
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
??????🌈個人主頁:人不走空??????
💖系列專欄:算法專題
?詩詞歌賦:斯是陋室,惟吾德馨

目錄
??????🌈個人主頁:人不走空??????
💖系列專欄:算法專題
?詩詞歌賦:斯是陋室,惟吾德馨
2.1 架構設計
自注意力機制(Self-Attention Mechanism)
前饋神經網絡(Feedforward Neural Network)
殘差連接(Residual Connection)和層歸一化(Layer Normalization)
最終輸出
2.2 自注意力機制詳解
2.3 多頭注意力機制
2.4 位置編碼
2.5 訓練過程
2.5.1 預訓練
2.5.2 微調
作者其他作品:
 ?
?
2.1 架構設計
ChatGPT的核心架構是基于Transformer解碼器。Transformer解碼器主要由多個堆疊的解碼器層(Decoder Layer)組成,每個層包括以下幾個關鍵組件:
自注意力機制(Self-Attention Mechanism)
自注意力機制是解碼器的核心組件之一,用于捕捉輸入序列中各個單詞之間的關系。通過計算查詢(Query)、鍵(Key)和值(Value)向量之間的相似度,自注意力機制能夠為每個單詞分配不同的權重,反映其在當前上下文中的重要性。這一機制使得模型能夠在生成過程中考慮到整個輸入序列的各個部分,從而生成連貫且上下文相關的文本。
前饋神經網絡(Feedforward Neural Network)
前饋神經網絡由兩個線性變換和一個非線性激活函數(通常是ReLU)組成。它對每個位置的表示進行非線性變換,以增強模型的表達能力。具體步驟如下:
- 第一層線性變換:將輸入向量映射到一個更高維度的隱空間。
- 激活函數:應用ReLU激活函數,增加模型的非線性特性。
- 第二層線性變換:將激活后的向量映射回原始維度。
這種雙層結構能夠捕捉復雜的特征和模式,進一步提升模型的生成質量。
殘差連接(Residual Connection)和層歸一化(Layer Normalization)
為了緩解深層神經網絡中常見的梯度消失和梯度爆炸問題,Transformer解碼器引入了殘差連接和層歸一化技術。
- 殘差連接:在每個子層的輸入和輸出之間添加一個直接連接,使得輸入能夠跳躍式地傳遞到后面的層。這種連接方式不僅有助于梯度的反向傳播,還能加快模型的收斂速度。
- 層歸一化:對每一層的輸入進行歸一化處理,使得輸入在不同訓練階段保持穩定,有助于加速訓練過程和提高模型的穩定性。
每個解碼器層的輸入是前一層的輸出,經過自注意力機制、前饋神經網絡、殘差連接和層歸一化的處理后,傳遞給下一層。通過多層堆疊,模型能夠逐層提取和整合更加抽象和高層次的特征。
最終輸出
在所有解碼器層處理完畢后,模型的輸出被傳遞到一個線性層,該層將高維表示映射到詞匯表的維度。接著,通過Softmax函數計算每個單詞的概率分布。這一步驟將解碼器的輸出轉換為一個概率分布,用于預測下一個單詞。整個生成過程是自回歸的,即每次生成一個單詞,然后將其作為輸入,用于生成下一個單詞。
2.2 自注意力機制詳解
自注意力機制是Transformer中最關鍵的部分,它通過計算查詢、鍵和值的點積來捕捉輸入序列中的依賴關系。具體步驟如下:
-
查詢、鍵和值的生成:輸入序列通過線性變換生成查詢(Q)、鍵(K)和值(V)矩陣。
Q=XWQ?,K=XWK?,V=XWV?
-
計算注意力權重:通過點積計算查詢和鍵的相似度,然后除以一個縮放因子(通常是鍵的維度的平方根),最后通過Softmax函數將相似度轉換為概率分布。
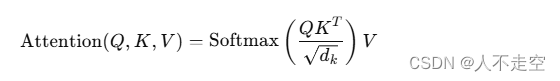
-
加權求和:用注意力權重對值進行加權求和,得到每個位置的注意力表示。
2.3 多頭注意力機制
為了捕捉輸入序列中的多種關系,Transformer引入了多頭注意力機制(Multi-Head Attention)。具體來說,將查詢、鍵和值矩陣分成多個頭,每個頭獨立地計算注意力,然后將各頭的輸出拼接起來,再通過線性變換得到最終的輸出。
多頭注意力機制的公式如下:
MultiHead(Q,K,V)=Concat(head1?,head2?,…,headh?)WO?
其中,每個頭的計算方法為:
headi?=Attention(QWQi??,KWKi??,VWVi??)
2.4 位置編碼
Transformer沒有循環結構,因此無法自然地捕捉序列中的位置信息。為了解決這個問題,Transformer引入了位置編碼(Positional Encoding)。位置編碼通過正弦和余弦函數生成,并加到輸入序列的詞嵌入中,使得模型能夠區分序列中不同位置的單詞。
位置編碼的公式如下:
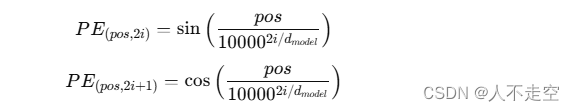
其中,pospospos表示位置,iii表示維度的索引,dmodeld_{model}dmodel?表示詞嵌入的維度。
2.5 訓練過程
ChatGPT的訓練過程包括兩個主要階段:預訓練和微調。
2.5.1 預訓練
在預訓練階段,模型在大規模的無監督文本數據上進行訓練。訓練目標是最大化給定上下文條件下生成下一個單詞的概率。具體來說,模型通過計算預測單詞與真實單詞之間的交叉熵損失來進行優化。
預訓練的公式如下:
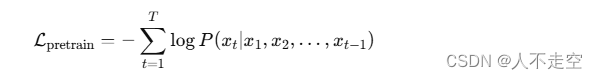
其中,xtx_txt?表示序列中的第ttt個單詞,TTT表示序列的長度。
2.5.2 微調
在微調階段,模型通過監督學習和強化學習在特定任務或領域的數據上進行進一步訓練。監督學習使用標注數據進行訓練,強化學習則通過與環境的交互,優化特定的獎勵函數。
微調過程包括以下步驟:
- 監督學習微調:使用人工標注的數據進行監督學習,優化模型在特定任務上的性能。
- 強化學習微調:使用強化學習算法(如策略梯度)進行優化,通過與環境的交互,最大化獎勵函數。
強化學習微調的公式如下:
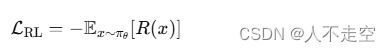
其中,πθ?表示模型的策略,R(x)表示獎勵函數。
作者其他作品:
【Java】Spring循環依賴:原因與解決方法
OpenAI Sora來了,視頻生成領域的GPT-4時代來了
[Java·算法·簡單] LeetCode 14. 最長公共前綴 詳細解讀
【Java】深入理解Java中的static關鍵字
[Java·算法·簡單] LeetCode 28. 找出字a符串中第一個匹配項的下標 詳細解讀
了解 Java 中的 AtomicInteger 類
算法題 — 整數轉二進制,查找其中1的數量
深入理解MySQL事務特性:保證數據完整性與一致性
Java企業應用軟件系統架構演變史?

)

)

 : 循環賽日程表)








【UIAbility組件與UI的數據同步】)




