國內外主流大模型語言技術對比 2024
自2017年起,美國深度布局人工智能,全面融入經濟、文化與社會。至2023年,中國憑借自研技術平臺嶄露頭角,ChatGPT及其技術成國家戰略焦點,引領未來科技浪潮。中美競逐,人工智能正重塑全球格局。
GPT-3作為核心變革,憑借海量參數與創新的“提示語”理念,大幅增強自然語言理解與生成能力,廣泛應用于情感分析、機器翻譯等領域,引領技術革新。
ChatGPT采用GPT-3.5的人類反饋強化學習,顯著提升語言生成能力,靈活適應新指令,突破傳統參數依賴,展現強大技術實力。
OpenAI的戰略轉型、技術革新、巨資投入、強大算力與頂尖團隊,共筑ChatGPT成功基石,成就行業典范。
ChatGPT憑借GPT-3.5技術,在準確性、多任務處理及泛化能力上領先市場,但面臨時效性、成本及專業領域局限挑戰。國際巨頭如Google、Meta在技術研發與商業應用上保持優勢。ChatGPT通過API與訂閱模式搶占市場先機,而Google、百度則深耕B端市場,競爭激烈。
中國通用大型語言模型發展勢頭強勁,百度、華為等公司緊追國際潮流,然而,數據、算力與工程化實施仍是其面臨的挑戰。
語言大型模型的國際研發現狀呈現明顯的區域差異。
在國際科研舞臺,Geoffrey Hinton(愛丁堡大學)、Tomas Mikolov(布爾諾理工大學)、Chris Manning與Quoc Le(斯坦福大學)、以及Ilya Sutskever(多倫多大學)等領軍人物,憑借前沿技術引領創新浪潮,他們的杰出貢獻展現了科研領域的非凡實力與深遠影響。
國內語言大模型研發領域頂尖團隊頻頻突破,如清華大學的唐杰教授、孫茂松教授、朱小燕教授、張亞勤,復旦大學的邱錫鵬教授團隊,以及哈爾濱工業大學的王曉龍教授等,他們在自然語言處理AI底層技術研究中取得新進展,展現了中國在該領域的強大實力與創新能力。
大型語言模型革新了數字產業的人機交互,增強軟件用戶友好性與功能。它們關鍵性地降低了企業應用構建成本,推動新生態平臺發展,并顯著提升對話式AI產品的智能感知能力。同時,這些模型引領多行業功能升級與生態整合,引領產業未來。
ChatGPT等大型AI模型崛起,引領商業創新,卻亦引發安全倫理挑戰,如角色替代、數據偏見、隱私泄露等。業界與科研人員對此質疑,呼吁審慎發展。為應對風險,已采用基于人類反饋的強化學習及監管框架等措施,確保AI健康、可持續發展。
GPT-4等通用人工智能(AGI)技術不僅提升生產力、驅動經濟增長,更重塑人類思維與文化傳統,引領學科革新。本報告旨在為ChatGPT技術及產業提供發展指引,推動產業協作,共創行業繁榮,邁向健康、快速的發展新紀元。
一、ChatGPT 的技術研發基礎
ChatGPT,作為OpenAI的杰作,是引領未來的聊天式生成預訓練語言模型。這一基于大規模預訓練的生成式AI系統,將人工智能的交互體驗提升至全新高度。
該模型汲取了GPT系列模型精髓,專注于理解和生成自然語言,為用戶提供宛如真人的對話體驗。它立足于自然語言處理(NLP)這一計算機科學和人工智能的核心領域,致力于實現計算機對人類語言的深度理解和自然生成,引領人機交互進入全新境界。
NLP技術歷經數十年演變,從規則到統計,再到深度學習,實現質的飛躍。特別是近年來,深度學習技術尤其是預訓練語言模型(如GPT系列)的崛起,極大地推動了NLP領域的突破性進展。
(一)自然語言處理的發展歷史
自然語言處理融合計算機科學、人工智能與語言學,歷經研究范式變革,展現跨學科魅力,引領智能語言理解新潮流。
自然語言處理早期依賴小規模專家知識,手動設計規則和知識庫應對歧義與抽象性,但難應對大規模數據和復雜任務。隨著機器學習崛起,計算機能通過學習樣本自動處理語言,顯著提升處理效率與準確性。
采用本數據進行自然語言處理雖在某些特定任務中表現出色,但面對復雜任務時,受限于訓練數據和特征工程,效果受限。隨著深度學習崛起,基于深度神經網絡的自然語言處理方法嶄露頭角,通過多層網絡提取特征和語義表示,輕松應對大規模數據和復雜任務,但計算資源和標注數據需求更高。
近期,大規模預訓練語言模型在自然語言處理領域備受矚目。該方法利用海量語料庫預訓練,學習通用語言與知識表示,以少量標注數據高效解決多任務,效果顯著。
表 1-1 知識表示和調用方式的演進
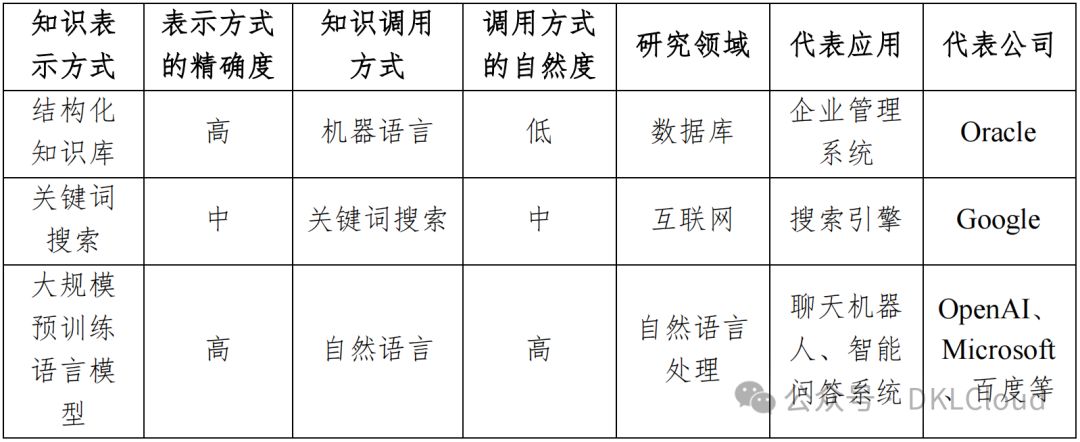
語言理解將自然語言轉化為計算機可處理的分詞、詞性標注、句法分析;而語言生成則將處理結果轉換為自然語言回答、摘要,實現人機交互的順暢。
早期自然語言處理依賴規則與專家知識,如語法、詞典與邏輯規則,但僅適用于小規模任務。隨著數據量與任務復雜度激增,基于規則的方法已難以為繼,急需創新方法應對挑戰。
隨著機器學習和深度學習的發展,自然語言處理研究進入了新的階段。
深度學習引領自然語言處理革新,其神經網絡特征提取與語義表示技術,精準解決語言歧義與抽象難題,成效顯著,開啟智能語言處理新篇章。
近年來,隨著大規模預訓練語言模型的興起,自然語言處理的研究進入了新的階段。基于大規模預訓練語言模型的自然語言處理方法,如 BERT(Bidirectional Encoder Representations from Transformers)、GPT 等,通過預訓練模型來學習通用的語言表示和知識表示,可以用較少的標注數據解決多個任務,并取得了極好的效果。這種方法的出現,使得自然語言處理能夠處理更多的語言任務和應用,如機器翻譯、問答系統、文本分類、情感分析等。
自然語言處理飛速發展,關鍵技術和算法如詞嵌入、文本向量化、注意力機制和序列模型等,為其奠定了堅實基礎。這些創新技術持續推動自然語言處理向前,使其成為人工智能領域不可或缺的重要力量,引領著人工智能應用的廣泛發展。
自然語言處理廣泛應用于搜索引擎、智能客服、語音識別、翻譯、情感分析、智能寫作等領域。尤其在人機對話中,如聊天機器人、智能問答系統,其技術提升機器理解與表達能力,實現自然流暢的人機交流。隨著技術不斷發展,自然語言處理將在更多行業發揮關鍵作用。
(二)大規模預訓練語言模型的技術發展
圖 1-1 簡要介紹了大模型的發展歷程。
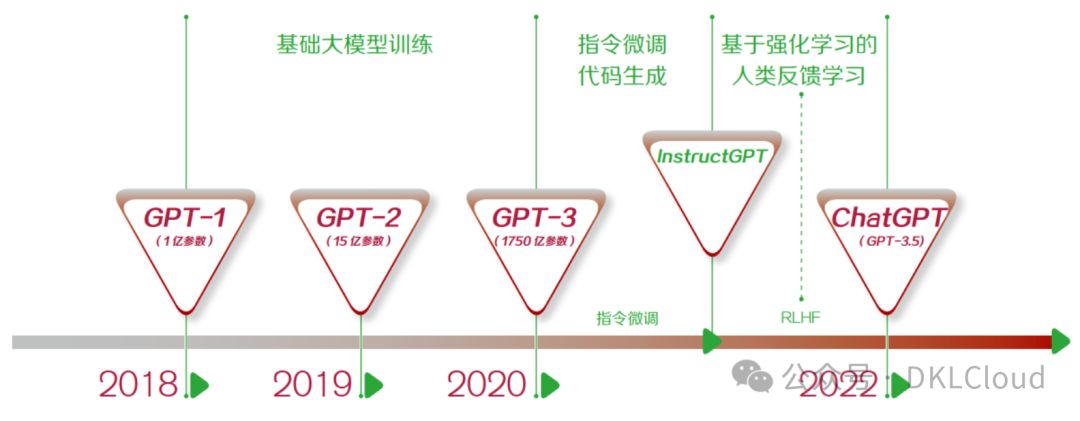
圖 1-1 大規模預訓練語言模型發展歷程及重要概念
2018年,OpenAI首推GPT模型,引領自然語言處理預訓練風潮。盡管初期未獲廣泛矚目,后起之秀BERT風頭更勁。但OpenAI堅持創新,接連推出GPT-2、GPT-3,持續推動自然語言處理領域的技術革新。每一步的突破,都預示著AI語言處理能力的巨大飛躍。
GPT-3模型卓越非凡,搭載1,750億參數,并引入“提示語”創新理念。無需調整模型,僅憑特定任務提示,即可高效完成任務。如輸入“我太喜歡ChatGPT了,這句話的情感是__”,GPT-3即能精準回應“褒義”,展現其卓越性能。
增加輸入中的示例可顯著提升任務完成效果,此現象稱為“語境學習”。欲了解更多技術細節,建議查閱相關綜述文章,以獲取更深入的解析與指導。
GPT-3雖備受矚目,但其在魯棒性、可解釋性和推理能力上仍有局限,與人類深層語義理解相去甚遠。然而,ChatGPT的推出徹底顛覆了我們對大模型的認知,展現出前所未有的能力,為AI領域注入了新的活力。
二、OpenAI ChatGPT 技術發展歷程
(一)ChatGPT:生成式 AI 里程碑
ChatGPT,即Chat Generative Pre-trained Transformer,在連續對話、內容質量、語義識別及邏輯推斷上均顯著超越傳統對話解決方案,大幅超出市場對聊天機器人的預期,標志著生成式人工智能(AIGC)的重要突破,如圖2-1所示,ChatGPT無疑是該領域的里程碑之作。
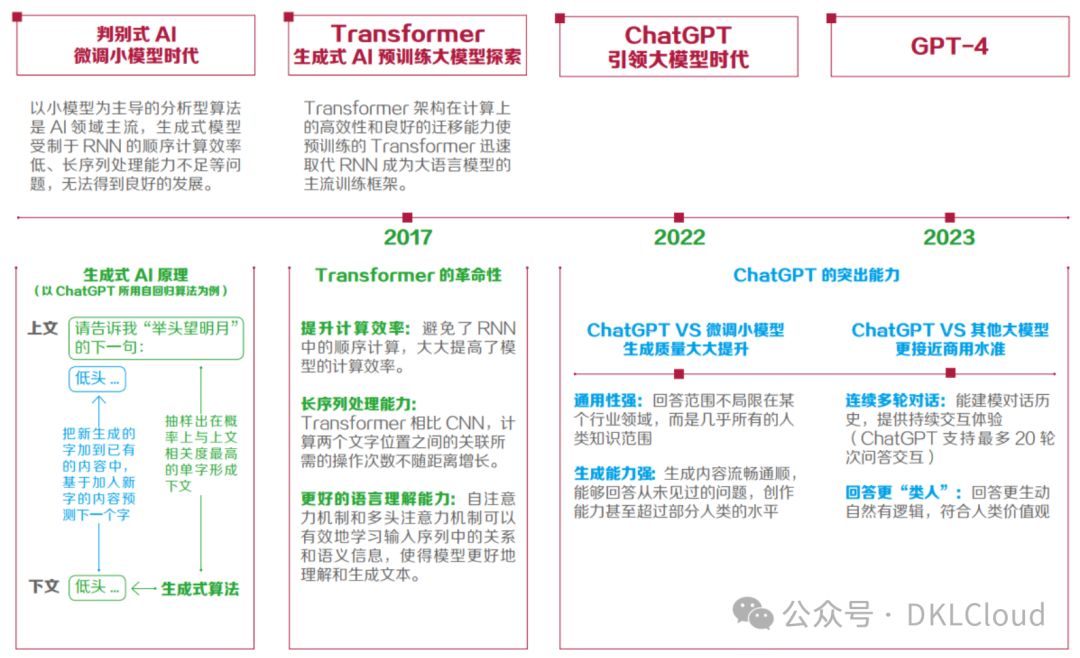
圖 2-1 生成式 AI 發展歷程與 ChatGPT 的突出能力
這款模型是強大的生成式預訓練大語言模型,以“Chat”彰顯其互動魅力,通過“Generative”展現卓越的生成算法實力。
生成式算法曾受循環神經網絡(RNN)局限,但2017年Transformer架構的突破,為生成式AI帶來了飛躍。這一創新架構成功解決了過往瓶頸,讓生成式AI在預訓練Transformer框架下實現顯著發展。
該模型引領自然語言處理、計算機視覺及多模態領域通用大模型迅速演進,其參數量的幾何級增長與多元化訓練策略的探索,標志著大型通用模型正打破NLP領域小型模型主導的傳統模式,展現出強大的發展潛力和廣闊的應用前景。
(二)ChatGPT 核心技術:人類反饋強化學習
ChatGPT依托GPT-3.5超大預訓練模型,通過人性化需求優化,顯著提升了語言生成能力,為用戶帶來卓越體驗。
借助RHLF技術,我們精調模型指令,激活多維能力,確保輸出貼合人類需求、偏好與價值觀。這一創新提升了模型對新指令的適應性,如圖2-2所示,使模型更加智能、靈活,滿足不斷變化的人類期望。
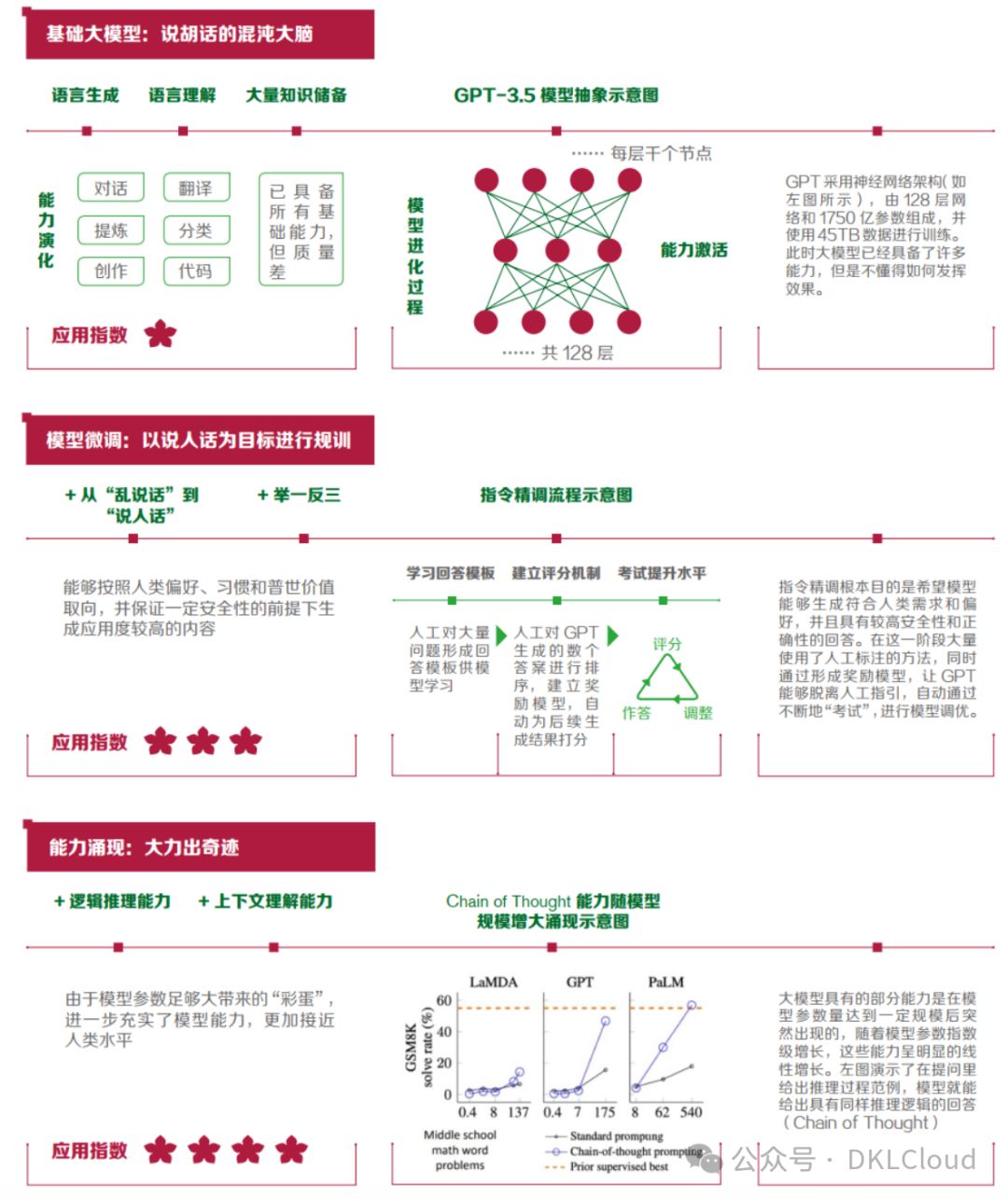
圖 2-2 ChatGPT 能力實現解析
ChatGPT在邏輯推理和上下文理解上的卓越表現,并非單純由參數量驅動,而是達到一定規模后自然涌現的能力。這種“能力涌現”已在其他大規模預訓練模型中證實,彰顯其獨特優勢。
(三)OpenAI ChatGPT 成功要素分析
OpenAI的轉型為ChatGPT的商業化奠定了堅實基礎,引領市場新風向。其堅守實現安全通用人工智能的初心,創始團隊憑借第一性原理定位研發,突破技術瓶頸,確立了在通用AI領域的領軍地位,如圖2-3所示,彰顯其卓越實力與堅定決心。
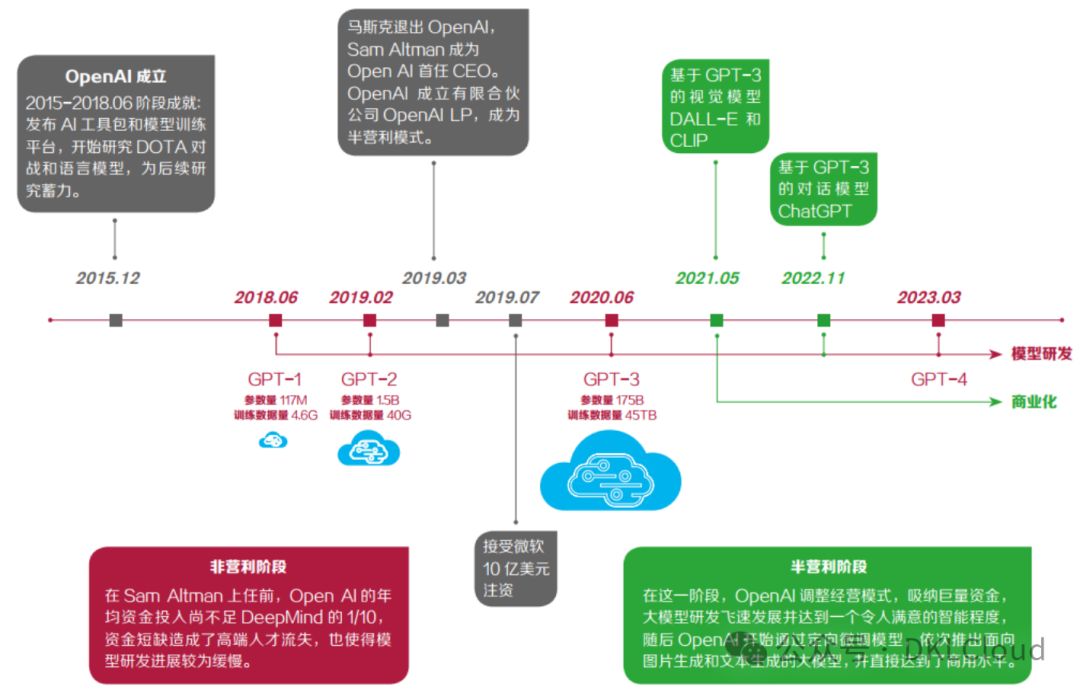
圖 2-3 資金投入與發展策略為 ChatGPT 成功帶來至關重要的影響
在數據方面,GPT-3 模型訓練了高達 45TB 的數據,涵蓋數千萬本文學作品。
在GPT系列的發展中,從GPT-1到ChatGPT,投入資金高達數十億美元,涵蓋數據采集、模型訓練、運營及人力資源。算力層面,OpenAI攜手微軟Azure,運用約1萬塊NVIDIA A100 GPU,確保模型高效運行,展現對先進技術的堅定投資與不懈追求。
ChatGPT的成功,人才因素尤為關鍵。其核心團隊匯聚了87名全球頂尖AI專家,他們大多來自斯坦福、伯克利和麻省理工等名校,其中更有5人榮登2023年“AI 2000全球人工智能學者”榜單。其成功正是初心、數據、資金、算力與人才等多維度要素共同作用的必然結果。
三、國內外主要大語言模型技術對比
(一)ChatGPT 的優勢
ChatGPT作為開年爆品,三個月內狂攬億級用戶,憑借卓越的全面性、準確性、流暢性與可玩性,贏得了廣泛贊譽。
相較于其他產品和范式,ChatGPT 在以下三個方面具有優勢:
ChatGPT超越常規聊天機器人,如微軟小冰、百度度秘。其精準流暢的回答、細致推理與卓越任務完成能力,得益于其強大的底座、思維鏈推理及零樣本能力,為用戶帶來前所未有的智能交互體驗。
ChatGPT經GPT-3.5系列Code-davinci-002精細微調,擁有龐大規模,記憶海量知識,并展現獨特涌現潛力。它顛覆傳統scaling law,實現逐步推理。通過指令微調,ChatGPT具備出色泛化能力,輕松應對未知任務,顯著提升其通用性[7],展現卓越智能魅力。
相較于其他大規模語言模型:ChatGPT 通過更多的多輪對話數
ChatGPT通過指令微調,建模對話歷史,實現持續用戶交互。其獨特的基于人類反饋的強化學習在微調階段,調整模型輸出偏好,使結果更貼近人類預期,超越其他大規模語言模型。
ChatGPT緩解安全性和偏見問題,確保耐用性。通過真實用戶反饋,實現AI正循環,強化人機對齊能力,持續輸出安全、精準的回復。
ChatGPT革新自然語言處理:在零樣本和少樣本場景下,其泛化能力遠超微調小模型,即便面對未見任務也能有所作為。相較之前依賴特定任務數據微調的模式,ChatGPT展現出了更強的適應性和效果。例如,InstructGPT作為其前身,即便以英語指令為主,仍能應對多樣語言挑戰。
ChatGPT在機器翻譯中,竟能精準翻譯未包含在指令集中的塞爾維亞語,展現非凡的泛化能力。其作為大型語言模型,在創作型任務上更是出類拔萃,實力超越多數普通人,令人矚目。
ChatGPT卓越能力源自GPT-3.5底座,卓越思維鏈推理與零樣本能力,并通過人類反饋強化學習優化模型偏好。其在準確性、流暢性、任務完成與泛化能力上均領先,為自然語言處理領域帶來無限可能。ChatGPT的強大,預示著自然語言處理技術的嶄新篇章。
(二)ChatGPT 的劣勢
大規模語言模型自身的局限:作為大規模語言模型,ChatGPT面臨多個限制和挑戰。
其次,由于模型不能實時更新,其回答的時效性受到限制,特別是在快速變化的知識領域。
模型回答因生成算法(如Beam Search或采樣)及對輸入的敏感性,存在不穩定和不一致現象,凸顯了當前大規模語言模型在實用性和可靠性上的局限(如表3-1所示),需進一步改進與優化。
表 3-1 ChatGPT 存在不足的示例


ChatGPT的局限性源于其基于現實語言數據預訓練的大規模模型。數據偏見可能導致生成有害內容,盡管RLHF方法有所緩解,但仍需謹慎應對誘導。此外,作為OpenAI部署的工具,用戶數據的安全亦需關注,長期大規模使用存在數據泄漏風險,需采取相應防護措施。
標注策略導致的局限:ChatGPT 雖然通過基于人類反饋的強化學習優化了生成結果,但這也帶來了標注人員偏好和潛在偏見的問題。模型還傾向于生成更長、看似全面的答案,但這在某些情境下反而顯得啰嗦。
盡管作為突圍型產品表現優秀,ChatGPT 在某些特定場景下可能不是最高性價比的解決方案。例如,對于不需要大規模 生 成 能 力 或 額 外 知 識 的 自 然 語 言 理 解 ( Natural Language Understanding,NLU)任務,微調小模型可能更適用;在機器閱讀理解或非英文的機器翻譯任務中,其表現也可能受限。大模型的現實世界先驗知識很難通過提示來覆蓋,導致糾正事實錯誤變得困難。
表3-1揭示了ChatGPT的不足之處(基于2023年2月24日測試),其在獨特答案和符號邏輯推理任務中表現欠佳,且尚不支持多模態數據處理。
因此,在商業應用中,選擇 NLP 技術時需要綜合考慮任務需求、成本和性能。
(三)中國自研通用基礎大語言模型
2023年3月,OpenAI震撼發布GPT-4架構的ChatGPT,實現多模態交互,長文本理解與生成能力顯著優化,可控性突破顯著。這一創新引領全球科技界,引發強烈關注與討論。
中國科技投資界矚目,百度緊跟潮流,推出“文心一言”。雖與ChatGPT在功能、成熟度及并發處理上存差距,但此舉彰顯中國在全球科技競賽中的積極姿態,開啟新一輪科技探索的篇章。
百度已啟動API開放測試,精準定位B端市場。科技巨頭們如360、阿里、華為、商湯、京東、科大訊飛、字節跳動等亦不甘示弱,紛紛加速戰略部署,結合各自業務生態,探索多元化戰略路徑,共同推動行業創新發展。
大模型技術將成為企業競爭的核心資源,領跑者將在應用層和算力層雙獲優勢,掌握更多營收話語權,贏得未來市場的主導地位。
自研通用大語言模型(LLM)至關重要。自主可控是網絡和信息安全的核心,自研模型在全球格局中具備戰略價值。從實力上看,僅中國頂尖互聯網公司憑借算力、數據、算法、人才及資金的齊備,具備研發LLM的可行條件。
參與者各選戰略路線,但預見未來,掌握先進大模型和生態系統的企業將占據應用至算力層營收的制高點,主導話語權。

圖 3-1 通用基礎大語言模型的價值與自研卡點
在通用基礎大語言模型的研發和應用方面,價值與挑戰并存(如圖 3-1 所示)。
自主可控模型在全球政治經濟格局中戰略價值凸顯,規避數據跨境風險,滿足政企私有化部署需求,更可抵御美國科技保護主義,其重要性不言而喻。
更進一步,如能成功開發,其將像“超級大腦”一樣,成為具有巨大商業價值的資產。
實現這一目標頗具挑戰,難點在于美國芯片禁令影響高端AI算力,中文高質量數據資源匱乏,以及分布式訓練、模型蒸餾等關鍵技術和工程能力的研發需求。
實現“know-how”數據向問答能力的高效轉化,離不開提示工程師的深入參與。盡管潛力巨大,但仍需應對多重復雜挑戰與限制,確保轉化過程的順利進行。
隨著ChatGPT大模型技術嶄露頭角,結合中國AI產業鏈及競爭格局,行業巨頭掌握通用基礎大模型正逐步侵蝕垂直領域廠商市場份額,成為行業新趨勢。
長遠來看,這種壓力不容忽視。但關鍵在于大模型與產品、應用的深度融合,這依賴于垂直數據、行業專長、定制場景、用戶反饋及端到端工程能力,這些因素共同構筑了成功的基石。
垂直領域和應用層廠商應緊抓時機,深度融合大模型技術與自有技術棧,優化產品功能,筑牢“數據飛輪”壁壘。隨著大語言模型和AIGC應用需求激增,將涌現一批專注于大模型開發平臺服務的工具型、平臺型企業,助力客戶高效開發實施AIGC應用,共創智能未來。
中國大語言模型產業鏈中,通用基礎大模型作為核心,以其龐大參數和高度通用性,奠定產業基石。垂直基礎大模型和工具平臺構筑中間層,與應用產品相輔相成。這一架構高效整合,共同推動產業發展。
垂直基礎大模型與工具平臺由通用廠商賦能,專為應用層廠商或產品開發提供專業服務。此類廠商亦能獨立開發應用產品,其參數量級與通用性有別于通用模型,展現了高度的專業性和實用性。
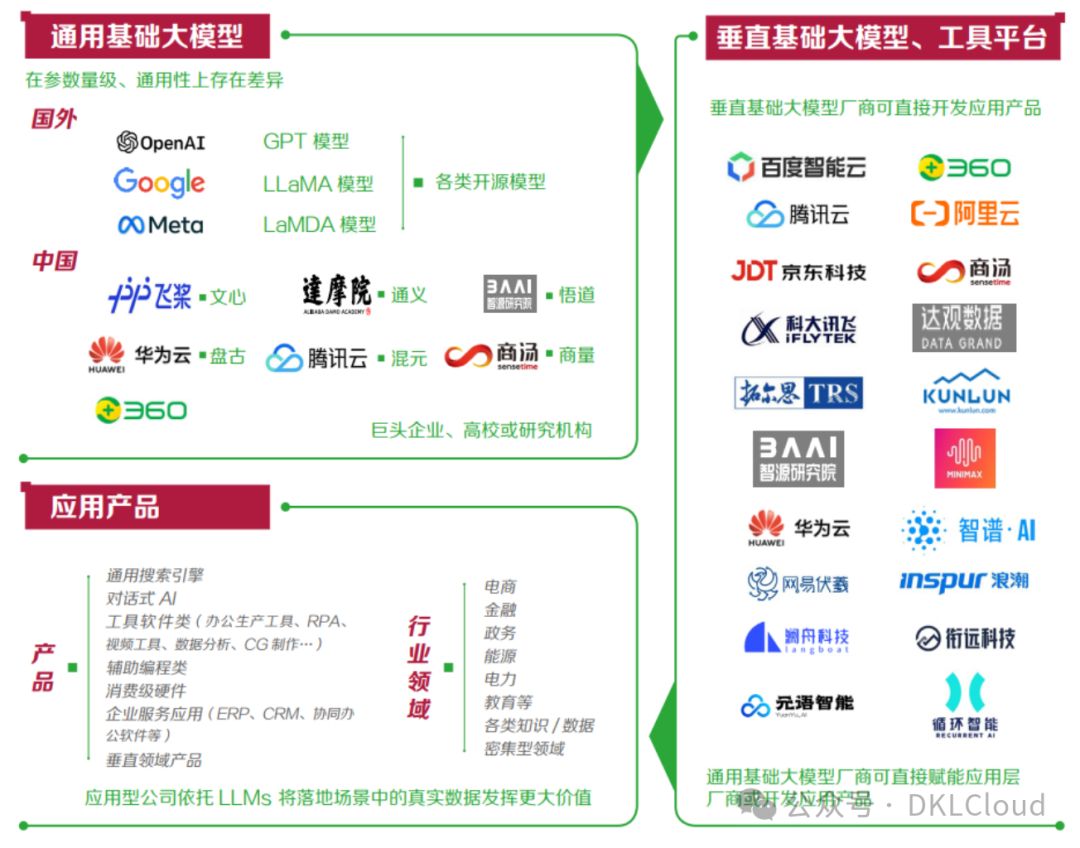

圖 3-2 中國大語言模型產業價值鏈
算法與模型構筑價值鏈核心,而算力與數據基礎設施是不可或缺的基石。算力支撐大模型訓練與運行,數據提供豐富訓練素材與用戶反饋,二者共同鑄就健壯高效的大語言模型生態系統,推動產業蓬勃發展。
(四)國內外語言大模型對比
這些公司在激烈的競爭中不斷激發創新,推動大型語言模型蓬勃發展,以API和開源形式廣泛開放,為開發者提供了前所未有的便利與機遇。
本報告表3-2對比了知名文本大規模預訓練模型,涵蓋參數量、輸入長度限制、訪問方式與模型微調等關鍵指標,為您全面呈現各模型性能差異。
根據表 3-2 的觀察,幾個關鍵點顯而易見:
OpenAI和Google在文本大型語言模型領域顯著領先,憑借先發優勢和市場主導,推動行業發展,并構建了龐大的家族式模型集群。
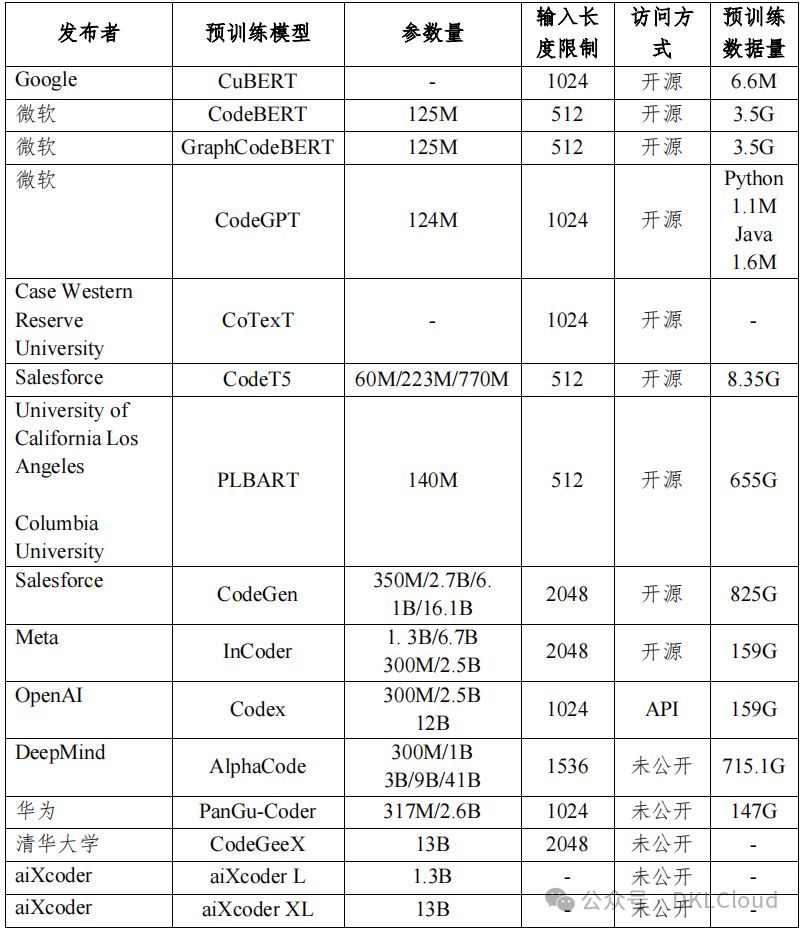
代碼預訓練模型成為研究新寵,其在代碼任務上表現出卓越性能。本報告表3-3概述了代碼領域的預訓練模型,揭示其前沿發展。
國內技術與ChatGPT的差距主要集中在大模型環節,涉及數據清洗、標注精度、模型設計創新及訓練推理技術積累等方面。
ChatGPT憑借文本/跨模態大模型、多輪對話、強化學習等技術的融合創新領先,而國內多數科技企業和院所僅聚焦垂直應用,缺乏跨技術融合創新實力。
國內頭部企業已涉足相關技術研發,但尚無匹敵ChatGPT的大模型產品。由于大模型訓練成本高昂,涉及億級投入與海量試錯,國內企業研發投入不足,導致研發推廣和產業落地滯后于海外同行。
表 3-2 大規模文本預訓練模型對比表
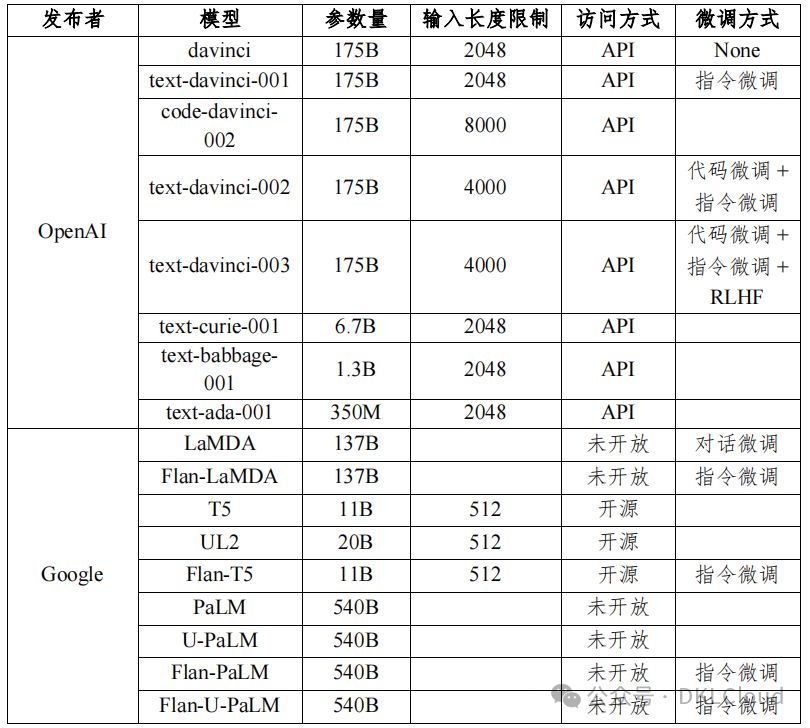
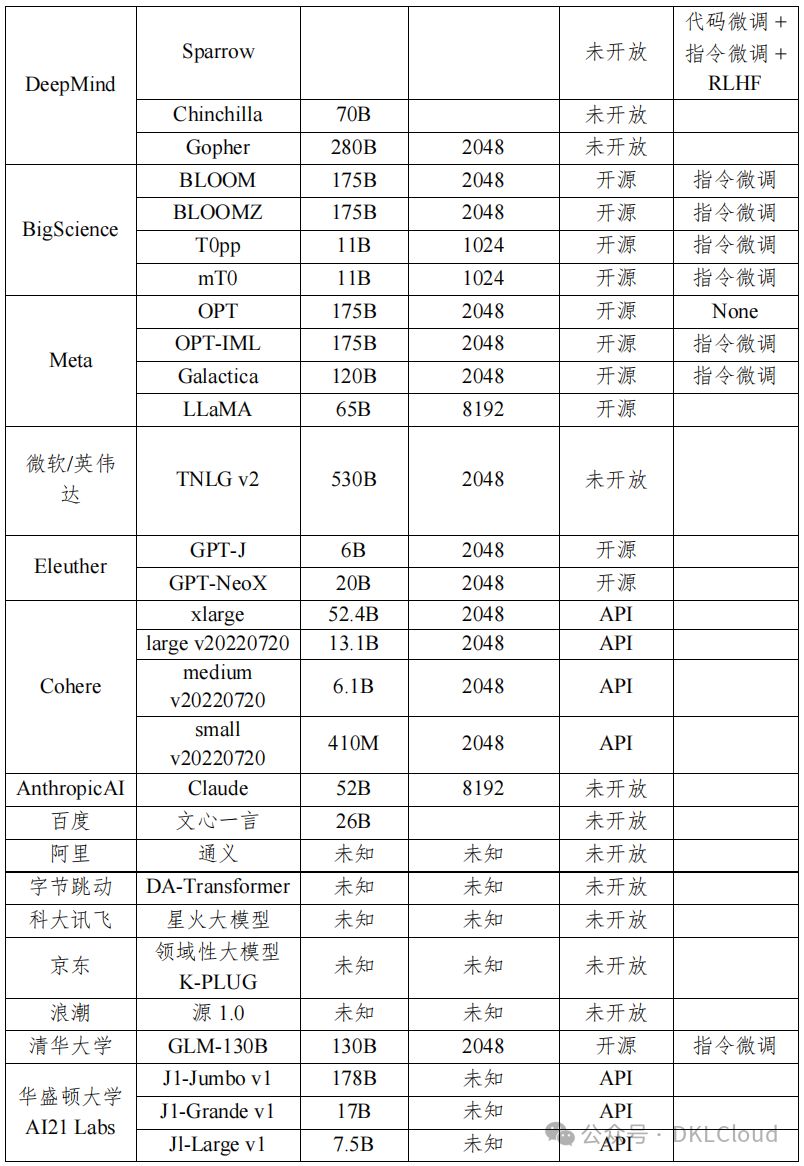
表 3-3 代碼預訓練模型對比表
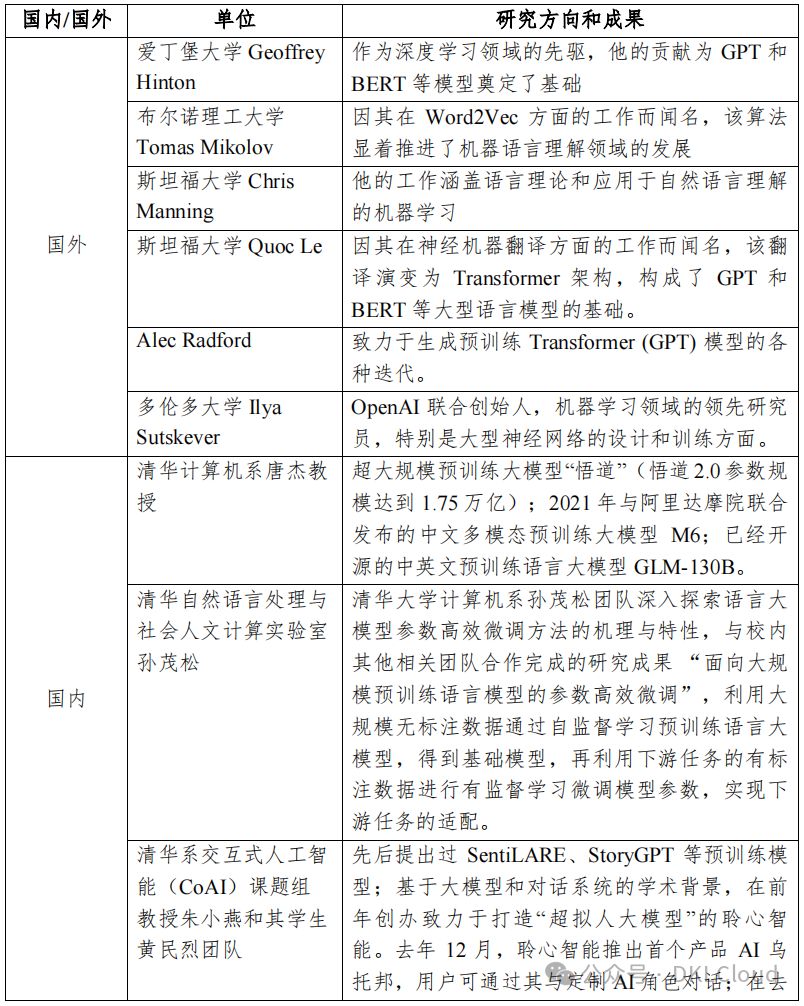
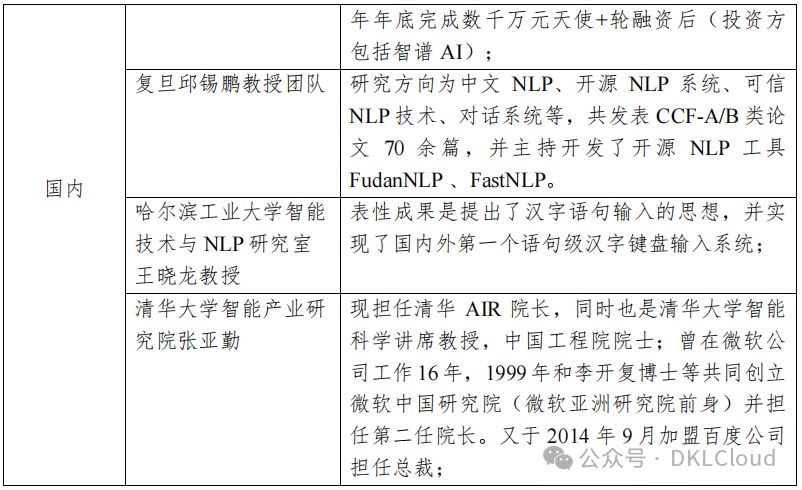
語言大模型研發技術國內外差異顯著,表3-4精選了國內外頂尖研究機構及其卓越成果,展現了語言模型領域的研發現狀。
中美語言大模型研發技術對比:美國在端到端語言大模型研發上領先,而中國雖有進展,但仍存在顯著差距,需繼續努力以追趕國際前沿。
表 3-4 語言大模型研發技術國內外主要研究機構及代表性成果
(六)大模型訓練:領先公司硬件資源全面對比
人工智能與大語言模型訓練蓬勃發展,全球頂尖科技公司與研究機構競相投入高端硬件資源,力求在性能與效率上實現新突破。
OpenAI憑借前沿AI技術,運用800張NVIDIA A100顯卡,耗電1500千瓦時,高效訓練GPT系列模型。而Google則借助自研TPU v4,部署1000張顯卡,耗電約1300千瓦時,支撐大規模機器學習項目。兩者均展示了在AI領域的強大實力與高效能耗管理。
Meta憑借900張NVIDIA V100顯卡,耗電1400千瓦時,為虛擬現實與增強現實技術賦能。而百度則精選700張AMD Instinct MI100顯卡,耗電僅1200千瓦時,加速自動駕駛與智能搜索的突破。兩大科技巨頭分別通過尖端顯卡布局,推動各自關鍵業務飛速發展。
清華大學,中國頂尖教育研究機構,在AI領域展現實力,采用600張NVIDIA A30顯卡,耗電量僅約1000千瓦時,高效驅動各類學術研究與創新項目,為科技進步注入強勁動力。
大語言模型訓練領域競爭激烈,業界領先顯卡與自主硬件齊頭并進,推動硬件技術革新,為AI未來奠定堅實基礎。
(七)國內外主要大語言模型研發路徑與技術對比
在全球大語言模型(LLMs)的競賽中,ChatGPT、Gopher、LaMDA、Llama等國際巨頭樹立標桿,而國內百度“文心一言”、360大語言模型、阿里“通義千問”和商湯“商量”等亦引領風潮。當前,ChatGPT在對話與文本生成能力上略勝一籌,但這技術壁壘并非不可打破,國內巨頭亦展現強勁實力。
Google等國際巨頭因戰略和技術理念差異暫時落后,但新技術涌現使趕超ChatGPT成為可能。國內如百度等企業,在數據集、計算及工程化上存短板,短期難以趕超國外模型。實現突破需國內AI產業全鏈條協同進步,共創未來。
大語言模型性能受訓練數據、模型規模、生成算法與優化技術影響顯著。量化其影響尚在探索中,結論未明。目前,世界頂尖大語言模型在技術層面未顯顯著差距,仍需深入研究以揭示各因素的具體作用。
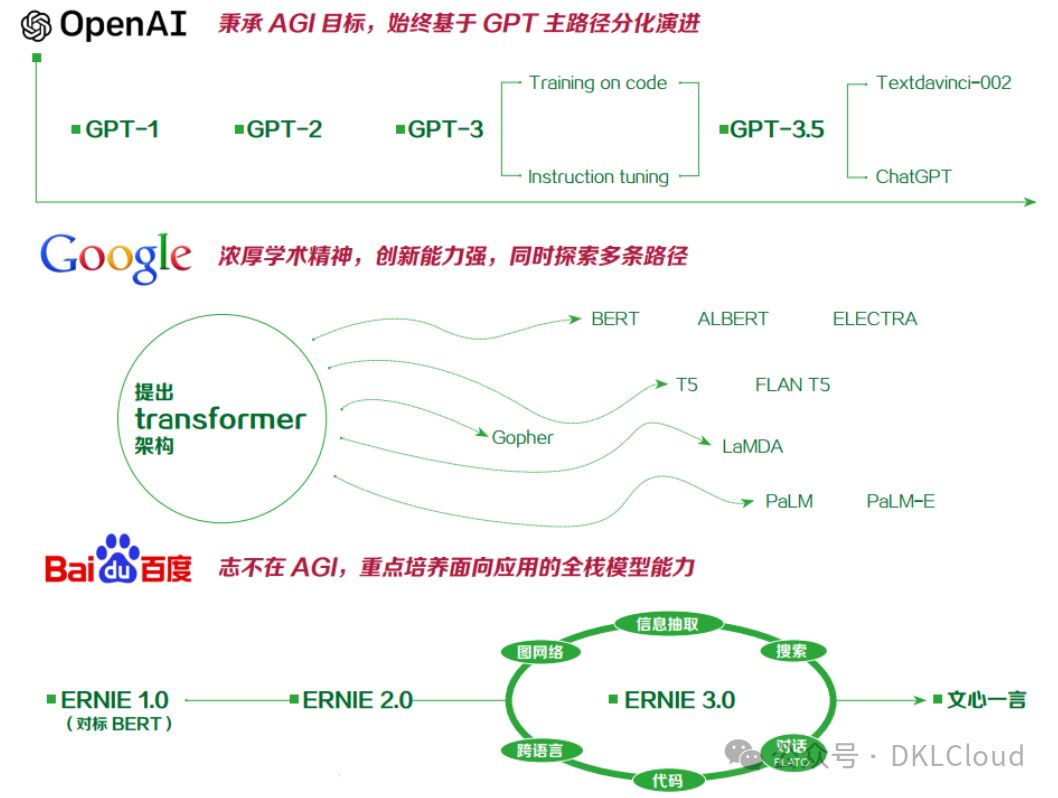
圖 3-3 國內外主要大語言模型研發路徑與技術對比
(八)國內外主要大語言模型廠商商業路徑對比
ChatGPT在戰略拓展上確立了獨特的商業路徑,聚焦API、訂閱制及戰略合作(如與微軟Bing、Office的嵌入合作)三大營收模式。其在用戶數據積累、產品布局及生態建設上已搶占先機,展現出顯著的優勢。
Google作為搜索引擎巨頭,對聊天機器人等創新相對保守,更傾向運用大模型能力推進“模型即服務”,拓展云服務市場份額。百度作為國內大模型領軍企業,戰略緊隨Google,專注于B端市場,憑借全棧優勢構建全鏈能力,引領行業潮流。

圖 3-4 國內外主要大語言模型廠商商業路徑對比
ChatGPT在C端生態布局上雙管齊下:引進上游插件,增強應用能力,打造super APP吸引用戶;同時創新軟件交互,將用戶納入生態圈,實現C端生態全面布局,引領行業新潮流。
OpenAI攜手微軟Azure,間接實現B端“模型即服務”模式,直接提供大模型API,助力小型B端開發者,深化B端生態布局。谷歌亦不甘示弱,以多款大模型能力組合,積極拓展B端市場,提升競爭力。雙方共同推動B端生態繁榮發展。
-對此,您有什么看法見解?-
-歡迎在評論區留言探討和分享。-






![[力扣題解] 404. 左葉子之和](http://pic.xiahunao.cn/[力扣題解] 404. 左葉子之和)


適應基于分數的擴散模型中的未知低維結構)


)



 IP 地址)


