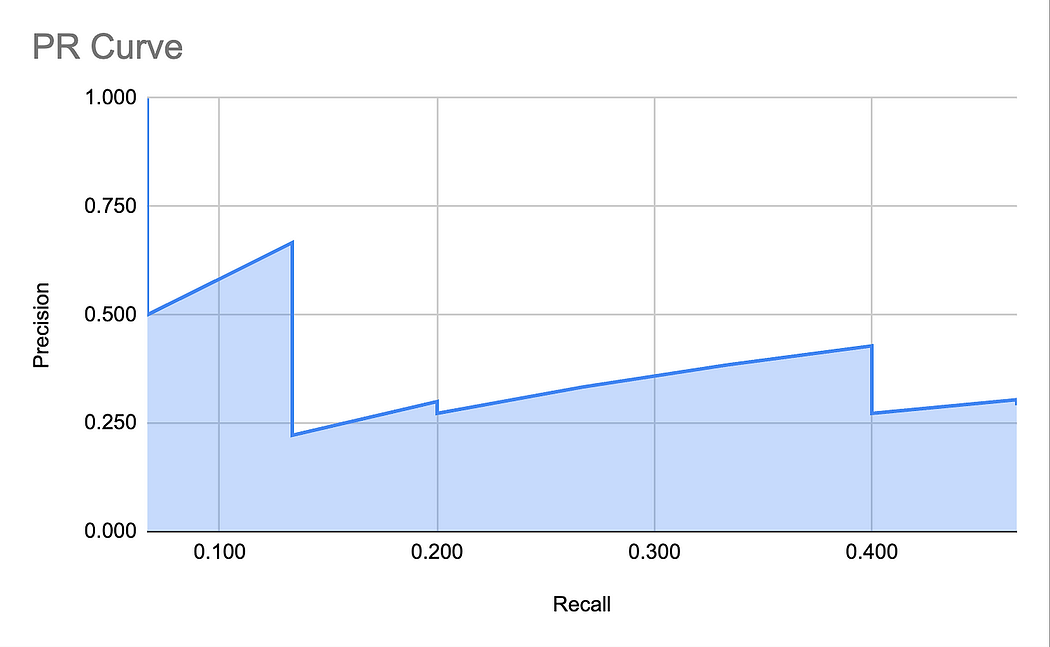
創建 PR 曲線的過程如下:
- 將置信度設置為 1,初始精確率設為 1。召回率將為 0(如果你做數學計算的話)。在曲線上標記這個點。
- 開始降低置信度,直到獲得第一次檢測。計算精確率和召回率。精確率將再次為 1(因為你沒有假正例)。在曲線上標記這個點。
- 繼續降低閾值,直到新的檢測出現。在曲線上標記這個點。
- 重復上述步驟,直到閾值足夠低,使得召回率達到 1。此時,精確率可能在 0.5 左右。
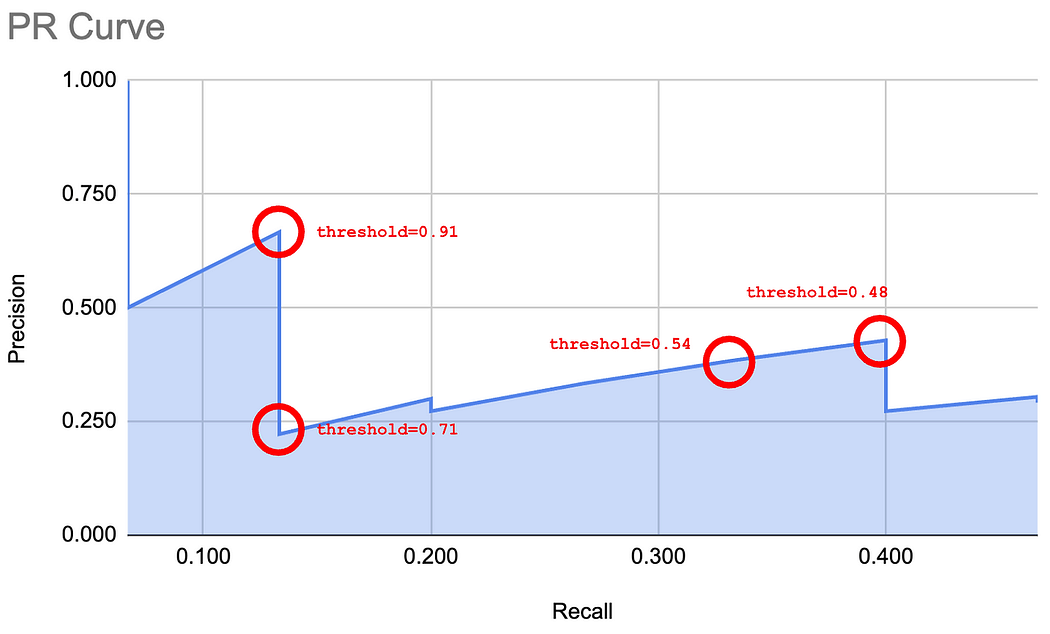
下圖展示了在 PR 曲線上評估某些點的閾值。
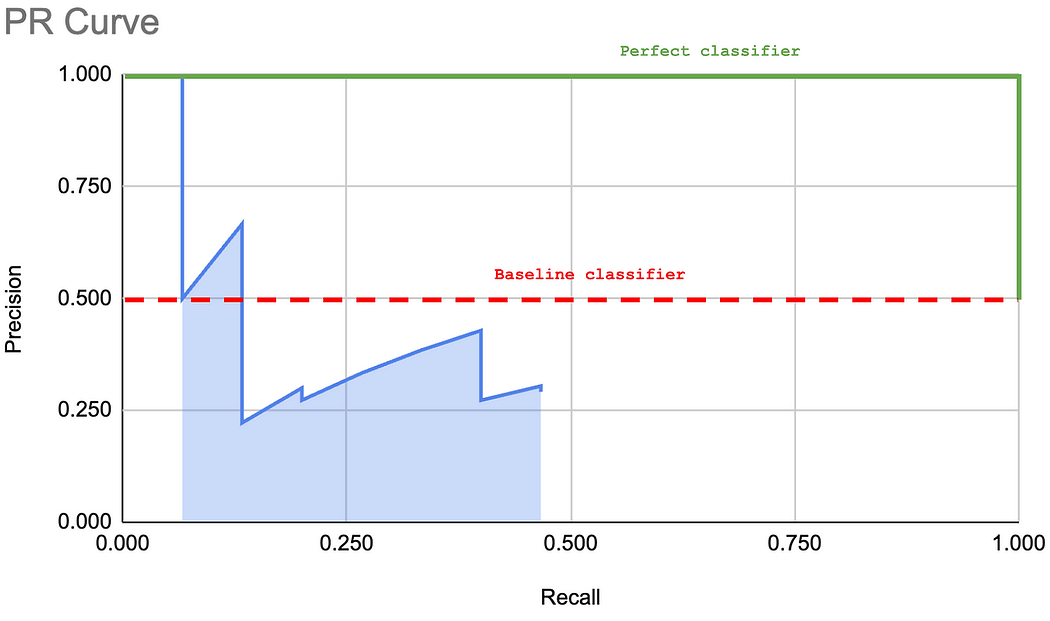
可以看到,這條曲線的形狀可以用來描述模型的性能。下圖展示了一個“基線”分類器和一個“完美”分類器。分類器越接近“完美”曲線,性能越好。
6.1 實用的 PR 曲線算法
在現實中,有一種更實用的方法來計算 PR 曲線。雖然這可能看起來有些反直覺,但結果與上述步驟相同,只是更適合腳本化:
- 將所有圖像的所有預測按置信度從高到低排序。
- 對于每個預測,計算 TP、FP 以及累積的 TP 和 FP 數量(之前所有 TP 和 FP 的總和)。
- 對于每個預測,使用累積的 TP 和 FP 計算精確率和召回率。
- 繪制結果的精確率和召回率的散點圖。
下表展示了在包含 15 個對象的小數據集上運行該算法的結果:
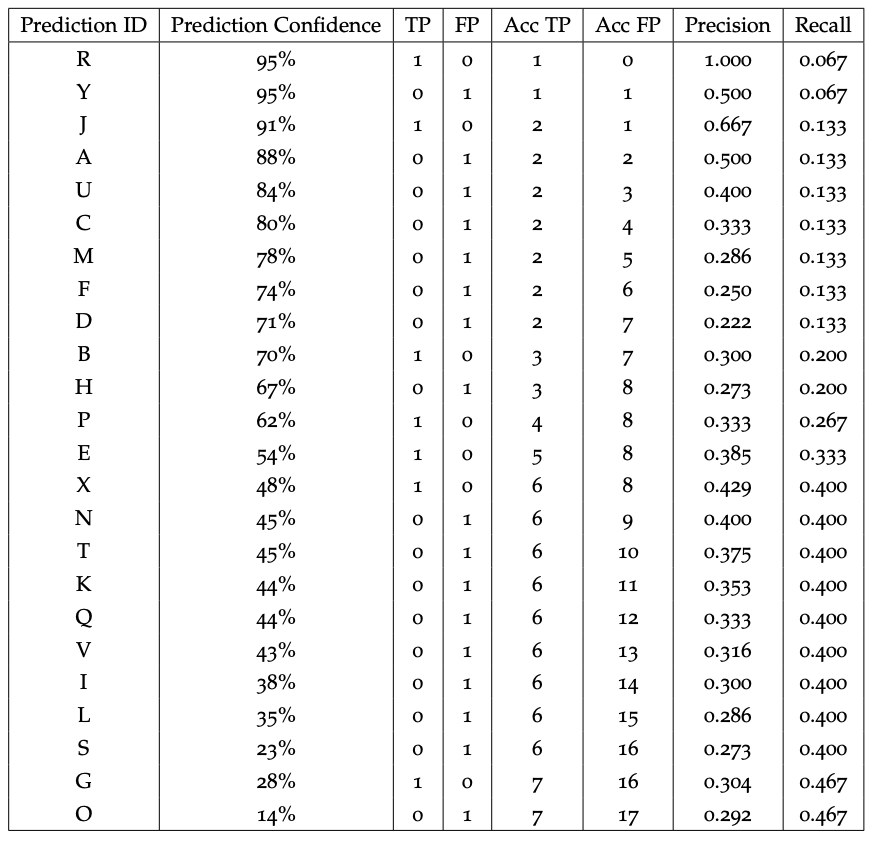
計算 PR 曲線的運行表。來源。
例如,如果我們計算 ID 為 K 的檢測的精確率和召回率(記住該數據集有 15 個真實對象,即 TP+FN=15):
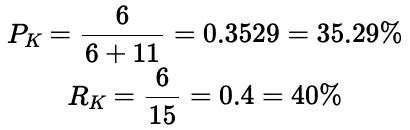
得到的 PR 曲線就是我們之前展示過的那條。為了方便起見,再次展示這個圖:
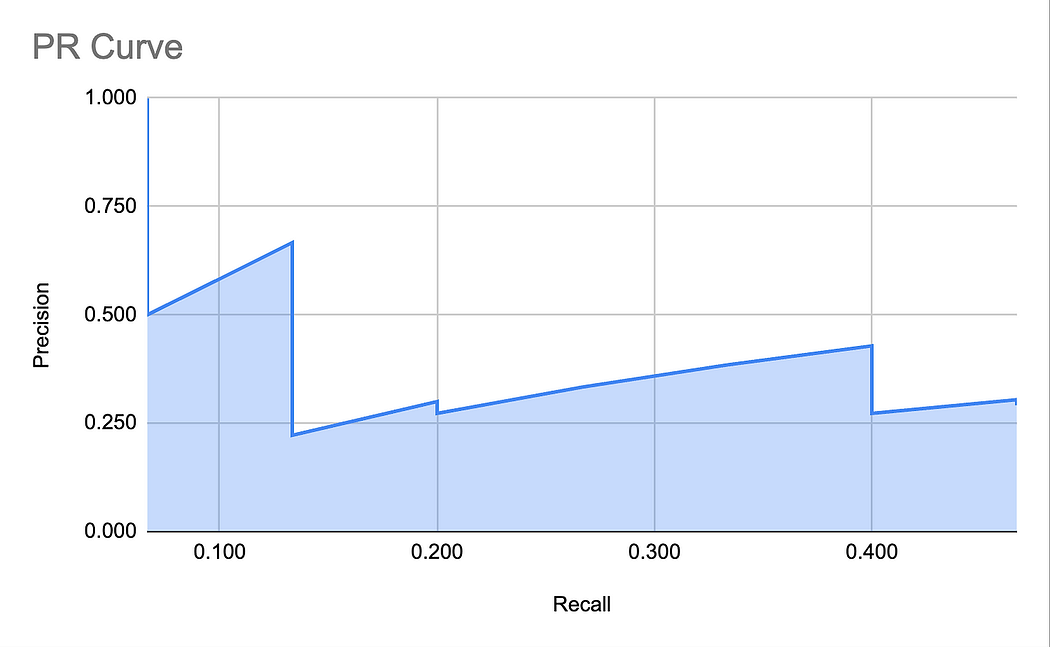
七、AP——平均精確率
到目前為止,我們已經知道如何為每個類別創建 PR 曲線。現在是時候計算平均精確率了。
AP 是 PR 曲線下的面積(AUC)。
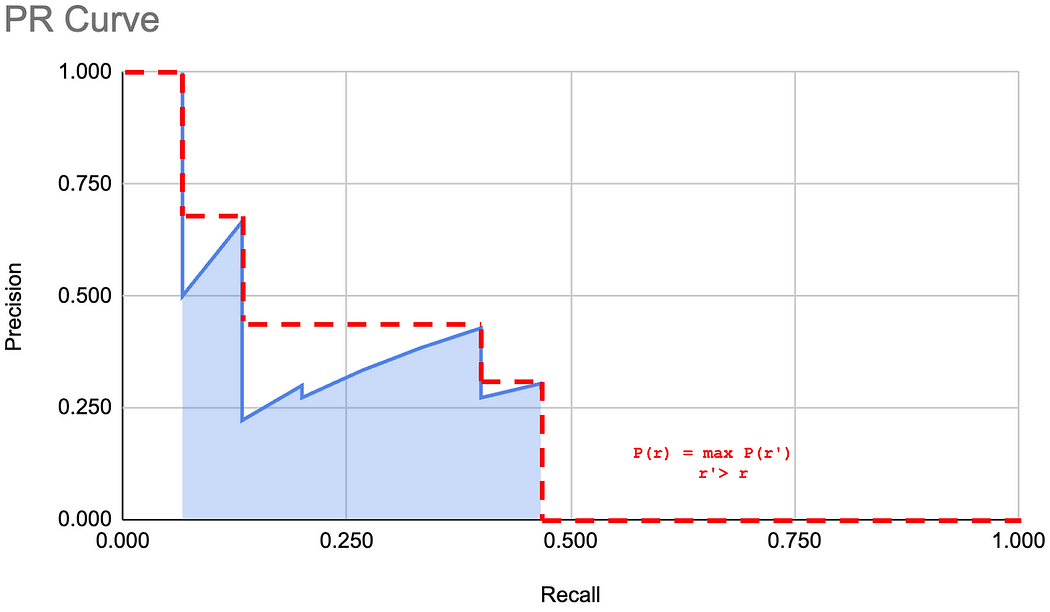
然而,正如你可能已經注意到的,PR 曲線的不規則形狀和尖峰使得計算這個面積相當困難。因此,COCO 定義了一個 11 點插值,使計算變得更簡單。
7.1 COCO 11 點插值
對于一個給定的類別 C,11 點插值包括以下三個步驟:
- 定義 11 個等間距的召回率評估點:[0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]。
- 對于每個召回率評估點 r,找到所有召回率 r’ >= r 中最高的精確率 p。或者用數學公式表示為:
p ( r ) = max ? r ′ ≥ r p ( r ′ ) p(r) = \max_{r' \geq r} p(r') p(r)=r′≥rmax?p(r′)
圖形化地看,這僅僅是一種從圖中去除尖峰的方法,使其看起來像這樣:
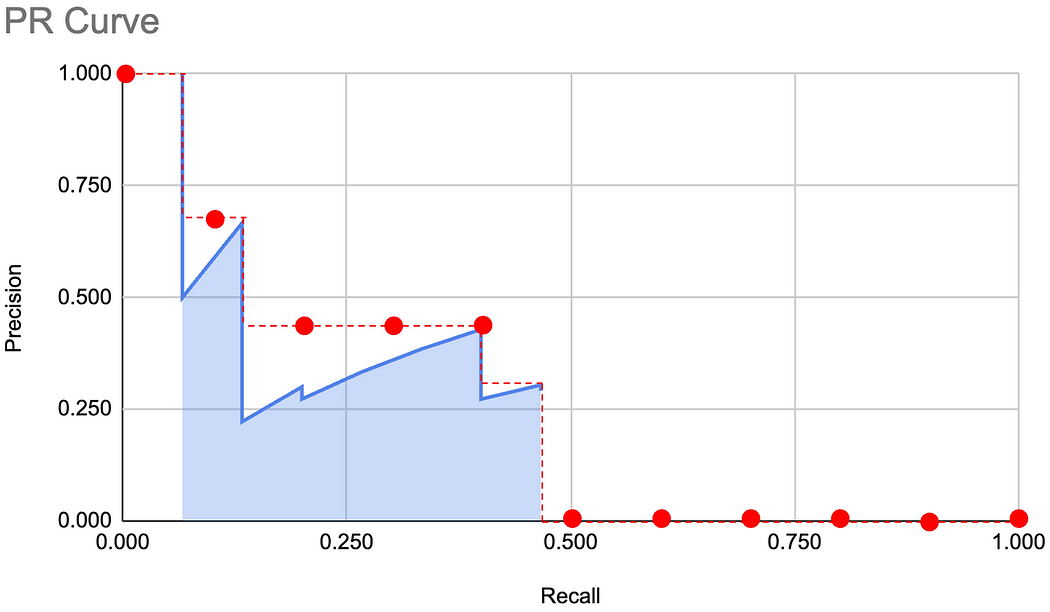
- 在這些召回率評估點上對獲得的精確率取平均值,得到類別 C 的平均精確率 AP_C:
A P C = 1 11 ∑ r ∈ [ 0.0 , 0.1 , … , 1.0 ] p ( r ) AP_C = \frac{1}{11} \sum_{r \in [0.0, 0.1, \dots, 1.0]} p(r) APC?=111?r∈[0.0,0.1,…,1.0]∑?p(r)
讓我們以同一個圖表為例,計算 AP。
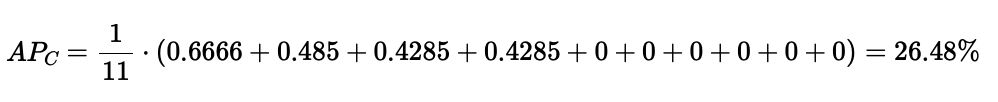
7.2 COCO mAP——平均精度均值
我們終于可以計算 mAP 了,這也是本文的核心指標。在上一節中,我們計算了一個給定類別的 AP。mAP 不過是每個類別的 AP 的平均值。換句話說:
m A P = 1 N ∑ C = 1 N A P C mAP = \frac{1}{N} \sum_{C=1}^{N} AP_C mAP=N1?C=1∑N?APC?
其中 ( N ) 是類別的總數。
因此,從某種意義上說,mAP 是精確率的平均值的平均值。現在讓我們深入了解 COCO 生成的報告的具體內容。
COCO 沒有區分 AP 和 mAP,但從概念上講,它們指的是 mAP。
7.3 不同 IoU 閾值下的 mAP
報告的第一部分如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.309
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.519
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.327
讓我們先關注 IoU。
- IoU@0.50 和 IoU@0.75 是很簡單的。正如在 IoU 部分解釋的那樣,這些只是在兩個不同的 IoU 閾值(分別為 50% 和 75%)下評估的系統。當然,你期望 0.75 的值會低于 0.5,因為它更嚴格,需要更好的邊界框匹配。
- IoU@[0.50:0.95] 我們已經知道它擴展為 10 個不同的 IoU 閾值:0.5, 0.55, 0.6, …, 0.95。從這些值中,我們計算每個 IoU 閾值的 mAP 并取平均值。這通常是最嚴格的指標,因此也是默認的。
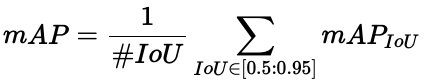
這變成了“平均值的平均值的平均值”!
7.4 不同目標大小的 mAP
報告的下一部分如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.173
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.462
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.547
現在我們關注面積部分。這些作為過濾器,用于衡量檢測器在不同大小范圍的目標上的性能。
- 小目標 的面積范圍為 ([02, 322))。
- 中等目標 的面積范圍為 ([322, 962))。
- 大目標 的面積范圍為 ([962, ∞))。
面積以像素為單位,而 (∞) 在實際中被定義為 (1e?2)。因此,對于 area=small 的報告,只會考慮面積在指定范圍內的目標。
八、AR——平均召回率
最后,除了 mAP(或 AP)之外,COCO 還提供了 AR(平均召回率)。正如你所想象的,計算方法相同,只是從召回率的角度進行評估。除了常規的報告行之外,值得注意的是以下幾行:
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.297
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.511
在這里,他們變化了一個 maxDets 參數,它控制了每張圖像中可能的檢測數量上限,用于進行精確率和召回率的計算。每張圖像最多檢測 100 個目標聽起來可能很多,但要記住,在 PR 曲線中,你會從 0 到 1 變化置信度閾值,而在最低值時,你可能會得到很多假正例。
值得注意的是,maxDets 的變化只在召回率方面才有意義。這是因為精確率衡量的是檢測的準確性,而召回率衡量的是模型在數據集中檢測所有相關實例的能力,這受到潛在檢測數量的影響。
九、COCO 評估 API
現在,希望你已經清楚了不同類型的 mAP 的計算方法,更重要的是,理解了它們的含義。COCO 提供了一個 Python 模塊,能夠在后臺計算所有這些指標,并且實際上是 他們競賽任務的官方結果呈現方式。
以下是如何使用 COCO 評估 API 的示例:
# 下載示例數據集
import requests
import zipfile
from tqdm import tqdm# 示例模型
from ultralytics import YOLO# COCO 工具
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval# 檢查是否需要重新下載
import os# 下載文件的輔助函數
def download_file(url, file_path):response = requests.get(url, stream=True)total_size_in_bytes = int(response.headers.get('content-length', 0))block_size = 1024 # 1 Kibibyteprogress_bar = tqdm(total=total_size_in_bytes, unit='iB', unit_scale=True)with open(file_path, 'wb') as file:for data in response.iter_content(block_size):progress_bar.update(len(data))file.write(data)progress_bar.close()coco_url = "https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017val.zip"
coco_zip_path = 'coco2017val.zip'# 如果沒有 coco 目錄,則下載并解壓
if not os.path.exists('coco'):download_file(coco_url, coco_zip_path)# 解壓文件with zipfile.ZipFile(coco_zip_path, 'r') as zip_ref:zip_ref.extractall('.')# 加載預訓練的 YOLOv8 模型
model = YOLO('./yolov8n.pt')# 加載 COCO 驗證圖像注釋
coco_annotations_path = 'coco/annotations/instances_val2017.json'
coco = COCO(coco_annotations_path)# 獲取圖像 ID
image_ids = coco.getImgIds()
images = coco.loadImgs(image_ids)# 處理圖像并收集檢測結果
results = []
for img in images:image_path = f"coco/images/val2017/{img['file_name']}"preds = model(image_path)[0].numpy().boxes# 將結果轉換為 COCO 兼容的格式for xyxy, conf, cls in zip(preds.xyxy, preds.conf, preds.cls):result = {'image_id': img['id'],'category_id': int(cls.item() + 1), 'bbox': [xyxy[0].item(), xyxy[1].item(), xyxy[2].item() - xyxy[0].item(), xyxy[3].item() - xyxy[1].item()],'score': conf.item()}results.append(result)# 將結果轉換為 COCO 對象
coco_dt = coco.loadRes(results)# 運行 COCO 評估
coco_eval = COCOeval(coco, coco_dt, 'bbox')
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
創建虛擬環境,安裝依賴項并運行報告:
pip3 install ultralytics
pip3 install requests
pip3 install pycocotools
python3 ./coco_map_report.py
輸出結果如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.053Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.071Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.058Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.021Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.052Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.083Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.043Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.061Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.061Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.027Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.062Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.094



】庫存管理模塊開發實戰:從基礎搭建到智能管控)


注意力機制(第2/4集),pytorch 中的多維注意力機制、自注意力機制、掩碼自注意力機制、多頭注意力機制)






)



之旅——啟航①)

