apply
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
第一個參數是函數
可以在Series或DataFrame上執行一個函數
支持對行、列或單個值進行處理
import numpy as np
import pandas as pdf = lambda x: x.max()-x.min()df = pd.DataFrame(np.random.randn(4,3),columns=list('bde'),index=['utah', 'ohio', 'texas', 'oregon'])
print(df)
'''b d e
utah -0.631142 0.081229 -0.791898
ohio 1.571634 0.801737 1.478349
texas -0.408345 -1.920296 1.001519
oregon 0.013308 2.496898 -0.580166
'''t1 = df.apply(f)
print(t1)
'''
b 2.202776
d 4.417194
e 2.270247
dtype: float64
'''
t2 = df.apply(f, axis=1)
print(t2)
'''
utah 0.873127
ohio 0.769897
texas 2.921815
oregon 3.077063
dtype: float64
'''df = pd.read_csv('C:/data/temp.csv')
df.apply(['max', 'min'])
'''name team Q1 Q2 Q3 Q4
max Zachary E 98 99 99 99
min Aaron A 1 1 1 2
'''df.apply({'Q1':'max', 'Q2': 'min'})
'''
Q1 98
Q2 1
dtype: int64
'''df.apply({'Q1':'mean', 'Q2': ['max', 'min']})
'''Q1 Q2
mean 49.2 NaN
max NaN 99.0
min NaN 1.0
'''df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
df
''' A B
0 4 9
1 4 9
2 4 9
'''# 使用numpy通用函數 (如 np.sqrt(df)):
df.apply(np.sqrt)
'''A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
'''# 使用聚合功能
df.apply(np.sum, axis=0)
'''
A 12
B 27
dtype: int64
agg/aggregate
DataFrame.agg(func, axis=0, *args, **kwargs)
func : function, str, list 或者 dict。用于聚合數據的函數。如果是函數,則必須在傳遞給 DataFrame 或傳遞給 DataFrame.apply。可接受的組合為:
- 函數 function
- 字符串函數名 string function name
- 函數和/或函數名列表,如 [np.sum, ‘mean’]
- 軸標簽->函數、函數名稱或此類列表的字典
axis : {0 or ‘index’, 1 or ‘columns’}, 默認 0
- 如果 0 或者 ‘index’:將函數應用于每列
- 如果 1 或者 ‘columns’: 將函數應用于每一行
Series.agg
s = pd.Series([1, 2, 3, 4])
s
'''
0 1
1 2
2 3
3 4
dtype: int64
'''s.agg('min')
# 1s.agg(['min', 'max'])
'''
min 1
max 4
dtype: int64
'''# 指定索引名
s.agg(A=max)
'''
A 4
dtype: int64
'''
s.agg(Big=max, Small=min)
'''
Big 4
Small 1
dtype: int64
'''
DataFrame.agg
df = pd.DataFrame([[1, 2, 3],[4, 5, 6],[7, 8, 9],[np.nan, np.nan, np.nan]],columns=['A', 'B', 'C'])# 在行上聚合這些函數
df.agg(['sum', 'min'])
'''A B C
sum 12.0 15.0 18.0
min 1.0 2.0 3.0
'''# 每列有不同的聚合
df.agg({'A' : ['sum', 'min'], 'B' : ['min', 'max']})
'''A B
sum 12.0 NaN
min 1.0 2.0
max NaN 8.0
'''# 在列上聚合
df.agg("mean", axis="columns")
'''
0 2.0
1 5.0
2 8.0
3 NaN
dtype: float64
'''
DataFrameGroupBy.agg
agg 可以為分組對象調用方法,與 DataFrame 的一點不同是,DataFrameGroupBy 對象在使用 agg 時可以指定計算引擎(engine 參數)和 引擎的參數(engine_kwargs)。
返回:DataFrame
aggregate(self, func=None,engine=None, engine_kwargs=None,*args, **kwargs)
engine:str, 默認 None,有:
- ‘cython’ : 通過cython的C擴展執行函數
- ‘numba’ : 通過numba中的JIT編譯代碼運行函數
- None : 默認為 “cython” 或全局設置 compute.use_numba
df = pd.DataFrame({"A": [1, 1, 2, 2],"B": [1, 2, 3, 4],"C": [0.362838, 0.227877, 1.267767, -0.562860],}
)df
'''A B C
0 1 1 0.362838
1 1 2 0.227877
2 2 3 1.267767
3 2 4 -0.562860
'''# 聚合是針對每個列的
df.groupby('A').agg('min')
'''B C
A
1 1 0.227877
2 3 -0.562860
'''# 多重聚合
df.groupby('A').agg(['min', 'max'])
'''B Cmin max min max
A
1 1 2 0.227877 0.362838
2 3 4 -0.562860 1.267767
'''# 選擇要聚合的列
df.groupby('A').B.agg(['min', 'max'])
'''min max
A
1 1 2
2 3 4
'''# 每列的聚合不同
df.groupby('A').agg({'B': ['min', 'max'], 'C': 'sum'})
'''B Cmin max sum
A
1 1 2 0.590715
2 3 4 0.704907
'''grouped = df.groupby("A")# 分組對象
grouped["C"].agg([np.sum, np.mean, np.std])# 指定列,多個聚合
'''sum mean std
A
1 0.590715 0.295357 0.095432
2 0.704907 0.352454 1.294449
'''
grouped.agg([np.sum, np.mean, np.std])# 所有列分別多個聚合
'''B Csum mean std sum mean std
A
1 3 1.5 0.707107 0.590715 0.295357 0.095432
2 7 3.5 0.707107 0.704907 0.352454 1.294449
'''
聚合滾動窗口 Rolling.agg
df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6], "C": [7, 8, 9]})
df
'''A B C
0 1 4 7
1 2 5 8
2 3 6 9
'''df.rolling(2).sum()
'''A B C
0 NaN NaN NaN
1 3.0 9.0 15.0
2 5.0 11.0 17.0
'''df.rolling(2).agg({"A": "sum", "B": "min"})
'''A B
0 NaN NaN
1 3.0 4.0
2 5.0 5.0
'''
stack() 和 unstack()
stack() 函數會將數據從“表格結構”變成“花括號結構”,即將其行索引變成列索引,反之,
unstack() 函數將數據從“花括號結構”變成“表格結構”,即要將其中一層的列索引變成行索引。
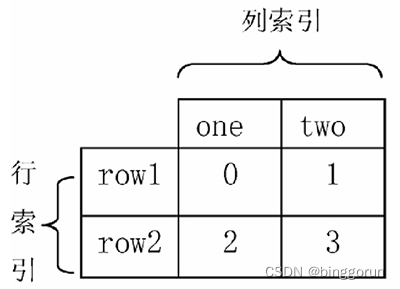 表格結構
表格結構 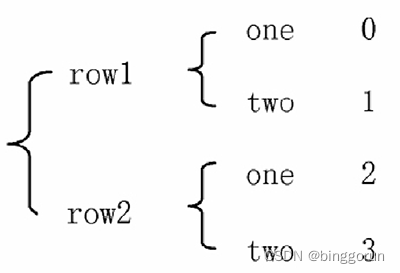 花括號結構
花括號結構
stack() 函數
DataFrame.stack(level=-1,dropna=True)
- level:接收 int、str、list,默認為 -1,表示從列軸到索引軸堆疊的級別,定義為一個索引或標簽,或者索引或標簽列表;
- dropna:接收布爾值,默認為 True,表示是否在缺失值的結果框架/系列中刪除行。將列級別堆疊到索引軸上可以創建原始數據幀中缺失的索引值和列值的組合。
函數返回值為 DataFrame 或 Series。
unstack() 函數
DataFrame.unstack(level=-1, fill_value=None)
Series.unstack(level=-1, fill_value=None)
- level:接收 int、string 或其中的列表,默認為 -1(最后一級),表示 unstack 索引的級別或級別名稱。
- fill_value:如果取消堆棧,則用此值替換 NaN 缺失值,默認為 None。
函數返回值為 DataFrame 或 Series。
import numpy as np
import pandas as pd
#創建DataFrame
data = pd.DataFrame(np.arange(4).reshape((2, 2)),
index=pd.Index(['row1', 'row2'], name='rows'),
columns=pd.Index(['one', 'two'], name='cols'))
print(data)
'''
cols one two
rows
row1 0 1
row2 2 3
'''
#使用stack()函數改變data層次化結構
result = data.stack()
print('data改變成"花括號"結構','\n',result)
'''
data改變成"花括號"結構
rows cols
row1 one 0two 1
row2 one 2two 3
'''
print('恢復到原來結構','\n',result.unstack())
'''
恢復到原來結構
cols one two
rows
row1 0 1
row2 2 3
'''
print(result.unstack(0))
'''
rows row1 row2
cols
one 0 2
two 1 3
'''
print(result.unstack('rows'))
#創建Series
s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd'])
s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e'])
data2 = pd.concat([s1, s2], keys=['one', 'two'])
print(data2)
'''
one a 0b 1c 2d 3
two c 4d 5e 6
dtype: int64
'''
print('將data2改變成表格結構','\n',data2.unstack())
'''
將data2改變成表格結構 a b c d e
one 0.0 1.0 2.0 3.0 NaN
two NaN NaN 4.0 5.0 6.0
'''
#使用stack()函數改變成"花括號"結構,并刪除缺失值行
print(data2.unstack().stack())'''one a 0.0b 1.0c 2.0d 3.0
two c 4.0d 5.0e 6.0
dtype: float64
'''
#使用stack()函數改變成"花括號"結構,不刪除缺失值行
print(data2.unstack().stack(dropna=False))
'''
one a 0.0b 1.0c 2.0d 3.0e NaN
two a NaNb NaNc 4.0d 5.0e 6.0
dtype: float64
'''
#用字典創建DataFrame
df = pd.DataFrame({'left': result, 'right': result + 3},
columns=pd.Index(['left', 'right'], name='side'))
print(df)
'''
side left right
rows cols
row1 one 0 3two 1 4
row2 one 2 5two 3 6
'''
#使用unstack()、stack()函數
print(df.unstack('rows'))
'''
side left right
rows row1 row2 row1 row2
cols
one 0 2 3 5
two 1 3 4 6
'''
print(df.unstack('rows').stack('side'))
'''
rows row1 row2
cols side
one left 0 2right 3 5
two left 1 3right 4 6
'''
concat()和merge()
- 軸向連接(concatenation): pd.concat() 可以沿一個軸將多個DataFrame對象連接在一起, 形成一個新的Dataframe對象
- 融合(merging):pd.merge()方法可以根據一個或多個鍵將不同DataFrame中的行連接起來。
concat() 軸向連接
concat() 函數可以將數據根據不同的軸作進行合并
pd.concat(objs, axis=0, join=‘outer’)
- objs: series、dataframe或者是panel構成的序列list
- axis: 需要合并鏈接的軸,0是行,1是列,默認是0
- join:連接的方式 inner:得到的是兩表的交集,或者outer:得到的是兩表的并集,默認是outer;
join=‘outer’,axis=0
當join=‘outer’,axis參數為0時,列進行并集處理,縱向表拼接,缺失值由NaN填充,并且會保留原有數據的行索引
dict1={'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3']}
df1=pd.DataFrame(dict1)dict2={'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']}
df2=pd.DataFrame(dict2)
pd.concat([df1, df2], axis=0, join='outer')
'''A B C D
0 A0 B0 C0 NaN
1 A1 B1 C1 NaN
2 A2 B2 C2 NaN
3 A3 B3 C3 NaN
0 NaN B0 C0 D0
1 NaN B1 C1 D1
2 NaN B2 C2 D2
3 NaN B3 C3 D3
'''
pd.concat([df1,df2],axis=0,join='outer',ignore_index=True) # 使用ignore_index參數置為 true, 重新生成一個新的index
'''A B C D
0 A0 B0 C0 NaN
1 A1 B1 C1 NaN
2 A2 B2 C2 NaN
3 A3 B3 C3 NaN
4 NaN B0 C0 D0
5 NaN B1 C1 D1
6 NaN B2 C2 D2
7 NaN B3 C3 D3
'''
join=‘outer’,axis=1
當join=‘outer’,axis參數為1時,行進行并集處理,橫向表拼接,缺失值由NaN填充
pd.concat([df1,df2],axis=1,join='outer')
'''A B C B C D
0 A0 B0 C0 B0 C0 D0
1 A1 B1 C1 B1 C1 D1
2 A2 B2 C2 B2 C2 D2
3 A3 B3 C3 B3 C3 D3
'''
join=inner, axis=0
pd.concat([df1,df2],axis=0,join='inner',ignore_index=True)
'''
B C
0 B0 C0
1 B1 C1
2 B2 C2
3 B3 C3
4 B0 C0
5 B1 C1
6 B2 C2
7 B3 C3
'''
merge() 融合
merge(left, right, how=‘inner’, on=None)
- left和right, 兩個要合并的DataFrame(對應的左連接和右連接)
- how: 連接的方式, 有inner(內連接)、left(左連接)、right(右連接)、outer(外連接), 默認為 inner
- on: 指的是用于連接的列索引名稱, 必須存在于左右兩個DataFrame中, 如果沒有指定且其他參數也沒有指定,則兩個DataFrame列名交集作為連接鍵
inner(內連接)
merge()默認做inner連接,并且使用兩個DataFrame的列名交集(key)作為連接鍵,同樣,最終連接的數據也是兩個DataFramekey列數據的交集
dict1={'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3']}
df1=pd.DataFrame(dict1)
df1
'''A B C
0 A0 B0 C0
1 A1 B1 C1
2 A2 B2 C2
3 A3 B3 C3
'''dict2={'B': ['B0', 'B1', 'B4', 'B5'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']}
df2=pd.DataFrame(dict2)
df2
'''B C D
0 B0 C0 D0
1 B1 C1 D1
2 B4 C2 D2
3 B5 C3 D3
'''
pd.merge(df1,df2)
'''A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
'''
outer (外連接)
當merge()做outer連接時最終連接的數據是兩個DataFramekey列數據的并集,缺失的內容由NaN填充
pd.merge(df1,df2,on=['B','C'],how='outer')
'''A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 NaN
3 A3 B3 C3 NaN
4 NaN B4 C2 D2
5 NaN B5 C3 D3
'''
left(左連接)
當merge()做left連接時,最終連接的數據將以left數據的鏈接建為準合并兩個數據的列數據,缺失的內容由NaN填充
pd.merge(df1,df2,on=['B'],how='left')
'''A B C_x C_y D
0 A0 B0 C0 C0 D0
1 A1 B1 C1 C1 D1
2 A2 B2 C2 NaN NaN
3 A3 B3 C3 NaN NaN
'''
right (右連接)
當merge()做right連接時,最終連接的數據將以right數據的鏈接建為準合并兩個數據的列數據,缺失的內容由NaN填充
pd.merge(df1,df2,on=['B'],how='right')
'''A B C_x C_y D
0 A0 B0 C0 C0 D0
1 A1 B1 C1 C1 D1
2 NaN B4 NaN C2 D2
3 NaN B5 NaN C3 D3
'''
應用場景
1)兩張同類型的表合并成一張表,可使用concat( )將兩個表沿著0軸合并;
2)兩張相互關聯的表(如用戶信息、訂單信息) 需要關聯生成一張完整的表,可使用merge()根據用戶ID將兩個表合并成一個完整的表;
lambda
語法格式:lambda arguments: expression
- lambda是 Python 的關鍵字,用于定義 lambda 函數。
- arguments 是參數列表,可以包含零個或多個參數,但必須在冒號(:)前指定。
- expression 是一個表達式,用于計算并返回函數的結果。
f = lambda: "Hello, world!"
print(f()) # 輸出: Hello, world!x = lambda a : a + 10
print(x(5))#輸出:15x = lambda a, b, c : a + b + c
print(x(5, 6, 2))## 輸出: 13
lambda 函數通常與內置函數如 map()、filter() 和 reduce() 一起使用,以便在集合上執行操作
map()函數逐一處理
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared) # 輸出: [1, 4, 9, 16, 25]
filter()篩選
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # 輸出:[2, 4, 6, 8]
reduce() 累計計算
from functools import reduce
numbers = [1, 2, 3, 4, 5]
# 使用 reduce() 和 lambda 函數計算乘積
product = reduce(lambda x, y: x * y, numbers)
print(product) # 輸出:120
query數據篩選
query()方法允許你使用字符串表達式來篩選DataFrame的行。這個表達式類似于你在Python中使用的常規表達式,但是它專門針對DataFrame的列名和值。
import pandas as pd# 創建一個示例DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': ['p', 'q', 'r', 's']
}
df = pd.DataFrame(data)# 使用query()方法篩選A列大于2的行
filtered_df = df.query('A > 2')
print(filtered_df)
'''A B C
2 3 7 r
3 4 8 s
'''import pandas as pd# 創建一個示例DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': ['p', 'q', 'r', 's']
}
df = pd.DataFrame(data)#兩者都需要滿足的并列條件使用符號 &,或 單詞 and
#只需要滿足其中之一的條件使用符號 |,或 單詞 or
# 篩選A列大于2且B列小于等于7的行
filtered_df = df.query('A > 2 and B <= 7')
print(filtered_df)
'''A B C
2 3 7 r
'''import pandas as pd# 創建一個示例DataFrame
data = {'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': ['p', 'qu', 'r', 's']
}
df = pd.DataFrame(data)# 篩選C列以'q'開頭的行
filtered_df = df.query('C.str.startswith("q")')
print(filtered_df)
'''A B C
1 2 6 qu'''# 通過變量來篩選數據,在變量前使用 @ 符號即可
name = 'Python數據之道'
df.query('brand == @name')# 當需要在某列中篩選多個符合要求的值的時候,可以通過列表(list)來實現;需要注意下 雙引號 和 單引號的分開使用
df.query('brand in ["Python數據之道","價值前瞻"]')
# df.query("brand in ['Python數據之道','價值前瞻']")query()方法還可以與其他pandas功能(如groupby()、sort_values()等)結合使用,以執行更復雜的數據操作。
import pandas as pd# 創建一個示例DataFrame
data = {'A': [1, 1, 2, 2, 3, 3, 4, 4],'B': [5, 6, 6, 7, 7, 8, 8, 9],'C': ['p', 'q', 'r', 's', 'p', 'q', 'r', 's']
}
df = pd.DataFrame(data)# 按A列分組,并在每個組內篩選B列的最大值
grouped_df = df.groupby('A').apply(lambda x: x.query('B == B.max()'))
print(grouped_df)
'''A B C
A
1 1 1 6 q
2 3 2 7 s
3 5 3 8 q
4 7 4 9 s'''
Sample
random.sample()
random.sample(population, k)
- 參數population表示要從中進行抽樣的序列,可以是一個列表、元組或集合等可迭代對象。
- 參數k表示要抽取的樣本數量,必須是一個非負整數且不大于population的長度。
- 無重復抽樣
import random
colors = ['red', 'blue', 'green', 'yellow', 'orange']
sample_colors = random.sample(colors, 2)
print(sample_colors) # 輸出類似 ['yellow', 'blue']
choices()重復抽樣
需要指定抽樣次數k(k命名參數),并通過參數weights來為每個元素指定權重(默認情況下,每個元素的權重相等)
import random
x = ['apple', 'banana', 'cherry']
print(random.choices(x, weights = [10, 1, 1], k = 3))
# 輸出可能為:['apple', 'banana', 'apple'], ['apple', 'apple', 'cherry']等
DataFrame 對象的方法
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
- n(int或None):指定要抽取的樣本數量。如果指定了 n,則 frac 應設置為 None。
- frac(float或None):指定要抽取的樣本占原數據框的比例。可以是小數,表示抽取的比例,例如 frac=0.25 表示抽取 25% 的樣本。如果同時指定了 n 和 frac,將使用 frac 參數。
- replace(bool,默認為False):控制是否允許重復抽樣。 True:則允許同一樣本被抽取多次; False:不允許重復抽樣。
- weights(str或數組型,默認為None):指定每個樣本的權重。可以是列名,指示樣本權重的列,也可以是權重數組。
- random_state(int或RandomState實例或None,默認為None):控制隨機抽樣的隨機化過程。指定一個整數可實現可重復的隨機抽樣。
- axis({0或‘index’,1或‘columns’},默認為0):指定抽樣的軸。如果為 0 或 ‘index’,則在行上進行抽樣;如果為 1 或 ‘columns’,則在列上進行抽樣。
import pandas as pddf = pd.read_csv('C:/Users/Admin/Desktop/data.txt', sep='\t')# 從數據框中抽取10個樣本
sampled_data = df.sample(n=10)# 從數據框中抽取總樣本的30%
sampled_data_frac = df.sample(frac=0.3)# 從數據框中進行有放回抽樣(允許重復)
sampled_with_replacement = df.sample(n=10, replace=True)# 指定每個樣本的權重進行抽樣
sampled_with_weights = df.sample(n=10, weights='column_with_weights')# 指定隨機種子以實現可重復抽樣
sampled_with_seed = df.sample(n=10, random_state=42)










)








