相信很多的小伙伴,有些是大數據測試崗位,有些是ETL開發,都面臨著如何要造數據的情況。
1,造數背景
【大數據測試崗位】,比較出名的就是寧波銀行,如果你在寧波銀行做大數據開發,對著需求開發完代碼之后,可能需要把代碼提交給測試人員,那么測試人員會根據這個業務需求,他們會自己造一批數據,然后看看你的sql腳本,是不是有一些明顯的sql錯誤,以及開發規范的問題。當然,還有最重要的一點是,他們會拿著你的腳本取跑數,看看的出來的數據是不是符合業務的邏輯與需求。
如果是【ETL開發崗位】,那么在你連通了HIVE和其他的數據庫(比如說,Oracle,mysql,kingbases等等),接著你把代碼也開發好了,那么怎么判斷你的數據是不是ETL到目標數據庫里面了呢?當然是自己先在源數據庫里造一批數據,然后走調度跑腳本,如果不報錯的情況下,我們再到目標數據庫里查看一下,我們之前造的數據是不是ETL過去了。
如果是【大數據開發崗位】,那基本不咋造數據,因為在測試環境,就是有測試數據,還有生產上來的脫敏數據。這些都是可以拿來借鑒參考開發的。
2,造數階段
那么如何造數呢??直接上 HUE 摸魚兒展示一下
一張圖拿捏:
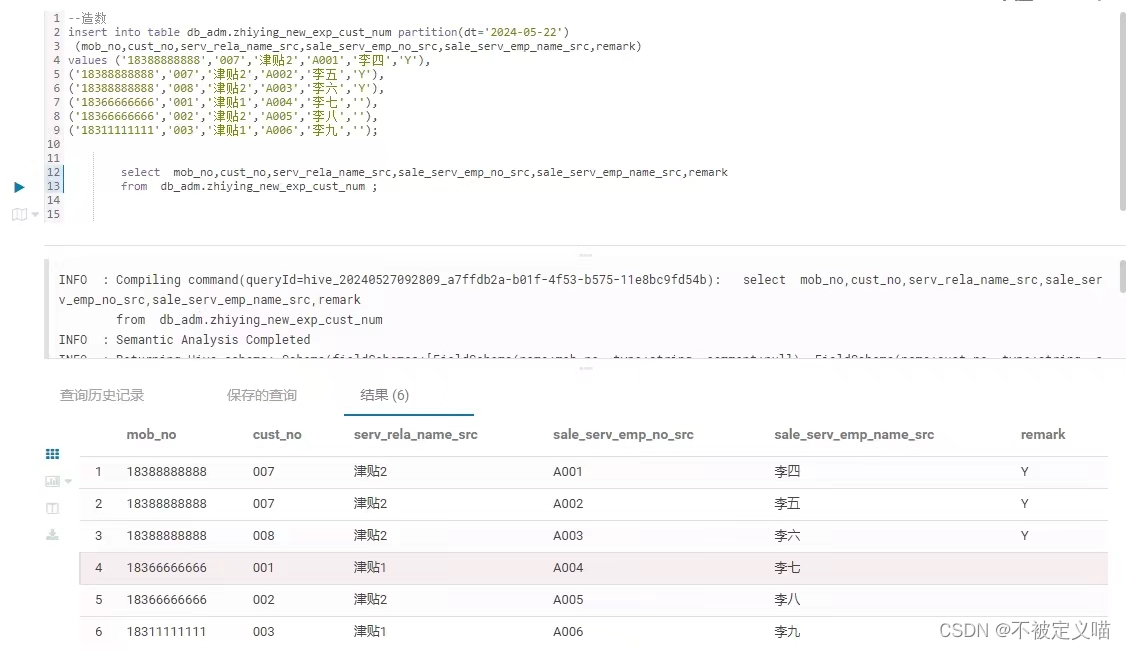
3,造數代碼
--如果是分區表(直接建立分區,同時往該分區插入數據)insert into table xxxx partiton ( dt = '2024-05-27' )(字段1,字段2,字段3......)values (值1,值2,值3.......) , (值4,值5,值6.......)--如果不是分區表insert into table xxxx (字段1,字段2,字段3......)values (值1,值2,值3.......), (值4,值5,值6.......)4,造數邏輯
當然,造數代碼不難,但是數據可不是瞎造的,其中還是有一定的講究。
1,首先,你得先了解整個需求文檔,它的數據的最細粒度是什么??
比如說一個客戶對應多個資金賬號,那么你就按照最細粒度來造數。
可以造3條數據,一個客戶對應3個不同的資金賬號。
2,其次,根據需求文檔的某些特殊字段進行窮舉。
比如說,客戶類型字段,總共分為3個,個人客戶,機構客戶,產品客戶。
這個時候,你可以發散出3條數據,窮舉出來。
3,也可以根據數據的低概率可能性造數。
比如,非主鍵字段,可以故意設置一些null值。
比如,要算一個完成率,你可以設置分母為0的情況。
比如,一般一個員工,只能歸屬于一個營業部,但是你清楚這個業務,你可以把某個客戶,分別放在2個不同的營業部下面。
4,最后,我想說,測試人員得要對業務需求文檔要有一定的理解。
清楚哪些是開發重點,哪些是爭議點,在重點之處下文章,才能取得好的效果。
只有這樣子,跑出來的數據才是全面的。你無需造數太多,但一定要麻雀雖小五臟俱全。才能叫校驗出開發代碼人員的代碼有沒有漏洞,能不能良好的實現業務需求。
==========================================================
好了,這個知識點就分享到這里。
之后看看給大家分享一下測試數據的崗位的小伙伴是怎么測試你的腳本的,有空也會分享一下ETL開發的流程。
歡迎大家點贊收藏關注,不一定很難,但都是經驗之談。
)








![[AI Google] 三種新方法利用 Gemini 提高 Google Workspace 的生產力](http://pic.xiahunao.cn/[AI Google] 三種新方法利用 Gemini 提高 Google Workspace 的生產力)









