大模型技術論文不斷,每個月總會新增上千篇。本專欄精選論文重點解讀,主題還是圍繞著行業實踐和工程量產。若在某個環節出現卡點,可以回到大模型必備腔調或者LLM背后的基礎模型新閱讀。而最新科技(Mamba,xLSTM,KAN)則提供了大模型領域最新技術跟蹤。若對于具身智能感興趣的請移步具身智能專欄。技術宅麻煩死磕AI架構設計。


FineWeb
FineWeb是一個新發布的開源數據集,它希望通過其廣泛收集的英語網絡數據來推動語言模型研究發展。FineWeb 由 huggingface 領導的團體研發,提供超過15萬億個Token,這些Token來自2013年至2024年的 CommonCrawl轉儲。
FineWeb在設計時一絲不茍,使用datatrove進行流水線處理。這個過程針對數據集進行清理和重復數據刪除的操作,從而提高其質量和適用性以便利于大語言模型的訓練和評估。
FineWeb的主要優勢之一在于其性能。通過精心策劃和創新的過濾技術,FineWeb在各種基準測試任務中優于C4、Dolma v1.6、The Pile和 SlimPajama 等已建立的數據集。在FineWeb上訓練的模型表現出卓越的性能,它已經成為自然語言處理的寶貴資源。
透明度和可重建是FineWeb發展的核心原則。該數據集及其處理管道代碼在ODC-By 1.0許可下發布,使研究人員能夠輕松復制和構建其發現。FineWeb還進行了廣泛的消融和基準測試,以驗證其對已建立數據集的有效性,確保其在語言模型研究中的可靠性和有用性。
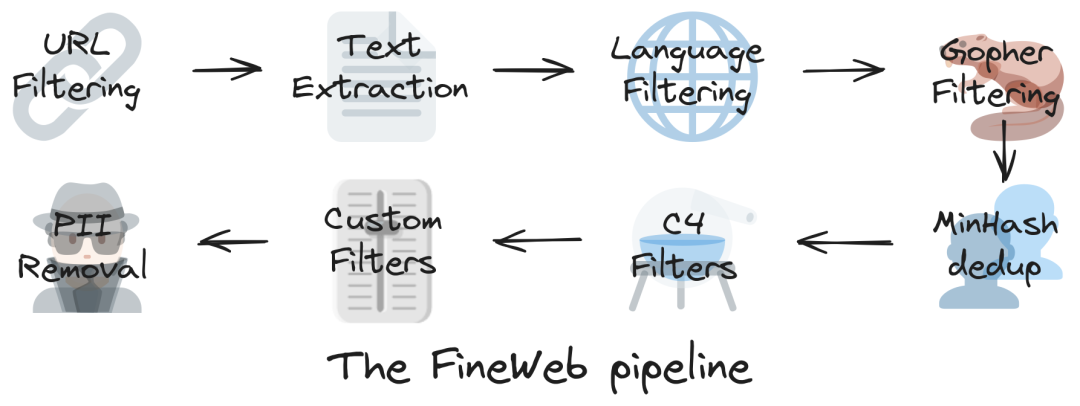
FineWeb利用了URL?過濾、語言檢測和質量評估等過濾步驟提高數據集的完整性和豐富性。每個CommonCrawl轉儲都使用高級MinHash技術單獨刪除重復數據,進一步提高了數據集的質量和實用性。<小編認為Minio其實也是可以的!>

關聯閱讀
2024年似乎已經打破了數據集方面的“4 分鐘英里”。盡管Redpajama 2提供了高達30T?的Tokens,但大多數在2023年的LLMs都使用高達2.5T?的Tokens進行訓練。隨后DBRX推出12T的Tokens,Reka Core/Flash/Edge 推出5T的Tokens,Llama 3推出15T的Tokens。現在Huggingface 發布了一個開放數據集,其中包含12年過濾和重復數據刪除的CommonCrawl的數據,總共有15T個Tokens。














)




