
隨著OCR技術的不斷發展,將表格圖片轉為excel已不再是難題,但是,目前市面上的程序還大多處于僅能將圖片表格轉為普通的excel格式階段,而不能將其結構化,這樣就會產生許多的弊端,具體弊端如下:
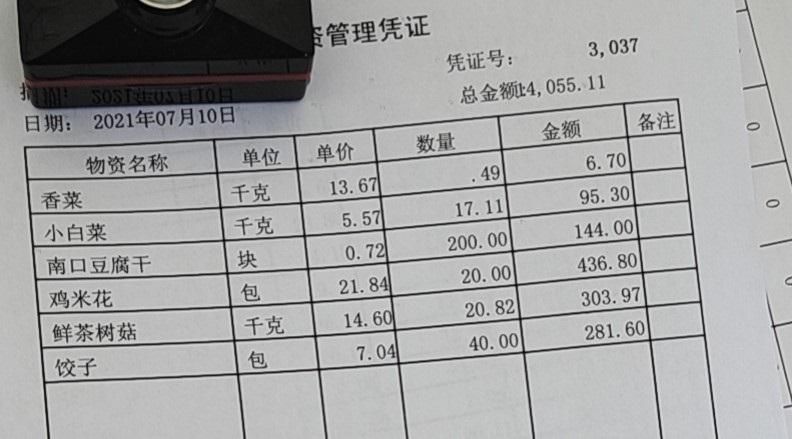
<spanclass="bjh-image-caption ">原圖片
一、數據難以管理和整合:
沒結構化的數據缺乏固定格式和字段定義,因此在收集、存儲和管理方面存在挑戰。傳統的數據庫系統通常是基于結構化數據設計的,無法輕松處理沒結構化的數據。企業需要投入大量資源來開發專門的系統或工具,以有效地收集、存儲和管理沒結構化的數據,這增加了管理和維護的復雜性。
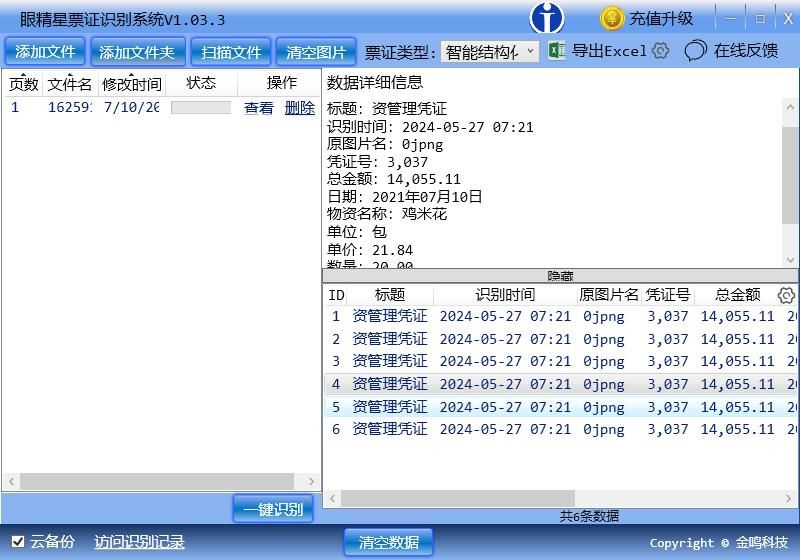
<spanclass="bjh-image-caption ">結構化識別結果
二、數據查詢和檢索效率低下:
由于沒結構化的數據內容不受限制,查詢和檢索不結構化數據變得更加困難。傳統的數據庫查詢語言通常無法直接應用于沒結構化的數據,需要使用復雜的算法和技術來提取所需信息。這導致數據查詢和檢索效率低下,用戶需要花費更多的時間和精力來獲取有用的信息,影響了工作效率和決策速度。
三、數據分析受限:
沒結構化的數據復雜性和多樣性使得數據分析變得更加困難。傳統的數據分析工具和技術通常適用于結構化數據,無法直接應用于不結構化數據。企業需要開發新的分析方法和工具,以從不結構化數據中提取洞察和價值。這增加了數據分析的復雜性和成本,限制了企業對不結構化數據的充分利用。

綜上所述,企業和機構面對沒結構化的數據時,會面臨管理、查詢、檢索和分析等方面的挑戰。為了克服這些挑戰,建議用戶在使用OCR軟件時,盡量選擇、使用具識別成結構化數據功能的軟件(如金某表格文字識別大師、眼某星票證識別系統等,以提高企業和機構的工作效率,降低維護數據的成本。
#OCR文字識別#
)
















)
