目錄
一、數據文件
二、模型配置文件 config.py
三、數據加載文件 loader.py
1.導入文件和類的定義
2.初始化
3.數據加載方法
代碼運行流程
4.文本編碼 / 解碼方法
① encode_sentence():
② decode():
代碼運行流程
③ padding():
代碼運行流程
5.類內魔術方法
6.加載映射關系文件
7.加載詞表
8.數據加載器封裝
9.數據加載文件測試
10.完整代碼
四、模型文件 model.py
1.導入文件
2.將字典配置包裝為對象
3.模型初始化
4.前向計算
代碼運行流程
5.選擇優化器
6.模型文件測試
7.完整代碼
五、模型評估文件 evaluate.py
1.類初始化
2.評估模型方法
代碼運行流程
3.統計寫入
代碼運行流程
4.統計結果展示
代碼運行流程
5.解碼
分組類別規定
代碼運行流程
6.完整代碼
六、模型訓練文件 main.py
代碼運行流程
1.導入文件
2.日志文件配置
3.LoRA目標模塊配置(包裝函數)
4.模型訓練主程序
① 創建保存模型的目錄
② 加載訓練數據
③ 加載模型
④ 標識是否使用GPU
⑤ 加載優化器
⑥ 加載效果測試類
⑦ 訓練主流程 ?
Ⅰ、Epoch循環控制
Ⅱ、模型設置訓練模式
Ⅲ、Batch數據遍歷
Ⅳ、梯度清零與設備切換
Ⅴ、前向傳播與損失計算
Ⅵ、反向傳播與參數更新
Ⅶ、損失記錄與日志輸出
Ⅷ、Epoch評估與日志
Ⅸ、完整訓練代碼
七、模型預測文件 predict.py
代碼運行流程
1.導入文件
2.初始化?
3.加載映射關系表
4.加載字詞表
5.文本句子編碼
6.解碼文本
代碼運行流程
7.預測文件
代碼運行流程
8.模型效果測試
9.完整代碼?
Death is not?an end, but silence when storie cease.
死亡不是終點,遺忘才是
????????????????????????????????????????????????????????????????????????????????—— 25.4.5
一、數據文件
通過網盤分享的文件:Ner命名實體識別任務
鏈接: https://pan.baidu.com/s/1r8cjMyIdQ0oWcNvtIK35Qw?pwd=98u7 提取碼: 98u7?
--來自百度網盤超級會員v3的分享
二、模型配置文件 config.py
model_path:模型保存路徑,訓練后的模型權重和文件會存儲在該目錄下。
schema_path:定義任務中實體類別或標簽的配置文件路徑(通常是 JSON 文件)
train_data_path:訓練數據集的存儲路徑,通常包含訓練文本和對應的標簽文件
valid_data_path:驗證/測試數據集的存儲路徑,用于模型性能評估。
vocab_path:詞匯表文件路徑,包含所有可能的字符或詞語列表,用于構建模型的輸入編碼(如字符級或詞級 Embedding)。
max_length:輸入文本序列的最大長度。超過此長度的文本會被截斷,不足的會用占位符(如?[PAD])填充。
hidden_size:神經網絡隱藏層的維度大小(例如 LSTM、Transformer 層的隱藏單元數)。
num_layers:神經網絡的層數(如 LSTM 或 Transformer 的堆疊層數)。
epoch:訓練的總輪次,即模型遍歷整個訓練數據集的次數。
batch_size:每次輸入模型的樣本數量。較大的?batch_size?會占用更多內存,但可能加速訓練。
optimizer:優化器類型,用于更新模型參數以最小化損失函數。
learning_rate:學習率,控制參數更新的步長。較小的值收斂更穩定,但速度較慢;較大的值可能不穩定。
use_crf:是否在模型輸出層使用 ??CRF(條件隨機場)??。CRF 常用于序列標注任務(如 NER)以提升標簽序列的合理性。
class_num:分類任務的類別數量。在 NER 任務中,通常為實體類型數 + 1(例如?O?表示非實體)。
bert_path:預訓練 BERT 模型的本地路徑,用于加載 BERT 的權重和配置
# -*- coding: utf-8 -*-"""
配置參數信息
"""Config = {"model_path": "model_output","schema_path": "ner_data/schema.json","train_data_path": "ner_data/train","valid_data_path": "ner_data/test","vocab_path":"chars.txt","max_length": 100,"hidden_size": 256,"num_layers": 2,"epoch": 10,"batch_size": 16,"optimizer": "adam","learning_rate": 1e-3,"use_crf": False,"class_num": 9,"bert_path": r"F:\人工智能NLP/NLP資料\week6 語言模型/bert-base-chinese"
}三、數據加載文件 loader.py
1.導入文件和類的定義
json:用于 ??JSON 文件的讀寫?。?
re:??正則表達式庫??,處理字符串匹配和文本清洗。
os:??操作系統接口庫??,處理文件路徑和目錄操作。
torch:??PyTorch 深度學習框架??,提供張量計算、自動求導和模型訓練功能。
random:生成 ??隨機數??,用于數據隨機化。
jieba:中文分詞工具??,將中文文本分割成詞語序列。
numpy:??數值計算庫??,支持高效的數組和矩陣運算。
Dataset:PyTorch 數據集的基類,用于封裝自定義數據集。
DataLoader:批量加載數據的工具,支持多進程加速和隨機采樣。
defaultdict:提供 ??默認值字典??,當鍵不存在時返回指定類型的默認值。
BertTokenize:HuggingFace Transformers 庫中的 ??BERT 分詞器??,用于將文本轉換為 BERT 模型所需的輸入格式。
DataGenerator:自定義數據生成類
# -*- coding: utf-8 -*-import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from transformers import BertTokenizer"""
數據加載
"""class DataGenerator:2.初始化
data_path:原始數據存儲路徑(如?ner_data/train),指向包含訓練/驗證數據的文件或目錄。
config:全局配置字典,存放模型超參數、路徑和其他運行配置。
self.config:將外部傳入的?config?參數保存為類實例的屬性,方便在整個類中訪問配置內容。
self.path:將傳入的?data_path?保存為類實例屬性,表示要處理的數據路徑。
self.tokenizer:BERT 分詞器對象,負責將原始文本轉換為 BERT 模型所需的輸入格式
self.sentences:存儲預處理后的數據集
self.schema:標簽到索引的映射字典,通常從?schema.json?文件中加載。
schema_path:指向一個 ??標簽定義文件??(通常是 JSON 格式),用于明確任務中的類別或標簽體系。
self.load_vocab():從?bert_path?加載 BERT 分詞器的??自定義實現方法??
self.load_schema():解析?schema.json?文件,生成標簽與索引的映射字典
self.load():核心數據加載方法,負責以下操作:讀取數據、數據處理、保存數據
def __init__(self, data_path, config):self.config = configself.path = data_pathself.tokenizer = load_vocab(config["bert_path"])self.sentences = []self.schema = self.load_schema(config["schema_path"])self.load()3.數據加載方法
代碼運行流程
# `load()` 方法運行流程├── 1. ?**?初始化數據容器?**?
│ - `self.data = []`: 創建空列表存儲處理后的樣本(每個樣本為 `[input_ids, labels]` 張量對)├── 2. ?**?讀取原始文件?**?
│ - `with open(self.path, encoding="utf8") as f`: 打開 `data_path` 指向的數據文件
│ - `segments = f.read().split("\n\n")`: 按空行分段落(每個段落為一個樣本)├── 3. ?**?遍歷每個段落(樣本)?**?
│ │
│ ├── 3.1 ?**?初始化當前樣本?**?
│ │ - `sentenece = []`: 存儲字符序列(如 `["我", "愛", "NLP"]`)
│ │ - `labels = [8]`: 初始化標簽列表,首項為 `8`(可能是 `[CLS]` 標簽的預設值)
│ │
│ ├── 3.2 ?**?按行處理段落內容?**?
│ │ │
│ │ ├── 3.2.1 ?**?跳過空行?**?
│ │ │ - `if line.strip() == "": continue`
│ │ │
│ │ ├── 3.2.2 ?**?分割字符和標簽?**?
│ │ │ - `char, label = line.split()`: 例如行內容為 `"我 O"` → `char="我", label="O"`
│ │ │
│ │ ├── 3.2.3 ?**?收集字符和標簽?**?
│ │ - `sentenece.append(char)`: 字符加入列表
│ │ - `labels.append(self.schema[label])`: 標簽轉換為索引(如 `"O"` → `0`)
│ │
│ ├── 3.3 ?**?生成完整句子?**?
│ │ - `sentence = "".join(sentenece)`: 合并字符為字符串(如 `"我愛NLP"`)
│ │ - `self.sentences.append(sentence)`: 保存原始句子(可能用于調試或展示)
│ │
│ ├── 3.4 ?**?編碼句子為 input_ids?**?
│ │ - `input_ids = self.encode_sentence(sentenece)`: 調用 `encode_sentence` 方法生成 BERT 輸入 ID
│ │
│ ├── 3.5 ?**?填充標簽序列?**?
│ │ - `labels = self.padding(labels, -1)`: 調用 `padding` 方法,填充標簽到固定長度(用 `-1` 表示填充位)
│ │
│ └── 3.6 ?**?保存為張量對?**?
│ - `self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])`: 轉換為 PyTorch 張量并存入 `self.data`└── 4. ?**?返回?**?- `return`: 方法結束,`self.data` 準備就緒供后續使用self.data:存儲預處理后的數據樣本,每個樣本是一個列表,包含兩個?torch.LongTensor?張量
open():打開文件并返回文件對象,用于讀取或寫入文件內容。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
file | str | 必填 | 文件路徑(如?"data.txt")。 |
mode | str | 'r' | 文件模式:'r'(讀)、'w'(寫)、'a'(追加)、'b'(二進制模式)等。 |
encoding | str | 系統默認 | 文本編碼(如?"utf-8")。 |
| 其他參數 | - | - | 如?errors(編解碼錯誤處理)、newline(換行符控制)等。 |
self.path:原始數據存儲路徑(如?ner_data/train),指向包含訓練/驗證數據的文件或目錄。
f:文件對象,表示已打開的文件句柄,用于讀取內容
segments:存儲按空行分割后的段落列表,每個段落對應一個樣本。
segment:單個段落(即一個樣本),包含多行文本,每行格式為字符標簽。
文件對象.read():從文件中讀取內容,返回字符串或字節對象。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
size | int | None | 讀取的字節數(若未指定則讀取全部)。 |
字符串.split():按分隔符分割字符串,返回列表。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
sep | str | None | 分隔符(默認為所有空白字符)。 |
maxsplit | int | -1 | 最大分割次數(默認無限制)。 |
sentence:合并當前段落中的所有字符,生成完整的原始句子字符串。
labels:存儲標簽索引序列,初始值為?[8]([CLS]標簽的預留位置)
line:段落中的單行文本,格式為?字符標簽(如?"我 O")。
字符串.strip():去除字符串兩端的指定字符(默認去除空白符)。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
chars | str | None | 要刪除的字符集合(默認空白符)。 |
char:單個字符(如?"我"),從每行文本中提取。
label:標簽名(如?"O"、"B-PER"),從每行文本中提取。
列表.append():向列表末尾添加元素,無返回值。
| 參數名 | 類型 | 說明 |
|---|---|---|
object | any | 要添加的元素。 |
字符串.join():用指定字符串連接可迭代對象中的元素。
| 參數名 | 類型 | 說明 |
|---|---|---|
iterable | iterable | 要連接的元素(如列表、元組)。 |
self.encode_sentence():自定義編碼方法,將字符列表編碼為 BERT 的?input_ids。
self.padding():自定義方法,將標簽序列填充到固定長度。
torch.LongTensor():創建長整型(64 位)張量,支持從列表、數組等初始化。
| 參數名 | 類型 | 說明 |
|---|---|---|
data | array-like | 初始化數據(如列表、NumPy 數組)。 |
dtype | torch.dtype | 張量數據類型(默認為?torch.int64)。 |
device | torch.device | 張量存儲設備(如?"cpu"?或?"cuda")。 |
requires_grad | bool | 是否啟用梯度計算(默認為?False)。 |
def load(self):self.data = []with open(self.path, encoding="utf8") as f:segments = f.read().split("\n\n")for segment in segments:sentence = []labels = [8] # cls_tokenfor line in segment.split("\n"):if line.strip() == "":continuechar, label = line.split()sentence.append(char)labels.append(self.schema[label])sentence = "".join(sentenece)self.sentences.append(sentence)input_ids = self.encode_sentence(sentenece)labels = self.padding(labels, -1)# print(self.decode(sentence, labels))# input()self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])return4.文本編碼 / 解碼方法
① encode_sentence():
text:需要編碼的原始文本輸入(單條文本或列表)。
tokenizer.encode():是 Hugging Face Transformers 庫中分詞器(如?BertTokenizer)的核心方法,用于將 ??原始文本?? 轉換為模型可處理的 ??數值化輸入??
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
text | str?或?List[str] | 必填 | 要編碼的文本(單條文本或列表)。 |
text_pair | str?或?List[str] | None | 第二個文本序列(用于句子對任務,如問答、文本相似度)。 |
add_special_tokens | bool | True | 是否添加模型特定的特殊標記(如?[CLS],?[SEP])。 |
padding | str?或?bool | False | 填充策略: -? "max_length": 填充到?max_length。-? "longest": 填充到批次最長序列。-? False/"do_not_pad": 不填充。 |
truncation | str?或?bool | False | 截斷策略: -? True/"longest_first": 截斷到?max_length。-? "only_first"/"only_second": 截斷第一個或第二個句子。 |
max_length | int | 模型最大長度 | 序列的最大長度(包括特殊標記)。 |
return_tensors | str | None | 返回張量格式: -? "pt": PyTorch 張量。-? "tf": TensorFlow 張量。-? "np": NumPy 數組。 |
return_attention_mask | bool | True | 是否返回?attention_mask(標識有效 token 位置)。 |
| ??其他參數?? | - | - | 如?return_token_type_ids(是否返回 token 類型 ID)、return_overflowing_tokens?等。 |
def encode_sentence(self, text, padding = True):return self.tokenizer.encode(text,padding=padding,max_length=self.config["max_length"],truncation=True)② decode():
代碼運行流程
# `decode()` 方法運行流程├── 1. ?**?預處理輸入?**?
│ ├── `sentence = "$" + sentence`
│ │ - 在句子開頭添加特殊字符 `$`(可能是為了索引對齊或調試)
│ └── `labels = "".join([str(x) for x in labels[:len(sentence) + 2]])`
│ - 將標簽列表轉換為字符串(如 `[0,4,4]` → `"044"`)
│ - 截斷標簽到 `len(sentence) + 2` 的長度(可能存在越界風險)├── 2. ?**?初始化結果容器?**?
│ └── `results = defaultdict(list)`
│ - 創建默認值為列表的字典,用于存儲提取的實體(如 `{"LOCATION": ["上海"]}`)├── 3. ?**?正則匹配與實體提取?**?
│ ├── 3.1 ?**?匹配地點(LOCATION)?**?
│ │ ├── `for location in re.finditer("(04+)", labels):`
│ │ │ - 正則模式 `04+`: 匹配以 `0` 開頭、后跟多個 `4` 的標簽序列(如 `"044"`)
│ │ ├── `s, e = location.span()`
│ │ │ - 獲取匹配子串的起始 (`s`) 和結束 (`e`) 索引
│ │ └── `results["LOCATION"].append(sentence[s:e])`
│ │ - 根據索引從句子中提取文本(如 `sentence[1:3] → "上海"`)
│ │
│ ├── 3.2 ?**?匹配組織(ORGANIZATION)?**?
│ │ ├── `for location in re.finditer("(15+)", labels):`
│ │ │ - 正則模式 `15+`: 匹配以 `1` 開頭、后跟多個 `5` 的標簽序列
│ │ └── 其他操作同步驟 3.1
│ │
│ ├── 3.3 ?**?匹配人物(PERSON)?**?
│ │ ├── `for location in re.finditer("(26+)", labels):`
│ │ │ - 正則模式 `26+`: 匹配以 `2` 開頭、后跟多個 `6` 的標簽序列
│ │ └── 其他操作同步驟 3.1
│ │
│ └── 3.4 ?**?匹配時間(TIME)?**?
│ ├── `for location in re.finditer("(37+)", labels):`
│ │ - 正則模式 `37+`: 匹配以 `3` 開頭、后跟多個 `7` 的標簽序列
│ └── 其他操作同步驟 3.1└── 4. ?**?返回結果?**?└── `return results` - 返回實體字典(如 `{"LOCATION": ["上海"], "TIME": ["2023年"]}`)sentence:原始句子字符串,函數中在開頭添加了?"$",是為了 ??調整索引對齊??(例如避免標簽與字符位置錯位)。
labels:標簽序列(數值類型),轉換為字符串形式以便正則匹配。
字符串.join():將可迭代對象(如列表、元組)中的元素用指定字符串連接,生成新字符串。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
iterable | 可迭代對象 | 必填 | 需要連接的元素集合。 |
str():將對象轉換為字符串表示。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
object | any | 必填 | 需要轉換的對象。 |
results:存儲提取的實體結果,結構為?{"LOCATION": ["實體1", ...], "ORGANIZATION": [...]}
defaultdict():創建一個默認值字典,當訪問不存在的鍵時,返回指定類型的默認值。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
default_factory | 類型/函數 | 必填 | 生成默認值的工廠函數(如?list,?int)。 |
?**?kwargs | 關鍵字參數 | 可選 | 初始化的鍵值對(如?a=1)。 |
location:正則匹配結果對象,包含匹配到的子串位置信息(通過?.span()?獲取)
字符串.span():Python 中?re.Match?對象的方法,用于返回正則表達式匹配的子串在原始字符串中的 ??起始和結束位置索引??。返回值為元組?(start, end),其中:
????????start??:匹配子串的起始索引(包含)。
? end??:匹配子串的結束索引(不包含)。
re.finditer():在字符串中查找所有匹配正則表達式的子串,返回迭代器(包含所有匹配對象)
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
pattern | str | 必填 | 正則表達式模式。 |
string | str | 必填 | 要搜索的字符串。 |
flags | int | 0 | 正則匹配標志(如?re.IGNORECASE)。 |
s(start):匹配到的標簽子串在?labels?字符串中的 ??起始索引??(包含該位置)
e(end):匹配到的標簽子串在?labels?字符串中的 ??結束索引??(不包含該位置)。
列表.append():向列表末尾添加一個元素。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
object | any | 必填 | 要添加到列表的元素。 |
def decode(self, sentence, labels):sentence = "$" + sentencelabels = "".join([str(x) for x in labels[:len(sentence) + 2]])results = defaultdict(list)for location in re.finditer("(04+)", labels):s, e = location.span()print("location", s, e)results["LOCATION"].append(sentence[s:e])for location in re.finditer("(15+)", labels):s, e = location.span()print("org", s, e)results["ORGANIZATION"].append(sentence[s:e])for location in re.finditer("(26+)", labels):s, e = location.span()print("per", s, e)results["PERSON"].append(sentence[s:e])for location in re.finditer("(37+)", labels):s, e = location.span()print("time", s, e)results["TIME"].append(sentence[s:e])return results③ padding():
代碼運行流程
# `padding` 方法運行流程├── 1. ?**?輸入參數?**?
│ ├── `input_id`: 待處理的原始序列(如 `[token1, token2, ...]`)。
│ └── `pad_token`: 填充符(默認值 `0`,通常對應 `[PAD]`)。├── 2. ?**?截斷序列?**?
│ ├── ?**?條件判斷?**?: 若 `len(input_id) > max_length`
│ │ └── 截取前 `max_length` 個元素:`input_id = input_id[:max_length]`。
│ └── ?**?否則?**?(長度 ≤ `max_length`):
│ └── 保留原序列。├── 3. ?**?填充序列?**?
│ ├── ?**?計算填充長度?**?: `pad_length = max_length - len(input_id)`。
│ ├── ?**?條件判斷?**?: 若 `pad_length > 0`
│ │ └── 追加 `pad_length` 個填充符:`input_id += [pad_token] * pad_length`。
│ └── ?**?否則?**?(`pad_length ≤ 0`):
│ └── 無需填充。└── 4. ?**?返回結果?**?└── 返回統一長度(`max_length`)的序列:`return input_id`。input_id:待處理的原始輸入序列(通常是 token ID 列表)
pad_token:填充符的 token ID,用于在序列末尾填充。
config["max_length"]:預定義的序列最大長度,所有輸入序列將被統一調整至此長度。
# 補齊或截斷輸入的序列,使其可以在一個batch內運算def padding(self, input_id, pad_token=0):input_id = input_id[:self.config["max_length"]]input_id += [pad_token] * (self.config["max_length"] - len(input_id))return input_id5.類內魔術方法
__len__():返回數據長度
__getitem()__:根據索引返回元素
def __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]6.加載映射關系文件
path:任務中實體類別或標簽的配置文件路徑(通常是 JSON 文件)
f:文件對象
open():打開文件并返回文件對象,用于讀寫文件內容。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
file | str | 必填 | 文件路徑(如?"data/schema.json")。 |
mode | str | "r" | 文件模式(如?"r"、"w"、"a"、"rb"?等)。 |
encoding | str | 系統默認 | 文本編碼格式(如?"utf-8")。 |
errors | str | None | 編解碼錯誤處理策略(如?"ignore"、"strict")。 |
newline | str | None | 換行符控制(如?"\n")。 |
json.load():從文件對象中解析 JSON 數據,返回對應的 Python 數據結構(如字典、列表)。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
fp | 文件對象 | 必填 | 已打開的文件對象(需以讀模式打開)。 |
object_hook | function | None | 自定義函數,用于處理解碼后的字典對象(高級用法)。 |
parse_float | function | float | 自定義函數,用于解析 JSON 中的浮點數(如?decimal.Decimal)。 |
parse_int | function | int | 自定義函數,用于解析 JSON 中的整數(如?str?保留原始格式)。 |
encoding | str | "utf-8" | 文件編碼(僅 Python 3 之前版本需要顯式指定)。 |
def load_schema(self, path):with open(path, encoding="utf8") as f:return json.load(f)7.加載詞表
vocab_path:詞匯表文件路徑,包含模型或分詞器使用的 ??所有詞匯或子詞單元列表??,用于將文本轉換為數值化的 token ID。
BertTokenizer.from_pretrained():加載分詞器配置??:根據?vocab_path?自動讀取分詞器配置(如詞匯表、特殊標記、分詞規則等)。
| 參數名 | 類型 | 默認值 | 作用 |
|---|---|---|---|
??pretrained_model_name_or_path?? | str?或?os.PathLike | 必填 | ??核心參數??: - 預訓練模型名稱(如? "bert-base-chinese")。- 本地目錄路徑(需包含? vocab.txt?和?tokenizer_config.json)。 |
use_fast | bool | True | 是否使用 ??快速分詞器??(Rust 實現,性能更優)。 (若? False,則使用 Python 實現的分詞器)。 |
cache_dir | str | None | 指定模型文件的緩存目錄(覆蓋默認的?~/.cache/huggingface)。 |
force_download | bool | False | 是否強制重新下載模型文件(即使本地緩存已存在)。 |
local_files_only | bool | False | 是否僅使用本地文件(不聯網下載)。 (適用于離線環境或已有緩存文件)。 |
revision | str | "main" | 指定模型版本: - Git 分支名(如? "dev")。- 標簽名(如? "v1.0")。- 提交哈希(如? "123abc")。 |
subfolder | str | "" | 若分詞器文件存儲在模型目錄的子文件夾中,需指定子文件夾名。 |
proxies | Dict[str, str] | None | 設置代理服務器(格式:{"http": "http://proxy:port", "https": "https://proxy:port"})。 |
trust_remote_code | bool | False | 是否信任遠程代碼(當加載自定義分詞器時,需設置為?True)。(注意:存在安全風險,需謹慎使用)。 |
mirror | str | None | 指定鏡像源地址(如?"https://mirror.example.com")。(用于網絡受限環境)。 |
def load_vocab(vocab_path):return BertTokenizer.from_pretrained(vocab_path)8.數據加載器封裝
data_path:數據文件或目錄的路徑,指向包含訓練/驗證數據的存儲位置。
config:配置字典,包含數據加載、模型訓練等參數。
shuffle:是否在每個 epoch 開始時打亂數據順序。
- 訓練階段??:設為?
True,避免模型記憶數據順序,提升泛化能力。 - ??驗證/測試階段??:設為?
False,確保結果可復現。
dg:DataGenerator?類的實例,負責 ??數據加載與預處理??
dl:DataLoader?類的實例,負責 ??批量數據生成與加載??。
DataLoader():將自定義數據集(如?Dataset?或?DataGenerator)封裝為 ??可迭代的批量數據加載器??
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
dataset | Dataset | 必填 | 數據集對象(需實現?__len__?和?__getitem__?方法)。 |
batch_size | int | 1 | 每個批次的樣本數量。 |
shuffle | bool | False | 是否在每個 epoch 開始時打亂數據順序(推薦訓練時設為?True)。 |
num_workers | int | 0 | 數據加載的子進程數(建議設置為 CPU 核心數,如?4)。 |
drop_last | bool | False | 是否丟棄最后一個不完整的批次(當總樣本數無法被?batch_size?整除時)。 |
pin_memory | bool | False | 是否將數據復制到 CUDA 固定內存(提升 GPU 傳輸效率)。 |
collate_fn | Callable | None | 自定義批次處理函數(用于處理不同長度的序列,如填充對齊)。 |
sampler | Sampler | None | 自定義采樣策略(覆蓋?shuffle?參數)。 |
batch_sampler | Sampler | None | 自定義批次采樣策略(覆蓋?batch_size?和?drop_last)。 |
timeout | int | 0 | 數據加載的超時時間(秒,0?表示無限等待)。 |
# 用torch自帶的DataLoader類封裝數據
def load_data(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dl
9.數據加載文件測試
dg:自定義數據集對象,負責 ??加載和預處理數據??。
dl:數據加載器,將?dg?中的數據集 ??分批次加載??,支持迭代訪問。
x:輸入特征(如 BERT 的?input_ids?和?attention_mask),形狀為?(batch_size, sequence_length)。
y:標簽(如序列標注的標簽索引),形狀與?x?相同或為?(batch_size,)(分類任務)
.shape:PyTorch 張量的屬性,返回張量的維度信息。
if __name__ == "__main__":from config import Configdg = DataGenerator("ner_data/train", Config)dl = DataLoader(dg, batch_size=32)for x, y in dl:print(x.shape, y.shape)print(x[1], y[1])input()10.完整代碼
# -*- coding: utf-8 -*-import json
import re
import os
import torch
import random
import jieba
import numpy as np
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from transformers import BertTokenizer"""
數據加載
"""class DataGenerator:def __init__(self, data_path, config):self.config = configself.path = data_pathself.tokenizer = load_vocab(config["bert_path"])self.sentences = []self.schema = self.load_schema(config["schema_path"])self.load()def load(self):self.data = []with open(self.path, encoding="utf8") as f:segments = f.read().split("\n\n")for segment in segments:sentenece = []labels = [8] # cls_tokenfor line in segment.split("\n"):if line.strip() == "":continuechar, label = line.split()sentenece.append(char)labels.append(self.schema[label])sentence = "".join(sentenece)self.sentences.append(sentence)input_ids = self.encode_sentence(sentenece)labels = self.padding(labels, -1)# print(self.decode(sentence, labels))# input()self.data.append([torch.LongTensor(input_ids), torch.LongTensor(labels)])returndef encode_sentence(self, text, padding=True):return self.tokenizer.encode(text,padding="max_length",max_length=self.config["max_length"],truncation=True)def decode(self, sentence, labels):sentence = "$" + sentencelabels = "".join([str(x) for x in labels[:len(sentence) + 2]])results = defaultdict(list)for location in re.finditer("(04+)", labels):s, e = location.span()print("location", s, e)results["LOCATION"].append(sentence[s:e])for location in re.finditer("(15+)", labels):s, e = location.span()print("org", s, e)results["ORGANIZATION"].append(sentence[s:e])for location in re.finditer("(26+)", labels):s, e = location.span()print("per", s, e)results["PERSON"].append(sentence[s:e])for location in re.finditer("(37+)", labels):s, e = location.span()print("time", s, e)results["TIME"].append(sentence[s:e])return results# 補齊或截斷輸入的序列,使其可以在一個batch內運算def padding(self, input_id, pad_token=0):input_id = input_id[:self.config["max_length"]]input_id += [pad_token] * (self.config["max_length"] - len(input_id))return input_iddef __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]def load_schema(self, path):with open(path, encoding="utf8") as f:return json.load(f)def load_vocab(vocab_path):return BertTokenizer.from_pretrained(vocab_path)# 用torch自帶的DataLoader類封裝數據
def load_data(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dlif __name__ == "__main__":from config import Configdg = DataGenerator("ner_data/train", Config)dl = DataLoader(dg, batch_size=32)for x, y in dl:print(x.shape, y.shape)print(x[1], y[1])input()四、模型文件 model.py
1.導入文件
torch:導入 PyTorch 核心庫,提供張量計算、自動求導等深度學習基礎功能。
torch.nn:導入 PyTorch 的神經網絡模塊,包含常用的網絡層、損失函數等。
torch.optim:導入優化器,用于更新模型參數以最小化損失函數。
CRF:導入條件隨機場(CRF)模塊,用于 ??序列標注任務??(如 NER)
BertModel:導入 Hugging Face Transformers 庫中的預訓練 BERT 模型。
# -*- coding: utf-8 -*-import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torchcrf import CRF
from transformers import BertModel2.將字典配置包裝為對象
config:字典 (dict) ,存儲模型或應用的配置參數(如超參數、路徑設置等)
class ConfigWrapper(object):def __init__(self, config):self.config = configdef to_dict(self):return self.config3.模型初始化
nn.Module:PyTorch 所有神經網絡的基類,提供參數管理、GPU 遷移等功能。
self.config:字典,模型配置信息
ConfigWrapper():將字典配置包裝為對象
max_length:輸入序列的最大長度(如?512),用于填充或截斷
class_num:分類類別數(如 NER 任務中的實體類型數
self.bert:加載預訓練的 BERT 模型,將文本編碼為上下文相關的向量表示。
bert_path:預訓練 BERT 模型的路徑或名稱
self.classify:nn.Linear?全連接層,將 BERT 輸出的隱藏狀態映射到標簽空間
BertModel.from_pretrained():加載預訓練的 BERT 模型,生成文本的上下文相關向量表示。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
pretrained_model_name_or_path | str?或?os.PathLike | 必填 | 預訓練模型名稱(如?"bert-base-chinese")或本地路徑。 |
config | PretrainedConfig | None | 自定義模型配置(若未提供,自動加載默認配置)。 |
output_hidden_states | bool | None | 是否返回所有隱藏層的輸出。 |
return_dict | bool | True | 是否以字典形式返回輸出(代碼中設為?False,返回元組)。 |
self.crf_layer:CRF?條件隨機場層。
nn.Linear():定義全連接層,執行線性變換 ??y = xA^T + b??,將輸入數據映射到標簽空間。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
in_features | int | 必填 | 輸入特征維度(如 BERT 隱藏層維度?768)。 |
out_features | int | 必填 | 輸出特征維度(即分類類別數?class_num)。 |
bias | bool | True | 是否包含偏置項?b。 |
CRF():條件隨機場層,用于優化序列標注任務中的標簽轉移概率,提升標簽序列的合理性。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
num_tags | int | 必填 | 標簽類別數(與?class_num?一致)。 |
batch_first | bool | False | 輸入張量是否以?(batch_size, seq_len, ...)?格式組織。 |
transitions | Tensor | None | 自定義的初始轉移矩陣(若未提供,隨機初始化)。 |
self.use_crf:控制模型是否使用 CRF 層。
self.loss:計算模型輸出與真實標簽之間的損失
torch.nn.CrossEntropyLoss():計算交叉熵損失,用于衡量模型輸出與真實標簽的差異。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
ignore_index | int | -100 | 忽略的標簽索引(代碼中設為?-1,對應填充部分)。 |
reduction | str | "mean" | 損失計算方式:"none"、"mean"(默認)、"sum"。 |
class TorchModel(nn.Module):def __init__(self, config):super(TorchModel, self).__init__()self.config = ConfigWrapper(config)max_length = config["max_length"]class_num = config["class_num"]# self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)# self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=num_layers)self.bert = BertModel.from_pretrained(config["bert_path"], return_dict=False)self.classify = nn.Linear(self.bert.config.hidden_size, class_num)self.crf_layer = CRF(class_num, batch_first=True)self.use_crf = config["use_crf"]self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) # loss采用交叉熵損失4.前向計算
代碼運行流程
# forward() 方法流程├── 1. ?**?輸入處理?**?
│ ├→ `x`: 輸入張量(如 token IDs,形狀 `(batch_size, seq_len)`)
│ └→ `target`: 真實標簽(可選,形狀 `(batch_size, seq_len)` 或 `(batch_size,)`)├── 2. ?**?BERT 編碼?**?
│ └→ `x, _ = self.bert(x)`
│ - `x`: BERT 輸出的最后一層隱藏狀態(形狀 `(batch_size, seq_len, hidden_size)`)
│ - `_`: 忽略的池化輸出(通常用于分類任務)。├── 3. ?**?分類層映射?**?
│ └→ `predict = self.classify(x)`
│ - `predict`: 模型輸出的 logits(形狀 `(batch_size, seq_len, num_tags)`)├── 4. ?**?分支條件:是否存在真實標簽 (target)?**?
│ │
│ ├── 4.1 ?**?存在真實標簽 (訓練階段)?**?
│ │ │
│ │ ├── 4.1.1 ?**?是否使用 CRF?**?
│ │ │ ├→ ?**?是?**?:
│ │ │ │ ├→ `mask = target.gt(-1)`
│ │ │ │ │ - `mask`: 有效標簽掩碼(形狀 `(batch_size, seq_len)`,`True` 表示非填充位置)
│ │ │ │ └→ `return -self.crf_layer(predict, target, mask, reduction="mean")`
│ │ │ │ - 計算 CRF 的負對數似然損失(標量)。
│ │ │ └→ ?**?否?**?:
│ │ │ └→ `return self.loss(predict.view(-1, num_tags), target.view(-1))`
│ │ │ - 使用交叉熵損失(展平后的 logits 和標簽)。
│ │ └── 4.1.2 ?**?結束分支?**?
│ │
│ └── 4.2 ?**?無真實標簽 (預測階段)?**?
│ │
│ ├── 4.2.1 ?**?是否使用 CRF?**?
│ │ ├→ ?**?是?**?:
│ │ │ └→ `return self.crf_layer.decode(predict)`
│ │ │ - 返回 Viterbi 解碼后的標簽序列(形狀 `(batch_size, seq_len)`)。
│ │ └→ ?**?否?**?:
│ │ └→ `return predict`
│ │ - 直接返回 logits(形狀 `(batch_size, seq_len, num_tags)`)。
│ └── 4.2.2 ?**?結束分支?**?└── 5. ?**?返回結果?**?├→ ?**?訓練模式?**?: 返回損失值(標量)。└→ ?**?預測模式?**?: 返回預測標簽或 logits。x:輸入張量,表示分詞后的 token IDs,形狀?(batch_size, sequence_length)
target:真實標簽,訓練時提供,預測時為?None。
predict:模型輸出的 logits,形狀由任務類型決定。
self.bert():預訓練的 BERT 模型,用于文本編碼。
????????x??:BERT 的最后一層隱藏狀態,形狀為?(batch_size, sequence_length, hidden_size)(如?(32, 128, 768))。
??_??:忽略的池化輸出(通常用于分類任務,此處未使用)。
self.classify():線性層(nn.Linear),將 BERT 輸出映射到標簽空間。
self.use_crf:控制是否使用 CRF 層優化輸出序列。
mask:有效標簽掩碼(僅 CRF 使用),過濾填充位置。
.gt():比較張量中的元素是否大于給定值,返回布爾類型掩碼。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
other | Tensor?或標量 | 是 | 無 | 比較的閾值或相同形狀的張量。 |
self.crf_layer():CRF 層,計算負對數似然損失。
self.loss():計算交叉熵損失(非 CRF 模式)。
view():調整張量的形狀(類似?reshape),不改變數據內容。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
*shape | 可變參數(整數) | 是 | 無 | 目標形狀的維度值(如?2,3)。 |
shape():返回張量的維度形狀(元組形式)。
self.crf_layer[CRF()].decode():使用Viterbi維特比算法解碼最優標簽序列,返回最優標簽序列。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
emissions | Tensor | 是 | 無 | 模型的發射分數(logits)。 |
mask | BoolTensor?或?None | 否 | None | 有效位置掩碼(None?表示全有效)。 |
# 當輸入真實標簽,返回loss值;無真實標簽,返回預測值def forward(self, x, target=None):# x = self.embedding(x) #input shape:(batch_size, sen_len)# x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)x, _ = self.bert(x)predict = self.classify(x) # ouput:(batch_size, sen_len, num_tags) -> (batch_size * sen_len, num_tags)if target is not None:if self.use_crf:mask = target.gt(-1)return - self.crf_layer(predict, target, mask, reduction="mean")else:# (number, class_num), (number)return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))else:if self.use_crf:return self.crf_layer.decode(predict)else:return predict5.選擇優化器
config:存儲模型訓練的超參數配置信息
model:PyTorch 模型實例,待訓練的神經網絡模型,包含所有可訓練參數(權重和偏置)。
optimizer:字符串,指定優化器類型,決定如何更新模型參數以最小化損失函數。
learning_rate:浮點數,定義優化器的學習率,控制優化器在參數更新時的步長大小,直接影響模型收斂速度和穩定性。
Adam():自適應學習率優化器,適用于大多數深度學習任務。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
params | iterable | 必填 | 模型的參數集合(通常來自?model.parameters())。 |
lr | float | 1e-3 | 學習率(控制參數更新步長)。 |
betas | Tuple[float, float] | (0.9, 0.999) | 用于計算梯度一階矩和二階矩的衰減系數(動量項)。 |
eps | float | 1e-8 | 數值穩定性項,防止除以零。 |
weight_decay | float | 0 | L2 正則化系數(用于防止過擬合)。 |
amsgrad | bool | False | 是否使用 AMSGrad 變體(改進數值穩定性)。 |
SGD():隨機梯度下降優化器,需手動調整學習率和動量參數。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
params | iterable | 必填 | 模型的參數集合(通常來自?model.parameters())。 |
lr | float | 必填 | 學習率(控制參數更新步長)。 |
momentum | float | 0 | 動量因子(加速梯度下降過程)。 |
dampening | float | 0 | 動量抑制因子(防止動量過大)。 |
weight_decay | float | 0 | L2 正則化系數(用于防止過擬合)。 |
nesterov | bool | False | 是否使用 Nesterov 動量(改進梯度方向計算)。 |
model.parameters():返回模型的所有可訓練參數(torch.nn.Parameter?對象)
def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)6.模型文件測試
if __name__ == "__main__":from config import Configmodel = TorchModel(Config)7.完整代碼
# -*- coding: utf-8 -*-import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from torchcrf import CRF
from transformers import BertModel"""
建立網絡模型結構
"""class ConfigWrapper(object):def __init__(self, config):self.config = configdef to_dict(self):return self.configclass TorchModel(nn.Module):def __init__(self, config):super(TorchModel, self).__init__()self.config = ConfigWrapper(config)max_length = config["max_length"]class_num = config["class_num"]# self.embedding = nn.Embedding(vocab_size, hidden_size, padding_idx=0)# self.layer = nn.LSTM(hidden_size, hidden_size, batch_first=True, bidirectional=True, num_layers=num_layers)self.bert = BertModel.from_pretrained(config["bert_path"], return_dict=False)self.classify = nn.Linear(self.bert.config.hidden_size, class_num)self.crf_layer = CRF(class_num, batch_first=True)self.use_crf = config["use_crf"]self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) # loss采用交叉熵損失# 當輸入真實標簽,返回loss值;無真實標簽,返回預測值def forward(self, x, target=None):# x = self.embedding(x) #input shape:(batch_size, sen_len)# x, _ = self.layer(x) #input shape:(batch_size, sen_len, input_dim)x, _ = self.bert(x)predict = self.classify(x) # ouput:(batch_size, sen_len, num_tags) -> (batch_size * sen_len, num_tags)if target is not None:if self.use_crf:mask = target.gt(-1)return - self.crf_layer(predict, target, mask, reduction="mean")else:# (number, class_num), (number)return self.loss(predict.view(-1, predict.shape[-1]), target.view(-1))else:if self.use_crf:return self.crf_layer.decode(predict)else:return predictdef choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)if __name__ == "__main__":from config import Configmodel = TorchModel(Config)五、模型評估文件 evaluate.py
1.類初始化
config:提供評估所需的路徑和超參數。
model:執行預測任務的核心模型。
logger:記錄評估過程的關鍵指標。
self.valid_data:調用?load_data?加載驗證集數據,結果存儲在?self.valid_data?中
load_data():負責驗證集數據的標準化加載與預處理
????????config:配置信息,用于控制數據加載的細節。????????
????????shuffle:是否打亂數據順序(驗證集通常設為?False?以保證結果可復現)。
????????config["valid_data_path"]:驗證集數據文件或目錄路徑
class Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = loggerself.valid_data = load_data(config["valid_data_path"], config, shuffle=False)2.評估模型方法
代碼運行流程
# `eval()` 方法運行流程├── 1. ?**?初始化評估狀態?**?
│ ├── `self.logger.info("開始測試第%d輪模型效果:" % epoch)`
│ │ - 記錄日志:開始第 `epoch` 輪的模型評估。
│ └── `self.stats_dict = {實體類型: defaultdict(int)}`
│ - 初始化統計字典,記錄每個實體類別的 TP/FP/FN(后續由 `write_stats` 填充)。├── 2. ?**?設置模型為評估模式?**?
│ └── `self.model.eval()`
│ - 關閉 dropout 和 batch normalization 的隨機性。├── 3. ?**?遍歷驗證數據批次?**?
│ │
│ ├── 3.1 ?**?獲取當前批次的原始句子?**?
│ │ └── `sentences = self.valid_data.dataset.sentences[...]`
│ │ - 從數據集中提取當前批次對應的原始文本(用于后續結果分析)。
│ │
│ ├── 3.2 ?**?數據遷移至 GPU(如果可用)?**?
│ │ └── `batch_data = [d.cuda() for d in batch_data]`
│ │ - 將輸入數據移至 GPU 加速計算。
│ │
│ ├── 3.3 ?**?解析輸入和標簽?**?
│ │ └── `input_id, labels = batch_data`
│ │ - 分離輸入(`input_id`)和真實標簽(`labels`)。
│ │
│ ├── 3.4 ?**?禁用梯度計算?**?
│ │ └── `with torch.no_grad():`
│ │ - 關閉梯度計算,減少內存占用。
│ │
│ ├── 3.5 ?**?模型預測?**?
│ │ └── `pred_results = self.model(input_id)`
│ │ - 使用模型對輸入進行預測(不計算損失,僅前向傳播)。
│ │
│ └── 3.6 ?**?統計預測結果?**?
│ └── `self.write_stats(labels, pred_results, sentences)`
│ - 對比預測結果和真實標簽,更新 `stats_dict`(如統計 TP/FP/FN)。├── 4. ?**?輸出評估結果?**?
│ └── `self.show_stats()`
│ - 計算并打印精確率、召回率、F1 值等指標。└── 5. ?**?返回?**?└── `return` - 結束評估,可能返回統計結果(代碼中未顯式返回)。epoch:當前評估的輪次(整數),用于日志記錄(如“第5輪模型效果”)
logger.info():記錄信息級別的日志,用于輸出程序運行狀態或調試信息
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的變量參數。 |
?**?kwargs | dict | {} | 關鍵字參數(如?exc_info)。 |
self.stats_dict:按實體類別(如?LOCATION)存儲統計信息的字典,每個類別對應一個?defaultdict(int),用于統計 ??TP(True Positive)??、??FP(False Positive)??、??FN(False Negative)
defaultdict():創建帶有默認值的字典,當訪問不存在的鍵時返回默認值(由工廠函數指定)
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
default_factory | Callable | 必填 | 生成默認值的工廠函數(如?int、list)。 |
model.eval():將 PyTorch 模型設置為評估模式(關閉 Dropout 和 Batch Normalization 的隨機性)
index:當前批次的索引(整數)
batch_data:當前批次的輸入數據和標簽,格式由?DataLoader?的?collate_fn?決定(通常為?(input_ids, labels))。
enumerate():遍歷可迭代對象(如列表、DataLoader),返回索引和元素的組合。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
iterable | Iterable | 必填 | 可迭代對象(如列表、DataLoader)。 |
start | int | 0 | 索引的起始值。 |
self.valid_data:調用?load_data?加載驗證集數據,結果存儲在?self.valid_data?中
sentences:當前批次對應的原始文本列表(用于調試或結果分析)
torch.cuda.is_available():檢查當前系統是否支持 CUDA(即 GPU 加速是否可用)。
cuda():將張量或模型遷移到 GPU 上以加速計算。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
device | int?或?torch.device | None | 目標 GPU 設備號(如?0)。若未指定,使用當前設備。 |
input_id:模型的輸入張量,形狀為?(batch_size, sequence_length),表示分詞后的 token IDs
labels:真實標簽張量,形狀與?input_id?相同,每個位置為類別索引。
torch.no_grad():上下文管理器,禁用梯度計算以節省內存和計算資源。
pred_results:模型的預測輸出
self.wite_stats:自定義方法,對比?labels?和?pred_results,更新?self.stats_dict?中的 TP/FP/FN。
self.show_stats():自定義方法,基于?self.stats_dict?計算并打印評估指標(如精確率、召回率、F1 值)。
def eval(self, epoch):self.logger.info("開始測試第%d輪模型效果:" % epoch)self.stats_dict = {"LOCATION": defaultdict(int),"TIME": defaultdict(int),"PERSON": defaultdict(int),"ORGANIZATION": defaultdict(int)}self.model.eval()for index, batch_data in enumerate(self.valid_data):sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data #輸入變化時這里需要修改,比如多輸入,多輸出的情況with torch.no_grad():pred_results = self.model(input_id) #不輸入labels,使用模型當前參數進行預測self.write_stats(labels, pred_results, sentences)self.show_stats()return3.統計寫入
代碼運行流程
# write_stats() 方法運行流程├── 1. 輸入驗證
│ └→ `assert len(labels) == len(pred_results) == len(sentences)`
│ - 確保輸入數據一致性(樣本數相同)├── 2. 處理預測結果(條件分支)
│ ├── ?**?條件?**?: `if not self.config["use_crf"]`
│ │ └→ `pred_results = torch.argmax(pred_results, dim=-1)`
│ │ - 將 logits 轉換為預測標簽索引(非 CRF 模型)
│ └── ?**?否則?**?(使用 CRF):
│ └→ 直接使用 CRF 解碼后的標簽序列├── 3. 遍歷每個樣本
│ │
│ ├── 3.1 轉換預測標簽(非 CRF 情況)
│ │ ├── ?**?條件?**?: `if not self.config["use_crf"]`
│ │ │ └→ `pred_label = pred_label.cpu().detach().tolist()`
│ │ │ - 將 GPU 張量 → CPU 列表(如 `[0, 1, 2]`)
│ │ └→ `true_label = true_label.cpu().detach().tolist()`
│ │ - 真實標簽同樣轉換為列表
│ │
│ ├── 3.2 解碼實體
│ │ ├→ `true_entities = self.decode(sentence, true_label)`
│ │ │ - 解碼真實標簽,得到實體字典(如 `{"LOCATION": [(0, 2)]}`)
│ │ └→ `pred_entities = self.decode(sentence, pred_label)`
│ │ - 解碼預測標簽,得到預測的實體字典
│ │
│ └── 3.3 統計指標
│ └→ ?**?遍歷每個實體類型?**?:
│ ├→ `self.stats_dict[key]["正確識別"] += ...`
│ ├→ `self.stats_dict[key]["樣本實體數"] += ...`
│ └→ `self.stats_dict[key]["識別出實體數"] += ...`└── 4. 返回└→ `return`- 更新后的統計字典將用于計算精確率、召回率labels:真實標簽張量,形狀為?(batch_size, sequence_length),每個元素為類別索引。
pred_results:模型預測輸出(CRF 解碼后的標簽或 logits)。
??????????未使用 CRF??:形狀為?(batch_size, sequence_length, class_num)?的 logits。
????????使用 CRF??:形狀為?(batch_size, sequence_length)?的預測標簽索引。
sentences:原始文本列表(長度為?batch_size),用于實體解碼時的上下文參考。
assert:斷言條件為真,否則拋出?AssertionError,用于調試時驗證程序邏輯。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
condition | 布爾表達式 | 必填 | 斷言條件,若為?False?觸發異常。 |
message | str | "" | 可選錯誤消息(如?assert x > 0, "x必須大于0")。 |
config["use_crf"]:配置項,控制是否使用 CRF 層(影響預測結果處理方式)。
torch.argmax():返回張量中最大值所在的索引,用于將模型輸出的 logits 轉換為預測標簽。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
input | torch.Tensor | 必填 | 輸入張量(如模型輸出的 logits)。 |
dim | int | 必填 | 沿指定維度取最大值索引(如?dim=-1?表示最后一個維度)。 |
keepdim | bool | False | 是否保持輸出張量的維度(如保持?(batch_size, 1)?而非?(batch_size,))。 |
pred_lable:單個樣本的預測標簽列表(格式同?true_label)。
true_label:單個樣本的真實標簽列表(如?[0, 1, 2, 0])
cpu():將張量從 GPU 遷移到 CPU,便于后續處理(如轉換為列表)。
detach():從計算圖中分離張量,阻斷梯度傳播,通常用于評估階段。
tolist():將張量(Tensor)轉換為 Python 列表(List),便于序列化或非張量操作。
true_entities:真實實體字典,鍵為實體類型,值為實體位置列表(如?[(0, 2)])。
self.decode():自定義方法,將標簽序列解碼為實體字典(輸入:文本和標簽列表)。
pred_entities:預測實體字典,結構同?true_entities。
self.state_dict:統計字典,按實體類型存儲?正確識別、樣本實體數、識別出實體數。
ent:代表預測的單個實體,通常以 ??實體位置范圍(起始索引,結束索引)?? 的形式存在。
def write_stats(self, labels, pred_results, sentences):assert len(labels) == len(pred_results) == len(sentences)if not self.config["use_crf"]:pred_results = torch.argmax(pred_results, dim=-1)for true_label, pred_label, sentence in zip(labels, pred_results, sentences):if not self.config["use_crf"]:pred_label = pred_label.cpu().detach().tolist()true_label = true_label.cpu().detach().tolist()true_entities = self.decode(sentence, true_label)pred_entities = self.decode(sentence, pred_label)# 正確率 = 識別出的正確實體數 / 識別出的實體數# 召回率 = 識別出的正確實體數 / 樣本的實體數for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:self.stats_dict[key]["正確識別"] += len([ent for ent in pred_entities[key] if ent in true_entities[key]])self.stats_dict[key]["樣本實體數"] += len(true_entities[key])self.stats_dict[key]["識別出實體數"] += len(pred_entities[key])return4.統計結果展示
代碼運行流程
# show_stats() 方法運行流程├── 1. 初始化 Macro-F1 存儲列表
│ └→ F1_scores = []├── 2. 遍歷每個實體類型
│ │
│ ├── 2.1 計算精確率(Precision)
│ │ └→ precision = 正確識別數 / (識別出實體數 + 1e-5)
│ │
│ ├── 2.2 計算召回率(Recall)
│ │ └→ recall = 正確識別數 / (樣本實體數 + 1e-5)
│ │
│ ├── 2.3 計算 F1 值
│ │ └→ F1 = 2 * (precision * recall) / (precision + recall + 1e-5)
│ │
│ ├── 2.4 記錄日志(實體級別的指標)
│ │ └→ self.logger.info("%s類實體,準確率:%f, 召回率: %f, F1: %f" % ...)
│ │
│ └── 2.5 存儲 F1 值
│ └→ F1_scores.append(F1)├── 3. 計算并記錄 Macro-F1
│ └→ self.logger.info("Macro-F1: %f" % np.mean(F1_scores))├── 4. 計算 Micro-F1
│ │
│ ├── 4.1 匯總全局統計量
│ │ ├→ correct_pred = sum(所有實體的正確識別數)
│ │ ├→ total_pred = sum(所有實體的識別出實體數)
│ │ └→ true_enti = sum(所有實體的樣本實體數)
│ │
│ ├── 4.2 計算 Micro-Precision 和 Micro-Recall
│ │ ├→ micro_precision = correct_pred / (total_pred + 1e-5)
│ │ └→ micro_recall = correct_pred / (true_enti + 1e-5)
│ │
│ ├── 4.3 計算 Micro-F1
│ │ └→ micro_f1 = 2 * (micro_precision * micro_recall) / (...)
│ │
│ └── 4.4 記錄日志(Micro-F1)
│ └→ self.logger.info("Micro-F1 %f" % micro_f1)└── 5. 結束├→ self.logger.info("--------------------")└→ returnF1_scores:存儲每個實體類型的 F1 值,用于計算 ??Macro-F1??。
key:代表當前遍歷的實體類別名稱??,用于逐個處理模型在驗證集上需要統計的實體類型。
precision:精確率:正確識別數 / 預測實體總數(TP / (TP + FP))
self.stats_dict:統計字典,存儲每個實體類型的?正確識別、樣本實體數、識別出實體數。
recall:召回率:正確識別數 / 真實實體總數(TP / (TP + FN))
F1:F1 值:精確率和召回率的調和平均值。
self.logger:日志記錄器,用于輸出評估結果。
logger.info():記錄信息級別的日志,輸出程序運行狀態或評估結果。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串,如?"準確率:%f" % 0.85)。 |
*args | tuple | () | 格式化字符串的變量參數(如?%f?對應的浮點數)。 |
?**?kwargs | dict | {} | 關鍵字參數(如?exc_info=True?記錄異常信息)。 |
correct_pred:所有實體類型的 ??總正確識別數??(Micro-F1 的分子)。
sum():計算可迭代對象(如列表、生成器)中所有元素的和。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
iterable | Iterable | 必填 | 可迭代對象(如?[1, 2, 3]?或生成器表達式)。 |
start | int/float | 0 | 起始累加值(如?sum([1, 2], start=10)?結果為?13)。 |
total_pred:所有實體類型的 ??總預測實體數??(Micro-Precision 的分母)。
true_enti:所有實體類型的 ??總真實實體數??(Micro-Recall 的分母)。
micro_precision:全局正確識別數 / 全局預測實體數。
micro_recall:全局正確識別數 / 全局真實實體數。
micro_f1:全局精確率和召回率的調和平均值。
def show_stats(self):F1_scores = []for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:# 正確率 = 識別出的正確實體數 / 識別出的實體數# 召回率 = 識別出的正確實體數 / 樣本的實體數precision = self.stats_dict[key]["正確識別"] / (1e-5 + self.stats_dict[key]["識別出實體數"])recall = self.stats_dict[key]["正確識別"] / (1e-5 + self.stats_dict[key]["樣本實體數"])F1 = (2 * precision * recall) / (precision + recall + 1e-5)F1_scores.append(F1)self.logger.info("%s類實體,準確率:%f, 召回率: %f, F1: %f" % (key, precision, recall, F1))self.logger.info("Macro-F1: %f" % np.mean(F1_scores))correct_pred = sum([self.stats_dict[key]["正確識別"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])total_pred = sum([self.stats_dict[key]["識別出實體數"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])true_enti = sum([self.stats_dict[key]["樣本實體數"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])micro_precision = correct_pred / (total_pred + 1e-5)micro_recall = correct_pred / (true_enti + 1e-5)micro_f1 = (2 * micro_precision * micro_recall) / (micro_precision + micro_recall + 1e-5)self.logger.info("Micro-F1 %f" % micro_f1)self.logger.info("--------------------")return5.解碼
分組類別規定
{"B-LOCATION": 0,"B-ORGANIZATION": 1,"B-PERSON": 2,"B-TIME": 3,"I-LOCATION": 4,"I-ORGANIZATION": 5,"I-PERSON": 6,"I-TIME": 7,"O": 8}代碼運行流程
# decode() 方法運行流程├── 1. 預處理輸入
│ ├→ `sentence = "$" + sentence`
│ │ - 在句子開頭添加 `$` 符號(可能是為了對齊索引)。
│ └→ `labels = "".join([str(x) for x in labels[:len(sentence)+1]])`
│ - 將標簽列表轉換為字符串(如 `[0,4,4]` → `"044"`),并截斷至 `len(sentence)+1` 長度。├── 2. 初始化結果字典
│ └→ `results = defaultdict(list)`├── 3. 正則匹配實體標簽序列
│ │
│ ├── 3.1 匹配 LOCATION 實體
│ │ └→ `for location in re.finditer("(04+)", labels):`
│ │ - 正則模式 `04+`:匹配以 `0`(B-LOCATION)開頭,后跟多個 `4`(I-LOCATION)的序列。
│ │
│ ├── 3.2 匹配 ORGANIZATION 實體
│ │ └→ `for location in re.finditer("(15+)", labels):`
│ │ - 正則模式 `15+`:匹配以 `1`(B-ORGANIZATION)開頭,后跟多個 `5`(I-ORGANIZATION)的序列。
│ │
│ ├── 3.3 匹配 PERSON 實體
│ │ └→ `for location in re.finditer("(26+)", labels):`
│ │ - 正則模式 `26+`:匹配以 `2`(B-PERSON)開頭,后跟多個 `6`(I-PERSON)的序列。
│ │
│ └── 3.4 匹配 TIME 實體
│ └→ `for location in re.finditer("(37+)", labels):`
│ - 正則模式 `37+`:匹配以 `3`(B-TIME)開頭,后跟多個 `7`(I-TIME)的序列。├── 4. 提取實體文本
│ └→ 對每個匹配的實體位置 `(s, e)`:
│ - `results[實體類型].append(sentence[s:e])`
│ - 從預處理后的句子中提取子串(如 `sentence[1:3]` 對應原句子的 `0:2`)。└── 5. 返回結果└→ `return results`sentence:原始文本句子
labels:標簽序列(每個元素為索引值,對應 BIO 標簽,如?0?表示?B-LOCATION)。
字符串.join():將可迭代對象(如列表、元組)中的元素用指定字符串連接,生成一個新的字符串。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
iterable | Iterable | 必填 | 包含字符串元素的可迭代對象(如列表?["a", "b", "c"])。 |
str():?將對象轉換為字符串類型。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
object | 任意類型 | 必填 | 需要轉換為字符串的對象(如整數、浮點數、列表等)。 |
results:存儲實體的字典,鍵為實體類型,值為實體文本列表。
defaultdict():創建一個默認字典,當訪問不存在的鍵時返回指定類型的默認值(如空列表、0)
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
default_factory | Callable | 必填 | 生成默認值的工廠函數(如?int、list、lambda: "N/A")。 |
location:正則匹配結果,包含實體位置信息(span()?方法返回?(s, e))。
s、e:實體在預處理后句子中的起始和結束索引。
re.finditer():在字符串中查找所有匹配正則表達式的子串,返回一個迭代器(包含?re.Match?對象)。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
pattern | str | 必填 | 正則表達式模式(如?r"\d+")。 |
string | str | 必填 | 要搜索的字符串。 |
flags | int | 0 | 正則表達式標志(如?re.IGNORECASE)。 |
字符串.span():返回正則表達式匹配的子串在原始字符串中的起始和結束位置(元組?(start, end))
列表.append():在列表末尾添加一個元素。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
element | 任意類型 | 必填 | 要添加到列表末尾的元素。 |
'''{"B-LOCATION": 0,"B-ORGANIZATION": 1,"B-PERSON": 2,"B-TIME": 3,"I-LOCATION": 4,"I-ORGANIZATION": 5,"I-PERSON": 6,"I-TIME": 7,"O": 8}'''def decode(self, sentence, labels):sentence = "$" + sentencelabels = "".join([str(x) for x in labels[:len(sentence)+1]])results = defaultdict(list)for location in re.finditer("(04+)", labels):s, e = location.span()results["LOCATION"].append(sentence[s:e])for location in re.finditer("(15+)", labels):s, e = location.span()results["ORGANIZATION"].append(sentence[s:e])for location in re.finditer("(26+)", labels):s, e = location.span()results["PERSON"].append(sentence[s:e])for location in re.finditer("(37+)", labels):s, e = location.span()results["TIME"].append(sentence[s:e])return results
6.完整代碼
# -*- coding: utf-8 -*-
import torch
import re
import numpy as np
from collections import defaultdict
from loader import load_data"""
模型效果測試
"""class Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = loggerself.valid_data = load_data(config["valid_data_path"], config, shuffle=False)def eval(self, epoch):self.logger.info("開始測試第%d輪模型效果:" % epoch)self.stats_dict = {"LOCATION": defaultdict(int),"TIME": defaultdict(int),"PERSON": defaultdict(int),"ORGANIZATION": defaultdict(int)}self.model.eval()for index, batch_data in enumerate(self.valid_data):sentences = self.valid_data.dataset.sentences[index * self.config["batch_size"]: (index+1) * self.config["batch_size"]]if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data #輸入變化時這里需要修改,比如多輸入,多輸出的情況with torch.no_grad():pred_results = self.model(input_id) #不輸入labels,使用模型當前參數進行預測self.write_stats(labels, pred_results, sentences)self.show_stats()returndef write_stats(self, labels, pred_results, sentences):assert len(labels) == len(pred_results) == len(sentences)if not self.config["use_crf"]:pred_results = torch.argmax(pred_results, dim=-1)for true_label, pred_label, sentence in zip(labels, pred_results, sentences):if not self.config["use_crf"]:pred_label = pred_label.cpu().detach().tolist()true_label = true_label.cpu().detach().tolist()true_entities = self.decode(sentence, true_label)pred_entities = self.decode(sentence, pred_label)# 正確率 = 識別出的正確實體數 / 識別出的實體數# 召回率 = 識別出的正確實體數 / 樣本的實體數for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:self.stats_dict[key]["正確識別"] += len([ent for ent in pred_entities[key] if ent in true_entities[key]])self.stats_dict[key]["樣本實體數"] += len(true_entities[key])self.stats_dict[key]["識別出實體數"] += len(pred_entities[key])returndef show_stats(self):F1_scores = []for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]:# 正確率 = 識別出的正確實體數 / 識別出的實體數# 召回率 = 識別出的正確實體數 / 樣本的實體數precision = self.stats_dict[key]["正確識別"] / (1e-5 + self.stats_dict[key]["識別出實體數"])recall = self.stats_dict[key]["正確識別"] / (1e-5 + self.stats_dict[key]["樣本實體數"])F1 = (2 * precision * recall) / (precision + recall + 1e-5)F1_scores.append(F1)self.logger.info("%s類實體,準確率:%f, 召回率: %f, F1: %f" % (key, precision, recall, F1))self.logger.info("Macro-F1: %f" % np.mean(F1_scores))correct_pred = sum([self.stats_dict[key]["正確識別"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])total_pred = sum([self.stats_dict[key]["識別出實體數"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])true_enti = sum([self.stats_dict[key]["樣本實體數"] for key in ["PERSON", "LOCATION", "TIME", "ORGANIZATION"]])micro_precision = correct_pred / (total_pred + 1e-5)micro_recall = correct_pred / (true_enti + 1e-5)micro_f1 = (2 * micro_precision * micro_recall) / (micro_precision + micro_recall + 1e-5)self.logger.info("Micro-F1 %f" % micro_f1)self.logger.info("--------------------")return'''{"B-LOCATION": 0,"B-ORGANIZATION": 1,"B-PERSON": 2,"B-TIME": 3,"I-LOCATION": 4,"I-ORGANIZATION": 5,"I-PERSON": 6,"I-TIME": 7,"O": 8}'''def decode(self, sentence, labels):sentence = "$" + sentencelabels = "".join([str(x) for x in labels[:len(sentence)+1]])results = defaultdict(list)for location in re.finditer("(04+)", labels):s, e = location.span()results["LOCATION"].append(sentence[s:e])for location in re.finditer("(15+)", labels):s, e = location.span()results["ORGANIZATION"].append(sentence[s:e])for location in re.finditer("(26+)", labels):s, e = location.span()results["PERSON"].append(sentence[s:e])for location in re.finditer("(37+)", labels):s, e = location.span()results["TIME"].append(sentence[s:e])return results六、模型訓練文件 main.py
代碼運行流程
# 主程序運行流程├── 1. ?**?初始化配置和日志?**?
│ └→ `logging.basicConfig(...)`:配置日志格式和級別。├── 2. ?**?定義 PEFT 包裝函數?**?
│ └→ `peft_wrapper(model)`:應用 LoRA 微調配置到模型。├── 3. ?**?主函數 `main(config)`?**?
│ │
│ ├── 3.1 ?**?創建模型保存目錄?**?
│ │ └→ `os.mkdir(config["model_path"])`(如果目錄不存在)。
│ │
│ ├── 3.2 ?**?加載訓練數據?**?
│ │ └→ `train_data = load_data(...)`:加載預處理后的訓練數據。
│ │
│ ├── 3.3 ?**?初始化模型并應用 PEFT?**?
│ │ ├→ `model = TorchModel(config)`:構建基礎模型。
│ │ └→ `model = peft_wrapper(model)`:添加 LoRA 適配器。
│ │
│ ├── 3.4 ?**?遷移模型至 GPU(如果可用)?**?
│ │ └→ `model = model.cuda()`。
│ │
│ ├── 3.5 ?**?加載優化器?**?
│ │ └→ `optimizer = choose_optimizer(...)`:根據配置選擇優化器(如 Adam)。
│ │
│ ├── 3.6 ?**?初始化評估器?**?
│ │ └→ `evaluator = Evaluator(...)`:用于驗證集性能評估。
│ │
│ ├── 3.7 ?**?訓練循環?**?
│ │ │
│ │ ├── 3.7.1 ?**?遍歷每個 epoch?**?
│ │ │ ├→ `model.train()`:設置模型為訓練模式。
│ │ │ ├→ 遍歷每個批次數據:
│ │ │ │ ├→ `optimizer.zero_grad()`:清空梯度。
│ │ │ │ ├→ 數據遷移至 GPU(如果可用)。
│ │ │ │ ├→ 前向傳播:`loss = model(input_id, labels)`。
│ │ │ │ ├→ 反向傳播:`loss.backward()`。
│ │ │ │ └→ 參數更新:`optimizer.step()`。
│ │ │ └→ 記錄平均損失。
│ │ │
│ │ └── 3.7.2 ?**?每個 epoch 后的評估?**?
│ │ └→ `evaluator.eval(epoch)`:在驗證集上計算指標。
│ │
│ └── 3.8 ?**?保存最終模型?**?
│ └→ `torch.save(model.state_dict(), model_path)`。└── 4. ?**?程序入口?**?└→ `if __name__ == "__main__":`:調用 `main(Config)`。1.導入文件
torch:PyTorch 深度學習框架,用于構建、訓練和部署神經網絡。
os:操作系統交互庫,用于文件路徑處理和目錄操作。
random:生成偽隨機數,用于控制隨機性。
numpy:科學計算庫,支持多維數組和矩陣運算。
logging:日志記錄庫,用于輸出程序運行信息。
get_peft_model:將基礎模型包裝為 PEFT 模型。
LoraConfig:配置參數高效微調庫 LoRA(Low-Rank Adaptation)參數。
TaskType:指定任務類型(如序列標注、分類)。
# -*- coding: utf-8 -*-import torch
import os
import random
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from peft import get_peft_model, LoraConfig, TaskType2.日志文件配置
logger:全局日志記錄器實例,用于輸出訓練過程中的信息。
logging.basicConfig():配置日志系統的默認行為(如日志級別、格式、輸出位置)。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
level | int | WARNING | 日志級別(如?logging.INFO)。 |
format | str | 基礎格式 | 日志消息格式(如?'%(asctime)s - %(message)s')。 |
filename | str | None | 日志輸出文件路徑(如不指定則輸出到控制臺)。 |
filemode | str | 'a' | 文件寫入模式('w'?覆蓋,'a'?追加)。 |
logging.getLogger():獲取或創建一個日志記錄器實例(用于模塊化日志管理)。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
name | str | 必填 | 日志記錄器名稱(通常為模塊名)。 |
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)3.LoRA目標模塊配置(包裝函數)peft_wrapper ?
什么是LoRA
??????????LoRA(Low-Rank Adaptation,低秩適應)?? 是一種 ??參數高效微調技術??(Parameter-Efficient Fine-Tuning, PEFT),專為大型預訓練語言模型(如 BERT、GPT)設計。其核心思想是 ??通過低秩矩陣分解,僅微調模型的部分參數??,從而顯著減少訓練時的計算量和內存消耗。
LoRA的核心原理
??????????低秩矩陣分解?:在模型的權重矩陣旁插入 ??低秩適配器(Adapter)??,代替直接微調原始權重。
????????原始權重矩陣?![]() ,分解為:
,分解為: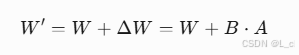 ?
?
????????![]() ,僅訓練?B?和?A??,保持?W?凍結。?
,僅訓練?B?和?A??,保持?W?凍結。?
????????參數高效性:??可訓練參數量從?d × k?減少到?r × (d + k),例如:若?d=1024,k=1024,r=8,參數從 104 萬減少到 16,384(減少 98%)。
"query"、"key":在BERT或其他Transformer架構中,每個Transformer層包含自注意力機制,其中包含三個核心線性變換矩陣:?Query (Q)??、Key (K)??、Value (V)?
這些矩陣通過線性層(nn.Linear)實現,通常命名為?attention.self.query、attention.self.key?和?attention.self.value
LoraConfig():定義 LoRA(Low-Rank Adaptation)微調策略的參數配置。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
r | int | 必填 | 低秩矩陣的秩(控制參數量)。 |
lora_alpha | int | 必填 | 縮放因子(控制低秩矩陣的影響強度)。 |
lora_dropout | float | 0.0 | LoRA 層的 Dropout 率。 |
target_modules | List[str] | 必填 | 應用 LoRA 的目標模塊(如 Transformer 的?["query", "key", "value"])。 |
get_peft_model():將基礎模型包裝為支持參數高效微調(PEFT)的模型(LoRA后的模型)。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
model | nn.Module | 必填 | 基礎模型實例。 |
peft_config | PeftConfig | 必填 | PEFT 配置對象(如?LoraConfig)。 |
def peft_wrapper(model):peft_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.1,target_modules=["query", "value"])return get_peft_model(model, peft_config)4.模型訓練主程序
① 創建保存模型的目錄
os.path.isdir():檢查指定路徑是否為目錄。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
path | str | 必填 | 待檢查的目錄路徑。 |
os.mkdir():創建新目錄。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
path | str | 必填 | 待創建的目錄路徑。 |
# 創建保存模型的目錄if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])② 加載訓練數據
train_data:加載并預處理訓練數據,生成適用于模型訓練的數據加載器。
config:配置字典,提供數據處理的詳細參數(如批次大小、最大長度、分詞方式等)。
config["train_data_path"]:訓練數據文件路徑(如?"data/train.txt"),存儲原始文本和標簽。
load_data():數據加載器封裝函數
# 加載訓練數據train_data = load_data(config["train_data_path"], config)③ 加載模型
config:模型配置,包含預訓練路徑、分類數、是否使用 CRF 等。
model:存儲模型實例。
TorchModel():根據配置構建基礎神經網絡模型。
peft_wrapper():將基礎模型轉換為參數高效微調(PEFT)版本。
# 加載模型model = TorchModel(config)model = peft_wrapper(model)④ 標識是否使用GPU
cuda_flag:GPU 是否可用的標志變量,用于控制模型是否遷移到 GPU 以優化計算性能。
torch.cuda.is_available():檢查當前系統是否支持 CUDA(即 GPU 是否可用)。
logging.info():記錄信息級別的日志消息。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的變量參數。 |
?**?kwargs | dict | {} | 關鍵字參數(如?exc_info)。 |
model.cuda():將模型遷移到 GPU 顯存以加速計算。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
device | int?或?torch.device | None | 目標 GPU 設備號(如?0)。 |
# 標識是否使用gpucuda_flag = torch.cuda.is_available()if cuda_flag:logger.info("gpu可以使用,遷移模型至gpu")model = model.cuda()⑤ 加載優化器
optimizer:優化器,用于更新模型參數以最小化損失函數。
config:存儲訓練和模型配置的字典
model:待訓練的模型實例,包含所有可訓練參數。
choose_optimizer():根據?config?選擇優化器并初始化
# 加載優化器optimizer = choose_optimizer(config, model)⑥ 加載效果測試類
evaluator:評估模型性能的類實例
config:全局配置字典,控制優化器、模型結構和訓練流程。
model:訓練和評估的目標模型,提供參數和計算圖。
logger:日志記錄器,用于輸出評估過程信息(如準確率、F1 值)。
Evaluator():評估模型性能的類,用于驗證集或測試集的指標計算(如準確率、F1 值)
# 加載效果測試類evaluator = Evaluator(config, model, logger)⑦ 訓練主流程 ?
Ⅰ、Epoch循環控制
epoch:當前訓練輪次的序號
config["epoch"]:控制訓練的總輪次(即模型遍歷完整訓練數據集的次數)
range():生成一個整數序列(常用于循環迭代)。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
start | int | 0 | 序列起始值。 |
stop | int | 必填 | 序列結束值(不包含)。 |
step | int | 1 | 步長(間隔)。 |
# 訓練for epoch in range(config["epoch"]):epoch += 1Ⅱ、模型設置訓練模式
model.train():設置模型為訓練模式(啟用 Dropout 和 BatchNorm 的隨機性)
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
mode | bool | True | 是否設置為訓練模式。 |
model.train()Ⅲ、Batch數據遍歷
logging.info():記錄信息級別的日志消息。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的變量參數。 |
?**?kwargs | dict | {} | 關鍵字參數(如?exc_info)。 |
logger:日志記錄器,用于輸出訓練過程中的關鍵信息。
train_loss:列表,存儲當前 epoch 內所有批次的損失值。
index:當前批次在 epoch 中的序號(從 0 開始計數)。
batch_data:單個批次的訓練數據,包含輸入和標簽。
epoch:當前訓練輪次的序號
enumerate():遍歷可迭代對象并返回索引和元素。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
iterable | Iterable | 必填 | 可迭代對象(如列表)。 |
start | int | 0 | 索引的起始值。 |
logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):Ⅳ、梯度清零與設備切換
optimizer.zero_grad():清空模型參數的梯度緩存。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
set_to_none | bool | False | 是否將梯度設為?None(節省內存)。 |
optimizer:優化器,用于更新模型參數以最小化損失函數。
cuda_flag:指示 GPU 是否可用(True?表示可用)。
batch_data:單個批次的訓練數據,包含輸入和標簽。
cuda():將模型遷移到 GPU 顯存以加速計算。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
device | int?或?torch.device | None | 目標 GPU 設備號(如?0)。 |
input_id:輸入文本的 token ID 序列(經過編碼處理)。
lables:與輸入對應的真實標簽(監督信號)。
optimizer.zero_grad()if cuda_flag:batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data # 輸入變化時這里需要修改,比如多輸入,多輸出的情況
Ⅴ、前向傳播與損失計算
loss:模型根據輸入?input_id?和真實標簽?labels?計算出的標量值,反映了模型預測結果與真實標簽之間的差距。
input_id:輸入文本的 token ID 序列(經過編碼處理)。
lables:與輸入對應的真實標簽(監督信號)。
loss = model(input_id, labels)Ⅵ、反向傳播與參數更新
loss:模型根據輸入?input_id?和真實標簽?labels?計算出的標量值,反映了模型預測結果與真實標簽之間的差距。
optimizer:優化器,用于更新模型參數以最小化損失函數。
loss.backward():反向傳播計算梯度。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
retain_graph | bool | False | 是否保留計算圖(用于多次反向傳播)。 |
optimizer.step():根據梯度更新模型參數。
loss.backward()optimizer.step()Ⅶ、損失記錄與日志輸出
train_loss:列表,存儲當前輪次所有批次的損失值
loss:前向傳播計算損失
index:當前批次在 epoch 中的序號(從 0 開始計數)。
train_data:訓練數據加載器,按批次(batch)提供訓練數據,支持高效的數據加載和預處理。
列表.append():在列表末尾添加元素。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
element | 任意類型 | 必填 | 要添加的元素。 |
item():將張量中的單個值轉換為 Python 標量(如?float?或?int)。
logger.info():記錄信息級別的日志消息。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的變量參數。 |
?**?kwargs | dict | {} | 關鍵字參數(如?exc_info)。 |
train_loss.append(loss.item())if index % int(len(train_data) / 2) == 0:logger.info("batch loss %f" % loss)Ⅷ、Epoch評估與日志
logger.info():記錄信息級別的日志消息。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
msg | str | 必填 | 日志消息(支持格式化字符串)。 |
*args | tuple | () | 格式化字符串的變量參數。 |
?**?kwargs | dict | {} | 關鍵字參數(如?exc_info)。 |
np.mean():計算數組或列表的平均值。
| 參數名 | 類型 | 默認值 | 說明 |
|---|---|---|---|
array | array_like | 必填 | 輸入數組或列表。 |
axis | int?或?None | None | 計算均值的維度(如?0) |
logger:日志記錄器,用于將訓練過程中的關鍵信息輸出到控制臺或日志文件。
train_loss:列表,存儲當前 epoch 內所有批次的損失值。
evaluator:評估器實例,在驗證集上評估模型的性能(如準確率、召回率、F1 值),并記錄結果
epoch:當前訓練輪次的序號(從 1 開始計數)。
logger.info("epoch average loss: %f" % np.mean(train_loss))evaluator.eval(epoch)Ⅸ、完整訓練代碼
# -*- coding: utf-8 -*-import torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from peft import get_peft_model, LoraConfig, TaskTypelogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型訓練主程序
"""def peft_wrapper(model):peft_config = LoraConfig(r=8,lora_alpha=32,lora_dropout=0.1,target_modules=["query", "value"])return get_peft_model(model, peft_config)def main(config):# 創建保存模型的目錄if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])# 加載訓練數據train_data = load_data(config["train_data_path"], config)# 加載模型model = TorchModel(config)model = peft_wrapper(model)# 標識是否使用gpucuda_flag = torch.cuda.is_available()if cuda_flag:logger.info("gpu可以使用,遷移模型至gpu")model = model.cuda()# 加載優化器optimizer = choose_optimizer(config, model)# 加載效果測試類evaluator = Evaluator(config, model, logger)# 訓練for epoch in range(config["epoch"]):epoch += 1model.train()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):optimizer.zero_grad()if cuda_flag:batch_data = [d.cuda() for d in batch_data]input_id, labels = batch_data # 輸入變化時這里需要修改,比如多輸入,多輸出的情況loss = model(input_id, labels)loss.backward()optimizer.step()train_loss.append(loss.item())if index % int(len(train_data) / 2) == 0:logger.info("batch loss %f" % loss)logger.info("epoch average loss: %f" % np.mean(train_loss))evaluator.eval(epoch)model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)torch.save(model.state_dict(), model_path)return model, train_dataif __name__ == "__main__":model, train_data = main(Config)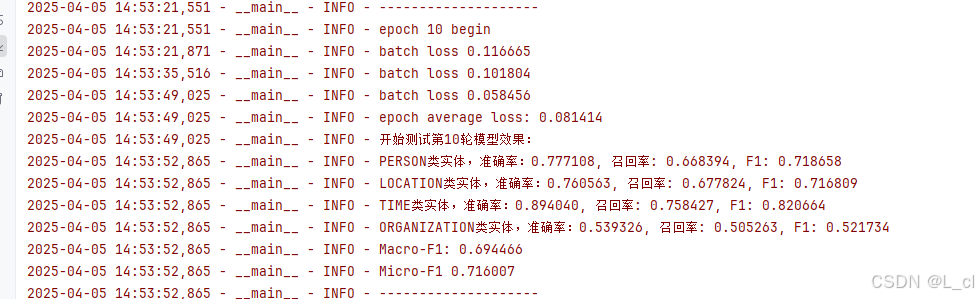
七、模型預測文件 predict.py
代碼運行流程
# 代碼運行流程樹狀圖├── 1. ?**?初始化 NER 實例?**?
│ ├→ 加載配置:`Config`
│ ├→ 加載詞匯表:`BertTokenizer.from_pretrained(bert_path)`
│ ├→ 加載實體類別定義:`load_schema(schema_path)`
│ ├→ 構建基礎模型:`TorchModel(config)`
│ ├→ 應用 PEFT 微調:`peft_wrapper(model)`
│ ├→ 加載預訓練權重:`state_dict.update(torch.load(model_path))`
│ ├→ 權重重新載入:`model.load_state_dict(state_dict)`
│ └→ 設置模型為評估模式:`model.eval()`├── 2. ?**?輸入句子預處理?**?
│ ├→ 示例輸入:`sentence = "(本報約翰內斯堡電)本報記者安洋賀廣華..."`
│ └→ 調用 `predict(sentence)` 方法。├── 3. ?**?句子編碼?**?
│ ├→ 調用 `encode_sentence(sentence)`
│ ├→ 使用 `BertTokenizer` 將文本轉換為 ID 序列:
│ │ ├→ `padding="max_length"`(填充至最大長度)
│ │ ├→ `max_length=config["max_length"]`
│ │ └→ `truncation=True`(截斷超長部分)├── 4. ?**?模型推理?**?
│ ├→ 輸入張量轉換:`torch.LongTensor([input_ids])`
│ ├→ 模型前向傳播:`model(input_ids)`
│ ├→ 輸出 logits:`res = model(...)[0]`
│ └→ 取預測標簽:`labels = torch.argmax(res, dim=-1)`├── 5. ?**?標簽解碼?**?
│ ├→ 調用 `decode(sentence, labels)`
│ ├→ ?**?預處理?**?:
│ │ ├→ 句子開頭添加 `$`:`sentence = "$" + sentence`
│ │ └→ 標簽序列轉換為字符串:`labels = "".join(...)`
│ ├→ ?**?正則匹配實體位置?**?:
│ │ ├→ `LOCATION`:模式 `04+`(B=0, I=4)
│ │ ├→ `ORGANIZATION`:模式 `15+`(B=1, I=5)
│ │ ├→ `PERSON`:模式 `26+`(B=2, I=6)
│ │ └→ `TIME`:模式 `37+`(B=3, I=7)
│ └→ ?**?提取實體文本?**?:`sentence[s:e]`├── 6. ?**?輸出結果?**?
│ └→ 示例輸出:
│ ```python
│ {
│ "LOCATION": ["約翰內斯堡"],
│ "PERSON": ["安洋", "賀廣華"],
│ ...
│ }
│ ```└── 7. ?**?程序結束?**?└→ 返回實體字典并打印。1.導入文件
torch:PyTorch 深度學習框架,提供張量計算、自動微分和 GPU 加速功能。
re:正則表達式,處理字符串的模式匹配和文本清洗。
json:讀寫 JSON 格式數據。
collections:Python 標準庫中的一個模塊,提供了許多??高效且專用的容器數據類型??,是對 Python 內置數據類型(如?list、dict、tuple?等)的補充。
defaultdict:提供帶有默認值的字典,避免鍵不存在時的?KeyError。
transformers?(Hugging Face Transformers 庫)?:提供預訓練模型(如 BERT、GPT)和 NLP 工具。
BertTokenizer:將文本轉換為 BERT 模型所需的輸入格式(如 token IDs、attention masks)。
BertModel:加載預訓練的 BERT 模型,作為特征提取器或微調的基礎。
# -*- coding: utf-8 -*-
import torch
import re
import json
from collections import defaultdict
from config import Config
from model import TorchModel
from transformers import BertTokenizer, BertModel
from main import peft_wrapper
2.初始化?
config:全局配置字典,存儲所有超參數、路徑和模型設置。
model_path:預訓練模型權重文件的路徑(如?"model/epoch_10.pth")。
self.config:將全局配置字典保存為實例屬性,方便類內其他方法訪問。
self.tokenizer:BERT 分詞器實例,用于將文本轉換為模型輸入(如 token IDs)。
config["bert_path"]:
self.schema:存儲標簽或數據結構的定義(如實體類型、分類標簽)。
config["schema_path"]:
self.load_vocab():自定義函數,加載分詞器(Tokenizer)??:將文本數據轉換為模型可處理的輸入格式(如 token IDs、attention masks)。
self.load_schema():自定義函數,??加載標簽定義(Schema)??:定義任務的輸出結構(如實體類型、分類標簽)。
model:初始化基礎模型(基于 BERT 的任務特定模型,如分類或序列標注)
TorchModel():自定義模型類
peft_wrapper():應用參數高效微調(PEFT)策略(如 LoRA)到基礎模型。
state_dict:字典,鍵為參數名,值為?torch.Tensor
model.state_dict():返回一個字典(OrderedDict),包含模型的所有可學習參數(權重和偏置)。
- ??鍵(Key)??:參數名稱(如?
"bert.encoder.layer.0.attention.query.weight")。 - ??值(Value)??:對應的參數張量(
torch.Tensor)。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
destination | dict | 否 | None | 若提供,參數將存入此字典(否則創建新字典)。 |
prefix | str | 否 | "" | 在所有鍵名前添加前綴(例如?prefix="module."?用于多 GPU 模型)。 |
keep_vars | bool | 否 | False | 保留?torch.Tensor?的計算圖信息(用于繼續訓練,通常不需設置)。 |
state_dict.update():將預訓練權重合并到當前模型的參數中。
torch.load():加載由?torch.save()?保存的對象(如模型參數、優化器狀態、張量等)。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
f | str?或?IO?對象 | 是 | - | 文件路徑或文件句柄(如打開的文件對象)。 |
map_location | str?或?dict | 否 | None | 指定加載設備(如?"cpu"?或?"cuda:0"),或映射規則(如?{"cuda:0": "cpu"})。 |
pickle_module | module | 否 | pickle | 指定反序列化模塊(通常不需修改)。 |
weights_only | bool | 否 | False | 若為?True,僅加載張量(禁止加載可能含有惡意代碼的?pickle?對象)。 |
???**?kwargs?? | - | 否 | - | 傳遞給?pickle_module.load()?的額外參數。 |
model.load_state_dict():將合并后的參數加載回模型,完成權重初始化
model.eval():將模型設置為評估模式(關閉 Dropout 和 BatchNorm 的隨機性)。
def __init__(self, config, model_path):self.config = configself.tokenizer = self.load_vocab(config["bert_path"])self.schema = self.load_schema(config["schema_path"])model = TorchModel(config)model = peft_wrapper(model)state_dict = model.state_dict()state_dict.update(torch.load(model_path))model.load_state_dict(state_dict)model.eval()self.model = modelprint("模型加載完畢!")3.加載映射關系表
path:字符串 (str),表示要加載的 JSON 文件的路徑。
f:文件對象 (TextIOWrapper),通過?open()?打開文件后的文件句柄,用于讀取文件內容。
open():打開一個文件并返回文件對象,用于讀取或寫入文件內容。支持文本模式和二進制模式,并允許指定編碼、錯誤處理等。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
file | str | 是 | - | 文件路徑(如?"data/schema.json")。 |
mode | str | 否 | 'r' | 打開模式:'r'(讀)、'w'(寫)、'a'(追加)、'b'(二進制)等。 |
encoding | str | 否 | 系統默認 | 文本編碼(如?'utf-8')。 |
errors | str | 否 | 'strict' | 編碼錯誤處理方式(如?'ignore'?忽略錯誤)。 |
newline | str | 否 | None | 控制換行符(僅文本模式)。 |
| ??其他參數?? | - | - | - | (如?buffering、closefd?等,通常無需指定)。 |
json.load():從文件對象中讀取 JSON 數據,并將其解析為 Python 對象(如字典、列表)。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
fp | 文件對象 | 是 | - | 已打開的文件對象(通過?open()?獲取)。 |
object_hook | Callable | 否 | None | 自定義 JSON 對象解碼函數(如將字典轉換為自定義類)。 |
parse_float | Callable | 否 | float | 自定義浮點數解析函數(如使用?decimal.Decimal)。 |
parse_int | Callable | 否 | int | 自定義整數解析函數。 |
| ??其他參數?? | - | - | - | (如?parse_constant、cls?等,通常無需指定)。 |
def load_schema(self, path):with open(path, encoding="utf8") as f:return json.load(f)4.加載字詞表
vocab_path:字符串 (str)?,?指定 BERT 分詞器的加載路徑
BertTokenizer.from_pretrained():加載預訓練的 BERT 分詞器(Tokenizer),將文本轉換為模型可處理的輸入格式(如 token IDs、attention masks)。支持從 Hugging Face 模型庫或本地路徑加載分詞器,確保與預訓練模型兼容,并自動處理文本的標準化、分詞、添加特殊標記(如?[CLS]、[SEP])等操作。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
pretrained_model_name_or_path | str?或?Path | 是 | - | 預訓練模型的名稱(如?"bert-base-chinese")或本地目錄路徑。 |
cache_dir | str | 否 | None | 指定模型文件的緩存目錄。 |
force_download | bool | 否 | False | 是否強制重新下載模型文件(覆蓋緩存)。 |
resume_download | bool | 否 | False | 是否支持斷點續傳下載。 |
proxies | dict | 否 | None | 設置代理服務器(如?{"http": "http://10.10.1.10:3128"})。 |
local_files_only | bool | 否 | False | 是否僅使用本地文件(不聯網下載)。 |
token | str?或?bool | 否 | None | Hugging Face 認證 Token(用于訪問私有模型)。 |
revision | str | 否 | "main" | 指定模型版本(如 Git 分支、標簽或提交哈希)。 |
use_fast | bool | 否 | True | 是否使用快速分詞器(基于 Rust 實現,速度更快)。 |
| ??其他參數?? | - | - | - | (如?trust_remote_code、mirror?等,通常無需指定)。 |
# 加載字表或詞表def load_vocab(self, vocab_path):return BertTokenizer.from_pretrained(vocab_path)
5.文本句子編碼
text:需要編碼的原始文本輸入(例如:"你好,世界")。
padding:控制是否對序列進行填充(Padding)以統一長度。
self.tokenizer:BertTokenizer,將文本轉換為模型輸入格式(token IDs、attention masks 等)。
encode():將??文本字符串??轉換為模型可處理的 ??Token ID 序列??,支持填充(Padding)、截斷(Truncation)、添加特殊標記(如?[CLS]、[SEP])等操作。
| 參數名 | 類型 | 必需 | 默認值 | 說明 | 示例值 |
|---|---|---|---|---|---|
text | str?或?List[str] | 是 | - | 要編碼的文本(單句或列表)。 | "你好,世界" |
padding | bool?或?str | 否 | False | 填充策略:True/"longest"(填充到最長序列)、"max_length"(填充到指定長度)。 | "max_length" |
max_length | int | 否 | 分詞器模型最大長度 | 控制填充或截斷后的序列長度(如?512)。 | 128 |
truncation | bool?或?str | 否 | False | 截斷策略:True(截斷到?max_length)、"only_first"(僅截斷首句)。 | True |
add_special_tokens | bool | 否 | True | 是否添加特殊標記(如 BERT 的?[CLS]?和?[SEP])。 | True |
return_tensors | str | 否 | None | 返回張量格式:"pt"(PyTorch)、"tf"(TensorFlow)、"np"(NumPy)。 | "pt" |
return_attention_mask | bool | 否 | True | 是否返回?attention_mask(標識有效 token 位置)。 | True |
| ??其他參數?? | - | - | - | (如?return_token_type_ids、return_overflowing_tokens?等)。 | - |
def encode_sentence(self, text, padding=True):return self.tokenizer.encode(text,padding="max_length",max_length=self.config["max_length"],truncation=True)6.解碼文本
代碼運行流程
decode(sentence, labels)
├─ 預處理階段
│ ├─ 修改句子:sentence = "$" + sentence
│ └─ 轉換標簽:labels → 字符串(示例:數值標簽[0,4,4,4] → "0444")
│ ├─ 截取長度:labels[:len(sentence)+1]
│ └─ 合并字符:生成連續字符串(如"0444")
├─ 初始化結果字典:results = defaultdict(list)
├─ 正則匹配實體
│ ├─ 匹配 LOCATION
│ │ ├─ 正則模式:r"(04+)" (匹配以0開頭后續多個4的標簽)
│ │ └─ 對每個匹配項:
│ │ ├─ 獲取起止位置:s, e = match.span()
│ │ └─ 提取文本:sentence[s:e] → 存入results["LOCATION"]
│ ├─ 匹配 ORGANIZATION
│ │ ├─ 正則模式:r"(15+)" (匹配以1開頭后續多個5的標簽)
│ │ └─ 對每個匹配項:
│ │ ├─ 獲取起止位置:s, e = match.span()
│ │ └─ 提取文本:sentence[s:e] → 存入results["ORGANIZATION"]
│ ├─ 匹配 PERSON
│ │ ├─ 正則模式:r"(26+)" (匹配以2開頭后續多個6的標簽)
│ │ └─ 對每個匹配項:
│ │ ├─ 獲取起止位置:s, e = match.span()
│ │ └─ 提取文本:sentence[s:e] → 存入results["PERSON"]
│ └─ 匹配 TIME
│ ├─ 正則模式:r"(37+)" (匹配以3開頭后續多個7的標簽)
│ └─ 對每個匹配項:
│ ├─ 獲取起止位置:s, e = match.span()
│ └─ 提取文本:sentence[s:e] → 存入results["TIME"]
└─ 返回結果:return results(包含所有匹配實體的字典)sentence:str?類型,原始輸入句子(如?"北京歡迎你")。
labels:數值序列(如?List[int]?或?np.ndarray),模型預測的標簽序列,每個元素對應一個字符的實體類型編碼。
join():將可迭代對象(如列表、元組)中的元素連接成一個字符串,元素之間用調用該方法的字符串(空字符串)分隔。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
iterable | 可迭代對象 | 是 | 無 | 包含字符串元素的可迭代對象(如列表)。 |
str():將對象轉換為字符串形式
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
object | 任意對象 | 是 | 無 | 需轉換為字符串的對象。 |
default():創建一個默認字典,當訪問不存在的鍵時,返回由?default_factory?生成的默認值。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
default_factory | 可調用對象 | 是 | 無 | 生成默認值的函數(如?list、int)。 |
results:存儲不同實體類型的識別結果,字典的鍵為實體類型(如?"LOCATION"),值為對應實體的文本列表。
location:通過?re.finditer?獲得的匹配對象,表示一個正則表達式匹配的結果,包含匹配的位置和文本信息。
s(start):實體標簽在?labels?字符串中的起始索引。
e(end):實體標簽在?labels?字符串中的結束索引。
re.finditer():在字符串中查找所有匹配正則表達式的子串,返回一個迭代器,每個元素是匹配對象。
Match.span:返回正則匹配的起始和結束位置(閉區間),格式為?(start, end)。
列表.append():在列表末尾添加一個元素。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
element | 任意類型 | 是 | 無 | 要添加的元素。 |
def decode(self, sentence, labels):sentence = "$" + sentencelabels = "".join([str(int(x)) for x in labels[:len(sentence) + 1]])results = defaultdict(list)for location in re.finditer("(04+)", labels):s, e = location.span()results["LOCATION"].append(sentence[s:e])for location in re.finditer("(15+)", labels):s, e = location.span()results["ORGANIZATION"].append(sentence[s:e])for location in re.finditer("(26+)", labels):s, e = location.span()results["PERSON"].append(sentence[s:e])for location in re.finditer("(37+)", labels):s, e = location.span()results["TIME"].append(sentence[s:e])return results7.預測文件
代碼運行流程
predict(sentence)
├─ 輸入處理階段
│ ├─ 調用 self.encode_sentence(sentence) → input_ids
│ │ ├─ 將句子編碼為模型輸入格式(Token ID序列)
│ │ └─ 輸出示例:[101, 123, 456, 789, 102](BERT格式)
│ └─ 轉換為張量:torch.LongTensor([input_ids])
│ ├─ 添加批次維度:[input_ids] → shape (1, seq_len)
│ └─ 示例:tensor([[101, 123, 456, 789, 102]])
├─ 模型推理階段(無梯度計算)
│ ├─ with torch.no_grad():
│ │ ├─ 模型前向傳播:self.model(input_tensor) → res
│ │ │ ├─ 輸出形狀:(batch_size, seq_len, num_labels)
│ │ │ └─ 示例:shape (1, 5, 8)(8個實體類別)
│ │ └─ 提取預測結果:res[0] → shape (seq_len, num_labels)
│ │ └─ 示例:shape (5, 8)
│ └─ 取argmax生成標簽:torch.argmax(res, dim=-1) → labels
│ ├─ 對每個token選擇最大概率的標簽
│ └─ 示例輸出:tensor([0,4,4,4,0])(數值標簽序列)
├─ 后處理階段
│ └─ 調用 self.decode(sentence, labels) → results
│ ├─ 將標簽序列解碼為實體字典
│ └─ 示例輸出:
│ {
│ "LOCATION": ["北京"],
│ "ORGANIZATION": [],
│ "PERSON": ["張三"]
│ }
└─ 返回結果:return resultssentence:輸入的原始文本句子。
input_ids:通過?self.encode_sentence()?將句子編碼后的 ??Token ID 序列??(如 BERT 的?[CLS]?+ 句子 +?[SEP])。
self.encode_sentence():將句子編碼為模型輸入的 Token ID 序列,包含分詞、添加特殊標記、填充/截斷等操作。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
text | str | 是 | 無 | 要編碼的原始文本。 |
padding | bool | 否 | True | 是否填充到固定長度。 |
torch.no_grad():上下文管理器,??禁用梯度計算??,減少內存占用并加速推理。
res:模型輸出的 ??每個 Token 的預測概率分布??。
labels:對?res?在最后一個維度(dim=-1)取 ??最大概率對應的索引??,即預測的標簽序列。
torch.LongTensor():將 Python 列表或 NumPy 數組轉換為 ??PyTorch 長整型張量??。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
data | 可迭代對象 | 是 | 無 | 要轉換為張量的數據。 |
torch.argmax():在指定維度(dim)上取最大值的索引。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
input | Tensor | 是 | 無 | 輸入張量。 |
dim | int | 是 | 無 | 要在哪個維度取最大值。 |
results:????字典??,用于存儲從輸入句子中識別出的 ??不同類別的實體及其對應的文本片段??。
字典的 ??鍵(Key)?? 是實體類別(如?"LOCATION"、"ORGANIZATION"),??值(Value)?? 是對應類別下所有實體文本組成的列表。
self.decode():?將標簽序列解碼為 ??實體字典??(如?{"LOCATION": ["北京"], "PERSON": ["張三"]})。
| 參數名 | 類型 | 必需 | 默認值 | 說明 |
|---|---|---|---|---|
sentence | str | 是 | 無 | 原始句子。 |
labels | torch.Tensor | 是 | 無 | 預測的標簽序列。 |
def predict(self, sentence):input_ids = self.encode_sentence(sentence)with torch.no_grad():res = self.model(torch.LongTensor([input_ids]))[0]labels = torch.argmax(res, dim=-1)results = self.decode(sentence, labels)return results8.模型效果測試
sl:命名實體識別模型實例??,用于加載配置和預訓練模型,執行實體識別任務。
sentence:??輸入文本??,包含需要識別的實體(如人名、地點、組織等)。
res:命名實體識別結果??,按實體類型分類存儲識別出的文本片段。
if __name__ == "__main__":sl = NER(Config, "model_output/epoch_10.pth")sentence = "(本報約翰內斯堡電)本報記者安洋賀廣華留學人員檔案庫建立本報訊中國質量體系認證機構國家認可委員會日前正式簽署了國際上第一個質量認證的多邊互認協議,表明中國質量體系認證達到了國際水平。"res = sl.predict(sentence)print(res)9.完整代碼?
# -*- coding: utf-8 -*-
import torch
import re
import json
from collections import defaultdict
from config import Config
from model import TorchModel
from transformers import BertTokenizer, BertModel
from main import peft_wrapper"""
模型效果測試
"""class NER:def __init__(self, config, model_path):self.config = configself.tokenizer = self.load_vocab(config["bert_path"])self.schema = self.load_schema(config["schema_path"])model = TorchModel(config)model = peft_wrapper(model)state_dict = model.state_dict()state_dict.update(torch.load(model_path))model.load_state_dict(state_dict)model.eval()self.model = modelprint("模型加載完畢!")def load_schema(self, path):with open(path, encoding="utf8") as f:return json.load(f)# 加載字表或詞表def load_vocab(self, vocab_path):return BertTokenizer.from_pretrained(vocab_path)def encode_sentence(self, text, padding=True):return self.tokenizer.encode(text,padding="max_length",max_length=self.config["max_length"],truncation=True)def decode(self, sentence, labels):sentence = "$" + sentencelabels = "".join([str(int(x)) for x in labels[:len(sentence) + 1]])results = defaultdict(list)for location in re.finditer("(04+)", labels):s, e = location.span()results["LOCATION"].append(sentence[s:e])for location in re.finditer("(15+)", labels):s, e = location.span()results["ORGANIZATION"].append(sentence[s:e])for location in re.finditer("(26+)", labels):s, e = location.span()results["PERSON"].append(sentence[s:e])for location in re.finditer("(37+)", labels):s, e = location.span()results["TIME"].append(sentence[s:e])return resultsdef predict(self, sentence):input_ids = self.encode_sentence(sentence)with torch.no_grad():res = self.model(torch.LongTensor([input_ids]))[0]labels = torch.argmax(res, dim=-1)results = self.decode(sentence, labels)return resultsif __name__ == "__main__":sl = NER(Config, "model_output/epoch_10.pth")sentence = "(本報約翰內斯堡電)本報記者安洋賀廣華留學人員檔案庫建立本報訊中國質量體系認證機構國家認可委員會日前正式簽署了國際上第一個質量認證的多邊互認協議,表明中國質量體系認證達到了國際水平。"res = sl.predict(sentence)print(res)


-Pratt解析算法:SQL表達式解析的核心引擎)


)
:基于機器學習的數值預測)


)


![STM32單片機入門學習——第22節: [7-2] AD單通道AD多通道](http://pic.xiahunao.cn/STM32單片機入門學習——第22節: [7-2] AD單通道AD多通道)


)


)
——DML和DQL)