一、介紹
這篇文章主要是針對目標檢測框架的攻擊,不同于現有的攻擊方法,該論文主要的側重點是考慮視角的變化問題,通過在車上布置多個顯示器,利用視角動態選擇哪一個顯示器播放攻擊內容,通過這種方法達到隱蔽與攻擊的兼顧。
二、方法
文章的威脅模型假定攻擊者對被攻擊的模型有完全的了解,即白盒攻擊。攻擊分為兩種情況:物體靜止相機移動和物體移動相機靜止。理想情況應該是有一個外部設備來實時確定被攻擊者與攻擊者的位置關系,但是這里為了簡化實驗,選擇的是由實驗者控制相機和攻擊車輛的位置關系。
攻擊的方法依然遵循原來的套路,采用疊加擾動并使模型性能下降的方法。這里選擇的被攻擊模型是YOLOV2,訓練時手動標記顯示器的位置并疊加圖像,為了考慮到現實場景下的變化,作者在疊加圖像的過程中隨機給圖像增加了亮度和對比度上的調整。

損失函數部分,考慮到目標檢測模型實際上存在兩個關鍵的指標:包圍框和類別。這里作者設計了三種損失項:類別、物體以及交叉項。類別是只考慮類別損失,增大預測的類別與真實值之間的差異,同時作者還增加了一個語義類別,簡單來說就是盡量不讓車被誤識別為自行車、卡車,而是被誤識別為道路、樹木等雜七雜八的東西。

物體項則是盡量降低目標檢測結果的“置信度”這一項指標,當置信度過低時模型會認為該物體是錯誤的,從而直接過濾掉這一物體。
除此之外,作者也引入了平滑度的項,用于優化攻擊的內容,減小矚目性。

作者并沒有使用顯示器的NPS損失,最后的優化函數只包含兩個損失項:
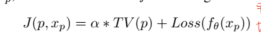
)







案例)










