參考:CLIP論文筆記--《Learning Transferable Visual Models From Natural Language Supervision》_visual n-grams模型-CSDN博客
- openAI,2021,將圖片和文字聯系在一起,----->得到一個能非常好表達圖片和文字的模型
- 主題:多模態理解任務
任務:計算圖片和文本的相似度
訓練:有監督的對比學習
背景
- zero-shot transfer:零樣本遷移到下游任務(一些NLP模型可以直接在A數據集上預訓練,再到B,C,D數據集做任務時,這個模型可以不使用這個數據集的任何數據(zero-shot)進行參數微調而直接做任務)
- “狹窄的視覺概念”是指模型在ImageNet等數據集上訓練,只是為了學會區分像“貓”、“狗”這樣的類,但不同的貓種類模型是不會區分的,比如“橘貓”和“奶牛貓”,即其他的視覺信息沒有被充分利用。
- Visual N-Grams促成CLIP的誕生的最重要的論文。【用自然語言監督信號來讓促成一些現存的CV分類數據集(包含ImageNet數據集)實現zero-shot transfer。】
?方法
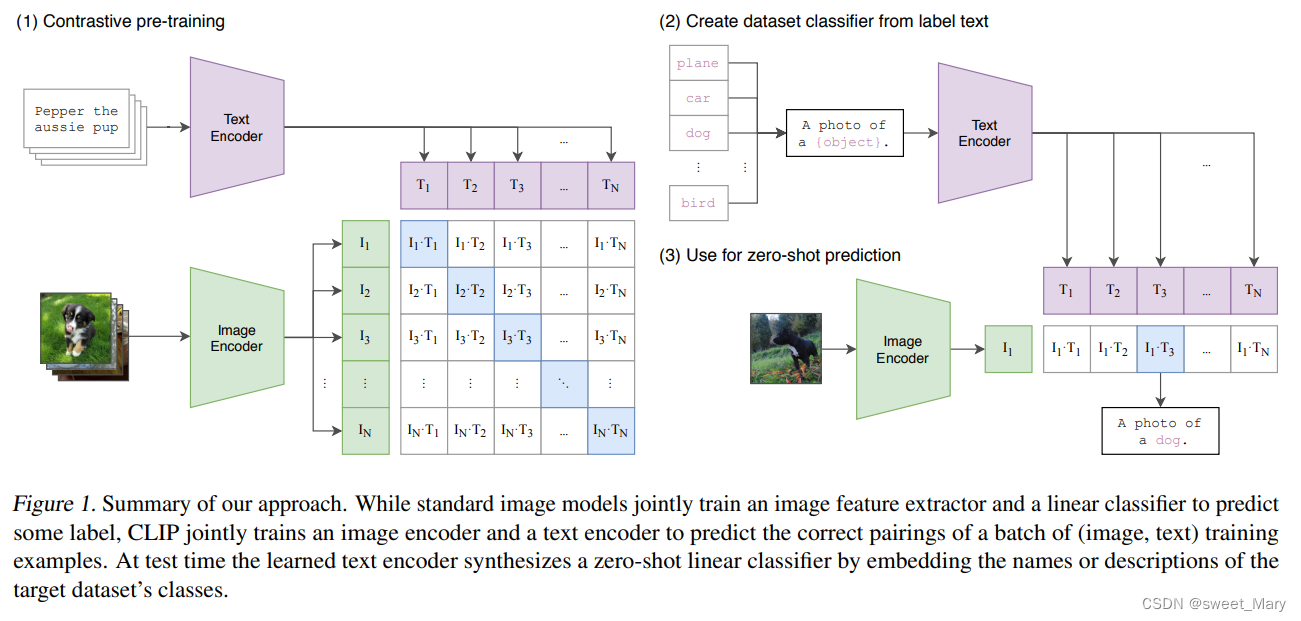
- 標準的圖像模型 VS CLIP:
- 標準的圖像模型:一個圖像特征提取器和一個線性分類器---預測標簽
- CLIP:一個圖像編碼器和一個文本編碼器---預測一批(圖像、文本)正確配對
- 測試:輸入句子(a photo of {label}---Prompt工程)+圖片
- 從自然語言中學習:將圖片表示與語言聯系起來,從而實現靈活的zero-shot transfer
- 超大數據集:用4億對來自網絡的圖文數據集,將文本作為圖像標簽,進行訓練。這個數據集稱為WebImageText(WIT)
- 預訓練
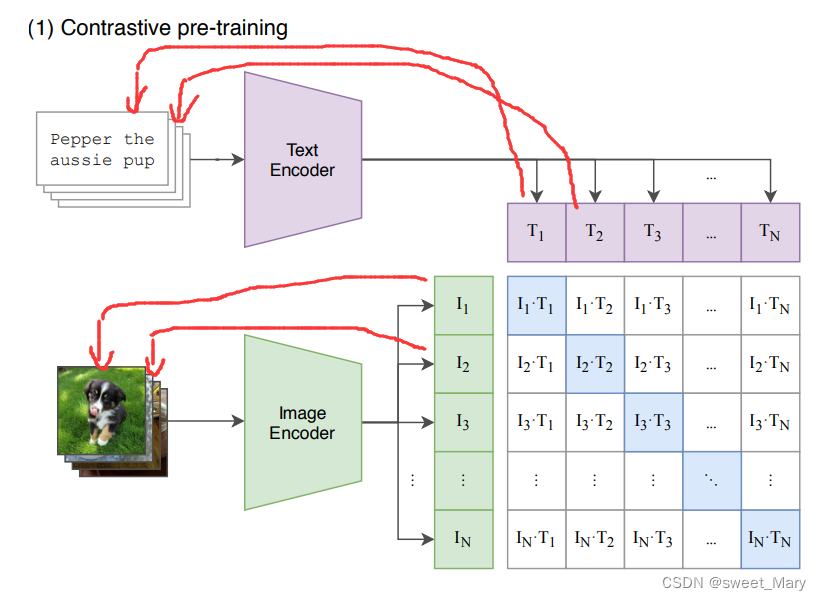
- 圖片分類任務------>圖文匹配任務?
- 貢獻點:采用了海量圖文對數據和超大batch size進行預訓練,并不在于其模型結構
- 模態之間的cosine similarity:N個匹配的圖文對相似度最大,
個不匹配的圖文對相似度最小
- 對角線上都是配對的正樣本對,而矩陣的其他元素,則是由同個batch內的圖片和不配對的文本(相反亦然)組成的負樣本。
- 測試
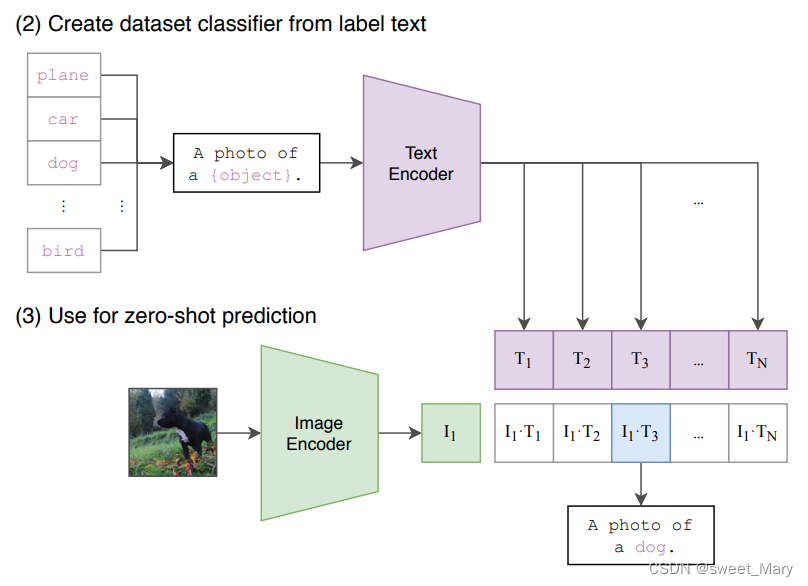
?


筆記)
)





)
)






)

