
前言
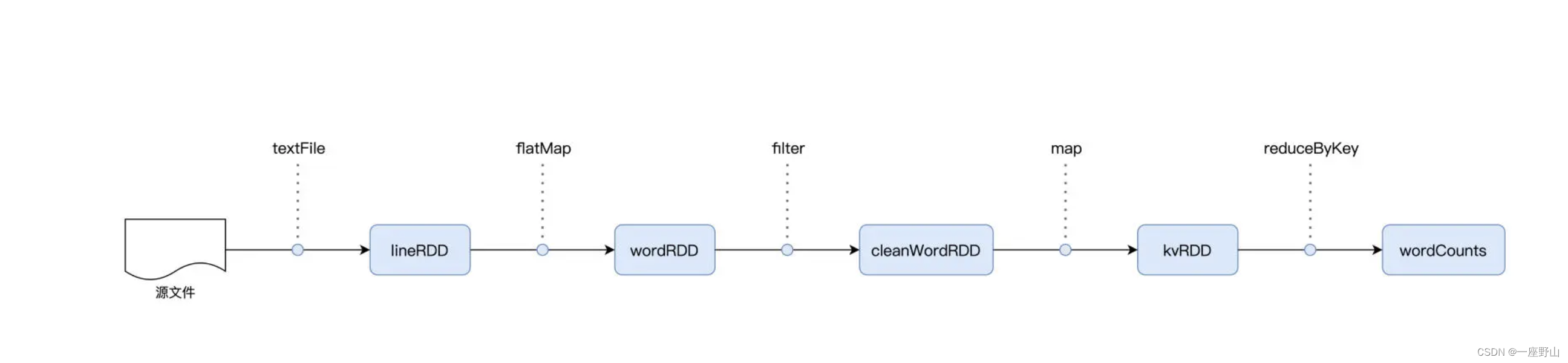
RDD 是 Spark 對于分布式數據集的抽象,每一個 RDD 都代表著一種分布式數據形態。比如 lineRDD,它表示數據在集群中以行(Line)的形式存在;而 wordRDD 則意味著數據的形態是單詞,分布在計算集群中。?

參數
參數是函數、或者返回值是函數的函數,我們把這類函數統稱為“高階函數”(Higher-order Functions)。換句話說,這 4 個算子,都是高階函數。?

?
import org.apache.spark.rdd.RDD
val rootPath: String = _
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 讀取文件內容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行為單位做分詞
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把RDD元素轉換為(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照單詞做分組計數
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印詞頻最高的5個詞匯
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)?
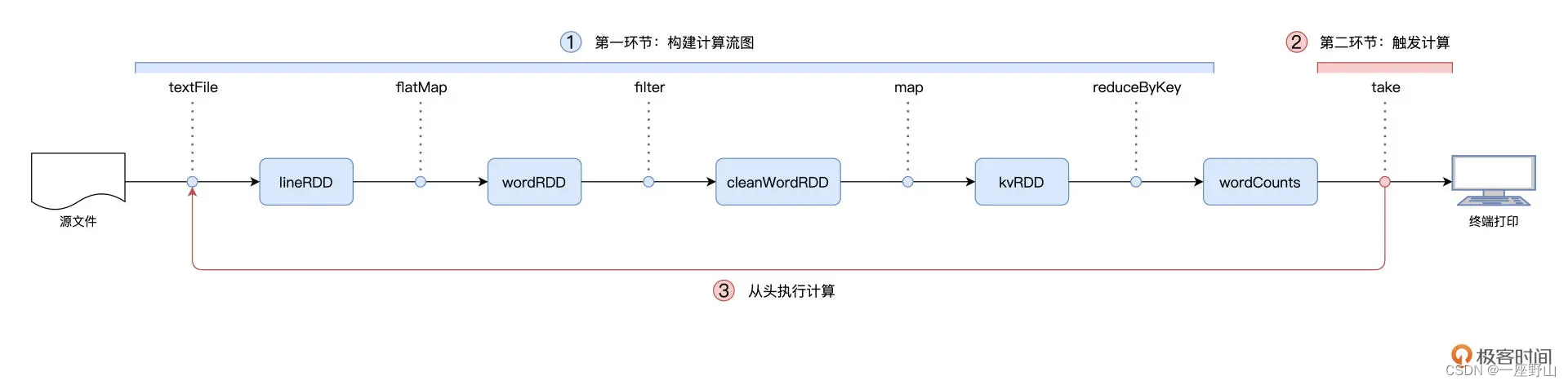
在 RDD 的編程模型中,一共有兩種算子,Transformations 類算子和 Actions 類算子。開發者需要使用 Transformations 類算子,定義并描述數據形態的轉換過程,然后調用 Actions 類算子,將計算結果收集起來、或是物化到磁盤。
換句話說,開發者調用的各類 Transformations 算子,并不立即執行計算,當且僅當開發者調用 Actions 算子時,之前調用的轉換算子才會付諸執行。在業內,這樣的計算模式有個專門的術語,叫作“延遲計算”(Lazy Evaluation)。延遲計算很好地解釋了本講開頭的問題:為什么 Word Count 在執行的過程中,只有最后一行代碼會花費很長時間,而前面的代碼都是瞬間執行完畢的呢?
 ?
?



與 關系型數據庫(RDBMS)的比較)




 - 專業創意軟件)







)


