單目標檢測
單目標檢測(Single Object Detection)是人工智能領域中的一個重要研究方向,旨在通過計算機視覺技術,識別和定位圖像中的特定目標物體。單目標檢測可以應用于各種場景,如智能監控、自動駕駛、醫療影像分析等。
簡單來說,單目標檢測就是在確定一個目標在圖片中的位置:
?本文將以信號燈檢測為例,介紹單目標檢測的方法
環境準備
這個案例需要安裝以下兩個庫:
pip install paddlepaddle-gpu
pip install lxml數據集準備
本文采用如下數據集:紅綠燈檢測_練習_訓練集(非比賽數據)_數據集-飛槳AI Studio星河社區 (baidu.com)
這個數據集共有2000張信號燈的照片,其中1000張綠燈,1000張紅燈。每張照片都對應著一個xml文件,標注著信號燈在圖片中的位置:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<annotation><folder>Images</folder><filename>green_0.jpg</filename><source><database>Unknown</database></source><size><width>424</width><height>240</height><depth>3</depth></size><segmented>0</segmented><object><name>green</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><occluded>0</occluded><bndbox><xmin>247</xmin><ymin>147</ymin><xmax>301</xmax><ymax>190</ymax></bndbox></object>
</annotation>
這里面,<width>和<height>標簽分別定義了寬和高,<name>定義了樣本的類別(red或者green),<bndbox>里的標簽則是定義了信號燈的位置(矩形框)
接下來我們編寫dataset.py,用于定義數據集類:
import paddle
import glob
from lxml import etree
from PIL import Image
import numpy as np # 定義一個字典,將顏色名稱映射到ID
name_to_id = {'red': 0, 'green': 1} # 將絕對坐標轉換為相對坐標
def to_labels(path): # 讀取XML文件內容 text = open(f'{path}').read().encode('utf8') # 解析XML內容 xml = etree.HTML(text) # 提取圖像的寬度和高度 width = int(xml.xpath('//size/width/text()')[0]) height = int(xml.xpath('//size/height/text()')[0]) # 提取邊界框的坐標 xmin = int(xml.xpath('//bndbox/xmin/text()')[0]) xmax = int(xml.xpath('//bndbox/xmax/text()')[0]) ymin = int(xml.xpath('//bndbox/ymin/text()')[0]) ymax = int(xml.xpath('//bndbox/ymax/text()')[0]) # 將絕對坐標轉換為相對坐標 return xmin / width, ymin / height, xmax / width, ymax / height # 定義一個PaddlePaddle數據集類
class Dataset(paddle.io.Dataset): def __init__(self, pos='training_data'): super().__init__() # 調用父類構造函數 # 查找指定目錄下的所有.jpg圖片和.xml標簽文件 self.imgs = glob.glob(f'{pos}/*.jpg') self.labels = glob.glob(f'{pos}/*.xml') def __getitem__(self, idx): # 根據索引獲取圖片和標簽 img = self.imgs[idx] label = to_labels(self.labels[idx]) # 打開圖片并轉換為RGB模式 pil_img = Image.open(img).convert('RGB') # 將PIL圖片轉換為numpy數組,并轉換為float32類型 # 同時將通道順序從HWC轉換為CHW(PaddlePaddle默認輸入格式) t = paddle.to_tensor(np.array(pil_img, dtype=np.float32).transpose((2, 0, 1))) # 返回圖片張量和標簽張量 return t, paddle.to_tensor(label[:4]) def __len__(self): # 返回數據集中圖片的數量 return len(self.imgs)訓練腳本
單目標檢測可以看作一個回歸問題,輸出4個值,用于確定目標的坐標,因此我們可以使用resnet,并指定其類別數量為4(即輸出4個值),并采用MSE損失函數(因為這是回歸問題),據此,可以寫出訓練腳本的代碼:
import paddle
from dataset import Dataset # 初始化Dataset實例,設置數據位置為'training_data'
dataset = Dataset(pos='training_data') # 使用ResNet18網絡結構,并設置輸出類別數為4
net = paddle.vision.resnet18(num_classes=4)
# 將網絡封裝為PaddlePaddle的Model對象
model = paddle.Model(net) # 準備模型訓練,包括優化器(Adam)和損失函數(均方誤差損失)
model.prepare( paddle.optimizer.Adam(parameters=model.parameters()), paddle.nn.MSELoss(),
) # 訓練模型,設置訓練輪數為160,批處理大小為16
model.fit(dataset, epochs=160, batch_size=16, verbose=1) # 保存模型到'output/model'路徑
model.save('output/model')可以看到,訓練腳本還是非常簡單的。
簡單使用
使用腳本也很簡單:
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import numpy as np
from PIL import Image
import paddle # 圖片路徑
img_path = 'testing_data/red_1003.jpg'
# 打開圖片并轉換為RGB格式
pil_img = Image.open(img_path).convert('RGB')
# 將PIL圖片轉換為Paddle Tensor,并調整通道順序
t = paddle.to_tensor([np.array(pil_img, dtype=np.float32).transpose((2, 0, 1))]) # 加載ResNet18模型,并設置為4個類別
net = paddle.vision.resnet18(num_classes=4)
model = paddle.Model(net)
# 加載訓練好的模型權重
model.load('output/model') # 預測圖片
pred = model.predict_batch(t)[0][0]
print(f'預測結果:{pred}') # 根據預測結果計算邊界框坐標
xmin = float(pred[0]) * 424
ymin = float(pred[1]) * 240
xmax = float(pred[2]) * 424
ymax = float(pred[3]) * 240 # 顯示原始圖片
plt.imshow(np.array(t[0], dtype=np.int32).transpose((1, 2, 0))) # 定義多邊形的頂點坐標(這里是預測的邊界框)
vertices = np.array([[xmin, ymin], [xmin, ymax], [xmax, ymax], [xmax, ymin]])
# 創建一個多邊形對象,用于繪制邊界框
polygon = patches.Polygon(vertices, closed=True, edgecolor='black', facecolor='none')
# 將多邊形添加到當前坐標軸上
plt.gca().add_patch(polygon)
# 顯示圖片和邊界框
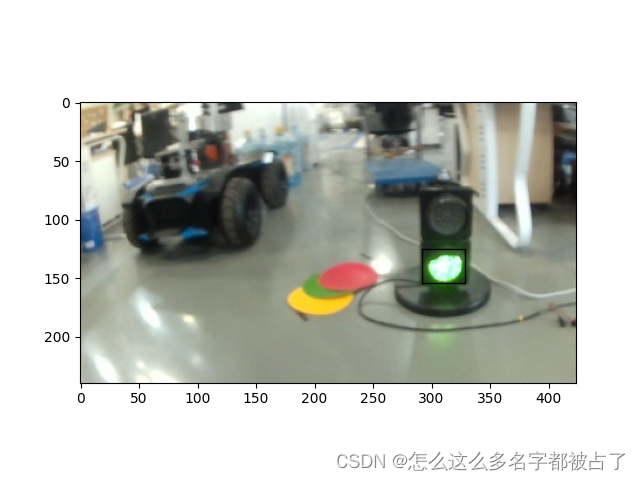
plt.show()輸出:



![AT_abc348_c [ABC348C] Colorful Beans 題解](http://pic.xiahunao.cn/AT_abc348_c [ABC348C] Colorful Beans 題解)


)

數據(全國/分省/分市))
)










