OpenAI 發布 ChatGPT 已經1年多了,生成式人工智能(AIGC)也已經廣為人知,我們常常津津樂道于 ChatGPT 和 Claude 這樣的人工智能系統能夠神奇地生成文本與我們對話,并且能夠記憶上下文情境。
GPT-4多模態分析對話
Midjunery和DALL·E 這樣的AI繪圖軟件可以通過Prompt 輸入文本提示生成多張令人驚艷的美圖,看起來相當神奇。

Midjunery V6
但是,你有沒有想過,生成式人工智能(AIGC)究竟是怎么運作的呢?在這篇文章里,我們就來簡單了解一下生成式人工智能技術(AIGC)的基本原理,看看它到底能做些什么,還有啥時候你可能不太想依賴它。"
😝有需要的小伙伴,可以V掃描下方二維碼免費領取🆓
 一、**從有監督學習到生成式人工智能**
一、**從有監督學習到生成式人工智能**
大多數傳統類型的人工智能(如判別式人工智能)都是為了對現有數據進行分類或歸類而設計的。相反,生成式人工智能模型的目標是生成前所未見的完全原創的人工制品。
在今天,有監督學習(Supervised Learning)和生成式人工智能(Generative Artificial Intelligence)是當今人工智能領域的兩個最重要領域,其重點是創建算法和模型,以便從訓練數據集生成與模式相似的新的真實數據。

AI 學習框架
生成式人工智能模型經過訓練,可以從龐大的數據集中學習其中的潛在模式,并使用該知識生成與原始數據集相似但不相同的全新樣本或數據。

Midjunery V6 生成的人像
例如,在人類或者貓狗的圖像數據集上訓練的生成式人工智能算法可以生成全新的人類圖像或者貓和狗的圖像,這些圖像看起來與原始數據集中的圖像相似,但不是精確的復制品。因此,"生成 "一詞被用來描述它。
生成式人工智能(Generative AI)的涌現標志著人工智能技術的重大進步。
1.1 有監督學習的局限性與挑戰
在2010年左右,隨著大規模有監督學習逐漸成為主流,人們開始寄希望于大數據能夠為AI模型的性能帶來質的飛躍。
然而,從那時起,AI 科學家們開始觀察到一個令人困擾的問題:盡管我們有大量的數據可供使用,但即使我們向小型AI模型繼續提供更多的數據,它們的性能改善并不明顯。
例如,在構建語音識別系統時,盡管AI接受了數千乃至數十萬小時的訓練數據,但其準確性與僅使用少量數據的系統相比并無顯著提高。這一現象引發了人們對監督學習有效性的懷疑。
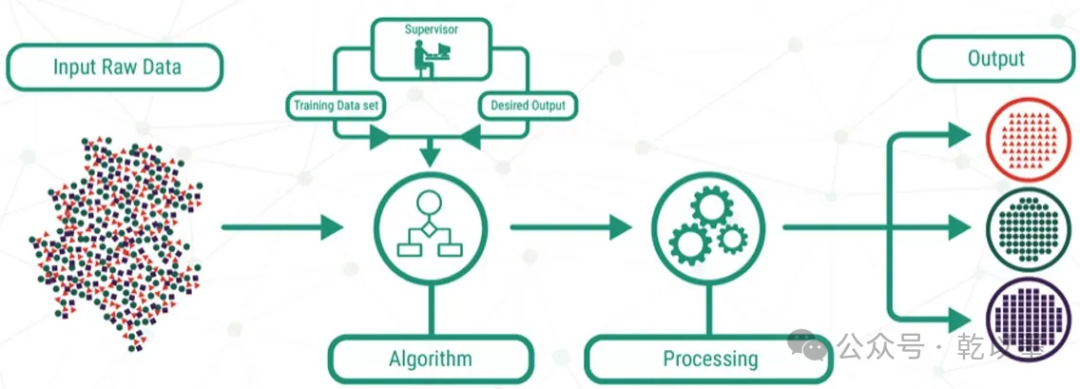
有監督學習的基本流程
進一步的研究表明,僅靠大規模監督學習和大數據集并不能無限地提升 AI 模型的準確性。
這是因為:
- ? 首先,大規模數據集可能存在著標簽噪聲或錯誤,導致模型學習到了不準確的模式。
- ? 此外,數據可能存在偏差,導致模型在面對新穎數據時表現不佳。
- ? 其次,隨著數據量的增加,模型的容量可能變得不足以有效地利用數據。即使有更多的數據可用,模型也可能因其結構或參數的限制而無法充分利用這些信息。
- ? 再次,大規模監督學習通常依賴于端到端的訓練方法,其中模型直接從輸入到輸出進行訓練。這種方法可能會導致模型在理解數據背后的真實機制方面缺乏深入的抽象能力,從而限制了其性能。
1.2 生成式人工智能的出現
隨著人們對監督學習的限制和挑戰有了更深入的認識,研究人員開始尋求其他方法來克服這些問題。在這個過程中,生成式人工智能(Generative Artificial Intelligence)應運而生,并逐漸成為人工智能領域的重要組成部分。
生成式人工智能(AIGC)與傳統的機器學習算法不同,它不僅僅局限于對已有數據的分類或預測,而是可以通過學習數據的分布,創造出全新的、以前從未見過的內容,它能夠像一座神奇的創意工廠一樣,通過Prompt 提示詞不斷地生產出令人驚嘆的全新數據、圖像、音頻和文本內容。
生成式人工智能與其他類型人工智能之間的另一個關鍵區別是,生成式人工智能模型通常使用無監督和半監督機器學習算法。
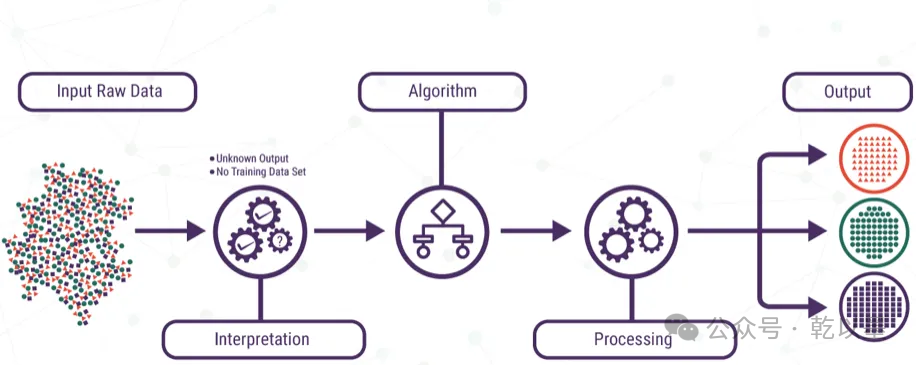
無監督學習的基本流程
這意味著它們不需要對學習的數據進行預先標記,這使得生成式人工智能在結構化或組織數據稀缺或難以獲取的應用中特別有用。
- ? 這些生成式人工智能系統通常基于深度學習模型構建,這些模型能夠從大量的訓練數據中學習數據的統計結構和語義信息。
- ? 其次,生成式模型具有更強的表達能力,能夠捕捉數據中的復雜結構和分布。相比之下,傳統的監督學習方法可能會受到數據標簽的限制,無法完全表達數據的多樣性和復雜性。
- ? 此外,生成式人工智能還為解決監督學習中的標簽噪聲和數據偏差問題提供了新的途徑。通過學習數據的潛在表示,生成式模型可以更好地理解數據背后的真實機制,從而提高模型對噪聲和偏差的魯棒性。
生成式人工智能的出現為人工智能領域帶來了新的思路和解決方案,克服了傳統監督學習方法的一些限制和挑戰。通過結合生成式方法和傳統的監督學習技術,我們可以更好地利用數據,提高模型的性能和泛化能力。
二、生成式人工智能的思想
2.1 生成式人工智能的基本工作原理:
生成式人工智能的基本工作原理是通過學習數據的分布特征,從而能夠生成與原始數據相似的新數據。其核心思想是從訓練數據中學習數據的概率分布,并使用學習到的分布模型來生成新的數據樣本。
生成式人工智能通常采用生成對抗網絡(GANs)或變分自編碼器(VAEs)、Transformer 等模型來實現。
就拿生成對抗網絡(GANs)來說,GANs 模型包括兩個主要組成部分:

生成對抗網絡工作機制(GANs)
1. 生成器(Generator): 生成器是一個神經網絡模型,用來接收一個隨機噪聲向量或其他形式的輸入,并將其映射到數據空間。生成器的目標是通過根據用戶輸入的分析數據模式來創建新數據。通過不斷調整生成器的參數,使得生成的樣本盡可能地接近真實場景中的數據分布。
2. 判別器(Discriminator): 判別器也是一個神經網絡模型,其任務是對生成器生成的樣本與真實數據進行區分,估計樣本來自于訓練數據的概率。它接收來自生成器產生的樣本和真實數據的輸入,并嘗試將它們分類為真實或偽造。判別器的目標是最大化正確地將真實數據分類為真實樣本,同時將生成的樣本正確分類為偽造樣本。
每當有用戶輸入時,生成器就會生成新的數據,判別器將分析它的真實性。來自判別器的反饋使算法能夠調整生成器參數并不斷地重新調整和細化輸出。
在數學上可以證明,在任意函數的生成器(G)和判別器(D)空間中,存在唯一的解決方案,使得生成器(Generator)生成的內容可以重現真實訓練數據的分布,也就是當判別器 D=0.5 時,生成器 G 產生的信息與輸入的信息達到平衡。
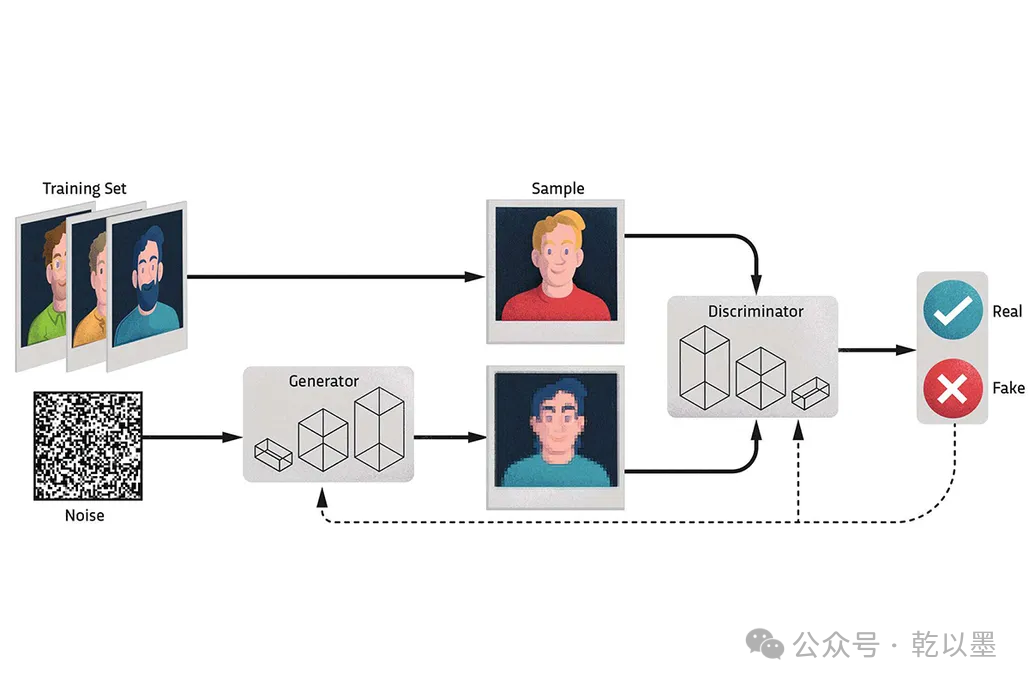
生成對抗網絡的工作過程
通過訓練生成器和判別器的對抗過程,生成式人工智能模型不斷地提高生成樣本的質量,使得生成的樣本更加逼真,并且與真實數據的分布更加接近。
這種對抗性訓練的過程使得生成器和判別器之間達到一種平衡,最終這個過程一直持續到生成器產生與輸入信息無法區分的數據為止。
2.2 生成式人工智能的工作過程
生成式人工智能的工作過程通常如下:

生成式AI的工作過程
- \1. 學習數據分布:生成式模型首先通過大量的訓練數據學習輸入數據的分布。這些數據可以是圖像、文本、音頻等形式。模型通過學習數據的特征和統計分布來理解輸入數據的內在規律。
- \2. 生成新數據:一旦生成式模型學習到了數據的分布,它就可以通過隨機采樣或輸入特定的條件來生成新的數據。生成的數據可能具有與訓練數據相似的統計特性和結構,但通常是全新的、之前未見過的數據。
- \3. 優化過程:生成式模型的訓練通常涉及到一個優化過程,通過最小化生成數據與真實數據之間的差異來調整模型參數。對抗性生成網絡(GANs)中使用了對抗訓練的思想,包括生成器和判別器兩個部分,它們相互競爭并共同提高模型的性能。
- \4. 控制生成過程:一些生成式模型允許用戶在生成新數據時提供一些條件或控制參數,以影響生成結果。例如,在生成圖像時可以指定生成的圖像類別或風格,或者在生成文本時可以指定生成的主題或情感。
- \5. 評估生成結果:生成式模型通常需要經過一定的評估和調優來確保生成的數據質量和多樣性。這可能涉及到定量指標如生成數據的多樣性、真實度等,以及定性評估如人工評價生成數據的質量和逼真度。
- 然后通過一個稱為 "推理 "的過程來完善輸出。在推理過程中,模型會調整其輸出,以更好地匹配所需的輸出或糾正任何錯誤。這樣就能確保生成的輸出更加逼真,更符合用戶希望看到的效果。
三、如何評估生成式人工智能模型
選擇正確的模型對于某些特定的任務至關重要,因為每個任務都有其獨特的需求和目標,而不同的生成式人工智能模型也各有其優缺點。
比如,某一些模型可能比較擅長生成高質量的圖像內容,而另一些模型則更擅長生成順暢連貫的文本內容。
因此在選擇時,需要重視對生成模型進行評估以確定最適合特定任務的模型。這種評估不僅有助于選擇正確的模型,還有助于確定需要改進的方面。
通過這種方式,可以完善模型并增加實現預期結果的可能性,從而提高人工智能系統的整體成功率。
在評估模型時,通常需要考慮三個關鍵要素:

評估模型的三要素
- \1. Quality 質量:生成式模型的輸出質量至關重要,尤其是在直接與用戶交互的應用程序中。
- 例如,在文本生成模型中,前言不搭后語的文本可能會讓人感覺一團糟,在語音生成模型中,低質量的語音可能會讓人聽不懂;而在圖像生成模型中,生成的圖像最好是能夠做到渾然天成,和真實的圖像無法區分。
- \2. Diversity 多樣性:優秀的生成式模型應該能夠捕獲數據分布中的各種模式,而不會降低生成的質量。這種多樣性有助于減少模型中不必要的偏差。
- \3. Speed 速度:許多交互式應用程序需要快速生成結果,例如實時圖像編輯,以支持內容創建的工作流程。因此,在評估生成模型時,生成的速度也是一個重要的考量因素。
如何系統的去學習大模型LLM ?
作為一名熱心腸的互聯網老兵,我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。
但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的 AI大模型資料 包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。
😝有需要的小伙伴,可以V掃描下方二維碼免費領取🆓

一、全套AGI大模型學習路線
AI大模型時代的學習之旅:從基礎到前沿,掌握人工智能的核心技能!

二、640套AI大模型報告合集
這套包含640份報告的合集,涵蓋了AI大模型的理論研究、技術實現、行業應用等多個方面。無論您是科研人員、工程師,還是對AI大模型感興趣的愛好者,這套報告合集都將為您提供寶貴的信息和啟示。

三、AI大模型經典PDF籍
隨著人工智能技術的飛速發展,AI大模型已經成為了當今科技領域的一大熱點。這些大型預訓練模型,如GPT-3、BERT、XLNet等,以其強大的語言理解和生成能力,正在改變我們對人工智能的認識。 那以下這些PDF籍就是非常不錯的學習資源。


四、AI大模型商業化落地方案

階段1:AI大模型時代的基礎理解
- 目標:了解AI大模型的基本概念、發展歷程和核心原理。
- 內容:
- L1.1 人工智能簡述與大模型起源
- L1.2 大模型與通用人工智能
- L1.3 GPT模型的發展歷程
- L1.4 模型工程
- L1.4.1 知識大模型
- L1.4.2 生產大模型
- L1.4.3 模型工程方法論
- L1.4.4 模型工程實踐
- L1.5 GPT應用案例
階段2:AI大模型API應用開發工程
- 目標:掌握AI大模型API的使用和開發,以及相關的編程技能。
- 內容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具類框架
- L2.1.4 代碼示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架應用現狀
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架與Thought
- L2.2.5 Prompt框架與提示詞
- L2.3 流水線工程
- L2.3.1 流水線工程的概念
- L2.3.2 流水線工程的優點
- L2.3.3 流水線工程的應用
- L2.4 總結與展望
階段3:AI大模型應用架構實踐
- 目標:深入理解AI大模型的應用架構,并能夠進行私有化部署。
- 內容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的設計理念
- L3.1.2 Agent模型框架的核心組件
- L3.1.3 Agent模型框架的實現細節
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的應用場景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特點
- L3.3.2 ChatGLM的開發環境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特點
- L3.4.2 LLAMA的開發環境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介紹
階段4:AI大模型私有化部署
- 目標:掌握多種AI大模型的私有化部署,包括多模態和特定領域模型。
- 內容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的關鍵技術
- L4.3 模型私有化部署的實施步驟
- L4.4 模型私有化部署的應用場景
學習計劃:
- 階段1:1-2個月,建立AI大模型的基礎知識體系。
- 階段2:2-3個月,專注于API應用開發能力的提升。
- 階段3:3-4個月,深入實踐AI大模型的應用架構和私有化部署。
- 階段4:4-5個月,專注于高級模型的應用和部署。
這份完整版的大模型 LLM 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】
😝有需要的小伙伴,可以Vx掃描下方二維碼免費領取🆓

)
)



)








)



