- 轉載于小林coding:https://www.xiaolincoding.com/network/1_base/how_os_deal_network_package.html
1. OSI七層模型
- 應用層,負責給應用程序提供統一的接口;
- 表示層,負責把數據轉換成兼容另一個系統能識別的格式;
- 會話層,負責建立、管理和終止表示層實體之間的通信會話;
- 傳輸層,負責端到端的數據傳輸;
- 網絡層,負責數據的路由、轉發、分片;
- 數據鏈路層,負責數據的封幀和差錯檢測,以及 MAC 尋址;
- 物理層,負責在物理網絡中傳輸數據幀;- 應用層,負責給應用程序提供統一的接口;
2. 數據傳輸過程
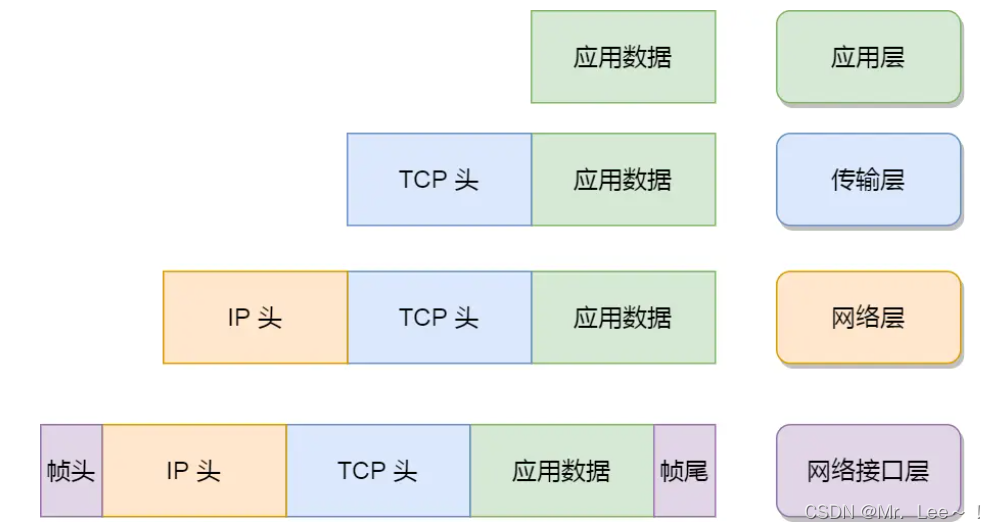
- 傳輸層,給應用數據前面增加了 TCP 頭;
- 網絡層,給 TCP 數據包前面增加了 IP 頭;
- 網絡接口層,給 IP 數據包前后分別增加了幀頭和幀尾;
- 數據鏈路層中并不能傳輸任意大小的數據包,所以在以太網中,規定了最大傳輸單元(MTU)是
1500字節,也就是規定了單次傳輸的最大 IP 包大小- 當網絡包超過 MTU 的大小,就會在網絡層分片,以確保分片后的 IP 包不會超過 MTU 大小
- 如果 MTU 越小,需要的分包就越多,那么網絡吞吐能力就越差
- 如果 MTU 越大,需要的分包就越少,那么網絡吞吐能力就越好
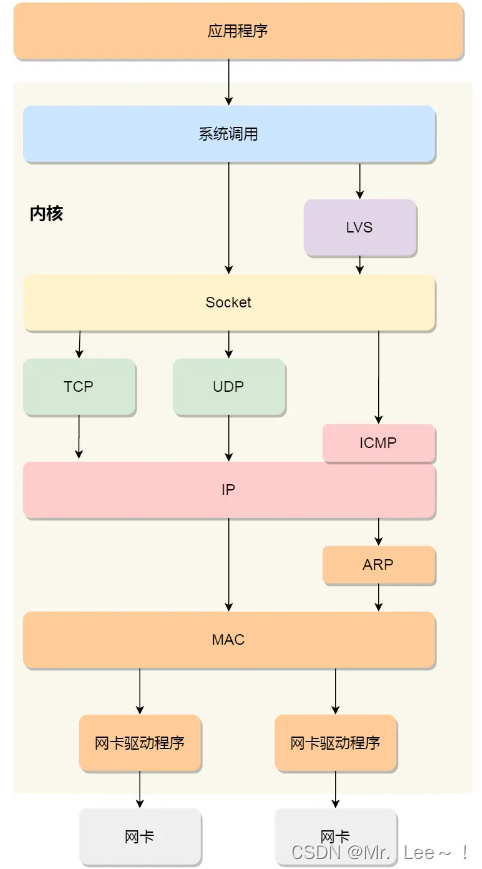
3. Linux 網絡協議棧
- 應用程序需要通過系統調用,來跟 Socket 層進行數據交互;
- Socket 層的下面就是傳輸層、網絡層和網絡接口層;
- 最下面的一層,則是網卡驅動程序和硬件網卡設備;
4. Linux 接收網絡包的流程
- 網卡是計算機里的一個硬件,專門負責接收和發送網絡包,當網卡接收到一個網絡包后,會通過 DMA 技術,將網絡包寫入到指定的內存地址,也就是寫入到 Ring Buffer ,這個是一個環形緩沖區,接著就會告訴操作系統這個網絡包已經到達。
- 告知操作系統網絡包已到達的方式:
- 觸發中斷:每當網卡收到一個網絡包,就觸發一個中斷告訴操作系統
- 問題:在高性能網絡場景下,網絡包的數量會非常多,那么就會觸發非常多的中斷,CPU收到中斷后會先去處理這件事,因此會影響系統的整體性能
- NAPI機制:混合「中斷和輪詢」的方式來接收網絡包,當有網絡包到達時,會通過 DMA 技術,將網絡包寫入到指定的內存地址,接著網卡向 CPU 發起硬件中斷,當 CPU 收到硬件中斷請求后,根據中斷表,調用已經注冊的中斷處理函數。
- 中斷處理函數:
- 先「暫時屏蔽中斷」,表示已經知道內存中有數據了,告訴網卡下次再收到數據包直接寫內存就可以了,不要再通知 CPU 了,這樣可以提高效率,避免 CPU 不停的被中斷。
- 接著,發起「軟中斷」,然后恢復剛才屏蔽的中斷。
- 軟中斷:內核中的 ksoftirqd 線程專門負責軟中斷的處理,當 ksoftirqd 內核線程收到軟中斷后,就會來輪詢處理數據(采用poll方法)。
- ksoftirqd 線程會從 Ring Buffer 中獲取一個數據幀,用 sk_buff 表示,從而可以作為一個網絡包交給網絡協議棧進行逐層處理。
- 網絡協議棧:
- 先進入到網絡接口層,在這一層會檢查報文的合法性,如果不合法則丟棄,合法則會找出該網絡包的上層協議的類型,比如是 IPv4,還是 IPv6,接著再去掉幀頭和幀尾,然后交給網絡層。
- 網絡層,則取出 IP 包,判斷網絡包下一步的走向,比如是交給上層處理還是轉發出去。當確認這個網絡包要發送給本機后,就會從 IP 頭里看看上一層協議的類型是 TCP 還是 UDP,接著去掉 IP 頭,然后交給傳輸層。
- 傳輸層取出 TCP 頭或 UDP 頭,根據四元組「源 IP、源端口、目的 IP、目的端口」 作為標識,找出對應的 Socket,并把數據放到 Socket 的接收緩沖區。
- 應用層程序調用 Socket 接口,將內核的 Socket 接收緩沖區的數據「拷貝」到應用層的緩沖區,然后喚醒用戶進程。
- 中斷處理函數:
- 觸發中斷:每當網卡收到一個網絡包,就觸發一個中斷告訴操作系統

5. Linux 發送網絡包的流程
- 首先,應用程序會調用 Socket 發送數據包的接口,由于這個是系統調用,所以會從用戶態陷入到內核態中的 Socket 層,內核會申請一個內核態的 sk_buff 內存,將用戶待發送的數據拷貝到 sk_buff 內存,并將其加入到發送緩沖區。
- 接下來,網絡協議棧從 Socket 發送緩沖區中取出 sk_buff,并按照 TCP/IP 協議棧從上到下逐層處理。
- 如果使用的是 TCP 傳輸協議發送數據,那么先拷貝一個新的 sk_buff 副本,因為 sk_buff 后續在調用網絡層,最后到達網卡發送完成的時候,這個 sk_buff 會被釋放掉。而 TCP 協議是支持丟失重傳的,在收到對方的 ACK 之前,這個 sk_buff 不能被刪除。所以內核的做法就是每次調用網卡發送的時候,實際上傳遞出去的是 sk_buff 的一個拷貝,等收到 ACK 再真正刪除。
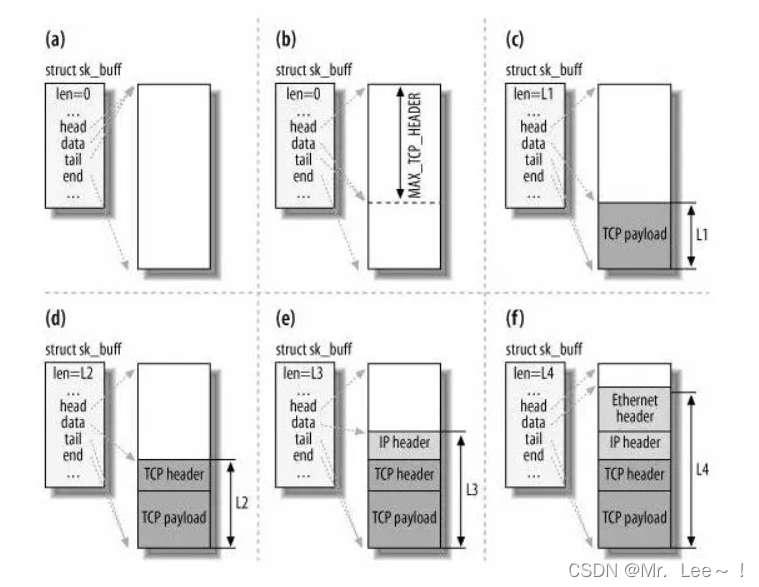
- 接著,對 sk_buff 填充 TCP 頭。sk_buff 可以表示各個層的數據包,在應用層數據包叫 data,在 TCP 層我們稱為 segment,在 IP 層我們叫 packet,在數據鏈路層稱為 frame。
- 全部數據包只用一個結構體來描述是因為:協議棧采用的是分層結構,上層向下層傳遞數據時需要增加包頭,下層向上層數據時又需要去掉包頭,如果每一層都用一個結構體,那在層之間傳遞數據的時候,就要發生多次拷貝,這將大大降低 CPU 效率。
- 只用 sk_buff 一個結構體來描述所有的網絡包不會發生拷貝,通過調整 sk_buff 中
data的指針來實現,比如:- 當接收報文時,從網卡驅動開始,通過協議棧層層往上傳送數據報,通過增加
skb->data的值,來逐步剝離協議首部。 -
- 當要發送報文時,創建 sk_buff 結構體,數據緩存區的頭部預留足夠的空間,用來填充各層首部,在經過各下層協議時,通過減少
skb->data的值來增加協議首部。
- 當要發送報文時,創建 sk_buff 結構體,數據緩存區的頭部預留足夠的空間,用來填充各層首部,在經過各下層協議時,通過減少
- 當接收報文時,從網卡驅動開始,通過協議棧層層往上傳送數據報,通過增加
-
到達網絡層的主要工作:選取路由(確認下一跳的 IP)、填充 IP 頭、netfilter 過濾、對超過 MTU 大小的數據包進行分片。處理完這些工作后會交給網絡接口層處理。
- 網絡接口層會通過 ARP 協議獲得下一跳的 MAC 地址,然后對 sk_buff 填充幀頭和幀尾,接著將 sk_buff 放到網卡的發送隊列中。
- 這一些工作準備好后,會觸發「軟中斷」告訴網卡驅動程序,這里有新的網絡包需要發送,驅動程序會從發送隊列中讀取 sk_buff,將這個 sk_buff 掛到 RingBuffer 中,接著將 sk_buff 數據映射到網卡可訪問的內存 DMA 區域,最后觸發真實的發送。
- 當發送完成的時候,網卡設備會觸發一個硬中斷來釋放內存,主要是釋放 sk_buff 內存和清理 RingBuffer 內存。
- 最后,當收到這個 TCP 報文的 ACK 應答時,傳輸層就會釋放原始的 sk_buff 。
-
問題:發送網絡數據的時候,涉及幾次內存拷貝操作?
- 第一次,調用發送數據的系統調用的時候,內核會申請一個內核態的 sk_buff 內存,將用戶待發送的數據拷貝到 sk_buff 內存,并將其加入到發送緩沖區。
- 第二次,在使用 TCP 傳輸協議的情況下,從傳輸層進入網絡層的時候,每一個 sk_buff 都會被克隆一個新的副本出來。副本 sk_buff 會被送往網絡層,等它發送完的時候就會釋放掉,然后原始的 sk_buff 還保留在傳輸層,目的是為了實現 TCP 的可靠傳輸,等收到這個數據包的 ACK 時,才會釋放原始的 sk_buff 。
- 第三次,當 IP 層發現 sk_buff 大于 MTU 時才需要進行。會再申請額外的 sk_buff,并將原來的 sk_buff 拷貝為多個小的 sk_buff。













)
)
)



