官網支持python,curl和node.js
 ?
?
因為服務器剛好有php環境,所以先用curl調個普通的語音溝通api
<?php
// 定義 API Key 和請求地址
define('MOONSHOT_API_KEY', 'sk-PXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXgk1');
define('MOONSHOT_API_URL', 'https://api.moonshot.cn/v1/chat/completions');// 設置請求頭
$headers = ['Content-Type: application/json','Authorization: Bearer ' . MOONSHOT_API_KEY,
];// 設置請求體
$data = ['model' => 'moonshot-v1-8k','messages' => [['role' => 'system','content' => '你是我的靈緹寵物犬,名字叫做小羊,今年兩歲。',],['role' => 'user','content' => '在嗎?給我講個小故事?',],],'temperature' => 0.3,
];// 初始化 cURL 會話
$ch = curl_init();// 設置 cURL 選項
curl_setopt($ch, CURLOPT_URL, MOONSHOT_API_URL);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);// 執行 cURL 會話
$response = curl_exec($ch);// 檢查是否有錯誤發生
if (curl_errno($ch)) {echo 'cURL 錯誤: ' . curl_error($ch);
} else {// 打印響應內容echo 'API 響應: ' . $response;
}// 關閉 cURL 會話
curl_close($ch);
?>返回結果很不錯

==================================================
下來才是這篇文章測試的關鍵,測試多模態也就是云端圖片內容識別
然而我用php調用file api時候,會提示我圖片無法解析,所以先跑起來官方的python試試
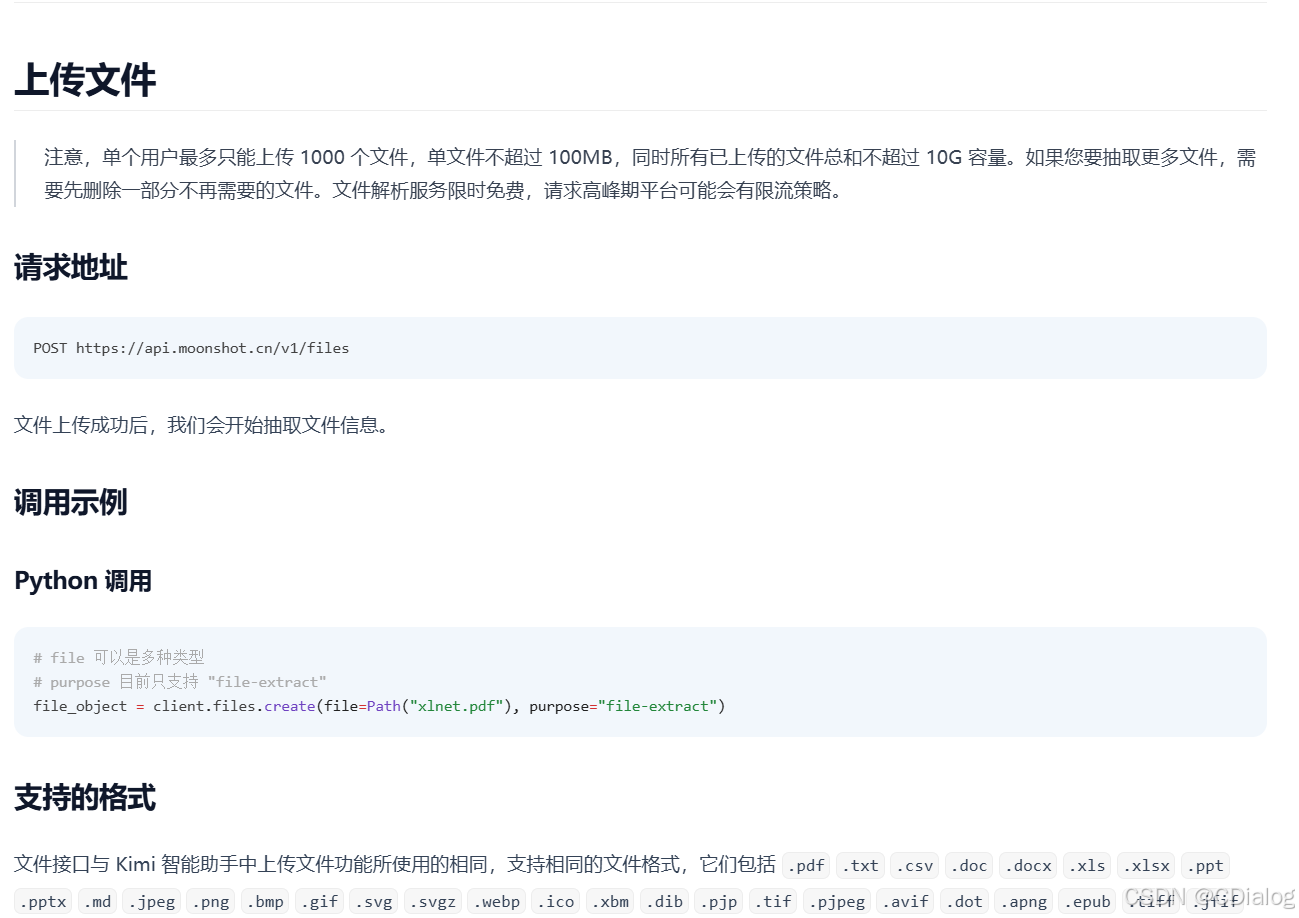
這個是官方示例
from pathlib import Path
from openai import OpenAIclient = OpenAI(api_key = "$MOONSHOT_API_KEY",base_url = "https://api.moonshot.cn/v1",
)# xlnet.pdf 是一個示例文件, 我們支持 pdf, doc 以及圖片等格式, 對于圖片和 pdf 文件,提供 ocr 相關能力
file_object = client.files.create(file=Path("xlnet.pdf"), purpose="file-extract")# 獲取結果
# file_content = client.files.retrieve_content(file_id=file_object.id)
# 注意,之前 retrieve_content api 在最新版本標記了 warning, 可以用下面這行代替
# 如果是舊版本,可以用 retrieve_content
file_content = client.files.content(file_id=file_object.id).text# 把它放進請求中
messages = [{"role": "system","content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅長中文和英文的對話。你會為用戶提供安全,有幫助,準確的回答。同時,你會拒絕一切涉及恐怖主義,種族歧視,黃色暴力等問題的回答。Moonshot AI 為專有名詞,不可翻譯成其他語言。",},{"role": "system","content": file_content,},{"role": "user", "content": "請簡單介紹 xlnet.pdf 講了啥"},
]# 然后調用 chat-completion, 獲取 Kimi 的回答
completion = client.chat.completions.create(model="moonshot-v1-32k",messages=messages,temperature=0.3,
)print(completion.choices[0].message)跑下來結果需要安裝python openai模塊

那就裝吧
pip install openai其中碰到有個要升級的,升級
好了,安裝成功了

回到代碼執行位置
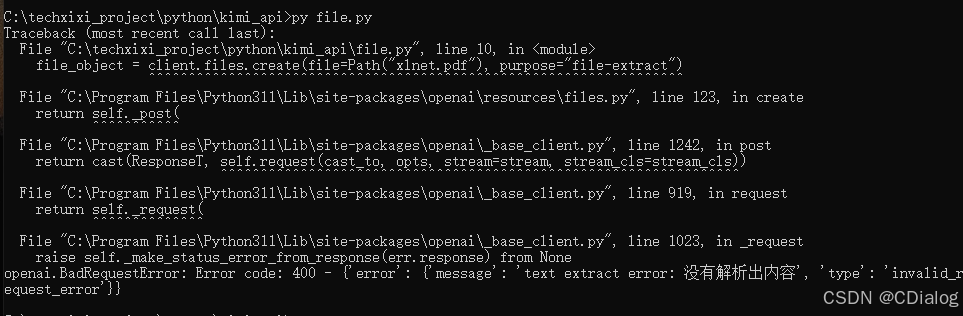
哎,和我的php代碼沒啥區別嘛,都是返回沒有解析出內容。尷尬了。。。
換圖片試試看吧,這張圖我直接丟給kimi網頁版,是可以解析的啊~~~ 奇怪奇怪奇怪
openai.BadRequestError: 這里看到返回一個錯誤號400
去官網查一下吧。

看到官網有個官方kimi api調試工具,老老實實試一下吧
https://github.com/MoonshotAI/moonpalace/releases![]() https://github.com/MoonshotAI/moonpalace/releases
https://github.com/MoonshotAI/moonpalace/releases
這里搞個windows版吧
下載后原來是個命令行工具
這個先放一邊,我又發現在新手指南里有個vision的api

尼瑪,為啥不放在上面api列表,而是放在這里,好吧,看到的晚了。
試了一下,果然可以,沒毛病,看來文件api是不可以做內容識別的,暫時這么理解吧,需要專門的vision這個視覺模型,而官網的自動識別可以自動去調用,這么就說的通了
再往下看,還有個自動選擇kimi模型的條目
這些就后面大家有興趣再去研究吧,反正我的圖片內容識別已經搞定了,這篇文章功德圓滿,后續繼續其他工作了。
bye~~





案例)












)
