????????本篇博客將向各位詳細介紹elasticsearch,也算是對我最近學完elasticsearch的一個總結,對于如何在Kibana中使用DSL指令,本篇文章不會進行介紹,這里只會介紹在java中如何進行使用,保證你看完之后就會在項目中進行上手,那我們開始本篇教程吧~
什么是ElasticSearch
- Elasticsearch,基于lucene.分布式的Restful實時搜索和分析引擎(實時)
- 分布式的實時文件存儲,每個字段都被索引并可被搜索
- 高擴展性,可擴展至上百臺服務器,處理PB級結構化或非結構化數據
- Elasticsearch用于全文檢索,結構化搜索,分析/合并使用
ElasticSearch是如何做到這么快的
- 分布式存儲:ElasticSearch把數據存儲在多個節點上,從而減少單個節點的壓力,從而提高性能
- 索引分片:ElasticSearch把索引分成多個分片,這樣可以讓查詢操作并行化,從而提高性能
- 全文索引:ElasticSearch把文檔轉換成可搜索的結構化數據,從而提高效率
- 倒排索引:ElasticSearch將文檔進行分詞處理,把每個詞在哪個文檔中出現過進行映射,并存儲這些信息,從而在搜索時,查詢這些分詞和搜索這些分詞存在在哪些文檔中,提高查詢效率
- 異步請求處理:ElasticSearch能夠在請求到達時立即返回,避免長時間等待,提高效率
全文索引和倒排索引是什么
????????全文檢索是指計算機索引程序通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程序就根據事先建立的索引進行查找,并將查找的結果反饋給用戶的檢索方式。這個過程類似于通過字典中的檢索字表查字的過程。全文搜索搜索引擎數據庫中的數據。
-
優點:
-
可以給多個字段創建索引
-
根據索引字段搜索、排序速度非常快
-
-
缺點:
-
根據非索引字段,或者索引字段中的部分詞條查找時,只能全表掃描。
-
????????倒排索引就和傳統的索引結構相反,傳統的索引是由文檔組成的,每個文檔中都包含了若干個詞匯,然后根據這些詞匯簡歷索引。而倒排索引則與其相反,倒排索引由詞匯構成,每個詞匯對應若干個文檔,然后根據這些文檔建立索引。
-
優點:
-
根據詞條搜索、模糊搜索時,速度非常快
-
-
缺點:
-
只能給詞條創建索引,而不是字段
-
無法根據字段做排序
-
ElasticSearch和Mysql之間的映射關系
| Mysql類型? ? ? ? | ElasticSearch類型 | 說明 |
| VARCHAR | text、keyword | 根據是否需要使用全文搜索或精確搜索選擇使用text或keyword |
| CHAR???????? | keyword? ? ? ? ? ? ? ? ? ? ? ? | 通常映射為keyword,因為它們存儲較短的、不經常變化的字符序列 |
| BLOB/TEXT? ? ? ?? | text | 大文本塊使用text,適用于全文檢索 |
| INT,BIGINT | long | 大多數整數型使用long,以支持更大的數值 |
| TINYINT | byte | 較小的整數可以映射為byte類型 |
| DECIMAL,FLOAT,DOUBLE | double,float | |
| DATE,DATETIME,TIMESTAMP | date | |
| BOOLEAN | boolean |
倒排索引建立步驟
es中建立倒排索引需要兩步,首先對文檔進行分詞,其次建立倒排索引
分詞
????????分詞的意思大概就是對文檔中的數據通過es的分詞器進行分割成一個個詞項,比如 “我是銀氨溶液” 這句話,經過分詞過后就是 “我”、“是”、“銀氨”、“溶液”,當然es的分詞器分為ik_smart分詞器和ik_max_word分詞,所以實際操作時這句話會被分解為不同的詞段。
es中的一些概念
????????文檔
????????elasticsearch是面向文檔(Document)存儲的,可以是數據庫中的一條商品數據,一個訂單信息。文檔數據會被序列化為json格式后存儲在elasticsearch中。
????????字段
Json文檔中往往包含很多的字段(Field),類似于數據庫中的列。
????????索引
索引(Index),就是相同類型的文檔的集合。因此,我們可以把索引當做是數據庫中的表。
????????映射
????????數據庫的表會有約束信息,用來定義表的結構、字段的名稱、類型等信息。因此,索引庫中就有映射(mapping),是索引中文檔的字段約束信息,類似表的結構約束。
對照圖表:
| MySQL | Elasticsearch | 說明 |
|---|---|---|
| Table | Index | 索引(index),就是文檔的集合,類似數據庫的表(table) |
| Row | Document | 文檔(Document),就是一條條的數據,類似數據庫中的行(Row),文檔都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文檔中的字段,類似數據庫中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文檔的約束,例如字段類型約束。類似數據庫的表結構(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON風格的請求語句,用來操作elasticsearch,實現CRUD |
RestAPI
首先,在這篇文章中不會將所有api都介紹完,所以這了貼上官方文檔的地址,以共各位查看:
ElasticSearch官方文檔
這里需要先引入es的依賴
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>同時,你需要在pom文件中修改es的版本和你本地的一樣
 ?然后,我們需要把es注入到spring容器中
?然后,我們需要把es注入到spring容器中
@Configuration
public class ElasticSearchClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client=new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));return client;}
}?準備工作完成之后就可以開始接下來的學習啦~
索引的CRUD操作
索引的操作較為簡單,而且項目中實際都是對文檔進行操作,所以我這里貼出索引的相關操作代碼,并做出解釋,各位可以了解一下
@Autowired@Qualifier("restHighLevelClient")private RestHighLevelClient client;// 測試索引的創建 Request@Testvoid testCreateIndex() throws Exception {
// 1、創建索引請求CreateIndexRequest request = new CreateIndexRequest("yinan_index");
// 2、客戶端執行請求,請求后獲得響應CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);System.out.println(createIndexResponse);}// 測試獲取索引@Testvoid testGetIndex() throws IOException {GetIndexRequest getIndex = new GetIndexRequest("yinan_index");boolean exists = client.indices().exists(getIndex, RequestOptions.DEFAULT);System.out.println(exists);}// 刪除索引@Testvoid testDeleteIndex() throws Exception {DeleteIndexRequest request = new DeleteIndexRequest("yinan_index");AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);System.out.println(delete.isAcknowledged());}
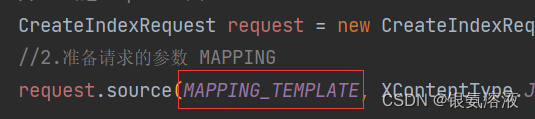
其中indices中包含了操作索引庫的所有方法,在創建索引的時候如果有多個字段,可以提前寫好?一個字符串常量,例如:
public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
?然后將新增索引中的代碼修改成以下:
文檔的CRUD操作
對于文檔這里將重點介紹查詢的相關方法,其它操作只做簡單介紹。
查詢操作
MatchAll
/*** 查詢全部*/@Testvoid testMatchAll() throws IOException {//1.準備requestSearchRequest request = new SearchRequest("hotel");//2.準備參數request.source().query(QueryBuilders.matchAllQuery());//3.發起請求得到響應結果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析響應handleResponse(response);}結果如下:

?從結果我們也可以看到這個api是查詢所有數據的方法,但是控制臺只顯示了10條數據,這是因為這個方法自動進行分頁處理,每頁10條數據。
Match
/*** 全文檢索*/@Testvoid testMatch() throws IOException {//1.準備requestSearchRequest request = new SearchRequest("hotel");//2.準備參數request.source().query(QueryBuilders.matchQuery("all","如家"));//3.發起請求得到響應結果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析響應handleResponse(response);}結果:

match用來做基本的模糊匹配,在es中會對文本進行分詞,在match查詢的時候也會對查詢條件進行分詞,然后通過倒排索引找到匹配的數據。
term
@Testvoid testMatch() throws IOException {//1.準備requestSearchRequest request = new SearchRequest("hotel");//2.準備參數
// request.source().query(QueryBuilders.matchQuery("all","如家"));request.source().query(QueryBuilders.termQuery("city","北京"));//3.發起請求得到響應結果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析響應handleResponse(response);}結果:
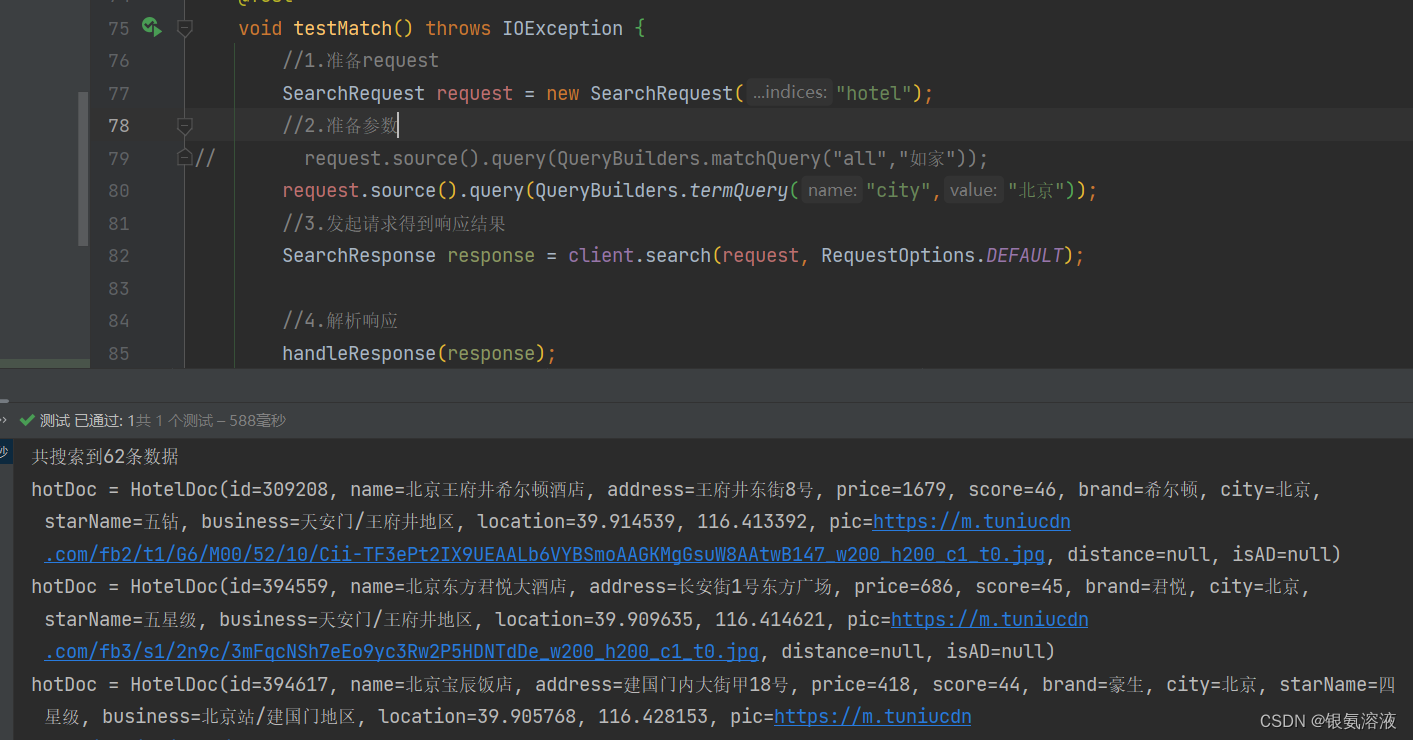 ?從結果來看,term是做精確查詢的,所以一般可以用在查詢某個具體的屬性的時候
?從結果來看,term是做精確查詢的,所以一般可以用在查詢某個具體的屬性的時候
multiMatchQuery
@Testvoid testMatch() throws IOException {//1.準備requestSearchRequest request = new SearchRequest("hotel");//2.準備參數
// request.source().query(QueryBuilders.matchQuery("all","如家"));
// request.source().query(QueryBuilders.termQuery("city","北京"));request.source().query(QueryBuilders.multiMatchQuery("如家", "city", "name"));//3.發起請求得到響應結果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析響應handleResponse(response);}?結果:
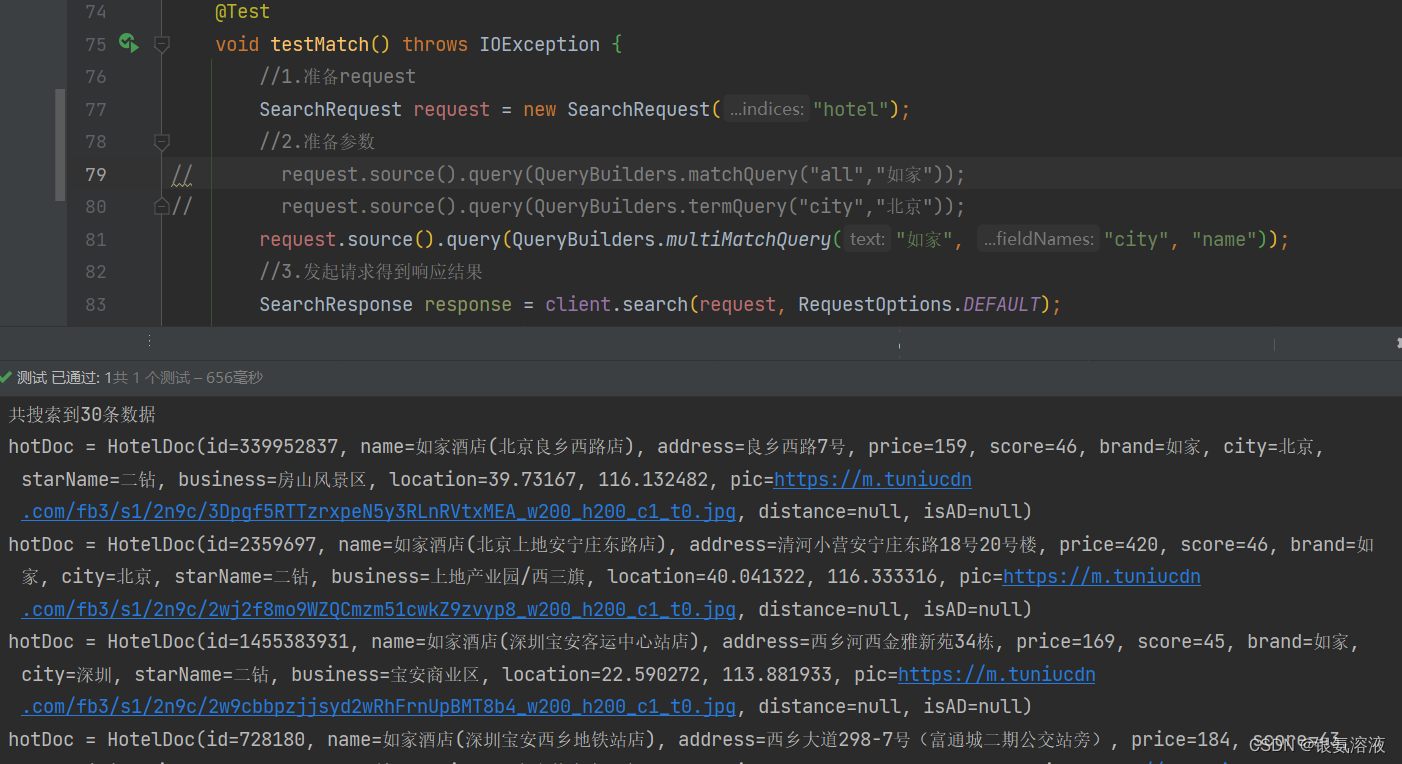
????multiMatchQuery接受兩個參數,一個是text,一個是fieldname,前者表示要查詢的內容,后者表示要在哪些字段中進行查詢,如果后者中的數據只有一個,那該方法和matchall一致,如果后者有多個,那查詢的結果必須要滿足其中的一個。
rangeQuery
@Testvoid testMatch() throws IOException {//1.準備requestSearchRequest request = new SearchRequest("hotel");//2.準備參數
// request.source().query(QueryBuilders.matchQuery("all","如家"));
// request.source().query(QueryBuilders.termQuery("city","北京"));
// request.source().query(QueryBuilders.multiMatchQuery("如家", "city", "name"));request.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(150));//3.發起請求得到響應結果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析響應handleResponse(response);}結果:
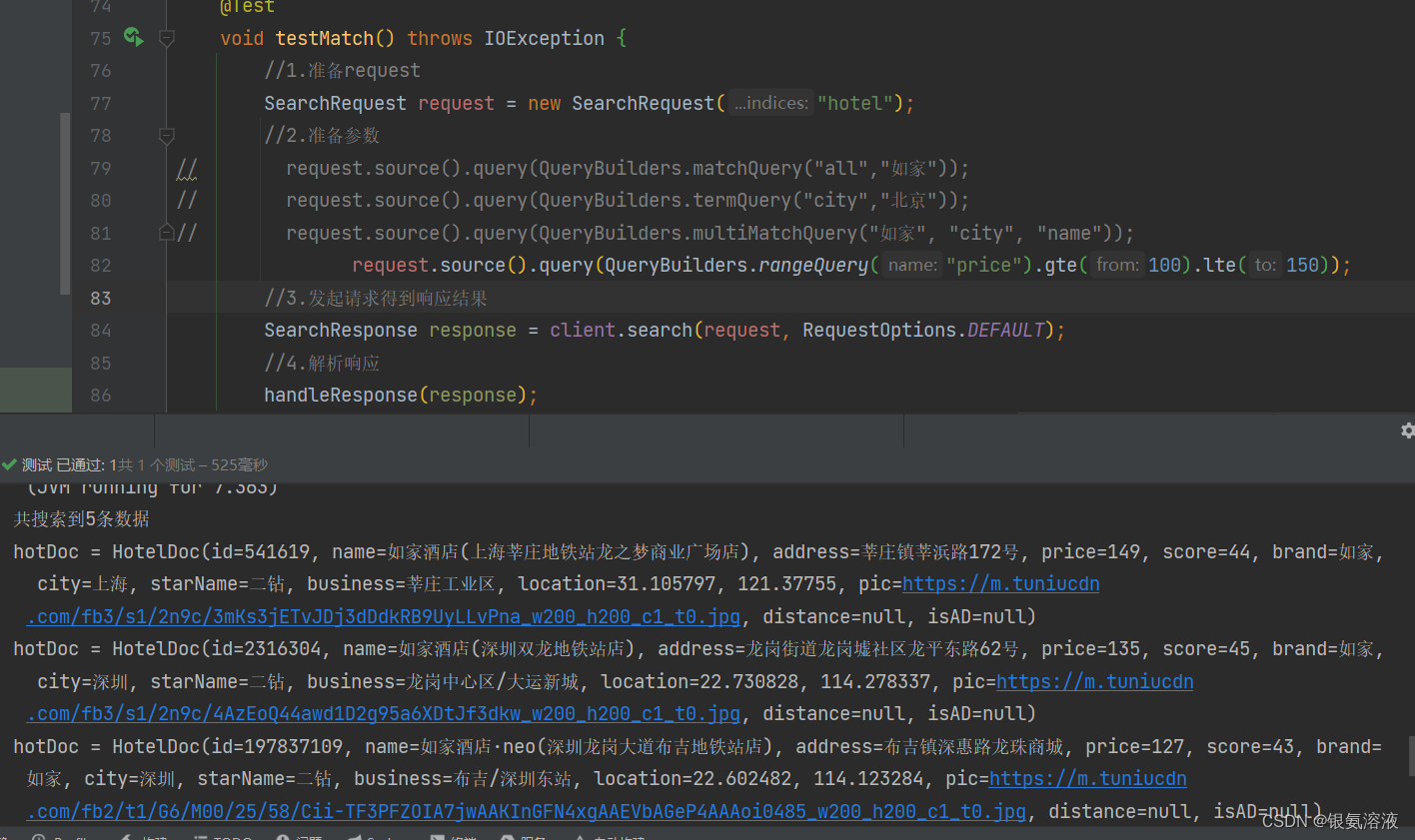
該方法主要做范圍查詢,相當于sql語句中的between....and...
布爾查詢
/*** 布爾查詢* @throws IOException*/@Testvoid testBool() throws IOException {//1.準備requestSearchRequest request = new SearchRequest("hotel");//2.準備參數BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.must(QueryBuilders.termQuery("city","北京"));boolQuery.filter(QueryBuilders.rangeQuery("price").lte(300));request.source().query(boolQuery);//3.發起請求得到響應結果SearchResponse response = client.search(request, RequestOptions.DEFAULT);System.out.println( "========"+response.getHits());//4.解析響應handleResponse(response);}/*** 解析響應結果* @param response*/private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();//總條數long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"條數據");//文檔數組SearchHit[] hits = searchHits.getHits();//遍歷for (SearchHit hit : hits){//獲取文檔sourceString json = hit.getSourceAsString();//反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//獲取高亮結果Map<String, HighlightField> highlightFields = hit.getHighlightFields();if(!CollectionUtils.isEmpty(highlightFields)){//根據字段名獲取高亮結果HighlightField highlightField = highlightFields.get("name");if(highlightField != null){//獲取高亮值String name = highlightField.getFragments()[0].string();//替換hotelDoc.setName(name);}}System.out.println("hotDoc = "+hotelDoc);}
這里簡單說一下怎么得到的?handleResponse函數
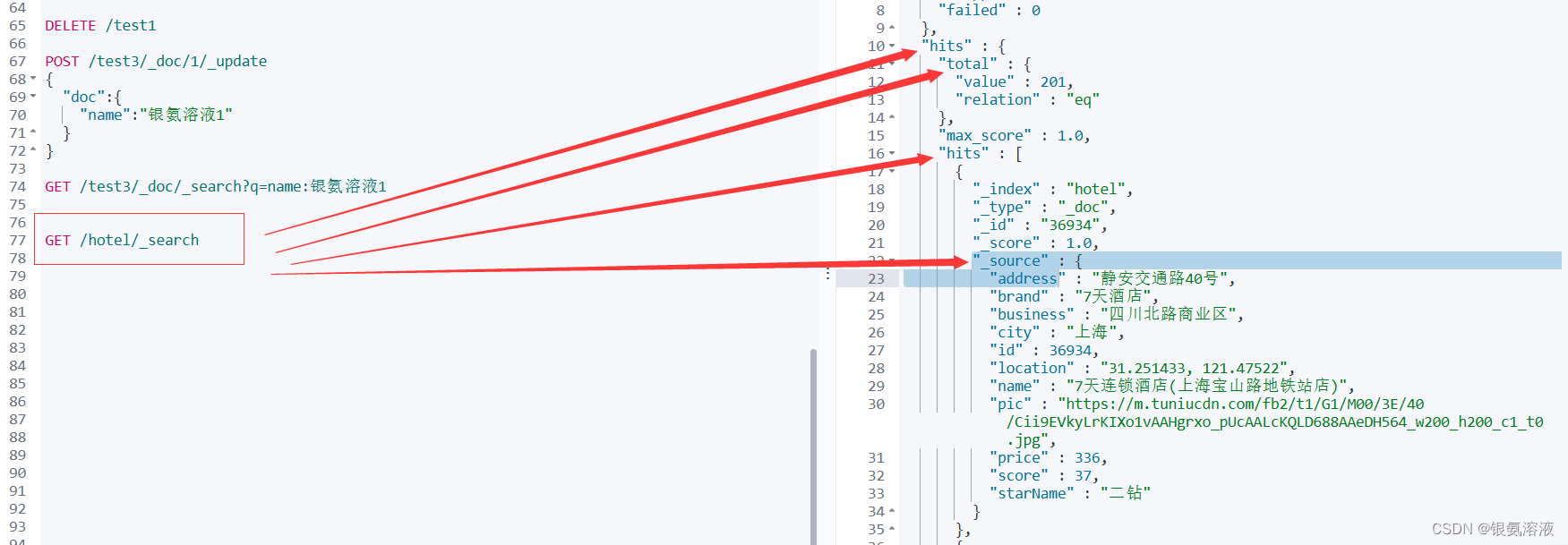
通過以上圖片我們就不難看出?response的響應結構,因此我們就可以具體推出相關信息,所以沒有學習過在Kibana上使用DSL指令的朋友可以先去學習一下,然后再來運用到java中事半功倍。
當然,如果你只需要獲取數據和總條數,可以修改成以下形式:
private PageResult handleResponse(SearchResponse response) {SearchHits hits = response.getHits();long total = hits.getTotalHits().value;SearchHit[] searchHits = hits.getHits();List<HotelDoc> hotels = new ArrayList<>();for (SearchHit searchHit : searchHits) {String source = searchHit.getSourceAsString();
// 反序列化HotelDoc hotelDoc = JSON.parseObject(source, HotelDoc.class);hotels.add(hotelDoc);}return new PageResult(total,hotels);}分頁和排序 對結果的處理
/*** 分頁和排序 對結果的處理*/@Testvoid testPageAndSort() throws IOException {int page = 1,size = 5;//1.準備requestSearchRequest request = new SearchRequest("hotel");//2.準備參數request.source().query(QueryBuilders.matchAllQuery());//排序request.source().sort("price", SortOrder.ASC);//分頁request.source().from((page-1)*size).size(size);//3.發起請求得到響應結果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析響應handleResponse(response);}當然,還有其它一些api這里還沒有介紹到,各位可以去官網進行查看詳細文檔說明~
?添加文檔
@Data
@Setter
@Getter
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {private String name;private Integer age;
} @Testvoid testAddDocument() throws IOException {
// 1、創建對象User user = new User("yinan", 20);
// 2、創建請求IndexRequest request = new IndexRequest("yinan_index");
// 規則 put /yinan_index/_doc/1request.id("1");request.timeout(TimeValue.timeValueSeconds(1));request.timeout("1s");
// 將數據放入請求 jsonrequest.source(JSON.toJSONString(user), XContentType.JSON);
// 客戶端發送請求,獲取相應的結果IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);System.out.println(indexResponse.toString());System.out.println(indexResponse.status()); //對應我們命令返回狀態}
批量添加文檔
@Testvoid testBulkRequest() throws Exception {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");ArrayList<User> userList = new ArrayList<>();userList.add(new User("yinan1", 21));userList.add(new User("yinan1", 21));userList.add(new User("yinan3", 26));userList.add(new User("yinan4", 24));userList.add(new User("yinan5", 27));userList.add(new User("yinan12", 20));for (int i = 0; i < userList.size(); i++) {bulkRequest.add(new IndexRequest("yinan_index").id("" + (i + 1)).source(JSON.toJSONString(userList.get(i)), XContentType.JSON));}BulkResponse itemResponses = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(itemResponses.hasFailures());}修改文檔
@Testvoid testUpdateDocument() throws Exception {UpdateRequest request = new UpdateRequest("yinan_index", "1");request.timeout("1s");User user = new User("yinan_update", 21);request.doc(JSON.toJSONString(user), XContentType.JSON);UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);System.out.println(updateResponse.status());}刪除文檔
@Testvoid testDeleteDocument() throws Exception {DeleteRequest request = new DeleteRequest("yinan_index", "1");request.timeout("1s");DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);System.out.println(deleteResponse.status());}以上就是對es部分api的講解,當然只看api使用是遠遠不夠的,所以我們需要做一個小訓練來鞏固我們學習的東西。
資料已經置頂在本篇博客,有需要的請自取~






)











拷貝一行)
詳解)