引入
通過前面的學習,我們對于Spark已經有一個基本的認識,并且搭建了一個本地的練習環境,因為本專欄的主要對象是數倉和數分,所以就不花大篇幅去寫環境搭建等內容,當然,如果感興趣的小伙伴可以留言,如果人多的話,我也可以在后面加餐篇里面補充企業目前常見的架構環境搭建,比如Spark on yarn以及Spark on k8s等。
本文將進入Spark 核心數據結構:RDD(彈性分布式數據集 )的學習,如果未閱讀論文篇的小伙伴,推薦先閱讀以后,再看本文哈,相關鏈路如下:
- 論文詳解
- 論文總結
RDD 的核心概念
RDD 是 Spark 最核心的數據結構,RDD(Resilient Distributed Dataset)全稱為彈性分布式數據集,是 Spark 對分布式數據集的抽象,它用于囊括所有內存中和磁盤中的分布式數據實體,它實質上是一組分布式的 JVM 不可變對象集合,不可變決定了它是只讀的,所以 RDD 在經過變換產生新的 RDD 時,(如下圖中 A-B),原有 RDD 不會改變。
在論文總結里,我們有提到這個彈性體現在兩個方面:
- 第一個是數據存儲上。 數據不再是存放在硬盤上的,而是可以緩存在內存中。只有當內存不足的時候,才會把它們換出到硬盤上。同時,數據的持久化,也支持硬盤、序列化后的內存存儲,以及反序列化后Java對象的內存存儲三種形式。雖然需要占用更多的內存,但是計算速度會更快。
- 第二個是選擇把什么數據輸出到硬盤上。 Spark會根據數據計算的DAG Lineage,來判斷某一個RDD對于前置數據是寬依賴,還是窄依賴的。如果是寬依賴的,意味著一個節點的故障,可能會導致大量的數據要進行重新計算,乃至數據網絡傳輸的需求。那么,它就會把數據計算的中間結果存儲到硬盤上。
如下就是第二點提到的DAG圖,通過它可以大概反推出計算邏輯:A 和 C 都是兩張表,在分別進行分組聚合和篩選的操后, 做了一次 join 操作。在圖中深色的方框就是我們所說的分區(partition),它和計算任務是一一對應的,也就是說,有多少個分區,就有多少個計算任務,顯然一個作業會有多個計算任務,這也是分布式計算的意義所在,我們可以通過設置分區數量來控制每個計算任務的計算量。
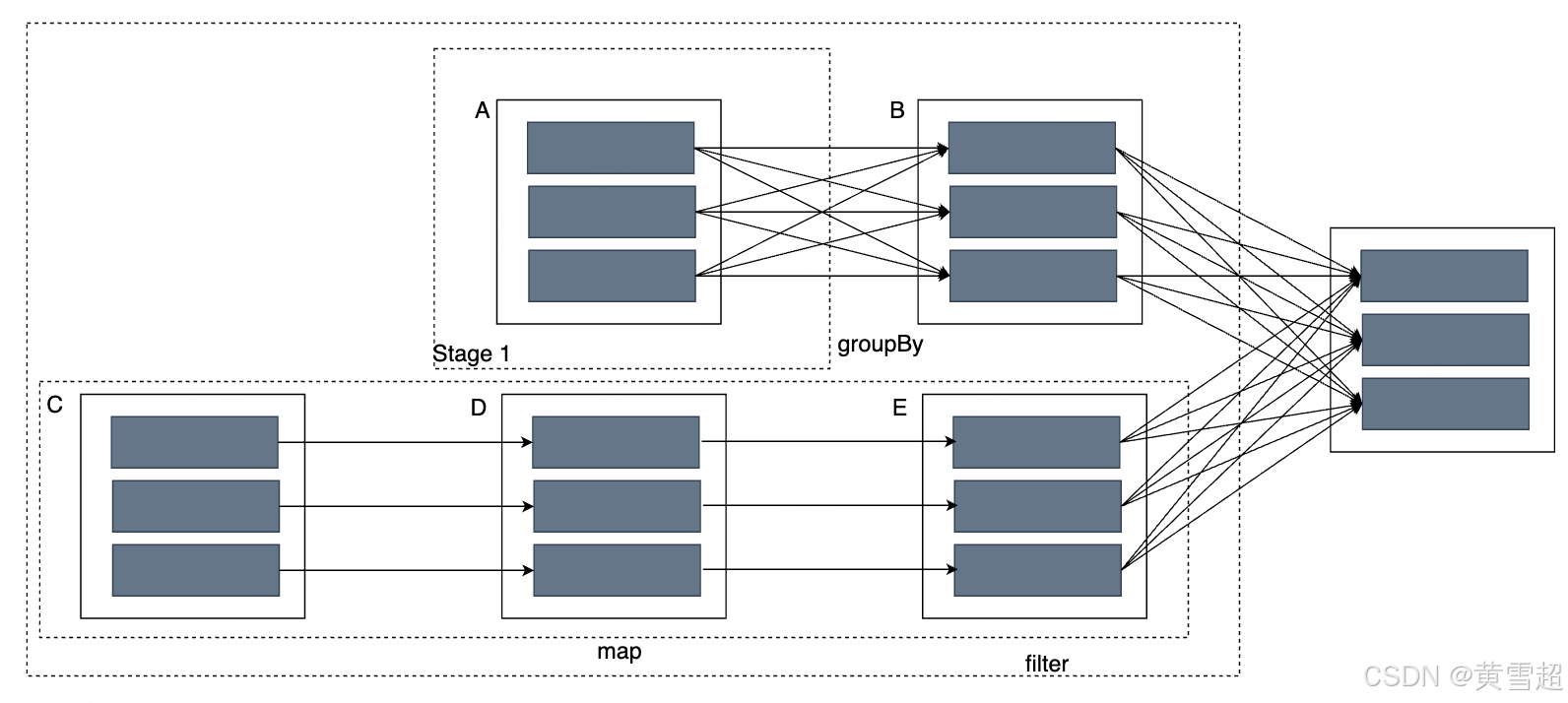
在 DAG 中,每個計算任務的輸入就是一個分區,一些相關的計算任務所構成的任務集合可以被看成一個 Stage。RDD 則是分區的集合(圖中 A、B、C、D、E),在面對出錯情況(例如任意一臺節點宕機)時,Spark 能通過 RDD 之間的依賴關系恢復任意出錯的 RDD,例如最終輸出節點故障,我們無需重跑所有任務,只用通過 B 和 E 就能算出最后的 RDD,這就是彈性的好處。
下面我們通過源碼去進一步了解RDD。
深入RDD
還是老樣子,我們先看看RDD的源碼注釋:
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel. This class contains the basic operations available on all RDDs, such as map, filter, and persist. In addition, PairRDDFunctions contains operations available only on RDDs of key-value pairs, such as groupByKey and join; DoubleRDDFunctions contains operations available only on RDDs of Doubles; and SequenceFileRDDFunctions contains operations available on RDDs that can be saved as SequenceFiles. All operations are automatically available on any RDD of the right type (e. g. RDD[(Int, Int)]) through implicit.
Internally, each RDD is characterized by five main properties:
A list of partitions
A function for computing each split
A list of dependencies on other RDDs
Optionally, a Partitioner for key-value RDDs (e. g. to say that the RDD is hash-partitioned)
Optionally, a list of preferred locations to compute each split on (e. g. block locations for an HDFS file)
All of the scheduling and execution in Spark is done based on these methods, allowing each RDD to implement its own way of computing itself. Indeed, users can implement custom RDDs (e. g. for reading data from a new storage system) by overriding these functions. Please refer to the Spark paper ? for more details on RDD internals.翻譯:
彈性分布式數據集(RDD)是 Spark 中的基本抽象。它代表一個不可變的、分區的元素集合,可以并行操作。這個類包含所有 RDD 都具備的基本操作,如映射(map)、過濾(filter)和持久化(persist)。此外,PairRDDFunctions 包含僅適用于鍵值對 RDD 的操作,如按鍵分組(groupByKey)和連接(join);DoubleRDDFunctions 包含僅適用于 Double 類型 RDD 的操作;SequenceFileRDDFunctions 包含適用于可保存為 SequenceFiles 的 RDD 的操作。通過隱式轉換,所有操作會自動適用于任何合適類型的 RDD(例如 RDD [(Int, Int)])。
在內部,每個 RDD 由五個主要屬性來描述:
- 分區的集合;
- 用于計算每個分片的函數(算子);
- 對其他 RDD 的依賴關系集合;
- 可選的,鍵值型?RDD 的分區器(例如,表明該 RDD 是哈希分區的);
- 可選的,計算每個分片的首選位置集合(例如,HDFS 文件的塊位置)。
Spark 中的所有調度和執行都是基于這些方法進行的,這使得每個 RDD 能夠實現自己的計算方式。實際上,用戶可以通過重寫這些函數來實現自定義的 RDD(例如,從新的存儲系統讀取數據)。有關 RDD 內部機制的更多詳細信息,請參考 Spark 論文 。
?可以看到里面提到了RDD的5個核心特性,我們對應梳理理解如下:
- 每個RDD有多個分區組成(分區列表/集合)
- 每個rdd都有作用于每個分區的函數/算子(計算函數/算子)
- ?每個RDD都有與上下游有依賴的RDD, RDD之間是有依賴關系的(依賴關系)
- 針對key-value的 RDD 默認是Hash分區,也可以指定其它分區器(k-v分區器)
- 每個RDD的分區,其實都有副本的概念,到底選用那個副本來計算,給每個分區都計算出來了一個首選位置,這個選擇主要是移動計算而不是存儲的思路(副本位置)
下面我們從源碼實現里面去看看:
/*** 存儲當前RDD的分區數組。該變量是volatile的,以確保多線程環境下的可見性;* 同時是transient的,意味著在序列化時會被忽略。* 初始值為null,在第一次調用`getPartitions`方法時會被賦值。*/
@volatile @transient private var partitions_ : Array[Partition] = _
/*** 存儲當前RDD依賴的其他RDD的依賴關系序列。* 每個依賴關系描述了當前RDD如何依賴于其他RDD,* 這些依賴關系對于Spark的任務調度和數據處理流程至關重要。* 同樣,該變量被標記為`@transient`,因為依賴關系可能包含不可序列化的對象。*/
@transient private var deps: Seq[Dependency[_]]
/*** 可選的分區器,用于指定RDD的分區方式。* 如果此值為 None,則表示該RDD沒有指定分區器,可能會使用默認的分區方式。* transient 關鍵字表示該字段不會被序列化,這在分布式計算中很常見,* 因為分區器通常在運行時動態確定,不需要在不同節點之間進行序列化和傳輸。*/
@transient val partitioner: Option[Partitioner] = None/*** 由子類實現,用于返回此RDD的分區集合。* 該方法只會被調用一次,因此可以在其中實現耗時的計算邏輯。* 返回的分區數組必須滿足以下屬性:* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`** @return 此RDD的分區數組*/
protected def getPartitions: Array[Partition]/*** 由子類實現,用于返回此RDD如何依賴于父RDD。* 該方法只會被調用一次,因此可以在其中實現耗時的計算邏輯。** @return 此RDD對父RDD的依賴關系序列*/
protected def getDependencies: Seq[Dependency[_]] = deps
/*** 可選地由子類重寫,用于指定每個分區的首選計算位置。* 例如,對于從HDFS文件讀取的RDD,首選位置可能是HDFS塊所在的節點。* 默認情況下,返回一個空的序列,表示沒有首選位置。** @param split 需要計算的分區。* @return 分區的首選位置列表,如果沒有則返回空序列。*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil通過源碼我們能更直觀的理解前面的特性,尤其是上面代碼中的@volatile @transient private var partitions_ : Array[Partition] = _它說明了一個重要的問題,RDD 是分區的集合,本質上還是一個集合,所以在理解時,可以用分區之類的概念去理解,但是在使用時,就可以忘記這些,把其當做是一個普通的集合去使用就好了。
除此之外,在Spark論文中有提到RDD的編程模型中,一共有兩類操作,Transformations 類轉換操作是定義新 RDD 的惰性操作,而Actions 類行動操作則啟動計算,將值返回給程序或將數據寫入外部存儲。
在這樣的編程模型下,Spark 在運行時的計算被劃分為兩個環節:
- 基于不用數據形態之間的轉換,構建計算流圖(DAG,Directed Acyclic Graph);
- 通過 Actions 類算子,以回溯的方式去觸發執行這個計算流圖。
換句話說,開發者調用的各類 Transformations 算子,并不立即執行計算,當且僅當開發者調用 Actions 算子時,之前調用的轉換算子才會付諸執行。在業內,這樣的計算模式有個專門的術語,叫作“延遲計算”(Lazy Evaluation)。
總結
我們重點講解了 RDD的核心概念,RDD 是 Spark 對于分布式數據集的抽象,它用于囊括所有內存中和磁盤中的分布式數據實體。對于 RDD,你要重點掌握它的 5 大特性/屬性:
- 分區列表/集合
- 計算函數/算子
- 依賴關系
- k-v分區器
- 副本位置
把評論區回復的貼上來,方便小伙伴們閱讀,有其他疑問也可以私信或者評論告訴我:
- 一組分片(Partition)?,本質就是RDD數據集的基本組成單位。對于RDD來說,每個分片都會被一個計算任務處理,并決定并行計算的粒度。用戶可以在創建RDD時指定RDD的分片個數,如果沒有指定,那么就會采用默認值。默認值就是程序所分配到的CPU Core的數目。每個分配的存儲是由BlockManager實現的。每個分區都會被邏輯映射成BlockManager的一個Block,而這個Block會被一個Task負責計算。
- 一個用于每個分區計算的函數。Spark中RDD的計算是以分片為單位的,每個RDD都會實現compute函數以達到這個目的。compute函數會對迭代器進行復合,不需要保存每次計算的結果。
- RDD之間的依賴關系。RDD的每次轉換都會生成一個新的RDD,所以RDD之間就會形成類似于流水線一樣的前后依賴關系。在部分分區數據丟失時,Spark可以通過這個依賴關系重新計算丟失的分區數據,而不是對RDD的所有分區進行重新計算。
- RDD的分區函數。只有對于key-value的RDD,才會有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函數不但決定了RDD本身的分片數量,也決定了parent RDD Shuffle輸出時的分片數量。
- 一個存儲存取每個Partition的優先位置(preferred location)的列表?。對于一個HDFS文件來說,這個列表保存的就是每個Partition所在的塊的位置。按照“移動數據不如移動計算”的理念,Spark在進行任務調度的時候,會盡可能地將計算任務分配到其所要處理數據塊的存儲位置。
深入理解 RDD 之后,你需要熟悉 RDD 的編程模型。在 RDD 的編程模型中,開發者需要
使用 Transformations 類算子,定義并描述數據形態的轉換過程,然后調用 Actions 類算
子,將計算結果收集起來、或是物化到磁盤。
而延遲計算指的是,開發者調用的各類 Transformations 算子,并不會立即執行計算,當
且僅當開發者調用 Actions 算子時,之前調用的轉換算子才會付諸執行。
如下是Spark3.5.4的RDD源碼,并配置了相關注釋,給小伙伴們留了個作業,請結合以下源碼和官網,梳理歸類 Transformations 算子和Actions 算子:
/*** 抽象類 RDD 表示彈性分布式數據集,是 Spark 中的基本抽象。* 它代表一個不可變的、分區的元素集合,可以并行操作。** @tparam T 此 RDD 中元素的類型* @param _sc Spark 上下文,用于與 Spark 集群交互* @param deps 此 RDD 依賴的其他 RDD 的依賴關系序列*/
abstract class RDD[T: ClassTag](@transient private var _sc: SparkContext,@transient private var deps: Seq[Dependency[_]]) extends Serializable with Logging {// 檢查元素類型是否為 RDD,如果是則發出警告,因為 Spark 不支持嵌套 RDDif (classOf[RDD[_]].isAssignableFrom(elementClassTag.runtimeClass)) {// 這是一個警告而不是異常,以避免破壞可能定義了嵌套 RDD 但未運行作業的用戶程序。logWarning("Spark does not support nested RDDs (see SPARK-5063)")}/*** 獲取 Spark 上下文。* 如果上下文為空,則拋出異常。** @return Spark 上下文*/private def sc: SparkContext = {if (_sc == null) {throw SparkCoreErrors.rddLacksSparkContextError()}_sc}/*** 構造一個僅依賴于一個父 RDD 的 RDD,使用一對一依賴關系。** @param oneParent 父 RDD*/def this(@transient oneParent: RDD[_]) =this(oneParent.context, List(new OneToOneDependency(oneParent)))/*** 獲取 Spark 配置。** @return Spark 配置*/private[spark] def conf = sc.conf// =======================================================================// 應由 RDD 子類實現的方法// =======================================================================/*** :: DeveloperApi ::* 由子類實現,用于計算給定分區的數據。** @param split 要計算的分區* @param context 任務上下文,包含任務執行的相關信息* @return 分區元素的迭代器*/@DeveloperApidef compute(split: Partition, context: TaskContext): Iterator[T]/*** 由子類實現,返回此 RDD 的分區集合。* 此方法僅會被調用一次,因此可以在其中執行耗時的計算。** 分區數組必須滿足以下屬性:* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`** @return 分區數組*/protected def getPartitions: Array[Partition]/*** 由子類實現,返回此 RDD 對父 RDD 的依賴關系。* 此方法僅會被調用一次,因此可以在其中執行耗時的計算。** @return 依賴關系序列*/protected def getDependencies: Seq[Dependency[_]] = deps/*** 可選地由子類重寫,以指定每個分區的首選計算位置。** @param split 分區* @return 首選位置序列*/protected def getPreferredLocations(split: Partition): Seq[String] = Nil/*** 可選地由子類重寫,以指定 RDD 的分區方式。*/@transient val partitioner: Option[Partitioner] = None// =======================================================================// 所有 RDD 可用的方法和字段// =======================================================================/*** 獲取創建此 RDD 的 Spark 上下文。** @return Spark 上下文*/def sparkContext: SparkContext = sc/*** 獲取此 RDD 的唯一 ID(在其 Spark 上下文中)。*/val id: Int = sc.newRddId()/*** 此 RDD 的友好名稱。*/@transient var name: String = _/*** 為 RDD 分配一個名稱。** @param _name 要分配的名稱* @return 此 RDD 實例*/def setName(_name: String): this.type = {name = _namethis}/*** 使用指定的存儲級別標記此 RDD 進行持久化。** @param newLevel 目標存儲級別* @param allowOverride 是否允許用新級別覆蓋現有級別* @return 此 RDD 實例*/private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {// TODO: 處理存儲級別的更改if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {throw SparkCoreErrors.cannotChangeStorageLevelError()}// 如果這是第一次標記此 RDD 進行持久化,則向 Spark 上下文注冊以進行清理和統計。只執行一次。if (storageLevel == StorageLevel.NONE) {sc.cleaner.foreach(_.registerRDDForCleanup(this))sc.persistRDD(this)}storageLevel = newLevelthis}/*** 設置此 RDD 的存儲級別,以便在第一次計算后跨操作持久化其值。* 僅當 RDD 尚未設置存儲級別時,才能使用此方法分配新的存儲級別。本地檢查點是一個例外。** @param newLevel 目標存儲級別* @return 此 RDD 實例*/def persist(newLevel: StorageLevel): this.type = {if (isLocallyCheckpointed) {// 這意味著用戶之前調用了 localCheckpoint(),這應該已經標記此 RDD 進行持久化。// 這里我們應該用用戶明確請求的級別覆蓋舊的存儲級別(在將其調整為使用磁盤后)。persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)} else {persist(newLevel, allowOverride = false)}}/*** 使用默認存儲級別(`MEMORY_ONLY`)持久化此 RDD。** @return 此 RDD 實例*/def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)/*** 使用默認存儲級別(`MEMORY_ONLY`)持久化此 RDD。** @return 此 RDD 實例*/def cache(): this.type = persist()/*** 標記此 RDD 為非持久化,并從內存和磁盤中移除其所有塊。** @param blocking 是否阻塞直到所有塊被刪除(默認:false)* @return 此 RDD 實例*/def unpersist(blocking: Boolean = false): this.type = {logInfo(s"Removing RDD $id from persistence list")sc.unpersistRDD(id, blocking)storageLevel = StorageLevel.NONEthis}/*** 獲取此 RDD 的當前存儲級別,如果未設置則返回 StorageLevel.NONE。** @return 存儲級別*/def getStorageLevel: StorageLevel = storageLevel/*** 用于鎖定此 RDD 的所有可變狀態(持久化、分區、依賴關系等)。* 不使用 `this` 是因為 RDD 是用戶可見的,用戶可能已經在 RDD 上添加了自己的鎖;* 共享鎖可能會導致死鎖。** 一個線程可能會在一系列 RDD 依賴關系中持有多個這樣的鎖。* 如果在持有 stateLock 的同時嘗試鎖定另一個資源,并且這些鎖的獲取順序不能保證相同,就可能會發生死鎖。* 這可能會導致一個線程先獲取 stateLock,然后獲取資源,而另一個線程先獲取資源,然后獲取 stateLock,從而導致死鎖。** 執行器可能會引用共享字段(盡管它們永遠不應該修改它們,只有驅動程序會進行修改)。*/private[spark] val stateLock = new Serializable {}// 我們的依賴關系和分區將通過調用下面的子類方法獲取,并且在進行檢查點操作時會被覆蓋@volatile private var dependencies_ : Seq[Dependency[_]] = _// 當我們覆蓋依賴關系時,我們會保留對舊依賴關系的弱引用,以便用戶進行清理。@volatile @transient private var legacyDependencies: WeakReference[Seq[Dependency[_]]] = _@volatile @transient private var partitions_ : Array[Partition] = _/*** 獲取此 RDD 的檢查點 RDD(如果已進行檢查點操作)。** @return 檢查點 RDD 的可選實例*/private def checkpointRDD: Option[CheckpointRDD[T]] = checkpointData.flatMap(_.checkpointRDD)/*** 獲取此 RDD 的依賴關系列表,考慮到 RDD 是否進行了檢查點操作。** @return 依賴關系序列*/final def dependencies: Seq[Dependency[_]] = {checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {if (dependencies_ == null) {stateLock.synchronized {if (dependencies_ == null) {dependencies_ = getDependencies}}}dependencies_}}/*** 獲取此 RDD 的依賴關系列表,忽略檢查點操作。** @return 依賴關系序列的可選實例*/final private def internalDependencies: Option[Seq[Dependency[_]]] = {if (legacyDependencies != null) {legacyDependencies.get} else if (dependencies_ != null) {Some(dependencies_)} else {// 這種情況應該很少見。stateLock.synchronized {if (dependencies_ == null) {dependencies_ = getDependencies}Some(dependencies_)}}}/*** 獲取此 RDD 的分區數組,考慮到 RDD 是否進行了檢查點操作。** @return 分區數組*/final def partitions: Array[Partition] = {checkpointRDD.map(_.partitions).getOrElse {if (partitions_ == null) {stateLock.synchronized {if (partitions_ == null) {partitions_ = getPartitionspartitions_.zipWithIndex.foreach { case (partition, index) =>require(partition.index == index,s"partitions($index).partition == ${partition.index}, but it should equal $index")}}}}partitions_}}/*** 返回此 RDD 的分區數。** @return 分區數*/@Since("1.6.0")final def getNumPartitions: Int = partitions.length/*** 獲取分區的首選位置,考慮到 RDD 是否進行了檢查點操作。** @param split 分區* @return 首選位置序列*/final def preferredLocations(split: Partition): Seq[String] = {checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {getPreferredLocations(split)}}/*** 此 RDD 的內部方法;如果適用,將從緩存中讀取,否則進行計算。* 此方法不應該由用戶直接調用,而是供自定義 RDD 子類的實現者使用。** @param split 分區* @param context 任務上下文* @return 分區元素的迭代器*/final def iterator(split: Partition, context: TaskContext): Iterator[T] = {if (storageLevel != StorageLevel.NONE) {getOrCompute(split, context)} else {computeOrReadCheckpoint(split, context)}}/*** 返回給定 RDD 的祖先,這些祖先僅通過一系列窄依賴關系與之相關。* 此方法使用深度優先搜索遍歷給定 RDD 的依賴樹,但不保證返回的 RDD 有特定順序。** @return 祖先 RDD 序列*/private[spark] def getNarrowAncestors: Seq[RDD[_]] = {val ancestors = new mutable.HashSet[RDD[_]]def visit(rdd: RDD[_]): Unit = {val narrowDependencies = rdd.dependencies.filter(_.isInstanceOf[NarrowDependency[_]])val narrowParents = narrowDependencies.map(_.rdd)val narrowParentsNotVisited = narrowParents.filterNot(ancestors.contains)narrowParentsNotVisited.foreach { parent =>ancestors.add(parent)visit(parent)}}visit(this)// 為了避免循環,不包括根 RDD 本身ancestors.filterNot(_ == this).toSeq}/*** 計算 RDD 分區或從檢查點讀取(如果 RDD 正在進行檢查點操作)。** @param split 分區* @param context 任務上下文* @return 分區元素的迭代器*/private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] ={if (isCheckpointedAndMaterialized) {firstParent[T].iterator(split, context)} else {compute(split, context)}}/*** 獲取或計算 RDD 分區。當 RDD 被緩存時,由 RDD.iterator() 使用。** @param partition 分區* @param context 任務上下文* @return 分區元素的迭代器*/private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {val blockId = RDDBlockId(id, partition.index)var readCachedBlock = true// 此方法在執行器上調用,因此我們需要調用 SparkEnv.get 而不是 sc.env。SparkEnv.get.blockManager.getOrElseUpdateRDDBlock(context.taskAttemptId(), blockId, storageLevel, elementClassTag, () => {readCachedBlock = falsecomputeOrReadCheckpoint(partition, context)}) match {// 塊命中。case Left(blockResult) =>if (readCachedBlock) {val existingMetrics = context.taskMetrics().inputMetricsexistingMetrics.incBytesRead(blockResult.bytes)new InterruptibleIterator[T](context, blockResult.data.asInstanceOf[Iterator[T]]) {override def next(): T = {existingMetrics.incRecordsRead(1)delegate.next()}}} else {new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]])}// 需要計算塊。case Right(iter) =>new InterruptibleIterator(context, iter)}}/*** 在一個作用域內執行一段代碼,使得在該作用域內創建的所有新 RDD 都將屬于同一個作用域。* 有關更多詳細信息,請參閱 {{org.apache.spark.rdd.RDDOperationScope}}。** 注意:給定的代碼塊中不允許使用 return 語句。** @param body 要執行的代碼塊* @tparam U 代碼塊的返回類型* @return 代碼塊的返回值*/private[spark] def withScope[U](body: => U): U = RDDOperationScope.withScope[U](sc)(body)// 轉換操作(返回一個新的 RDD)/*** 通過對該 RDD 的所有元素應用一個函數,返回一個新的 RDD。** @param f 應用于每個元素的函數* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/def map[U: ClassTag](f: T => U): RDD[U] = withScope {val cleanF = sc.clean(f)new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))}/*** 首先對該 RDD 的所有元素應用一個函數,然后將結果展平,返回一個新的 RDD。** @param f 應用于每個元素的函數,返回一個可遍歷的集合* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {val cleanF = sc.clean(f)new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.flatMap(cleanF))}/*** 返回一個新的 RDD,其中只包含滿足謂詞的元素。** @param f 用于過濾元素的謂詞函數* @return 新的 RDD*/def filter(f: T => Boolean): RDD[T] = withScope {val cleanF = sc.clean(f)new MapPartitionsRDD[T, T](this,(_, _, iter) => iter.filter(cleanF),preservesPartitioning = true)}/*** 返回一個新的 RDD,其中包含該 RDD 中的不同元素。** @param numPartitions 新 RDD 的分區數* @param ord 元素的排序規則* @return 新的 RDD*/def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {def removeDuplicatesInPartition(partition: Iterator[T]): Iterator[T] = {// 創建一個外部追加僅映射的實例,該實例忽略值。val map = new ExternalAppendOnlyMap[T, Null, Null](createCombiner = _ => null,mergeValue = (a, b) => a,mergeCombiners = (a, b) => a)map.insertAll(partition.map(_ -> null))map.iterator.map(_._1)}partitioner match {case Some(_) if numPartitions == partitions.length =>mapPartitions(removeDuplicatesInPartition, preservesPartitioning = true)case _ => map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)}}/*** 返回一個新的 RDD,其中包含該 RDD 中的不同元素。* 使用該 RDD 的分區數作為新 RDD 的分區數。** @return 新的 RDD*/def distinct(): RDD[T] = withScope {distinct(partitions.length)}/*** 返回一個新的 RDD,該 RDD 正好有 numPartitions 個分區。** 可以增加或減少該 RDD 的并行度。內部使用洗牌操作來重新分配數據。** 如果要減少該 RDD 的分區數,建議使用 `coalesce`,它可以避免執行洗牌操作。** @param numPartitions 新的分區數* @param ord 元素的排序規則* @return 新的 RDD*/def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {coalesce(numPartitions, shuffle = true)}/*** 返回一個新的 RDD,該 RDD 被合并為 `numPartitions` 個分區。** 這會產生一個窄依賴關系,例如,如果從 1000 個分區合并到 100 個分區,不會進行洗牌操作,* 而是每個新分區將獲取當前分區中的 10 個分區。如果請求的分區數更大,則保持當前的分區數。** 但是,如果進行大幅度的合并,例如合并到 numPartitions = 1,這可能會導致計算只在比預期少的節點上進行* (例如,numPartitions = 1 時只在一個節點上進行)。為了避免這種情況,可以將 shuffle 設置為 true。* 這將添加一個洗牌步驟,但意味著當前的上游分區將并行執行(根據當前的分區方式)。** @param numPartitions 新的分區數* @param shuffle 是否進行洗牌操作* @param partitionCoalescer 可選的分區合并器* @param ord 元素的排序規則* @return 新的 RDD*/def coalesce(numPartitions: Int, shuffle: Boolean = false,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T] = withScope {require(numPartitions > 0, s"Number of partitions ($numPartitions) must be positive.")if (shuffle) {/** 從隨機分區開始,將元素均勻分布到輸出分區。 */val distributePartition = (index: Int, items: Iterator[T]) => {var position = new XORShiftRandom(index).nextInt(numPartitions)items.map { t =>// 注意,鍵的哈希碼將只是鍵本身。HashPartitioner 將對其進行取模操作。position = position + 1(position, t)}} : Iterator[(Int, T)]// 包括一個洗牌步驟,以便我們的上游任務仍然可以分布執行new CoalescedRDD(new ShuffledRDD[Int, T, T](mapPartitionsWithIndexInternal(distributePartition, isOrderSensitive = true),new HashPartitioner(numPartitions)),numPartitions,partitionCoalescer).values} else {new CoalescedRDD(this, numPartitions, partitionCoalescer)}}/*** 返回此 RDD 的一個采樣子集。** @param withReplacement 元素是否可以被多次采樣(采樣后是否替換)* @param fraction 作為此 RDD 大小的一部分,樣本的預期大小* 無替換:每個元素被選中的概率;fraction 必須在 [0, 1] 范圍內* 有替換:每個元素被選中的預期次數;fraction 必須大于或等于 0* @param seed 隨機數生成器的種子** @note 這不能保證提供給定 [[RDD]] 的確切分數計數。** @return 采樣后的 RDD*/def sample(withReplacement: Boolean,fraction: Double,seed: Long = Utils.random.nextLong): RDD[T] = {require(fraction >= 0,s"Fraction must be nonnegative, but got ${fraction}")withScope {if (withReplacement) {new PartitionwiseSampledRDD[T, T](this, new PoissonSampler[T](fraction), true, seed)} else {new PartitionwiseSampledRDD[T, T](this, new BernoulliSampler[T](fraction), true, seed)}}}/*** 隨機將此 RDD 按提供的權重分割。** @param weights 分割的權重,若它們的和不為 1,則會進行歸一化* @param seed 隨機種子** @return 分割后的 RDD 數組*/def randomSplit(weights: Array[Double],seed: Long = Utils.random.nextLong): Array[RDD[T]] = {require(weights.forall(_ >= 0),s"Weights must be nonnegative, but got ${weights.mkString("[", ",", "]")}")require(weights.sum > 0,s"Sum of weights must be positive, but got ${weights.mkString("[", ",", "]")}")withScope {val sum = weights.sumval normalizedCumWeights = weights.map(_ / sum).scanLeft(0.0d)(_ + _)normalizedCumWeights.sliding(2).map { x =>randomSampleWithRange(x(0), x(1), seed)}.toArray}}/*** 為 DataFrames 中的隨機分割暴露的內部方法。根據給定的概率范圍對 RDD 進行采樣。** @param lb 用于伯努利采樣器的下限* @param ub 用于伯努利采樣器的上限* @param seed 隨機數生成器的種子** @return 此 RDD 的一個無替換隨機子樣本。*/private[spark] def randomSampleWithRange(lb: Double, ub: Double, seed: Long): RDD[T] = {this.mapPartitionsWithIndex( { (index, partition) =>val sampler = new BernoulliCellSampler[T](lb, ub)sampler.setSeed(seed + index)sampler.sample(partition)}, isOrderSensitive = true, preservesPartitioning = true)}/*** 以數組形式返回此 RDD 的固定大小采樣子集。** @param withReplacement 是否進行有放回采樣* @param num 返回樣本的大小* @param seed 隨機數生成器的種子** @return 指定大小的樣本數組** @note 只有當結果數組預期較小時才應使用此方法,因為所有數據都會加載到驅動程序的內存中。*/def takeSample(withReplacement: Boolean,num: Int,seed: Long = Utils.random.nextLong): Array[T] = withScope {val numStDev = 10.0require(num >= 0, "Negative number of elements requested")require(num <= (Int.MaxValue - (numStDev * math.sqrt(Int.MaxValue)).toInt),"Cannot support a sample size > Int.MaxValue - " +s"$numStDev * math.sqrt(Int.MaxValue)")if (num == 0) {new Array[T](0)} else {val initialCount = this.count()if (initialCount == 0) {new Array[T](0)} else {val rand = new Random(seed)if (!withReplacement && num >= initialCount) {Utils.randomizeInPlace(this.collect(), rand)} else {val fraction = SamplingUtils.computeFractionForSampleSize(num, initialCount,withReplacement)var samples = this.sample(withReplacement, fraction, rand.nextInt()).collect()// 如果第一個樣本不夠大,繼續嘗試采樣;這種情況不應該經常發生,因為我們初始大小使用了較大的乘數var numIters = 0while (samples.length < num) {logWarning(s"Needed to re-sample due to insufficient sample size. Repeat #$numIters")samples = this.sample(withReplacement, fraction, rand.nextInt()).collect()numIters += 1}Utils.randomizeInPlace(samples, rand).take(num)}}}}/*** 返回此 RDD 和另一個 RDD 的并集。任何相同的元素都會多次出現(使用 `.distinct()` 消除它們)。** @param other 另一個 RDD* @return 并集 RDD*/def union(other: RDD[T]): RDD[T] = withScope {sc.union(this, other)}/*** 返回此 RDD 和另一個 RDD 的并集。任何相同的元素都會多次出現(使用 `.distinct()` 消除它們)。* 這是 `union` 方法的別名。** @param other 另一個 RDD* @return 并集 RDD*/def ++(other: RDD[T]): RDD[T] = withScope {this.union(other)}/*** 返回按給定鍵函數排序的此 RDD。** @param f 用于提取鍵的函數* @param ascending 是否升序排序* @param numPartitions 結果 RDD 的分區數* @param ord 鍵的排序規則* @param ctag 鍵的類型標簽* @return 排序后的 RDD*/def sortBy[K](f: (T) => K,ascending: Boolean = true,numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {this.keyBy[K](f).sortByKey(ascending, numPartitions).values}/*** 返回此 RDD 和另一個 RDD 的交集。輸出不會包含任何重復元素,即使輸入 RDD 中有重復元素。** @note 此方法內部會執行洗牌操作。** @param other 另一個 RDD* @return 交集 RDD*/def intersection(other: RDD[T]): RDD[T] = withScope {this.map(v => (v, null)).cogroup(other.map(v => (v, null))).filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }.keys}/*** 返回此 RDD 和另一個 RDD 的交集。輸出不會包含任何重復元素,即使輸入 RDD 中有重復元素。** @note 此方法內部會執行洗牌操作。** @param other 另一個 RDD* @param partitioner 結果 RDD 使用的分區器* @param ord 元素的排序規則* @return 交集 RDD*/def intersection(other: RDD[T],partitioner: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] = withScope {this.map(v => (v, null)).cogroup(other.map(v => (v, null)), partitioner).filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }.keys}/*** 返回此 RDD 和另一個 RDD 的交集。輸出不會包含任何重復元素,即使輸入 RDD 中有重復元素。* 在集群上執行哈希分區。** @note 此方法內部會執行洗牌操作。** @param other 另一個 RDD* @param numPartitions 結果 RDD 的分區數* @return 交集 RDD*/def intersection(other: RDD[T], numPartitions: Int): RDD[T] = withScope {intersection(other, new HashPartitioner(numPartitions))}/*** 返回一個新的 RDD,通過將每個分區內的所有元素合并為一個數組。** @return 新的 RDD,元素為數組*/def glom(): RDD[Array[T]] = withScope {new MapPartitionsRDD[Array[T], T](this, (_, _, iter) => Iterator(iter.toArray))}/*** 返回此 RDD 和另一個 RDD 的笛卡爾積,即所有元素對 (a, b) 的 RDD,其中 a 屬于 `this`,b 屬于 `other`。** @param other 另一個 RDD* @tparam U 另一個 RDD 中元素的類型* @return 笛卡爾積 RDD*/def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {new CartesianRDD(sc, this, other)}/*** 返回一個分組元素的 RDD。每個組由一個鍵和映射到該鍵的元素序列組成。* 每個組內元素的順序不保證,并且每次計算結果 RDD 時可能會不同。** @note 此操作可能非常昂貴。如果是為了對每個鍵執行聚合操作(如求和或求平均值),* 使用 `PairRDDFunctions.aggregateByKey` 或 `PairRDDFunctions.reduceByKey` 會提供更好的性能。** @param f 用于提取鍵的函數* @param kt 鍵的類型標簽* @tparam K 鍵的類型* @return 分組后的 RDD*/def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {groupBy[K](f, defaultPartitioner(this))}/*** 返回一個分組元素的 RDD。每個組由一個鍵和映射到該鍵的元素序列組成。* 每個組內元素的順序不保證,并且每次計算結果 RDD 時可能會不同。** @note 此操作可能非常昂貴。如果是為了對每個鍵執行聚合操作(如求和或求平均值),* 使用 `PairRDDFunctions.aggregateByKey` 或 `PairRDDFunctions.reduceByKey` 會提供更好的性能。** @param f 用于提取鍵的函數* @param numPartitions 結果 RDD 的分區數* @param kt 鍵的類型標簽* @tparam K 鍵的類型* @return 分組后的 RDD*/def groupBy[K](f: T => K,numPartitions: Int)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {groupBy(f, new HashPartitioner(numPartitions))}/*** 返回一個分組元素的 RDD。每個組由一個鍵和映射到該鍵的元素序列組成。* 每個組內元素的順序不保證,并且每次計算結果 RDD 時可能會不同。** @note 此操作可能非常昂貴。如果是為了對每個鍵執行聚合操作(如求和或求平均值),* 使用 `PairRDDFunctions.aggregateByKey` 或 `PairRDDFunctions.reduceByKey` 會提供更好的性能。** @param f 用于提取鍵的函數* @param p 分區器* @param kt 鍵的類型標簽* @param ord 鍵的排序規則* @tparam K 鍵的類型* @return 分組后的 RDD*/def groupBy[K](f: T => K, p: Partitioner)(implicit kt: ClassTag[K], ord: Ordering[K] = null): RDD[(K, Iterable[T])] = withScope {val cleanF = sc.clean(f)this.map(t => (cleanF(t), t)).groupByKey(p)}/*** 返回一個通過將元素傳遞給一個外部進程而創建的 RDD。** @param command 要執行的命令* @return 新的 RDD,元素為字符串*/def pipe(command: String): RDD[String] = withScope {// 類似于 Runtime.exec(),如果我們得到一個字符串,使用標準的 StringTokenizer(按空格)將其拆分為單詞pipe(PipedRDD.tokenize(command))}/*** 返回一個通過將元素傳遞給一個外部進程而創建的 RDD。** @param command 要執行的命令* @param env 環境變量映射* @return 新的 RDD,元素為字符串*/def pipe(command: String, env: Map[String, String]): RDD[String] = withScope {// 類似于 Runtime.exec(),如果我們得到一個字符串,使用標準的 StringTokenizer(按空格)將其拆分為單詞pipe(PipedRDD.tokenize(command), env)}/*** 返回一個通過將元素傳遞給一個外部進程而創建的 RDD。* 結果 RDD 通過為每個分區執行一次給定的進程來計算。每個輸入分區的所有元素作為由換行符分隔的輸入行寫入進程的標準輸入。* 結果分區由進程的標準輸出組成,標準輸出的每一行都會成為輸出分區的一個元素。即使對于空分區也會啟動一個進程。** 可以通過提供兩個函數來定制打印行為。** @param command 在外部進程中運行的命令* @param env 要設置的環境變量* @param printPipeContext 在管道元素之前,調用此函數以提供管道上下文數據的機會。* 打印行函數(如 out.println)將作為 printPipeContext 的參數傳遞。* @param printRDDElement 使用此函數來定制如何管道元素。此函數將以每個 RDD 元素作為第一個參數,* 打印行函數(如 out.println())作為第二個參數調用。* 例如,以流式方式管道 groupBy() 的 RDD 數據,而不是構造一個巨大的字符串來連接所有元素:* {{{* def printRDDElement(record:(String, Seq[String]), f:String=>Unit) =* for (e <- record._2) {f(e)}* }}}* @param separateWorkingDir 是否為每個任務使用單獨的工作目錄* @param bufferSize 管道進程標準輸入寫入器的緩沖區大小* @param encoding 與管道進程交互(通過標準輸入、標準輸出和標準錯誤)使用的字符編碼* @return 結果 RDD*/def pipe(command: Seq[String],env: Map[String, String] = Map(),printPipeContext: (String => Unit) => Unit = null,printRDDElement: (T, String => Unit) => Unit = null,separateWorkingDir: Boolean = false,bufferSize: Int = 8192,encoding: String = Codec.defaultCharsetCodec.name): RDD[String] = withScope {new PipedRDD(this, command, env,if (printPipeContext ne null) sc.clean(printPipeContext) else null,if (printRDDElement ne null) sc.clean(printRDDElement) else null,separateWorkingDir,bufferSize,encoding)}/*** 通過對該 RDD 的每個分區應用一個函數,返回一個新的 RDD。** `preservesPartitioning` 指示輸入函數是否保留分區器,除非這是一個鍵值對 RDD 且輸入函數不修改鍵,否則應設置為 `false`。** @param f 應用于每個分區的函數* @param preservesPartitioning 是否保留分區器* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U],preservesPartitioning: Boolean = false): RDD[U] = withScope {val cleanedF = sc.clean(f)new MapPartitionsRDD(this,(_: TaskContext, _: Int, iter: Iterator[T]) => cleanedF(iter),preservesPartitioning)}/*** [性能] Spark 內部的 mapPartitionsWithIndex 方法,跳過閉包清理。* 這是一個性能相關的 API,只有在確定 RDD 元素是可序列化的且不需要閉包清理時才能謹慎使用。** @param f 應用于每個分區的函數,接收分區索引和迭代器作為參數* @param preservesPartitioning 指示輸入函數是否保留分區器,* 除非這是一個鍵值對 RDD 且輸入函數不修改鍵,否則應設置為 `false`。* @param isOrderSensitive 函數是否對順序敏感。如果對順序敏感,當輸入順序改變時,可能會返回完全不同的結果。* 大多數有狀態的函數對順序敏感。* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/private[spark] def mapPartitionsWithIndexInternal[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean = false,isOrderSensitive: Boolean = false): RDD[U] = withScope {new MapPartitionsRDD(this,(_: TaskContext, index: Int, iter: Iterator[T]) => f(index, iter),preservesPartitioning = preservesPartitioning,isOrderSensitive = isOrderSensitive)}/*** [性能] Spark 內部的 mapPartitions 方法,跳過閉包清理。** @param f 應用于每個分區的函數* @param preservesPartitioning 是否保留分區器* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/private[spark] def mapPartitionsInternal[U: ClassTag](f: Iterator[T] => Iterator[U],preservesPartitioning: Boolean = false): RDD[U] = withScope {new MapPartitionsRDD(this,(_: TaskContext, _: Int, iter: Iterator[T]) => f(iter),preservesPartitioning)}/*** 通過對該 RDD 的每個分區應用一個函數,同時跟蹤原始分區的索引,返回一個新的 RDD。** `preservesPartitioning` 指示輸入函數是否保留分區器,除非這是一個鍵值對 RDD 且輸入函數不修改鍵,否則應設置為 `false`。** @param f 應用于每個分區的函數,接收分區索引和迭代器作為參數* @param preservesPartitioning 是否保留分區器* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/def mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean = false): RDD[U] = withScope {val cleanedF = sc.clean(f)new MapPartitionsRDD(this,(_: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),preservesPartitioning)}/*** 通過對該 RDD 的每個分區應用一個評估器,返回一個新的 RDD。* 給定的評估器工廠將被序列化并發送到執行器,每個任務將使用該工廠創建一個評估器,* 并使用評估器轉換輸入分區的數據。** @param evaluatorFactory 分區評估器工廠* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/@DeveloperApi@Since("3.5.0")def mapPartitionsWithEvaluator[U: ClassTag](evaluatorFactory: PartitionEvaluatorFactory[T, U]): RDD[U] = withScope {new MapPartitionsWithEvaluatorRDD(this, evaluatorFactory)}/*** 將此 RDD 的分區與另一個 RDD 的分區進行拉鏈操作,并通過對拉鏈后的分區應用一個評估器,返回一個新的 RDD。* 假設兩個 RDD 具有 *相同數量的分區*,但不要求每個分區中的元素數量相同。** @param rdd2 另一個 RDD* @param evaluatorFactory 分區評估器工廠* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/@DeveloperApi@Since("3.5.0")def zipPartitionsWithEvaluator[U: ClassTag](rdd2: RDD[T],evaluatorFactory: PartitionEvaluatorFactory[T, U]): RDD[U] = withScope {new ZippedPartitionsWithEvaluatorRDD(this, rdd2, evaluatorFactory)}/*** 通過對該 RDD 的每個分區應用一個函數,同時跟蹤原始分區的索引,返回一個新的 RDD。** `preservesPartitioning` 指示輸入函數是否保留分區器,除非這是一個鍵值對 RDD 且輸入函數不修改鍵,否則應設置為 `false`。** `isOrderSensitive` 指示函數是否對順序敏感。如果對順序敏感,當輸入順序改變時,可能會返回完全不同的結果。* 大多數有狀態的函數對順序敏感。** @param f 應用于每個分區的函數,接收分區索引和迭代器作為參數* @param preservesPartitioning 是否保留分區器* @param isOrderSensitive 函數是否對順序敏感* @tparam U 新 RDD 中元素的類型* @return 新的 RDD*/private[spark] def mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U],preservesPartitioning: Boolean,isOrderSensitive: Boolean): RDD[U] = withScope {val cleanedF = sc.clean(f)new MapPartitionsRDD(this,(_: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),preservesPartitioning,isOrderSensitive = isOrderSensitive)}/*** 將此 RDD 與另一個 RDD 進行拉鏈操作,返回鍵值對 RDD,其中每個鍵值對包含兩個 RDD 中的第一個元素、第二個元素等。* 假設兩個 RDD 具有 *相同數量的分區* 且 *每個分區中的元素數量相同*(例如,一個 RDD 是通過對另一個 RDD 進行映射操作得到的)。** @param other 另一個 RDD* @tparam U 另一個 RDD 中元素的類型* @return 拉鏈后的 RDD*/def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {zipPartitions(other, preservesPartitioning = false) { (thisIter, otherIter) =>new Iterator[(T, U)] {def hasNext: Boolean = (thisIter.hasNext, otherIter.hasNext) match {case (true, true) => truecase (false, false) => falsecase _ => throw SparkCoreErrors.canOnlyZipRDDsWithSamePartitionSizeError()}def next(): (T, U) = (thisIter.next(), otherIter.next())}}}/*** 將此 RDD 的分區與另一個 RDD 的分區進行拉鏈操作,并通過對拉鏈后的分區應用一個函數,返回一個新的 RDD。* 假設兩個 RDD 具有 *相同數量的分區*,但不要求每個分區中的元素數量相同。** @param rdd2 另一個 RDD* @param preservesPartitioning 是否保留分區器* @param f 應用于拉鏈后分區的函數* @tparam B 另一個 RDD 中元素的類型* @tparam V 新 RDD 中元素的類型* @return 新的 RDD*/def zipPartitions[B: ClassTag, V: ClassTag](rdd2: RDD[B], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V] = withScope {new ZippedPartitionsRDD2(sc, sc.clean(f), this, rdd2, preservesPartitioning)}/*** 將此 RDD 的分區與另一個 RDD 的分區進行拉鏈操作,并通過對拉鏈后的分區應用一個函數,返回一個新的 RDD。* 假設兩個 RDD 具有 *相同數量的分區*,但不要求每個分區中的元素數量相同。* 不保留分區器。** @param rdd2 另一個 RDD* @param f 應用于拉鏈后分區的函數* @tparam B 另一個 RDD 中元素的類型* @tparam V 新 RDD 中元素的類型* @return 新的 RDD*/def zipPartitions[B: ClassTag, V: ClassTag](rdd2: RDD[B])(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V] = withScope {zipPartitions(rdd2, preservesPartitioning = false)(f)}/*** 將此 RDD 的分區與另外兩個 RDD 的分區進行拉鏈操作,并通過對拉鏈后的分區應用一個函數,返回一個新的 RDD。* 假設三個 RDD 具有 *相同數量的分區*,但不要求每個分區中的元素數量相同。** @param rdd2 第二個 RDD* @param rdd3 第三個 RDD* @param preservesPartitioning 是否保留分區器* @param f 應用于拉鏈后分區的函數* @tparam B 第二個 RDD 中元素的類型* @tparam C 第三個 RDD 中元素的類型* @tparam V 新 RDD 中元素的類型* @return 新的 RDD*/def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] = withScope {new ZippedPartitionsRDD3(sc, sc.clean(f), this, rdd2, rdd3, preservesPartitioning)}/*** 將此 RDD 的分區與另外兩個 RDD 的分區進行拉鏈操作,并通過對拉鏈后的分區應用一個函數,返回一個新的 RDD。* 假設三個 RDD 具有 *相同數量的分區*,但不要求每個分區中的元素數量相同。* 不保留分區器。** @param rdd2 第二個 RDD* @param rdd3 第三個 RDD* @param f 應用于拉鏈后分區的函數* @tparam B 第二個 RDD 中元素的類型* @tparam C 第三個 RDD 中元素的類型* @tparam V 新 RDD 中元素的類型* @return 新的 RDD*/def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C])(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] = withScope {zipPartitions(rdd2, rdd3, preservesPartitioning = false)(f)}/*** 將此 RDD 的分區與另外三個 RDD 的分區進行拉鏈操作,并通過對拉鏈后的分區應用一個函數,返回一個新的 RDD。* 假設四個 RDD 具有 *相同數量的分區*,但不要求每個分區中的元素數量相同。** @param rdd2 第二個 RDD* @param rdd3 第三個 RDD* @param rdd4 第四個 RDD* @param preservesPartitioning 是否保留分區器* @param f 應用于拉鏈后分區的函數* @tparam B 第二個 RDD 中元素的類型* @tparam C 第三個 RDD 中元素的類型* @tparam D 第四個 RDD 中元素的類型* @tparam V 新 RDD 中元素的類型* @return 新的 RDD*/def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V] = withScope {new ZippedPartitionsRDD4(sc, sc.clean(f), this, rdd2, rdd3, rdd4, preservesPartitioning)}/*** 將此 RDD 的分區與另外三個 RDD 的分區進行拉鏈操作,并通過對拉鏈后的分區應用一個函數,返回一個新的 RDD。* 假設四個 RDD 具有 *相同數量的分區*,但不要求每個分區中的元素數量相同。* 不保留分區器。** @param rdd2 第二個 RDD* @param rdd3 第三個 RDD* @param rdd4 第四個 RDD* @param f 應用于拉鏈后分區的函數* @tparam B 第二個 RDD 中元素的類型* @tparam C 第三個 RDD 中元素的類型* @tparam D 第四個 RDD 中元素的類型* @tparam V 新 RDD 中元素的類型* @return 新的 RDD*/def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag](rdd2: RDD[B], rdd3: RDD[C], rdd4: RDD[D])(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V] = withScope {zipPartitions(rdd2, rdd3, rdd4, preservesPartitioning = false)(f)}// 動作操作(啟動一個作業以將值返回給用戶程序)/*** 對該 RDD 的所有元素應用一個函數。** @param f 應用于每個元素的函數*/def foreach(f: T => Unit): Unit = withScope {val cleanF = sc.clean(f)sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))}/*** 對該 RDD 的每個分區應用一個函數。** @param f 應用于每個分區的函數*/def foreachPartition(f: Iterator[T] => Unit): Unit = withScope {val cleanF = sc.clean(f)sc.runJob(this, (iter: Iterator[T]) => cleanF(iter))}/*** 返回一個包含該 RDD 所有元素的數組。** @note 只有當結果數組預期較小時才應使用此方法,因為所有數據都會加載到驅動程序的內存中。** @return 包含所有元素的數組*/def collect(): Array[T] = withScope {val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)Array.concat(results: _*)}/*** 返回一個包含該 RDD 所有元素的迭代器。** 迭代器將消耗與該 RDD 中最大分區相同的內存。** @note 這會導致多個 Spark 作業,如果輸入 RDD 是寬轉換的結果(例如,使用不同分區器進行連接),* 為了避免重新計算,輸入 RDD 應該先進行緩存。** @return 包含所有元素的迭代器*/def toLocalIterator: Iterator[T] = withScope {def collectPartition(p: Int): Array[T] = {sc.runJob(this, (iter: Iterator[T]) => iter.toArray, Seq(p)).head}partitions.indices.iterator.flatMap(i => collectPartition(i))}/*** 通過應用 `f` 返回一個包含所有匹配值的 RDD。** @param f 部分函數,用于篩選和轉換元素* @tparam U 新 RDD 中元素的類型* @return 包含匹配值的 RDD*/def collect[U: ClassTag](f: PartialFunction[T, U]): RDD[U] = withScope {val cleanF = sc.clean(f)filter(cleanF.isDefinedAt).map(cleanF)}/*** 返回一個 RDD,其中包含 `this` 中不在 `other` 中的元素。** 使用 `this` 的分區器/分區大小,因為即使 `other` 很大,結果 RDD 也將 <= 我們。** @param other 另一個 RDD* @return 包含差集元素的 RDD*/def subtract(other: RDD[T]): RDD[T] = withScope {subtract(other, partitioner.getOrElse(new HashPartitioner(partitions.length)))}/*** 返回一個 RDD,其中包含 `this` 中不在 `other` 中的元素。** @param other 另一個 RDD* @param numPartitions 結果 RDD 的分區數* @return 包含差集元素的 RDD*/def subtract(other: RDD[T], numPartitions: Int): RDD[T] = withScope {subtract(other, new HashPartitioner(numPartitions))}/*** 返回一個 RDD,其中包含 `this` 中不在 `other` 中的元素。** @param other 另一個 RDD* @param p 分區器* @param ord 元素的排序規則* @return 包含差集元素的 RDD*/def subtract(other: RDD[T],p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] = withScope {if (partitioner == Some(p)) {// 我們的分區器知道如何處理 T(因為我們有一個分區器,實際上是 (K, V))// 所以創建一個新的分區器,用于解包我們的假元組val p2 = new Partitioner() {override def numPartitions: Int = p.numPartitionsoverride def getPartition(k: Any): Int = p.getPartition(k.asInstanceOf[(Any, _)]._1)}// 不幸的是,由于我們創建了一個新的 p2,我們仍然會得到 ShuffleDependencies// 并且在調用 .keys 時,即使 SubtractedRDD 會因為 p2 的解包分區而已經按正確/真實的鍵(例如 p)分區,也不會設置分區器。this.map(x => (x, null)).subtractByKey(other.map((_, null)), p2).keys} else {this.map(x => (x, null)).subtractByKey(other.map((_, null)), p).keys}}/*** 使用指定的可交換和關聯的二元運算符對該 RDD 的元素進行歸約。** @param f 歸約函數* @return 歸約結果*/def reduce(f: (T, T) => T): T = withScope {val cleanF = sc.clean(f)val reducePartition: Iterator[T] => Option[T] = iter => {if (iter.hasNext) {Some(iter.reduceLeft(cleanF))} else {None}}var jobResult: Option[T] = Noneval mergeResult = (_: Int, taskResult: Option[T]) => {if (taskResult.isDefined) {jobResult = jobResult match {case Some(value) => Some(f(value, taskResult.get))case None => taskResult}}}sc.runJob(this, reducePartition, mergeResult)// 從 Option 中獲取最終結果,或者如果 RDD 為空則拋出異常jobResult.getOrElse(throw SparkCoreErrors.emptyCollectionError())}/*** 以多級樹模式對該 RDD 的元素進行歸約。** @param depth 樹的建議深度(默認:2)* @see [[org.apache.spark.rdd.RDD#reduce]]* @return 歸約結果*/def treeReduce(f: (T, T) => T, depth: Int = 2): T = withScope {require(depth >= 1, s"Depth must be greater than or equal to 1 but got $depth.")val cleanF = context.clean(f)val reducePartition: Iterator[T] => Option[T] = iter => {if (iter.hasNext) {Some(iter.reduceLeft(cleanF))} else {None}}val partiallyReduced = mapPartitions(it => Iterator(reducePartition(it)))val op: (Option[T], Option[T]) => Option[T] = (c, x) => {if (c.isDefined && x.isDefined) {Some(cleanF(c.get, x.get))} else if (c.isDefined) {c} else if (x.isDefined) {x} else {None}}partiallyReduced.treeAggregate(Option.empty[T])(op, op, depth).getOrElse(throw SparkCoreErrors.emptyCollectionError())}/*** 對每個分區的元素進行聚合,然后對所有分區的結果進行聚合,使用給定的關聯函數和中性 "零值"。* 函數 op(t1, t2) 允許修改 t1 并將其作為結果返回,以避免對象分配;但是,它不應該修改 t2。** 此操作的行為與函數式語言(如 Scala)中為非分布式集合實現的折疊操作有所不同。* 此折疊操作可能會分別應用于各個分區,然后將這些結果折疊為最終結果,而不是按某種定義的順序依次應用于每個元素。* 對于非交換函數,結果可能與應用于非分布式集合的折疊操作不同。** @param zeroValue 每個分區的累積結果的初始值,以及不同分區的合并結果的初始值 - 這通常是中性元素* (例如,列表連接的 `Nil` 或求和的 `0`)* @param op 用于在分區內累積結果和合并不同分區結果的運算符* @return 聚合結果*/def fold(zeroValue: T)(op: (T, T) => T): T = withScope {// 克隆零值,因為我們也會將其作為任務的一部分進行序列化var jobResult = Utils.clone(zeroValue, sc.env.closureSerializer.newInstance())val cleanOp = sc.clean(op)val foldPartition = (iter: Iterator[T]) => iter.fold(zeroValue)(cleanOp)val mergeResult = (_: Int, taskResult: T) => jobResult = op(jobResult, taskResult)sc.runJob(this, foldPartition, mergeResult)jobResult}/*** 對每個分區的元素進行聚合,然后對所有分區的結果進行聚合,使用給定的合并函數和中性 "零值"。* 此函數可以返回與該 RDD 的類型 T 不同的結果類型 U。* 因此,我們需要一個操作來將 T 合并到 U 中,以及一個操作來合并兩個 U,就像在 scala.TraversableOnce 中一樣。* 這兩個函數都允許修改并返回其第一個參數,而不是創建一個新的 U,以避免內存分配。** @param zeroValue 每個分區的累積結果的初始值,以及不同分區的合并結果的初始值 - 這通常是中性元素* (例如,列表連接的 `Nil` 或求和的 `0`)* @param seqOp 用于在分區內累積結果的運算符* @param combOp 用于合并不同分區結果的關聯運算符* @tparam U 聚合結果的類型* @return 聚合結果*/def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U = withScope {// 克隆零值,因為我們也會將其作為任務的一部分進行序列化var jobResult = Utils.clone(zeroValue, sc.env.serializer.newInstance())val cleanSeqOp = sc.clean(seqOp)val cleanCombOp = sc.clean(combOp)val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)val mergeResult = (_: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)sc.runJob(this, aggregatePartition, mergeResult)jobResult}/*** 以多級樹模式對該 RDD 的元素進行聚合。* 此方法在語義上與 [[org.apache.spark.rdd.RDD#aggregate]] 相同。** @param zeroValue 每個分區的累積結果的初始值,以及不同分區的合并結果的初始值 - 這通常是中性元素* (例如,列表連接的 `Nil` 或求和的 `0`)* @param seqOp 用于在分區內累積結果的運算符* @param combOp 用于合并不同分區結果的關聯運算符* @param depth 樹的建議深度(默認:2)* @tparam U 聚合結果的類型* @return 聚合結果*/def treeAggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U,combOp: (U, U) => U,depth: Int = 2): U = withScope {treeAggregate(zeroValue, seqOp, combOp, depth, finalAggregateOnExecutor = false)}/*** [[org.apache.spark.rdd.RDD#treeAggregate]] 帶有一個參數,用于在執行器上進行最終聚合。** @param zeroValue 每個分區的累積結果的初始值,以及不同分區的合并結果的初始值 - 這通常是中性元素* (例如,列表連接的 `Nil` 或求和的 `0`)* @param seqOp 用于在分區內累積結果的運算符* @param combOp 用于合并不同分區結果的關聯運算符* @param depth 樹的建議深度* @param finalAggregateOnExecutor 是否在執行器上進行最終聚合* @tparam U 聚合結果的類型* @return 聚合結果*/def treeAggregate[U: ClassTag](zeroValue: U,seqOp: (U, T) => U,combOp: (U, U) => U,depth: Int,finalAggregateOnExecutor: Boolean): U = withScope {require(depth >= 1, s"Depth must be greater than or equal to 1 but got $depth.")if (partitions.length == 0) {Utils.clone(zeroValue, context.env.closureSerializer.newInstance())} else {val cleanSeqOp = context.clean(seqOp)val cleanCombOp = context.clean(combOp)val aggregatePartition =(it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)var partiallyAggregated: RDD[U] = mapPartitions(it => Iterator(aggregatePartition(it)))var numPartitions = partiallyAggregated.partitions.lengthval scale = math.max(math.ceil(math.pow(numPartitions, 1.0 / depth)).toInt, 2)// 如果創建一個額外的級別不能幫助減少// 時鐘時間,我們停止樹聚合。// 當不能節省時鐘時間時,不觸發樹聚合while (numPartitions > scale + math.ceil(numPartitions.toDouble / scale)) {numPartitions /= scaleval curNumPartitions = numPartitionspartiallyAggregated = partiallyAggregated.mapPartitionsWithIndex {(i, iter) => iter.map((i % curNumPartitions, _))}.foldByKey(zeroValue, new HashPartitioner(curNumPartitions))(cleanCombOp).values}if (finalAggregateOnExecutor && partiallyAggregated.partitions.length > 1) {// 將部分聚合的 RDD 映射為鍵值對 RDD// 在單個執行器上使用一個分區進行計算// 獲取新的 RDD[U]partiallyAggregated = partiallyAggregated.map(v => (0.toByte, v)).foldByKey(zeroValue, new ConstantPartitioner)(cleanCombOp).values}val copiedZeroValue = Utils.clone(zeroValue, sc.env.closureSerializer.newInstance())partiallyAggregated.fold(copiedZeroValue)(cleanCombOp)}}/*** 返回該 RDD 中的元素數量。** @return 元素數量*/def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum/*** count() 的近似版本,在超時時間內返回一個可能不完整的結果,即使并非所有任務都已完成。** 置信度是結果的誤差范圍包含真實值的概率。也就是說,如果以置信度 0.9 重復調用 countApprox,* 我們預計 90% 的結果將包含真實計數。置信度必須在 [0,1] 范圍內,否則將拋出異常。** @param timeout 作業的最大等待時間,以毫秒為單位* @param confidence 結果的期望統計置信度* @return 可能不完整的結果,帶有誤差范圍*/def countApprox(timeout: Long,confidence: Double = 0.95): PartialResult[BoundedDouble] = withScope {require(0.0 <= confidence && confidence <= 1.0, s"confidence ($confidence) must be in [0,1]")val countElements: (TaskContext, Iterator[T]) => Long = { (_, iter) =>var result = 0Lwhile (iter.hasNext) {result += 1Liter.next()}result}val evaluator = new CountEvaluator(partitions.length, confidence)sc.runApproximateJob(this, countElements, evaluator, timeout)}/*** 返回該 RDD 中每個唯一值的計數,作為一個本地的 (值, 計數) 對映射。** @note 只有當結果映射預期較小時才應使用此方法,因為整個映射都會加載到驅動程序的內存中。* 要處理非常大的結果,考慮使用** {{{* rdd.map(x => (x, 1L)).reduceByKey(_ + _)* }}}** 它返回一個 RDD[T, Long] 而不是一個映射。** @param ord 元素的排序規則* @return 唯一值的計數映射*/def countByValue()(implicit ord: Ordering[T] = null): Map[T, Long] = withScope {map(value => (value, null)).countByKey()}/*** countByValue() 的近似版本。** @param timeout 作業的最大等待時間,以毫秒為單位* @param confidence 結果的期望統計置信度* @param ord 元素的排序規則* @return 可能不完整的結果,帶有誤差范圍*/def countByValueApprox(timeout: Long, confidence: Double = 0.95)(implicit ord: Ordering[T] = null): PartialResult[Map[T, BoundedDouble]] = withScope {require(0.0 <= confidence && confidence <= 1.0, s"confidence ($confidence) must be in [0,1]")if (elementClassTag.runtimeClass.isArray) {throw SparkCoreErrors.countByValueApproxNotSupportArraysError()}val countPartition: (TaskContext, Iterator[T]) => OpenHashMap[T, Long] = { (_, iter) =>val map = new OpenHashMap[T, Long]iter.foreach {t => map.changeValue(t, 1L, _ + 1L)}map}val evaluator = new GroupedCountEvaluator[T](partitions.length, confidence)sc.runApproximateJob(this, countPartition, evaluator, timeout)}/*** 返回該 RDD 中不同元素的近似數量。** 所使用的算法基于 streamlib 對 "HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm" 的實現,* 可在 <a href="https://doi.org/10.1145/2452376.2452456">此處</a> 找到。** 相對精度約為 `1.054 / sqrt(2^p)`。設置一個非零的 (`sp` 大于 `p`) 將觸發寄存器的稀疏表示,* 這可能會減少內存消耗并在基數較小時提高精度。** @param p 正常集合的精度值。* `p` 必須是一個介于 4 和 `sp` 之間的值(如果 `sp` 不為零,最大為 32)。* @param sp 稀疏集合的精度值,介于 0 和 32 之間。* 如果 `sp` 等于 0,則跳過稀疏表示。* @return 不同元素的近似數量*/def countApproxDistinct(p: Int, sp: Int): Long = withScope {require(p >= 4, s"p ($p) must be >= 4")require(sp <= 32, s"sp ($sp) must be <= 32")require(sp == 0 || p <= sp, s"p ($p) cannot be greater than sp ($sp)")val zeroCounter = new HyperLogLogPlus(p, sp)aggregate(zeroCounter)((hll: HyperLogLogPlus, v: T) => {hll.offer(v)hll},(h1: HyperLogLogPlus, h2: HyperLogLogPlus) => {h1.addAll(h2)h1}).cardinality()}/*** 返回該 RDD 中不同元素的近似數量。** 所使用的算法基于 streamlib 對 "HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm" 的實現,* 可在 <a href="https://doi.org/10.1145/2452376.2452456">此處</a> 找到。** @param relativeSD 相對精度。較小的值會創建需要更多空間的計數器。* 它必須大于 0.000017。* @return 不同元素的近似數量*/def countApproxDistinct(relativeSD: Double = 0.05): Long = withScope {require(relativeSD > 0.000017, s"accuracy ($relativeSD) must be greater than 0.000017")val p = math.ceil(2.0 * math.log(1.054 / relativeSD) / math.log(2)).toIntcountApproxDistinct(if (p < 4) 4 else p, 0)}/*** 將此 RDD 與其元素的索引進行拉鏈操作。排序首先基于分區索引,然后是每個分區內元素的順序。* 因此,第一個分區中的第一個元素的索引為 0,最后一個分區中的最后一個元素的索引最大。** 這類似于 Scala 的 zipWithIndex,但它使用 Long 而不是 Int 作為索引類型。* 當此 RDD 包含多個分區時,此方法需要觸發一個 Spark 作業。** @note 某些 RDD(例如,由 groupBy() 返回的 RDD)不保證分區內元素的順序。* 因此,分配給每個元素的索引不能保證,并且如果重新計算 RDD,索引甚至可能會改變。* 如果需要固定的順序來保證相同的索引分配,應該使用 sortByKey() 對 RDD 進行排序或將其保存到文件中。** @return 拉鏈后的 RDD,元素為 (元素, 索引) 對*/def zipWithIndex(): RDD[(T, Long)] = withScope {new ZippedWithIndexRDD(this)}/*** 將此 RDD 與生成的唯一 Long ID 進行拉鏈操作。第 k 個分區中的元素將獲得 ID k, n+k, 2*n+k, ...,* 其中 n 是分區數。因此可能會存在間隙,但此方法不會觸發 Spark 作業,這與 [[org.apache.spark.rdd.RDD#zipWithIndex]] 不同。** @note 某些 RDD(例如,由 groupBy() 返回的 RDD)不保證分區內元素的順序。* 因此,分配給每個元素的唯一 ID 不能保證,并且如果重新計算 RDD,ID 甚至可能會改變。* 如果需要固定的順序來保證相同的索引分配,應該使用 sortByKey() 對 RDD 進行排序或將其保存到文件中。** @return 拉鏈后的 RDD,元素為 (元素, 唯一 ID) 對*/def zipWithUniqueId(): RDD[(T, Long)] = withScope {val n = this.partitions.length.toLongthis.mapPartitionsWithIndex { case (k, iter) =>Utils.getIteratorZipWithIndex(iter, 0L).map { case (item, i) =>(item, i * n + k)}}}/*** 獲取該 RDD 的前 num 個元素。它首先掃描一個分區,然后使用該分區的結果來估計滿足限制所需的額外分區數。** @note 只有當結果數組預期較小時才應使用此方法,因為所有數據都會加載到驅動程序的內存中。** @note 由于內部實現的復雜性,如果在 `Nothing` 或 `Null` 類型的 RDD 上調用此方法,將拋出異常。** @param num 要獲取的元素數量* @return 包含前 num 個元素的數組*/def take(num: Int): Array[T] = withScope {val scaleUpFactor = Math.max(conf.get(RDD_LIMIT_SCALE_UP_FACTOR), 2)if (num == 0) {new Array[T](0)} else {val buf = new ArrayBuffer[T]val totalParts = this.partitions.lengthvar partsScanned = 0while (buf.size < num && partsScanned < totalParts) {// 本次迭代要嘗試的分區數。這個數字可以大于 totalParts,因為我們實際上在 runJob 中會將其限制為 totalParts。var numPartsToTry = conf.get(RDD_LIMIT_INITIAL_NUM_PARTITIONS)val left = num - buf.sizeif (partsScanned > 0) {// 如果上一次迭代后沒有找到任何行,則乘以 limitScaleUpFactor 并重試。// 否則,插值計算我們需要嘗試的分區數,但高估 50%。最后我們也會限制這個估計值。if (buf.isEmpty) {numPartsToTry = partsScanned * scaleUpFactor} else {// 由于 left > 0,numPartsToTry 總是 >= 1numPartsToTry = Math.ceil(1.5 * left * partsScanned / buf.size).toIntnumPartsToTry = Math.min(numPartsToTry, partsScanned * scaleUpFactor)}}val p = partsScanned.until(math.min(partsScanned + numPartsToTry, totalParts).toInt)val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p)res.foreach(buf ++= _.take(num - buf.size))partsScanned += p.size}buf.toArray}}/*** 返回該 RDD 中的第一個元素。** @return 第一個元素*/def first(): T = withScope {take(1) match {case Array(t) => tcase _ => throw SparkCoreErrors.emptyCollectionError()}}/*** 根據指定的隱式 Ordering[T] 返回該 RDD 中的前 k 個(最大)元素,并保持排序順序。* 這與 [[takeOrdered]] 相反。例如:* {{{* sc.parallelize(Seq(10, 4, 2, 12, 3)).top(1)* // 返回 Array(12)** sc.parallelize(Seq(2, 3, 4, 5, 6)).top(2)* // 返回 Array(6, 5)* }}}** @note 只有當結果數組預期較小時才應使用此方法,因為所有數據都會加載到驅動程序的內存中。** @param num k,要返回的前 k 個元素的數量* @param ord 元素的排序規則* @return 包含前 k 個元素的數組*/def top(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {takeOrdered(num)(ord.reverse)}/*** 根據指定的隱式 Ordering[T] 返回該 RDD 中的前 k 個(最小)元素,并保持排序順序。* 這與 [[top]] 相反。例如:* {{{* sc.parallelize(Seq(10, 4, 2, 12, 3)).takeOrdered(1)* // 返回 Array(2)** sc.parallelize(Seq(2, 3, 4, 5, 6)).takeOrdered(2)* // 返回 Array(2, 3)* }}}** @note 只有當結果數組預期較小時才應使用此方法,因為所有數據都會加載到驅動程序的內存中。** @param num k,要返回的前 k 個元素的數量* @param ord 元素的排序規則* @return 包含前 k 個元素的數組*/def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {if (num == 0 || this.getNumPartitions == 0) {Array.empty} else {this.mapPartitionsWithIndex { case (pid, iter) =>if (iter.nonEmpty) {// 優先級隊列保留最大的元素,所以我們反轉排序規則。Iterator.single(collectionUtils.takeOrdered(iter, num)(ord).toArray)} else if (pid == 0) {// 確保分區 0 總是返回一個數組,以避免在空 RDD 上進行 reduce 操作Iterator.single(Array.empty[T])} else {Iterator.empty}}.reduce { (array1, array2) =>val size = math.min(num, array1.length + array2.length)val array = Array.ofDim[T](size)collectionUtils.mergeOrdered[T](Seq(array1, array2))(ord).copyToArray(array, 0, size)array}}}/*** 根據隱式 Ordering[T] 返回該 RDD 中的最大值。** @param ord 元素的排序規則* @return 最大值*/def max()(implicit ord: Ordering[T]): T = withScope {this.reduce(ord.max)}/*** 根據隱式 Ordering[T] 返回該 RDD 中的最小值。** @param ord 元素的排序規則* @return 最小值*/def min()(implicit ord: Ordering[T]): T = withScope {this.reduce(ord.min)}/*** @note 由于內部實現的復雜性,如果在 `Nothing` 或 `Null` 類型的 RDD 上調用此方法,將拋出異常。* 這在實踐中可能會出現,例如,`parallelize(Seq())` 的類型是 `RDD[Nothing]`。* (無論如何都應該避免使用 `parallelize(Seq())`,而應使用 `parallelize(Seq[T]())`。)** @return 如果且僅當該 RDD 不包含任何元素時返回 true。注意,即使 RDD 至少有 1 個分區,它也可能為空。*/def isEmpty(): Boolean = withScope {partitions.length == 0 || take(1).length == 0}/*** 將此 RDD 保存為文本文件,使用元素的字符串表示形式。** @param path 文件路徑*/def saveAsTextFile(path: String): Unit = withScope {saveAsTextFile(path, null)}/*** 將此 RDD 保存為壓縮文本文件,使用元素的字符串表示形式。** @param path 文件路徑* @param codec 壓縮編解碼器類*/def saveAsTextFile(path: String, codec: Class[_ <: CompressionCodec]): Unit = withScope {this.mapPartitions { iter =>val text = new Text()iter.map { x =>require(x != null, "text files do not allow null rows")text.set(x.toString)(NullWritable.get(), text)}}.saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path, codec)}/*** 將此 RDD 保存為序列化對象的 SequenceFile。** @param path 文件路徑*/def saveAsObjectFile(path: String): Unit = withScope {this.mapPartitions(iter => iter.grouped(10).map(_.toArray)).map(x => (NullWritable.get(), new BytesWritable(Utils.serialize(x)))).saveAsSequenceFile(path)}/*** 通過應用 `f` 創建此 RDD 中元素的元組。** @param f 用于提取鍵的函數* @tparam K 鍵的類型* @return 新的 RDD,元素為 (鍵, 元素) 對*/def keyBy[K](f: T => K): RDD[(K, T)] = withScope {val cleanedF = sc.clean(f)map(x => (cleanedF(x), x))}/*** 一個用于測試的私有方法,用于查看每個分區的內容。** @return 包含每個分區元素的二維數組*/private[spark] def collectPartitions(): Array[Array[T]] = withScope {sc.runJob(this, (iter: Iterator[T]) => iter.toArray)}/*** 標記此 RDD 進行檢查點操作。它將被保存到 `SparkContext#setCheckpointDir` 設置的檢查點目錄中的文件中,* 并且所有對其父 RDD 的引用將被移除。此函數必須在對此 RDD 執行任何作業之前調用。* 強烈建議將此 RDD 持久化到內存中,否則將其保存到文件中需要重新計算。*/def checkpoint(): Unit = RDDCheckpointData.synchronized {// 注意:由于下游在確保子 RDD 分區指向正確的父分區方面存在復雜性,我們在這里使用全局鎖。// 將來我們應該重新考慮這個問題。if (context.checkpointDir.isEmpty) {throw SparkCoreErrors.checkpointDirectoryHasNotBeenSetInSparkContextError()} else if (checkpointData.isEmpty) {checkpointData = Some(new ReliableRDDCheckpointData(this))}}/*** 使用 Spark 現有的緩存層標記此 RDD 進行本地檢查點操作。** 此方法適用于希望截斷 RDD 血緣關系,同時跳過在可靠分布式文件系統中復制物化數據這一昂貴步驟的用戶。* 這對于需要定期截斷長血緣關系的 RDD(例如 GraphX)很有用。** 本地檢查點犧牲了容錯性以換取性能。特別是,檢查點數據被寫入執行器的臨時本地存儲,而不是可靠的、容錯的存儲。* 這意味著如果在計算過程中執行器發生故障,檢查點數據可能不再可用,導致不可恢復的作業失敗。** 這與動態分配一起使用不安全,因為動態分配會移除執行器及其緩存塊。如果必須同時使用這兩個功能,建議將* `spark.dynamicAllocation.cachedExecutorIdleTimeout` 設置為較高的值。** `SparkContext#setCheckpointDir` 設置的檢查點目錄不被使用。** @return 此 RDD 實例*/def localCheckpoint(): this.type = RDDCheckpointData.synchronized {if (Utils.isDynamicAllocationEnabled(conf) &&conf.contains(DYN_ALLOCATION_CACHED_EXECUTOR_IDLE_TIMEOUT)) {logWarning("Local checkpointing is NOT safe to use with dynamic allocation, " +"which removes executors along with their cached blocks. If you must use both " +"features, you are advised to set `spark.dynamicAllocation.cachedExecutorIdleTimeout` " +"to a high value. E.g. If you plan to use the RDD for 1 hour, set the timeout to " +"at least 1 hour.")}// 注意:此時我們實際上不知道用戶以后是否會調用 persist() 方法,// 所以我們必須在這里顯式調用它,以確保緩存塊在 SparkContext 中注冊以便后續清理。//// 但是,如果用戶已經在這個 RDD 上調用了 persist() 方法,那么我們必須將他/她指定的存儲級別// 調整為適合本地檢查點的級別(即使用磁盤),以保證正確性。if (storageLevel == StorageLevel.NONE) {persist(LocalRDDCheckpointData.DEFAULT_STORAGE_LEVEL)} else {persist(LocalRDDCheckpointData.transformStorageLevel(storageLevel), allowOverride = true)}// 如果這個 RDD 已經被檢查點并物化,它的血緣關系已經被截斷。// 在這種情況下,我們不能覆蓋我們的 `checkpointData`,因為它是恢復檢查點數據所必需的。// 如果被覆蓋,下次在這個 RDD 上進行物化操作會導致錯誤。if (isCheckpointedAndMaterialized) {logWarning("Not marking RDD for local checkpoint because it was already " +"checkpointed and materialized")} else {// 血緣關系還沒有被截斷,所以只需用我們的檢查點數據覆蓋任何現有的檢查點數據checkpointData match {case Some(_: ReliableRDDCheckpointData[_]) => logWarning("RDD was already marked for reliable checkpointing: overriding with local checkpoint.")case _ =>}checkpointData = Some(new LocalRDDCheckpointData(this))}this}/*** 返回此 RDD 是否已被檢查點并物化,無論是可靠地還是本地地。** @return 如果已被檢查點并物化則返回 true,否則返回 false*/def isCheckpointed: Boolean = isCheckpointedAndMaterialized/*** 返回此 RDD 是否已被檢查點并物化,無論是可靠地還是本地地。* 這是 `isCheckpointed` 的別名,用于澄清返回值的語義。供測試使用。** @return 如果已被檢查點并物化則返回 true,否則返回 false*/private[spark] def isCheckpointedAndMaterialized: Boolean =checkpointData.exists(_.isCheckpointed)/*** 返回此 RDD 是否被標記為本地檢查點。* 供測試使用。** @return 如果被標記為本地檢查點則返回 true,否則返回 false*/private[rdd] def isLocallyCheckpointed: Boolean = {checkpointData match {case Some(_: LocalRDDCheckpointData[T]) => truecase _ => false}}/*** 返回此 RDD 是否已被可靠地檢查點并物化。** @return 如果已被可靠地檢查點并物化則返回 true,否則返回 false*/private[rdd] def isReliablyCheckpointed: Boolean = {checkpointData match {case Some(reliable: ReliableRDDCheckpointData[_]) if reliable.isCheckpointed => truecase _ => false}}/*** 獲取此 RDD 被檢查點到的目錄的名稱。* 如果 RDD 是本地檢查點,則此方法未定義。** @return 檢查點目錄的名稱的可選實例*/def getCheckpointFile: Option[String] = {checkpointData match {case Some(reliable: ReliableRDDCheckpointData[T]) => reliable.getCheckpointDircase _ => None}}/*** 移除 RDD 的洗牌操作及其非持久化的祖先。* 當不使用洗牌服務運行時,清理洗牌文件可以實現縮容。* 如果在此調用后使用 RDD,應該先對其進行檢查點并物化。* 如果不確定自己在做什么,請不要使用此功能。* 緩解孤立洗牌文件的其他技術:* * 調整驅動程序的垃圾回收以更積極,以便觸發常規的上下文清理器* * 設置適當的洗牌文件 TTL 以自動清理** @param blocking 是否阻塞直到清理完成(默認:false)*/@DeveloperApi@Since("3.1.0")def cleanShuffleDependencies(blocking: Boolean = false): Unit = {sc.cleaner.foreach { cleaner =>/*** 清理洗牌操作及其所有父操作。*/def cleanEagerly(dep: Dependency[_]): Unit = {dep match {case dependency: ShuffleDependency[_, _, _] =>val shuffleId = dependency.shuffleIdcleaner.doCleanupShuffle(shuffleId, blocking)case _ => // 不做任何操作}val rdd = dep.rddval rddDepsOpt = rdd.internalDependenciesif (rdd.getStorageLevel == StorageLevel.NONE) {rddDepsOpt.foreach(deps => deps.foreach(cleanEagerly))}}internalDependencies.foreach(deps => deps.foreach(cleanEagerly))}}/*** :: 實驗性 ::* 將當前階段標記為屏障階段,在該階段中,Spark 必須同時啟動所有任務。* 若任務失敗,Spark 不會僅重啟失敗的任務,而是會中止整個階段并重新啟動該階段的所有任務。* 屏障執行模式功能尚處于實驗階段,僅能處理有限的場景。* 請閱讀相關的 SPIP 和設計文檔,以了解其限制和未來規劃。* @return 一個 [[RDDBarrier]] 實例,可在屏障階段內執行操作* @see [[org.apache.spark.BarrierTaskContext]]* @see <a href="https://issues.apache.org/jira/browse/SPARK-24374">* SPIP: 屏障執行模式</a>* @see <a href="https://issues.apache.org/jira/browse/SPARK-24582">設計文檔</a>*/@Experimental@Since("2.4.0")def barrier(): RDDBarrier[T] = withScope(new RDDBarrier[T](this))/*** 指定在計算此 RDD 時使用的資源配置文件。此功能僅在某些集群管理器中受支持,* 并且目前需要啟用動態分配。* 這將導致獲取具有指定資源的新執行器來計算該 RDD。*/@Experimental@Since("3.1.0")def withResources(rp: ResourceProfile): this.type = {// 設置資源配置文件resourceProfile = Option(rp)// 將資源配置文件添加到資源配置文件管理器中sc.resourceProfileManager.addResourceProfile(resourceProfile.get)this}/*** 獲取為此 RDD 指定的資源配置文件,如果未指定則返回 null。* @return 用戶指定的資源配置文件,若未指定則返回 null(為了 Java 兼容性)*/@Experimental@Since("3.1.0")def getResourceProfile(): ResourceProfile = resourceProfile.orNull// =======================================================================// 其他內部方法和字段// =======================================================================// 存儲級別,默認為不存儲private var storageLevel: StorageLevel = StorageLevel.NONE// 資源配置文件,初始為 None@transient private var resourceProfile: Option[ResourceProfile] = None/** 創建此 RDD 的用戶代碼(例如 `textFile`, `parallelize`)。 */@transient private[spark] val creationSite = sc.getCallSite()/*** 與創建此 RDD 的操作關聯的作用域。** 這比調用站點更靈活,并且可以進行分層定義。更多詳細信息,請參閱 {{RDDOperationScope}} 的文檔。* 如果用戶在不使用任何 Spark 操作的情況下自己實例化此 RDD,則此作用域未定義。*/@transient private[spark] val scope: Option[RDDOperationScope] = {// 從本地屬性中獲取 RDD 作用域的 JSON 字符串,并將其轉換為 RDDOperationScope 對象Option(sc.getLocalProperty(SparkContext.RDD_SCOPE_KEY)).map(RDDOperationScope.fromJson)}/*** 獲取創建此 RDD 的調用站點的簡短形式。* @return 調用站點的簡短形式,如果不存在則返回空字符串*/private[spark] def getCreationSite: String = Option(creationSite).map(_.shortForm).getOrElse("")/*** 獲取此 RDD 元素的 ClassTag。* @return 元素的 ClassTag*/private[spark] def elementClassTag: ClassTag[T] = classTag[T]// 檢查點數據,初始為 Noneprivate[spark] var checkpointData: Option[RDDCheckpointData[T]] = None// 是否對所有標記為檢查點的祖先 RDD 進行檢查點操作。默認情況下,// 我們一旦找到第一個這樣的 RDD 就停止,這是一種優化,允許我們寫入更少的數據,// 但并非對所有工作負載都安全。例如,在流式處理中,我們可能會在每個批次中對 RDD 及其父 RDD 進行檢查點操作,// 在這種情況下,父 RDD 可能永遠不會被檢查點,其譜系也不會被截斷,從而導致長期運行時出現 OOM(SPARK-6847)。private val checkpointAllMarkedAncestors =Option(sc.getLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS)).exists(_.toBoolean)/*** 返回第一個父 RDD。* @tparam U 父 RDD 元素的類型* @return 第一個父 RDD*/protected[spark] def firstParent[U: ClassTag]: RDD[U] = {// 獲取依賴項列表的第一個元素,并將其 RDD 轉換為指定類型dependencies.head.rdd.asInstanceOf[RDD[U]]}/*** 返回第 j 個父 RDD:例如,rdd.parent[T](0) 等同于 rdd.firstParent[T]。* @param j 父 RDD 的索引* @tparam U 父 RDD 元素的類型* @return 第 j 個父 RDD*/protected[spark] def parent[U: ClassTag](j: Int): RDD[U] = {// 獲取指定索引的依賴項,并將其 RDD 轉換為指定類型dependencies(j).rdd.asInstanceOf[RDD[U]]}/*** 獲取創建此 RDD 的 [[org.apache.spark.SparkContext]]。* @return 創建此 RDD 的 SparkContext*/def context: SparkContext = sc/*** 私有 API,用于更改 RDD 的 ClassTag。* 用于內部 Java - Scala API 兼容性。* @param cls 新的 Class 類型* @return 具有新 ClassTag 的 RDD*/private[spark] def retag(cls: Class[T]): RDD[T] = {// 根據傳入的 Class 類型創建新的 ClassTagval classTag: ClassTag[T] = ClassTag.apply(cls)// 調用另一個 retag 方法,使用新的 ClassTagthis.retag(classTag)}/*** 私有 API,用于更改 RDD 的 ClassTag。* 用于內部 Java - Scala API 兼容性。* @param classTag 新的 ClassTag* @return 具有新 ClassTag 的 RDD*/private[spark] def retag(implicit classTag: ClassTag[T]): RDD[T] = {// 對每個分區應用 identity 函數,并保留分區器,使用新的 ClassTagthis.mapPartitions(identity, preservesPartitioning = true)(classTag)}// 避免多次處理 doCheckpoint 以防止過度遞歸@transient private var doCheckpointCalled = false/*** 對這個 RDD 進行檢查點操作,即保存該 RDD。此方法在使用該 RDD 的作業完成后調用* (因此該 RDD 已被物化并可能存儲在內存中)。* doCheckpoint() 會遞歸地調用其父 RDD 的 doCheckpoint() 方法。*/private[spark] def doCheckpoint(): Unit = {RDDOperationScope.withScope(sc, "checkpoint", allowNesting = false, ignoreParent = true) {// 檢查是否已經調用過 doCheckpointif (!doCheckpointCalled) {// 標記為已調用doCheckpointCalled = true// 檢查是否定義了檢查點數據if (checkpointData.isDefined) {// 如果需要對所有標記為檢查點的祖先 RDD 進行檢查點操作if (checkpointAllMarkedAncestors) {// 先對父 RDD 進行檢查點操作,因為在我們對自己進行檢查點操作后,譜系將被截斷dependencies.foreach(_.rdd.doCheckpoint())}// 對當前 RDD 進行檢查點操作checkpointData.get.checkpoint()} else {// 若未定義檢查點數據,遞歸調用父 RDD 的 doCheckpoint 方法dependencies.foreach(_.rdd.doCheckpoint())}}}}/*** 將此 RDD 的依賴項從其原始父 RDD 更改為從檢查點文件創建的新 RDD (`newRDD`),* 并忘記其舊的依賴項和分區。*/private[spark] def markCheckpointed(): Unit = stateLock.synchronized {// 保存舊的依賴項到弱引用中legacyDependencies = new WeakReference(dependencies_)// 清除依賴項clearDependencies()// 清空分區信息partitions_ = null// 忘記依賴項的構造函數參數deps = null }/*** 清除此 RDD 的依賴項。此方法必須確保移除對原始父 RDD 的所有引用,* 以便父 RDD 可以被垃圾回收。RDD 的子類可以重寫此方法以實現自己的清理邏輯。* 請參閱 [[org.apache.spark.rdd.UnionRDD]] 以獲取示例。*/protected def clearDependencies(): Unit = stateLock.synchronized {// 將依賴項設置為 nulldependencies_ = null}/*** 返回此 RDD 及其遞歸依賴項的調試描述。* @return 調試描述字符串*/def toDebugString: String = {// 獲取一個 RDD 及其存儲信息的調試描述,不包含其子 RDDdef debugSelf(rdd: RDD[_]): Seq[String] = {import Utils.bytesToString// 獲取持久化信息,如果存儲級別不為 NONE,則獲取存儲級別的描述,否則為空字符串val persistence = if (storageLevel != StorageLevel.NONE) storageLevel.description else ""// 獲取 RDD 的存儲信息,包括緩存分區數、內存大小和磁盤大小val storageInfo = rdd.context.getRDDStorageInfo(_.id == rdd.id).map(info =>" CachedPartitions: %d; MemorySize: %s; DiskSize: %s".format(info.numCachedPartitions, bytesToString(info.memSize), bytesToString(info.diskSize)))// 返回 RDD 描述和存儲信息s"$rdd [$persistence]" +: storageInfo}// 對最后一個子 RDD 應用不同的規則def debugChildren(rdd: RDD[_], prefix: String): Seq[String] = {// 獲取依賴項的數量val len = rdd.dependencies.lengthlen match {case 0 => Seq.emptycase 1 =>// 獲取第一個依賴項val d = rdd.dependencies.head// 遞歸調用 debugString 方法,處理第一個依賴項的 RDDdebugString(d.rdd, prefix, d.isInstanceOf[ShuffleDependency[_, _, _]], true)case _ =>// 獲取除最后一個依賴項之外的所有依賴項val frontDeps = rdd.dependencies.take(len - 1)// 遞歸調用 debugString 方法,處理前面的依賴項的 RDDval frontDepStrings = frontDeps.flatMap(d => debugString(d.rdd, prefix, d.isInstanceOf[ShuffleDependency[_, _, _]]))// 獲取最后一個依賴項val lastDep = rdd.dependencies.last// 遞歸調用 debugString 方法,處理最后一個依賴項的 RDDval lastDepStrings =debugString(lastDep.rdd, prefix, lastDep.isInstanceOf[ShuffleDependency[_, _, _]], true)// 合并前面和最后一個依賴項的調試信息frontDepStrings ++ lastDepStrings}}// 依賴棧中的第一個 RDD 沒有父 RDD,因此不需要 +-def firstDebugString(rdd: RDD[_]): Seq[String] = {// 構建分區信息字符串val partitionStr = "(" + rdd.partitions.length + ")"// 計算左偏移量val leftOffset = (partitionStr.length - 1) / 2// 構建下一個前綴字符串val nextPrefix = (" " * leftOffset) + "|" + (" " * (partitionStr.length - leftOffset))// 處理 RDD 自身的調試信息debugSelf(rdd).zipWithIndex.map{case (desc: String, 0) => s"$partitionStr $desc"case (desc: String, _) => s"$nextPrefix $desc"} ++ debugChildren(rdd, nextPrefix)}// 處理洗牌依賴的 RDD 的調試信息def shuffleDebugString(rdd: RDD[_], prefix: String = "", isLastChild: Boolean): Seq[String] = {// 構建分區信息字符串val partitionStr = "(" + rdd.partitions.length + ")"// 計算左偏移量val leftOffset = (partitionStr.length - 1) / 2// 處理前綴字符串val thisPrefix = prefix.replaceAll("\\|\\s+$", "")// 構建下一個前綴字符串val nextPrefix = (thisPrefix+ (if (isLastChild) " " else "| ")+ (" " * leftOffset) + "|" + (" " * (partitionStr.length - leftOffset)))// 處理 RDD 自身的調試信息debugSelf(rdd).zipWithIndex.map{case (desc: String, 0) => s"$thisPrefix+-$partitionStr $desc"case (desc: String, _) => s"$nextPrefix$desc"} ++ debugChildren(rdd, nextPrefix)}// 處理 RDD 的調試信息def debugString(rdd: RDD[_],prefix: String = "",isShuffle: Boolean = true,isLastChild: Boolean = false): Seq[String] = {if (isShuffle) {// 處理洗牌依賴的 RDDshuffleDebugString(rdd, prefix, isLastChild)} else {// 處理非洗牌依賴的 RDDdebugSelf(rdd).map(prefix + _) ++ debugChildren(rdd, prefix)}}// 調用 firstDebugString 方法并將結果拼接成字符串firstDebugString(this).mkString("\n")}/*** 返回此 RDD 的字符串表示形式。* @return 字符串表示形式*/override def toString: String = "%s%s[%d] at %s".format(Option(name).map(_ + " ").getOrElse(""), getClass.getSimpleName, id, getCreationSite)/*** 將此 RDD 轉換為 JavaRDD。* @return JavaRDD 實例*/def toJavaRDD() : JavaRDD[T] = {// 創建一個 JavaRDD 實例,使用當前 RDD 和元素的 ClassTagnew JavaRDD(this)(elementClassTag)}/*** 判斷此 RDD 是否處于屏障階段。在屏障階段,Spark 必須同時啟動所有任務。** 如果此 RDD 的至少一個父 RDD 或其本身是從 [[RDDBarrier]] 映射而來的,則此 RDD 處于屏障階段。* 對于 [[ShuffledRDD]],此函數始終返回 false,因為 [[ShuffledRDD]] 表示一個新階段的開始。** 如果 [[MapPartitionsRDD]] 是從 [[RDDBarrier]] 轉換而來的,則該 [[MapPartitionsRDD]] 應被標記為屏障。* @return 如果處于屏障階段則返回 true,否則返回 false*/private[spark] def isBarrier(): Boolean = isBarrier_// 出于性能考慮,緩存該值以避免在長 RDD 鏈上重復計算 `isBarrier()`@transient protected lazy val isBarrier_ : Boolean =// 過濾掉洗牌依賴的依賴項,檢查是否存在處于屏障階段的父 RDDdependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())// 緩存輸出確定性級別的值private final lazy val _outputDeterministicLevel: DeterministicLevel.Value =// 調用 getOutputDeterministicLevel 方法獲取輸出確定性級別getOutputDeterministicLevel/*** 返回此 RDD 輸出的確定性級別。請參考 [[DeterministicLevel]] 以獲取定義。** 默認情況下,可靠檢查點的 RDD 或沒有父 RDD 的根 RDD 是 DETERMINATE。* 對于有父 RDD 的 RDD,我們將根據依賴關系為每個父 RDD 生成一個確定性級別候選。* 當前 RDD 的確定性級別是確定性最低的候選級別。請重寫 [[getOutputDeterministicLevel]] 方法* 以提供自定義的輸出確定性級別計算邏輯。* @return 輸出的確定性級別*/// TODO(SPARK-34612): 使其公開,以便用戶可以為自定義 RDD 設置確定性級別。// TODO: 這可以是每個分區的。例如,UnionRDD 可以為不同的分區具有不同的確定性級別。private[spark] final def outputDeterministicLevel: DeterministicLevel.Value = {if (isReliablyCheckpointed) {// 如果是可靠檢查點的 RDD,則返回 DETERMINATEDeterministicLevel.DETERMINATE} else {// 否則返回緩存的確定性級別_outputDeterministicLevel}}/*** 開發者 API:獲取此 RDD 輸出的確定性級別。* 默認情況下,一個可靠檢查點的 RDD 或沒有父 RDD 的根 RDD 是 DETERMINATE。* 對于有父 RDD 的 RDD,會根據依賴關系為每個父 RDD 生成一個確定性級別候選,* 當前 RDD 的確定性級別是這些候選中確定性最低的級別。* 子類可以重寫此方法以提供自定義的計算邏輯。* @return 輸出的確定性級別*/@DeveloperApiprotected def getOutputDeterministicLevel: DeterministicLevel.Value = {// 根據依賴關系計算每個父 RDD 的確定性級別候選val deterministicLevelCandidates = dependencies.map {// 對于洗牌依賴,如果父 RDD 的分區器與當前依賴的分區器相同,則認為洗牌未真正發生,// 假設當前 RDD 的輸出確定性級別與父 RDD 相同case dep: ShuffleDependency[_, _, _] if dep.rdd.partitioner.exists(_ == dep.partitioner) =>dep.rdd.outputDeterministicLevel// 對于洗牌依賴,如果父 RDD 的輸出是不確定的,則洗牌輸出也將是不確定的case dep: ShuffleDependency[_, _, _] =>if (dep.rdd.outputDeterministicLevel == DeterministicLevel.INDETERMINATE) {DeterministicLevel.INDETERMINATE} else if (dep.keyOrdering.isDefined && dep.aggregator.isDefined) {// 如果指定了聚合器(因此鍵是唯一的)并且指定了鍵排序,則輸出是確定的DeterministicLevel.DETERMINATE} else {// 在 Spark 中,歸約器會同時獲取多個遠程洗牌塊,這些洗牌塊的到達順序是完全隨機的。// 即使父映射 RDD 是確定的,歸約 RDD 也總是無序的DeterministicLevel.UNORDERED}// 對于窄依賴,假設當前 RDD 的輸出確定性級別與父 RDD 相同case dep => dep.rdd.outputDeterministicLevel}if (deterministicLevelCandidates.isEmpty) {// 如果沒有依賴項,默認假設根 RDD 是確定的DeterministicLevel.DETERMINATE} else {// 選擇確定性最低的級別deterministicLevelCandidates.maxBy(_.id)}}
}
/*** 包含與RDD相關的工具方法和隱式轉換。*/
object RDD {/*** 用于配置是否對所有標記為檢查點的祖先RDD進行檢查點操作的屬性鍵。*/private[spark] val CHECKPOINT_ALL_MARKED_ANCESTORS ="spark.checkpoint.checkpointAllMarkedAncestors"/*** 以下隱式函數在Spark 1.3之前位于SparkContext中,用戶需要 `import SparkContext._` 來啟用它們。* 現在我們將它們移到這里,以便編譯器自動找到它們。* 然而,為了向后兼容,我們仍然在SparkContext中保留舊的函數,并直接轉發到以下函數。*//*** 將一個鍵值對RDD轉換為PairRDDFunctions,以便使用鍵值對RDD的特定操作。** @param rdd 要轉換的鍵值對RDD。* @param kt 鍵的ClassTag。* @param vt 值的ClassTag。* @param ord 鍵的排序器,默認為null。* @tparam K 鍵的類型。* @tparam V 值的類型。* @return 轉換后的PairRDDFunctions實例。*/implicit def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null): PairRDDFunctions[K, V] = {new PairRDDFunctions(rdd)}/*** 將一個RDD轉換為AsyncRDDActions,以便使用RDD的異步操作。** @param rdd 要轉換的RDD。* @tparam T RDD中元素的類型。* @return 轉換后的AsyncRDDActions實例。*/implicit def rddToAsyncRDDActions[T: ClassTag](rdd: RDD[T]): AsyncRDDActions[T] = {new AsyncRDDActions(rdd)}/*** 將一個鍵值對RDD轉換為SequenceFileRDDFunctions,以便使用SequenceFile相關的操作。** @param rdd 要轉換的鍵值對RDD。* @param kt 鍵的ClassTag。* @param vt 值的ClassTag。* @param keyWritableFactory 鍵的Writable工廠。* @param valueWritableFactory 值的Writable工廠。* @tparam K 鍵的類型。* @tparam V 值的類型。* @return 轉換后的SequenceFileRDDFunctions實例。*/implicit def rddToSequenceFileRDDFunctions[K, V](rdd: RDD[(K, V)])(implicit kt: ClassTag[K], vt: ClassTag[V],keyWritableFactory: WritableFactory[K],valueWritableFactory: WritableFactory[V]): SequenceFileRDDFunctions[K, V] = {// 隱式定義鍵的轉換器implicit val keyConverter = keyWritableFactory.convert// 隱式定義值的轉換器implicit val valueConverter = valueWritableFactory.convertnew SequenceFileRDDFunctions(rdd,keyWritableFactory.writableClass(kt), valueWritableFactory.writableClass(vt))}/*** 將一個鍵值對RDD轉換為OrderedRDDFunctions,以便使用有序RDD的特定操作。** @param rdd 要轉換的鍵值對RDD。* @tparam K 鍵的類型,需要實現Ordering和ClassTag。* @tparam V 值的類型,需要實現ClassTag。* @return 轉換后的OrderedRDDFunctions實例。*/implicit def rddToOrderedRDDFunctions[K : Ordering : ClassTag, V: ClassTag](rdd: RDD[(K, V)]): OrderedRDDFunctions[K, V, (K, V)] = {new OrderedRDDFunctions[K, V, (K, V)](rdd)}/*** 將一個Double類型的RDD轉換為DoubleRDDFunctions,以便使用Double類型RDD的特定操作。** @param rdd 要轉換的Double類型RDD。* @return 轉換后的DoubleRDDFunctions實例。*/implicit def doubleRDDToDoubleRDDFunctions(rdd: RDD[Double]): DoubleRDDFunctions = {new DoubleRDDFunctions(rdd)}/*** 將一個數值類型的RDD轉換為DoubleRDDFunctions,先將RDD中的元素轉換為Double類型,再進行操作。** @param rdd 要轉換的數值類型RDD。* @param num 數值類型的隱式轉換。* @tparam T 數值類型。* @return 轉換后的DoubleRDDFunctions實例。*/implicit def numericRDDToDoubleRDDFunctions[T](rdd: RDD[T])(implicit num: Numeric[T]): DoubleRDDFunctions = {new DoubleRDDFunctions(rdd.map(x => num.toDouble(x)))}
}/*** RDD輸出的確定性級別,解釋了Spark重新運行RDD任務時輸出的差異情況。* 有三種確定性級別:* 1. DETERMINATE: 重新運行后,RDD輸出始終是相同的數據集,且順序相同。* 2. UNORDERED: 重新運行后,RDD輸出始終是相同的數據集,但順序可能不同。* 3. INDETERMINATE: 重新運行后,RDD輸出可能不同。** 注意,RDD的輸出通常依賴于其父RDD。當父RDD的輸出是INDETERMINATE時,該RDD的輸出很可能也是INDETERMINATE。*/
private[spark] object DeterministicLevel extends Enumeration {// 確定性級別:輸出始終相同且順序一致val DETERMINATE, // 確定性級別:輸出相同但順序可能不同UNORDERED, // 確定性級別:輸出可能不同INDETERMINATE = Value
}



![[2018][note]用于超快偏振開關和動態光束分裂的all-optical有源THz超表——](http://pic.xiahunao.cn/[2018][note]用于超快偏振開關和動態光束分裂的all-optical有源THz超表——)

)

工作流程介紹)










