探秘Transformer系列之(25)— KV Cache優化之處理長文本序列
文章目錄
- 探秘Transformer系列之(25)--- KV Cache優化之處理長文本序列
- 0x00 概述
- 0x01 優化依據
- 1.1 稀疏性
- 1.2 重要性
- 1.3 小結
- 0x02 稀疏化
- 1.1 分類
- 1.2 靜態稀疏化
- 1.2.1 Window Attention
- 1.2.2 StreamingLLM
- Attention sink
- 思路
- 問題
- 1.3 動態稀疏化
- 1.3.1 H2O
- 動機
- 方案
- 優化點
- 1.3.2 keyformer
- 動機
- 方案
- 評分函數
- 算法
- 優化點
- 1.3.3 小結
- 1.3 針對prefill的稀疏化
- 1.3.1 FastGen
- 洞見
- 算法
- 1.3.2 SnapKV
- 洞見
- 方案
- 1.4 針對層特點的稀疏化
- 1.4.1 PyramidKV
- 洞察
- 方案
- 1.4.2 PyramidInfer
- 動機
- 方案
- 1.4.3 ZigZagKV
- 動機
- 空間分配
- 1.4.4 Layer-Condensed KV Cache
- 1.5 其它方案
- 1.5.1 針對頭特點的稀疏化
- 1.5.2 投機采樣稀疏化
- 1.5.3 聚類稀疏化
- 0x02 復用
- 2.1 KV Cache合并
- 2.1.1 層間合并
- 2.3 層內合并
- 2.2 前綴復用
- 2.2.1 需求
- 2.2.1 Prompt Cache
- 洞見
- 方案
- 2.2.2 Hydragen
- 2.2.3 ChunkAttention
- 2.2.4 AttentionStore
- 2.2.5 Radix Attention
- 0x03 依據檢索的方案
- 3.1 InfiniGen
- 問題
- 洞察
- 設計
- 總體方案
- 離線階段
- Prefill階段
- 解碼階段
- KV Cache資源池管理
- 0xEE 個人信息
- 0xFF 參考
0x00 概述
即便做了KV Cache,在長序列場景下,也只是減少了K和V本身結果計算量。但是和后面的部分依然計算量很大,并且K和V存儲的壓力也非常大。這其實嚴重阻礙了我們使用更長的序列做輸入以及生成更長的序列。要解決這個問題,我們就需要對KV Cache進行優化。
KV Cache優化的核心在于減少內存消耗的原則。這一目標可以通過進一步壓縮鍵值對(Key-Value Pairs)中的“K”(鍵)或“V”(值)來實現。這些壓縮技術的選擇直接影響模型的效率,特別是在內存使用和處理速度方面。壓縮鍵值對就是讓K和V變短,也就是說我們要舍棄或者壓縮一些K和V。通過丟棄這些 token ,我們實際上將相應的注意力分數設置為零,并將注意力矩陣近似為一個更稀疏的矩陣。
減少序列長度是KV-Cache壓縮領域研究最多的點。目前大致分為幾個大方向:
- 拋棄不重要的token(稀疏化)。通過attention score或者attention的系數特征來判別不重要的token,然后把這些token對應的KV都拋棄掉。這部分研究跟LLM的量化一樣,都在activation outlier提出來之后取得了比較大的進展。雖然這種方法可以提高效率,但存在丟棄關鍵詞元的風險,特別是對于需要深入理解遠距離上下文的任務。
- 復用token。通過復用來降低序列長度。比如復用system prompt等,這是一種工程優化,從算法層面上看,是一種無損優化,無需訓練側介入。
- 基于檢索(retrieval/取回)的方法。比如把KVCache offload到cpu,以頁或者聚類的形式組織。q和每個頁或者聚類進行相似度計算來決定使用哪些頁或者聚類。每次只把得分最高的top-k個頁或者聚類加載到顯存計算。
注:全部文章列表在這里,估計最終在35篇左右,后續每發一篇文章,會修改文章列表。
csdn 探秘Transformer系列之文章列表
探秘Transformer系列之(1):注意力機制
探秘Transformer系列之(2)—總體架構
探秘Transformer系列之(3)—數據處理
探秘Transformer系列之(4)— 編碼器 & 解碼器
探秘Transformer系列之(5)— 訓練&推理
探秘Transformer系列之(6)— token
探秘Transformer系列之(7)— embedding
探秘Transformer系列之(8)— 位置編碼
探秘Transformer系列之(9)— 位置編碼分類
探秘Transformer系列之(10)— 自注意力
探秘Transformer系列之(11)— 掩碼
探秘Transformer系列之(12)— 多頭自注意力
探秘Transformer系列之(13)— FFN
探秘Transformer系列之(14)— 殘差網絡和歸一化
探秘Transformer系列之(15)— 采樣和輸出
探秘Transformer系列之(16)— 資源占用)
探秘Transformer系列之(17)— RoPE(上)
探秘Transformer系列之(17)— RoPE(下)
探秘Transformer系列之(18)— FlashAttention
探秘Transformer系列之(19)----FlashAttention V2 及升級版本
探秘Transformer系列之(20)— KV Cache
探秘Transformer系列之(21)— MoE
探秘Transformer系列之(22)— LoRA
探秘Transformer系列之(23)— 長度外推
探秘Transformer系列之(24)— KV Cache優化
0x01 優化依據
減少序列長度的理論根源主要是以下兩點:
- 大型語言模型(LLMs)注意力機制中的內在稀疏性。
- token的重要性程度不同。
1.1 稀疏性
盡管transformers存在巨大的計算需求,但LLMs的注意力機制內部確實存在固有的稀疏性。同理,KV Cache中做為注意力機制的歷史記錄,也必然是很稀疏的。當然,稀疏性的程度可能因特定的下游任務而異。
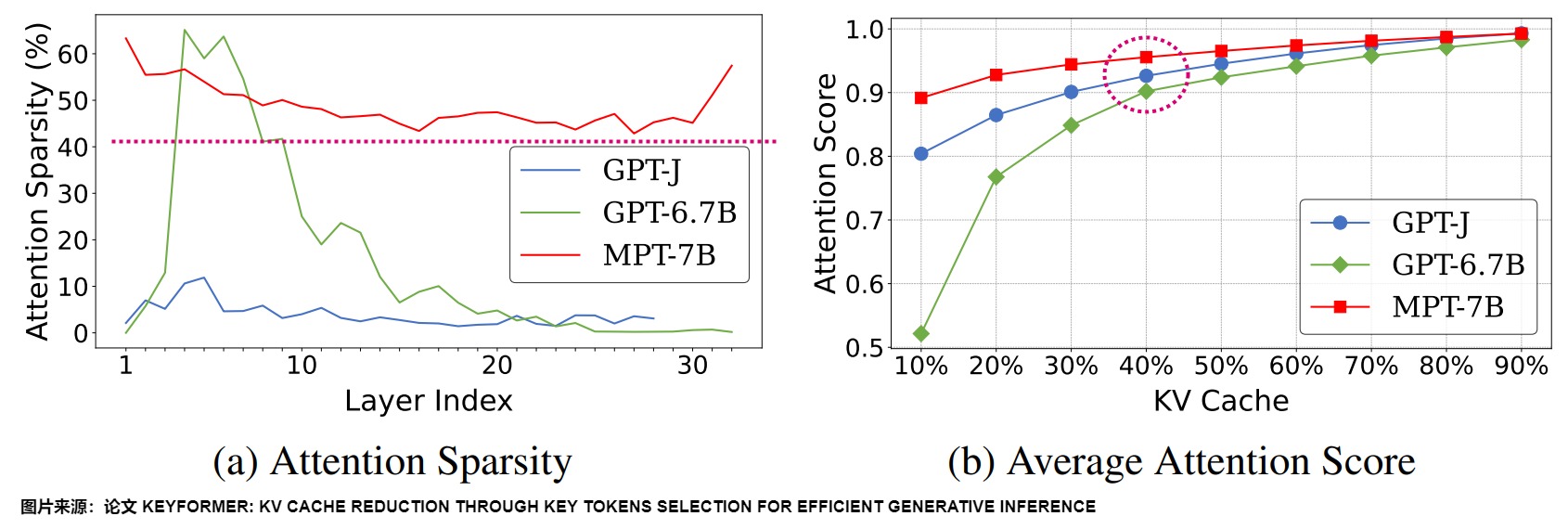
下圖(a) 展示了在使用CNN/DailyMail數據集進行摘要任務時,不同模型之間注意力稀疏性的多樣化水平。這種變化在模型的各個層面都有體現,包括整個模型、單個層以及模型的特定部分。在(b)中,累積分布函數(CDF)描繪了注意力分數與總上下文占比之間的關系。可以看出來,即使KV緩存大小減少了50%,關鍵token的平均累積注意力得分仍然保持在一個相當高的水平,大約在90%到95%之間。進而也可以產生同樣的token。
論文“H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models”的作者也發現,KV Cache其實是很稀疏的,只要5%就可以達到相同效果,即產生同樣的token。
因此,我們可以在內存消耗和模型準確性之間做一定的妥協和權衡。
1.2 重要性
導致稀疏性的一個原因可能是因為token的重要性不同。
LLM 最核心的模塊是 Attention:通過 Q 、 K 兩個矩陣進行矩陣乘,計算 O ( N 2 ) O(N^2) O(N2)大小的注意力得分矩陣,并使用注意力得分矩陣對 V 矩陣求加權平均值,得到注意力層的輸出矩陣。其中注意力得分矩陣每一行表示 Q 中每個 Token 和 K 中每個 Token 的相關性得分,注意力層輸出矩陣的每一行表示每個 Token 與其他 Token 的加權平均值。即然是加權平均,就說明每個 Token 的重要性并不相同,有的 Token 權重更大,而有的 Token 權重更小。
實際上,在文本生成過程中,只有一小部分 Token 獲得了最多的注意力。這強調了特定關鍵token的重要性以及它們在理解上下文和促進文本生成中的核心作用。為了發現這些token,不同研究人員做了不同的工作。
- 有些工作已經顯示了對初始token的偏向性。這種偏向性源于在解碼迭代過程中累積的注意力分數傾向于初始token的累積效應。即無論它們與語言建模任務的相關性如何,初始tokens都被分配了驚人的大量注意力得分(很大的原因并非是 token 決定的,而是其起始位置決定的),人們將tokens稱為“attention sinks”。當文本長度超過額定長度時,頭部的 token 就會被遺棄掉,這就會在 softmax 階段產生很大的問題,進而影響后續的推理結果。
- 也有一些工作發現稀疏的KV緩存可以有強時間局部性。稀疏性分布滿足冪律分布,少部分固定的token一直主導著decoding。即在計算attention score時,只有一小部分token對模型的價值貢獻最大,而且這些token在整段生成中都是重要的。人們稱這些token為“Heavy-Hitters”(H2)。比如,論文“Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time”發現,單個 token 的注意力分數呈現強冪律分布,這意味著某些 token 對 Attention 機制的重要性遠高于其他 token。作者據此提出了“重要性的持久性”(Persistence of Importance)假設:在生成過程中,只有具有顯著重要性的 token 會對后續生成步驟產生持續影響。論文進一步指出,大多數 Transformer 層之間的注意力模式高度相似,重疊比率超過 90%。因此,通過識別“高權重分數 token”,可以有效減少 KV Cache 的內存占用。此外,還可通過預先分配 KV Cache 的空間,僅存儲必要的 token,從而將計算復雜度簡化為常數級別。
當然,也有另一種可能是:因為模型經過訓練,不需要關注整個序列(例如,Mistral AI的Mistral-7B),因此會對某些token不再進行關注或者很少關注。
1.3 小結
我們已經知道,注意力模塊傾向于不成比例地持續將更多注意力集中在序列中的少數幾個詞元上。那么我們就可以不去存儲模型幾乎不關注或很少關注的詞元的鍵和值。
通過丟棄 KVCache 中一些權重小的 Token,讓它們不再參與注意力計算,我們將相應的注意力分數設為零,并用一個更稀疏的注意力矩陣來近似注意力矩陣。這樣就可以在保證模型效果的前提下壓縮 KVCache 長度,從而在一定量的顯存下保存更多的 Token,提高長文本的推理效率。另外,不將序列中所有詞元的鍵和值都存儲起來的一個可能的原因是:我們可以在每次迭代中重新計算缺失的鍵和值,即用時間換空間。
因此,壓縮 KVCache 長度的問題就可以轉化為通過算法設計找出一個序列中相關性更高的 Token。
0x02 稀疏化
減少序列長度的主要手段就是稀疏化。KV Cache 稀疏化(KVCache Sparsification)是通過減少不必要的存儲和計算來提高效率的一種優化方法。它的核心思想是選取需要關注的關鍵 token,并丟棄無關的 token,這是一種算法層面的優化,直接降低了計算,以減少 KV Cache 的體積和計算復雜度。
1.1 分類
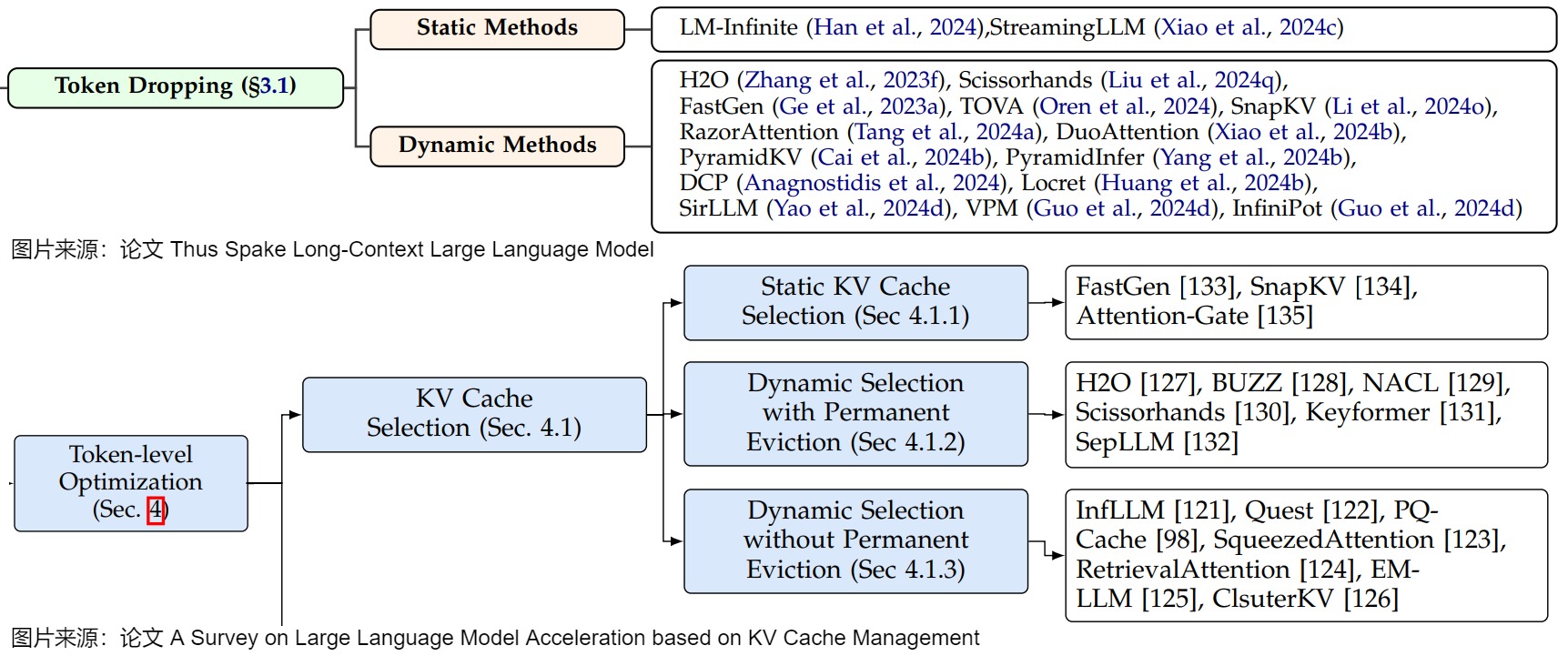
KV Cache 稀疏化的各種方案本質上就是選取需要關注的 token 方法的不同。但由于舍棄了部分 Token 的注意力計算,所以理論上是有損的,可能需要訓練側保證模型效果。稀疏化屬于目前比較主流的KVCache研究方向,不同論文對其的具體分類也不盡相同。兩篇綜述論文將稀疏化稱為Token Dropping和KV Cache Selection。下圖就是兩篇綜述中對稀疏化的不同稱呼和細分。
- Token丟棄是一種識別不重要token并將其丟棄的技術。然而,這些方法的關鍵挑戰在于如何確定哪些token是不重要的。
- KV Cache選擇機制旨在降低KV緩存的內存利用率,最大限度地減少推理延遲,并提高大型語言模型的整體吞吐量。KV Cache選擇機制以運行過程進行分類:靜態KV Cache選擇機制僅在預填充階段執行token過濾,所選token在后續解碼步驟中保持不變;動態KV Cache選擇機制在解碼階段不斷更新KV緩存,實現自適應緩存管理。
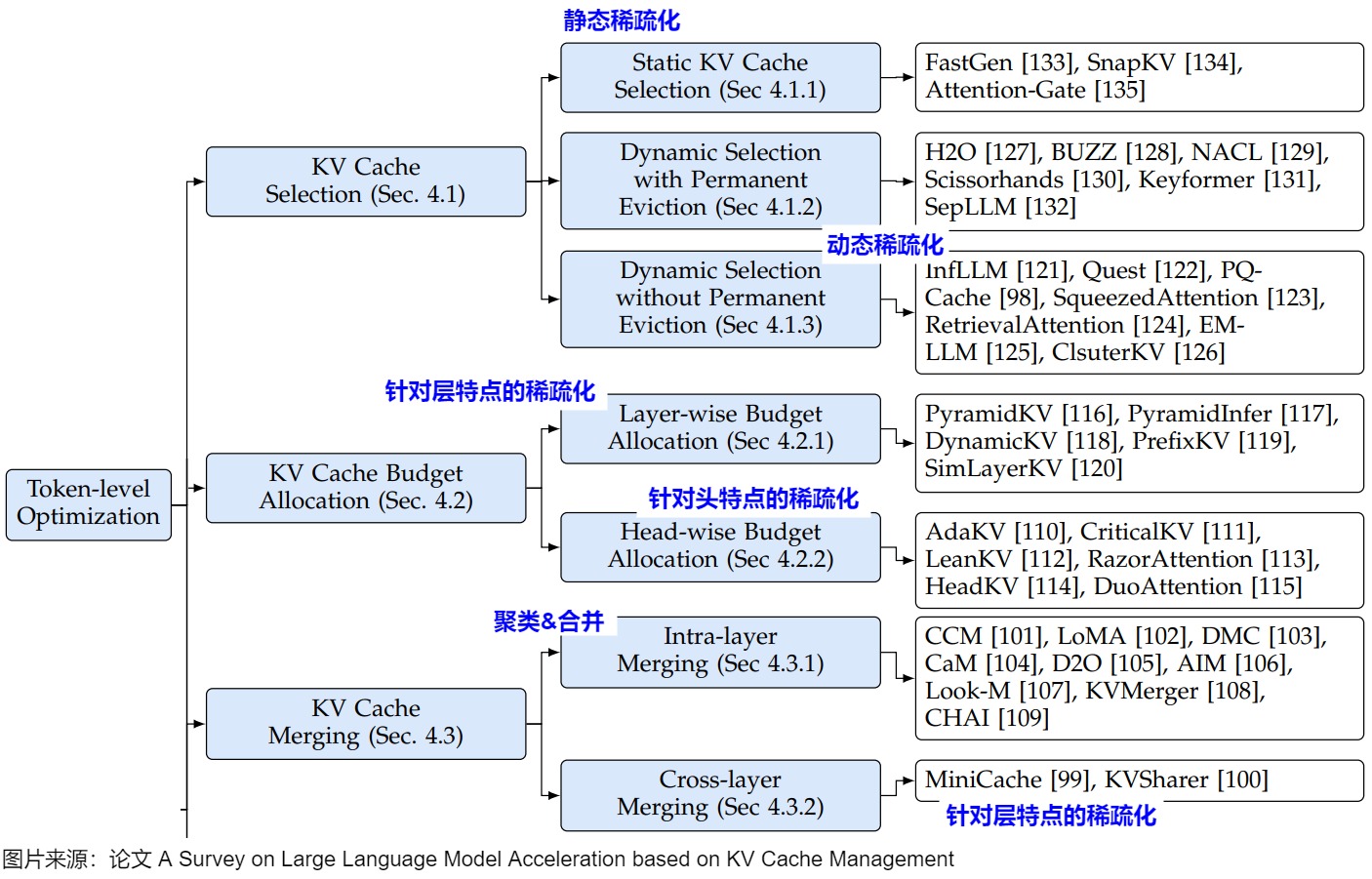
本文對稀疏化主要分為以下:
- 靜態稀疏化。在計算預測下一個 Token 時,只維護一個窗口大小的歷史 Token 信息。然后通過調整注意力窗口來調整序列長度。靜態稀疏化的窗口內的 Token 是固定的。
- 動態稀疏化。通過調整注意力窗口來調整序列長度。動態稀疏化窗口內的 Token 是不固定的。
- 針對prefill階段的稀疏化。主要是優化prompt的序列長度,取出其中重要的token。
- 針對層特點的稀疏化。LLM模型的注意力層有自己的特點,這也影響了KV Cache稀疏化策略。因此,在KV Cache管理中,即需要依據注意力權重的貢獻進行區分處理或者累積處理,也需要動態調整每層參與注意力計算的鍵token數量。
- 其它方案。比如結合投機采樣進行的稀疏化;針對頭特點的稀疏化等。
我們也用論文”A Survey on Large Language Model Acceleration based on KV Cache Management“來進行比對學習。該論文中與稀疏化對應的部分是KV Cache Selection、KV Cache Budget Allocation和KV Cache Merging。因為與筆者的分類方式不是正交的,所以我們在圖上做出標注。
我們接下來通過案例進行學習。
1.2 靜態稀疏化
靜態稀疏化可以通過注意力機制來實現,即稀疏注意力機制或者線性注意力。稀疏注意力機制的核心思想就是在推理中選擇合適的 Token 來進行相應的計算,這種方案在序列比較長時尤其有幫助,可以大幅降低 Attention 部分的 KV Cache 大小和計算量。線性注意力機制(如Linear Transformer、RWKV和Mamba等)通過將標準注意力機制替換為與序列長度線性相關的機制來減少內存需求。然而,這種方法可能會降低模型的表達能力,導致在需要復雜、長距離詞元依賴關系的任務中性能下降。
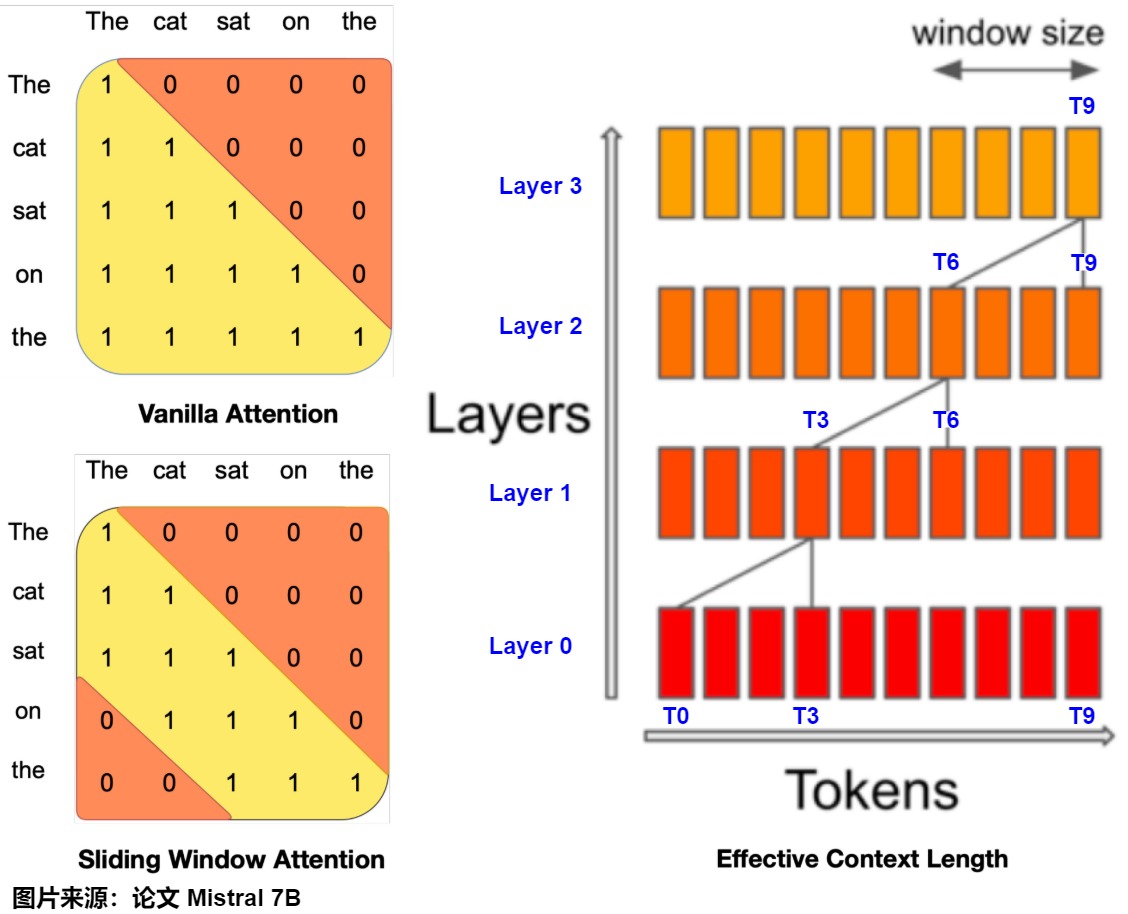
比如,Mistral-7B使用被稱為滑動窗口注意力(SWA)或局部注意力的注意力機制變體。局部注意力保證我們不需要關注整個序列,只通過關注最后(4096個)相鄰的詞元來構建詞元表示,這樣在KV緩存中永遠不會存儲超過窗口大小(例如4096)的張量對。再比如,
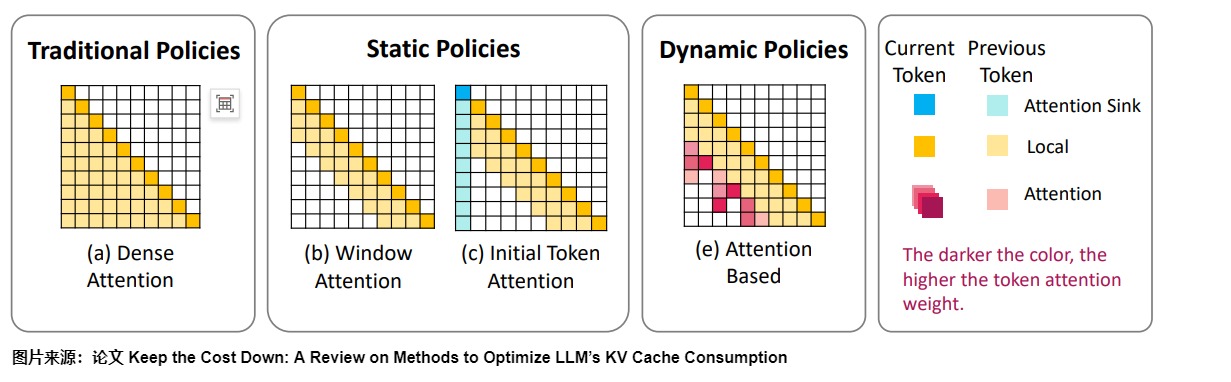
論文"Efficient Streaming Language Models with Attention Sinks"中分析了四種 Attention 實現,具體如下圖所示。其中T 為待預測的第 T 個 Token,L 表示 pretrain 時的最大序列長度(一般為 2k、4k 等),由于主要針對的是長序列場景,因此 T 遠大于 L。

第一種是原始注意力實現,后三種是稀疏化實現,這些稀疏化方法都是靜態的,即 Token 之間的相關性是一種固定的范式,每個 Token 的相關的 Token 都是固定距離的。
- Dense Attention是vanilla Attention 實現。每個 Token 都能看到該 Token 及之前的 Token,其計算復雜度為 O ( T 2 ) O(T^2) O(T2),KVCache 存儲復雜度為 O ( T ) O(T) O(T)。由于復雜度比較高,T 在預訓練的時候會比較小。在推理的時候,當文本長度超過了預訓練時的長度,模型效果就會大幅降級,所以表現出來的 PPL 值也比較大。
- 窗口注意力(Window Attention)緩存最近的 n 個tokens的KV。這種方法相當于只在最近的tokens的KV狀態上維護一個固定大小的滑動窗口。其中灰色的虛線框表示超過窗口長度后從 cache 中淘汰的 Token。計算復雜度為 O(T*L),計算復雜度低,cache 比較小,在推理中效率高。但是模型效果很差(PPL 很大),因為雖然但一旦開始tokens的鍵和值被刪除,性能就會急劇下降。
- 帶重計算的滑動窗口(Sliding Window with Re-computation)。 這種 Attention 與 Window Attention 類似,區別是 Sliding Window 不緩存窗口的 Tokens,而是為每個新token重建來自 L L L個最近tokens的 K V KV KV狀態。這種方案的模型效果對比Window Attention 高,PPL 值遠低于 Window Attention。主要原因是重計算把窗口中的 Tokens 作為初始 Tokens,這樣既保留初始 Tokens 又保證計算只在一個窗口內,大大降低了KVCache 存儲復雜度。由于重計算的存在,其精度可以保證,但是性能損失比較大。雖然它在長文本上表現良好,但由于在上下文重計算中的二次注意力,其的$O(TL^2 ) $ 復雜度使其相當緩慢,使得這種方法不適用于實際的流式應用。
- StreamingLLM 保留了用于穩定注意力計算的attention sink(幾個初始tokens),并結合了最近的tokens。它高效并且在擴展文本上提供穩定的性能。黃色的框表示初始的幾個 Token,也就是 Attention Sink,其計算復雜度為 O(T*L),模型精度很不錯,和帶重計算的滑動窗口 Attention 相當。
我們接下來分析窗口注意力和StreamingLLM。
1.2.1 Window Attention
Window Attention采用滑動窗口機制來解決長文本推理挑戰,其中落在窗口外的token被永久驅逐并變得無法訪問。
在原始注意力中,每一個token,都要和它之前所有的token做Attention。而通過我們平時語言習慣中可以知道,一段話中每個字之間的相關性差別很大。對于當前token,一般來說越相近的字相關性越強,距離越遠的token,能提供的信息量往往越低,因此似乎沒有必要浪費資源和這些遠距離的token做Attention。因此,滑動窗口(Sliding Window Attention)機制就是:每一個token只和包含其本身在內的前 L(L 表示窗口長度)個token做Attention,即只和當前token距離相近的token做注意力計算。這樣就可以把cache的容控制在 L 內。因為每個 Token 只和鄰近的 Token 做 Attention 計算,所以計算復雜度為 O(TL) ,KVCache 存儲復雜度為O(L)。這種方法極大的降低了 KVCache 的存儲開銷,從線性復雜度降低到常數復雜度。
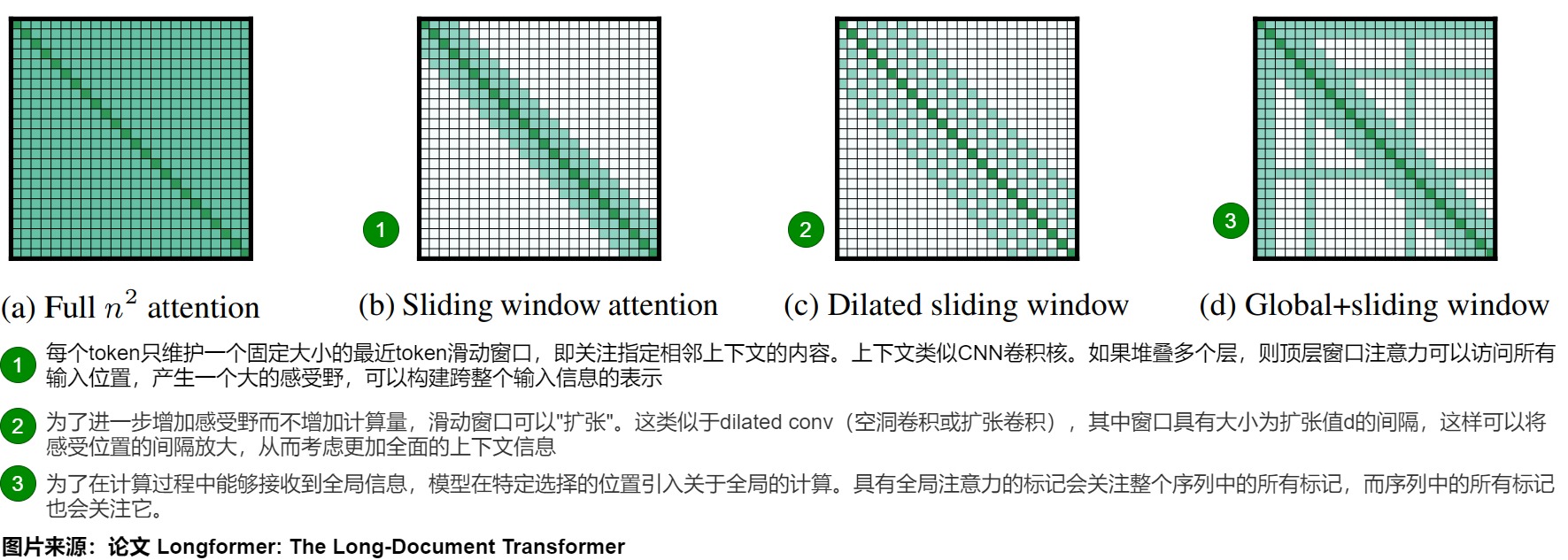
典型代表即 Longformer,具體如下圖所示。
-
(a)展示了傳統的“全注意力”機制,其中每個新生成的token都會關注序列中所有先前的token。
-
(b)描述了“滑動窗口注意力”。該方法維護一個固定大小的最近token滑動窗口,給定固定的窗口大小w,每個token都會關注其兩側 1 2 w \frac{1}{2}w 21?w個token。滑動窗口允許我們擁有一個固定大小的緩存。一旦序列增長超出滑動窗口token數,我們可以在緩存中循環并開始覆蓋。由于w可以設置的比較小,所以可以和輸入序列長度n呈線性關系,其計算復雜性為 O ( n × w ) O(n×w) O(n×w),更加適合淺層捕獲局部信息。而且,因為緩存中的位置無關緊要,所有與位置相關的信息都通過位置嵌入編碼,所以很容易實現并且效果很好。然而,這種方法限制了模型從過去捕獲全面語義信息的能力,導致文本生成質量較低且準確性下降。
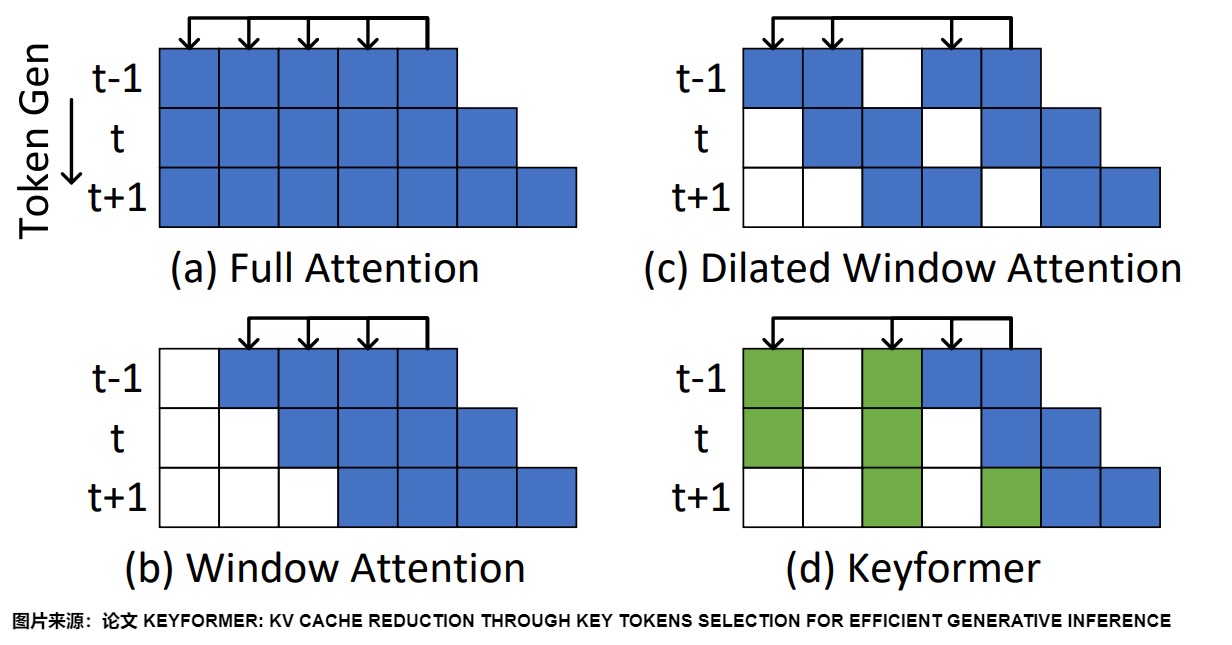
人們可能會疑惑,雖然距離越遠的token涵蓋的信息量可能越少,但不意味著它們對當前token一點用處都沒有,在滑動窗口中直接杜絕了它們的參與,這真的合理嗎?其實,Silding Window Attention并非完全不利用窗口外的token信息,而是隨著模型層數的增加,間接性地利用起窗口外的tokens。這里可以類比為CNN技術中的感受野。如果堆疊多個層,從layer0開始,每往上走一層,對應token的感受野就往前拓寬W,雖然在每一層它“最遠”只能看到前置序列中部分token,但是只要模型夠深,它一定能夠在某一層看到所有的前置tokens。該層窗口注意力可以訪問所有輸入位置,產生一個大的感受野,可以構建跨整個輸入信息的表示。在具有l層的Transformer中,頂層的感受野大小為 l × w l \times w l×w(假設對于所有層w是固定的)。根據應用程序的不同,可能為每個層使用不同的w 值更好,以在效率和模型表示能力之間取得平衡。具體如下圖所示。
-
?展示了一種稱為“膨脹窗口注意力”的變體,其準確性與窗口注意力類似,也存在類似的限制。其特點如下。
- 為了進一步增加感受野而不增加計算量,滑動窗口可以"擴張"。這類似于dilated conv(空洞卷積或擴張卷積),其中窗口具有大小為擴張值d的間隔,這樣可以將感受位置的間隔放大,讓token在當前位置適當捕捉到得更遠處的信息,關注更大的視野,考慮了更加全面的上下文信息。由于考慮了更加全面的上下文信息,空洞滑窗機制比普通的滑窗機制表現更佳。
- 每個位置的Q關注的K還是W個,但是W個不是連續的而是跳躍的。定義跳躍的間隔是d, 那么Q關注的K的范圍就是w * d。計算方面依然保持滑動窗口在計算性能方面的優點。
- 假設對于所有層都是固定的d和w,那么感受野大小為 l × d × w l × d × w l×d×w,即使對于較小的d值,也可以觸及成千上萬個token。在多頭注意力中,每個注意力頭計算不同的注意力分數。每個頭部具有不同的擴張配置的設置可以通過允許一些沒有擴張的頭部關注局部上下文,而其他具有擴張的頭部專注于更長的上下文,從而提高性能。
-
(d)是Global+sliding window(融合全局信息的滑窗機制),滑動窗口和擴張注意力不足以學習特定任務的表示,需要從其它方面借鑒。因此引入了全局注意力對這兩者進行補充。其特點如下:
- 全局注意力就和普通的transformer是一樣的,都是關注全部的K。依據具體任務的不同,在特定選擇的位置引入關于全局的計算,使得模型在計算過程中能夠接收到全局的信息。
- 具有全局注意力的token會關注整個序列中的所有token,而序列中的所有token也會關注它。由于這些token的數量相對較小且獨立于n,因此結合局部和全局注意力的復雜度仍然為O(n)。雖然指定全局注意力是與任務相關的,但這是一種向模型的注意力添加歸納偏差的簡單方式,比起使用復雜架構將信息跨越較小的輸入塊組合的現有任務特定方法要簡單得多。
1.2.2 StreamingLLM
StreamingLLM 利用“注意力沉積”效應,用早期Token 的KV結合近期上下文來優化長序列處理,實現了對無限長度輸入的支持,同時生成無限長度的輸出。
StreamingLLM 來自論文《Efficient Streaming Language Models with Attention Sinks》,其目標是讓模型能夠處理無限長度的輸入(這里的“無限長度輸入”與“無限長度上下文”有所不同——前者無需記住所有輸入內容)。
Window Attention方案雖然壓縮了KVCache的長度被壓縮,但是模型效果卻不好,主要原因是最初始的 Token 被丟棄了。這種 Token 的重要性其實非常高,丟棄會嚴重影響模型效果,精度下降比較大。而StreamingLLM恰恰彌補了這個缺憾。StreamingLLM發現注意力中的一個關鍵現象,即初始序列token中保留的鍵值對保持了關鍵的模型性能。這種注意力下沉效應通過早期位置的不對稱注意力權重積累來體現,而與語義意義無關。該方法利用了這一特性,將注意力匯位置與最近的上下文相結合,以實現高效處理。
StreamingLLM策略在 Window Attention 的基礎上,通過僅保留最初的位置詞元(sink tokens)和最后相鄰的詞元(局部注意力)來構建了一個滑動窗口緩存。因此,StreamingLLM KV Cache 的長度是固定的,既有固定部分(通常1到4個 token ),也有滑動部分。這樣既保留 Window Attention的特性,使得 KVCache 存儲復雜度為O(L),計算復雜度為 O(TL) ,同時又保證了模型效果不因丟失初始 Tokens 而大幅下降,PPL 和 Sliding Window Attention with recomputation 相似。
Attention sink
StreamingLLM作者發現,window attention只要加上開頭的幾個token比如就4個,再操作一下位置編碼,模型輸出的PPL就不會變好,輸出到20k長度都很平穩。論文將這種現象叫做Attention Sink(注意力池)。就好像文本的注意力被“沉溺”到了開頭的位置。即初始詞元聚集了大量注意力。而且intial tokens與生成token的絕對距離距離和語義信息都不重要,重要的是intial tokens是第一個或者前面幾個token,就是這些token作為錨點,所以其權重特別大。
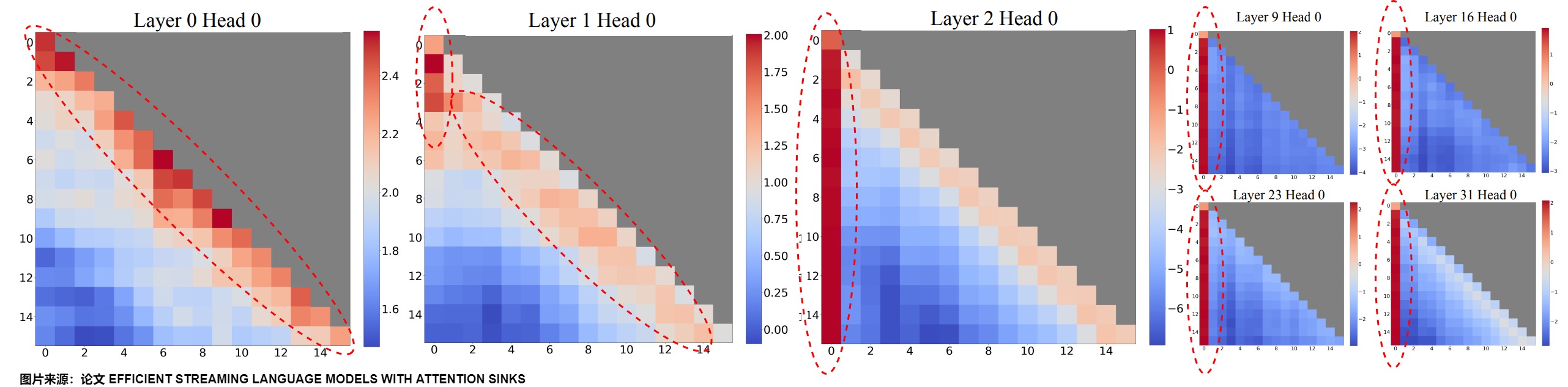
上圖給出了lama-2-7B中256個句子的平均注意力邏輯的可視化,每個句子的長度為16。觀察結果包括:
- 前兩層(第0層和第1層)的注意力圖呈現出“局部”模式,最近的token受到了更多的關注。
- 除了前兩層之外,之后的注意力主要集中在first token。
如果刪除這些初始token的KV,將導致注意力計算中SoftMax函數的相當一部分分母也被刪除。這種變化導致注意力得分的分布發生了顯著變化,偏離了正常推理環境中的預期。
為何會出現這種現象?Evan Miller 在“Attention Is Off By One” 做了精彩的解讀。
The problem with using softmax is that it forces each attention head to make an annotation, even if it has no information to add to the output vector. Using softmax to choose among discrete alternatives is great; using it for optional annotation (i.e. as input into addition) is, like, not cool, man. The problem here is exacerbated with multi-head attention, as a specialized head is more likely to want to “pass” than a general-purpose one. These attention heads are needlessly noisy, a deafening democracy where abstention is disallowed.
在Attention機制中,Softmax的輸出代表了key/query的匹配程度的概率,如果softmax在某個位置的值非常大,那么在反向傳播時,這個位置的權重就會被大幅度地更新。然而,有時候attention機制并不能確定哪個位置更值得關注,但是Softmax又需要所有位置的值的總和為1,因此模型必須“表態”給某些位置較大的權重,因此,模型傾向于將不必要的注意力值轉嫁給特定的token,這些token就是initial tokens。
因此,Evan Miller改進了一下Softmax,提出了“SoftMax-off-by-One”:把softmax的分母加了個1,這樣所有位置值可以加和不為1,Attention就有了可以不對任何位置“表態”的權利。
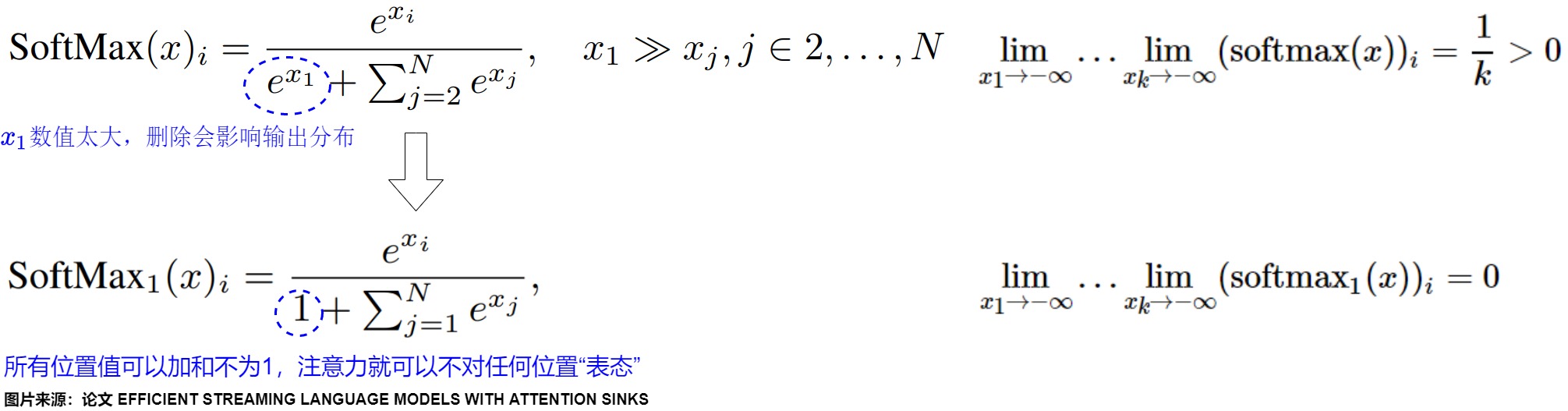
思路
根據attention sinks特性,論文作者參考之前多輪對話場景的解決方法,給出StreamingLLM的解決方案,即在window attention基礎上,新引入了initial tokens的KV。
- 錨點加窗口。StreamingLLM中的KV cache可以分為兩部分,既有一個固定部分(通常為1到4個詞元),又有一個滑動部分。
- 固定部分。保留整個序列的初始 Tokens(attention sink部分),圖中畫的是4個initial tokens;其作用是識別并保存模型固有的attention sink,錨定其推理的初始token來進行注意力計算并穩定模型性能。
- 滑動部分。滑動窗口的KV(Rolling KV部分)cache,保留了最近的3個tokens,窗口值固定為3。其目的是:想讓大模型無限輸出,達到“Streaming”效果:不用KV cache會計算太慢,但是用了KV cache,顯存占用隨長度增長太多。因此需要丟棄一些KV cache。
- 計算。每個 token 只和窗口內的 Tokens 以及序列的初始 Tokens 進行 Attention 計算。而且訓練期間,用“SoftMax-off-by-One”替代常規softmax,解決attention sink問題。
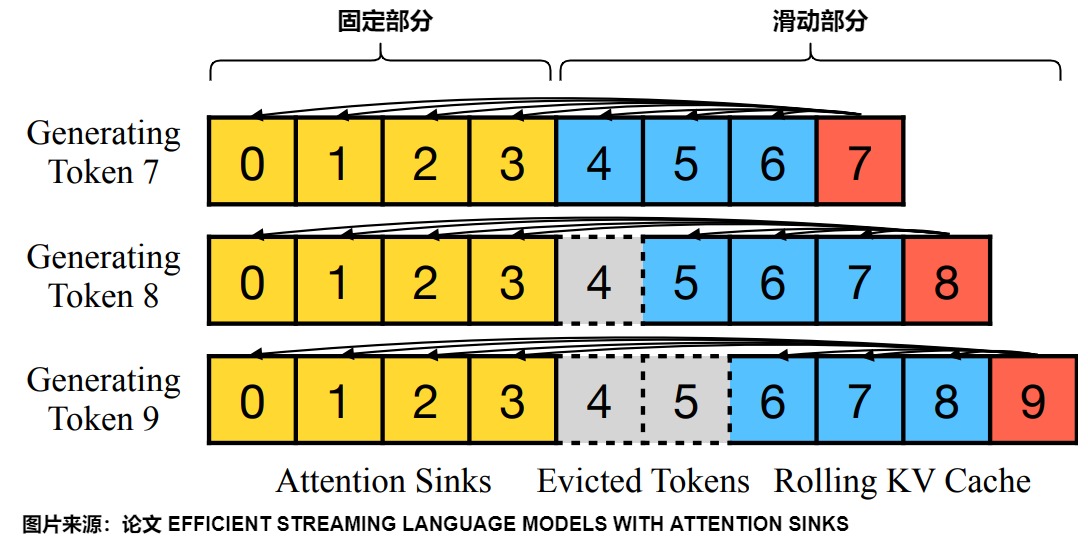
在實現中,會用“Rolling Buffer Cache"技術來丟棄KV cache中的某些行,同時也會控制位置編碼。下圖給出了Rolling Buffer Cache的運作流程,當我們使用滑動窗口后,KV Cache就不需要保存所有tokens的KV信息了,你可以將其視為一個固定容量(W)的cache,隨著token index增加,我們來“滾動更新” KV Cache。

問題
StreamingLLM雖然記住了Attention sink以及最近的窗口里面的token對應的KV cache,然而僅僅在注意力機制中依賴這k個token并不能提供必要的準確性。因為目前是按照位置把中間的token都丟掉了,萬一中間的token就是重要的怎么辦。這就是靜態 Token 稀疏化的問題:Token 候選集過于固定。這種 Token 候選集的設計源于作者通過觀察某些數據集中 Token 之間的相關性發現的規律。這種規律不能保證具備普適性,會導致關鍵token注意力中近期上下文的丟失和窗口注意力中關鍵上下文的缺失,會損害模型在長序列任務上的性能。
1.3 動態稀疏化
動態 Token 稀疏化本質是為當前處理 Token 維護一個相關性高的歷史 Token 集合,但與靜態 Token 稀疏化不同,這個集合的構造不再由 Token 距離或者固定 Token 決定,而是設計一種算法去篩選歷史的 Token。靜態 Token 稀疏化是動態 Token 稀疏化的子集,所以理論上動態 Token 稀疏化的效果會比靜態 Token 稀疏化更好。
然而,在推理過程中,尤其是當輸入序列包含未知或未見過的token時,動態確定哪些token作為關鍵token是一個相當大的挑戰,針對這挑戰主要有兩種方法:
- 評分函數。利用評分函數識別關鍵token。比如我們為每個token引入了一個評分函數fθ,以從總共n個token中識別出k個關鍵token。
- 驅逐策略。保留系統認為重要的KV,舍棄那些不重要的。其中重要性的判斷非常重要,大部分的系統都是對于每一層按照attention score的大小,保留top-B的結果。
其實這兩者是一枚硬幣的兩面:通過動態的評價策略來判斷需要保留和廢棄的KV值,通過運行時鍵/值驅逐來減少KV緩存大小。
需要注意的是,大部分工作都假設了注意力模式在不同迭代之間的持久性,即,如果某個token在當前迭代中被認為是不重要的(即具有較低的注意力權重),那么在生成未來token時,它也很可能保持不重要。基于這一假設,當KV緩存大小超過其預算時,他們會在每次迭代中從KV緩存中驅逐具有低注意力權重的token。被驅逐token的鍵和值在從內存中刪除后,將永久排除在后續迭代之外。
我們通過幾個案例來學習下。
1.3.1 H2O
論文”H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models“提出的H2O是比較經典的方案。H2O觀察到,注意力計算主要由一組被稱為重拳(“pivotal tokens”或“heavy hitters”)的高影響力token來驅動。因此,H2O將緩存優化重新表述為動態子模型問題,利用累積注意力得分來指導token保留決策。
動機
稀疏的KV緩存并不一定具有100%的時間局部性。比如,LLM在decode第6個token時不一定需要第1至第5個token,而是有可能需要其中的任意數量的token。想象一種最極端的情況,decode第6個token時,需要第1、2、4個token,decode第7個token時需要第3、5、6個token。因為在同一時刻雖然不會使用所有token,但是每個token都有可能在任意時刻被使用,所以這種情況下必須在內存中保存所有歷史token的KV緩存。論文將這類情況稱為Dynamic Sparsity,見下圖左一。
一種直觀的想法是,也許稀疏的KV緩存可以有類似密集KV緩存那樣的強時間局部性:在兩個decoding步驟之間僅有一小部分KV緩存不同,并且在某個decoding步驟被稀疏掉的token永遠不會在接下來再被使用,這樣就實現了與密集KV緩存類似的時間局部性同時減少了KV緩存內存占用。論文將這類情況稱為本地稀疏(Static Sparsity (Local))和等步長稀疏(Static Sparsity (Strided)),見下圖左二左三。
H2O認為,本地稀疏、等步長稀疏等強時間局部性的稀疏都太na?ve了,光看最近的K個元素或者等步長最近的K個元素無法代表所有的歷史信息。在滿足強時間局部性的稀疏策略中,應該存在更優的策略。H2O利用累積的token重要性在decoding過程中找到了這一策略,見圖左四。

H2O作者認為,最為理想的drop token方式是:預知未來的token對當前token的注意力分數,然后drop掉那些分數低的token。因為未來的token還不知道呢,所以只能預測。
因為attention分數比較大的token對計算結果的影響比較大,所以作者拿前面的attention分數相加的結果來預測之后的attention分數。作者在論文后續附錄中證明了在submodular情形下,H2O假設的貪心地構造KV緩存的策略是near-optimal的。即隨著規模的增長存在邊際效應。因此,H2O的設計問題已經收斂到了一個很小的問題:dynamic submodular problem(動態次模問題)。即如何設計貪心算法,滿足每次驅逐的token都是submodular最優的。即每次丟掉的token對生成的影響最小。
方案
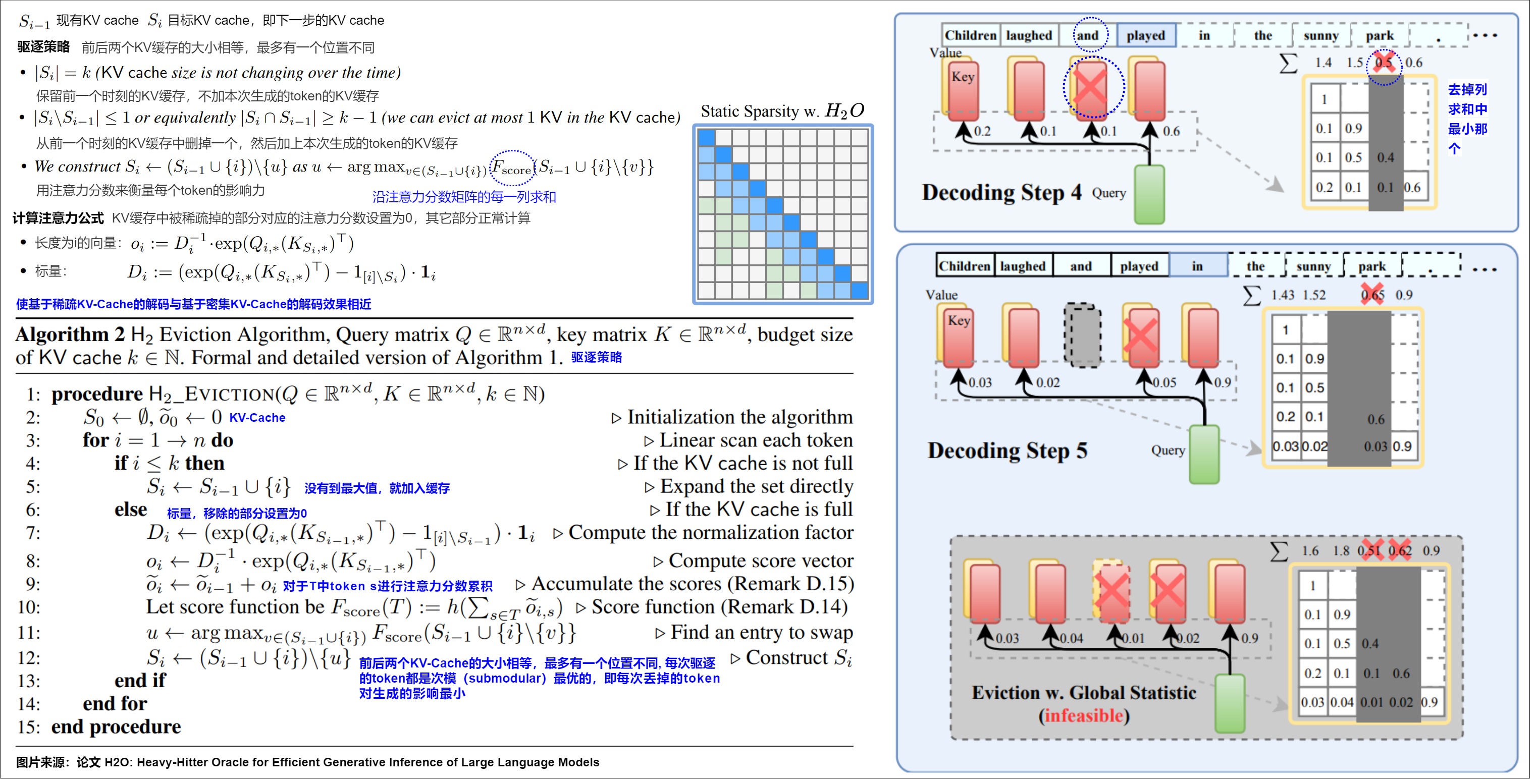
H2O的設計目標就是確定一個KV緩存維護/驅逐策略。H2O設置最大緩存 token 數量(預算),每次達到緩存預算時,該策略可以通過貪心法去計算token的打分,每次丟棄累積注意力分數最低的 token ,因此只保留在迭代中始終實現高注意力分數的 token。這樣使基于稀疏KV緩存的decoding效果與基于密集KV緩存的decoding效果相近。
H2O作者作者發現:在給定步驟中具有影響力的詞元(“pivotal tokens”或“heavy hitters”)在未來步驟中仍然具有影響力。換句話說,我們可以確信被丟棄的低影響力詞元在未來生成步驟中仍然可以相對被忽略,因此可以安全丟棄。基于此觀察,作者提出了一種名為“Heavy-Hitters Oracle”(H2O)的貪心的歷史 Token驅逐策略:對于某個token A ,A以及A之前的token都會對A有注意力,把這些注意力加起來,可以得到A的“重要性分數”。將每個token的重要性分數都計算出來,然后丟棄分數最低的那些token即可。H2O選擇了注意力分數作為評分函數,記作 f θ ( a c c ; a t t n ) f_θ(acc; attn) fθ?(acc;attn)。這樣就可以識別出在提示和token生成階段持續獲得較高注意力分數的token作為最關鍵或關鍵的token。此處其實有提高空間,因為是使用attention score的絕對值來反映token的影響力,求和隱含了“越久的token越重要“的假設,越久的token求和項越多,最終的值有可能越大。
算法具體流程如下圖所示:
-
初始化相關性歷史 Token 集合 ,設置集合最大容量。
-
迭代更新歷史 Token 集合。
- 當歷史 Token 集合大小等于最大容量時,將當前 Token 加入歷史 Token 集合中;
- 當歷史 Token 集合大小大于等于最大容量時,計算當前 Token 和歷史 Token 集合中所有 Token 的相關性得分(實現起來是對于注意力矩陣按列求和再取topk),將最低分的 Token 從集合中剔除,將當前 Token 加入到集合中。即每生成一步會將當前 Token 相關性最低的歷史 Token 永久剔除,被剔除的歷史 Token 將不會參與后續任何一個 Token 的 Attention 計算。用自然語言描述,就是KV緩存中被稀疏掉的部分對應的attention score設置為0,其它部分正常計算。
這樣可以保證前后兩個KV緩存的大小相等,最多有一個位置不同。即:要么從前一個時刻的KV緩存中刪掉一個,然后加上本次生成的token的KV緩存;要么保留前一個時刻的KV緩存,不加本次生成的token的KV緩存。這樣的KV緩存始終滿足強時間局部性。
圖上的反斜杠"\"是一種集合運算符號:相對差集。”U \ A“表示在集合U中,但不在集合A中的所有元素,比如相對差集{1,2,3} \ {2,3,4} 為{1} ,而相對差集{2,3,4} \ {1,2,3} 為{4} 。
與H2O類似的方案是Scissorhands。H2O算法一次僅丟棄一個詞元,而Scissorhands則根據目標壓縮比例(例如,減少30%的KV緩存)丟棄盡可能多的詞元。Scissorhands簡單地保留最近的詞元和在歷史窗口內具有最高注意力分數的詞元。而H2O則丟棄累計注意力分數最低的詞元,只保留那些在迭代過程中始終具有高注意力分數的詞元。
優化點
現有通過驅逐token來減少KV Cache大小的研究本質上存在一些挑戰。類似H2O的方法假設注意力模式在不同迭代之間不會改變,換句話說,H2O其實是用上一層KV緩存的稀疏性來指導下一層的KV緩存的稀疏性。但實際上情況并非如此,因為注意力模式在迭代之間具有動態性,在當前迭代中被認為不重要的token在后續迭代中可能會變得重要。在前面生成過程中被剔除的 Token 可能與當前的 Token 有著較高的相關性,但因為 Token 在前面的生成過程中已經被剔除,導致無法把 Token 召回和當前 Token 完成 Attention 計算。
因此,H2O的評估窗口較窄,導致其在KV緩存預算范圍內表現出較高的效率,但隨著序列長度超出KV緩存預算,它開始難以應對注意力模式的動態性,未能很好捕捉這些動態變化。
另外,H2O方法將保留的鍵/值token數量設置為輸入序列長度的一個固定百分比。在這種情況下,無論生成了多少個token,KV Cache預算始終保持恒定。然而,這種固定KV Cache預算存在一些局限性。每一層所需的鍵/值token數量是不同的,而每個查詢token也需要不同數量的鍵/值token來有效地表示基線模型的注意力模式。此外,即使是相鄰的查詢token,所需的鍵token數量也會發生顯著變化。固定的KV Cache預算忽視了查詢token之間的這種差異性,如果保留的鍵/值token數量不足以準確表示基線模型的注意力權重,會導致KV Cache管理效率低下。因此,需要根據每個查詢token的需求,動態調整所加載和計算的鍵/值token數量,同時考慮不同層和查詢token之間的差異性,以實現更高效的KV Cache管理。
1.3.2 keyformer
在生成推理中,大約90%的注意力權重集中在特定的一小部分token子集上,這些token被稱為“關鍵”token。這些token對于大型語言模型(LLMs)理解上下文至關重要,但可能不在窗口注意力的滑動窗口內。Keyformer引入了一種混合注意力方法,如下圖(d)所示,該方法在生成下一個token時結合了最近的token和前面的關鍵token。此外,Keyformer揭示了token移除會扭曲底層softmax概率分布。考慮到softmax分布在token顯著性評估中的關鍵作用,Keyformer 結合了正則化技術來減輕這些分布擾動。
動機
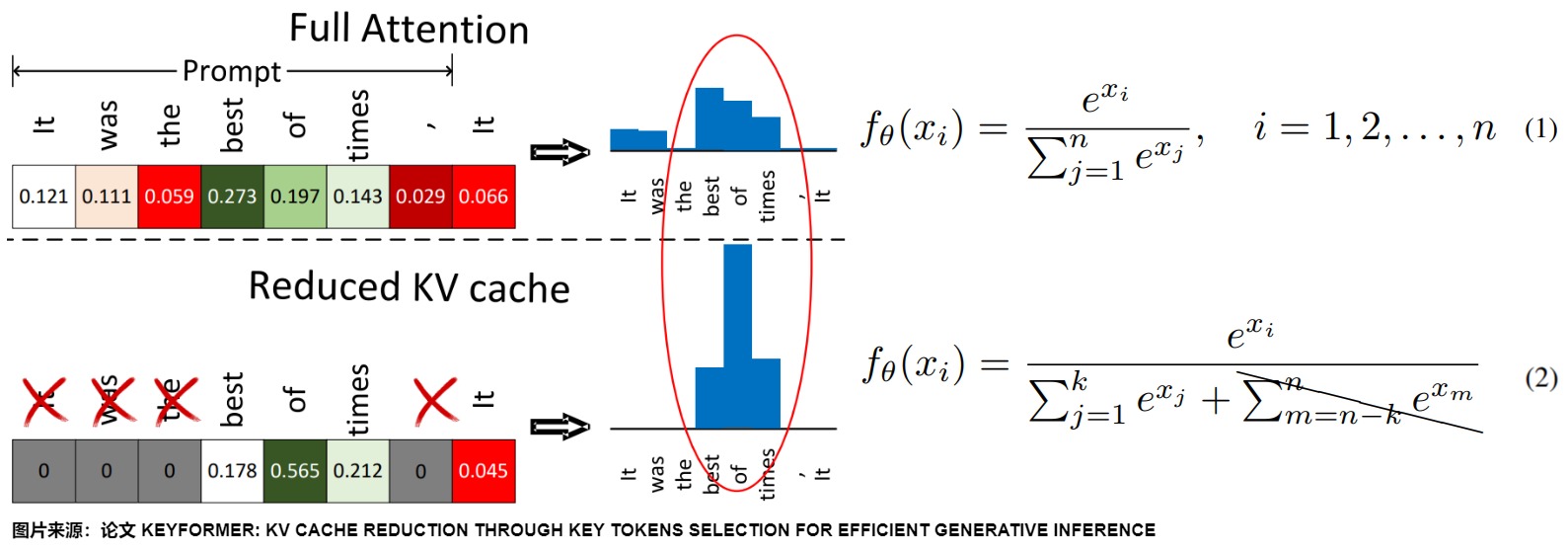
下圖比較了完整注意力下的得分函數分布與KV緩存減少后的分布情況。如方程2所示,當KV緩存減少時,分數較低的token會被丟棄,因為isoftmax函數的性質,這會破壞得分函數的分布,進而導致上下文信息的丟失、準確性的降低以及可能生成的文本質量下降。因此需要增強模型提取近期關鍵token的能力。
方案
評分函數
Keyformer通過對未歸一化的對數幾率(logits)應用正則化來調整由于丟棄tokens而導致的評分函數變化,從而識別關鍵tokens。具體而言,Keyformer提出了一個新穎的評分函數,記作fθ(Keyformer),以解決基于累積注意力的評分函數(fθ(acc attn))的局限性。這個新的評分函數將Gumbel噪聲分布整合到未歸一化的logits中。然而,它在形成基礎概率分布時未能考慮被丟棄的token。為了糾正這一點,Keyformer引入了一個溫度參數,記作τ。
具體剖析如下:
- Keyformer使用對數幾率正則化技術。通過引入額外的分布(ζ)來正則化減少的對數幾率,使模型保持魯棒性和適應性。即使在推理過程中存在未知上下文的情況下,它也能幫助識別關鍵token。Keyformer將這種噪聲添加到從QKT派生的未歸一化對數幾率中。此外,添加的分布類型對最終的概率分布產生顯著影響。對應下圖標號1。在這里,yi是經過調整的對數幾率(logits),xi是未歸一化的對數幾率,ζi是用于正則化的額外分布。
- 計算概率時,用溫度參數 τ 考慮被丟棄的token。“溫度”參數(τ)在調節概率分布的平滑性方面起著關鍵作用。這個參數控制概率中的隨機程度。在token從KV緩存中被移除時,τ 尤為重要,因為它們不能在沒有重新計算其鍵和值的情況下被重新引入。較高的τ值(τ → ∞)產生均勻概率,將所有token賦予相同的分數。相反,較低的τ值(τ → 0)產生更尖銳的分布,根據未歸一化的logits優先考慮特定的token。另外,隨著更多的token被丟棄,我們需要一個更均勻或隨機的概率分布。因此通過逐步增加τ和?τ來系統地增加我們評分函數fθ中的隨機性。
- 選擇的分布受到Gumbel分布的啟發。Gumbel分布特別適合我們的關鍵token識別任務,因為它描述了樣本集中最大值的分布,并且偏向于初始token。這使得它成為長序列中建模關鍵token的理想選擇。標號3展示了應用于未歸一化logits的標準Gumbel概率密度函數(pdf),而標號4顯示了添加Gumbel噪聲后logits的pdf。

算法
盡管當前token的相關性在識別關鍵token方面很重要,但模型在大多數生成的token中應該保持一致的行為。為了基于這種一致的行為來識別關鍵token,Keyformer在提示階段和token生成階段都應用累積評分函數(fθ)。如果沒有累積,token只能依賴于當前token與先前token的相關性。
在提示處理階段,Keyformer計算提示長度 S n S_n Sn?內所有n個token的鍵和值,以預測第一個token。給定KV緩存預算,Keyformer保留一個最近的w個token的窗口,從n-w個token的窗口中丟棄n-k個token,并且基于Keyformer評分函數來識別出k-w個token。關鍵token(k-w)和最近token(w)的組合形成了縮減的KV緩存。
在token生成階段,Keyformer使用縮減的KV緩存進行操作。第一個生成的token僅關注KV緩存中的k個token,如下圖圖中的解碼步驟2所示。最近窗口w向右移動一個token,而評分函數fθ則累積了來自前一個解碼步驟的評分函數。在token生成階段的每個解碼步驟中,模型會從大小為k+1-w的窗口中識別出k-w個關鍵token。因此,最近窗口中添加了一個token并刪除了一個token。
此外,溫度參數τ通過增加?τ來調整評分函數概率分布中移除token的數量。
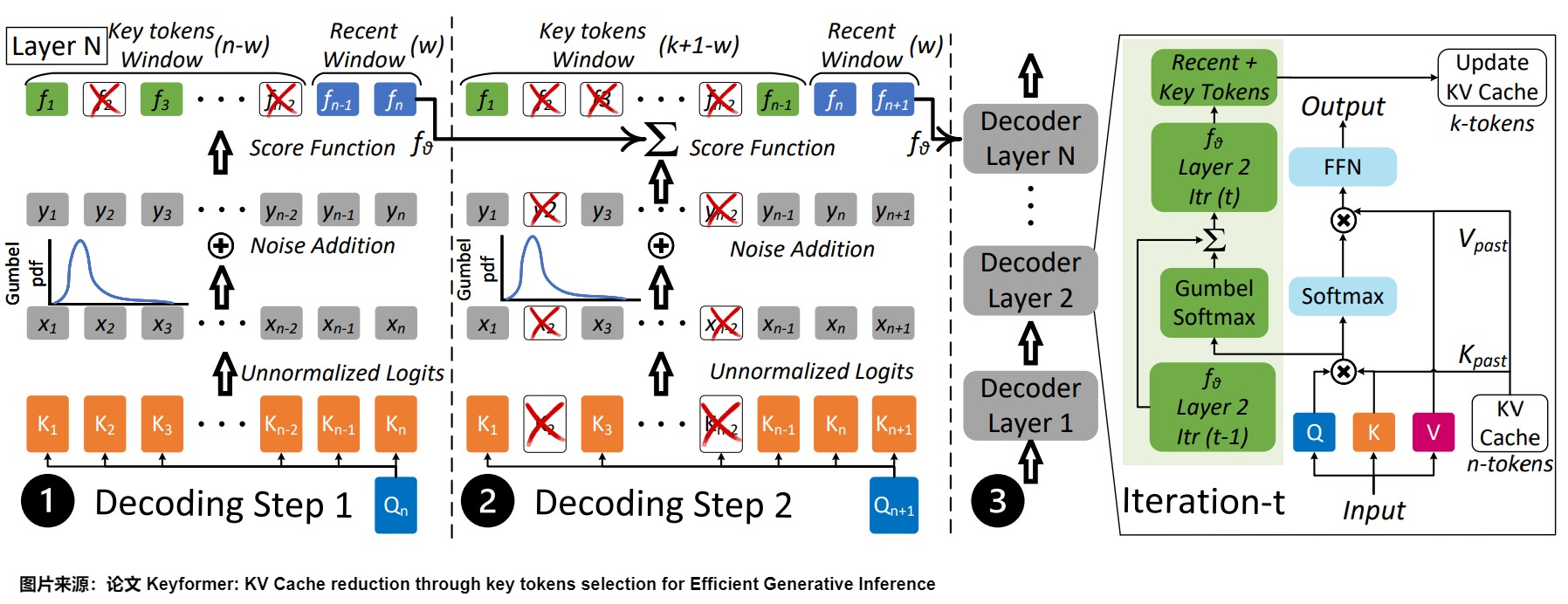
Keyformer的詳細算法參見下圖。

優化點
與H2O類似的技術如下:
-
SubGen是一種為 KV cache開發的高效壓縮技術。經驗證據表明,attention模塊中的關鍵嵌入存在顯著的聚類趨勢。基于這一關鍵見解,SubGen設計了一種具有亞線性復雜度的新穎緩存方法,對關鍵token采用在線聚類并對值進行在線? (2)采樣。
-
LESS(Low-rank Embedding Sidekick with Sparse policy)會學習原始注意力輸出和稀疏策略近似的注意力輸出之間的殘差,通過將稀疏策略丟棄的信息累積到恒定大小的低等級緩存或狀態中來實現此目的,從而允許查詢仍然訪問信息以恢復注意力圖中先前省略的區域。
上述基于永久驅逐的方法面臨兩個重大限制。
- 首先,對token的不可逆驅逐可能會損害模型在長序列任務上的性能,特別是在needle-in-a-haystack場景中,這些方法被證明難以適應多回合對話環境。
- 其次,在解碼階段選擇KV緩存會引入計算開銷,對解碼延遲產生不利影響,并影響端到端加速。
為了應對這些挑戰,幾項研究側重于開發解碼階段KV緩存選擇策略,而無需永久驅逐。比如:
- InfLLM:塊級存儲全KV Cache,GPU保留關鍵Token,次要部分卸載至CPU。
- SqueezedAttention:離線K均值聚類生成語義鍵簇,推理時加載相關鍵。
- SparQ:基于查詢向量顯著元素選擇性檢索緩存鍵的隱藏維度,近似計算注意力。
這些方法通常采用多層緩存系統(例如CPU-GPU分層緩存),并利用先進的數據結構和系統級增強功能來優化檢索效率,從而在減少GPU KV緩存占用的情況下實現高效推理。為了加速關鍵token的檢索,這幾項研究提出了基于索引的方法,以塊或集群粒度組織和訪問KV緩存,采用多級緩存(如CPU-GPU層次存儲)避免永久移除,優化檢索效率,從而實現高效的查詢和提取操作。
1.3.3 小結
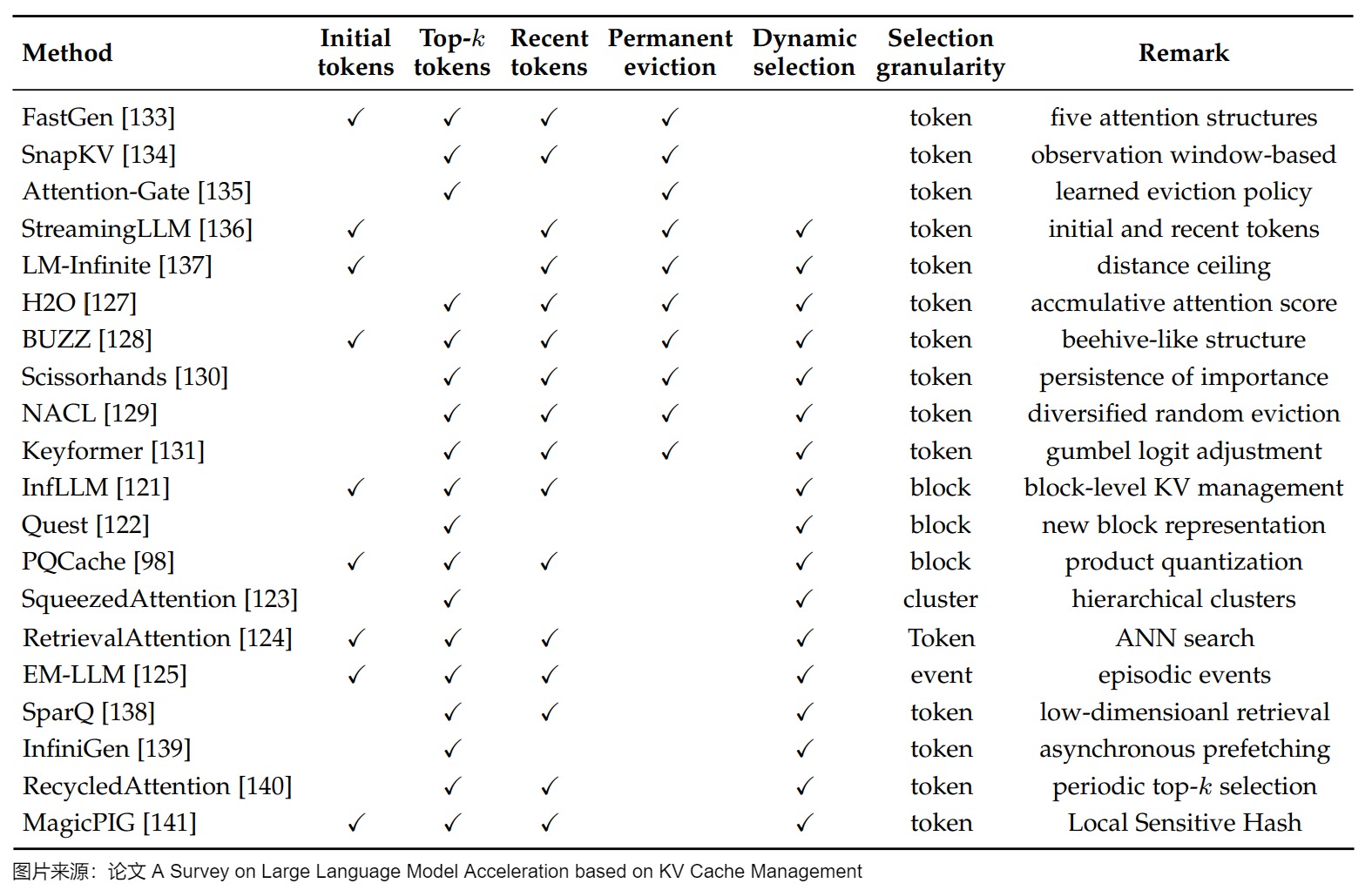
論文“A Survey on Large Language Model Acceleration based on KV Cache Management”給出了靜態稀疏化和動態稀疏化方法的一些總結。
1.3 針對prefill的稀疏化
現有的KV緩存壓縮方法主要關注生成階段的優化,忽略了輸入階段KV緩存的壓縮。而實踐中,大模型應用如對話(特別是RAG)和文檔處理的特點是:輸入很長,而輸出相對較短。輸入可能就已經把顯存撐爆。或者即便顯存還可以,每一步計算也會因為需要交互的token太多而非常慢。因此輸入階段的KV緩存是內存和計算瓶頸所在。比如我們輸入的prompt有16K,那么存儲這16K文本對應的所有KV,無論對于顯存還是計算都有極大的壓力。因此我們可以在prefill階段對KV Cache進行處理,drop一些不重要的token,即壓縮prompt生成的KV。而解碼階段就照常進行,這樣不需要在解碼階段進行額外的計算,又可以加速。
1.3.1 FastGen
FastGen 通過識別五種注意力模式(局部、標點導向、稀疏分布等),再在預填充期間識別重要的token。針對每個token,FastGen 對不同注意力的特點進行針對性的分析(profiling),從而來辨別注意模塊的內在結構。然后,相應地在已識別的不同結構上進行了不同的壓縮策略,以自適應的方式構建KV緩存。FastGen不設置緩存預算,而是設置注意力矩陣的最大近似誤差,因此專注于模型精度保持。
洞見
以前許多壓縮KV緩存的研究都沒有利用LLM中復雜的注意力結構。而LLM中的注意力結構有如下特點:
- 注意模塊中有豐富的結構。
- 不同的注意頭通常具有不同的功能,遵循不同模式。
- 并非所有注意模塊都需要關注所有表征。
上述特點表明需要根據每個單獨的注意頭定制壓縮策略。下圖左側是四種常見的注意力結構,右側是同一層的三個注意頭的注意圖。其中,特殊詞元(綠色)+ 標點詞元(橙色)+ 局部注意力(藍色)。灰色為其它詞元。
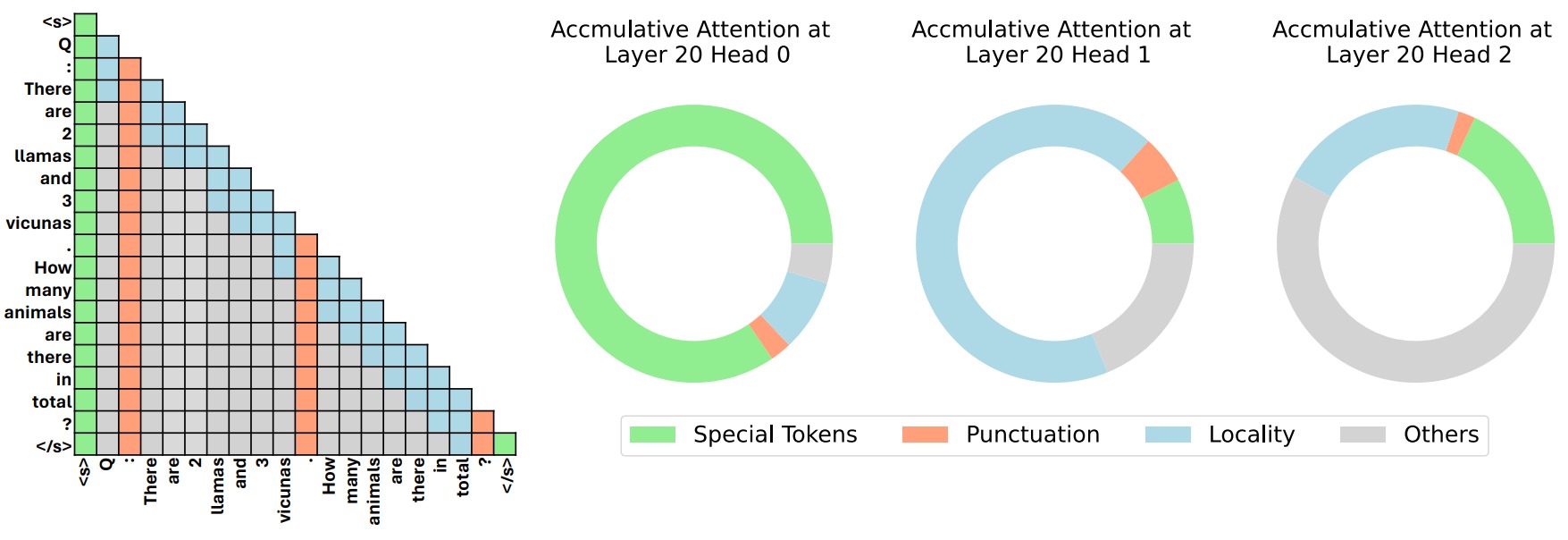
算法
除了傳統的全KV緩存策略外,FastGen考慮了四種基本的KV緩存壓縮策略。四種KV緩存壓縮策略是:
-
特殊token(Special Tokens)。在KV緩存中只保留特殊的token,如句子開頭token
<s>、指令token[INST]等。 -
標點符號(Punctuation)。在KV緩存中只保留標點符號,如“.”、“:”、“?”。
-
局部性(Locality)。此策略驅逐長期上下文,保留最后相鄰詞元。有些注意力模塊主要關注局部上下文,也就是我們常說的 Locality。在此策略中,一旦上下文token和當前token之間的相對距離超過閾值,上下文token的KV緩存將被逐出。閾值由預定義的局部上下文長度預算與輸入序列長度的比率所確定。
-
頻率(Frequency)。監控每個token的累計注意力分數,然后將這些分數視為token使用頻率,并只將最頻繁的token保存在KV緩存中。
FastGen可以分為兩步:
- 首先,在預填充階段結束時,對模型的注意力層進行剖析(profiling),識別各種注意頭的行為和結構模式,在這個profiling的指導下,自適應地為每個頭選擇最合適的滿足誤差目標的壓縮策略,構建KV Cache。與其他方法一樣,FastGen假設已識別的注意力模式將在未來的生成步驟中保持不變。如果誤差目標過于嚴格,無法達到,則FastGen會退回到常規的KV緩存。
- 然后,在每個生成步驟,不是不加區分地為每個新生成token添加新KV向量,而是根據每個token選擇的壓縮策略來管理其KV緩存。比如驅逐注意頭上強調局部上下文的長程文本,丟棄以特殊token為中心的注意頭上的非特殊token,并且僅對廣泛關注所有token的注意頭使用標準KV緩存。
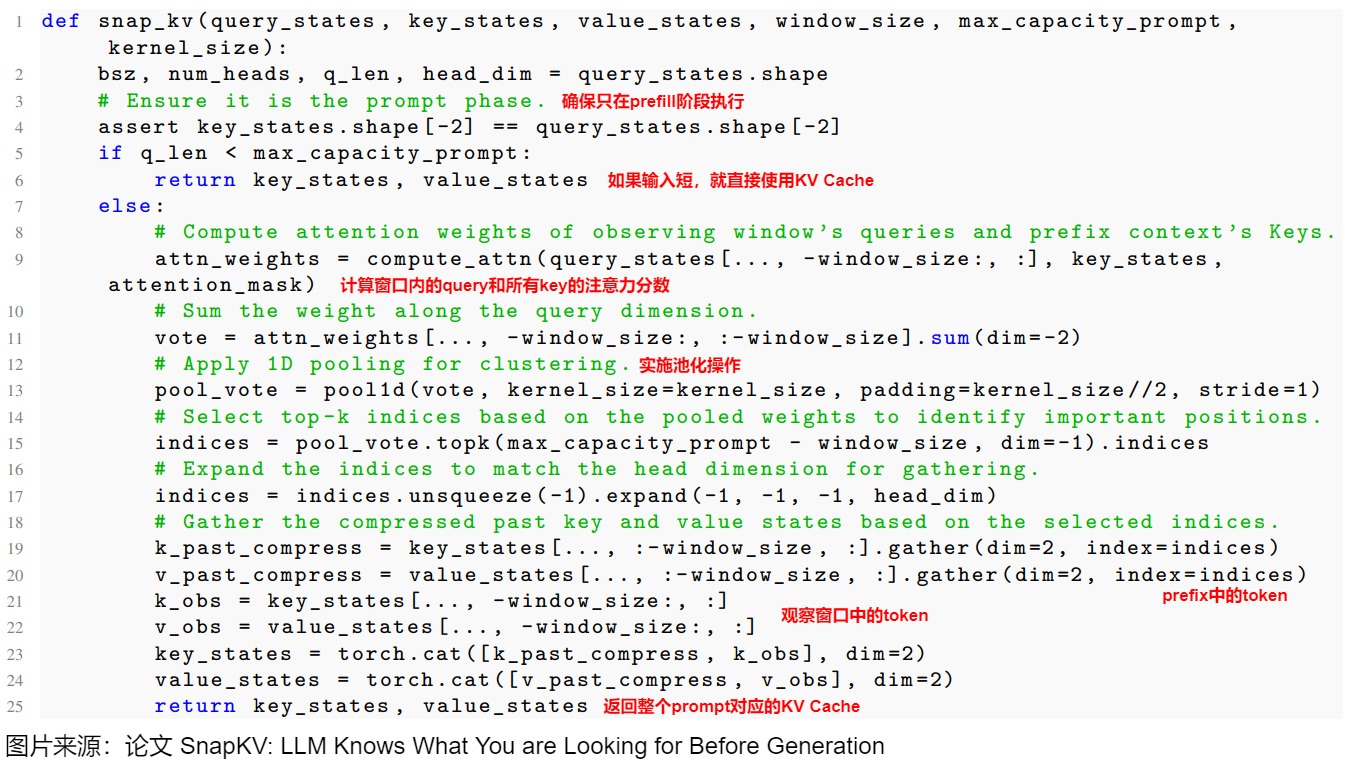
1.3.2 SnapKV
SnapKV 的核心思想是根據用戶問題識別重要的token。LLMs在生成過程中對輸入tokens的關注模式具有很強的一致性和穩定性,而這種模式可以在輸入序列末尾的一個小窗口內就觀察到。因此,SnapKV只保留那些被注意力heads持續關注的輸入tokens對應的KV,從而大幅壓縮KV緩存的尺寸。同時,SnapKV還引入了池化等聚類技術,既能捕捉局部的完整信息,又能過濾掉大部分無關tokens。
洞見
論文作者做了實驗,把輸入按照128個token為單位來劃分window,取靠近尾部的20個window來做計算。對于prefix里面的任意一個token,假設叫做 t i t_i ti?。我們取20個window里面的某一個window,假設叫 w i w_i wi?。 w i w_i wi?的每一個元素和 t i t_i ti?都會有交互,因為 t i t_i ti?在 w i w_i wi?的元素前面。那么, w i w_i wi?的每個元素和 t i t_i ti?都會計算出一個attention score。對于窗口 w i w_i wi?, t i t_i ti?會有128個attention score。取這128個attention score的均值作為 t i t_i ti?的重要性值。這樣,對于窗口 w i w_i wi?,prefix的每個token都可以計算出重要性值,然后根據平均score選出生成階段prefix中最重要的topK個token。
然后,作者比較窗口選擇出來的重要token和生成階段選擇出來的重要token的重疊率。通過比較20個窗口選擇的重要token和生成階段實際選擇出來的重要token,作者發現最后一個窗口選擇出來的和生成階段選擇的是高度重合的。因此這就說明:輸入里面哪些重要可以使用輸入prompt本身就可以決定。即論文所說的:
- Pattern can be identified before generation.
- Pattern is consistent during generation.
另外,作者還觀察到幾個現象。
- 無論生成上下文的長度如何,提示中的特定 Token 在生成過程中始終展現出更高的注意力權重,而且比較穩定。
- 提示中問題的位置并不會顯著改變觀察到的注意力模式的一致性。也就是,無論問題的位置如何,都可以獲得相關特征的注意力。
- 注意力模式高度依賴上下文,表明這些模式與用戶提出的具體指令有很強的關聯。
因此,一個上下文感知的 KV Cache 壓縮方法可能會帶來更好的性能。
方案
SnapKV簡化了FastGen的方法,只專注于根據token的重要性得分檢索token。在所有提示token中,只有一部分攜帶了響應生成的關鍵信息,這些token在生成階段保持了其重要性。SnapKV采用末端定位的觀察窗口(end-positioned observation window)來檢測這些重要的上下文token。然后,將它們對應的鍵值對與觀察窗口中的token連接起來
SnapKV在 Prefill 階段不是保留所有輸入 Token 的 KV Cache,而是采用稀疏化的方式。
-
在prefill階段,針對每個 Attention Head 將 Prompt 分為 Prefix 和 Window 兩部分,即下圖中橙色和綠色部分,可設為representative token 和 window token。對應下圖標號1。可以從位于 Prompt 末尾的 “Observation” 窗口獲得每個 Attention Head 在生成過程中始終關注特定的注意力特征。
-
通過 Window 中 Token 與 Prefix 中 Token 的 Attention Score 來選擇稀疏化的 Token。即假設window token之前的某個token為A,window token會對A有一個注意力分數,將所有window token對A的注意力分數加起來,就是A的“重要性分數”。重要性分數最高的那些token就是representative token。對應下圖標號2。
-
依據注意力分數選出topk的token,此外,在選取topk之前還要對attention矩陣進行一維的pooling操作,文中解釋這樣可以幫助LLM保留更完整的信息,因為只使用窗口選擇的內容,會造成生成的信息不全。對token附近token做pooling操作可以補齊上下文,類似高斯模糊。對應下圖標號3。
-
最后,將選出token的 KV Cache 和 最后一個窗口中 所有Token 的 KV Cache 一起作為 Prompt 的 KV Cache。對應下 圖標號3。
SnapKV只在 Prefill 階段篩選出關鍵的 KV Cache,然后在 Decoding 階段使用這些稀疏化的 KV Cache,以加速長上下文場景的生成速度。此外,Decoding 階段也不會再更新 Prompt 的 KV Cache。
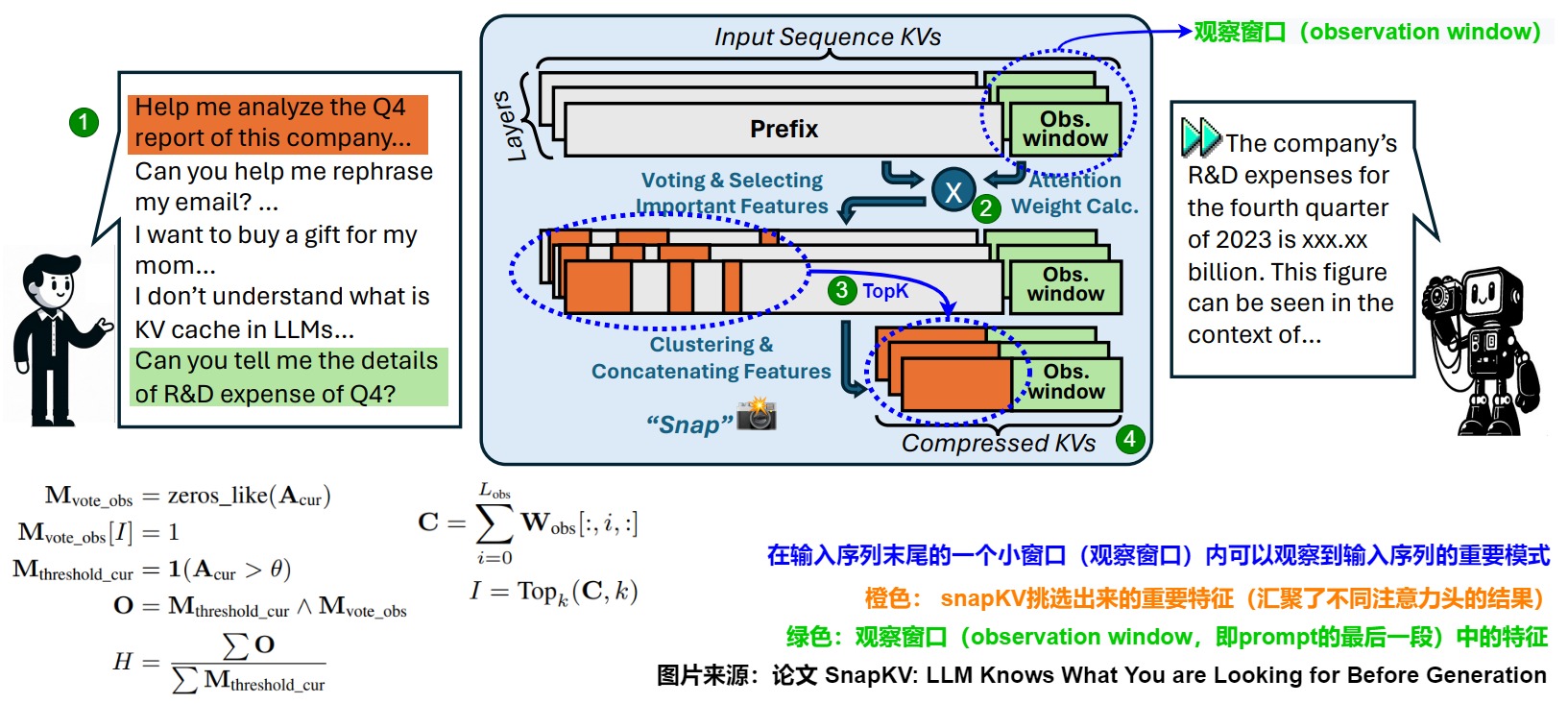
具體算法如下。
1.4 針對層特點的稀疏化
LLM的分層架構導致跨層的不同信息提取模式,每層的KV緩存對模型性能的貢獻不同。
LLM模型的注意力層有自己的特點,這也影響了KV Cache稀疏化策略。比如,為了估計需要保留多少KV Cache中的鍵/值,InfiGen作者對每個查詢token的注意力權重按降序排序,并累計鍵token的權重,直到累計權重達到0.9。下圖展示了在不同層(Layer 0 和 Layer 18)中,為了達到總注意力權重的0.9所需的鍵token數量分布情況。直方圖的橫軸表示鍵token數量,縱軸表示查詢token的數量。
- 第0層的注意力模式更加分散,不同查詢token所需的鍵token數量差異較大,需要參考更多的鍵token才能捕獲有效的注意力。
- 第18層絕大部分查詢token僅需16至幾十個鍵token即可達到累計權重0.9,只有極少數token需要更多的鍵token,說明高層的注意力模式更集中,依賴較少的鍵token即可獲得有效注意力。
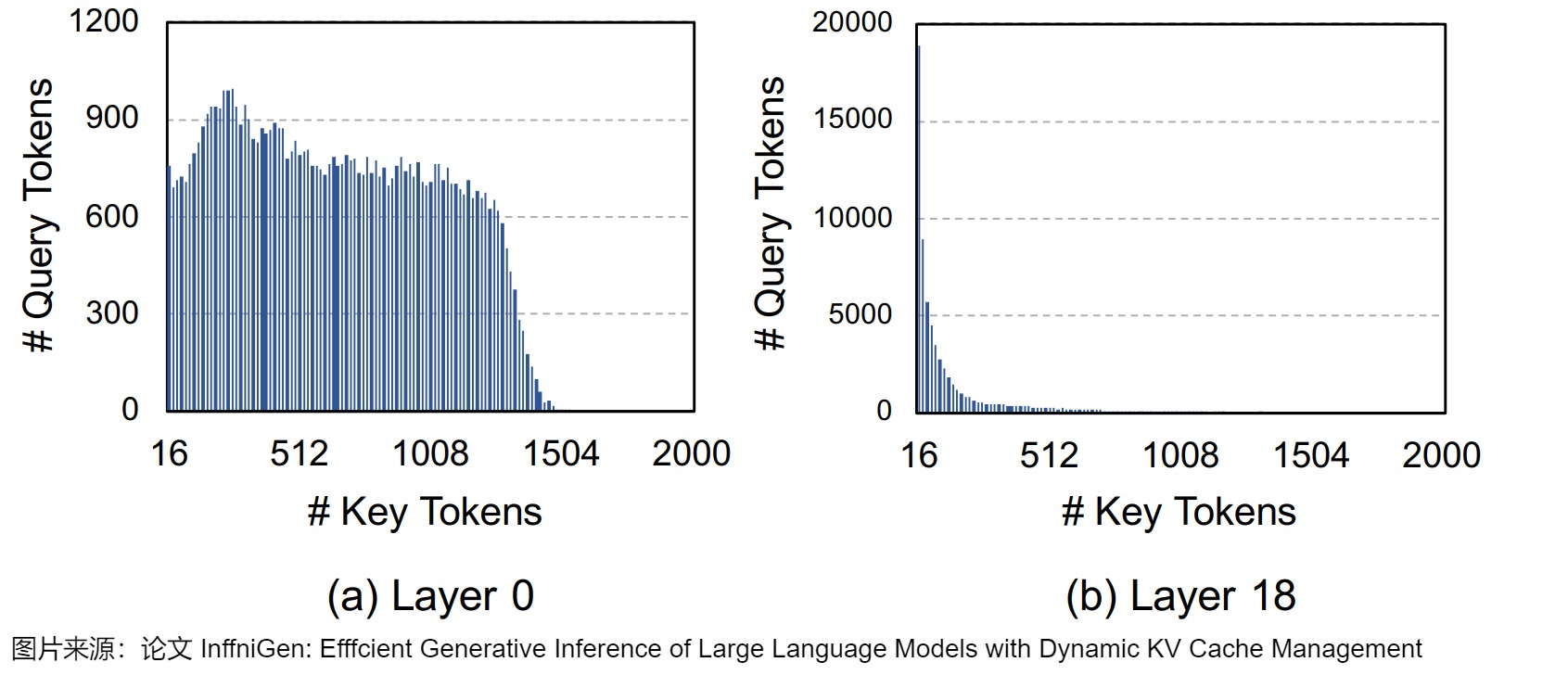
從這些觀察中我們可以知道,每個層對于總注意力其實都有著不同程度的貢獻,所以不能直接驅逐在外。而且,不同層的注意力模式差異顯著。因此,跨層的統一KV緩存壓縮可能不是最優的。
在KV Cache管理中,即需要針對LLM層間信息提取異質性,依據注意力權重的貢獻進行區分處理或者累積處理,也需要動態調整每層參與注意力計算的鍵token數量。通過根據每個組件對預測準確性的重要性智能分配內存資源,從而優化內存利用率,同時最大限度地減少準確性下降。
注:論文“A Survey on Large Language Model Acceleration based on KV Cache Management”是將基于層特點的稀疏化和基于頭特點的稀疏化都歸結到“KV Cache Budget Allocation”類別中,KV緩存預算分配通過根據每個組件對預測準確性的重要性來智能分配內存資源來解決這一挑戰。比如將更多的KV緩存分配給信息更加分散的較低層(前幾層),同時減少較高層信息比較集中的KV緩存等。論文給出了具體總結如下圖所示。

我們具體看看一些案例。
1.4.1 PyramidKV
論文“PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling”通過研究不同layer間的注意力機制,探索了跨層共享kvcache的效果,發現較低層在輸入序列中表現出均勻的注意力分布,而上層則表現出對特定token的集中注意力。因此,PyramidKV采用了金字塔形的內存分配策略,將更多的KV緩存分配給信息更加分散的較低層(前幾層),每個KV包含的信息較少,同時減少較高層的KV緩存,使得高層中信息變得集中在較少的關鍵token中,同時在每一層選擇具有高關注值的token。此外,在解碼階段,PyramidInfer通過由注意力值驅動的頻繁更新動態維護一組重要token。
洞察
作者研究了Llama模型進行多文檔問答的逐層注意力圖,發現了注意力層中存在金字塔形信息匯聚模式(Pyramidal Information Funneling):
- 在模型的低層(例如第0層)中,注意力得分呈現近似均勻分布,信息比較分散。這表明模型在較低層時從所有可用內容中全局聚合信息,而不會優先關注特定的段落。
- 當編碼信息進行到中間層(6-18)時,逐漸轉變為聚焦在段落內部的注意力模式(Localized Attention)。在這個階段,注意力主要集中在同一文檔內的Token上,表明模型在單個段落內進行了段落內部的信息聚合。即模型已經將需要的信息集中到了部分token中。
- 這種趨勢在上層(24-30)繼續并加強,而且可以觀察到“Attention Sink”和“Massive Activation”現象。
Massive Activation出自論文“Massive activations in large language models”,即在模型的隱藏狀態中存在極少數激活值(activations)遠大于其他激活值的情況,這些被激活稱為“massive activations”。
方案
作者選擇通過基于注意力模式動態分配緩存預算來提高壓縮效率。針對層的不同特性使用不同的KV Cache機制。
- 在前幾層使用全部的kvcache。因為這些層在聚合全局信息,所以信息更加分散。
- 越深的層使用越少的kvcache。在這些層中,注意力機制極大地集中在少數幾個關鍵Token上,因此只需要保留這些關鍵Token就能讓輸出保持一致并且減少顯存占用。而其他的token由于值很低,最后被采樣的概率也很低,因此可以考慮丟棄這部分token的cache。
KV Cache最終是一個金字塔形狀,即論文中提到的PyrimadKV。一旦為每一層確定了KV緩存預算,PyramidKV在每一個Transformer層中選擇根據注意力選擇要緩存的KV。最后的部分( α \alpha α個)Token的KV緩存,即Instruction Token,則會在所有Transformer層中保留。
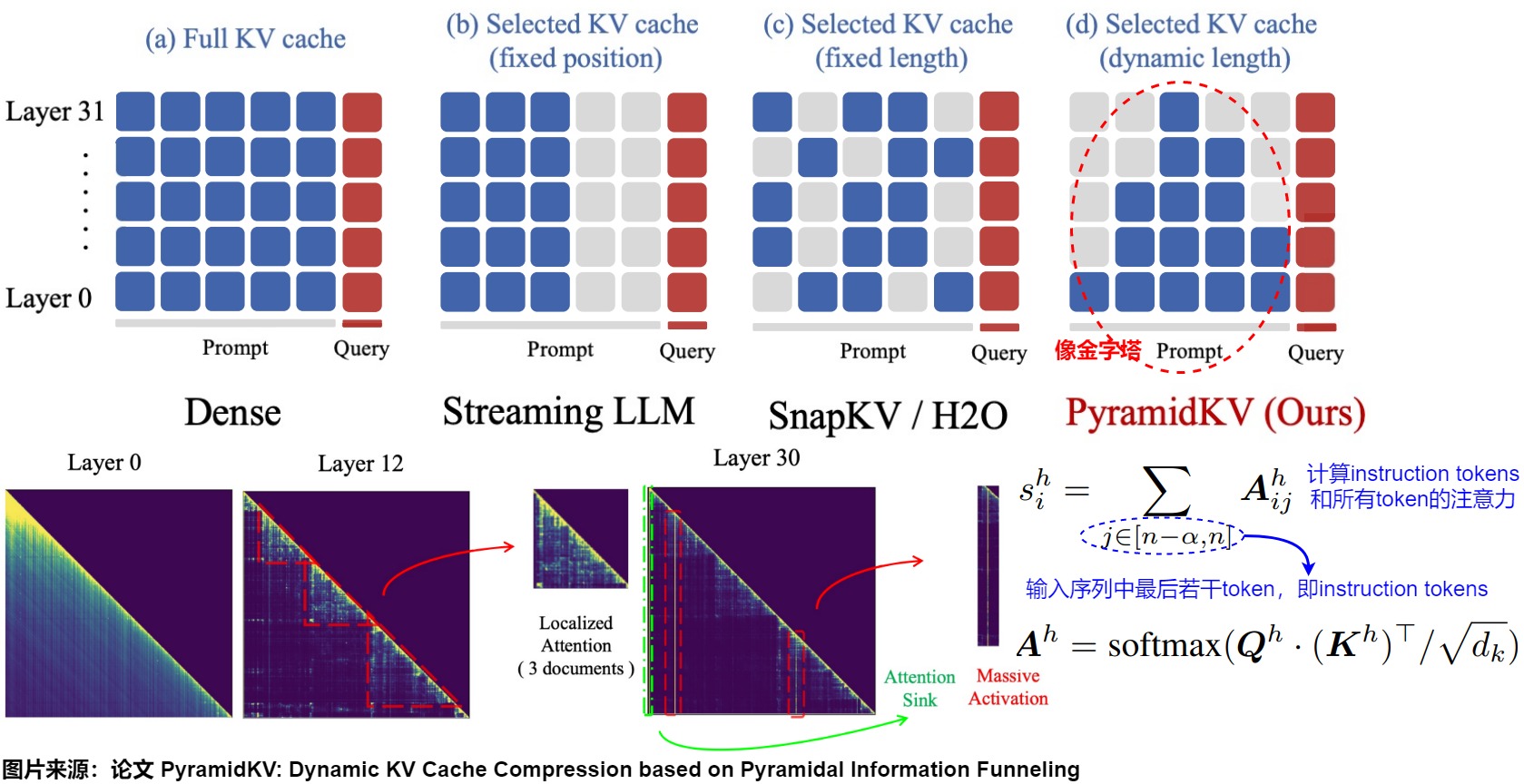
為了量化每個token在生成過程中的重要性,作者測量每個token從指令token中獲得的關注程度,并使用此測量值為KV緩存選擇重要token。具體實現流程如下:
-
因為最前面的token和最近鄰的token都包含重要信息,對生成效果影響顯著,不能舍棄,所以用超參數控制這些token的選擇,比如始終保留初始64個token(sink token)和最近的128個token(instruction token)。
-
確定第一層和最后一層要保留的token總數,比如第一層是全部,最后一層是1/10(超參數控制)的token。那么中間layer需要保存的token數目從第一層到最后一層線性遞減。具體計算token是用 instruction token和該token計算注意力分數來確定的。
-
確定了token數目k之后,就可以進行topk的選擇。由于qk矩陣每一行的權重和value值加權平均后得到最終的hidden_status,因此篩選規則就是qk矩陣每一行的權重值。
- 每一層layer在decoding時,只加載對應數目的kvcache進行計算。
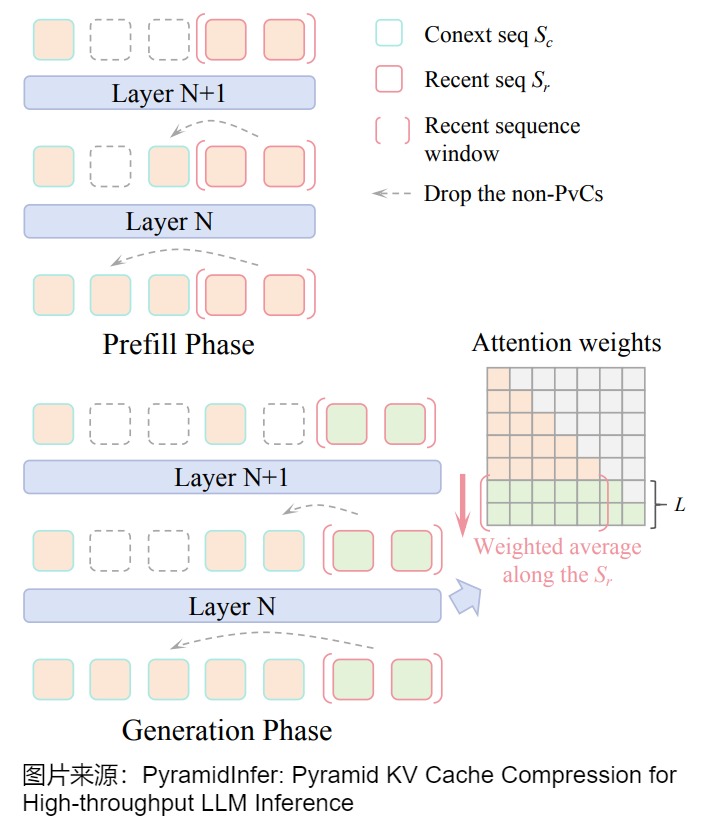
1.4.2 PyramidInfer
PyramidInfer也采用金字塔形的預算分配策略,同時在每一層選擇具有高注意力值的token。此外,在解碼階段,PyramidInfer依據注意力值來更新動態維護重要token。
動機
之前很多方案忽視了層與層之間的相互依賴以及預計算過程中巨大的內存消耗。PyramidInfer 的作者發現影響未來生成的關鍵 KV 的數量逐層減少,并且可以通過注意力權重的一致性來提取這些對將來有關鍵作用的 KV。基于這些發現,作者提出了 PyramidInfer,通過逐層保留關鍵上下文來壓縮 KV Cache。
下圖為 PyramidInfer 與 StreamingLLM 和 H2O 的區別,PyramidInfer 中 KV Cache 會逐層遞減,越往后越稀疏。
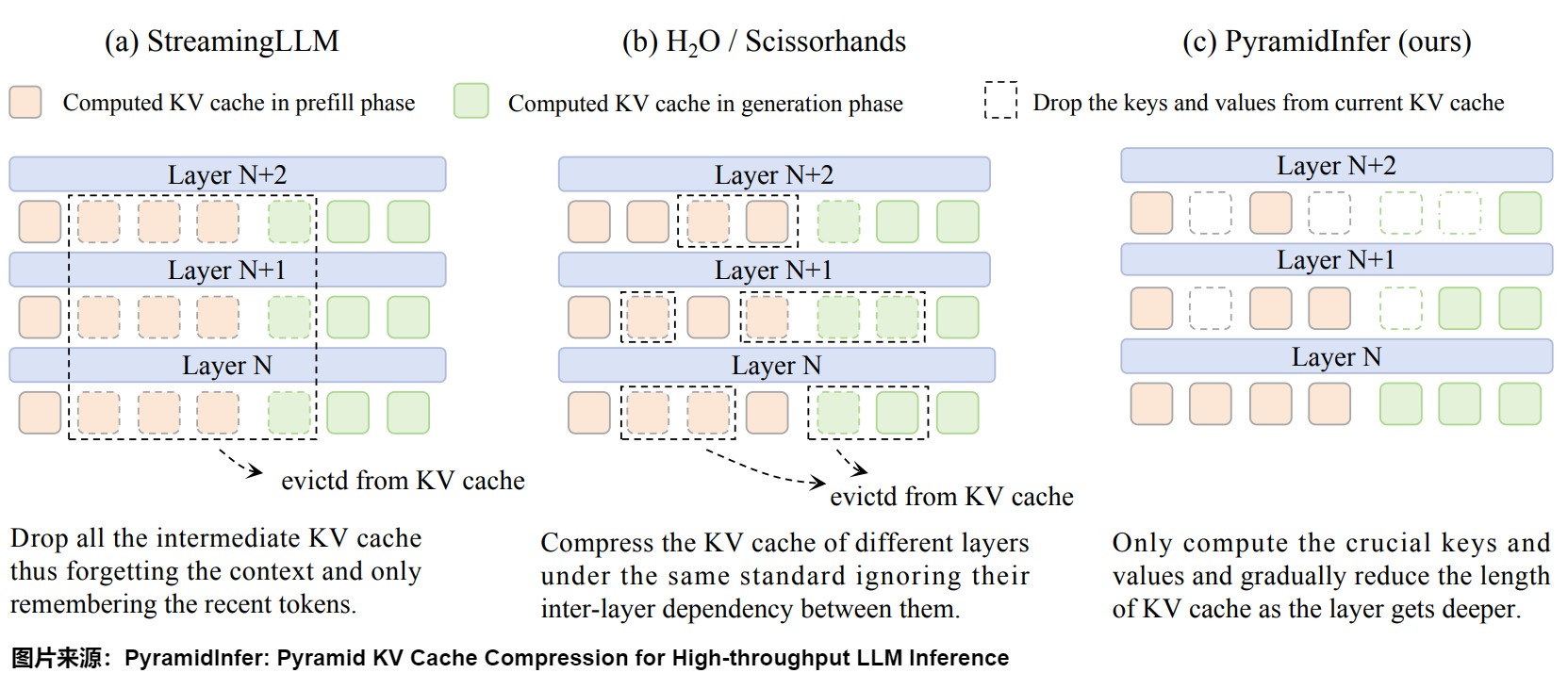
方案
PyramidInfer 的執行過程如下圖所示:
- 在 Prefill 階段,PyramidInfer 只保留每層的關鍵上下文(Pivotal Context, PvC)來壓縮 KV Cache。
- 在 Decoding 階段,PyramidInfer 根據新的最近的 Token 來更新 PvC。
1.4.3 ZigZagKV
ZigZagKV 其實是在SnapKV上繼續做優化,也就是說,它也是輸入prompt的KV Cache壓縮算法,但是ZigZagKV依據層特點進行了稀疏化,因此放在此處。
動機
為了更好的改進,ZigZagKV 定義如下幾個指標:
- MBA(Minimum Budget size required to maintain 90% of the totalAttention score),其實就是維持90%的attention score需要的最小KV數。
- LMBA(Layer Minimum Budget size to maintain Attention score),由于每個attention head都可以計算出一個MBA值,我們把一層里面所有的attention head的MBA的均值叫做LMBA。LMBA越高也就意味著需要更多的token來維持精度,也就意味著需要分配更多的顯存來存儲KV Cache。
- LMBO(Layer-wise Minimum Budget for Output):此參數的作用是以輸出的相似性這個維度分析一下需要保留多少的KV才能讓輸出類似。
具體參見下圖,其中, a i a_i ai?是A的第i個元素。n是當前KV Cache里面的token數量。

通過實驗,作者發現:
- 不同的模型的對應層的LMBA差距比較大;同一個模型不同層的LMBA差距也很大。
- 同一個模型不同層在保持輸出基本一致的限制下需要的KV數量差距很大。
基于上面的兩個觀察,作者得出的結論就是給模型的每一層分配同樣大小顯存來存儲KV Cache是不合理的。
空間分配
為每一層分配多大的空間存儲KV Cache是合理的呢?
一個直觀的想法就是每一層按照LMBA計算得到的比例來分配,大層多份,小的少分。具體參見下圖標號1,其中B是單層的Budget。這么分其實有一個問題,就是如果某一層的LMBA特別大的時候可能導致某些層分配到的空間特別小,也就意味著這些層基本無法保存任何KV。一個層基本沒有KV Cache,效果自然保證不了。所以,我們給每個層保留一個最小大小,分配公式改為下圖標號2。這就是ZigZagKV的主要改進點。SanpKV給每一層均勻分配空間。而ZigZagKV自適應地分配空間。
解決了每一層KV Cache的空間分配問題,還有一個問題就是要保存那些K和V。ZigZagKV里面token的選擇跟SnapKV非常類似。但是,SnapKV給所有的layer的head是平均分配的,ZigZagKV沒有給每個attention head分配同樣多的顯存,而是根據每個head可以保留絕大部分信息需要的token數來進行分配。

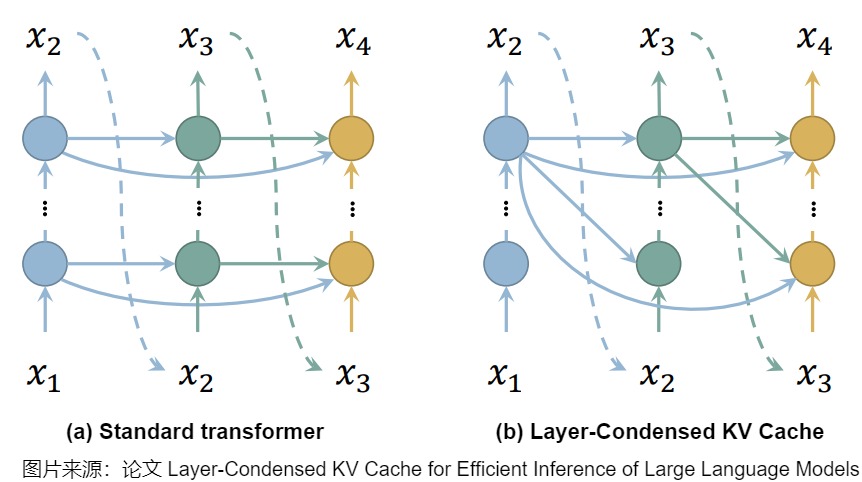
1.4.4 Layer-Condensed KV Cache
LCKV建議只計算和緩存一小部分層的鍵和值,甚至只計算頂層,然后讓底層的查詢與保存的鍵和值配對進行推理。這種方法不僅大大提高了推理速度,降低了內存消耗,而且與現有的內存節省技術正交,能夠直接集成以進一步優化。雖然這種機制使下一個注意力計算依賴于前一個注意力的頂層密鑰和值,這與Transformer的并行訓練相矛盾,但LCKV引入了一種近似訓練方法來支持并行訓練。
具體而言,Transformer 對模型輸入進行層層編碼的過程,其實也就是對token信息一步步加工的過程,因此Layer-Condensed KV Cache作者認為i最后一層的信息是最重要最全面的,可以忽略前面幾層處理得到的信息,只保留最后一層的KV cache。當生成后續 Token 時,其對應的 KV Cache 都從最后一層取。這樣模型不再需要計算以及保存前面這些層token的key和value,也不需要前面幾層的 W K W V W^K W^V WKWV 矩陣,極大的節省了計算和內存開銷。如下圖所示。
1.5 其它方案
1.5.1 針對頭特點的稀疏化
針對頭特點的稀疏化進行更細粒度的逐頭預算分配,它能夠在每一層內的單個注意力頭之間進行精確的內存分配,提供更靈活和有針對性的優化機會。
- AdaKV:基于注意力模式差異為各頭分配緩存,通過優化L1損失界限最大化保留信息。
- RazorAttention:描述了兩類不同的檢索頭。“回聲(echo)頭”專注于先前出現的相同token,“歸納(induction)頭”關注與當前token重復的之前token。該框架實現了差異化緩存策略,為檢索頭維護完整的緩存條目,同時將遠程注意力壓縮為非檢索頭的合并補償注意力。
- DuoAttention:DuoAttention引入了一種參數化方法來區分兩類注意力機制:檢索頭,對全面的長上下文處理至關重要;流式頭,主要處理最近的注意力和注意力吸收器。這種分類是通過學習參數實現的,這些參數可以自動識別需要全注意力的檢索頭。
1.5.2 投機采樣稀疏化
投機采樣稀疏化的思路是:通過draft模型生成候選token,然后選取其中重要的token。
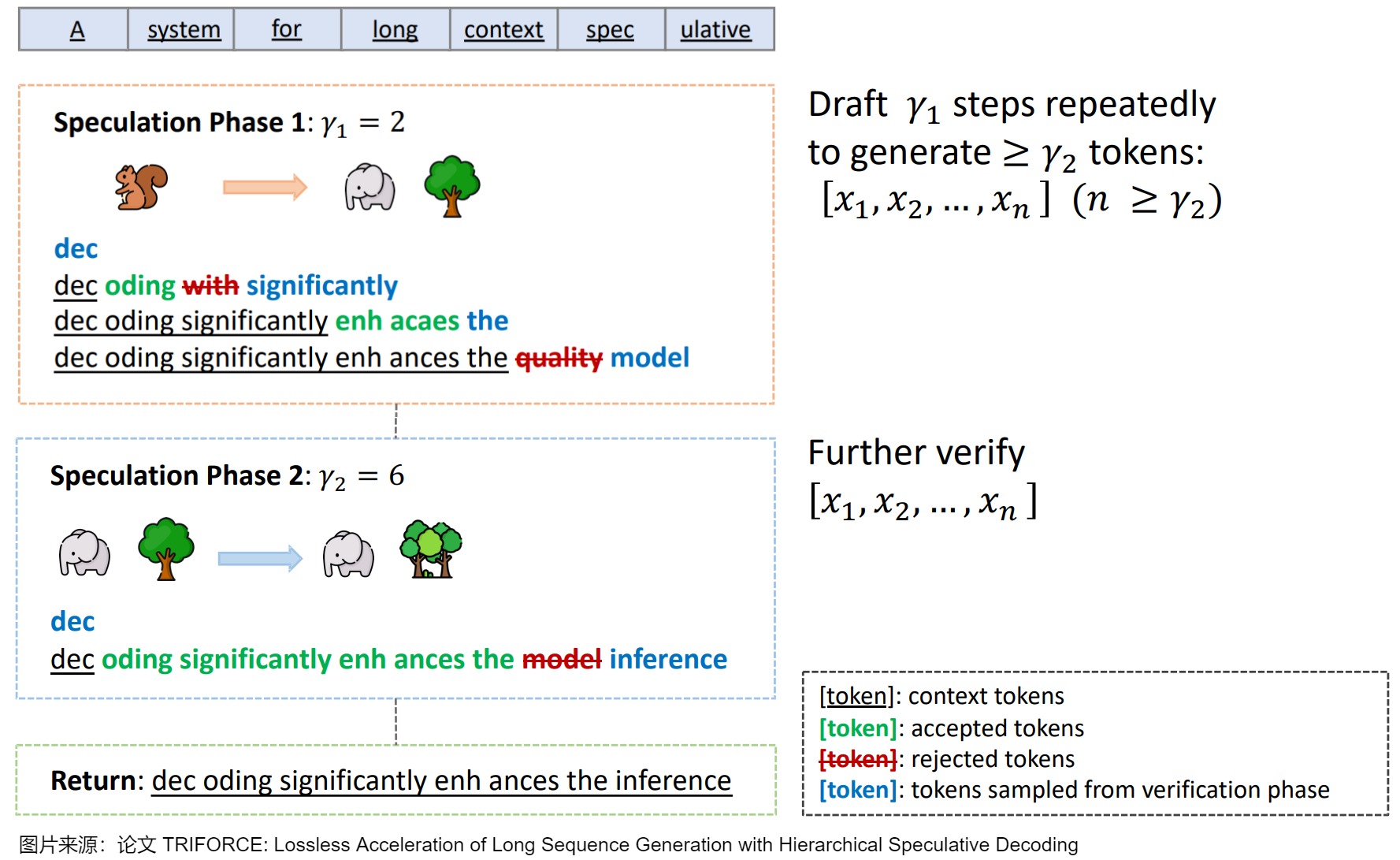
論文“TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding”提出了 TriForce,這是一種層次化投機采樣系統,主要用于長序列生成。TriForce想解決的是長序列生成背景下的加速問題。在長序列生成設定下,除了模型本身的權重,模型推理的 KV cache 也會占據大量的顯存,并在上下文足夠長的時候同樣成為制約推理速度的關鍵因素。
因此,TriForce引入了一個只使用部分 KV cache 的 target model 來減小全量的 KV cache 對于推理速度的制約,同時采用多級投機推理策略進一步降低 draft model 的推理開銷。TriForce的核心思路如下圖所示,其主要分為三個過程,涉及兩級投機采樣:
- Speculation Phase 1(此階段可以執行多次,直到獲得滿足條件的多個候選 Token):
- 使用比較小的 LLaMA-68M 模型作為草稿模型,同時使用 StreamingLLM 的方案快速生成多個候選。
- 使用 LLaMA2-7B-128K 模型作為 Target 模型,采用稀疏 key、value cache 方案進行并行驗證。驗證后的 Token 作為新的草稿。因為采用的稀疏 key、value cache,因此相應的結果可能是有損的。
- Speculation Phase 2(此階段執行一次):使用 LLaMA2-7B-128K 模型作為 Target 模型,采用全量 key、value cahe 方案進行并行驗證。此階段可以保證生成的結果無損。
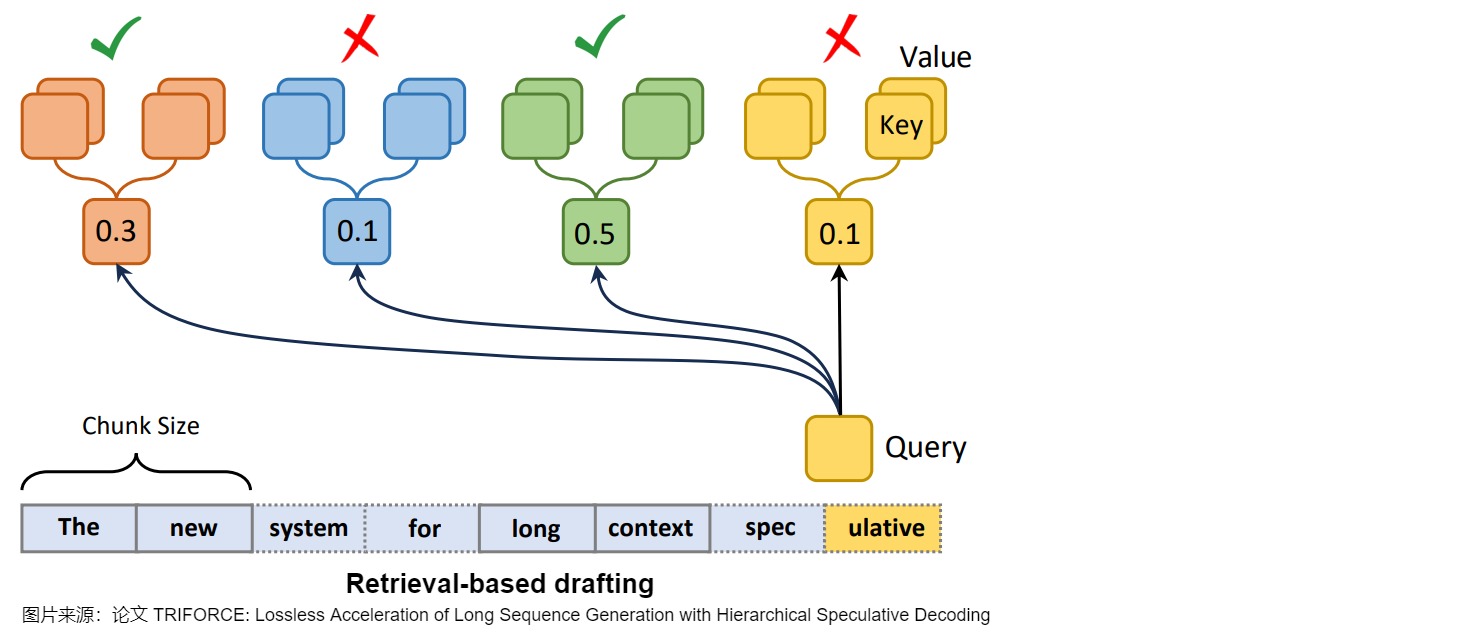
在緩存的使用上,TriForce采用基于檢索的方案:
- 將 key、value 劃分為不同的 Chunk。
- 使用 query 與每個 Chunk 的中心(使用均值作為中心)計算距離。
- 選擇 topk 的 Chunk 作為稀疏 key、value cache 進行 Attention 計算。
1.5.3 聚類稀疏化
為了加速關鍵注意力的檢索,一些研究工作提出了基于索引的方法,以塊或集群(cluster )粒度組織和訪問KV緩存,實現了高效的查詢和提取操作。InfLLM在塊中維護完整的KV緩存,同時通過分層存儲策略促進長序列處理。該框架采用CPU-GPU內存編排,在GPU內存中保留基本注意力和當前計算單元,同時將訪問頻率較低的單元卸載到CPU內存中。為了進一步提高top-k塊檢索精度,Quest框架提出了一種基于KV緩存塊中最小和最大鍵值的精細塊表示方法。
SqueezedAttention在離線階段采用K-means聚類來對語義相似的密鑰進行分組,每組由一個質心表示。在推理過程中,它將輸入查詢與這些質心進行比較,以識別和加載上下文中語義相關的鍵。同樣,RetrievalAttention使用近似最近鄰搜索(ANNS)技術索引KV緩存注意力。此外,EM-LLM動態地將傳入的注意力分段為偶發事件。此外,它實現了一種混合檢索機制,將語義相似性匹配與時間上下文相結合,以有效地訪問相關的KV緩存段。同樣,ClusterKV將注意力分組到語義簇中,并在推理過程中選擇性地召回它們,從而為LLM實現了高精度和高效率。
我們用ClusterKV為例進行學習。
在如何舍棄K和V的方向的研究主要又細分為兩個方向:
-
Non-recallable KV Cache:直接把一些系統判定為不重要的K和V舍棄掉。如何判定不重要是里面關鍵點。比如,保留attention sink以及最近的窗口里面的token對應的KV cache,把其它的都扔掉,以此來使得計算和顯存都可控。
-
Recallable KV Cache:實際上,KV Cache里面的某一個token的重要性是動態變化的。一個token也許在前面不重要,但是在后邊就變重要了。為了得到更好的結果,我們不能把某個KV直接拋棄掉,而應該根據具體的情況在一些時候拋掉KV,一些時候又把KV重載載入顯存繼續使用。
下圖給出了幾種方法的對比,圖上的星號表示重要的token。我們可以看出,重要的token其實是動態變化的。
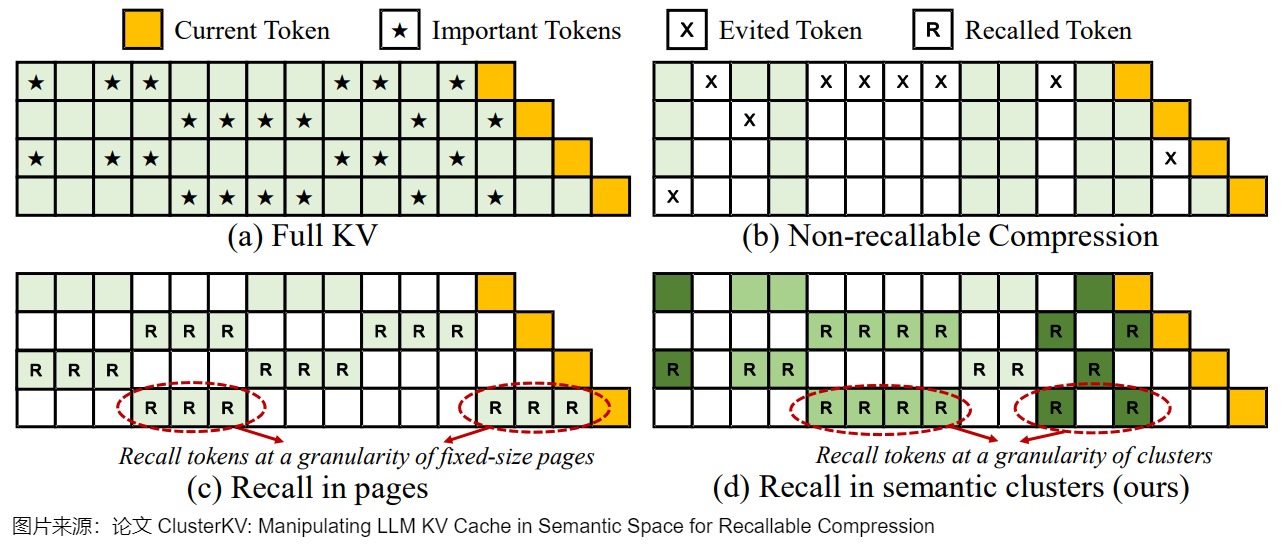
ClusterKV的一個重要觀察就是,對于一個q重要的token對應的K的cos距離都比較小。基于這個觀察,作者使用K-means聚類的方法把類似的K和對應的V進行聚類(使用K的相似性作為分類依據),這樣每個類都有一個中心向量,計算重要性的時候就使用這個中心向量來計算。如果q和一個中心向量的cos距離(1-cos值)比較小,那么q和這個類里面所有的向量的cos距離都應該比較小,換句話說距離比較小的類 都會比較大。所以我們可以把這一個整個類都加載進來做后續計算,并且保證漏掉的重要token盡量少。
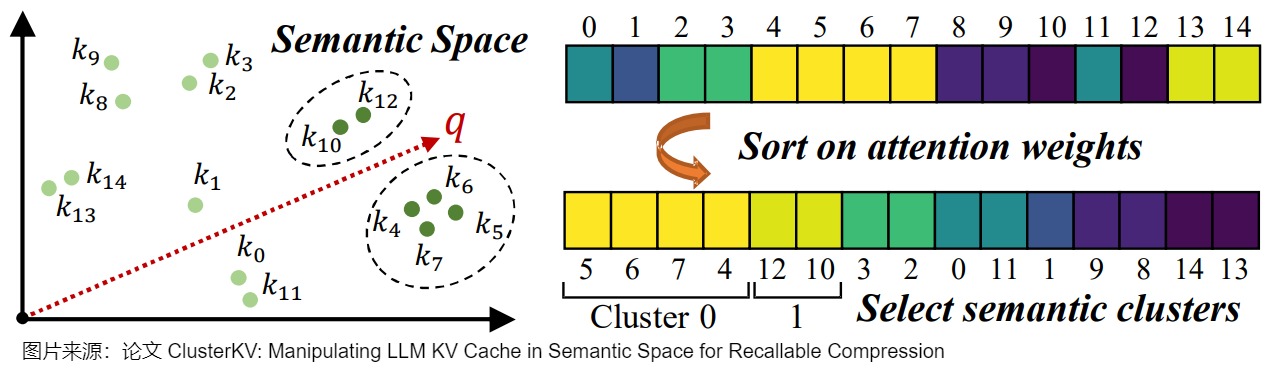
聚類方法如下:
- 先把attention sink部分保留,論文簡單地直接把前16個token對應的都保留;
- 對于prefill階段的結果進行聚類。作者實驗發現,對于32K的context,400個類是最佳權衡;
- decoding階段,每m步做一次聚類。論文中默認情況下每320個token生成完之后新作一次聚類。

在選擇類別是,先設置固定大小B,然后按照類別的重要性從最重要的開始取,一直取到所有類里面的元素加起來超過B為止。
0x02 復用
復用也是減少KV序列長度的一個重要手段。在本節,我們主要介紹兩種方案:KV Cache合并(Merging)和前綴復用。
2.1 KV Cache合并
面對是否刪除不重要的鍵值對以節省內存,還是保持原樣但進行壓縮而不刪除的問題,尚無定論。刪除操作或許能立即緩解內存壓力,但可能會潛在地影響模型的性能。相反,更先進的壓縮技術則力求在減少內存占用的同時,保持信息的完整性。
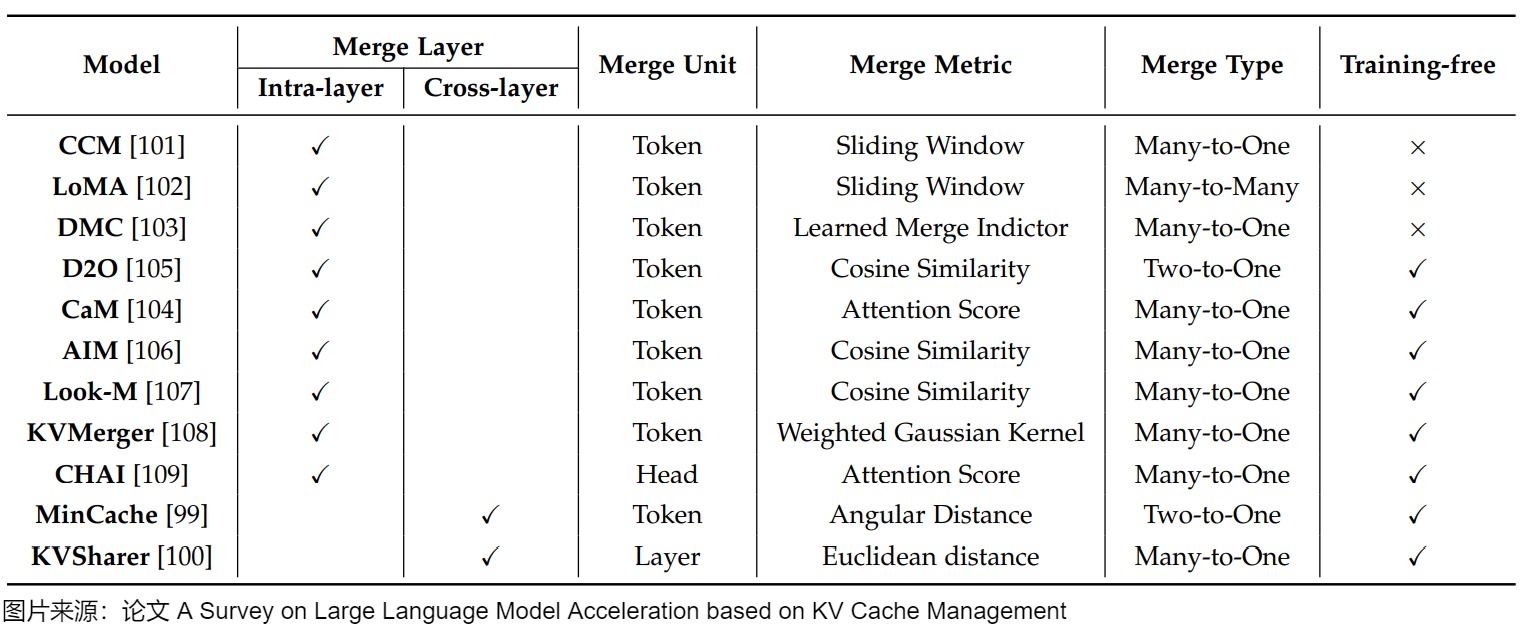
KV cache合并(KV cache merging )探索通過壓縮或整合KV緩存,盡可能保留被丟棄token的信息,而不會顯著降低模型精度,這可以視為對前面提到的token丟棄策略的擴展。KV緩存合并技術不是采用統一的壓縮策略,而是利用層內和層間的固有冗余來動態優化內存利用率。這些方法旨在減小KV緩存的大小,同時保留準確注意力計算所需的關鍵信息,從而在資源受限的環境中實現高效推理。現有的KV緩存合并策略可分為兩種主要方法:層內合并,側重于在各個層內合并KV緩存,以減少每層的內存使用;跨層合并,針對跨層冗余,以消除不必要的重復。這兩種方法都提供了互補的優勢,提供了平衡內存節省和模型性能下降的靈活性。KV緩存合并的總結如表4所示。
2.1.1 層間合并
對于層間合并,我們以MiniCache為例進行學習。
MiniCache 會合并中高層相似KV對。具體而言,MiniCache并將將相鄰相似層中每個token的KV對分解為向量共享方向向量和幅度,僅存儲共享的方向向量、注意力幅度和不可縮放的注意力,以最大限度地提高內存效率。
動機
作者發現,KV Cache 在 LLM 中的深層部分的相鄰層之間表現出了高度相似性,可以基于這些相似性對 KV Cache 進行壓縮與合并。此外,作者還引入了 Token 保留策略,對高度不同的 KV Cache 不進行合并。并且這種方法可以與其他的 KV Cache 量化方案正交使用。
思路
下圖給出了MiniCache和以前方法之間的主要區別。MiniCache的特點是沿著LLM的深度(depth)維度研究KV緩存的層間冗余,這是之前基于層內方法忽略的一個方面。這里,T是指預解碼的最后一個時間戳,T+1是指解碼的第一個時間戳。
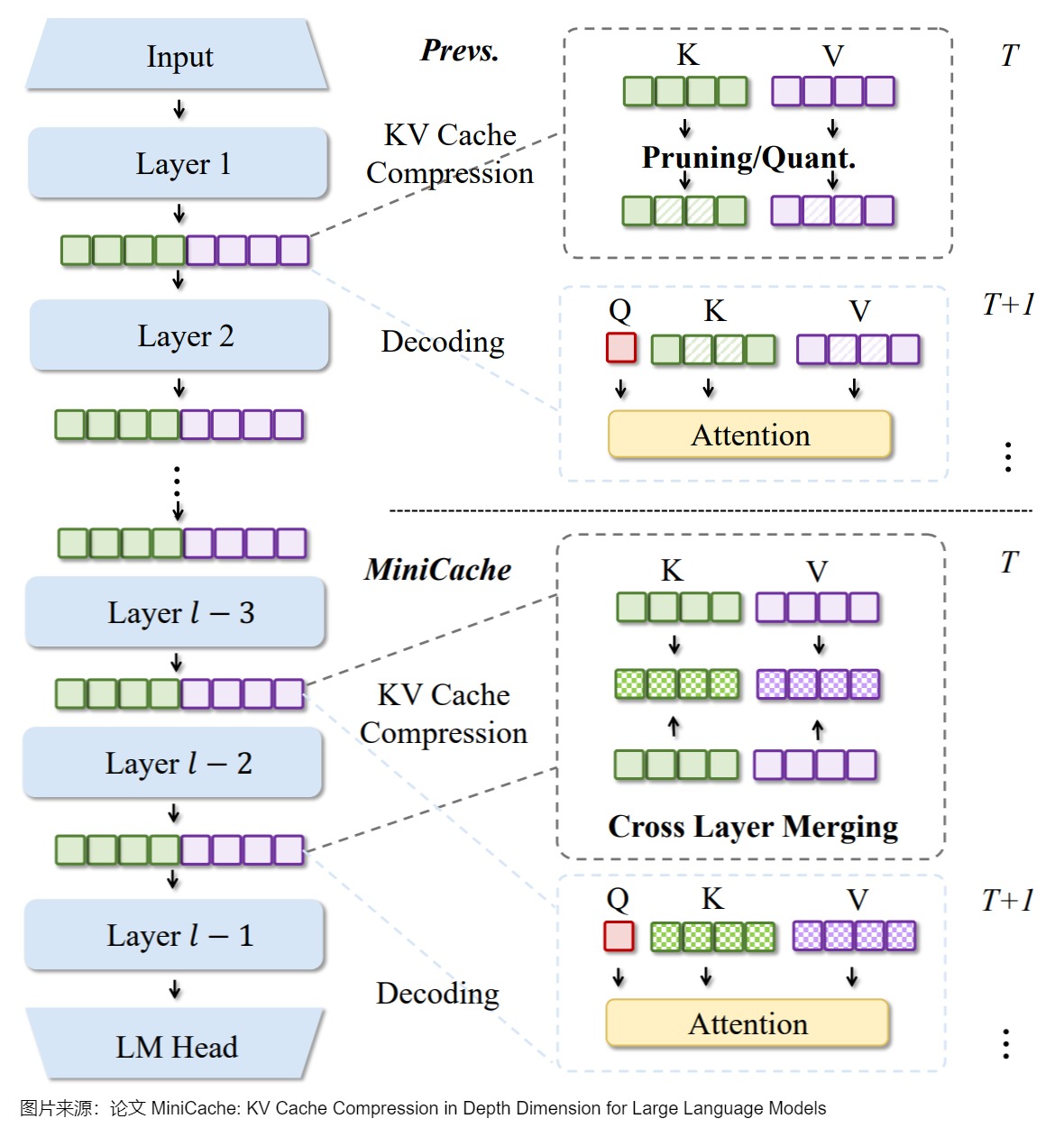
下圖是MiniCache的壓縮策略和保留策略。
- (a)描述了跨層壓縮過程。模型從層l和l-1中獲取KV緩存,并通過方程式(3)將它們合并到共享狀態中。此外,模型也選擇不可合并的注意力進行保留,然后將合并的緩存、保留注意力和數量存儲在C中。
- (b)說明了層l和l-1的恢復過程,其中包括方程式(2)中的數量重新縮放和保留注意力恢復。
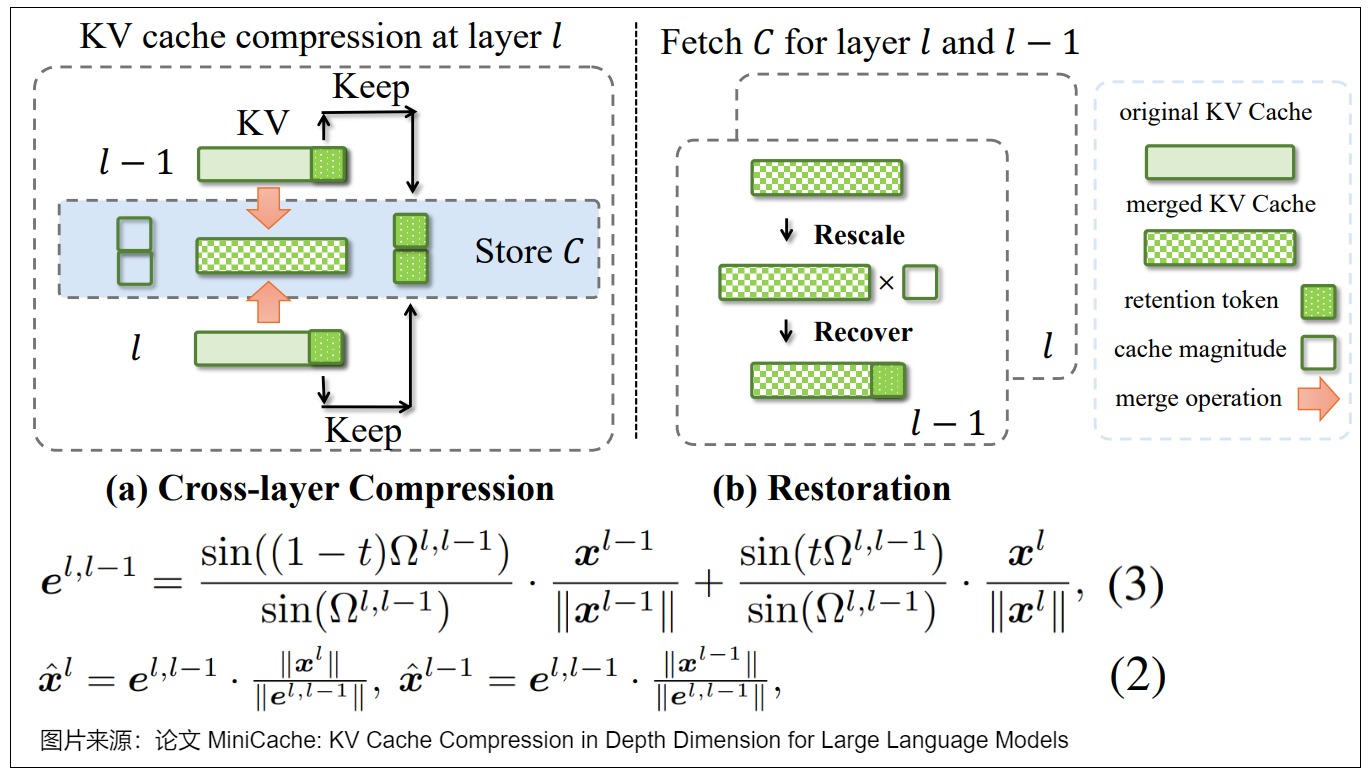
算法
下圖為MiniCache詳細的執行流程。
- 獲取 KV Cache:在 Prefill 階段,逐層生成 KV Cache。
- 跨層合并:當到達合并開始層 S 時,將當前層 L 的 KV Cache 與前一層 L-1 的 KV Cache 進行合并,以減少冗余。
- 緩存:將合并后的 KV Cache 存儲起來,以便將來使用。
- 刪除:在 Decoding 階段,刪除不必要的或冗余的 KV Cache,以優化內存使用。
- 加載和生成:獲取所需的 KV Cache,用于生成輸出。
- 恢復:對獲取的 KV Cache 應用誤差抑制機制,包括 rescaling 和 retention recovery,以最小化合并和壓縮過程中引入的誤差。
- 更新:在恢復階段后,使用最終的 KV Cache 更新共享的 KV Cache。
2.3 層內合并
我們使用DMC來學習層內合并。
在普通 Transformer 中,在每個時間步 𝑡,𝑘𝑡 和 𝑣𝑡 都會被追加到 KV Cache中。
在 DMC 中,KV Cache更新過程有所不同,如下圖算法 1 所示。在每個時間步長,DMC 會決定是將當前的key-value對直接添加(append)到緩存中,還是對它們與緩存中頂部的項進行加權平均(weighted average)。
具體而言,DMC 使用一個決策變量 𝛼𝑡∈ {0, 1} (只能取0和1) 和一個重要性變量 ω𝑡∈[0,1]。我們用 𝑘𝑡 和 𝑞𝑡 中的第一個神經元來提取這兩個分數。DMC 根據 𝛼𝑡 來決定是將 KV 表示 𝑘𝑡 和 𝑣𝑡 追加到緩存中,還是將其與緩存的最后一個元素累加。
DMC 中的內存以亞線性方式增長,雖然比不上Linear Attention Transformer推理時的內存恒定,但明顯好于Transformer。

2.2 前綴復用
LLM服務已經從無狀態發展為有狀態系統,利用推理請求中固有的依賴關系可以優化KV Cache。這些利用依賴關系的技術可以分為兩種類型:跨請求和請求內。
- 跨請求技術利用跨請求的依賴關系。一個顯著的技術是前綴復用,也稱之為上下文緩存,它為共享相同提示前綴的請求重用KV緩存,從而加快預填充階段。能夠在請求之間重復使用KV緩存將顯著提高時延(尤其是首詞元時延)和吞吐量(通過大幅減少具有共享前綴的并發請求的內存占用)。
- 另一方面,請求內技術利用單個請求內的依賴關系。一個著名的例子是分離推理,將一個請求分成兩個子請求以獲得更好的調度,以及序列并行性,將一個請求分成多個子請求以分發負載。
本篇介紹前綴復用,下一篇介紹分離推理。
2.2.1 需求
當前大部分 LLM 應用在構造輸入時一般遵循 system prompt + user prompt 范式,我們也經常會面臨具有長system prompt的場景以及多輪對話的場景。
-
長system prompt的場景。在LM程序的批量執行過程中,如果有多個大型語言模型(LLM)調用共享了相同的前綴,system prompt在不同的請求中是相同的,并且此部分位于提示的開頭,因此其鍵和值在請求之間也是相同的。system prompt可能在較長的時間跨進程共享,從幾秒鐘到甚至幾小時或幾天。這些預定義的長系統提示在命中率低的情況下會造成內存浪費,而且在大規模部署中頻繁刷新時是靜態和不靈活的。
-
多輪對話場景。在多輪對話場景下,下一輪的 prompt 實際上可以視作上一輪的 prompt 與 completion 的組合。每一輪對話需要依賴所有歷史輪次對話的上下文,歷史輪次中的KV Cache在后續每一輪中都要被重新計算。
這兩種情況下,理論上可以多次重用KV緩存中的數據。如果能把system prompt和歷史輪次中的KV Cache保存下來,留給后續的請求復用,那么可以避免出現多個冗余的 system prompt KVCache,將會極大地降低首Token的耗時,能提高服務的極限吞吐,并降低新一輪請求的首次 Token 計算時間(Time To First Token,TTFT)。比如,對于system prompt,如果這些緩存以自注意力機制中的鍵值對命名。具有相同提示符前綴的請求就可以共享同一KV緩存,從而有效減少計算冗余和內存消耗。在多輪對話的應用中,如果復用,則可以消除歷史輪次中生成對話的recompute。
能夠跨請求重用KV Cache將實現顯著的延遲(特別是第一個 token 延遲)和吞吐量(通過大大減少具有共享前綴的并發請求的內存占用)改進。
然而,這種優化非常復雜,面臨很多技術難點,因為它需要額外的存儲和更復雜的內存管理。比如每個推理進程都是獨立應用,這些副本是并行的。需要如何跨越多個調用和實例來高效地重用KV緩存(共享提示詞前綴)。然而,現有的系統卻缺乏有效的機制來支持這種重用,正因如此,目前大多數領先的推理系統都采取了一種相對保守的做法:并未分析整個大批次中的前綴共享特性,也未將共享相同前綴的 Request 一并調度。而是以 Request 為粒度進行任務調度,在完成一個請求的處理后就會丟棄其KV緩存,這不僅可能導致可共享的 KV Cache 過早被驅逐,這一寶貴資源無法在多次請求間共享,還延長了可共享 KV Cache 的生命周期,從而拖慢了執行速度,導致了大量的重復計算和內存浪費。
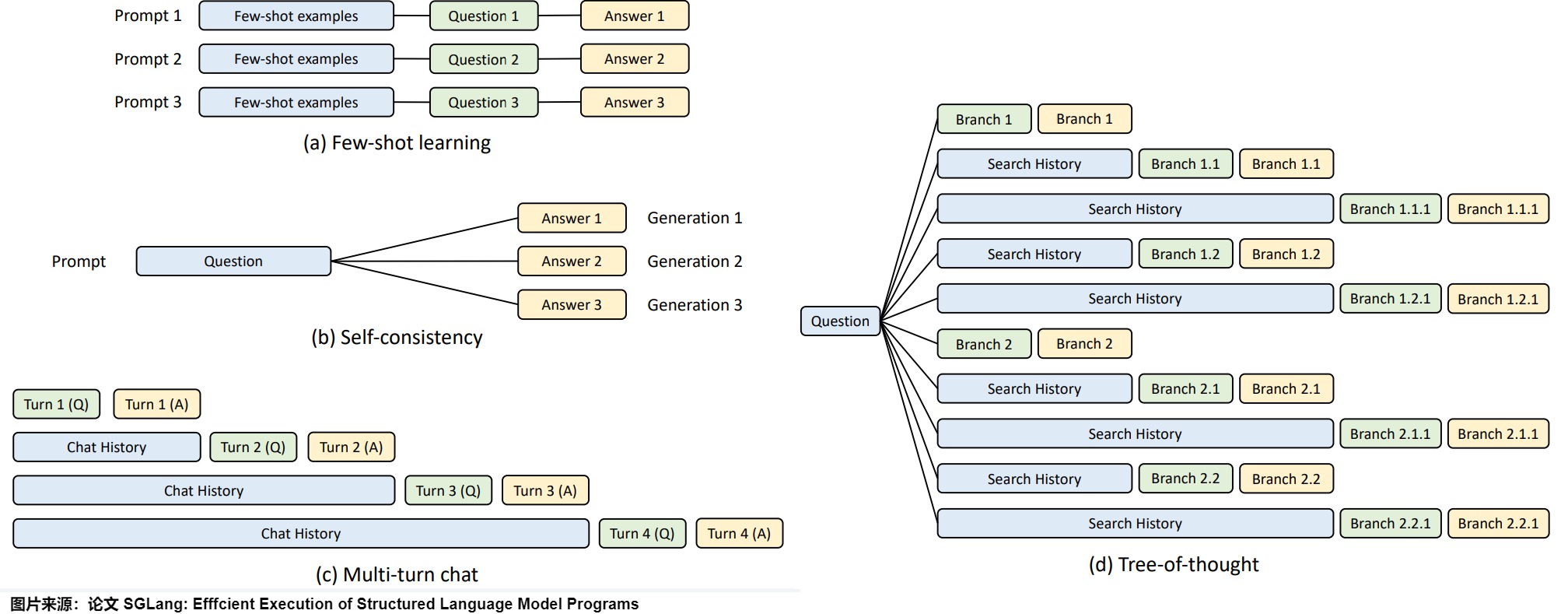
下圖是KV緩存的四種典型模型:小樣本學習示例(few-shot learning examples)、自一致性問題(questions in self-consistency) 、多輪聊天中的聊天記錄(chat history in multi-turn chat)以及思維樹中的搜索記錄(search history in tree-of-thought )。藍色框表示可共享提示部分,綠色框表示不可共享部分,黃色框標記不可共享的模型輸出。現有的系統很難自動處理所有模式。
接下來將介紹 Prefix Caching 在一些大型模型推理系統中的實現。
2.2.1 Prompt Cache
論文“Prompt Cache: Modular Attention Reuse For Low-latency Inference“提出了Prompt Cache,這是一種通過在不同的 LLM 提示中重用注意力來加速[LLM)推理的方法。Prompt Cache 采用一種稱為schema(議程)的方法來明確定義可重用的文本段,并將其稱為提示模塊。該schema可確保注意力重用期間的位置準確性。然后,Prompt Cache 在加載一個schema時填充其緩存。在推理時,如果這些“緩存”段出現在輸入提示詞中,系統使用內存中預先計算的鍵值注意力,只計算未緩存的文本。Prompt Cache在本質上也是以空間換時間的技術。
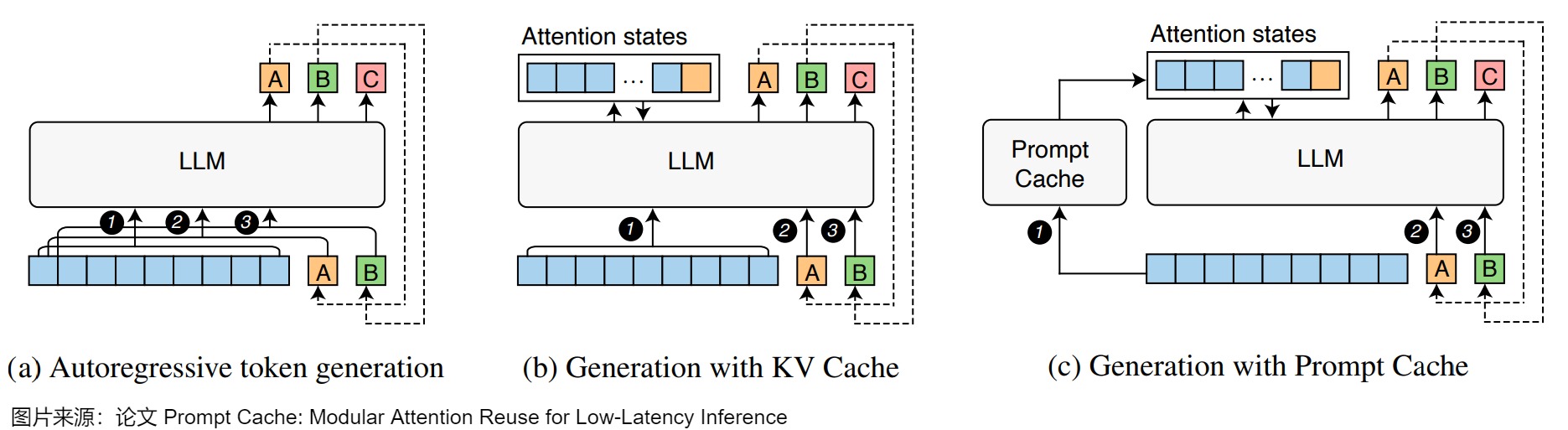
下圖是完全自回歸生成(a)、KV Cache(b)和 Prompt Cache?之間的區別,其中每種方法均顯示三個步驟(1 到 3步),每個框表示一個token。藍色框代表提示。
- LLM 接收提示并預測下一個 token (A) 。然后將生成的 token (A) 附加到提示以預測下一個 token (B)。此過程將持續到滿足停止條件。
- KV Cache 僅對提示計算一次注意力,并在后續步中重復使用KV Cache。
- Prompt Cache 可以跨服務重用 KV 狀態,從而省略提示詞的注意力計算。在加載模式時,Prompt Cache 填充緩存,并在基于該模式的提示詞中復用緩存狀態
隨著緩存段的大小增加,Prompt Cache的性能優勢會變得更加明顯,因為注意力的計算開銷與輸入序列大小成二次方關系,而 Prompt Cache 的空間和計算復雜度與大小成線性關系。
洞見
許多輸入提示都有重疊的文本段,例如系統消息、提示模板和為上下文提供的文檔。通過預先計算并將這些頻繁出現的文本段注意力存儲在推理服務器上,可以在這些文本端出現在用戶提示中時有效地重用它們。
然而,跨提示重用注意力時會出現兩個挑戰。
- 注意力是依賴位置編碼的,文本段的注意力只有在該段出現在相同位置時才能復用,怎么保證復用的注意力和當前 prompt 的位置相同呢?
- 系統如何高效地識別可能已緩存的文本段?
為了解決這兩個問題,Prompt Cache 結合了兩個想法。
- 使用提示標記語言 (Prompt Markup Language,
PML) 來格式化提示詞的結構。PML 將可重用的文本段標記為模塊,即提示模塊。它不僅解決了上述第二個問題,而且為解決第一個問題打開了思路,因為可以為每個提示模塊分配唯一的獨特的位置 ID。 - 作者發現,LLM 可以處理具有不連續位置 ID 的注意力。這意味著可以提取不同部分的注意力并將它們連接起來形成子集。這一點使用戶能夠根據需要選擇提示模塊,甚至在運行時更新某些提示模塊。
方案
一個schema是定義提示模塊并描述其相對位置和層次結構的文檔。LLM 用戶用 PML 編寫提示,目的是可以根據提示模塊重復使用注意力。重要的是,用戶必須從議程中派生出提示,該議程也是用 PML 編寫的。
當 Prompt Cache 收到提示時,它首先處理其schema并計算其提示模塊的注意力。它將這些狀態重用于提示中的提示模塊以及從同一議程派生的其他提示。
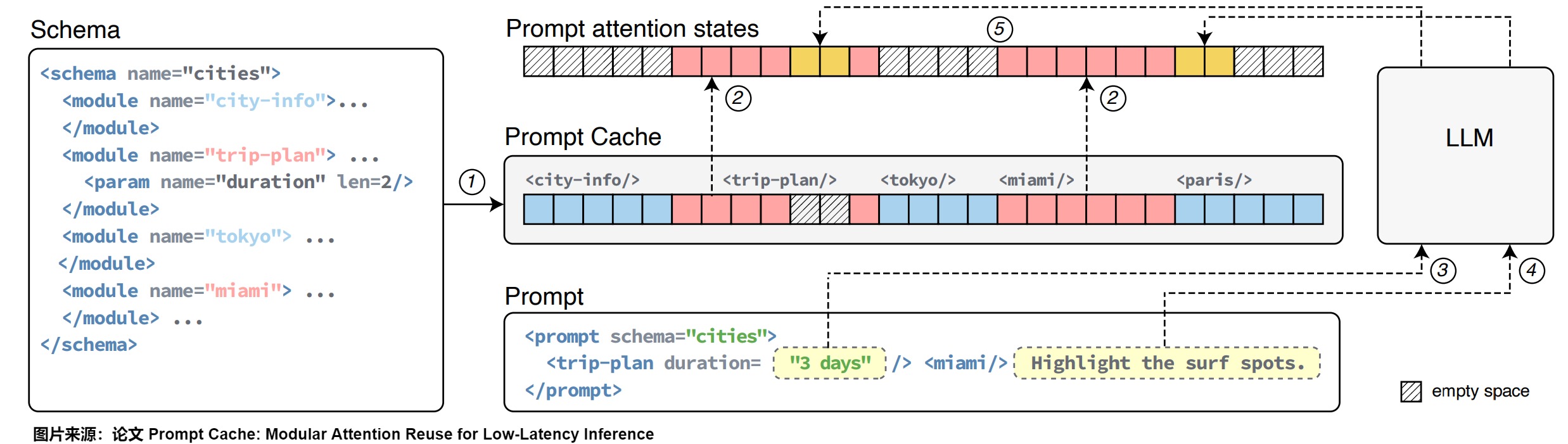
上圖顯示了基于示例schema的示例提示,可以解釋 Prompt Cache 的重用機制:
- PML 在schema和提示中都明確了可重用的提示模塊。提示可以包含在排除的模塊位置上新的文本段、參數以及末尾。
- Prompt Cache預先計算議程中所有模塊的注意力(1),并將其緩存以供將來重用。
- 當向 Prompt Cache 提供提示時,Prompt Cache 會對其進行解析,以確保與聲明的schema一致。Prompt Cache會驗證導入模塊的有效性。然后,Prompt Cache 從緩存中檢索導入提示模塊緩存的注意力(2),計算出參數(3)和新文本段(4)的注意力,并將它們連接起來,生成整個提示的注意力。
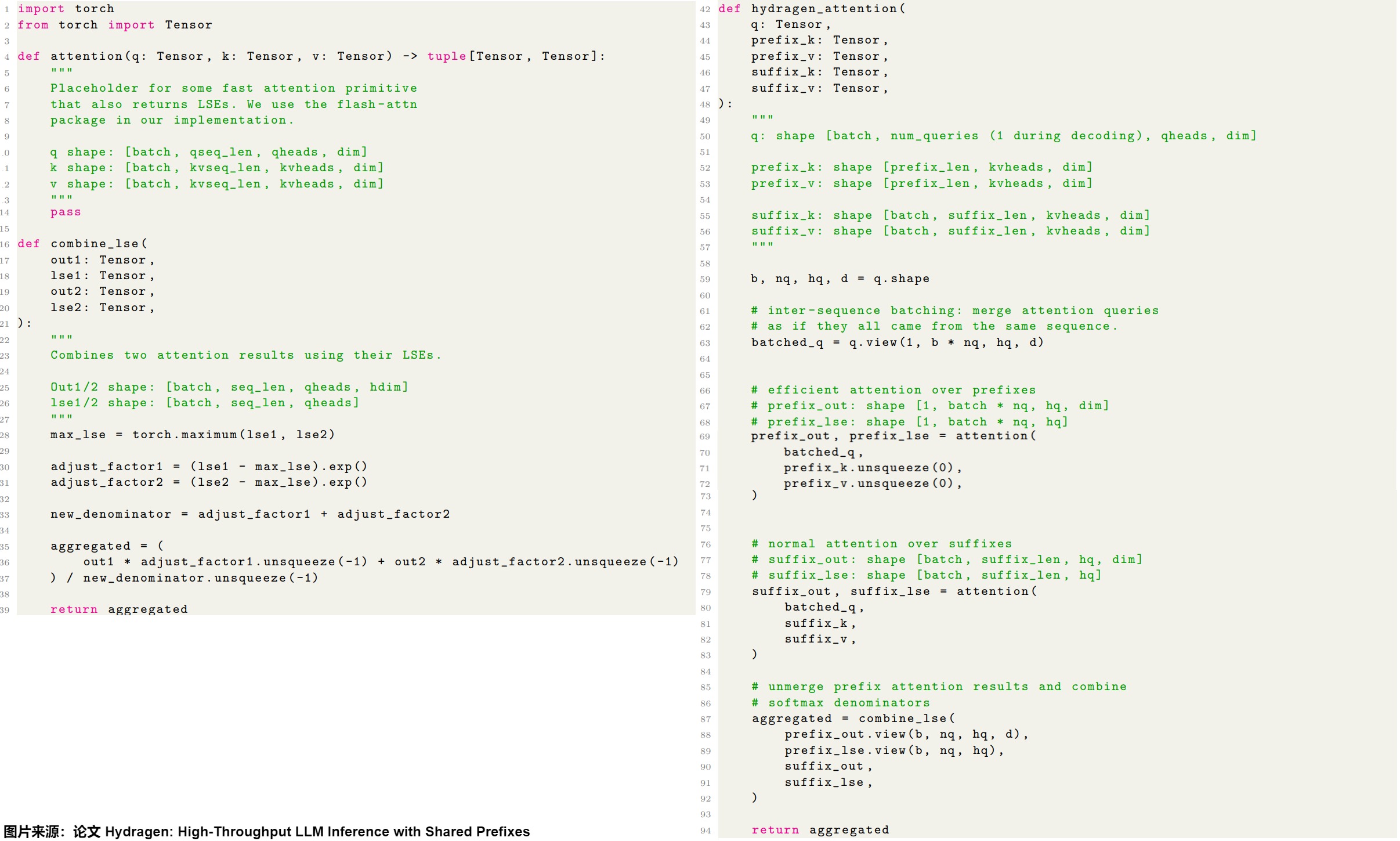
2.2.2 Hydragen
Hydragen是一種硬件感知的精確實現注意力機制的方法,適用于共享前綴的情況。Hydragen分別計算共享前綴和唯一后綴的注意力。利用單個共享的KV緩存來處理多個請求中的公共前綴,然后在跨序列將查詢拼接在一起,實現了高效的前綴注意力,減少了冗余的內存讀取。
下圖給出了Hydragen對應的結構描述:
- 左:LLM 推理場景示例,其中聊天機器人模型處理許多共享大共享前綴(系統提示)。
- 右:Hydragen 的概述,其中整體注意力被分解為共享前綴上的注意力以及在獨立后綴上的注意力。
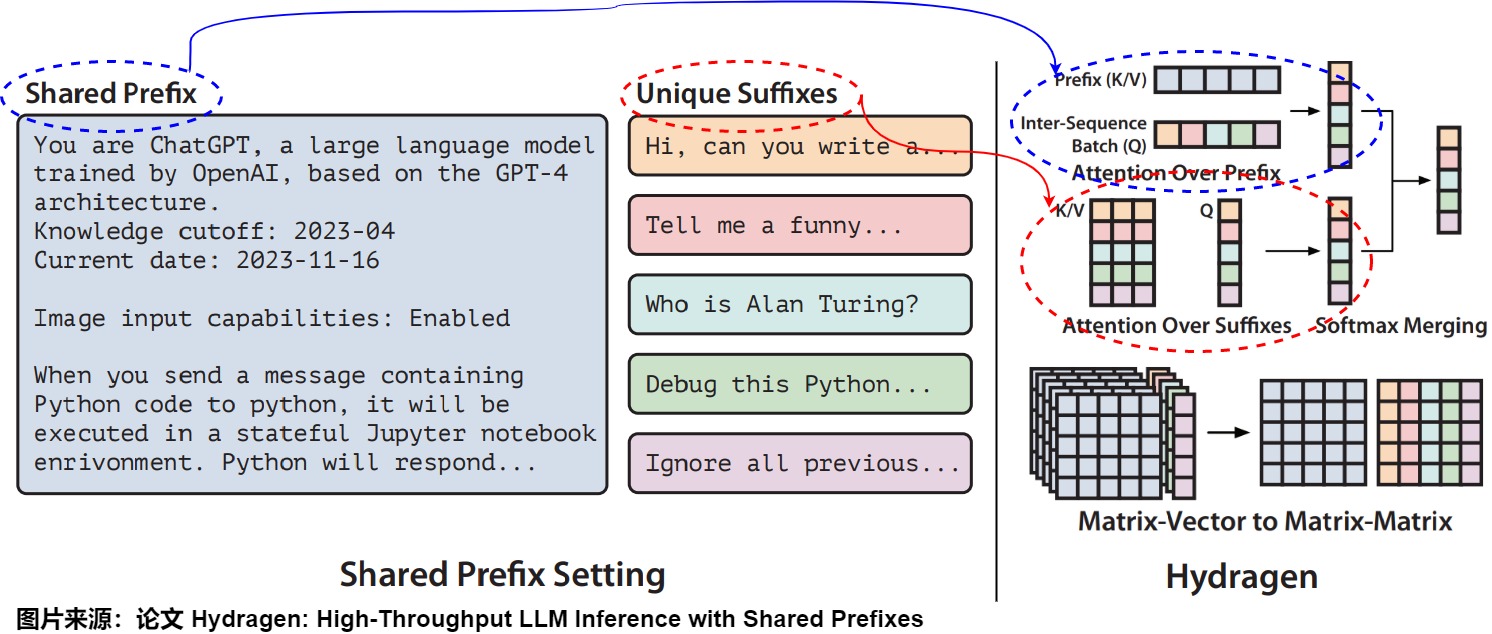
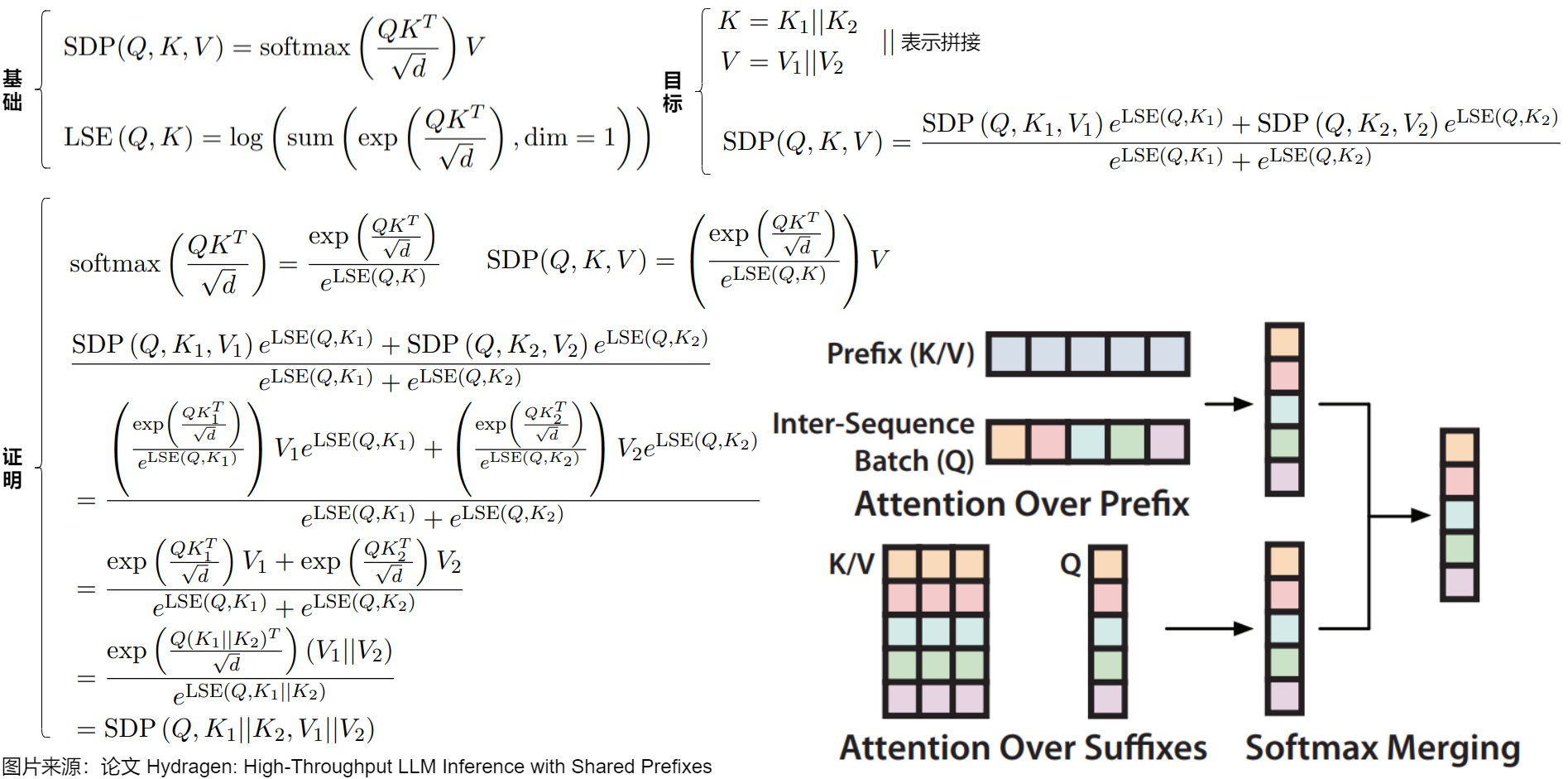
在計算注意力時,共享公共前綴的序列具有部分重疊的鍵和值。我們的目標是將這種部分重疊的計算分為兩個單獨的操作:關注共享前綴,其中存在總鍵值重疊;關注唯一后綴,其中沒有重疊。
下圖給出了推導過程。Hydragen希望避免直接計算SDP (Q, K, V ),轉而使用子計算$SDP (Q, K_1, V_1) 和 和 和SDP (Q, K_2, V_2) $的結果來計算這個值。劃分注意力的挑戰在于softmax運算,因為softmax分母是通過將序列中所有指數化的注意力得分相加來計算的。為了組合兩個子計算,Hydragen使用了一種分母重縮放技巧,其靈感來自FlashAttention的blocked softmax計算,通過該技巧,Hydragen可以通過計算全序列softmax分母并相應地重新縮放注意力輸出來得到最終結果SDP (Q, K, V )。
下圖給出了代碼示例。
2.2.3 ChunkAttention
ChunkAttention 將KV Cache分塊組織為前綴樹,支持運行時檢測和共享多個請求之間的公共前綴,通過兩階段分區算法提升數據局部性。 具體而言,ChunkAttention通過將整體的鍵/值張量分解為較小的塊,然后將它們結構化到輔助前綴樹中。而且,ChunkAttention在基于前綴樹的KV Cache基礎之上,又實現了兩階段分區算法,這樣在存在共享系統提示的情況下,可以增強自注意力計算時的數據局部性。
前綴樹
ChunkAttention認為KV緩存應該是前綴感知的,因此,ChunkAttention將所有解碼序列的KV緩存組織成前綴樹。KV緩存僅存儲當前正在解碼的序列的鍵/值張量,因此,KV緩存是前綴感知的,并且可以在運行時動態檢測和刪除冗余,無需人為干預。
前綴樹中的每條路徑定義了一個序列。服務器中可以同時存在多個樹(森林),例如,應用程序開發人員設計不同的系統提示。樹中的父子關系定義了每個塊所覆蓋的序列子集。根節點覆蓋所有序列,葉子節點只覆蓋一個序列。前綴樹的一個關鍵屬性是,在前綴樹中每個塊所覆蓋的序列在序列索引維度上是連續的。
下圖顯示了存儲在前綴樹中的KV緩存的結構。 S 0 S_0 S0?、 S 1 S_1 S1?、 S 2 S_2 S2?提示中的指令和示例是通用的,可以共享。但是問題各不相同,不可分享。每個節點是一個存儲三個關鍵要素的塊(chunk)C,三個要素是:
- 由序列 S i , . . . , S j S_i,...,S_j Si?,...,Sj?共享的c個上下文標記token,以便進行前綴樹操作。
- 對應著c個token的,大小為b×h×c×d的鍵張量的切片。
- 相應的值張量切片。
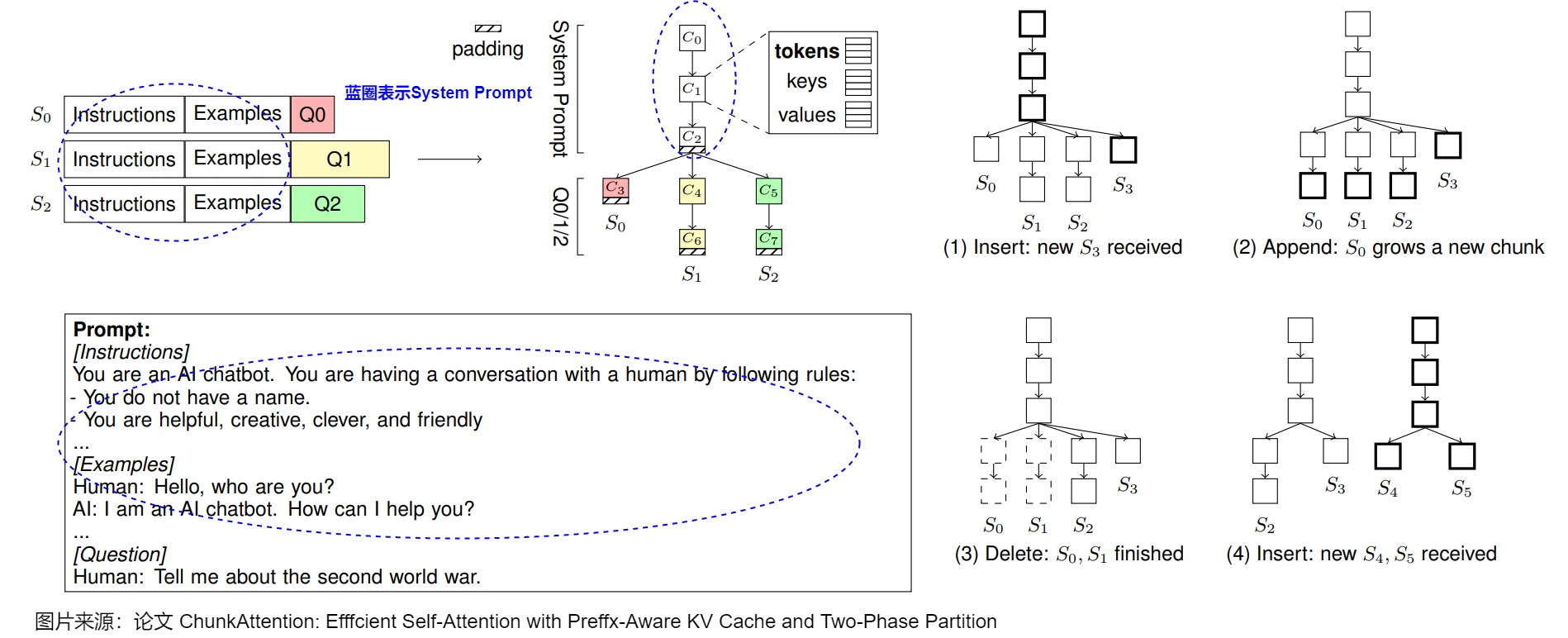
在推理過程中,存在三種可能的情況:i)新序列加入,ii)完成的序列離開,iii)所有序列一起解碼一個token。每種情況都可以轉化為前綴樹操作。當新序列加入時,搜索并更新前綴樹以插入新路徑。當完成的序列離開時,更新前綴樹以刪除其路徑。在每次解碼迭代中,我們將新token追加到葉子塊中,或者當葉子塊已滿時增加新塊。
通過共享公共前綴,ChunkAttention將可以同時處理的序列數量增加至約 1 / ( 1 ? r ) 1/(1-r) 1/(1?r)。共享比率r由共享token數 n s / ( n p + n c ) n_s/(n_p + n_c) ns?/(np?+nc?)定義,其中 n c n_c nc?是完成token數。在內存受限的推理場景中,這有助于增加批處理大小,從而提高吞吐量。
兩階段劃分(TPP)
在預填充期間,ChunkAttention執行前綴查找,以避免對匹配的提示前綴重復計算KV投影和位置嵌入。對于不匹配的后綴token,仍然計算KV投影和位置嵌入,并將鍵/值張量劃分并插入前綴樹中。然后,我們在整個鍵/值張量上應用現有的高度優化的自注意力內核,例如FlashAttention。
ChunkAttention中的分區策略是基于online softmax構建的,并受到FlashAttention的啟發。然而,FlashAttention在處理非連續內存或可變序列長度時不夠靈活,更適合于模型訓練而不是推理。在解碼過程中,當查詢token計數始終為1時,幾乎沒有收益。ChunkAttention擅長處理解碼期間可變的序列長度,并將幾個序列的注意力操作批處理以減少內存操作。因此,ChunkAttention和FlashAttention是互補的。
在迭代解碼過程中,自注意力計算被分為塊優先和序列優先兩個階段。這兩個階段關注查詢張量的不同切片、KV緩存塊,并使用不同的并行化策略。具有匹配提示前綴的序列的查詢張量被批處理在一起,與鍵/值張量一起執行注意力。
該過程如下圖所示。這里隱含了頭維度的處理。
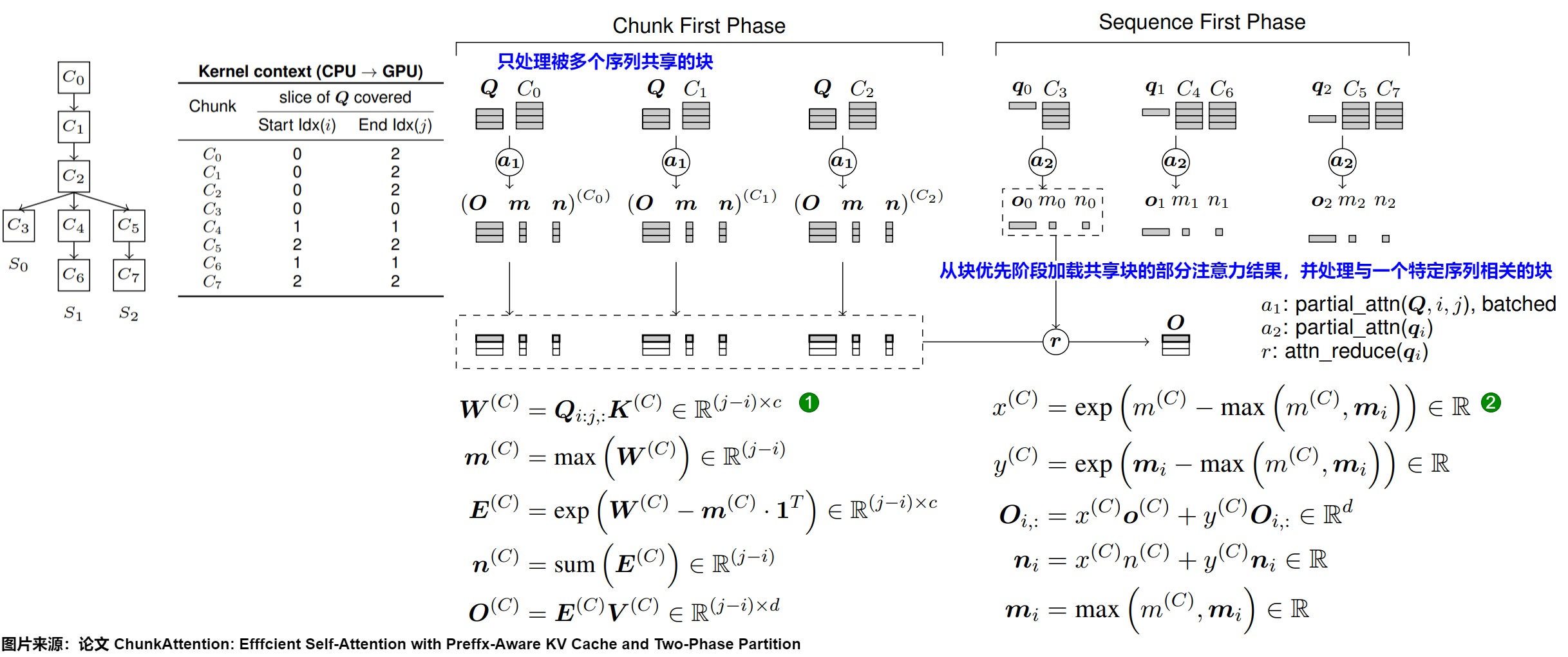
塊優先階段只處理被多個序列共享的塊。由于GPU具有比頭數(Llama 7B為32)更多的流式多處理器(A100為108),而通過頭進行劃分會低效利用硬件資源,因此我們會對鍵/值進行額外的劃分。具體算法如下圖所示:遍歷前綴樹中的共享塊,在遍歷中執行部分注意力內核partial_attn,并將部分注意力結果保存到內存中。

在序列優先階段,我們從塊優先階段加載共享塊的部分注意力結果,并繼續處理與一個特定序列相關的塊。我們通過切片Q的第i行來劃分序列,每個由序列優先內核處理的q都是一個向量,如下圖算法所示。

2.2.4 AttentionStore
AttentionStore允許在同一對話的后續輪次中重用KV緩存,從而有效減少了多輪對話中的重復計算開銷。為了提高AttentionStore的效率,其作者計了重疊KV緩存訪問、分層放置KV緩存和位置編碼解耦的KV緩存截斷方案。
動機
當前LLM服務引擎在執行多輪對話時存在顯著的效率問題,主要原因是多輪對話中KV緩存的重復計算。
在一次對話中,LLM引擎會將中間數據,即鍵值(KV)對,存儲在GPU上的高帶寬內存(HBM)中。然而,當對話結束且會話變得不活躍時,為了給其他活躍會話騰出空間,LLM引擎通常會丟棄與該會話相關的KV緩存。當同一個會話再次變得活躍(即用戶發送下一個消息)時,LLM引擎需要重新計算整個KV緩存。這就導致了同樣的KV緩存被重復計算,浪費了寶貴的GPU計算資源。隨著對話輪次的增加,重復計算的開銷也會線性增加。
如下圖(a)所示:在對話的第一個輪次,LLM服務引擎會生成q1和a1的KV緩存。然而,在完成第一個輪次后,為了回收HBM(高帶寬內存)空間,LLM服務引擎會丟棄這些KV緩存。在第二輪次中,LLM服務引擎需要重新生成q1和a1的KV緩存。在第三輪次中,它需要重新生成q1、a1、q2和a2的KV緩存。隨著會話的擴展,歷史token不斷積累,重復計算的開銷顯著增加。
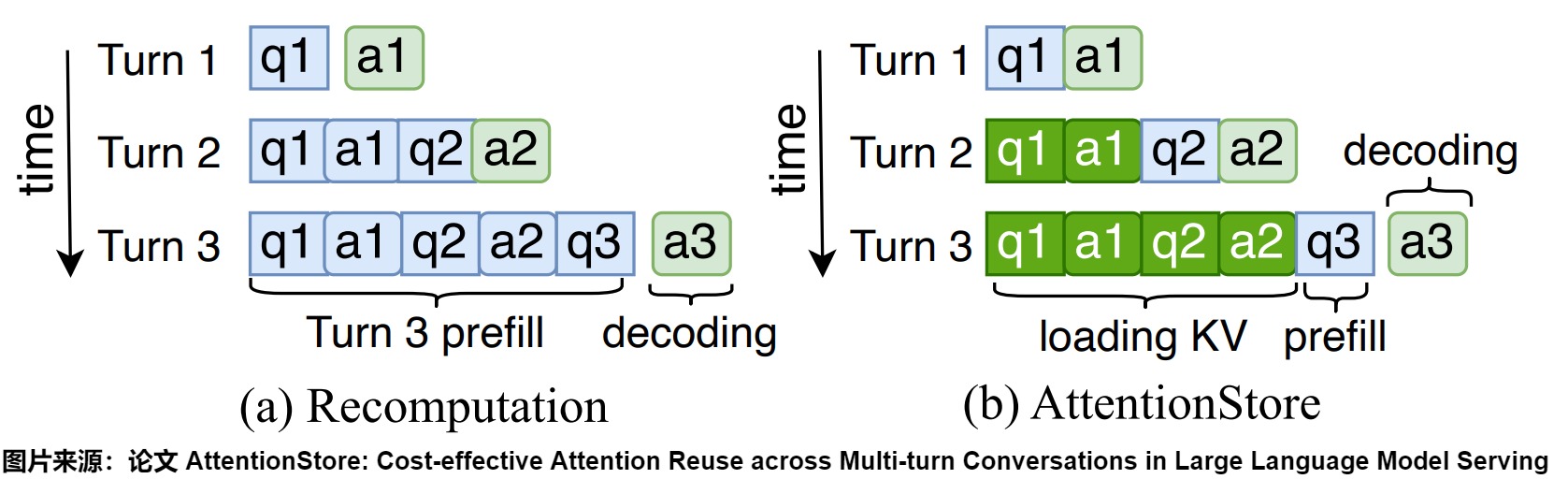
方案
AttentionStore引入了一個分層的KV緩存系統,利用成本效益高的存儲介質來保存所有請求的KV緩存,從而顯著提高了多輪對話的效率。
在傳統的注意力機制中,每次對話結束后,KV緩存都會被丟棄。AttentionStore將KV緩存保存在一個KV緩存系統中。當對話會話不活躍時,相關的KV緩存會被保存下來。如果同一會話在未來重新激活,其KV緩存將從KV緩存系統中獲取并重新用于推理。這樣,AttentionStore只需對新一輪對話中的新輸入token進行部分預填充,而無需重新預填充所有歷史token。例如,在執行第三輪對話推理時,q1、a1、q2和a2的KV緩存被復用,只需預填充q3,如上圖(b)所示。
另外,為了應對技術挑戰,AttentionStore也做了很多設計,通過這些設計,AttentionStore有效解決了多輪對話中的KV緩存管理問題,顯著提高了多輪對話的效率和性能。
- 為了減少從慢速存儲介質訪問KV緩存的開銷,AttentionStore采用了分層預加載和異步保存方案,將KV緩存的訪問與GPU計算重疊進行。
- 同時,為確保需要訪問的KV緩存始終處于最快速的層級,AttentionStore使用了調度感知的獲取和驅逐方案,根據推理任務調度器提供的提示,智能地將KV緩存放置在不同的層級中。
- 此外,AttentionStore通過解耦位置編碼和有效截斷KV緩存,避免了因上下文窗口溢出而導致的KV緩存失效。這一創新使得保存的KV緩存始終保持有效。
2.2.5 Radix Attention
SGLang論文提出的RadixAttention技術是實現KV緩存重用的典型方案之一,也是高效內存管理的代表。
與在生成請求完成后丟棄 KV 緩存的現有系統不同,RadixAttention會利用基數樹實現了緩存的快速匹配、插入和替換。而且,在RadixAttention中,無論是Prefix還是Generate階段產生的KV Cache,都會被緩存。這可以最大程度增加KV Cache被新請求復用的幾率。作為對比,ChunkAttention只聚焦在prefix本身。
思路
SGLang的Prefix Caching方案關鍵點如下:
- 跟以前那些“用完就扔”的系統不一樣,在每次處理完請求后,RadixAttention 算法不會在完成生成請求后丟棄KV緩存(提示符和生成的結果對應的KV Cache),而是將其保留在GPU內存中。
- RadixAttention 算法還將序列 token 與 KV Cache 之間的映射關系保存在 RadixTree 數據結構中。相較于傳統的字典樹(或稱前綴樹),Radix樹的邊不僅可以標記為單個元素,還可以標記為長度可變的元素序列。在必要的時候,一個已經在Tree中的大node可以動態地分裂成小node,以滿足動態shared prefix的需求。這一特性極大地加速了數據處理速度。
- 收到新請求時,調度器使用radix tree進行前綴匹配。如果有緩存命中,則調度器重用緩存的KV張量來滿足請求。
- 由于GPU內存有限,緩存的KV張量不能無限期保留。因此,RadixAttention算法包括一個驅逐策略(例如最近最少使用(LRU)驅逐策略)。最優緩存重用可能與像先來先服務這樣的調度不兼容。因此,RadixAttention配備了一個修改后的調度器,優先考慮與緩存前綴匹配的請求(緩存感知調度)。
方案
鑒于GPU內存資源寶貴且易于被迅速消耗的特點,不能永遠保留緩存的KV張量。為了讓緩存更加高效,RadixAttention還特別設計了兩種策略:
- “最近最少使用”(LRU)的淘汰策略。該策略優先移除那些最長時間未被訪問的葉子節點,給新的內容騰地方。通過這一策略,我們不僅有效釋放了被淘汰葉子節點所占用的內存,還充分利用了這些節點的共同祖先節點,實現內存的最大化復用。隨著系統運行,當這些祖先節點也變成孤立的葉子節點并符合淘汰條件時,它們同樣會被有序地逐出,從而保持整個緩存系統的健康與高效。
- 緩存感知的調度策略。我們將緩存命中率定義為已緩存提示token數除以提示token數(number of cached prompt tokens / number of prompt tokens)。當等待隊列中有許多請求時,執行請求的順序會顯著影響緩存命中率。例如,如果請求調度程序頻繁地在不同的、不相關的請求之間進行切換,則會導致高速緩存抖動和較低的命中率。因此,RadixAttention設計了一個具有緩存感知的調度算法來提高緩存命中率。這種算法會按匹配的前綴長度對請求進行排序,并優先處理具有較長匹配前綴的請求,而不是使用先到先服務的調度。
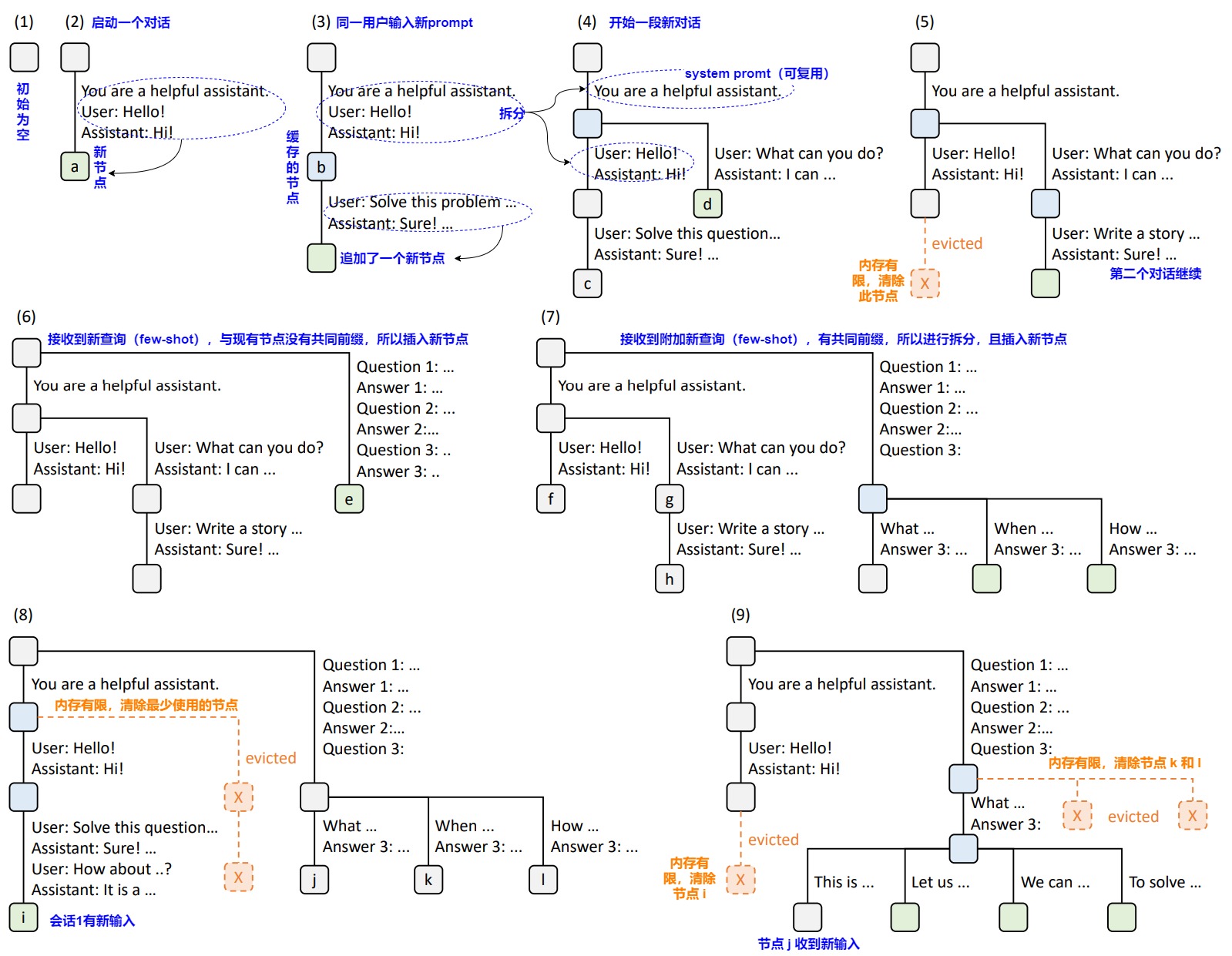
圖中(1)~(9)表示Radix Tree的動態變化。
整個樹結構表示對請求的共享和分支操作。每條邊都帶有一個標簽,代表子字符串或token序列。節點用顏色編碼以反映不同的狀態: 綠色表示新添加的節點,藍色表示在當前時間點內訪問的緩存節點,紅色表示已被驅逐的節點。新到達的請求會先從 Radix Tree 中匹配最長前綴,尋找最遠的一個節點。當請求仍有 Tokens 沒匹配到已有的前綴,則會新增 Token 子節點。每次新增 Token 時,將新增 Token 節點token為綠色,并將其前綴的節點token為藍色。這種token主要是更新節點的訪問時間,當緩存空間不足時,會將最近沒被訪問的節點清除。具體操作流程如下:
- 在步驟 (1) 中,基數樹最初為空。
- 在步驟 (2) 中,system prompt(系統提示)為“You are a helpful assistant”,服務器處理傳入的用戶消息“Hello”,并使用 LLM 輸出“hi”進行回復。整個對話(系統提示詞 “You are a helpful assistant.”,用戶消息“Hello”,以及 LLM 回復“hi”)被合并為一個大node,保存到Radix Tree的新節點a。
- 在步驟 (3) 中,同一個用戶輸入了一個新的prompt,服務器在基數樹中找到歷史對話前綴(即第一輪對話),并重新利用其 KV 緩存。新回合(Solve this problem…)作為新節點“b”被追加到樹中。
- 在步驟 (4) 中,開始新的聊天會話。服務器將 (3) 中的大節點“b”拆分為兩個節點"c"和”d”,以允許兩個聊天會話共享system prompt。
- 在步驟 (5) 中,第二個聊天會話繼續,用戶請求 “Write a story”。但是,由于內存限制,必須驅逐 (4) 中的節點“c”。新回合在 (4) 中被緩存到新的節點"d"。
- 在步驟 (6) 中,服務器收到一批小樣本學習查詢,這些查詢共享相同的小樣本示例集。服務器對其進行處理并將其插入樹中。因為新查詢與現有節點不共享任何前綴,所以根節點被拆分,生成節點“e”,以啟用共享。
- 在步驟 (7) 中,服務器收到一批其他的小樣本學習查詢。這些查詢和(6)共享相同的小樣本示例集,因此我們拆分 (6) 中的節點,插入新節點“f“,“g"和”h”。
- 在步驟 (8) 中,服務器從第一個聊天會話收到一條新消息。它驅逐了第二個聊天會話(節點“g”和“h”)中的所有節點,因為它們是最近最少使用的。
- 在步驟 (9) 中,服務器收到一個請求,以對 (8) 中節點“j”中的問題進行更多答案采樣。為了給這些請求騰出空間,我們驅逐了 (8) 中的節點“i”、“k”和“l”。
0x03 依據檢索的方案
依據檢索的方案是一種更為激進的策略:如果GPU內存不足,就將KV Cache存儲于更豐富但速度較慢的外部設備,甚至可能是另一種存儲介質上。這種方法將KV Cache管理轉變為一項檢索挑戰,即按需檢索相關鍵值對并重新集成到模型中。雖然這能減少主設備上的內存使用,但會增加檢索和集成過程的復雜性。
3.1 InfiniGen
現代LLM服務系統(DeepSpeed Inference & FlexGen)支持將數據卸載到CPU內存中,以便在有限的硬件預算內高效地為LLMs提供服務。這些基于卸載的推理系統甚至開始支持將KV Cache卸載到CPU內存中,從而允許用戶在GPU內存容量之外生成更長的上下文。然而,因為CPU和GPU之間的PCIe帶寬較低,將龐大的KV Cache從CPU內存傳輸到GPU成為LLM推理中新的性能瓶頸。
論文“InfiniGen: Efficient generative inference of large language models with dynamic KV cache management”通過預測機制,將KV Cache的主要部分卸載到CPU上,僅保留關鍵組件。在有新請求時,InfiniGen利用有限保留的信息(利用從上一層查詢選擇的重要KV條目的索引來檢索當前層中的KV緩存條目)來推測性地將一小部分KV Cache重新加載到GPU上,從而在不影響性能的前提下,節省高速計算設備的內存空間,同時避免大量數據交換。
InfiniGen是為了解決Offload中由于PCIe帶寬不足帶寬的推理延遲增加的問題。只是最后的解決方案是從算法的角度出發的。主要是節省decode的時間。
問題
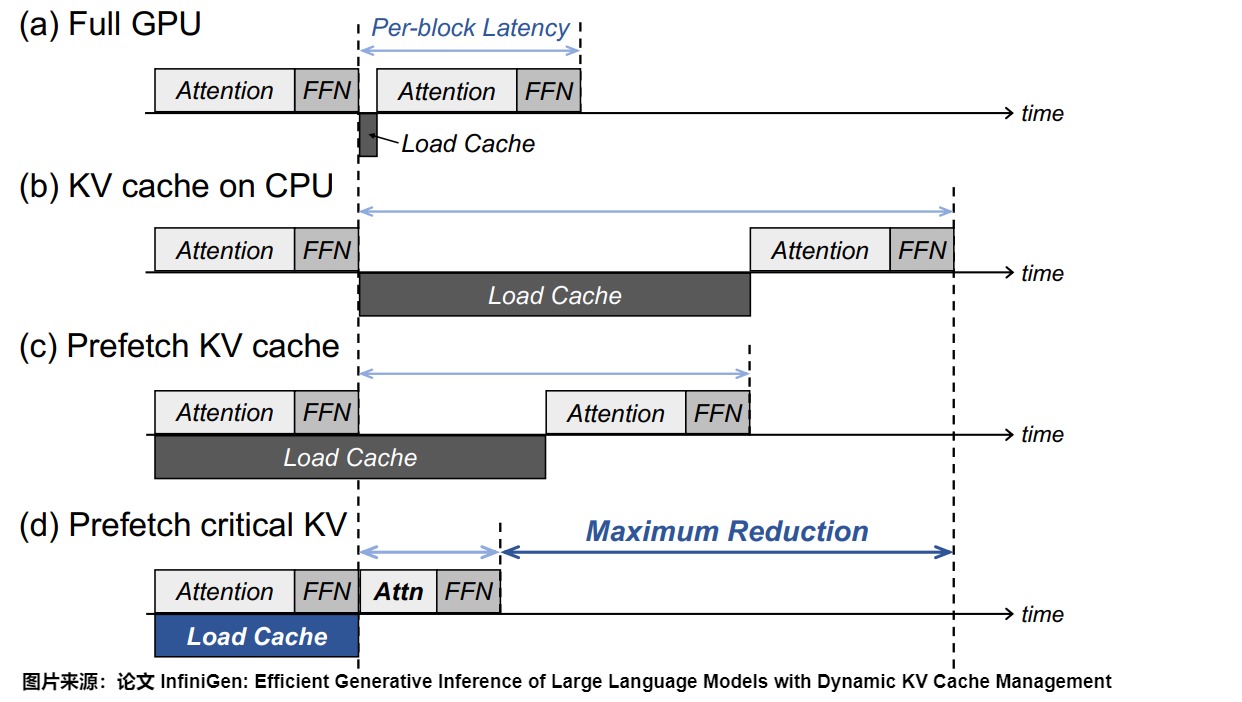
下圖展示了不同方式來執行Transformer塊的高層時序圖,從中可以看出性能瓶頸。
- (a) 表示KV Cache完全位于GPU內存中的情況。在這種情況下,KV Cache的加載延遲(Load Cache)僅涉及從GPU內存讀取操作,由于GPU內存的高帶寬,這個延遲幾乎可以忽略不計。然而,最大批量大小或序列長度受限于GPU內存容量,而GPU內存容量通常比CPU內存要小。
- (b)表示將KV Cache卸載到CPU內存中(KV Cache在CPU上)。盡管基于卸載的推理系統緩解了批量大小和序列長度的限制(可以支持更大的批量大小或更長的序列長度),但由于PCIe帶寬的限制,將數百GB的KV Cache傳輸到GPU進行注意力計算會顯著增加Transformer塊的整體執行時間。
- ?表示傳統的預取技術(預取KV Cache)。在這種情況下,只有部分加載延遲能夠被前一個Transformer塊的計算所隱藏。雖然通過量化壓縮KV Cache可能會在基于卸載的系統中減少數據傳輸的開銷, 但這并不能解決根本問題,因為量化并未解決KV Cache問題的根本原因——即KV條目隨著序列長度的線性增長。因此,必須進行智能的KV Cache管理,以減輕性能開銷,同時保留其優勢。
- (d)表示通過識別計算注意力得分的關鍵鍵和值,減少需要加載的KV Cache量。在注意力計算中,某些tokens的鍵和值比其他token更為重要。如果選擇適當的token,跳過一些不太關鍵token的注意力計算并不會顯著降低模型的準確性。
洞察
InfiniGen的核心洞察在于,通過對當前層輸入以及后續層部分查詢權重和鍵緩存進行最小限度的回顧,可以推測出對后續Transformer注意力層計算至關重要的少數關鍵token。這一方法使我們能夠僅預取必要的KV Cache條目(而非全部),從而緩解了基于卸載的LLM服務系統中從主機內存獲取數據時的開銷。
大型語言模型中的異常值
大型語言模型在Transformer塊的輸入張量中存在異常值。這些異常值指的是與其他元素相比,具有明顯更大數值的元素。在LLMs中,這些異常值會在層與層之間出現在少數固定的通道上(即二維矩陣中的列)。模型輸入的任何一行與權重矩陣(如 W K W^K WK)的一列之間的點積可能具有同樣大的幅度,這又導致了查詢和鍵矩陣中的異常值通道。
注意力分數就高度依賴于查詢和鍵矩陣中這少數具有較大幅度的幾列。這些大幅度列對注意力模式有很大影響,是因為查詢和鍵之間的點積高度受這些少數幾列的影響。
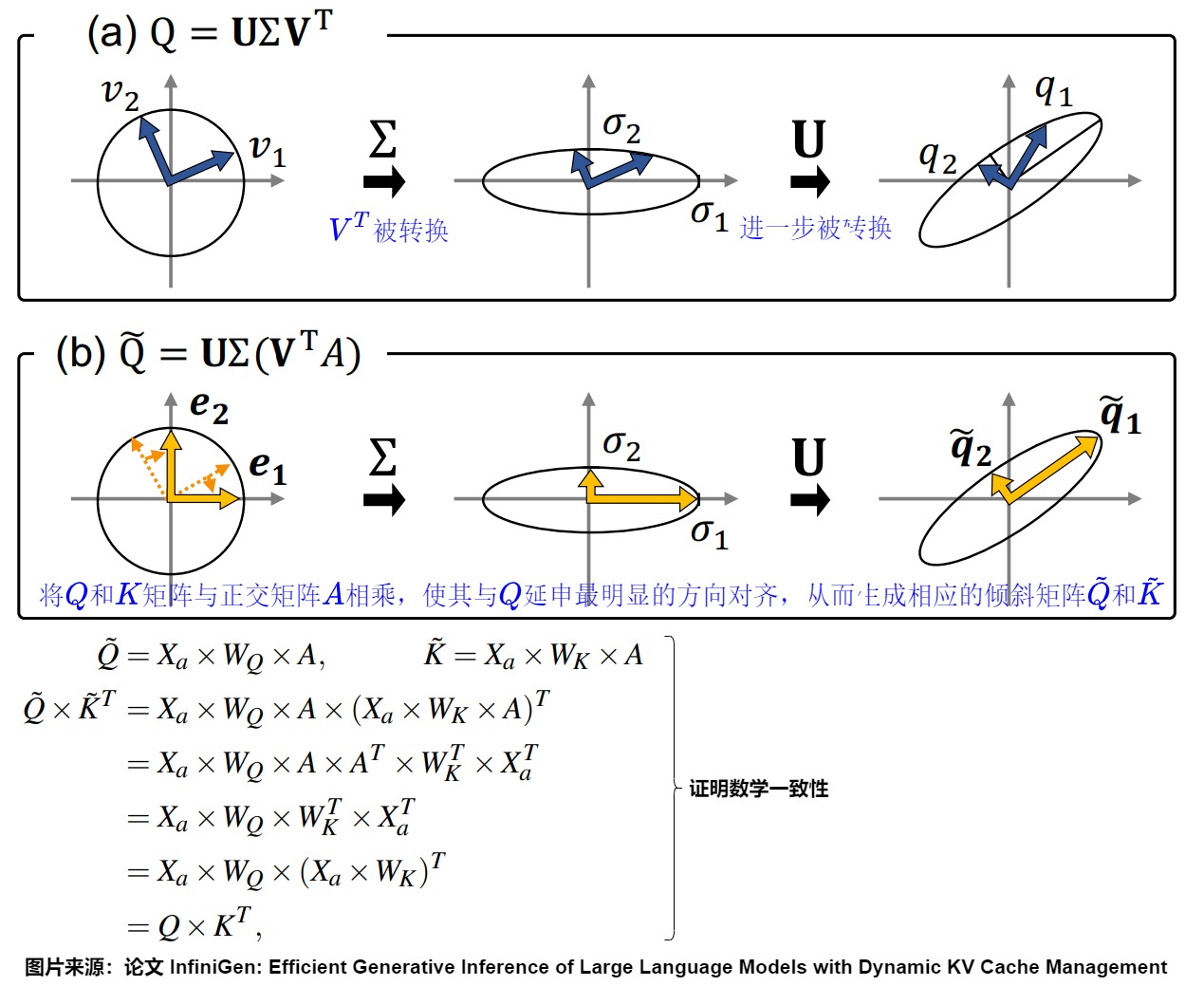
InfiniGen作者觀察到,通過傾斜查詢(Query)和鍵(Key)矩陣,使得一小部分通道遠大于其他通道,并僅利用這些通道來計算注意力得分矩陣,可以有效地預測哪些token是重要的。本質上,我們將Q和K矩陣與正交矩陣A相乘,使其與Q拉伸最明顯的方向對齊,從而生成相應的傾斜矩陣Q和K。
為了找到這樣的正交矩陣A,我們采用了奇異值分解(Singular Value Decomposition,簡稱SVD),這是線性代數中廣泛使用的矩陣因式分解技術。對于一個大小為m×n的實數矩陣Q,其SVD分解可以表示為如下形式:
Q = U Σ V ? \mathbf{Q} = \mathbf{U} \mathbf{Σ} \mathbf{V}^{\top} Q=UΣV?
其中,U和V分別是大小為m×m和n×n的正交矩陣,Σ是一個m×n的對角矩陣,其對角線上的非零值(σ1,σ2,…,σk)表示奇異值,其中k = min(m,n)。
例如,下圖展示了當m和n都為2時, V T V^T VT的列向量v1和v2如何變換為Q的列向量q1和q2。在(a)中,正交單位向量v1和v2首先被拉伸到橢圓上的點,這些點的半軸長度對應于Σ對角線上的元素。然后,這些向量通過矩陣U進行旋轉和/或反射,變成q1和q2。另一方面,(b)展示了正交矩陣A如何進行旋轉,使得得到的q1遠大于q2。具體來說,A將向量v1和v2旋轉到e1和e2,它們分別映射到橢圓的半軸上。這樣,向量就通過Σ矩陣被拉伸到最大和最小值。這個過程強調了q1相對于q2的幅度,使得我們能夠有效地僅使用q1來預測注意力得分,而忽略q2。
設計
InfiniGen建立在兩個關鍵設計原則之上。
- 首先,在計算Layer i-1 層的時候,同時計算出第 i 層需要哪些token的kv cache。即推測并選擇對產生下一個輸出token至關重要的KV Cache條目,同時丟棄非關鍵條目。
- 其次,它利用CPU內存容量,在CPU上維護KV Cache池,而不是在GPU上,以確保在緩解長內容生成中GPU內存容量有限問題的同時,能夠為大窗口大小的所有輸出和層識別關鍵的KV Cache值。
總體方案
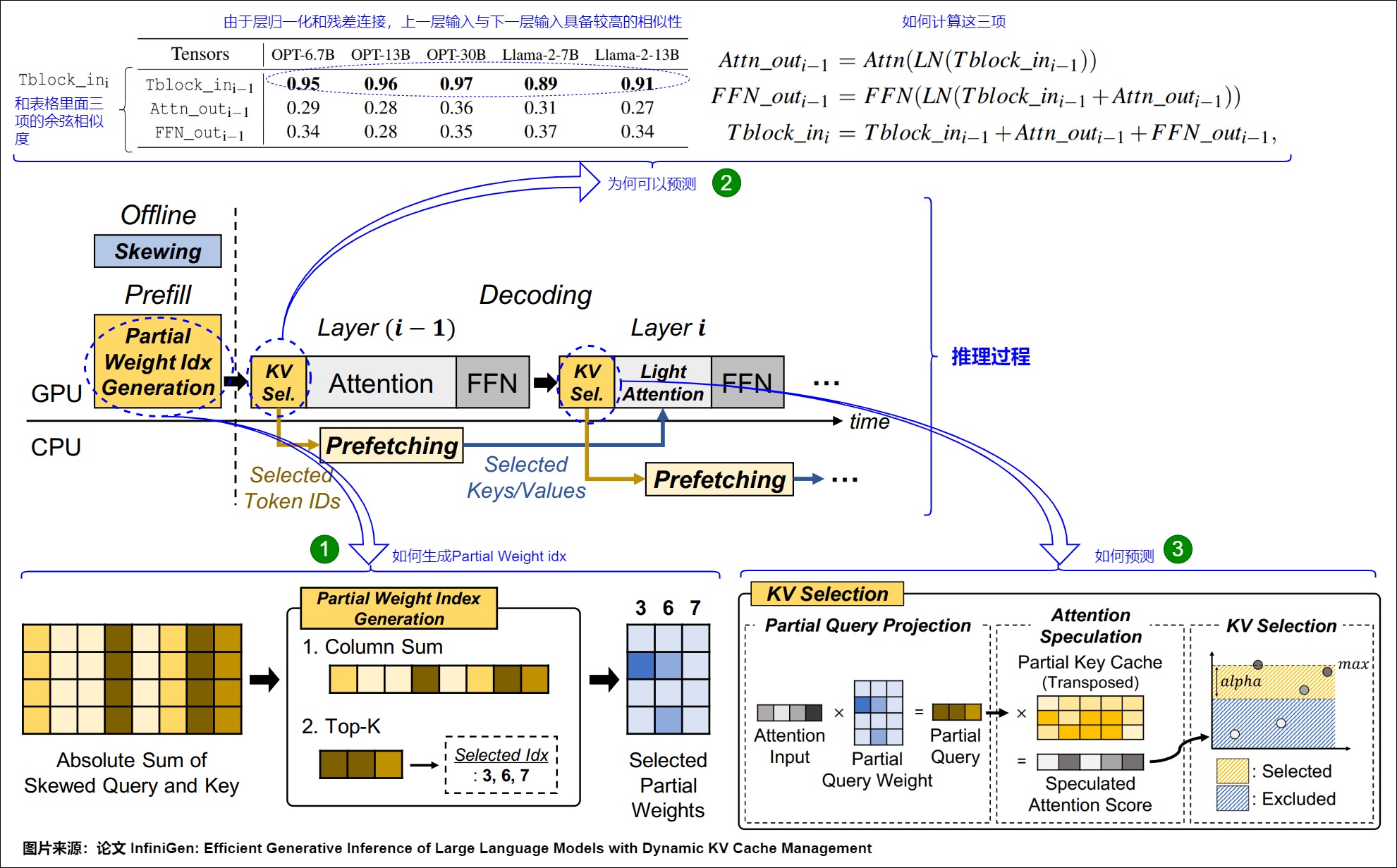
下圖展示了InfiniGen的操作流程。
離線階段
在離線階段,InfiniGen修改權重矩陣以生成偏斜的查詢和鍵矩陣。為了實現這一點,InfiniGen首先使用樣本輸入執行模型的前向傳遞一次。在此過程中,InfiniGen從每一層收集查詢矩陣,并對每個查詢矩陣執行奇異值分解(SVD)。使用查詢矩陣的分解矩陣獲得每一層的偏斜矩陣(Ai)。然后,將該偏斜矩陣與相應層中的每個查詢和鍵權重矩陣相乘,得到偏斜的查詢和鍵矩陣。
需要注意的是:
-
偏斜不會改變原始功能。即使在偏斜之后,注意力層也會產生相同的計算結果。
-
偏斜是一個一次性的離線過程,并且不會在運行時產生任何開銷,因為我們修改的是運行時不變的權重矩陣。
-
由于我們利用了列模式,這種模式源自模型的固有屬性而非輸入,因此在偏斜之后,無論我們為不同的輸入計算查詢和鍵,其值都會表現出高度的偏斜性,從而提高了我們預取模塊的有效性。
上圖標號1 展示了InfiniGen如何創建這些部分矩陣。
Prefill階段
在預填充階段,InfiniGen從查詢權重矩陣和鍵緩存中選擇幾個重要的列,以推測注意力模式,并生成在解碼階段使用的部分查詢權重和鍵緩存矩陣。
InfiniGen的預取模塊建立在以下關鍵觀察之上,大型語言模型(LLMs)中連續注意力層的注意力輸入高度相似。Transformer模型中連續層的注意力輸入之所以具有相似性,主要是因為層歸一化(LayerNorm)和殘差連接(Residual Connections)的作用。層歸一化減少了輸入數據的尺度差異,使得各層的輸入在數值上更加接近。而殘差連接使得每一層的輸出都直接加回到輸入上,這進一步增強了層與層之間輸入的相似性。因此,盡管每一層都會處理輸入并產生新的輸出,但由于層歸一化和殘差連接的存在,這些輸出在作為下一層輸入時,仍然保留了與上一層輸入較高的相似性。
此處對應圖上標號2。
解碼階段
標號3 展示了InfiniGen如何計算推測的注意力分數。
解碼階段:在解碼階段,InfiniGen推測下一層的注意力模式,并確定要預取的關鍵鍵和值。
在層i-1中,我們使用在預填充階段確定的層i的部分查詢權重矩陣和鍵緩存,以及層i-1的注意力輸入。在將部分查詢和部分鍵緩存相乘后,InfiniGen僅預取注意力分數大于最高注意力分數減去α的token的鍵和值。由于多個注意力頭是并行計算的,我們確保同一層中的每個頭通過平均各個頭之間最高分數和閾值之間的token數來預取相同數量的token。
通過減少需要加載和計算的鍵值(KV)緩存量,InfiniGen有效地降低了加載延遲(即從CPU到GPU的數據傳輸時間),同時保持了與具有完整KV Cache的原始模型相似的輸出質量。此外,由于InfiniGen不需要從CPU內存中加載固定數量的token,因此它僅利用必要的PCI互連帶寬。InfiniGen從第1層開始進行推測和預取,因為在第0層的計算過程中會出現對于利用輸入相似性至關重要的異常值。
KV Cache資源池管理
我們將鍵值(KV)緩存管理為一個池,將其卸載到CPU內存中,并僅將必要數量的數據預取到GPU中。雖然CPU內存的成本更低且容量大于GPU內存,但其容量仍然有限。因此,在某些部署場景中,限制KV Cache池的大小并移除那些由查詢token不常選擇的、重要性較低的KV條目可能至關重要。我們擴展了設計,以納入用戶定義的內存大小限制。在運行時,當CPU內存的大小達到用戶定義的限制時,KV Cache池管理器會選擇一個受害者KV條目進行逐出。隨后,管理器會用新生成的鍵和值覆蓋選定的受害者條目,并更新GPU中相應的部分鍵緩存。需要注意的是,KV條目的順序可以是任意的,只要相同token的鍵和值在KV Cache池中保持相同的相對位置即可。
選擇受害者(即要被逐出的KV條目)的策略非常重要,因為它直接影響模型的準確性。我們考慮了基于計數器的策略以及兩種廣泛使用的軟件緩存逐出策略:先進先出(FIFO)和最近最少使用(LRU)。
0xEE 個人信息
★★★★★★關于生活和技術的思考★★★★★★
微信公眾賬號:羅西的思考
如果您想及時得到個人撰寫文章的消息推送,或者想看看個人推薦的技術資料,敬請關注。

0xFF 參考
Z. Zheng, X. Ji, T. Fang, F. Zhou, C. Liu, and G. Peng, “Batchllm: Optimizing large batched llm inference with global prefix sharing and throughput-oriented token batching,” 2024. [Online]. Available: https://arxiv.org/abs/2412.03594
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y. Sheng, “Sglang: Efficient execution of structured language model programs,” 2024. [Online]. Available: https: //arxiv.org/abs/2312.07104
L. Ye, Z. Tao, Y. Huang, and Y. Li, “Chunkattention: Efficient selfattention with prefix-aware kv cache and two-phase partition,” 2024. [Online]. Available: https://arxiv.org/abs/2402.15220
C. Hu, H. Huang, J. Hu, J. Xu, X. Chen, T. Xie, C. Wang, S. Wang, Y. Bao, N. Sun, and Y. Shan, “Memserve: Context caching for disaggregated llm serving with elastic memory pool,” 2024. [Online]. Available: https://arxiv.org/abs/2406.17565
GPU加速LLM論文夸贊|InfiniGen通過動態KV Cache管理高效實現LLM的生成式推理:動機 GPUer
llm 推理 latency 分析
ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition 趙尚春
AttentionStore: Cost-effective Attention Reuse across Multi-turn Conversations in* *Large Language Model Serving
Modular Attention Reuse for Low-Latency Inference(@yale.edu)
論文: 《Efficiently Programming Large Language Models using SGLang》
ZigZagKV,KVCache80%的壓縮率可以達到近乎無損的效果
ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition(@microsoft.com)
Efficient Prompt Caching via Embedding Similarity(@UC Berkeley)
Modular Attention Reuse for Low-Latency Inference(@yale.edu)
33 倍 LLM 推理性能提升:Character.AI 的最佳實踐
[CLA] Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
[GQA] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
[KV Cache優化]🔥MQA/GQA/YOCO/CLA/MLKV筆記: 層內和層間KV Cache共享 DefTruth
[LLM 推理服務優化] DistServe速讀——Prefill & Decode解耦、模型并行策略&GPU資源分配解耦 阿杰
[LLM]KV cache詳解 圖示,顯存,計算量分析,代碼 莫笑傅立葉
[LLM性能優化]聊聊長文本推理性能優化方向 阿杰
[MLKV] MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
[MQA] Fast Transformer Decoding: One Write-Head is All You Need
[Prefill優化][萬字]🔥原理&圖解vLLM Automatic Prefix Cache(RadixAttention): 首Token時延優化 DefTruth
[YOCO] You Only Cache Once: Decoder-Decoder Architectures for Language Models
A Survey on Efficient Inference for Large Language Models
akaihaoshuai
Cascade Inference: Memory Bandwidth Efficient Shared Prefix Batch Decoding
Confused with four attention mechanism and their performance mentioned by paper · Issue #33 · mit-han-lab/streaming-ll
Continuous Batching:一種提升 LLM 部署吞吐量的利器 幻方AI
DejaVu:KV Cache Streaming For LLM
Efficient Streaming Language Models with Attention Sinks
GPT模型與K/V Cache導讀 皓月爭曦
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
https://lmsys.org/blog/2024-01-17-sglang/
Hydragen: High-Throughput LLM Inference with Shared Prefixes(@Stanford University)
Inference without Interference:混合下游工作負載的分離式LLM推理服務 竹言見智
kimi chat大模型的200萬長度無損上下文可能是如何做到的? [GiantPandaCV](javascript:void(0)😉
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
LaViT:這也行,微軟提出直接用上一層的注意力權重生成當前層的注意力權重 | CVPR 2024 VincentLee
LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
LLaMa 原理+源碼——拆解 (KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query Attention, SwiGLU) Yuezero_
LLM Inference Series: 3. KV caching unveiled
LLM 推理優化探微 (2) :Transformer 模型 KV 緩存技術詳解 Baihai IDP
LLM 推理優化探微 (3) :如何有效控制 KV 緩存的內存占用,優化推理速度? Baihai IDP
LLM推理入門指南②:深入解析KV緩存 OneFlow
LLM推理加速02 KV Cache 沉思的斯多葛九狗
LLM推理加速3:推理優化總結Mooncake/AttentionStore/vllm0.5/cache優化 etc
LLM推理加速調研 akaihaoshuai
LLM推理算法簡述 陸淳
MiniCache 和 PyramidInfer 等 6 種優化 LLM KV Cache 的最新工作 AI閑談
MLKV:跨層 KV Cache 共享,降低內存占用
MLSys 2024 Keyformer:選擇關鍵token,降低50%KV 緩存 MLSys2024 [MLSys2024](javascript:void(0)😉
MODEL TELLS YOU WHAT TO DISCARD: ADAPTIVE KV CACHE COMPRESSION FOR LLMS
Mooncake (1): 在月之暗面做月餅,Kimi 以 KVCache 為中心的分離式推理架構 ZHANG Mingxing
Mooncake (2):Kimi “潑天的流量”怎么接,分離架構下基于預測的調度策略 ZHANG Mingxing
Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving 手抓餅熊
Orca: How to Serve Large-scale Transformer Models WXB506
OSDI22 ORCA:LLM Serving系統優化經典之作,動態batch,吞吐提升36倍 MLSys2024
OSDI24最新力作:InfiniGen大模型推理高效KV緩存管理框架,吞吐提升3倍,準確性提升32% MLSys2024
SnapKV: KV Cache 稀疏化,零微調加速長序列 LLM 推理 AI閑談
SnapKV: LLM Knows What You are Looking for Before Generation
Token 稀疏化 + Channel 稀疏化:16 倍 LLM 推理加速 AI閑談
Transformers KV Caching Explained
TriForce:KV Cache 稀疏化+投機采樣,2.3x LLM 無損加速
vAttention:用于在沒有Paged Attention的情況下Serving LLM BBuf
YOCO:長序列優化,1M 長文本10x LLM 推理加速 AI閑談
You Only Cache Once: Decoder-Decoder Architectures for Language Models
ZHANG Mingxing:Mooncake (1): 在月之暗面做月餅,Kimi 以 KVCache 為中心的分離式推理架構
【手撕LLM- KV Cache】為什么沒有Q-Cache ?? 小冬瓜AIGC
一文讀懂KVCache 游凱超
為什么加速LLM推斷有KV Cache而沒有Q Cache? DefTruth
全面解析 LLM 推理優化:技術、應用與挑戰 AI閑談
關于 Mooncake 的碎碎念 許欣然
刀刀寧:筆記:Llama.cpp 代碼淺析(一):并行機制與KVCache
刀刀寧:筆記:Llama.cpp 代碼淺析(二):數據結構與采樣方法
分析 GPT 模型自回歸生成過程中的 KV Cache 優化技術 sudit
圖解Mixtral 8 * 7b推理優化原理與源碼實現 猛猿
圖解大模型計算加速系列:分離式推理架構1,從DistServe談起 猛猿
圖解大模型計算加速系列:分離式推理架構2,模糊分離與合并邊界的chunked-prefills 猛猿
圖解大模型計算加速系列:分離式推理架構2,模糊分離與合并邊界的chunked-prefills 猛猿
大模型并行推理的太祖長拳:解讀Jeff Dean署名MLSys 23杰出論文 方佳瑞
大模型推理優化–Prefill階段seq_q切分 kimbaol
大模型推理優化實踐:KV cache復用與投機采樣 米基 [阿里技術](javascript:void(0)😉
大模型推理優化技術-KV Cache [吃果凍不吐果凍皮](https://www.zhihu.com
/people/liguodong-iot)
大模型推理加速:KV Cache Sparsity(稀疏化)方法 歪門正道
大模型推理加速:看圖學KV Cache 看圖學
大模型推理性能優化之KV Cache解讀 Young
大模型百倍推理加 速之KV Cache稀疏篇 zhang
大白話解說Continous Batching Gnuey Iup
大語言模型推理性能優化綜述 Young
微軟 MInference:百萬 Token 序列,10x 加速
思辨|H2O: 從緩存視角解決LLM長上下文問題 DSTS Center [數據空間技術與系統](javascript:void(0)😉
打造高性能大模型推理平臺之Prefill、Decode分離系列(一):微軟新作SplitWise,通過將PD分離提高GPU的利用率 哆啦不是夢
打造高性能大模型推理平臺之Prefill、Decode分離系列(一):微軟新作SplitWise,通過將PD分離提高GPU的利用率 哆啦不是夢
月之暗明的月餅:以KVCache為中心,分離式推理架構,LLM吞吐能力飆升75%
極限探索:LLM推理速度的深度解析 MLSys2024
歪門正道:魔改KV Cache,讓大模型無限輸出!
符堯博士-全棧Transformer推理優化第二季:部署長上下文模型-翻譯 強化學徒
聊聊大模型推理中的分離式推理 刀刀寧
聊聊大模型推理服務中的優化問題 刀刀寧
阿杰:vLLM & PagedAttention 論文深度解讀(一)—— LLM 服務現狀與優化思路
高效生成:Splitwise論文解讀
https://yaofu.notion.site/Full-Stack-Transformer-Inference-Optimization-Season-2-Deploying-Long-Context-Models-ee25d3a77ba14f73b8ae19147f77d5e2#d03b8a2a583246cea5a1fdeb8f583586
Longformer
Efficient Streaming Language Models with Attention Sinks
https://www.evanmiller.org/attention-is-off-by-one.html?continueFlag=5d0e431f4edf1d8cccea47871e82fbc4
Massive activations in large language models. arXiv preprint arXiv:2402.17762, 2024. Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu.
PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
ZigZagKV,KVCache80%的壓縮率可以達到近乎無損的效果 杜凌霄
SnapKV: LLM Knows What You are Looking for Before Generation
FastGen:Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
[Prompt Cache]: Modular Attention Reuse for Low-Latency Inference(@yale.edu)
[Cache Similarity]: Efficient Prompt Caching via Embedding Similarity(@UC Berkeley)
[Shared Prefixes]: Hydragen: High-Throughput LLM Inference with Shared Prefixes(@Stanford University)
[ChunkAttention]: ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition(@microsoft.com)
ClusterKV,接近無損的KV Cache壓縮方法 杜凌霄
圖解大模型計算加速系列:分離式推理架構2,模糊分離與合并邊界的chunked-prefills 猛猿
《基于KV Cache管理的LLM加速研究綜述》精煉版 常華Andy
[KV Cache優化]🔥MQA/GQA/YOCO/CLA/MLKV筆記: 層內和層間KV Cache共享 DefTruth
Venkat Raman. Essential math & concepts for llm inference, 2024. URL https://venkat.e u/essential-math-concepts-for-llm-inference#heading-insights-from-model-lat ency-amp-understanding-hardware-utilization-on-modern-gpus.
Yao Fu. Challenges in deploying long-context transformers: A theoretical peak performance analysis. arXiv preprint arXiv:2405.08944, 2024
GQA,MLA之外的另一種KV Cache壓縮方式:動態內存壓縮(DMC) BBuf
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding 灰瞳六分
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding





)





`方法可能出現的超時問題)







