2025年4月5日Llama 4一開源,隨后OpenRouter等平臺就提供免費調用。對于中文社區來,官方的測評結果其實意義不大(原因先按下不表),就看知乎、微博、B站、twitter上的真實感受,最重要的是自己的真實案例測評。
核心架構創新
-
?混合專家(Mixture-of-Experts,MoE)架構:Llama 4 Scout活躍參數約為170億,內部包含16個專家,總參數量達1090億;Llama 4 Maverick活躍參數同樣約170億,但包含多達128個專家,總參數量高達4000億。Llama 4?Behemoth擁有2880億活躍參數,采用16個專家,總參數量高達2萬億,目前尚未完全訓練完畢、處于預覽階段的超大模型。
-
原生多模態:能處理文本、圖像、視頻、音頻等。
-
超長上下文窗口:Llama 4 Scout模型的上下文窗口超過1000萬token,Maverick模型上下文窗口約100萬token。
-
支持的語言(摘自于https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct):?阿拉伯語、英語、法語、德語、印地語、印度尼西亞語、意大利語、葡萄牙語、西班牙語、他加祿語、泰語和越南語。沒有中文!
訓練數據
- 預訓練數據:多種來源,包括公開可獲得的數據、授權的數據,以及Meta自有產品和服務中的信息。從語言角度,Llama 4包含多達200種語言語料庫,其中有100多種語言各有超過10億token的訓練數據。
-
訓練規模與資源消耗:Llama 4 Scout的預訓練耗費了約500萬GPU小時,Maverick耗費了約238萬GPU小時,總計約738萬GPU小時。Meta使用自建的大規模GPU集群訓練,大部分是NVIDIA H100 80GB,每塊卡TDP功耗700W。簡單換算一下,738萬GPU小時相當于單卡連續算738萬小時(84年!),當然實際是成千上萬卡并行訓練了數周到數月才完成的。可參考『不廢話』之大模型訓練數據中心算力和算效和『不廢話』之大模型訓練并行策略文章進行定量的分析 。
-
訓練語料的數量:Llama 4 Scout預訓練使用了約40萬億tokens,Maverick使用了約22萬億tokens,總計60多萬億token的多模態數據。
訓練優化策略
Meta在Llama 4的后期訓練(微調)上采用了一套精心設計的策略。他們發現,如果對模型進行過度的監督微調(SFT)或偏好優化,可能會過度約束模型,讓它在一些方面反而退步。因此,他們采取了一種"輕量SFT → 在線RL → 輕量DPO"的流程。
性能評測
結論:Llama 4系列各個模型都有中文能力,但中文能力很弱。
數學能力

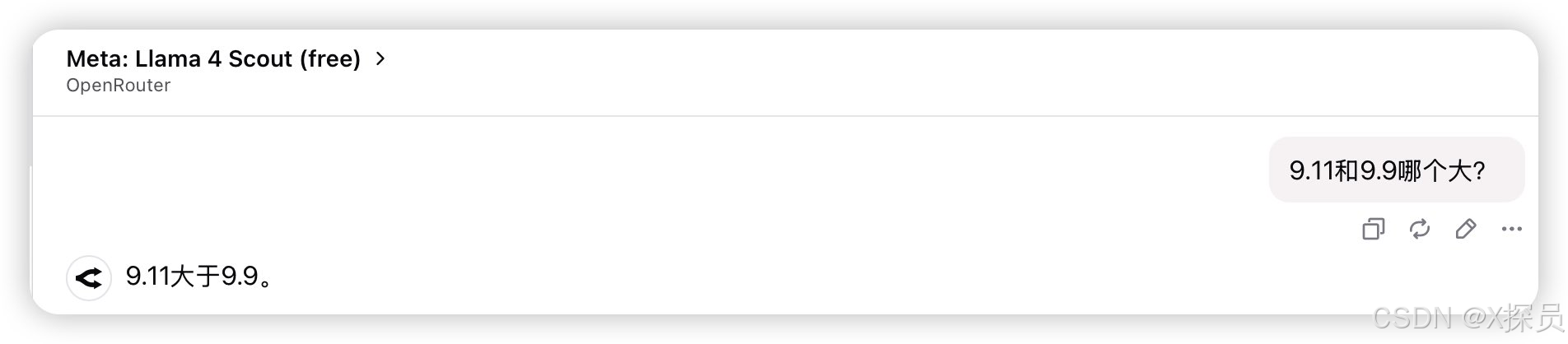
編碼能力
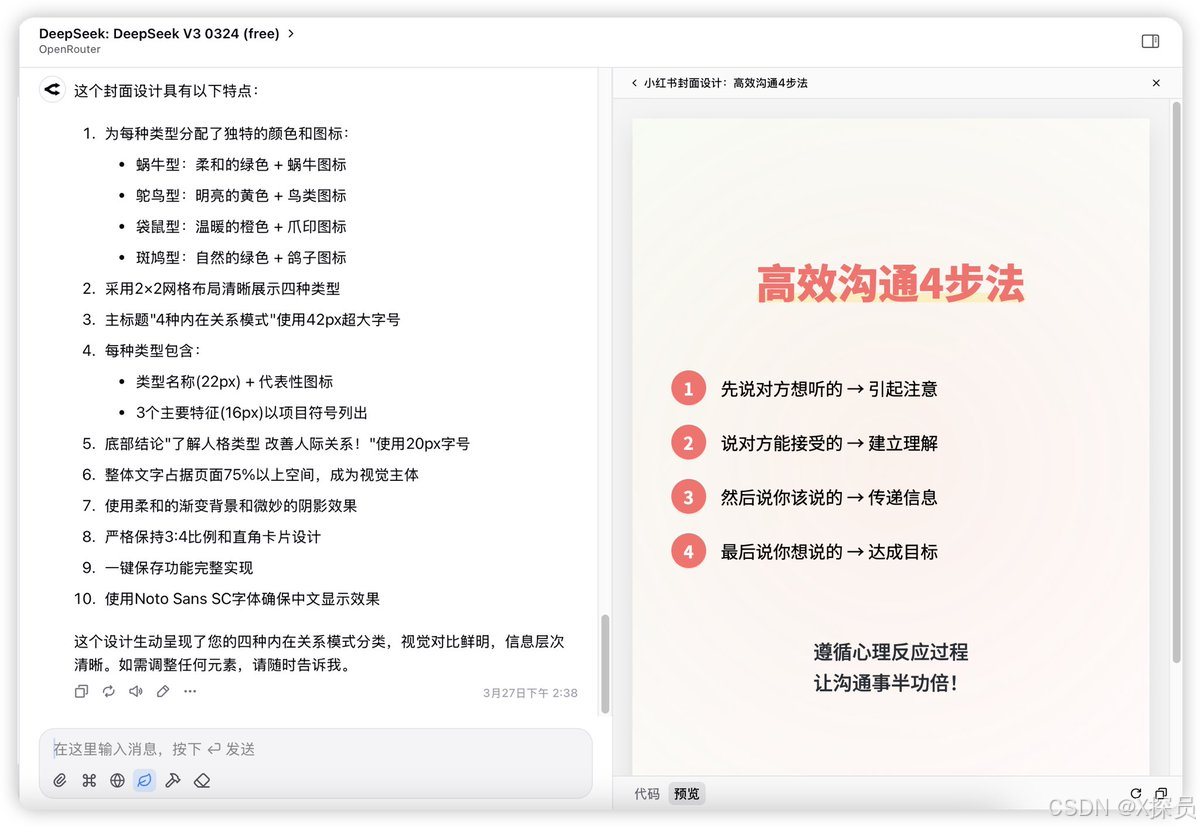
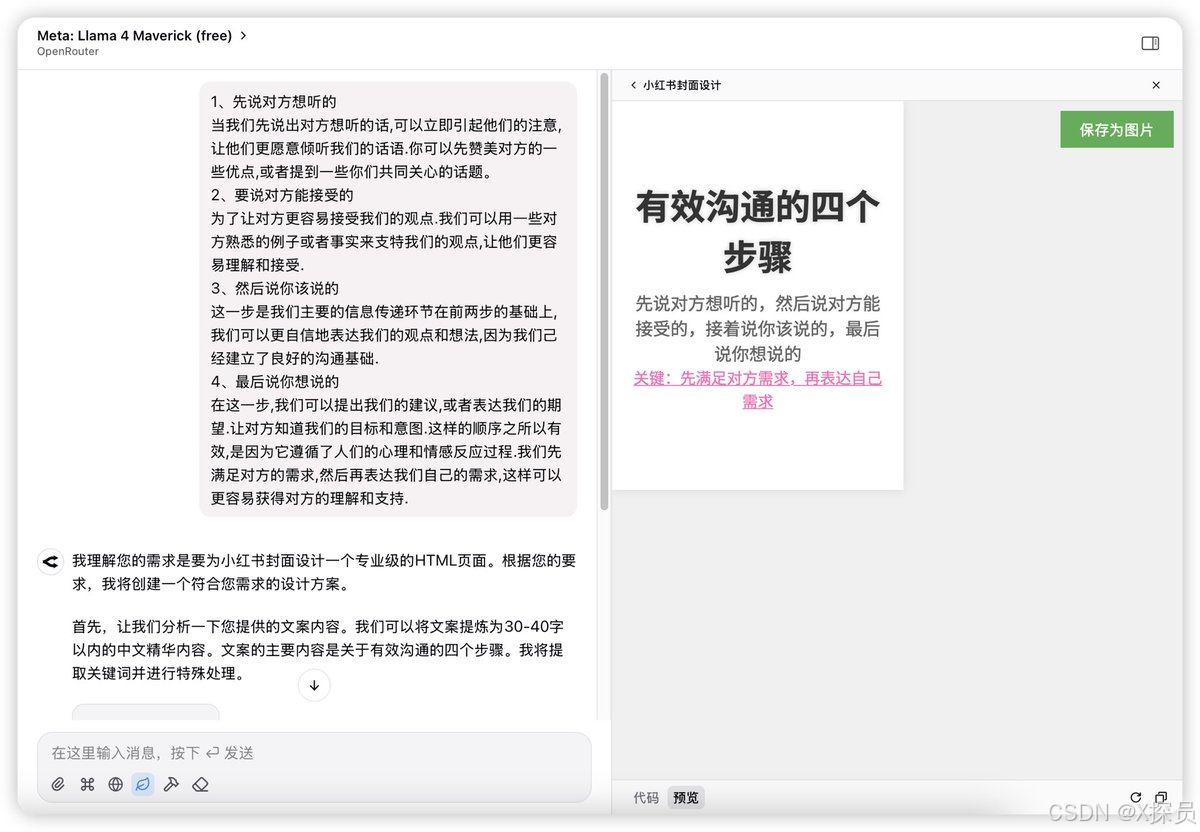
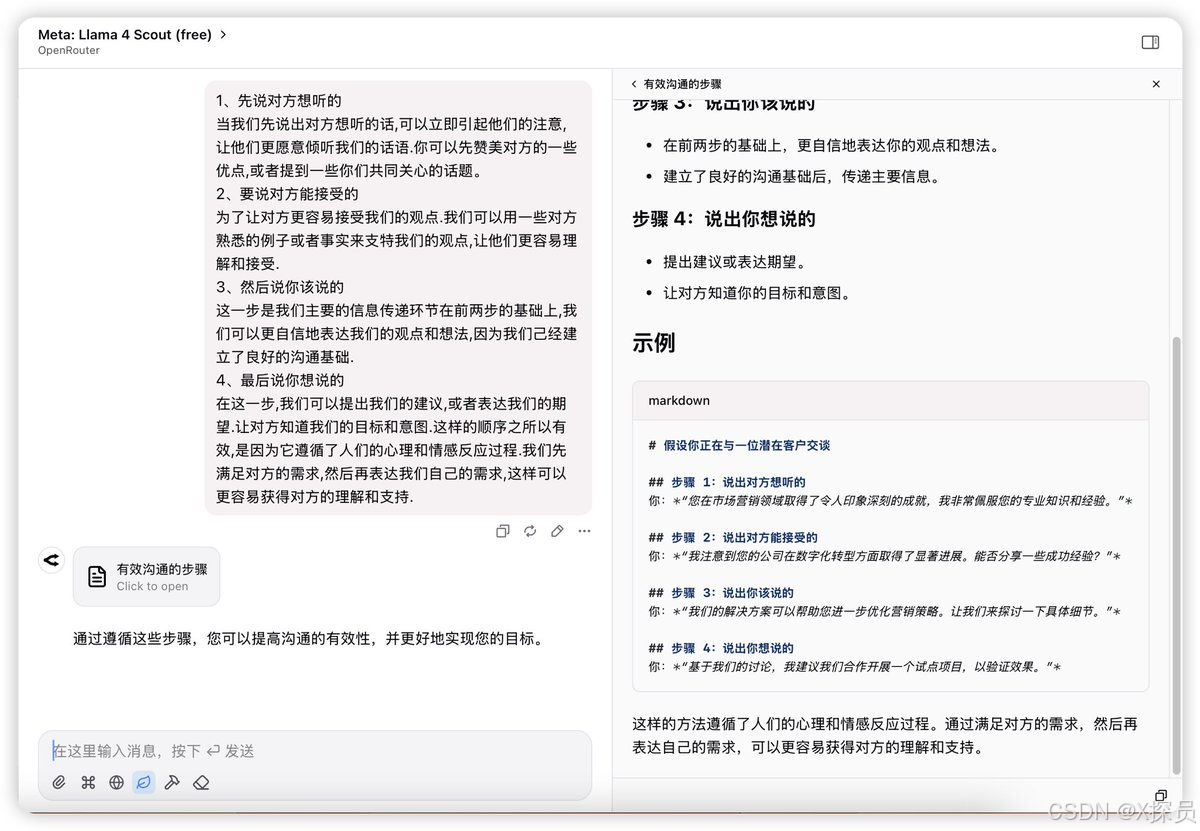
此測評是想讓模型根據給定的文本進行HTML網頁編寫,Llama 4的效果比DeepSeek V3的效果差太多了。



-Pratt解析算法:SQL表達式解析的核心引擎)


)
:基于機器學習的數值預測)


)


![STM32單片機入門學習——第22節: [7-2] AD單通道AD多通道](http://pic.xiahunao.cn/STM32單片機入門學習——第22節: [7-2] AD單通道AD多通道)


)


)