一直有傳言說,MySQL 表的數據只要超過 2000 萬行,其性能就會下降。而本文作者用實驗分析證明:至少在 2023 年,這已不再是 MySQL 表的有效軟限制。
傳言
互聯網上有一則傳言說,我們應該避免單個 MySQL 表中的數據超過 2000 萬行,否則表的性能就會下降——當數據量超過這個軟限制時,你就會發現 SQL 的查詢速度會比平時慢很多。這是多年前針對 HDD 做出的判斷。我想知道,時至 2023 年,SSD 上的 MySQL 是否仍然有此限制。如果真的有,那么原因是什么呢?
環境
數據庫
? MySQL 版本: 8.0.25
? 實例類型:AWS db.r5.large(2vCPUs, 16GiB RAM)
? EBS 存儲類型:General Purpose SSD(gp2)
測試客戶端
? Linux 內核版本:6.1
? 實例類型:AWS t2.micro(1 vCPU, 1GiB RAM)
實驗設計
創建具有相同結構、但大小不同的表。我一共創建了 9 個表,數據行數分別為:10 萬、20 萬、50 萬、100 萬、200 萬、500 萬、1000 萬、2000 萬、3000 萬、5000 萬和 6000 萬。
- 創建幾個具有相同結構的表:
CREATE TABLE row_test(
`id` int NOT NULL AUTO_INCREMENT,
`person_id` int NOT NULL,
`person_name` VARCHAR(200),
`insert_time` int,
`update_time` int,
PRIMARY KEY (`id`),
KEY `query_by_update_time` (`update_time`),
KEY `query_by_insert_time` (`insert_time`)
);
- 插入不同的數據。我使用了測試客戶端和表復制的方式創建了這些表。腳本可參考:https://github.com/gongyisheng/playground/blob/main/mysql/row_test/insert_data.py。
# test client
INSERT INTO {table} (person_id, person_name, insert_time, update_time) VALUES ({person_id}, {person_name}, {insert_time}, {update_time})
# copy
create table like <table>
insert into (`person_id`, `person_name`, `insert_time`, `update_time`)
select `person_id`, `person_name`, `insert_time`, `update_time` from
person_id、person_name、insert_time 和 update_time 的值是隨機的。
- 使用測試客戶端執行以下 sql 查詢來測試性能。腳本可參考:https://github.com/gongyisheng/playground/blob/main/mysql/row_test/select_test.py。
select count(*) from <table> -- full table scan
select count(*) from <table> where id = 12345 -- query by primary key
select count(*) from <table> where insert_time = 12345 -- query by index
select * from <table> where insert_time = 12345 -- query by index, but cause 2-times index tree lookup
- 查看 innodb 緩沖池狀態。
SHOW ENGINE INNODB STATUS
SHOW STATUS LIKE 'innodb_buffer_pool_page%
結果
查詢1:select count(*) from
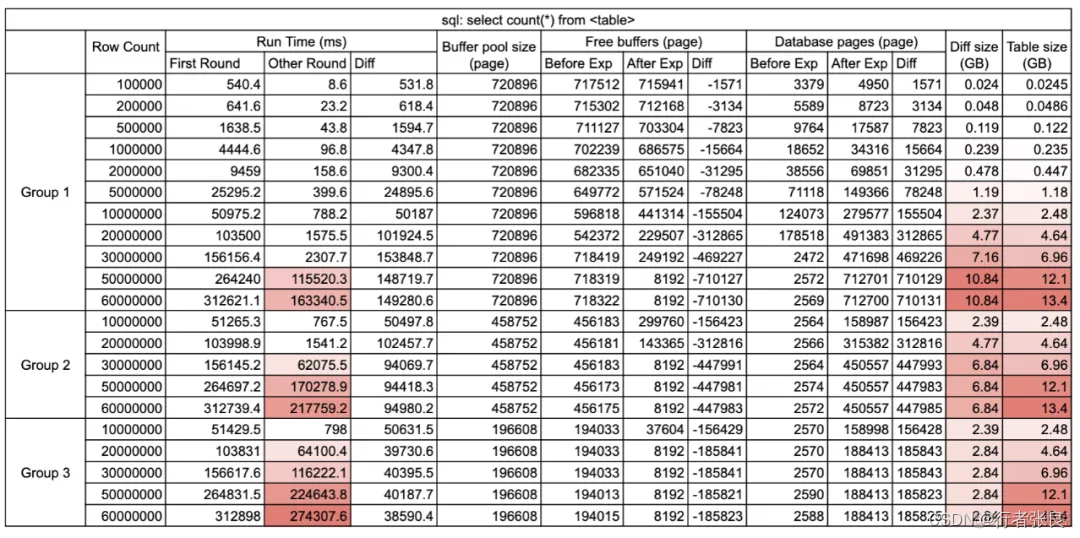
這種查詢會執行全表掃描,MySQL 并不擅長這種工作。
? 第一輪:沒有緩存。第一次執行查詢時,緩沖池中沒有緩存數據。
? 第二輪:有緩存。當緩沖池中已經有數據緩存時執行查詢,通常在第一次查詢執行完之后。
觀察結果:
1. 第一輪查詢的執行時間超出了后面幾次。
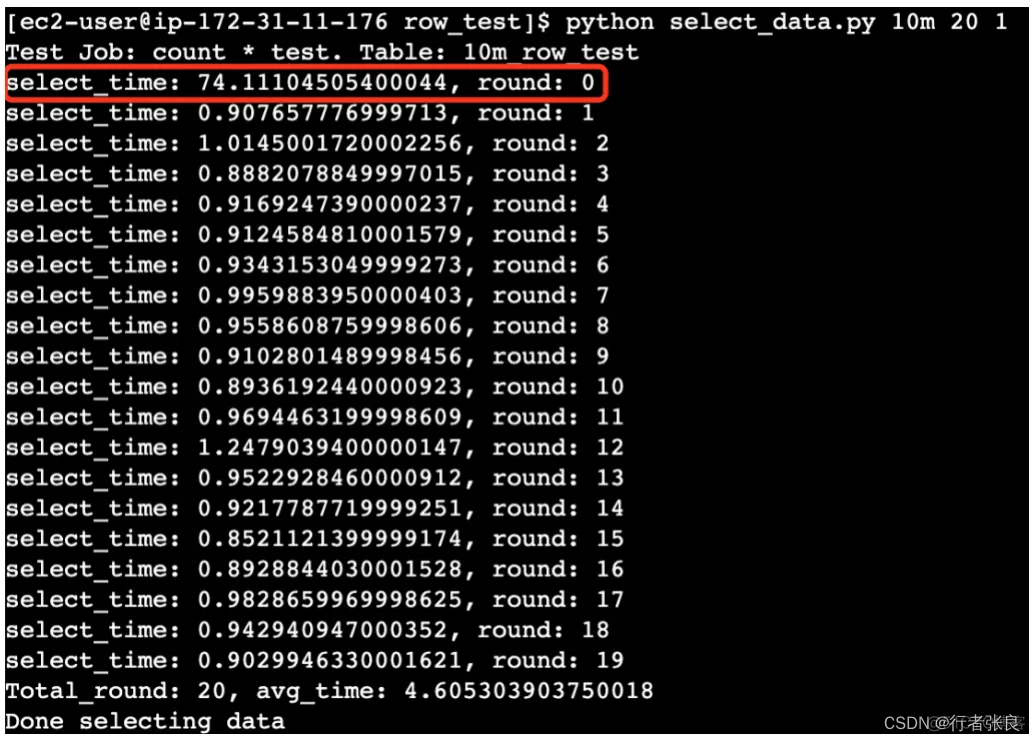
原因是 MySQL 使用了 innodb_buffer_pool 來緩存數據頁。在第一次執行查詢之前,緩沖池是空的,所以 MySQL 必須進行大量的磁盤 I/O 才能從 .idb 文件加載表。但在第一次執行結束后,緩沖池中存儲了數據,后續查詢可以直接讀取內存,避免磁盤 I/O,因此速度更快。該過程稱為 MySQL 緩沖池預熱。
2. select count(*) from < table > 會設法將整個表加載到緩沖池。
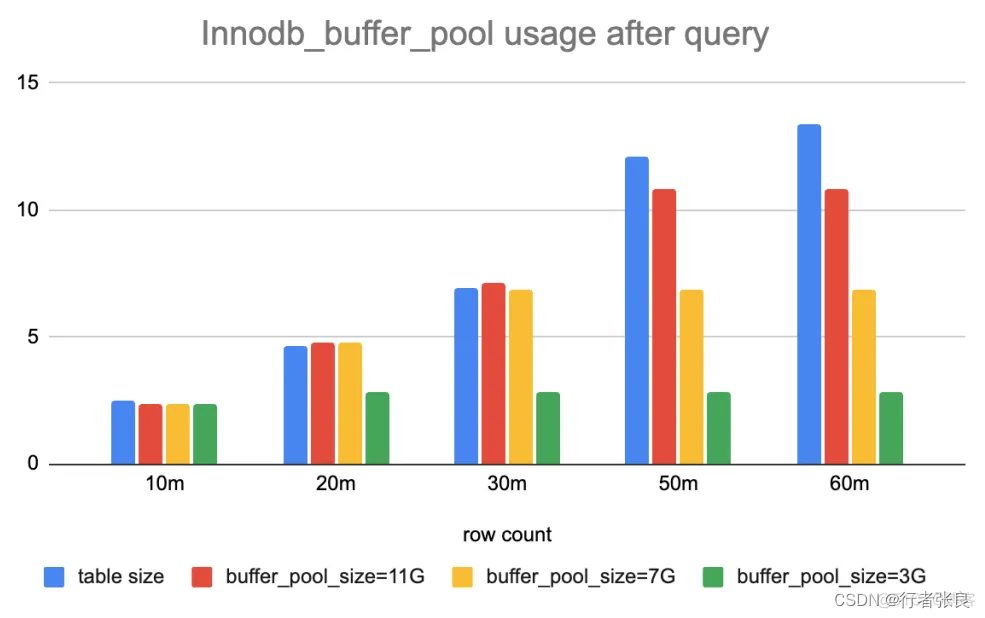
我比較了實驗前后 innodb_buffer_pool 的統計數據。運行查詢后,如果緩沖池足夠大,則其使用量變化等于表的大小。否則,只有部分表會緩存在緩沖池中。原因是查詢 select count(*) from table 會做全表掃描,并做逐行統計。如果沒有緩存,就需要將完整的表加載到內存中。為什么?因為 Innodb 支持事務,它不能保證事務在不同時間看到同一張表。全表掃描是獲得準確行數的唯一安全方法。
3. 如果緩沖池不能容納全表,則會爆發查詢延遲。
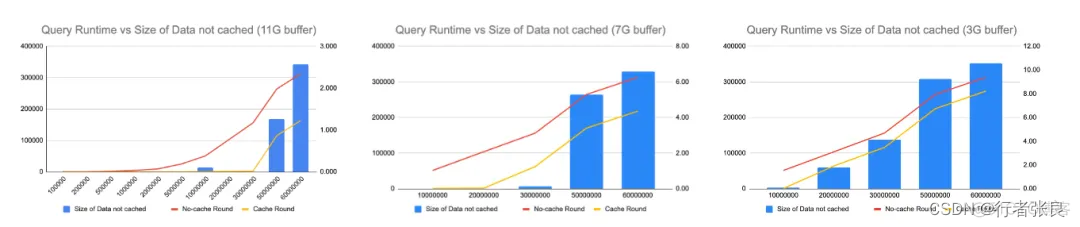
我注意到 innodb_buffer_pool 的大小會極大地影響查詢性能,因此我嘗試在不同的配置下運行查詢。當使用 11G 緩沖區,而表的大小達到 5000 萬行時,就會爆發查詢延遲。接著,我將緩沖區縮減到 7G,當表的大小達到 3000 萬行時,爆發了查詢延遲。最后,我將緩沖區縮減到 3G,當表的大小僅為 2000 萬行時,就爆發了查詢延遲。很明顯,如果表中的數據無法緩存在緩沖池中,則 select count(*) from
4. 對于沒有緩存的查詢,查詢花費的時間與表的大小呈線性關系,與緩沖池大小無關。
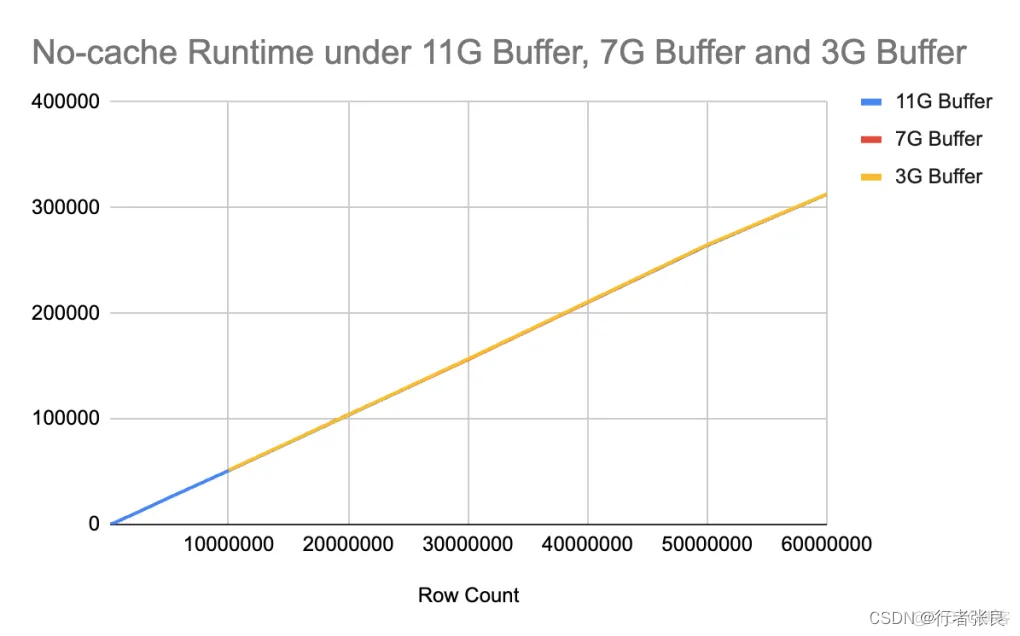
當沒有緩存時,查詢花費的時間由磁盤 I/O 決定,與緩沖池大小無關。在 IOPS 相同的情況下,是否使用 select count(*) 預熱緩沖池并沒有區別。
5. 如果無法完整地緩存整個表,則有無緩存的查詢運行時間差異是恒定的。
另請注意,如果無法完整地緩存整個表,雖然查詢運行時會突然上升,但運行時是可預測的。無論表的大小如何,有無緩存的時間差異是恒定的。原因是表的部分數據緩存在緩沖區中,這里的時間差異來自從緩沖區讀取數據節省的時間。
查詢2,3:select count(*) from where = 12345
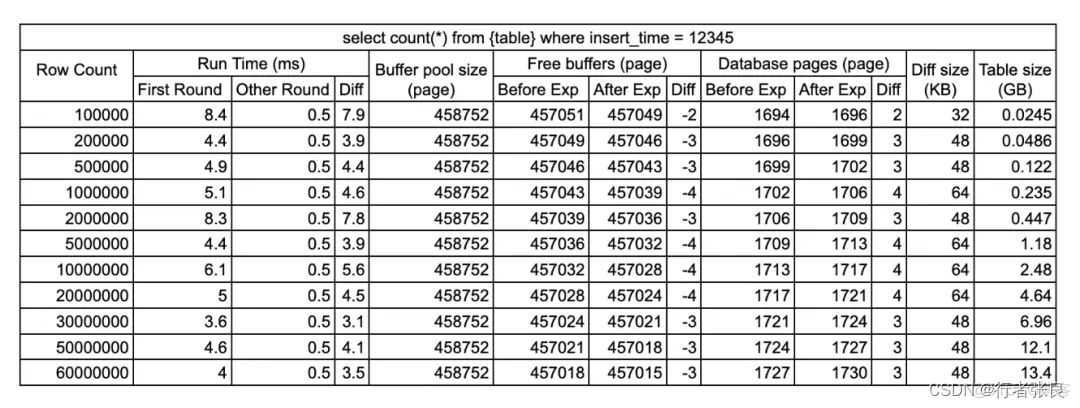
這個查詢使用了索引。由于不是范圍查詢,MySQL 只需要利用 B+ 樹的路徑從上到下查找頁面,并將這些頁面緩存到 innodb 緩沖池中即可。
我創建的表的 B+ 樹的深度都是 3,因此前面的 3~4 次 I/O 都被拿來預熱緩沖區,平均耗時 4~6 毫秒。之后,再次運行相同的查詢,MySQL 就會直接從內存中查找結果,耗時為 0.5 毫秒,約等于網絡 RTT。如果緩存頁面長時間未命中,并從緩沖池中逐出,則必須再次從磁盤加載該頁面,這樣就需要磁盤 I/O(最多 4 次)。
查詢4:select * from where = 12345
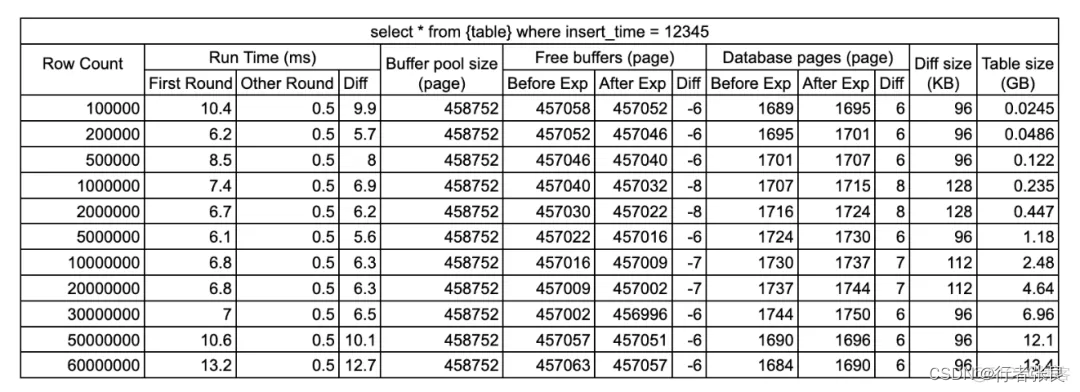
這個查詢涉及兩次索引查找。由于 select * 需要查詢獲取的 person_name、person_id 字段并不在索引中,因此在查詢執行期間,數據庫引擎必須查找 2 個 B+ 樹。它首先查找 insert_time B+ 樹,獲取目標行的主鍵,然后查找主鍵 B+ 樹,獲取該行的完整數據,如下圖所示:
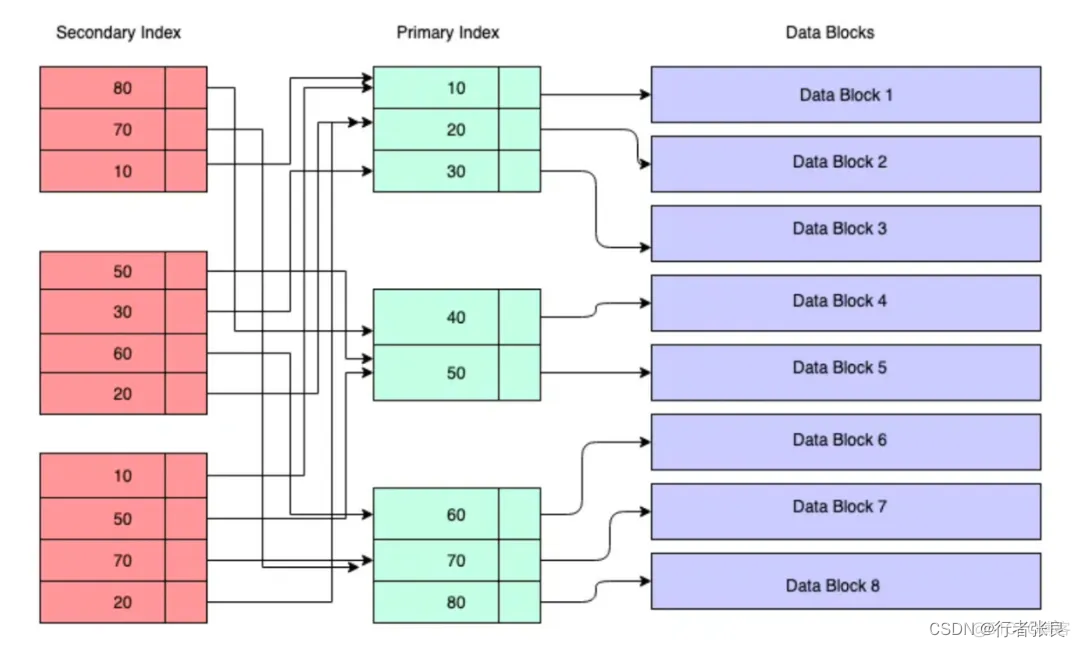
這就是我們應該在生產中避免 select * 的原因。此次實驗證實,此查詢加載的頁面塊比查詢 2 或 3 多出了 2 倍,且最高可達 8 倍。查詢的平均運行時間為 6~10 毫秒,也是查詢 2 或 3 的 1.5~2 倍。
傳言是怎么來的

首先,我們需要知道 innodb 索引頁的物理結構。默認頁面大小為 16k,由頁眉、系統記錄、用戶記錄、頁面導向器和尾部組成。只有剩下的 14~15k 用來存儲數據。
假設你使用 INT 作為主鍵(4 字節),每行 1KB 的有效負載。每個葉頁可以存儲 15 行,一個指向該頁的指針需要 4+8=12 字節。因此,每個非葉頁最多可以容納 15k / 12 字節 = 1280 個指針。如果你有一個 4 層的 B+ 樹,它最多可以容納 1280128015 = 24.6M 行數據。
回到 HDD 占據市場主導地位,且 SSD 對于數據庫而言過于昂貴的時代,4 次隨機 I/O 可能是我們可以容忍的最壞情況,而使用 2 次索引樹查找的查詢甚至會使情況變得更糟。當時的工程師想要控制索引樹的深度,不希望它們太深。而如今 SSD 越來越流行,隨機 I/O 比以前便宜了,因此我們應該反思一下 10 年前的規則。
順便說一句,5 層 B+ 樹可以容納 128012801280*15 = 31.4B 行數據,超過了 INT 所能容納的最大數據量。對每行大小的不同假設將導致不同的軟限制,或小于或大于 2000 萬行。例如,在我的實驗中,每一行大約是 816 字節(我使用 utf8mb4 字符集,所以每個字符占用 4 個字節),4 層 B+ 樹可以容納的軟限制是 29.5M。
結論
? Innodb 緩存池的大小、表的大小決定了是否會出現性能降級。
? 判斷是否需要拆分 MySQL 表的一個更有意義的指標是查詢運行時/緩沖池命中率。如果查詢總是命中緩沖區,則不會有任何性能問題。2000 萬行只是一個經驗值。
? 除了拆分 MySQL 表之外,增加 Innodb 緩存池的大小和數據庫的內存也是一個選擇。
? 如果可能,請避免在生產中使用 select *,這類語句在最壞的情況下會導致 2 次索引樹查找。
? (我個人的意見)考慮到 SSD 現在越來越流行,2000 萬行不再是 MySQL 表的有效軟限制。

![[數據集][目標檢測]輪胎檢測數據集VOC+YOLO格式439張1類別](http://pic.xiahunao.cn/[數據集][目標檢測]輪胎檢測數據集VOC+YOLO格式439張1類別)


)

)
)











