文章目錄
- 1. 背景與挖掘目標
- 2. 分析方法與過程
- 3. 數據分析
- 3.1 數據探索分析
- 3. 2 數據預處理
- 1. 屬性約束
- 2. 劃分用水事件
- 3. 確定單次用水事件時長閾值
- 4. 屬性構造
- 5.篩選候選洗浴事件
- 3.3 模型構建
- 3.4 模型檢驗
- 4. 思考總結

1. 背景與挖掘目標
隨著國內大家電品牌的進入和國外品牌的涌入,電熱水器相關技術在過去20年間得到了快速發展,屢屢創新。
-
首次提出封閉式電熱水器的概念到水電分離技術的研發。
-
漏電保護技術的應用及出水斷電技術和防電墻技術專利的申請突破。
如今高效能技術顛覆了業內對電熱水器“高能耗”的認知。
-
當下的熱水器行業也并非一片太平盛世,行業內正在上演一幕弱肉強食的“叢林法則”戲碼,市場份額逐步向龍頭企業集中,尤其是那些在資金、渠道和品牌影響力等方面擁有實力的綜合家電品類巨頭,正在不斷蠶食鯨吞市場蛋糕。
-
要想在該行業立足,只能走產品差異化的路線,提升技術實力和產品質量,在功能賣點、外觀等方面做出自身特色。
-
在熱水器用戶行為分析過程中,用水事件識別是最為關鍵的環節。根據該熱水器生產廠商提供的數據熱水器用戶用水事件劃分與識別項目的整體目標如下。
-
根據熱水器采集到的數據,劃分一次完整用水事件。
-
在劃分好的一次完整用水事件中,識別出洗浴事件。
2. 分析方法與過程
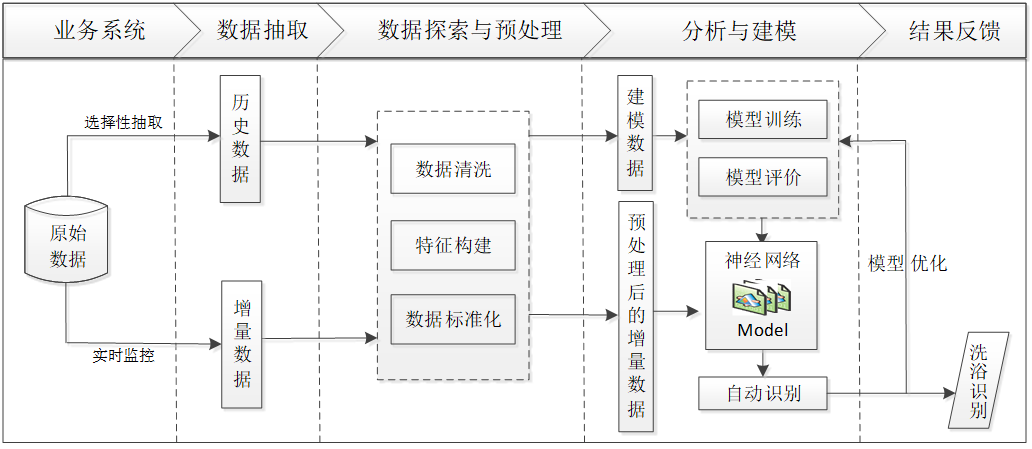
1.對熱水用戶的歷史用水數據進行選擇性抽取,構建專家樣本。
2.對步驟1形成的數據集進行數據探索分析與預處理,包括探索水流量的分布情況,刪除冗余屬性,識別用水數據的缺失值,并對缺失值作處理,根據建模的需要進行屬性構造等。根據以上處理,對用水樣本數據建立用水事件時間間隔識別模型和劃分一次完整的用水事件模型,再在一次完整用水事件劃分結果的基礎上,剔除短暫用水事件縮小識別范圍等。
3.在步驟2得到的建模樣本數據基礎上,建立洗浴事件識別模型,對洗浴事件識別模型進行模型分析評價。
4.對步驟3形成的模型結果應用并對洗浴事件劃分進行優化。
5.調用洗浴事件識別模型,對實時監控的熱水器流水數據進行洗浴事件自動識別。
3. 數據分析
3.1 數據探索分析
1.在熱水器的使用過程中,熱水器的狀態會經常發生改變,比如開機和關機、由加熱轉到保溫、由無水流到有水流、水溫由50℃變為49℃等。而智能熱水器在狀態發生改變或者水流量非零時,每兩秒會采集一條狀態數據。由于數據的采集頻率較高,并且數據來自大量用戶,數據總量非常大。
2.對原始數據采用無放回隨機抽樣法抽取200家熱水器用戶從2014年1月1日至2014年12月31日的用水記錄作為原始建模數據。
3.由于用戶不僅使用熱水器來洗浴,而且包括了洗手、洗臉、刷牙、洗菜、做飯等用水行為,所以熱水器采集到的數據來自各種不同的用水事件。
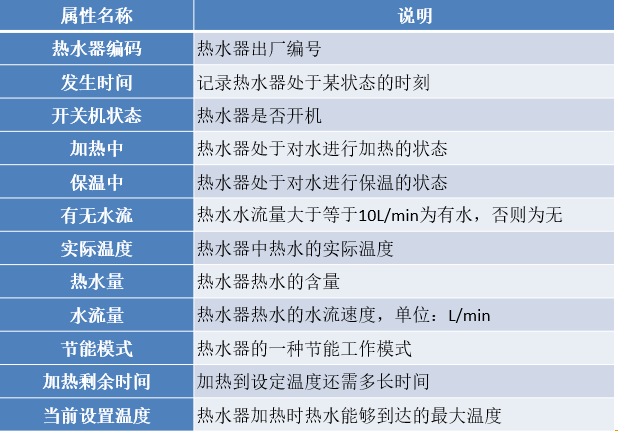
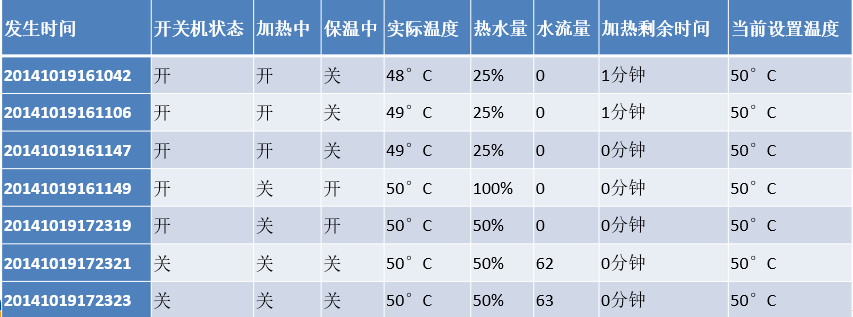
熱水器采集的用水數據包含12個屬性:熱水器編碼,發生時間,開關機狀態,加熱中,保溫中,有無水流,實際溫度,熱水量,水流量,節能模式,加熱剩余時間和當前設置溫度。其解釋說明下表所示。
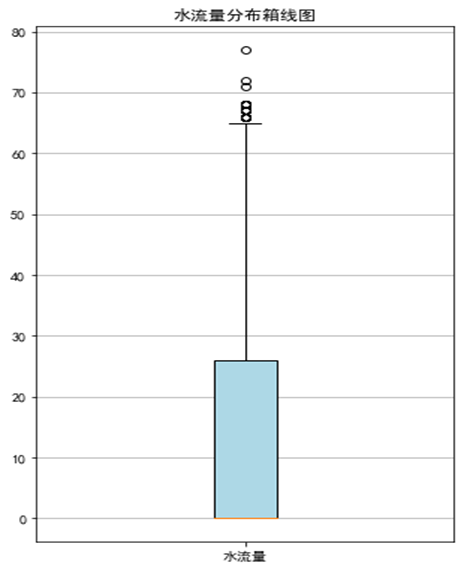
探索分析熱水器的水流量狀況,其中有無水流和水流量屬性最能直觀體現熱水器的水流量情況,對這兩個屬性進行探索分析,得到不同水流狀態的記錄的條形圖,無水流狀態的記錄明顯比有水流狀態的記錄要多

不同水流狀態的記錄的箱線圖,箱體貼近0,說明無水流量的記錄較多,水流量的分布與水流狀態的分布一致
用水停頓時間間隔定義為一條水流量不為0的流水記錄同下一條水流量不為0的流水記錄之間的時間間隔。
根據現場實驗統計,兩次用水的過程的用水停頓的間隔時長一般在不大于4分鐘。
為了探究用戶真實用水停頓時間間隔的分布情況,統計用水停頓的時間間隔并做頻率分布表。
通過頻率分布表分析用戶用水停頓時間間隔的規律性,具體的數據如下表所示。
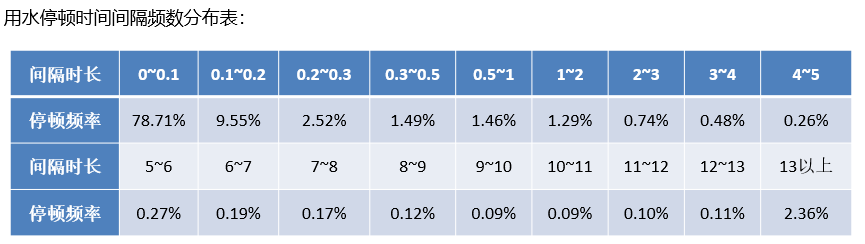
停頓時間間隔為00.3分鐘的頻率很高,根據日常用水經驗可以判斷其為一次用水時間中的停頓;停頓時間間隔為613分鐘的頻率較低,分析其為兩次用水事件之間的停頓間隔。
兩次用水事件的停頓時間間隔分布在3~7分鐘。根據現場實驗統計用水停頓的時間間隔近似。
3. 2 數據預處理
1. 屬性約束
由于熱水器采集的用水數據屬性較多,做以下處理,因分析的主要對象為用戶,分析的主要目標為用戶的洗浴行為的一般規律,所以“熱水器編號”屬性可以去除;因熱水器采集的數據中,“有無水流”屬性可以通過“水流量”屬性反應,“節能模式”屬性取值相同均為“關”,對分析無作用,可以去除。
刪除冗余屬性“熱水器編號”“有無水流”“節能模式”,刪除冗余屬性后得到用來建模的屬性如下表所示。
2. 劃分用水事件
用水狀態記錄中,水流量不為0表明用戶正在使用熱水;而水流量為0時用戶用熱水發生停頓或者用熱水結束。對于任一個用水記錄,如果它的向前時差超過閾值 ,則將它記為事件的開始編號;如果向后時差超過閾值 ,則將其記為事件的結束編號。劃分模型的符號說明如下表所示。

一次完整用水事件的劃分步驟如下。
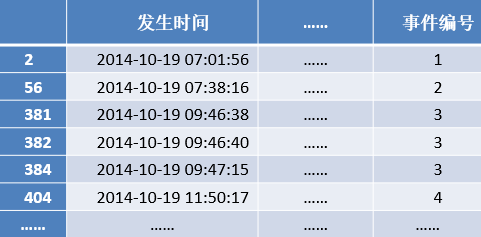
(1) 讀取數據記錄,識別到所有水流量不為0的狀態記錄,將它們的發生時間記為序列t1。
(2) 對序列t1構建其向前時差列和向后時差列,并分別與閾值進行比較。向前時差超過閾值T,則將它記為新的用水事件的開始編號;如果向后時差超過閾值T,則將其記為用水事件的結束編號。
循環執行步驟(2)直到向前時差列和向后時差列與均值比較完畢,結束事件劃分。
對用戶的用水數據進行劃分結果如下表所示。
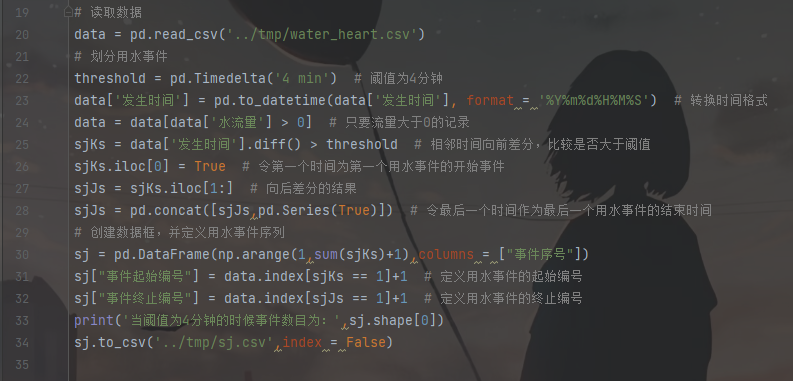
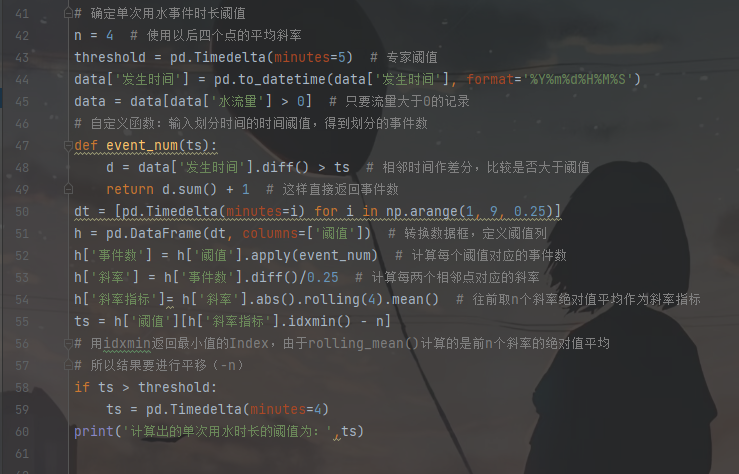
3. 確定單次用水事件時長閾值
對某熱水器用戶的數據根據不同的閾值劃分用水事件,得到了相應的事件個數,閾值變化與劃分得到事件個數如下表所示。
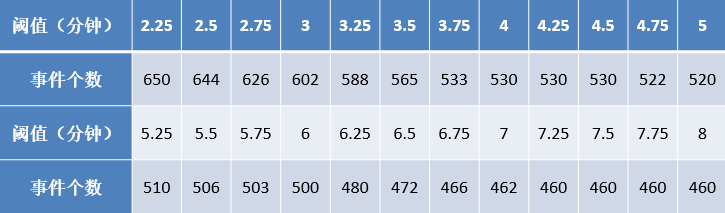
閾值與劃分事件個數關系如下圖所示。
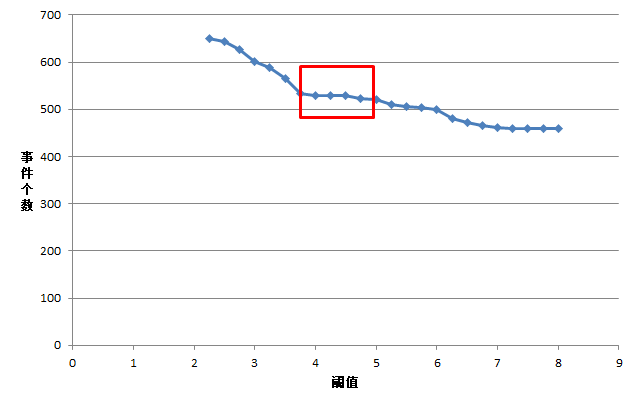
上圖為閾值與劃分事件個數的散點圖,圖中某段閾值范圍內,下降趨勢明顯,說明在該段閾值范圍內,用戶的停頓習慣比較集中。如果趨勢比較平緩,則說明用戶的停頓熱水的習慣趨于穩定,所以取該段時間開始的時間點作為閾值,既不會將短的用水事件合并,又不會將長的用水事件拆開。
用戶停頓熱水的習慣在方框的位置趨于穩定,說明熱水器用戶的用水的停頓習慣用方框開始的時間點作為劃分閾值會有一個好的效果。
曲線在上圖(散點圖)中方框趨于穩定時,其方框開始的點的斜率趨于一個較小的值。為了用程序來識別這一特征,將這一特征提取為規則。根據用水停頓時間間隔頻數分布表說明如何識別上圖中的方框中起始的時間。
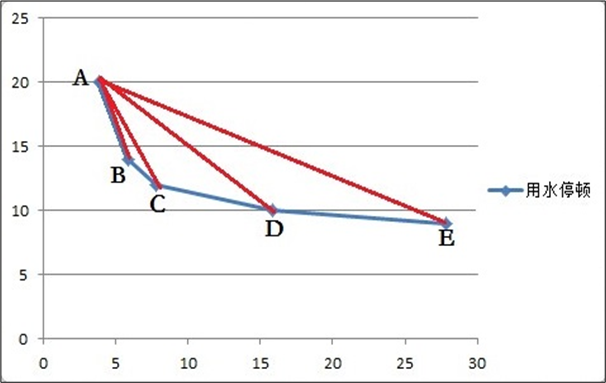
每個閾值對應一個點,給每個閾值計算得到一個斜率指標,如上圖所示,其中A點是要計算的斜率指標點。為了直觀的展示,如下表所示。



4. 屬性構造
1.構建用水時長與頻率屬性
不同用水事件的用水時長是基礎特征之一。根據用水時長這一特征可以構建下表所示的事件開始時間、事件結束時間、洗浴時間點、用水時長、總用水時長和用水時長/總用水時長這6個特征。
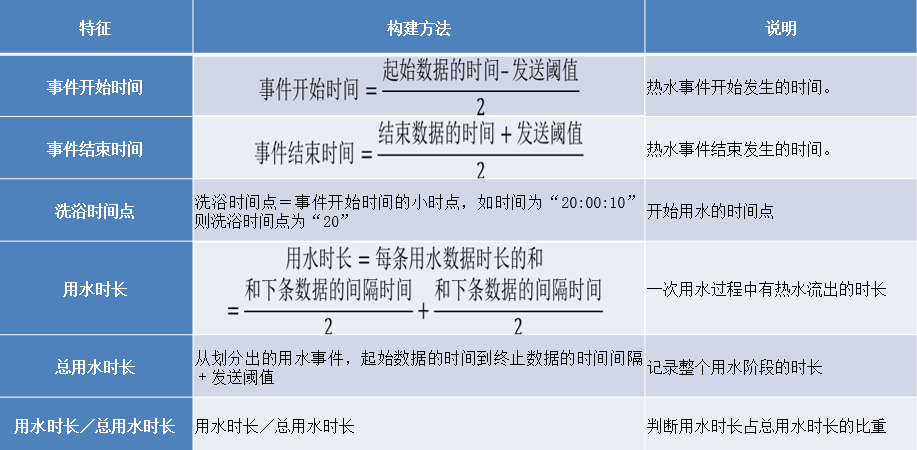
構建用水開始時間或結束的時間兩個特征時分別減去或加上了發送閾值(發送閾值是指熱水器傳輸數據的頻率的大小)。其原因如下,取平均值會導致很大的偏差。
綜合分析構建“用水開始時間”為起始數據的時間減去“發送閾值”的一半。
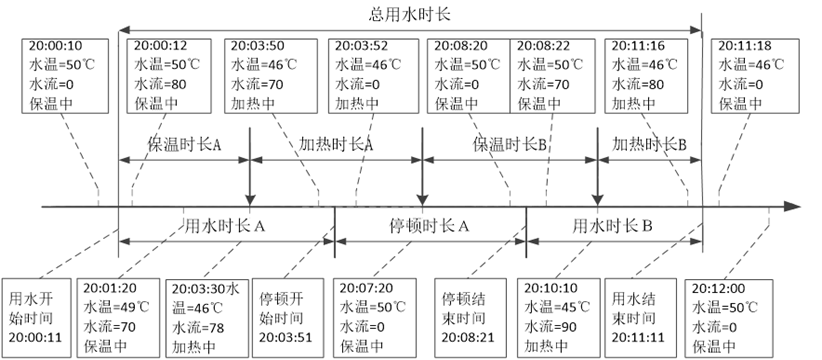
用水時長相關的特征只能夠區分出一部分用水事件,不同用水事件的用水停頓和頻率也不同。

# 轉換時間格式
data["發生時間"] = pd.to_datetime(data["發生時間"],format="%Y%m%d%H%M%S")# 構造特征:總用水時長
timeDel = pd.Timedelta("0.5 sec")
sj["事件開始時間"] = data.iloc[sj["事件起始編號"]-1,0].values- timeDel
sj["事件結束時間"] = data.iloc[sj["事件終止編號"]-1,0].values + timeDel
sj['洗浴時間點'] = [i.hour for i in sj["事件開始時間"]]
sj["總用水時長"] = np.int64(sj["事件結束時間"] - sj["事件開始時間"])/1000000000 + 1# 構造用水停頓事件
# 構造特征“停頓開始時間”、“停頓結束時間”
# 停頓開始時間指從有水流到無水流,停頓結束時間指從無水流到有水流
for i in range(len(data)-1):if (data.loc[i,"水流量"] != 0) & (data.loc[i + 1,"水流量"] == 0) :data.loc[i + 1,"停頓開始時間"] = data.loc[i +1, "發生時間"] - timeDelif (data.loc[i,"水流量"] == 0) & (data.loc[i + 1,"水流量"] != 0) :data.loc[i,"停頓結束時間"] = data.loc[i , "發生時間"] + timeDel# 提取停頓開始時間與結束時間所對應行號,放在數據框Stop中
indStopStart = data.index[data["停頓開始時間"].notnull()]+1
indStopEnd = data.index[data["停頓結束時間"].notnull()]+1
Stop = pd.DataFrame(data={"停頓開始編號":indStopStart[:-1],"停頓結束編號":indStopEnd[1:]})
# 計算停頓時長,并放在數據框stop中,停頓時長=停頓結束時間-停頓結束時間
Stop["停頓時長"] = np.int64(data.loc[indStopEnd[1:]-1,"停頓結束時間"].values-data.loc[indStopStart[:-1]-1,"停頓開始時間"].values)/1000000000
# 將每次停頓與事件匹配,停頓的開始時間要大于事件的開始時間,
# 且停頓的結束時間要小于事件的結束時間
for i in range(len(sj)):Stop.loc[(Stop["停頓開始編號"] > sj.loc[i,"事件起始編號"]) & (Stop["停頓結束編號"] < sj.loc[i,"事件終止編號"]),"停頓歸屬事件"]=i+1# 刪除停頓次數為0的事件
Stop = Stop[Stop["停頓歸屬事件"].notnull()]# 構造特征 用水事件停頓總時長、停頓次數、停頓平均時長、
# 用水時長,用水/總時長
stopAgg = Stop.groupby("停頓歸屬事件").agg({"停頓時長":sum,"停頓開始編號":len})
sj.loc[stopAgg.index - 1,"總停頓時長"] = stopAgg.loc[:,"停頓時長"].values
sj.loc[stopAgg.index-1,"停頓次數"] = stopAgg.loc[:,"停頓開始編號"].values
sj.fillna(0,inplace=True) # 對缺失值用0插補
stopNo0 = sj["停頓次數"] != 0 # 判斷用水事件是否存在停頓
sj.loc[stopNo0,"平均停頓時長"] = sj.loc[stopNo0,"總停頓時長"]/sj.loc[stopNo0,"停頓次數"]
sj.fillna(0,inplace=True) # 對缺失值用0插補
sj["用水時長"] = sj["總用水時長"] - sj["總停頓時長"] # 定義特征用水時長
sj["用水/總時長"] = sj["用水時長"] / sj["總用水時長"] # 定義特征 用水/總時長
print('用水事件用水時長與頻率特征構造完成后數據的特征為:\n',sj.columns)
print('用水事件用水時長與頻率特征構造完成后數據的前5行5列特征為:\n',sj.iloc[:5,:5])2.構建用水量與波動屬性
除了用水時長,停頓和頻率外,用水量也是識別該事件是否為洗浴事件的重要特征。可以構建出下表所示的兩個用水量特征。

同時用水波動也是區分不同用水事件的關鍵。根據不同用水事件的這一特征可以構建下表所示的水流量波動和停頓時長波動兩個特征。

data["水流量"] = data["水流量"] / 60 # 原單位L/min,現轉換為L/sec
sj["總用水量"] = 0 # 給總用水量賦一個初始值0
for i in range(len(sj)):Start = sj.loc[i,"事件起始編號"]-1End = sj.loc[i,"事件終止編號"]-1if Start != End:for j in range(Start,End):if data.loc[j,"水流量"] != 0:sj.loc[i,"總用水量"] = (data.loc[j + 1,"發生時間"] - data.loc[j,"發生時間"]).seconds* \data.loc[j,"水流量"] + sj.loc[i,"總用水量"]sj.loc[i,"總用水量"] = sj.loc[i,"總用水量"] + data.loc[End,"水流量"] * 2else:sj.loc[i,"總用水量"] = data.loc[Start,"水流量"] * 2sj["平均水流量"] = sj["總用水量"] / sj["用水時長"] # 定義特征 平均水流量
# 構造特征:水流量波動
# 水流量波動=∑(((單次水流的值-平均水流量)^2)*持續時間)/用水時長
sj["水流量波動"] = 0 # 給水流量波動賦一個初始值0
for i in range(len(sj)):Start = sj.loc[i,"事件起始編號"] - 1End = sj.loc[i,"事件終止編號"] - 1for j in range(Start,End + 1):if data.loc[j,"水流量"] != 0:slbd = (data.loc[j,"水流量"] - sj.loc[i,"平均水流量"])**2slsj = (data.loc[j + 1,"發生時間"] - data.loc[j,"發生時間"]).secondssj.loc[i,"水流量波動"] = slbd * slsj + sj.loc[i,"水流量波動"]sj.loc[i,"水流量波動"] = sj.loc[i,"水流量波動"] / sj.loc[i,"用水時長"] # 構造特征:停頓時長波動
# 停頓時長波動=∑(((單次停頓時長-平均停頓時長)^2)*持續時間)/總停頓時長
sj["停頓時長波動"] = 0 # 給停頓時長波動賦一個初始值0
for i in range(len(sj)):if sj.loc[i,"停頓次數"] > 1: # 當停頓次數為0或1時,停頓時長波動值為0,故排除for j in Stop.loc[Stop["停頓歸屬事件"] == (i+1),"停頓時長"].values:sj.loc[i,"停頓時長波動"] = ((j - sj.loc[i,"平均停頓時長"])**2) * j + \sj.loc[i,"停頓時長波動"]sj.loc[i,"停頓時長波動"] = sj.loc[i,"停頓時長波動"] / sj.loc[i,"總停頓時長"]print('用水量和波動特征構造完成后數據的特征為:\n',sj.columns)
print('用水量和波動特征構造完成后數據的前5行5列特征為:\n',sj.iloc[:5,:5])5.篩選候選洗浴事件
洗浴事件的識別是建立在一次用水事件識別的基礎上,也就是從已經劃分好的一次用水事件中識別出哪些一次用水事件是洗浴事件。
可以使用3個比較寬松的條件篩選掉那些非常短暫的用水事件,確定不可能為洗浴事件的數據去除掉,剩余的事件稱為“候選洗浴事件”。這三個條件是“或”的關系,也就是說,只要一次完整的用水事件滿足任意一個條件,就被判定為短暫用水事件,即會被篩選掉。3個篩選條件如下:
1.一次用水事件中總用水量小于5升。
2.用水時長小于100秒。
3.總用水時長小于120秒。

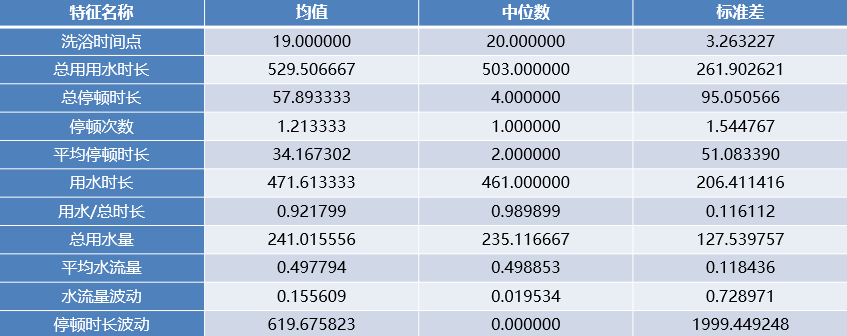
篩選前用水事件數目總共172個,經過篩選后,余下75個用水事件。結合日志,最終用于建模的屬性的總數為11個,其基本狀況
3.3 模型構建
根據建模樣本數據建立BP神經網絡模型識別洗浴事件。由于洗浴事件與普通用水事件在特征上存在不同,而且這些不同的特征在特征上被體現出來。于是,根據用戶提供的用水日志,將其中洗浴事件的數據狀態記錄作為訓練樣本訓練BP神經網絡。然后根據訓練好的網絡來檢驗新采集到的數據,具體過程如下圖所示。

在訓練神經網絡的時候,選取了“候選洗浴事件”的11個屬性作為網絡的輸入,分別為:洗浴時間點,總用水時長,總停頓時長,平均停頓時長,停頓次數,用水時長,用水時長/總用水時長,總用水量,平均水流量,水流量波動和停頓時長波動。
訓練BP網絡時給定的輸出(教師信號)為1與0,其中1代表該次事件為洗浴事件,0表示該次事件不是洗浴事件。是否為洗浴事件的標簽是根據熱水器的用水記錄日志得到。
構建神經網絡模型需要注意數據本身屬性之間的存在量級差異,因此需要進行標準化,消除量級差異。另外,為了便于后續應用模型,可以用joblib.dump函數保存模型。
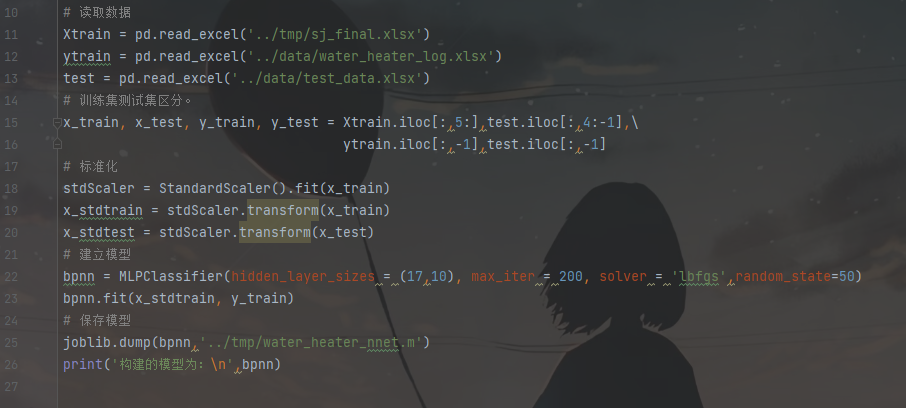
在訓練BP神經網絡時,對神經網絡的參數進行了尋優,發現含2個隱層的神經網絡訓練效果較好,其中2個隱層的隱節點數分別為17和10時訓練的效果較好。
根據樣本,得到訓練好的神經網絡后,就可以用來識別對應的用戶家的洗浴事件,其中待檢測的樣本的11個屬性作為輸入,輸出層輸出一個值在[-1,1]范圍內,如果該值小于0,則該事件不是洗浴事件,如果該值大于0,則該事件是洗浴事件。某熱水器用戶記錄了兩周的熱水器用水日志,將前一周的數據作為訓練數據,后一周的數據作為測試數據,代入上述模型進行測試。
3.4 模型檢驗
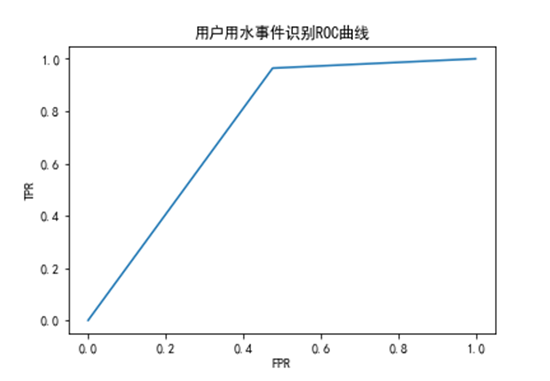
結合模型評價相關的知識,使用精確率(precision)、召回率(recall)和f1值來做模型評價的效果先顧地較為客觀、準確。同時結合ROC曲線,可以進一步更加直觀地評價模型的效果,得到模型的ROC曲線如下圖所示, ROC曲線覆蓋的面積較大,說明模型的識別效果較好。
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve
from sklearn.externals import joblib
import matplotlib.pyplot as pltbpnn = joblib.load('../tmp/water_heater_nnet.m') # 加載模型
y_pred = bpnn.predict(x_stdtest) # 返回預測結果
print('神經網絡預測結果評價報告:\n',classification_report(y_test,y_pred))
# 繪制roc曲線圖
plt.rcParams['font.sans-serif'] = 'SimHei' # 顯示中文
plt.rcParams['axes.unicode_minus'] = False # 顯示負號
fpr, tpr, thresholds = roc_curve(y_pred,y_test) # 求出TPR和FPR
plt.figure(figsize=(6,4)) # 創建畫布
plt.plot(fpr,tpr) # 繪制曲線
plt.title('用戶用水事件識別ROC曲線') # 標題
plt.xlabel('FPR') # x軸標簽
plt.ylabel('TPR') # y軸標簽
plt.savefig('../tmp/用戶用水事件識別ROC曲線.png') # 保存圖片
plt.show() # 顯示圖形
根據該熱水器用戶提供的用水日志判斷事件是否為洗浴與多層神經網絡模型識別結果報告,如下表所示。
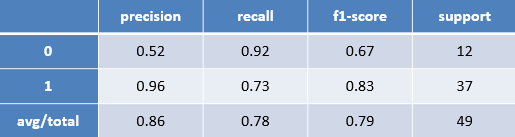
根據模型評估報告表可以看出,在洗浴事件的識別上精確率(precision)非常高,達到了96%,同時召回率(recall)也達到了70%以上。綜合上述結果,可以確定此次創建的模型是有效并且效果良好的能夠用于實際的洗浴事件的識別中。
4. 思考總結
根據模型劃分的結果,發現有時候會將兩次(或多次)洗浴劃分為一次洗浴,因為在實際情況中,存在著一個人洗完澡后,另一個人馬上洗的情況,這中間過渡期間的停頓間隔小于閾值。針對兩次(或多次)洗浴事件被合并為一次洗浴事件的情況,需要進行優化,對連續洗浴事件作識別,提高模型識別精確度。
連續洗浴識別法如下:
1.對每次用水事件,建立一個連續洗浴判別指標。連續洗浴判別指標初始值為0,每當有一個屬性超過設定的閾值,就給該指標加上相應的值,最后判別連續洗浴指標是否超過給定的閾值,如果超過給定的閾值,認為該次用水事件為連續洗浴事件。
2.選取5個前面提取得到的屬性,做為判別連續洗浴事件的特征屬性,5個屬性分別為:總用水時長、停頓次數、用水時長/總用水時長、總用水量、停頓時長波動。詳細的說明如下。
(1) 總用水時長的閾值為900秒,如果超過900秒,就認為可能是連續洗浴,對于每超出的一秒,在該事件的連續洗浴判別指標上加上0.005,詳情見表 10 21。
(2) 停頓次數的閾值為10次,如果超過10次,就認為可能是連續洗浴,對于每超出的一次,在該事件的連續洗浴判別指標上加上0.5,詳情見表 10 21。
(3) 用水時長/總用水時長的閾值為0.5,如果小于0.5,就認為可能是連續洗浴,對于每少一個單位在該事件的連續洗浴判別指標上加上0.2,詳情見表 10 21。
(4) 總用水量的閾值為30L次,如果超過30L,就認為可能是連續洗浴,對于每超出的1L,在該事件的連續洗浴判別指標上加上0.2,詳情見表 10 21。
(5) 停頓時長波動的閾值為1000,如果超過1000,就認為可能是連續洗浴,對于每超出一個單位,在該事件的連續洗浴判別指標上加上0.002,詳細見下表。

建立優化模型

其中S是連續洗浴判別指標。
連續洗浴事件的劃分模型如下:
(1) 當用水事件的連續洗浴判別指標 大于5時,確定為連續洗浴事件或一次洗浴事件加一次短暫用水事件,取中間停頓時間最長的停頓,劃分為兩次事件。
(2) 如果 不大于5,確定為一次洗浴事件。

與 關系型數據庫(RDBMS)的比較)




 - 專業創意軟件)







)




2024年:打造24/7實景無人直播,引領年輕資產創業新紀元!)