資源類型
在 Kubernetes 中,Pod 作為最小的原子調度單位,所有跟調度和資源管理相關的屬性都屬于 Pod。其中最常用的資源就是 CPU 和 Memory。
CPU 資源
在 Kubernetes 中,一個 CPU 等于 1 個物理 CPU 核或者一個虛擬核,取決于節點是一臺物理主機還是運行在某物理主機上的虛擬機。CPU 的請求是允許帶小數的,比如 0.5 等價于 500m,表示請求 500 millicpu 或 0.5 個 cpu 的意思,這樣 Pod 就會被分配 1 個 CPU 一半的計算能力。需要注意的是,Kubernetes 不允許設置精度小于 1m 的 CPU 資源。
Memory 資源
Memory 以 bytes 為單位,Kubernetes 支持使用 Ei、Pi、Ti、Gi、Mi、Ki(或者E、P、T、G、M、K)作為 bytes 的值。
其中 1Mi=1024*1024;1M=1000*1000,還要注意后綴的小寫情況,400m實際上請求的是 0.4 字節。
資源的請求和限制
在 Kubernetes 中,CPU 是一種可壓縮資源,當可壓縮資源不足時,Pod 會處于 Pending 狀態;而 Memory 是一種不可壓縮資源,當不可壓縮資源不足時,Pod 會因 OOM 而被殺掉。所以合理的請求和分配 CPU 和 Memory 資源,可以提高應用程序的性能。Pod 可以由多個 Container 組成,每個 Container 的資源配置通過累加,形成 Pod 整體的資源配置。
針對每個容器的資源請求和限制,可以通過以下字段設置:
-
spec.containers[].resources.limits.cpu
-
spec.containers[].resources.limits.memory
-
spec.containers[].resources.requests.cpu
-
spec.containers[].resources.requests.memory
下面是一個示例:
該 Pod 有兩個容器,每個容器請求的 CPU 和 Memory 都是 0.25 CPU 和 64 MiB,每個容器的資源限制都是 0.5 CPU 和 128 MiB,所以該 Pod 的資源請求為 0.5 CPU 和 128 MiB,資源限制為 1 CPU 和 256 MiB。
apiVersion: v1
kind: Pod
metadata:name: frontend
spec:containers:- name: appimage: images.my-company.example/app:v4resources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"- name: log-aggregatorimage: images.my-company.example/log-aggregator:v6resources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"QoS模型
除了通過 limits 和 requests 限制和請求資源,Kubernetes 還會根據值的不同,為 Pod 設置優先級。當 Node 上的資源不足時,驅逐低優先級的 Pod,以保證更重要的 Pod 正常運行。這里就要介紹 Kubernetes 中的 QoS**(Quality of Service,服務質量)**。
QoS 類一共有三種:Guaranteed、Burstable 和 BestEffort。當一個 Node 耗盡資源時,Kubernetes 驅逐策略為:BestEffort Pod > Burstable Pod > Guaranteed Pod。
- BestEffort:pod沒有設置requests和limit
- Burstable:pod設置request和limit,但request<limit
- Guaranteed:pod設置request和limit,并且request=limit
Guaranteed
判斷依據:
-
Pod 中的每一個 Container 都同時設置了 Memory limits 和 requests,且值相等
-
Pod 中的每一個 Container 都同時設置了 CPU limits 和 requests,且值相等
比如下面的 Pod 中,CPU 的請求和限制都為 0.7 CPU,Memory 的請求和限制都為 200 MiB。當該 Pod 創建后,它的 QoS Class 字段的值就是:Guaranteed。屬于該類型的 Pod 具有最嚴格的資源限制,且最不可能被驅逐。只有當獲取的資源超出 limits 值或沒有可被驅逐的 BestEffort Pod 或 Burstable Pod,這些 Pod 才會被殺死。
apiVersion: v1
kind: Pod
metadata:name: qos-demonamespace: qos-example
spec:containers:- name: qos-demo-ctrimage: nginxresources:limits:memory: "200Mi"cpu: "700m"requests:memory: "200Mi"cpu: "700m"
需要注意的是,當 Pod 僅設置了 limits 沒有設置 requests 時,Kubernetes 會自動為它設置與 limits 相同的 requests 值。
Burstable
判斷依據:
-
不滿足 Guaranteed 的判斷條件
-
至少有一個 Container 設置了 requests
在下面的 Pod 中,Memory 的限制為 200 MiB,請求為 100 MiB。兩者不相等,所以被劃分為 Burstable。
如果不指定 limits 的值,那么默認 limits 等于 Node 容量,允許 Pod 靈活地使用資源。如果 Node 資源不足,導致 Pod 被驅逐,只有在 BestEffort Pod 被驅逐后,Burstable Pod 才會被驅逐。
apiVersion: v1
kind: Pod
metadata:name: qos-demo-2namespace: qos-example
spec:containers:- name: qos-demo-2-ctrimage: nginxresources:limits:memory: "200Mi"requests:memory: "100Mi"
BestEffort
判斷依據:
-
不滿足 Guaranteed 或 Burstable 的判斷條件
-
既沒有設置 limits,也沒有設置 requests
屬于 BestEffort 的 Pod,可以使用未分配給其他 QoS 類中的資源。如果 Node 有 16 核 CPU 可供使用,且已經為 Guaranteed Pod 分配了 4 核 CPU,那么 BestEffort Pod 可以隨意使用剩余的 12 核 CPU。
如果 Node 的資源不足,那么將首先驅逐 BestEffort Pod。
apiVersion: v1
kind: Pod
metadata:name: qos-demo-3namespace: qos-example
spec:containers:- name: qos-demo-3-ctrimage: nginx
限制范圍和資源配額
默認情況下,Kubernetes 中的容器可以使用的資源是沒有限制的。但是當多個用戶使用同一個集群時,可能會出現有人占用過量的資源,導致其他人無法正常使用集群的情況。
限制范圍和資源配額正是解決該問題的方法。其中限制范圍通過 LimitRange 對象,在命名空間級別下限制 Pod 中容器的資源使用量,在創建 Pod 時,自動設置 CPU 和 Memory 的請求和限制。資源配額通過 ResourceQuota 對象,對每個命名空間的資源總量進行限制,避免命名空間中的程序無限制地使用資源。
在下面的例子中,定義了一個 LimitRange 對象。在該命名空間創建的 Pod 將遵循以下條件:
-
如果未指定 CPU 的 requests 和 limits,則均為 0.5 CPU
-
如果只指定了 requests,則 limits 的值在 0.1 CPU 和 1 CPU 之間
-
如果只指定了 limits,則 request 的值與 limits 相同,低于 0.1 CPU 的設為 0.1 CPU,高于 1 CPU 的設為 1 CPU。
-
如果命名空間存在多個 LimitRange 對象,應用哪個默認值是不確定的
apiVersion: v1
kind: LimitRange
metadata:name: cpu-resource-constraint
spec:limits:- default: # 此處定義默認限制值cpu: 500mdefaultRequest: # 此處定義默認請求值cpu: 500mmax: # max 和 min 定義限制范圍cpu: "1"min:cpu: 100mtype: Container
需要注意的是,當只指定了 requests,沒有指定 limits 時,requests 的值大于 LimitRange 設置的 limits 的默認值,將導致 Pod 無法調度。
資源配額的流程如下:
-
集群管理員為每個命名空間創建一個或多個 ResourceQuota 對象
-
當用戶在命名空間下創建對象時,Kubernetes 的配額系統會跟蹤集群的資源使用情況,以確保使用的資源總量不超過 ResourceQuota 中的配額
-
如果命名空間下的計算資源(CPU、Memory)被開啟,則用戶必須為 Pod 設置 limits 和 requests,否則系統將拒絕 Pod 的創建(或者使用 LimitRanger 解決)
下面的 ResourceQuota 定義了命名空間的資源限制:該命名空間中所有 Pod 的 CPU 總量不能超過 2,Pod 的 Memory 總量不能超過 2 GiB,PVC 的存儲總量不能超過 5 GiB,Pod 的數量不能超過 10 個。
apiVersion: v1
kind: ResourceQuota
metadata:name: example-quota
spec:hard:cpu: "2"memory: 2Gistorage: 5Gipods: "10"
CPU 管理器策略
默認情況下,kubelet 使用 CFS 配額 來對 Pod 的 CPU 進行約束。當 Node 上運行了很多 CPU 密集型任務時,Pod 可能會爭奪可用的 CPU 資源,工作負載可能會遷移到不同的 CPU 核,對上下文切換敏感的工作負載的性能會受到影響。為此,kubelet 提供了可選的 CPU 管理器策略。
管理策略
CPU 管理器目前有兩種策略:
-
None:默認策略
-
Static:允許為節點上具有整數型 CPU requests 的 Guaranteed Pod 賦予 CPU 親和性和獨占性。
此策略管理一個 CPU 共享池,該共享池最初包含節點上所有的 CPU 資源。可獨占性 CPU 資源數量等于 CPU 總量減去通過 kubeReserved 或 systemReserved 參數指定的 CPU 數量。這些參數指定的 CPU 供 BestEffort Pod、Burstable Pod 和 Guaranteed 中請求了非整數值 CPU 的 Pod 使用。只有那些請求了整數型 CPU 的 Guaranteed Pod,才會被分配獨占 CPU 資源。
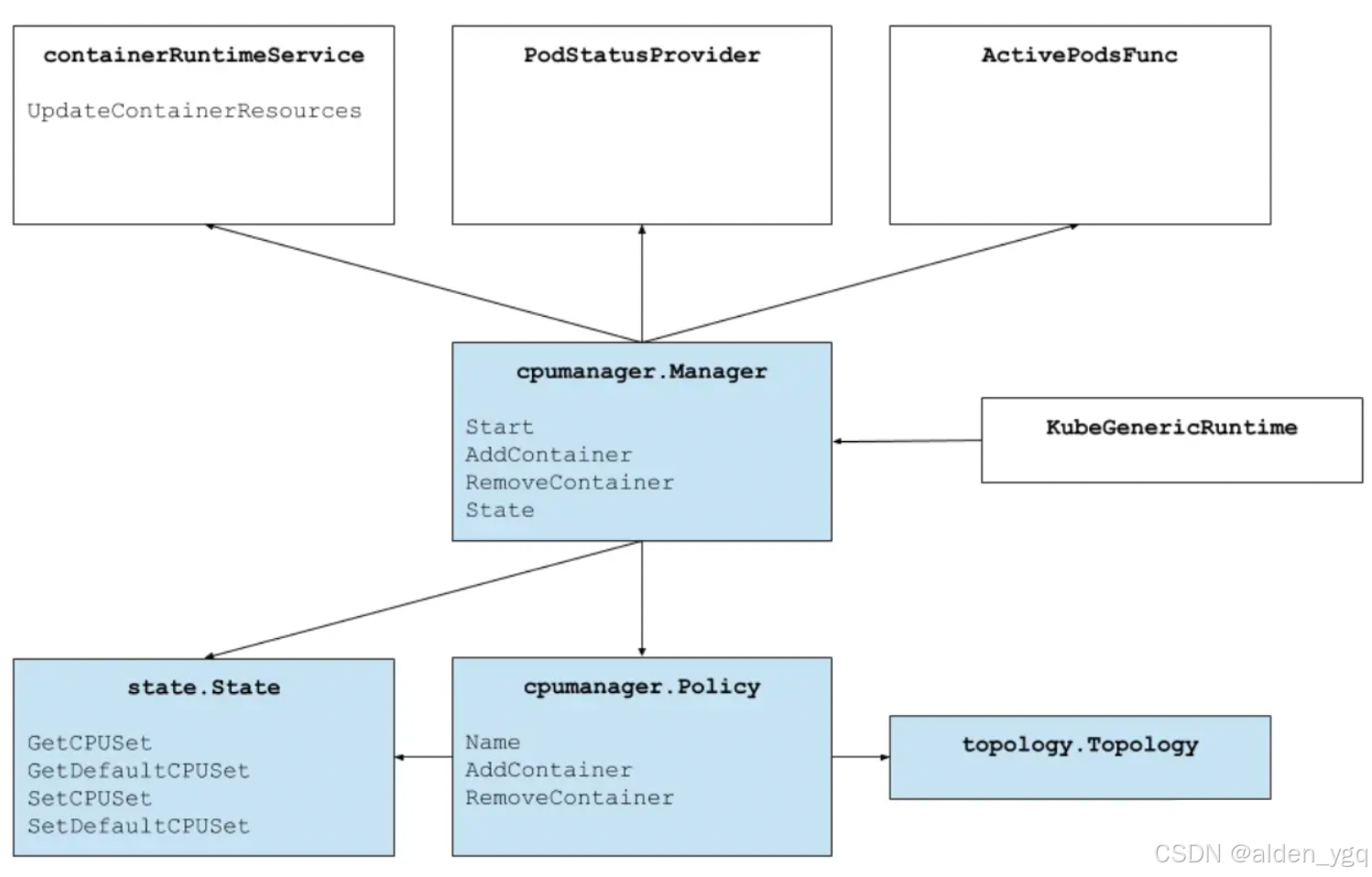
上圖顯示了 CPU 管理器的結構。CPU 管理器使用contaimerRuntimeService接口的UpdateContainerResources方法來修改容器可以運行的 CPU。Manager 定期使用 cgroupfs 技術來與每個正在運行的容器的 CPU 資源的當前狀態進行協調。
使用場景
如果工作負載具有以下場景,那么通過使用該策略,操作系統在CPU之間進行上下文切換的次數大大減少,容器里應用的性能會得到大幅提升。
-
對 CPU 節流敏感
-
對上下文切換敏感
-
對處理器換成未命中敏感
驗證策略
由于 CPU 管理器策略只能在 kubelet 生成新 Pod 時生效,所以簡單地從 "None" 更改為 "Static" 將不會對現有的 Pod 起作用。 因此,為了正確更改節點上的 CPU 管理器策略,可以執行以下步驟:
-
騰空節點
-
停止 kubelet
-
刪除舊的 CPU 管理器狀態文件。該文件的路徑默認為/var/lib/kubelet/cpu_manager_state。這將清除 CPUManager 維護的狀態,以便新策略設置的 cpu-sets 不會與之沖突
-
編輯 kubelet 配置/var/lib/kubelet/config.yml,以將 CPU 管理器策略更改為所需的值
-
啟動 kubelet
-
對需要更改其 CPU 管理器策略的每個節點重復此過程。
以下示例在config.yml添加了字段,如果該 Node 有 64 核,那么共享池將有 8 核,剩余的 56 核將用于指定了整數型 CPU 的 Guaranteed Pod。
systemReserved:cpu: "4"memory: "500m"
kubeReserved:cpu: "4"memory: "500m"
cpuManagerPolicy: "Static"
當重新啟動 kubelet 后,就會新建cpu_manager_state,"policyName" 字段將從 “None” 變為 “Static”。
{"policyName":"Static","defaultCpuSet":"","checksum":1353318690}創建一個 calculate.yml,用來驗證 Static 策略是否真的生效。用 go 寫了一個可以并發計算 200000 以內的素數的程序 calculate_primes。指定部署在啟動了 Static 策略的 dc02-pff-500-5c24-cca-e881-3c40 節點上,并把 Pod 設置為 Guaranteed。
apiVersion: batch/v1
kind: Job
metadata:name: calculate-job
spec:template:metadata:name: calculate-jobspec:nodeName: ***containers:- name: calculate-containerimage: ubuntu:latestcommand: ["./calculate_primes", "2000000"]resources:limits:cpu: "5"memory: "100Mi"volumeMounts:- name: mix-storage-volumemountPath: ***volumes:- name: mix-storage-volumepersistentVolumeClaim:claimName: mix-storage-pvcrestartPolicy: NeverbackoffLimit: 0
查看 Pod 可以確認確實為 Guaranteed。
通過 taskset -cp PID 和 cat cpu_manager_state 可以查看 calculate_primes 進程使用了序號為 8-12 的5個 CPU,表明 Static 策略生效,程序可以獨占 CPU。
而使用 None 策略時,通過 taskset -cp PID 命令可以查看當前進程并不會獨占 CPU,而是在 64 個 CPU 間隨意切換。
CPU、Memory 限制和請求的最佳實踐
Natan Yellin 通過“口渴的探險家”和“披薩派對”的例子,給出了關于 CPU 、Memory 限制和請求的最佳實踐。
省略版
永遠設置 Memory limits == requests
絕不設置 CPU limits
口渴的探險家
在該故事中,CPU 就是水,CPU 饑餓就是死亡。A 和 B 在沙漠中旅行,他們有一個神奇的水瓶,每天可以產生 3 升水,每人每天需要 1 升水才能存活。
情景1:without limits, without requests
A 很貪婪,在 B 之前喝光了所有的水,導致 B 渴死。因為沒有限制和請求,所以 A 能喝掉所有的水,導致 CPU 饑餓。
情景2:with limits, with or without requests
A 和 B 都喝了 1 升水,但是 A 生病了,需要額外的水,B 不讓 A 喝,因為 A 的限制是每天 1 升水,所以 A 渴死了。當有 CPU 限制時,就可能發生這種情況,即使有很多資源,也無法使用。
情景3:without limits, with requests
這次輪到 B 生病了,需要額外的水,但是當喝到只剩 1 升水時停下了,因為 A 每天需要 1 升水。兩個人都活了下來。當沒有 CPU 限制但有請求時就會出現這種情況,一切正常。
用表格概括一下 limits 和 requests 的區別
| Pod | CPU limits | No CPU limits |
|---|---|---|
| CPU requests | 能使用的CPU 在 requests和limits之間無法使用更多的 CPU | 能夠使用 requests 指定的 CPU 數量多余的CPU也能用,不會造成浪費 |
| No CPU requests | 能夠使用 limits 指定的 CPU 數量無法使用更多的 CPU | 隨意使用可能會耗盡節點資源 |
Kubernetes 給出了解釋:
Pod 保證能夠獲得所請求的 CPU 數量,如果沒有 limits,可能會使用多余的 CPU,但不會搶占其他正在運行任務的CPU。
披薩派對
想象一個披薩派對,每個人點 2 片,最多可以吃 4 片,相當于 requests = 2,limits = 4。但在訂購披薩的時候,是按每人 2 片的數量訂的。派對開始了,每張桌子都為坐下的人準備了 2 片披薩,誰都可以拿。但是在你準備吃的時候發現披薩沒有了,此時一個保鏢出來把正在吃披薩的另一個人擊倒,收集剩下的披薩(準確地說是也包括這個人吃過的披薩),給桌子上的其他人吃。并把剛才的那個人安排到另一張有更多披薩的桌子上。
當 Node 上的 Memory 不足時(OOM),就會出現這種情況。Pod 訪問不可用的 Memory,就會因 OOM 而被終止。如果客人只允許吃掉所訂購數量的披薩,即 requests = limits,那么大家都將相安無事。
總結
在 Kubernetes 中,CPU 和 Memory 資源的管理和分配是非常重要的。通過合理地分配和管理這些資源,可以確保 Kubernetes 集群的穩定性和可用性,提高應用程序的性能。











![[2018][note]用于超快偏振開關和動態光束分裂的all-optical有源THz超表——](http://pic.xiahunao.cn/[2018][note]用于超快偏振開關和動態光束分裂的all-optical有源THz超表——)

)

工作流程介紹)



