1?問題現象
SQL執行計劃是GaussDB性能分析及調優的核心,它輸出三個關鍵信息:
- 訪問路徑:掃描表數據的路徑。
- 連接順序:多表連接順序。
- 連接方式:多表連接方式。
2?技術背景
GaussDB SQL語句執行計劃是數據庫為運行SQL語句而執行的操作步驟序列。它顯示了數據庫如何訪問數據,包括表的掃描方式、索引的使用、連接方法等。通過執行計劃,我們可以了解SQL語句引用表的順序、SQL語句中每個表的訪問方法、針對SQL語句中連接操作相關表的連接方法,where條件過濾、order排序及count聚合等操作,從而找到性能瓶頸并進行優化。
通過分析執行計劃,可以識別出性能瓶頸,如全表掃描、索引使用不當等,并采取相應的優化措施,比如創建或調整索引、重寫查詢語句等,執行計劃是SQL性能分析及調優的核心,可以幫助開發者和數據庫管理員提升查詢效率和系統性能。
2.1?用explain查看執行計劃
GaussDB可以使用EXPLAIN命令可以查看優化器為每個查詢生成的具體執行計劃。
explain select 投影列 FROM 表名 WHERE 條件;2.1.1?explain分析示例
EXPLAIN給每個執行節點都輸出一行,顯示基本的節點類型和優化器為執行這個節點預計的開銷值。
- 最底層節點是表掃描節點,它掃描表并返回原始數據行。不同的表訪問模式有不同的掃描節點類型:順序掃描、索引掃描等。最底層節點的掃描對象也可能是非表行數據(不是直接從表中讀取的數據),如VALUES子句和返回行集的函數,它們有自己的掃描節點類型。
- ?如果查詢需要連接、聚集、排序或者對原始行做其他操作,那么就會在掃描節點上添加其他節點。并且這些操作通常都有多種方法,因此在這些位置也有可能出現不同的執行節點類型。
- 第一行(最上層節點)是執行計劃總執行開銷的預計。這個數值就是優化器試圖最小化的數值。
2.1.2?語法格式與選項
1)?顯示SQL語句執行計劃格式:
EXPLAIN [ ( option [, ...] ) ] statement;2)?其中選項option子句的語法:
ANALYZE [ boolean ] -- 執行語句,并顯示實際運行時間和其他統計數據
| PERFORMANCE [ Boolean ] -- 執行語句,并顯示性能開銷
| VERBOSE [ Boolean ] -- 顯示計劃額外信息
| COSTS [ Boolean ] -- 顯示代價
| CPU [ boolean ] -- 顯示cpu使用
| DETAIL [ boolean ] -- 打印節點信息
| NODES [ boolean ] -- 顯示執行節點
| NUM_NODES [ boolean ] -- 顯示節點數量
| BUFFERS [ boolean ] -- 顯示buffer使用
| TIMING [ boolean ] -- 顯示耗時
| PLAN [ boolean ] -- 顯示計劃
| FORMAT { TEXT | XML | JSON | YAML }3)?參數說明
- statement
指定要分析的SQL語句。
- ANALYZE?boolean
顯示實際運行時間和其他統計數據。當兩個參數同時使用時,在option中排在后面的一個生效。
取值范圍:
○?TRUE(缺省值):顯示實際運行時間和其他統計數據。
○?FALSE:不顯示。
- ?VERBOSE?boolean
顯示有關計劃的額外信息。
取值范圍:
○?TRUE(缺省值):顯示額外信息。
○?FALSE:不顯示。
- COSTS?boolean
包括每個規劃節點的估計總成本,以及估計的行數和每行的寬度。
取值范圍:
○?TRUE(缺省值):顯示估計總成本和寬度。
○?FALSE:不顯示。
- CPU?boolean
打印CPU的使用情況的信息。需要結合ANALYZE選項一起使用。
取值范圍:
○?TRUE(缺省值):顯示CPU的使用情況。
○?FALSE:不顯示。
- ?DETAIL?boolean
打印數據庫節點上的信息。需要結合ANALYZE選項一起使用。
取值范圍:
○?TRUE(缺省值):打印數據庫節點的信息。
○?FALSE:不打印。
- NODES?boolean(僅分布式模式可用,集中式模式不可用)
打印query執行的節點信息。
取值范圍:
○?TRUE(缺省值):打印執行的節點的信息。
○?FALSE:不打印。
- NUM_NODES?boolean(僅分布式模式可用,集中式模式不可用)
打印執行中的節點的個數信息。
取值范圍:
○?TRUE(缺省值):打印數據庫節點個數的信息。
○?FALSE:不打印。
- ?BUFFERS?boolean
包括緩沖區的使用情況的信息。需要結合ANALYZE選項一起使用。
取值范圍:
○?TRUE:顯示緩沖區的使用情況。
○?FALSE(缺省值):不顯示。
- ?TIMING?boolean
包括實際的啟動時間和花費在輸出節點上的時間信息。需要結合ANALYZE選項一起使用。
取值范圍:
○?TRUE(缺省值):顯示啟動時間和花費在輸出節點上的時間信息。
○?FALSE:不顯示。
- ?PLAN
是否將執行計劃存儲在plan_table中。當該選項開啟時,會將執行計劃存儲在plan_table中,不打印到當前屏幕,因此該選項為on時,不能與其他選項同時使用。
取值范圍:
○?ON(缺省值):將執行計劃存儲在plan_table中,不打印到當前屏幕。執行成功返回EXPLAIN?SUCCESS。
○?OFF:不存儲執行計劃,將執行計劃打印到當前屏幕。
- ?BLOCKNAME?boolean
是否顯示計劃的每個操作所處于的查詢塊。當該選項開啟時,會將每個操作所處于的查詢塊的名字輸出在Query Block列上,方便用戶獲取查詢塊名字,并使用Hint修改執行計劃:
○?TRUE(缺省值):顯示計劃時,將每個操作所處于的查詢塊的名字輸出在新增列Query Block列上。該選項需要在pretty模式下使用。
○?FALSE:不對計劃顯示產生影響。
- ?OUTLINE?boolean
是否顯示計劃的Outline Hint信息。
○?ON:顯示計劃時,將Outline Hint顯示在計劃下方?。
○?OFF(缺省值):不顯示計劃的Outline Hint信息。
- ADAPTCOST?boolean
在Normal模式下是否顯示計劃的基數估計方式信息。
○?ON(缺省值):Normal模式下,在計劃節點上展示基數估計的方式,包含默認方式和反饋方式,不對預備語句生效。
○?OFF:不展示基數估計的方式信息。
- ?FORMAT
指定輸出格式。
取值范圍:TEXT,XML,JSON和YAML。
默認值:TEXT。
- PERFORMANCE
使用此選項時,即打印執行中的所有相關信息。下述為部分信息描述:
○?ex c/r:代表平均每行使用cpu周期數,等于(ex?cyc)/(ex row)。
○?ex row:執行行數。
○?ex?cyc:代表使用的cpu周期數。
○?inc?cyc:代表包含子節點使用的總cpu周期數。
○?shared hit:代表算子的share buffer命中情況。
○?loops:算子循環執行次數。
○?total_calls:生成元素總數。
○?remote query poll time stream gather:算子用于偵聽各DN數據到達CN的網絡poll時間。
○?deserialize time:反序列化所需時間。
○?estimated time:估計時間。
- OPTEVAL?boolean
是否顯示SCAN算子(當前僅支持seqscan、indexscan、indexonlyscan、bitmapheapscan)的代價淘汰明細,當開啟此開關的時候,會在執行計劃中顯示一個名字為Cost Evaluation Info (identified by plan id)的計劃塊,該選項僅僅可以和COSTS、VERBOSE、FORMAT三個選項共存。
取值范圍:
○?TRUE:顯示SCAN算子的代價淘汰明細。
○?FALSE(缺省值):不顯示。
實際查看執行計劃時,這些參數根據實際需要進行增加,絕大部分場景下使用EXPLAIN ANALYZE?statement就行。
2.1.3?執行計劃顯示格式
GaussDB對執行計劃提供了normal、pretty、summary、run四種顯示格式:
- ?normal:代表使用默認的打印格式。
- ?pretty:代表使用GaussDB改進后的新顯示格式。新的格式層次清晰,計劃包含了plan node id,性能分析簡單直接。
- summary:在pretty的基礎上增加了對打印信息的分析。
- run:在summary的基礎上,將統計的信息輸出到csv格式的文件中,以便于進一步分析。
pretty格式執行計劃示例:
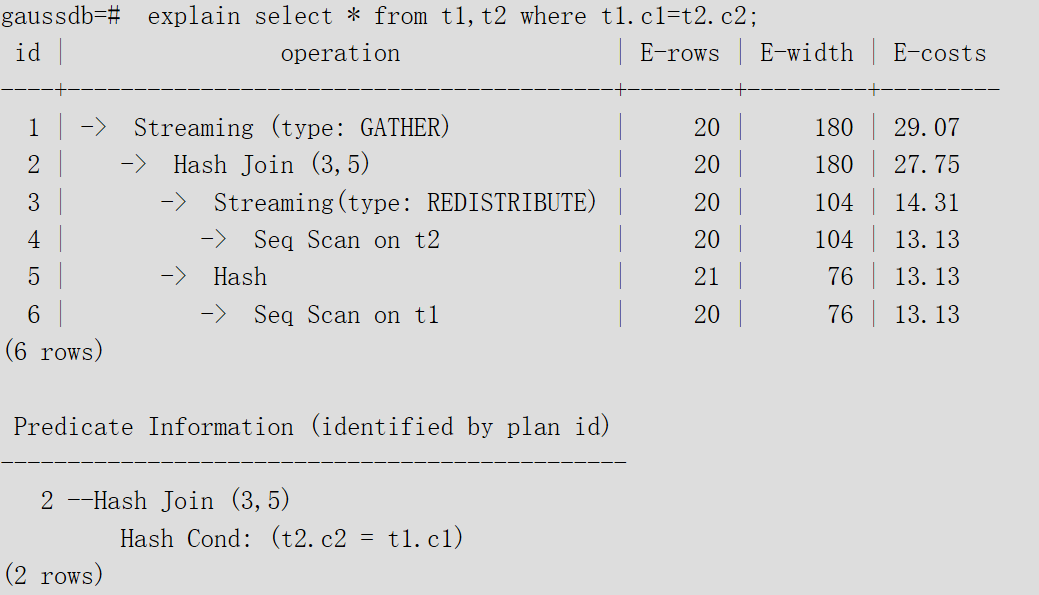
通過設置GUC參數explain_perf_mode,可以顯示不同格式的執行計劃。pretty格式是我們通常使用的。
2.1.4?查看執行計劃
除了設置不同的執行計劃顯示格式外,還可以通過不同的EXPLAIN用法,顯示不同詳細程度的執行計劃信息。常見有如下幾種,關于更多用法請參見EXPLAIN?語法說明。
- ?EXPLAIN?statement:只生成執行計劃,不實際執行。其中statement代表SQL語句。
- EXPLAIN ANALYZE?statement:生成執行計劃,進行執行,并顯示執行的概要信息。顯示中加入了實際的運行時間統計,包括在每個規劃節點內部花費的總時間(以毫秒計)和它實際返回的行數。
- ?EXPLAIN PERFORMANCE?statement:生成執行計劃,進行執行,并顯示執行期間的全部信息。
以如下SQL語句為例:
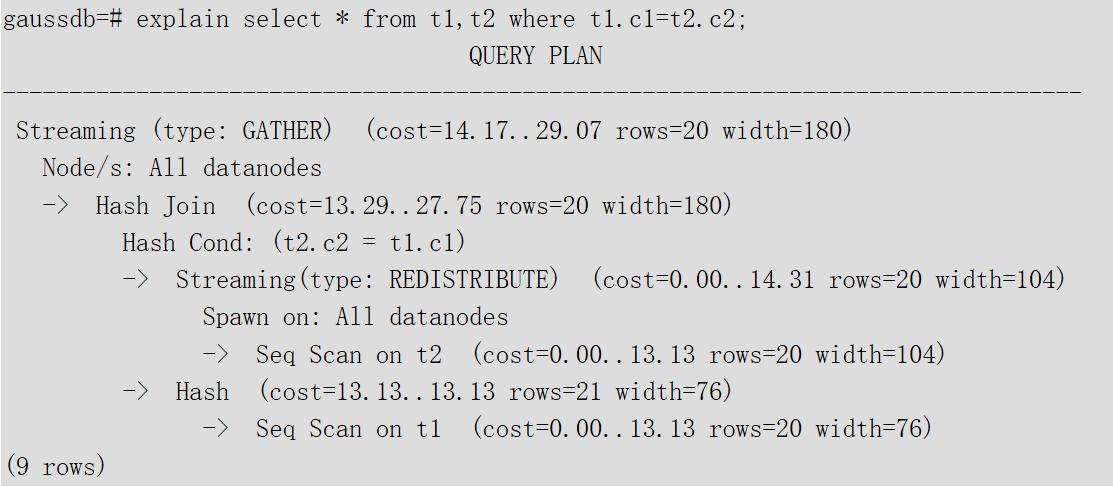
SELECT * FROM t1, t2 WHERE t1.c1 = t2.c2;執行EXPLAIN的輸出為:

2.1.5?執行計劃字段解讀
1)??執行計劃字段解讀(橫向):
- id:執行算子節點編號。
- ?operation:具體的執行節點算子名稱。
Streaming是一個特殊的算子,實現了分布式架構的核心數據shuffle功能,Streaming共有三種形態,分別對應了分布式結構下不同的數據shuffle功能:
○?Streaming(type: GATHER):作用是coordinator從DN收集數據。
○?Streaming(type: REDISTRIBUTE):作用是DN根據選定的列把數據重分布到所有的DN。
○?Streaming(type: BROADCAST):作用是把當前DN的數據廣播給其他所有的DN。
- E-rows:每個算子估算的輸出行數。
- ?E-memory:DN上每個算子估算的內存使用量,只有DN上執行的算子會顯示。
某些場景會在估算的內存使用量后使用括號顯示該算子在內存資源充足下可以自動擴展的內存上限。需要開啟enable_dynamic_workload參數后開啟內存使用量估算,且存在估算值大于0的算子時才會顯示該字段。
- E-width:每個算子輸出元組的估算寬度。
- ?E-costs:每個算子估算的執行代價。
○?E-costs是優化器根據成本參數定義的單位來衡量的,習慣上以磁盤頁面抓取為1個單位,其他開銷參數將參照它來設置。
○?每個節點的開銷(E-costs值)包括它的所有子節點的開銷。
○?開銷只反映了優化器關心的問題,并沒有把結果行傳遞給客戶端的時間考慮進去。雖然這個時間可能在實際的總時間里占據相當重要的分量,但是被優化器忽略了,因為它無法通過修改規劃來改變。
2)??執行計劃層級解讀(縱向):
- 第一層:Seq Scan on t2
表掃描算子,用Seq Scan的方式掃描表t2。這一層的作用是把表t2的數據從buffer或者磁盤上讀上來輸送給上層節點參與計算。
- 第二層:Hash
Hash算子,作用是把下層計算輸送上來的算子計算hash值,為后續hash join操作進行數據準備。
- ?第三層:Seq Scan on t1
表掃描算子,用Seq Scan的方式掃描表t1。這一層的作用是把表t1的數據從buffer或者磁盤上讀上來輸送給上層節點參與hash join計算。
- 第四層:Hash Join
join算子,主要作用是將t1表和t2表的數據通過hash join的方式連接,并輸出結果數據。
說明:
最頂層算子為Data Node Scan時,需要設置enable_fast_query_shipping為off才能看到具體的執行計劃,如下計劃:
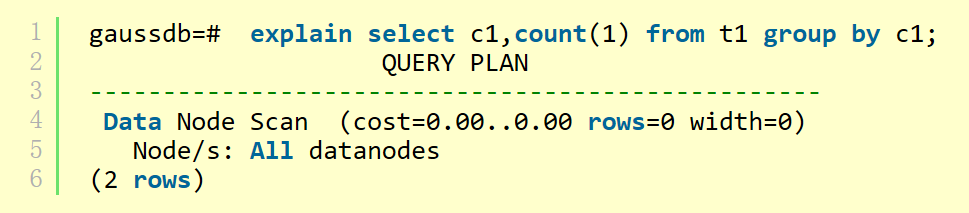
設置enable_fast_query_shipping參數之后,執行計劃顯示如下:

3)?執行計劃中的主要關鍵字說明:
a)表訪問方式
- Seq Scan
全表順序掃描。
- Index Scan
優化器決定使用兩步的規劃:最底層的規劃節點訪問一個索引,找出匹配索引條件的行的位置,然后上層規劃節點真實地從表中抓取出那些行。獨立地抓取數據行比順序地讀取開銷高很多,但是因為并非所有表的頁面都被訪問了,這么做實際上仍然比一次順序掃描開銷要少。使用兩層規劃的原因是,上層規劃節點在讀取索引標識出來的行位置之前,會先將它們按照物理位置排序,這樣可以最小化獨立抓取的開銷。
如果在WHERE語句中的存在多個字段上都有索引,那么優化器可能會使用索引的AND或OR的組合。
索引掃描可以分為以下幾類,差異在于索引的排序機制。
○?Bitmap Index Scan
使用位圖索引抓取數據頁。
○?Index Scan using?index_name
使用簡單索引搜索,該方式按照索引鍵的順序在索引表中抓取數據。該方式最常用于在大數據量表中只抓取少量數據的情況,或者通過ORDER BY條件匹配索引順序的查詢,以減少排序時間。
○?Index-Only Scan
當需要的所有信息都包含在索引中時,僅索引掃描便可獲取所有數據,不需要引用表。
- Bitmap Heap Scan
從其他操作創建的位圖中讀取頁面,過濾掉不符合條件的行。位圖堆掃描可避免隨機I/O,加快讀取速度。
- TID Scan
通過TupleID掃描表。
- Index?Ctid?Scan
通過Ctid上的索引對表進行掃描。
- CTE Scan
CTE對子查詢的操作進行評估并將查詢結果臨時存儲,相當于一個臨時表。CTE Scan算子對該臨時表進行掃描。
- Foreign Scan
從遠程數據源讀取數據。
- Function Scan
獲取函數返回的結果集,將它們作為從表中讀取的行并返回。
- ?Sample Scan
查詢并返回采樣數據。
- ?Subquery Scan
讀取子查詢的結果。
- ?Values Scan
作為VALUES命令的一部分讀取常量。
- WorkTable?Scan
工作表掃描。在操作中間階段讀取,通常是使用WITH RECURSIVE聲明的遞歸操作。
b) 表連接方式
- ?Nested Loop
嵌套循環,適用于被連接的數據子集較小的查詢。在嵌套循環中,外表驅動內表,外表返回的每一行都要在內表中檢索找到它匹配的行,因此整個查詢返回的結果集不能太大(不能大于10000),要把返回子集較小的表作為外表,而且在內表的連接字段上建議要有索引。
- (Sonic) Hash Join
哈希連接,適用于數據量大的表連接方式。優化器使用兩個表中較小的表,利用連接鍵在內存中建立hash表,然后掃描較大的表并探測散列,找到與散列匹配的行。Sonic和非Sonic的Hash Join的區別在于所使用hash表結構不同,不影響執行的結果集。
- Merge Join
歸并連接,通常情況下執行性能差于哈希連接。如果源數據已經被排序過,在執行歸并連接時,并不需要再排序,此時歸并連接的性能優于哈希連接。
c) 運算符
- ?sort
對結果集進行排序。
- ?filter
EXPLAIN輸出顯示WHERE子句當作一個"filter"條件附屬于順序掃描計劃節點。這意味著規劃節點為它掃描的每一行檢查該條件,并且只輸出符合條件的行。因為有WHERE子句,預計的輸出行數降低了。不過,掃描仍將必須訪問所有 10000 行,因此開銷沒有降低,實際上還增加了(確切的說,通過10000 * cpu_operator_cost)以反映檢查WHERE條件的額外CPU時間。
- ?LIMIT
LIMIT限定了執行結果的輸出記錄數。如果增加了LIMIT,那么不是所有的行都會被檢索到。
- ?Append
合并子操作的結果。
- ?Aggregate
將查詢行產生的結果進行組合。可以是GROUPBY、UNION、SELECT DISTINCT子句等函數的組合。
- ?BitmapAnd
位圖的AND操作,通過該操作組成匹配更復雜條件的位圖。
- ?BitmapOr
位圖的OR操作,通過該操作組成匹配更復雜條件的位圖。
- ?Gather
將并行線程的數據匯總。
- ?Group
對行進行分組,以進行GROUP BY操作。
- ?GroupAggregate
聚合GROUP BY操作的預排序行。
- Hash
對查詢行進行散列操作,以供父查詢使用。通常用于執行JOIN操作。
- ?HashAggregate
使用哈希表聚合GROUP BY的結果行。
- ?Merge Append
以保留排序順序的方式對子查詢結果進行組合,可用于組合表分區中已排序的行。
- ?ProjectSet
對返回的結果集執行函數。
- ?Recursive Union
對遞歸函數的所有步驟進行并集操作。
- SetOp
集合運算,如INTERSECT或EXCEPT。
- ?Unique
從有序的結果集中刪除重復項。
- HashSetOp
一種用于INTERSECT或EXCEPT等集合操作的策略,使用Append來避免預排序的輸入。
- ?LockRows
鎖定有問題的行以阻止其他查詢寫入,但允許讀。
- ?Materialize
將子查詢的結果存儲在內存里,以方便父查詢快速訪問獲取。
- ?Result
在不進行掃描的情況下返回一個值。
- WindowAgg
窗口聚合函數,一般由OVER語句觸發。
- ?Merge
歸并操作。
- StartWith?Operator
層次查詢算子,用于執行遞歸查詢操作。
- ?Rownum
對查詢結果的行編號進行條件過濾。通常出現在rownum子句里。
- ?Index Cond
索引掃描條件。
- ?Unpivot
轉置算子。
d) 分區剪枝相關信息
- ?Iterations
分區迭代算子對一級分區的迭代次數。如果顯示PART則為動態剪枝場景。
例如:Iterations:4表示迭代算子需要遍歷4個一級分區。Iterations:PART表示遍歷一級分區個數需要由分區鍵上的參數條件決定。
- ?Selected Partitions
一級分區剪枝的結果,m..n表示m到n號分區被剪枝選中,多個不連續的分區由逗號連接。
例如:Selected Partitions: 2..4,7表示2、3、4、7四個分區被選中。
e) 其他關鍵字
- ?Partitioned
對具體分區的操作。
- Partition Iterator
分區迭代器,通常代表子查詢是對分區的操作。
- InitPlan
非相關子計劃。
- Remote Query
下推到數據節點上的查詢語句。
- ?Exec Nodes
具體執行計劃的節點。
- ?Data Node Scan on
說明語句已下推給DN執行。
f)??執行信息
在SQL調優過程中經常需要執行EXPLAIN ANALYZE或EXPLAIN PERFORMANCE查看SQL語句實際執行信息,通過對比實際執行與優化器估算之間的差別來為優化提供依據。EXPLAIN PERFORMANCE相對于EXPLAIN ANALYZE增加了每個DN上的執行信息。
以如下SQL語句為例:
select count(*) from t1;執行EXPLAIN PERFORMANCE輸出為:
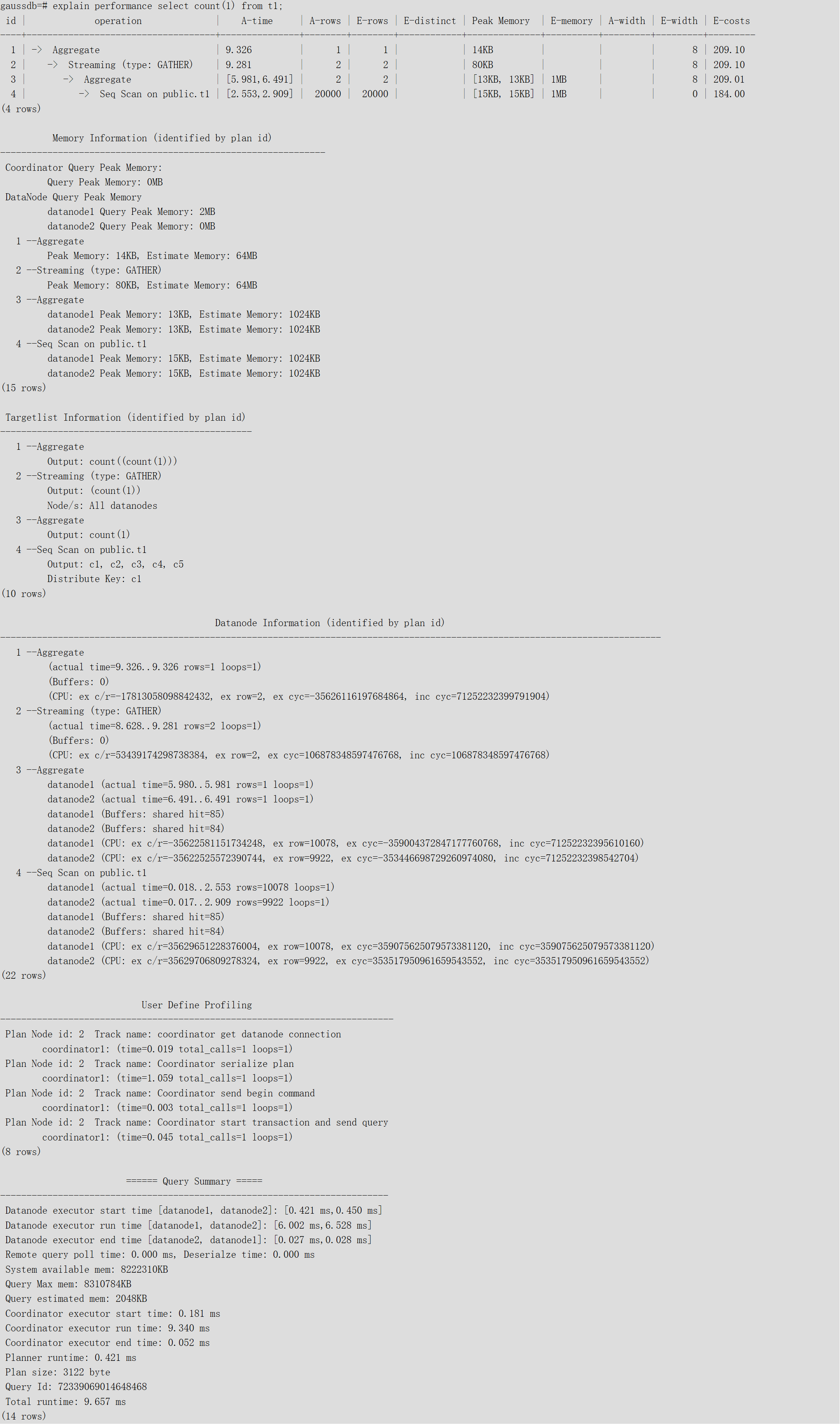
上述示例中顯示執行信息分為以下7個部分:
- ?計劃顯示
以表格的形式將計劃顯示出來,包含有11個字段,分別是:id、operation、A-time、A-rows、E-rows、E-distinct、Peak Memory、E-memory、A-width、E-width和E-costs。其中計劃類字段(id、operation以及E開頭字段)的含義與執行EXPLAIN時的含義一致,請參見執行計劃?小節中的說明。A-time、A-rows、E-distinct、Peak Memory、A-width的含義說明如下:
○?A-time:表示當前算子執行完成時間,一般DN上執行的算子的A-time是由[]括起來的兩個值,分別表示此算子在所有DN上完成的最短時間和最長時間。
○?A-rows:表示當前算子的實際輸出元組數。
○?E-distinct:表示hashjoin算子的distinct估計值。
○?Peak Memory:此算子在每個DN上執行時使用的內存峰值。
○?A-width:表示當前算子每行元組的實際寬度,僅對于重內存使用算子會顯示,包括:(Vec)HashJoin、(Vec)HashAgg、(Vec)?HashSetOp、(Vec)Sort、(Vec)Materialize算子等,其中(Vec)HashJoin計算的寬度是其右子樹算子的寬度,會顯示在其右子樹上。
- ?Predicate Information (identified by plan id):
這一部分主要顯示的是靜態信息,即在整個計劃執行過程中不會變的信息,主要是一些join條件和一些filter信息。
- ?Memory Information (identified by plan id):
這一部分顯示的是整個計劃中會將內存的使用情況打印出來的算子的內存使用信息,主要是Hash、Sort算子,包括算子峰值內存(peak memory),控制內存(control memory),估算內存使用(operator memory),執行時實際寬度(width),內存使用自動擴展次數(auto spread num),是否提前下盤(early spilled),以及下盤信息,包括重復下盤次數(spill Time(s)),內外表下盤分區數(inner/outer partition spill num),下盤文件數(temp file num),下盤數據量及最小和最大分區的下盤數據量(written disk IO [min, max] )。
- Targetlist?Information (identified by plan id)
這一部分顯示的是每一個算子輸出的目標列。
- DataNode?Information (identified by plan id)
這一部分會將各個算子的執行時間、CPU、buffer的使用情況全部打印出來。
- User Define Profiling
這一部分顯示的是CN和DN、DN和DN建連的時間,以及存儲層的一些執行信息。
- ====== Query Summary =====
這一部分主要打印總的執行時間和網絡流量,包括了各個DN上初始化和結束階段的最大最小執行時間、CN上的初始化、執行、結束階段的時間,以及當前語句執行時系統可用內存、語句估算內存等信息。
說明:
- rows和E-rows的差異體現了優化器估算和實際執行的偏差度。一般來說,偏差越大,優化器生成的計劃越不可信,人工干預調優的必要性越大。
- time中的兩個值偏差越大,表明此算子的計算偏斜(在不同DN上執行時間差異)越大,人工干預調優的必要性越大。
- Max Query Peak Memory經常用來估算SQL語句耗費內存,也被用來作為SQL語句調優時運行態內存參數設置的重要依據。一般會以EXPLAIN ANALYZE或EXPLAIN?PERFORMANCE的輸出作為進一步調優的輸入。
2.2?explain使用事項
在指定ANALYZE選項時,語句會被執行。如果用戶想使用EXPLAIN分析INSERT,UPDATE,DELETE,CREATE TABLE AS或EXECUTE語句,而不想改動數據(執行這些語句會影響數據),請使用如下方法。
START TRANSACTION;
EXPLAIN ANALYZE ...;
ROLLBACK;3?總結
使用EXPLAIN命令可以查看優化器為每個查詢生成的具體執行計劃。EXPLAIN給每個執行節點都輸出一行,顯示基本的節點類型和關注優化器為執行這個節點預計的開銷值。
)


















)