目錄
前言:
分布式系統
開源節流
認識Redis
負載均衡
緩存
微服務
前言:
本文只是作為Redis的一篇雜談,簡單理解一下Redis為什么要存在,以及它能做到和它不能做到的事兒,簡單提及一下它對應的優勢有什么,不足有什么之類的。
總之,本文只是Redis入門的雜談,咱們看看即可~
分布式系統
首先提到Redis,咱們除了能想到它快之外,還應該能想到分布式系統,即便沒有系統學習過Redis的同學,對于Redis的第一印象大概率就是它能應用在分布式系統上。
那么什么是分布式系統呢?
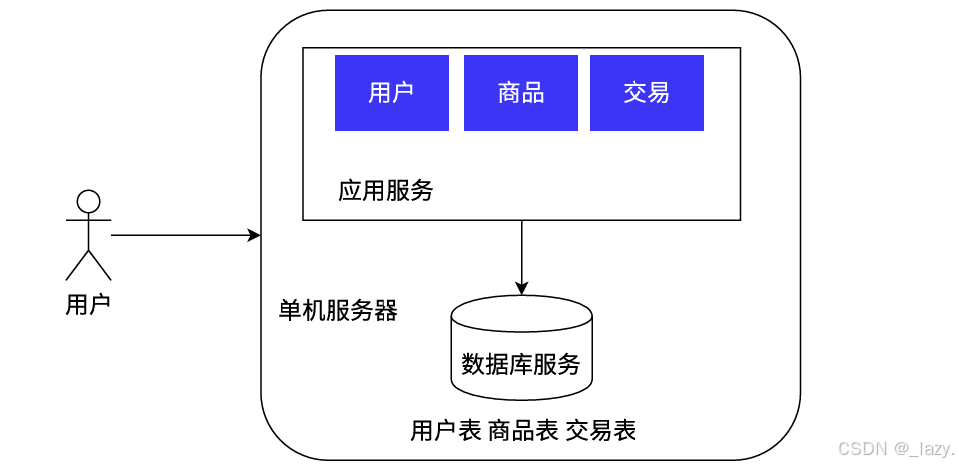
我們從最簡單的單機架構開始談。
其實到目前為止,挺多公司用的還是單機架構的服務器,什么是單機架構呢?就是上層的應用服務和數據庫服務都是由一個服務器來完成的。那么這個服務器就會面臨一個老生常談的問題,它這個單機服務器面臨大的吞吐量的時候怎么辦?
所以當數據量大起來的時候,一臺單機服務器就沒有辦法處理這么多的數據量,我們就可以引入其他服務器來幫助原來的單機服務器處理多余的數據量。
那么問題來了,我們是將服務器直接通上電,然后就可以直接運行,甚至可以直接處理數據了嗎?顯然并不是。
在引入了多臺主機的情況下,我們勢必面臨的問題是不僅有服務器和服務器之間的連接問題,甚至有了人與人之間的資源調度問題。因為多臺主機,代碼量幾乎是按照指數級增加的,所以前期的代碼開發,到后期的代碼維護,開發人員運維人員的調度明顯是一個問題。
我們從最簡單的分布式開始入手,最開始一臺服務器處理應用服務和數據庫存儲服務,那么我們思考,是否可以將數據庫存儲服務和應用服務分開:
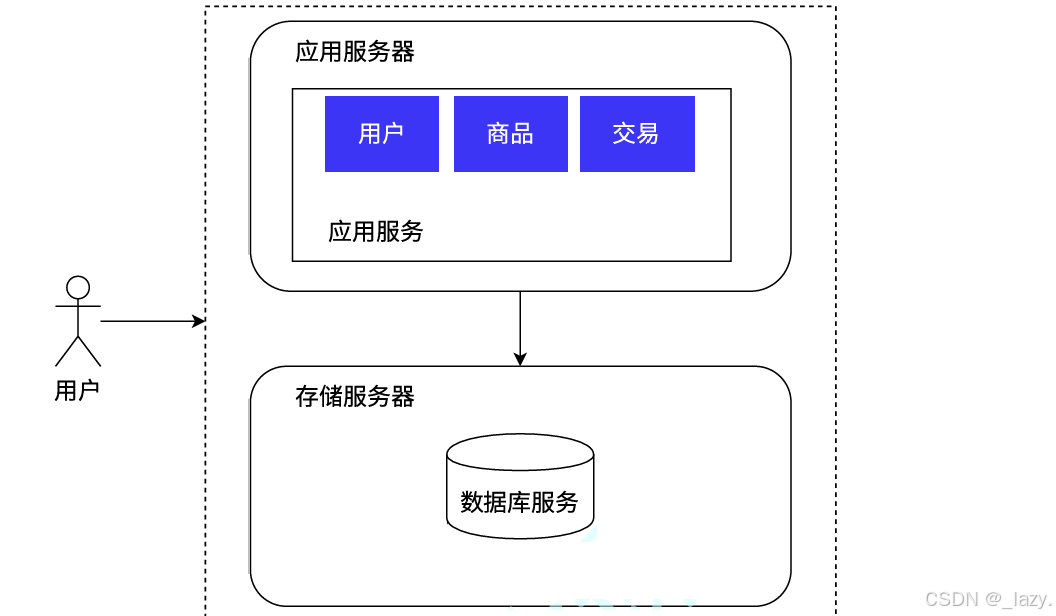
就像這樣,我們就擁有了兩臺主機,一臺是應用服務器的主機,一臺是存儲服務器的主機,一個專門用來處理應用的上層請求,一個專門用來處理數據庫的服務。
到現在,最最基本的分布式架構已經出來了,那么我們把數據量往上增加的過程,勢必會有一種煩惱:硬件資源和軟件資源如何增加?
開源節流
到了這個時候,面對非常龐大的數據量的時候,硬件資源反而是最好提升的,因為服務器處理請求的時候,吃的資源無非就是CPU,內存,硬盤,網絡等資源,所以面對硬件資源,我們可以這樣提升:主板上面多插幾塊CPU,多插幾塊內存,硬盤等同理,對于網絡來說我們可以提升網絡帶寬,可以更換網卡,從萬兆網卡更換成千兆網卡。
到這里,我們就簡單理解了開源節流中的開源,即非常簡單粗暴的增加硬件資源,無腦堆就行,但是我們仍然面臨的問題是,主板中的位置是有限的,也就是說硬件資源是沒有辦法無線堆積的,那么有人就說了,堆積主板唄,只能說想法是美好的,畢竟硬件資源最耗費的就是錢財了~~
那么開源的時候預算到了一定程度,沒有辦法了,我們是否應該考慮一下涉及到人工成本的節流?
比如Redis存儲熱點數據的時候,我們使用的是什么數據結構?這樣操作下來時間復雜度是多少?空間復雜度是多少?是否還有更多的空間進行優化?
此時就涉及到了人工的優化了,可是隨著服務器規模的增大,代碼量增大的可不是一點半點,那么人工成本就非常大了,并且改錯了一個bug可能就伴隨著n個Bug。
所以其實從這里就可以看到,分布式并不是一件太完美的事,雖然增加了數據量的處理,但是處理的成本是真的大~~
認識Redis
當我們訪問Redis的官方網站的時候,我們大概率能搜索到以下的關鍵字:in-memory data store, cache, streaming engine, message broker。

翻譯過來就就是存儲在內存的數據,緩存,流式引擎,消息隊列。
即我們可以理解為Redis可以做的事兒有以上這么多,當然實際上比這些多多了,不過你說Redis能做這么多,是因為它一發明出來就能做這么多事兒嗎?
顯然不是,最開始Redis的初心只是為了作為消息中間件,即用在消息隊列上面,那么這里就涉及了生產消費模型,最開始人們用了一段時間后,發現Redis好像不止可以用在消息隊列上,比如應用在流式引擎上好像更香。
所以到這里咱們簡單理解呢就是Redis最開始發明出來之后發現應用在其他領域好像也是個香餑餑,也就拿去開發了,不過目前的消息隊列呢很少有直接使用Redis作為中間件的,有很多其他著名的中間件,咱們可以上網搜搜~
咱們拿MySQL和Redis來講,MySQL最大的缺點就是訪問慢,數據量一起來,訪問速度是會有顯著的下降的,而巧了,Redis也可以當作數據庫使用,那么我們是不是就可以把MySQL踢出去,直接使用Redis呢?
顯然不能,MySQL慢是慢了點,但是人家的存儲量比Redis大到哪里去了,那么為什么Redis快呢?因為它是將數據存儲到了內存里面。
既然是存儲到了內存里面,那么按照訪問速度金字塔,CPU是最快的,然后是一級緩存二級緩存三級緩存等,最慢的是硬盤,而MySQL讀寫都是在硬盤,Redis讀寫都是在內存,你說這速度差的多不多吧!!
而對于Redis來說,還有一個獨特的點是它可以進行網絡通信,即將自己的內存數據通過網絡發送到其他主機上,這就很強了,不過有的時候也會受限于網絡等問題。咱們學習進程的時候都知道有一個東西叫做進程的隔離性,而對于Redis來說,它能進行進程間通信,即網絡通信,你說它強不強?
好了,我們簡單比較了以下MySQL和Redis的區別之后,我們是否會思考,有沒有存儲量大且速度快的方案?
顯然是有的,我們明顯可以結合MySQL和Redis使用,比如利用二八原則,即百分之20的數據可以滿足百分之80的訪問需求。我們就可以把這百分之20的數據放在Redis里面,到時候直接訪問redis就可以了,要是訪問的不是這20的數據,再訪問MySQL就行。
所以根據上文介紹的分布式系統來說,數據量雖然大,但是總有部分數據是經常訪問的,我們就把這種數據成為熱點數據,其他數據成為冷數據,冷數據咱們就通過MySQL訪問,熱數據我們大多都是通過Redis訪問。
負載均衡
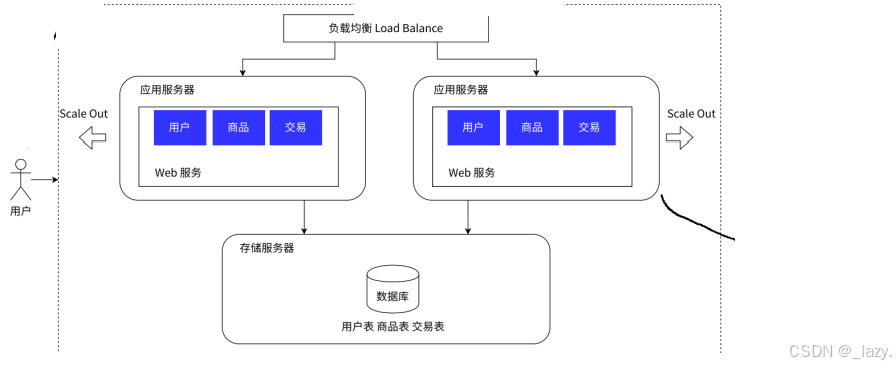
好了,我們現在引入負載均衡的概念了,既然數據量起來了,我們還有多個服務器,那么哪個服務器處理哪個請求呢?最簡單的方式是輪詢,即A服務器處理了第一個那么就B服務器處理第二個,好了,問題來了,誰來完成這個分配的任務呢?
此時,負載均衡就出現了,負載均衡就像是領導,它不處理請求,它要求的是分發每個請求,即把每個請求根據實際情況分發給不同的服務器,這樣就能完成一個削峰填谷的作用。大概率就不能出現某個主機處理的請求太多了導致服務器掛了的情況。
即,負載均衡=領導。
不過既然是領導,既然是要接受所有的請求,雖然不處理,但是仍然是要求負載均衡的接受請求的能力是要大于處理應用服務器的,那么你說會不會數據量大到負載均衡都接受不完的情況?
是非常有可能的,比如雙十一,618的時候,就是數據量大爆發的時候,這個時候就可能要引入更多的負載均衡器了。
緩存
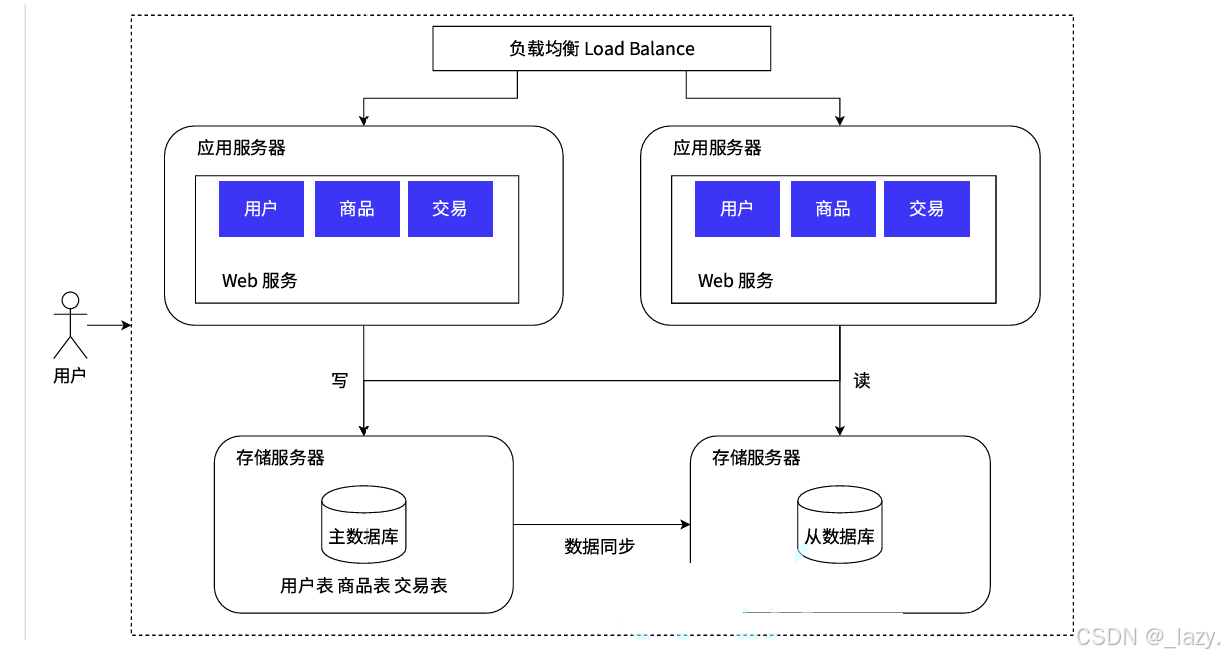
可是你別看數據量這么大的時候只有應用服務器在工作,數據多的時候,數據庫可是真的煩惱,因為幾乎所有的數據都是要從數據庫的這里走的,也就是說數據庫服務器是一個人默默承擔了所有。
那么為了解決問題,根據實際情況出發,我們發現數據庫的讀頻率是遠遠大于寫頻率的,所以我們不妨把數據庫服務器分為主數據庫和從數據庫,一個負責讀取一個負責寫,這樣我們引入了兩臺服務器分別完成讀寫的操作,自然面臨的一個問題就是同步問題。
而大多數情況,光把數據庫分為了讀寫數據庫還不夠,因為有的數據非常頻繁的訪問,這就導致了有的時候同步不及時,所以引入了緩存:
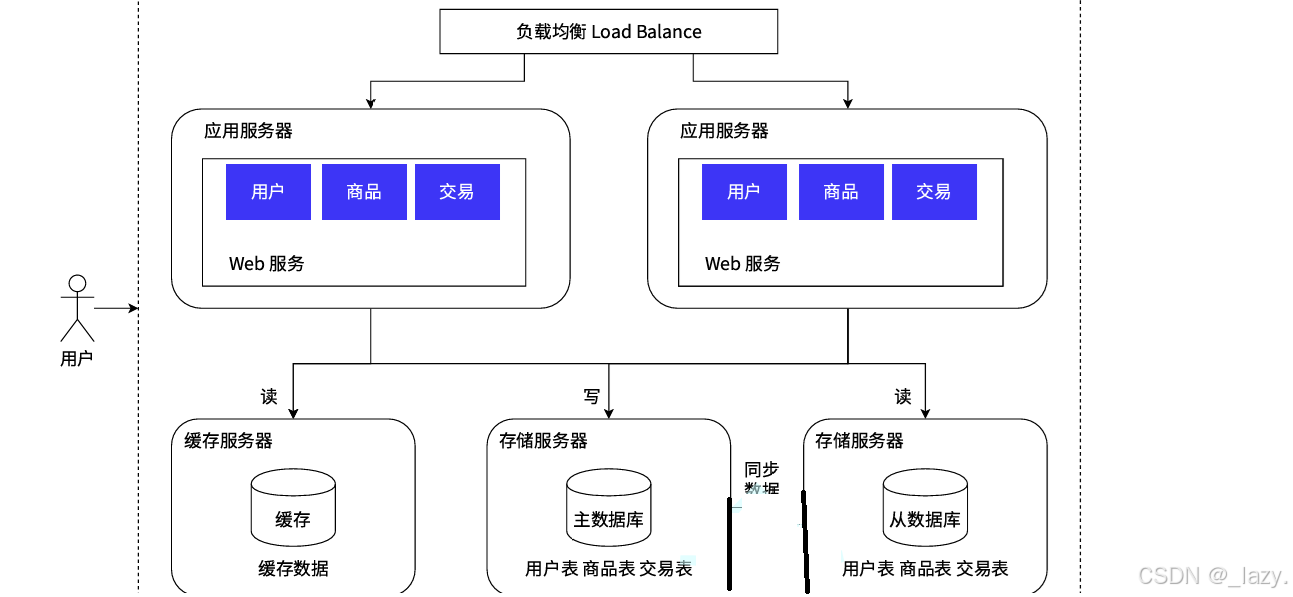
即我們將數據庫分為了三個,其中兩個用來讀取,一個是普通的從數據庫,一個是緩存,用來緩存熱點數據,這樣數據庫的壓力一下就下來了。
不過還是那句話,這樣后面的維護成本是比較大的,并且同步問題的難度也是越來越大了。此時咱門的Redis就應用到了緩存服務器里面了。不過這里的從數據庫存放的可都是全量數據。
微服務
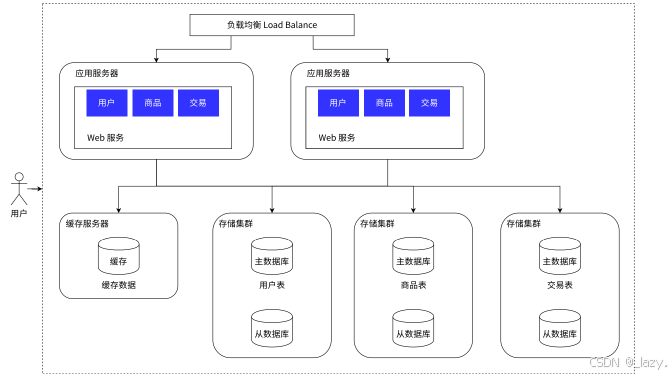
不過如果數據量在極端情況下,非常非常多,多到什么程度呢,多到一張表都需要拆分,此時就需要引入微服務了,即我們將數據量拆分了之后,哪個服務器處理哪個庫的哪個表的數據等。
即分庫分表。
這個時候的代碼量,以及維護難度是大大的提高了,不過能處理數據的程度也確實提升了不少了。
我們在這里就簡單的理解了微服務是什么,即將引入了多臺服務器,不過處理的內容比較單一,比如就一個數據庫的哪個哪個表。不過具體怎么分,那得看實際情況了。
引入微服務,解決了人的問題,付出的代價?
1.系統的性能下降~~(要想保證性能不下降太多,只能引入更多的機器,更多的硬件資源 =>充錢~~)
拆出來更多的服務,多個功能之間要更依賴網絡通信,網絡通信的速度很可能是比硬盤還慢的!!!幸運的是,硬件技術的發展,網卡現在有 萬兆 網卡,讀寫速度已經能過超過硬盤讀寫了~~
2.系統復雜程度提高, 可用性收到影響~~
服務器更多了,出現問題的概率就更大了~~
這就需要一系列的手段,來保證系統的可用性~~
(更豐富的監控報警,以及配套的運維人員)
微服務的優勢:
1.解決了人的資源分配問題.
2.使用微服務, 可以更方便于功能的復用
3.可以給不同的服務進行不同的部署
小結:
在分布式系統中,我們接觸到的名詞有:
應用/系統:即一個服務器程序。
模塊/組件:即一個應用中獨立的功能
分布式:引入多個服務器,每個服務器協同工作
集群:其實就是分布式上的多個主機,不過集群偏邏輯上
主從結構:比如數據庫可以分為主從數據庫,服務器節點也是
中間件:和業務無關的功能,比如消息隊列,數據庫,更多的是為了協助整個服務器工作。
可用性:系統整體可用的時間/總時間
響應時間:肯定是越短越好
吞吐量和并發:一條高速公路,兩個車道,并發量為2,一分鐘過了100輛車,吞吐量為100.
感謝閱讀!
本文主要還是通過分布式系統簡單引入Redis~~所以較為粗糙~~后面會越來越詳細的!!


`方法可能出現的超時問題)












![[特殊字符]【高并發實戰】Java Socket + 線程池實現高性能文件上傳服務器(附完整源碼)[特殊字符]](http://pic.xiahunao.cn/[特殊字符]【高并發實戰】Java Socket + 線程池實現高性能文件上傳服務器(附完整源碼)[特殊字符])


)
