1.概念
Eureka就好比是滴滴,負責管理、記錄服務提供者的信息。服務調用者無需自己尋找服務,而是把自己的 需求告訴Eureka,然后Eureka會把符合你需求的服務告訴你。同時,服務提供方與Eureka之間通過“心跳” 機制進行監控,當某個服務提供方出現問題,Eureka自然會把它從服務列表中剔除。這就實現了服務的自動注冊、發現、狀態監控。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?原理圖
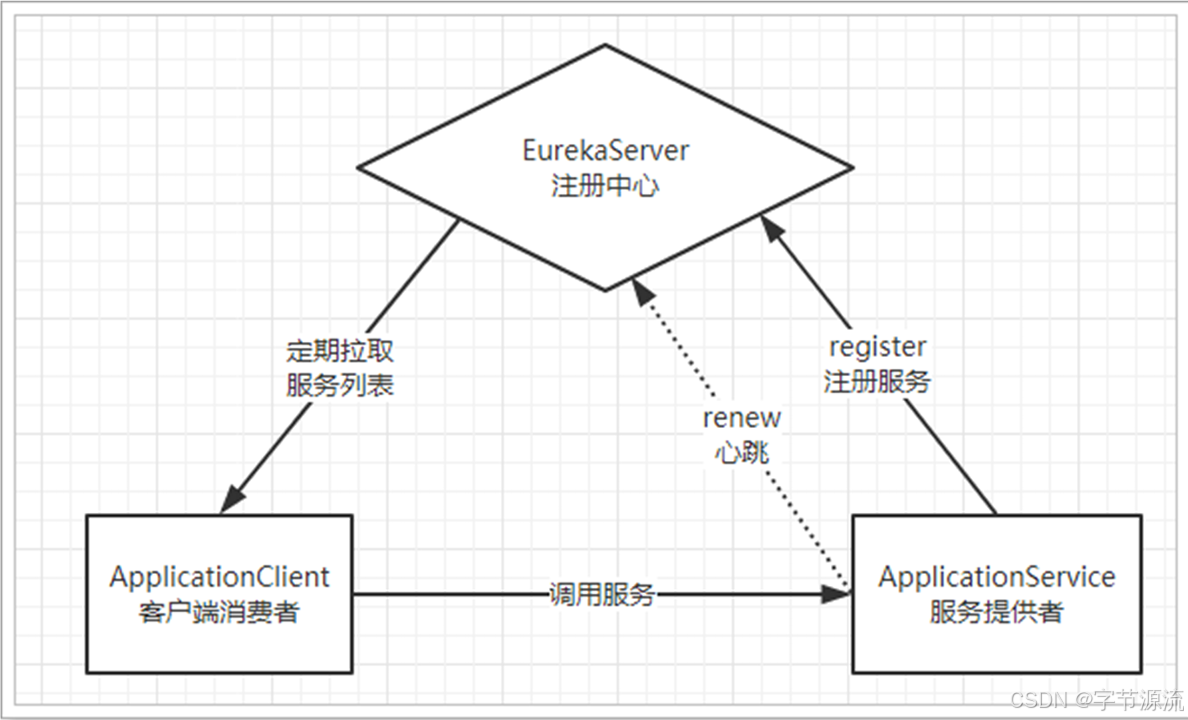
?Eureka:就是服務注冊中心(可以是一個集群),對外暴露自己的地址
服務提供者:啟動后向Eureka注冊自己信息(地址,提供什么服務)
服務消費者:向Eureka訂閱服務,Eureka會將對應服務的所有提供者地址列表發送給消費者,并且定 期更新
心跳(續約):微服務定期通過http方式向Eureka刷新自己的狀態
Eureka主要包含兩個組件:EurekaServer和EurekaClient
EurekaServer提供服務注冊,各個微服務節點通過配置啟動后,會在EurekaServer 中進行注冊。這樣EurekaServer 中的服務注冊表 將會存儲所有可用服務的節點信息,服務節點信息可以在eureka控制面板上看得到。
EurekaClient通過注冊中心進行訪問
通過EurekaClient這個客戶端,我們可以和EurekaServer進行交互。EurekaClient內部內置了一個默認 使用輪詢算法的負載均衡器。在應用啟動之后,將會向EurekaServer發送心跳(默認時間周期是30秒)。 如果EurekaServer在多個心跳周期內沒有收到某個節點的心跳,EurekaServer將會從服務注冊表中把 這個服務節點移除,默認時間是90秒。
2.搭建Eureka中心
首先在pom文件中導入依賴
<dependencies><!--eureka服務端依賴--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId></dependency><!--web啟動器--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency></dependencies>編寫application.yml文件
server:port: 7001
# 配置eureka服務端
eureka:client:register-with-eureka: false # 禁止自己注冊自己fetch-registry: false # 禁止抓取注冊中心中的服務信息service-url:defaultZone: http://localhost:7001/eureka/ # eureka服務端的地址編寫啟動類?
@SpringBootApplication
@EnableEurekaServer //標識當前服務是eureka服務端
public class EurekaServerApplication {public static void main(String[] args) {SpringApplication.run(EurekaServerApplication.class,args);}
}現在啟動項目,訪問7001端口,查看eureka服務端是否搭建成功:
 ?我們訪問到了eureka注冊中心的控制臺面板,說明我們的eureka注冊中心搭建成功。
?我們訪問到了eureka注冊中心的控制臺面板,說明我們的eureka注冊中心搭建成功。
?接下來就是對相應的服務提供方和服務消費方進行相應的配置。
首先是服務消費方
在pom文件中加上
<!--eureka-client--><dependency><groupId>org.springframework.cloud groupId><artifactId>spring-cloud-starter-netflix-eureka-client artifactId><dependency>在它的啟動類上添加開啟服務發現的注解:@EnableDiscoverClient
yml文件中要要加入
eureka:client:# 表示當前微服務是否向Eureka注冊中心注冊自己,設置為true即開啟注冊功能register-with-eureka: true # 表示客戶端是否從Eureka注冊中心獲取服務注冊列表,設置為true可獲取fetch-registry: true service-url:# defaultZone指定Eureka注冊中心的地址,這里設置為本地7001端口的Eureka服務地址defaultZone: http://localhost:7001/eureka/ ?
接下來是服務消費方
導入依賴
<!--eureka-client--><dependency><groupId>org.springframework.cloud groupId><artifactId>spring-cloud-starter-netflix-eureka-client artifactId><dependency>?然后在它的啟動類上添加開啟服務發現的注解:@EnableDiscoverClient
yml上加入
eureka:client:# 表示當前微服務是否向Eureka注冊中心注冊自己,設置為true即開啟注冊功能register-with-eureka: true # 表示客戶端是否從Eureka注冊中心獲取服務注冊列表,設置為true可獲取fetch-registry: true service-url:# defaultZone指定Eureka注冊中心的地址,這里設置為本地7001端口的Eureka服務地址defaultZone: http://localhost:7001/eureka/ 之后啟動項目,注冊中心就會多了兩個
 ?
?
3.eureka集群?
Eureka Server即服務的注冊中心,在剛才的案例中,我們只有一個EurekaServer,但是如果這個 EurekaServer掛掉了會影響整個應用。事實上EurekaServer也可以是一個集群,形成高可用的Eureka中 心,一個Eureka服務中心掛掉了還有其他的服務注冊中心。
多個Eureka Server之間也會互相注冊為服務,當服務提供者注冊到Eureka Server集群中的某個節點時, 該節點會把服務的信息同步給集群中的每個節點,從而實現數據同步。因此,無論客戶端訪問到Eureka Server集群中的任意一個節點,都可以獲取到完整的服務列表信息。
現在我們動手搭建高可用的EurekaServer,Eureka 集群的原理,就是 相互注冊,互相守望。
和之前的搭建一樣,我們只要把端口改了就行,這里我們改成7002
但是兩個注冊中心的defaultZone要改為對方的
就是進行互相注冊
然后服務消費方和提供方的配置文件也要進行修改,也就是defaultZone要把兩個注冊中心的URL都寫上就行了,用逗號隔開
4.服務集群
對服務提供方進行集群搭建
我們的微服務目前也只有一臺服務,如果在生產環境中掛掉了,也不能對外繼續提供服務,所以我們的服 務也可以進行集群。在這里我們以服務提供方為例。搭建兩臺服務提供方,另一臺服務提供方的端口號為 8002。
yml部分內容
server:port: 8001spring:application:name: service-provider # 配置服務名稱控制面板如下

對服務消費方進行集群搭建
?當我們有了兩臺服務提供方以后,我們需要改造服務消費端的服務調用方式。那么現在問題來了,我們應 該訪問兩臺服務提供方的哪一臺服務呢?以前在消費方指定訪問的是8001端口的微服務。現在我們需要 修改訪問提供方的訪問規則,規則就是通過服務提供方的名稱進行訪問,不再通過服務提供方的ip+端口 進行訪問。
我們修改服務消費方的控制器層代碼:
// 表明這是一個 RESTful 風格的控制器,用于處理 HTTP 請求并返回 JSON 或 XML 等數據
@RestController
// 定義該控制器處理的請求的基礎路徑,所有該控制器下的請求都會以 "consumer" 開頭
@RequestMapping("consumer")
// 抑制所有編譯器警告,通常不建議濫用,僅在特定場景下使用
@SuppressWarnings("all")
public class PaymentController {// 使用 Spring 的依賴注入機制,將 RestTemplate 對象注入到當前控制器中// RestTemplate 是 Spring 提供的用于發送 HTTP 請求的工具類@AutowiredRestTemplate restTemplate;/*** 根據 ID 查詢支付信息的方法* @param id 要查詢的支付信息的 ID* @return 包含支付信息的結果對象*/@RequestMapping("findById/{id}")public Result<Payment> findById(@PathVariable("id") Long id) {// 通過服務實例名稱進行訪問,構建請求的 URL// 這里的 "SERVICE-PROVIDER" 是服務提供者的實例名稱,在服務注冊中心中注冊的名稱// 拼接具體的請求路徑和參數String url = "http://SERVICE-PROVIDER/provider/findById?id=" + id;// 使用 RestTemplate 發送 GET 請求到指定的 URL,并將響應結果映射為 Result 類型的對象Result result = restTemplate.getForObject(url, Result.class);// 返回查詢結果return result;}
}?但此時必不能直接啟動,因為僅僅根據代碼中的url是不能知道調用哪臺服務提供方的機器,所以我們要進行負載均衡的實現,實現它就是要實現負載均衡器。
@ConfigurationpublicclassMyConfig {@Bean@LoadBalanced
開啟負載均衡的訪問
publicRestTemplaterestTemplate(){returnnewRestTemplate();}}6.服務發現?
有的時候,我們需要盤點一下我們eureka注冊中心上到底有哪些服務實例,我們需要獲取這些詳細服務的 各種細節(比如IP地址 服務端口號等),這個時候我們就需要使用一個新的注解來開啟服務發現功能,這個 注解就是EnableDiscoveryClient。對于注冊進eureka里面的微服務,可以通過服務發現來獲得該服務 的信息
首先:在微服務的啟動類上面添加EnableDiscoveryClient注解。開啟服務發現功能。
然后,消費方的控制器中定義如下邏輯
// 標識該類為 REST 風格的控制器,會將方法的返回值直接作為 HTTP 響應體返回
@RestController
// 為該控制器下的所有請求映射添加公共的請求路徑前綴 "consumer"
@RequestMapping("consumer")
// 使用 Lombok 提供的 @Slf4j 注解,自動生成一個日志記錄器對象 log,方便進行日志記錄
@Slf4j
// 抑制編譯器產生的所有警告信息,使用時需謹慎,可能會掩蓋一些潛在問題
@SuppressWarnings("all")
public class PaymentController {// 使用 @Resource 注解注入 DiscoveryClient 對象// DiscoveryClient 是 Spring Cloud 提供的用于與服務注冊中心交互的客戶端,可用于獲取服務注冊信息@Resourceprivate DiscoveryClient discoveryClient;/*** 獲取服務發現信息的接口* @return 返回 DiscoveryClient 對象,可用于前端進一步了解服務發現的情況*/@GetMapping("/customer/discovery")public Object discovery() {// 通過 DiscoveryClient 獲取服務注冊中心中所有已注冊的服務名稱列表List<String> services = discoveryClient.getServices();// 遍歷服務名稱列表,并使用日志記錄每個服務的名稱for (String service : services) {log.info("service:" + service);}// 根據服務提供方的名稱獲取對應的服務實例信息// 這里假定服務提供方在服務注冊中心注冊的名稱是 "service-provider"List<ServiceInstance> instances = discoveryClient.getInstances("service-provider");// 遍歷服務實例列表,獲取每個服務實例的詳細信息for (ServiceInstance instance : instances) {// 獲取服務實例的主機地址String host = instance.getHost();// 獲取服務實例的端口號int port = instance.getPort();// 獲取服務實例的服務 IDString serviceId = instance.getServiceId();// 使用日志記錄每個服務實例的主機地址、端口號和服務 IDlog.info("host:" + host + " port:" + port + " serviceId:" + serviceId);}// 返回 DiscoveryClient 對象,前端可以根據該對象獲取更多服務發現相關的信息return this.discoveryClient;}
}7.Eureka的自我保護機制?
Eureka服務端會檢查最近15分鐘內所有Eureka 實例正常心跳占比,如果低于85%就會觸發自我保護機 制。觸發了保護機制,Eureka將暫時把這些失效的服務保護起來,不讓其過期,但這些服務也并不是永遠 不會過期。Eureka在啟動完成后,每隔60秒會檢查一次服務健康狀態,如果這些被保護起來失效的服務 過一段時間后(默認90秒)還是沒有恢復,就會把這些服務剔除。如果在此期間服務恢復了并且實例心跳 占比高于85%時,就會自動關閉自我保護機制。
為什么會有自我保護機制? Eureka服務端為了防止Eureka客戶端本身是可以正常訪問的,但是由于網路通信故障等原因,造成 Eureka服務端失去于客戶端的連接,從而形成的不可用。
因為網絡通信是可能恢復的,但是Eureka客戶端只會在啟動時才去服務端注冊。如果因為網絡的原因而剔 除了客戶端,將造成客戶端無法再注冊到服務端。
如何選擇關閉還是開啟自我保護機制?Eureka服務端默認情況下是會開啟自我保護機制的。但我們在不同 環境應該選擇是否開啟保護機制。一般情況下,我們會選擇在開發環境下關閉自我保護機制,而在生產環 境下啟動自我保護機制。
開發環境下,我們啟動的服務數量較少而且會經常修改重啟。如果開啟自我保護機制,很容易觸發 Eureka客戶端心跳占比低于85%的情況。使得Eureka不會剔除我們的服務,從而在我們訪問的時候,會 訪問到可能已經失效的服務,導致請求失敗,影響我們的開發。
在生產環境下,我們啟動的服務多且不會反復啟動修改。環境也相對穩定,影響服務正常運行的人為情況 較少。適合開啟自我保護機制,讓Eureka進行管理。
如何關閉自我保護機制:
?在Eureka服務中心進行配置:
eureka:server:#服務端是否開啟自我保護機制(默認true)enable-self-preservation: false#掃描失效服務的間隔時間(單位毫秒,默認是60*1000)即60秒eviction-interval-timer-in-ms: 2000?在Eureka客戶端進行配置:
eureka:client:service-url:defaultZone: http://localhost:7001/eureka, http//localhost:7002/eurekainstance:#客戶端向注冊中心發送心跳的時間間隔,(默認30秒)lease-renewal-interval-in-seconds: 1#Eureka注冊中心(服務端)在收到客戶端心跳之后,等待下一次心跳的超時時間,如果在這個時間內沒有收到下次心跳,則移除該客戶端。(默認90秒)lease-expiration-duration-in-seconds: 2


















