分布式計算原理
分布式計算的原理總結一句話就是:分而治之。

- 把數據分片,存在不同的機器中,解決數據存儲的壓力。
- 客戶端和服務端之間通過相關協議來自動的完成在不同的機器之間進行數據的存取,用戶并不感知數據的物理存儲結構。 用戶面對的只有hdfs://xxx/user/xx.txt這樣的路徑地址。 其余的都由客戶端和服務端自動完成。
所有的分布式軟件都是分而治之的思路, 當數據量大到了單機無法承載的時候, 那么就利用上面的原理 ,把數據分布到不同的機器中。 這樣的架構也就可以支持橫向擴展,也就是當存儲軟件的性能或者磁盤空間不夠用時, 只要加機器就可以了。
下面是HDFS(一個分布式文件系統,屬于hadoop生態)的架構圖:
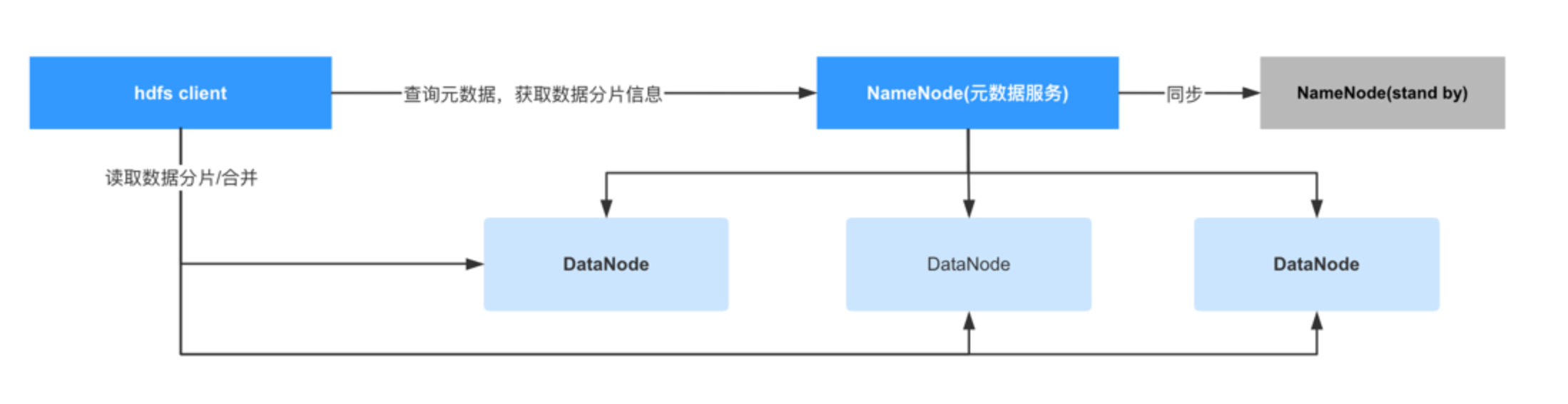
- DataNode:真正存儲數據的節點
- NameNode:元數據服務器,存儲所有數據的元信息,比如數據存儲在哪些機器中的哪些路徑。
- NameNode(standby):NameNode的備用節點,當主NameNode故障后,該服務會接替成為NameNode
- Hdfs client會負責查詢NameNode獲取數據分片信息并處理后返回給用戶,用戶不感知數據分布情況。
在HDFS中, NameNode負責存儲所有文件的元數據, 實際上所有的分布式文件存儲軟件都有一個類似NameNode的角色,畢竟數據分散在N個不同的機器中, 為了不讓用戶感知到這復雜的文件分布, 所以需要有這樣的一個角色來保存這些文件的元數據,這樣客戶端才可以跟服務端交互自動的完成文件的整合工作,用戶也可以在不感知的前提下讀寫文件, 大大降低了使用的復雜度。
需要注意的是對于HDFS來說, 可以支持的文件數量都是有限的,并且對于小文件的存儲非常的不友好。 因為HDFS是基于數據都是大數據的前提下進行設計的,所以它在文件切片并保存在不同的機器上的時候,是默認128M為一個block(塊)進行存儲,即便文件不足128M也會按128M進行保存。 也就是如果一個小文件只有28M,那么在HDFS中也會占用128的存儲空間, 這100M就是浪費的。 并且對于HDFS來說,我們可以看到它的設計里雖然可以有多個NameNode,但在同一個時間內只能有一個NameNode對外提供服務。 這是出于高可用的考慮(簡化元數據在多個namenode同步的問題,因為只有一個namenode在線, 所以剩下了很多數據一致性的問題),但它的缺點就是它沒有負載均衡的能力,當文件數量過多時,就會對NameNode產生很大的壓力, 使得集群整體的性能受到影響。所以我們在測試分布式存儲軟件本身的時候,也需要測試它能夠承載的文件數量。 所以一般在分布式存儲軟件中,或者大數據系統中, 一般測試人員都會測試海量小文件的場景 -- 構造海量的小文件并保存在存儲系統中,驗證它的各項性能指標。 后面講到造數工具的時候, 會演示如何在短時間內構造這樣大批量的數據。
分布式計算
分布式計算的原理也是一樣的,都是分而治之:

數據存儲的時候可以把數據分布在不同的機器中, 那么在計算時也可以把一個大的任務拆分成N個小任務在調度到不同的機器中來完成。 它的大概過程是這樣的:
- 計算任務分布在不同的節點中,各自掌握一段數據分片
- 每個計算任務各自計算自己掌握的數據
- 各個任務計算完畢后進行匯總并返回給客戶端
shuffle與數據傾斜
當我們了解到分布式計算的基本運算原理后,就可以開始了解在大數據領域中最著名的一個設計, 同樣也號稱是大數據領域中的頭號性能殺手 -- shuffle。 這是從 MapReduce 時代就開始的分布式計算獨特的設計理念。 理解好 shuffle 的原理對學習 spark 甚至是任何一門大數據技術都是至關重要的。Shuffle 中文翻譯為 “洗牌”,需要 Shuffle 的關鍵性原因是某種具有共同特征的數據需要最終匯聚到一個 partition 上進行計算。為什么要這么做呢? 因為對于一個分布式計算框架來說,網絡通信的開銷是十分昂貴的。假設我們有一千個計算節點在并發的執行一個計算任務。它們要聚合,計算,統計。數據在這一千個節點之間流動會造成相當大的網絡負擔。所以 spark 的設計者們為了減少網絡開銷而設計了 shuffle。它的原理就是盡量把一個計算任務所要處理的所有數據都聚集在一個 partition 上,這樣就節省了很多的網絡開銷。 例如我們今天學到的 groupByKey() 聚合操作,spark 一旦執行到這一步的時候,會把所有 key 相同的數據分配到同一個 partition 上以供后續操作。例如 key 為 A 的行分配到 X 節點進行計算,key 為 B 的行分配到 Y 節點進行計算,這樣在之后的計算中就免去了網絡開銷。而這個過程就是 shuffle。所謂洗牌就是這個意思了。
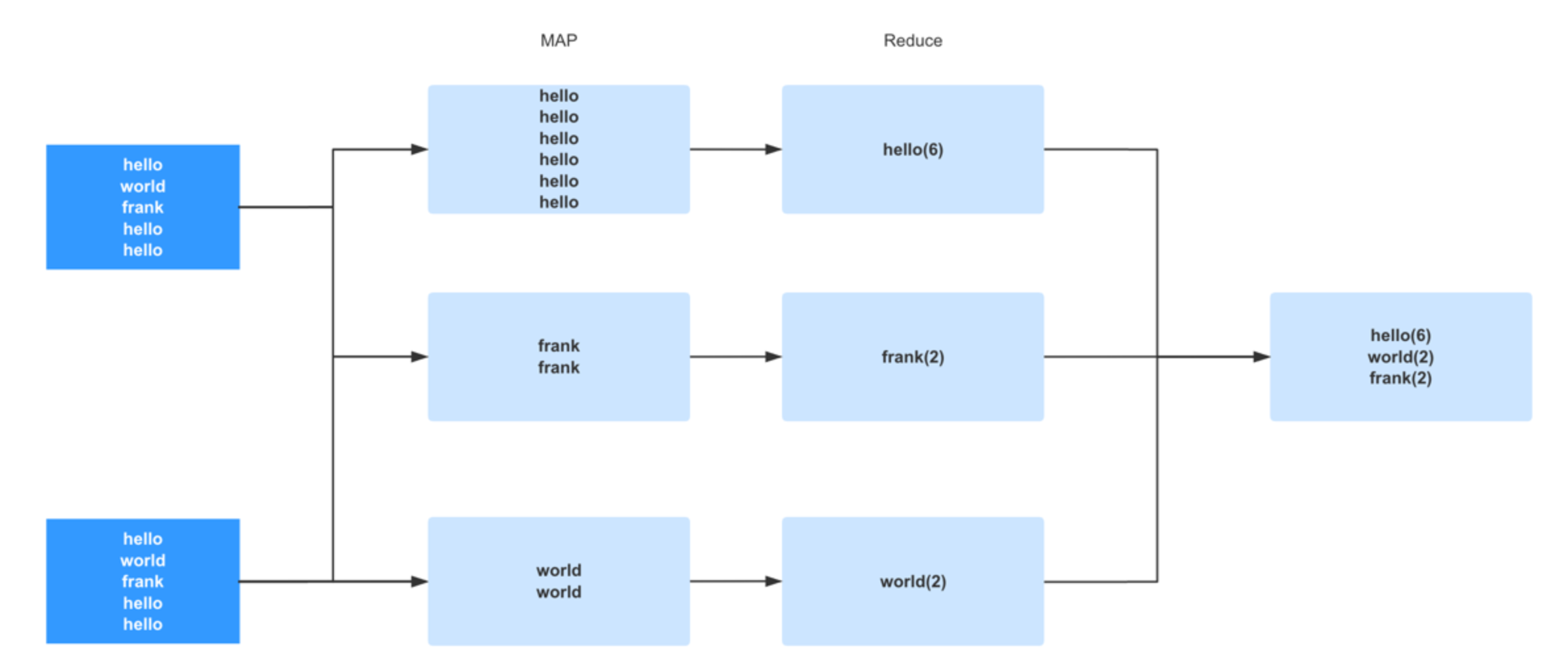
我們了解了 shuffle 相關的概念和原理后其實可以發現一個問題,那就是 shuffle 比較容易造成數據傾斜的情況。 例如上面我們看到的圖,在這批數據中,hello 這個單詞的行占據了絕大部分,當我們執行 groupByKey 的時候觸發了 shuffle。這時候大部分的數據 (Hello) 都匯集到了一個 partition 上。這種極端的情況就會造成著名的長尾現象,就是說由于大部分數據都匯集到了一個 partition 而造成了這個 partition 的 task 運行的十分慢。而其他的 task 早已完成,整個任務都在等這個大尾巴task 的結束。 這種現象破壞了分布式計算的設計初衷,因為最終大部分的計算任務都在一個單點上執行了。所以極端的數據分布就成為了機器學習和大數據處理這類產品的勁敵,我跟我司的研發人員聊的時候,他們也覺得數據傾斜的情況比較難處理,當然我們可以做 repartition(重新分片) 來重新整合 parition 的數量和分布等操作,以及避免或者減少 shuffle 的成本,也可以重新分配key來避免數據傾斜,各家不同的業務有不同的做法。在做這類產品的性能測試的時候,也跟我們以往的互聯網模式不同,產品的壓力不在于并發量上,而在于數據量和數據分布上(大數據產品中,批處理業務很少有極高的并發操作,只有流計算里才會有高并發,而流計算我們放到以后的章節來講)。
總而言之對于大數據產品來說,數據是否符合真實場景(包括數據的分布,分片,行數,列數等等)就決定性能測試的結果是否準確。 在很多產品中很難從線上直接拉取數據,有些場景是因為線上也沒有足夠的高質量數據,也有的是因為數據量實在過于龐大, 比如我們曾經測試過百億,千億和萬億規模的數據。 即便線上環境有這樣龐大的數據, 但要把數據從線上同步到測試環境也會長期占用極其龐大的網絡帶寬, 這為線上帶來了很大的風險。 同時對于很多做TOB類型的大數據產品來說(大數據產品大多都是TOB的,當然不一定是私有云, 也可能是公有云), 客戶數據是保密的,我們沒有辦法直接拿現成客戶數據。
所以綜上所述, 測試人員需要開發一款造數工具來在短時間內構建海量的數據, 而這部分內容,我將會在下一個章節講解。
?更多內容歡迎來到我的知識星球:
?





2024年:打造24/7實景無人直播,引領年輕資產創業新紀元!)






)

)





