目錄
一、HTML、HTTP、WEB綜合問題
1 前端需要注意哪些SEO
2 img的title和alt有什么區別
3 HTTP的幾種請求方法用途
4 從瀏覽器地址欄輸入url到顯示頁面的步驟
5 如何進行網站性能優化
6 HTTP狀態碼及其含義
7 語義化的理解
8 介紹一下你對瀏覽器內核的理解?
9 html5有哪些新特性、移除了那些元素?
10 HTML5的離線儲存怎么使用,工作原理能不能解釋一下?
11 瀏覽器是怎么對HTML5的離線儲存資源進行管理和加載的呢
13 iframe有那些缺點?
14 WEB標準以及W3C標準是什么?
15 xhtml和html有什么區別?
16 Doctype作用? 嚴格模式與混雜模式如何區分?它們有何意義?
17 行內元素有哪些?塊級元素有哪些? 空(void)元素有那些?行內元素和塊級元素有什么區別?
18 HTML全局屬性(global attribute)有哪些
19 Canvas和SVG有什么區別?
20 HTML5 為什么只需要寫
21 如何在頁面上實現一個圓形的可點擊區域?
22 網頁驗證碼是干嘛的,是為了解決什么安全問題
23 viewport
24 渲染優化
25 meta viewport相關
26 你做的頁面在哪些流覽器測試過?這些瀏覽器的內核分別是什么?
27 div+css的布局較table布局有什么優點?
28 a:img的alt與title有何異同?b:strong與em的異同?
29 你能描述一下漸進增強和優雅降級之間的不同嗎
30 為什么利用多個域名來存儲網站資源會更有效?
31 簡述一下src與href的區別
32 知道的網頁制作會用到的圖片格式有哪些?
33 在CSS/JS代碼上線之后,開發人員經常會優化性能。從用戶刷新網頁開始,一次JS請求一般情況下有哪些地方會有緩存處理?
33 一個頁面上有大量的圖片(大型電商網站),加載很慢,你有哪些方法優化這些圖片的加載,給用戶更好的體驗。
34 常見排序算法的時間復雜度,空間復雜度
35 web開發中會話跟蹤的方法有哪些
36 HTTP request報文結構是怎樣的
37 HTTP response報文結構是怎樣的
38 title與h1的區別、b與strong的區別、i與em的區別
39 請你談談Cookie的弊端
40 git fetch和git pull的區別
41 http2.0 做了哪些改進 http3.0 呢
二、CSS相關
1 css sprite是什么,有什么優缺點
3 link與@import的區別
4 什么是FOUC?如何避免
5 如何創建塊級格式化上下文(block formatting context),BFC有什么用
6 display、float、position的關系
7 清除浮動的幾種方式,各自的優缺點
8 為什么要初始化CSS樣式?
9 css3有哪些新特性
10 display有哪些值?說明他們的作用
11 介紹一下標準的CSS的盒子模型?低版本IE的盒子模型有什么不同的?
12 CSS優先級算法如何計算?
13 對BFC規范的理解?
14 談談浮動和清除浮動
15 position的值, relative和absolute定位原點是
16 display:inline-block 什么時候不會顯示間隙?
17 PNG\GIF\JPG的區別及如何選
18 行內元素float:left后是否變為塊級元素?
19 在網頁中的應該使用奇數還是偶數的字體?為什么呢?
20 ::before 和 :after中雙冒號和單冒號 有什么區別?解釋一下這2個偽元素的作用
21 如果需要手動寫動畫,你認為最小時間間隔是多久,為什么?(阿里)
22 CSS合并方法
23 CSS不同選擇器的權重(CSS層疊的規則)
24 列出你所知道可以改變頁面布局的屬性
25 CSS在性能優化方面的實踐
26 CSS3動畫(簡單動畫的實現,如旋轉等)
27 base64的原理及優缺點
28 幾種常見的CSS布局
流體布局
圣杯布局
29 stylus/sass/less區別
30 postcss的作用
31 css樣式(選擇器)的優先級
32 自定義字體的使用場景
33 如何美化CheckBox
34 偽類和偽元素的區別
35 base64的使用
36 自適應布局
37 請用CSS寫一個簡單的幻燈片效果頁面
38 什么是外邊距重疊?重疊的結果是什么?
39 rgba()和opacity的透明效果有什么不同?
40 css中可以讓文字在垂直和水平方向上重疊的兩個屬性是什么?
41 如何垂直居中一個浮動元素?
42 px和em的區別
43 Sass、LESS是什么?大家為什么要使用他們?
44 知道css有個content屬性嗎?有什么作用?有什么應用?
45 水平居中的方法
46 垂直居中的方法
47 如何使用CSS實現硬件加速?
48 重繪和回流(重排)是什么,如何避免?
49 說一說css3的animation
50 左邊寬度固定,右邊自適應
51 兩種以上方式實現已知或者未知寬度的垂直水平居中
52 如何實現小于12px的字體效果
53 css hack原理及常用hack
54 CSS有哪些繼承屬性
55 外邊距折疊(collapsing margins)
56 CSS選擇符有哪些?哪些屬性可以繼承
57 CSS3新增偽類有那些
58 如何居中div?如何居中一個浮動元素?如何讓絕對定位的div居中
59 用純CSS創建一個三角形的原理是什么
60 一個滿屏 品 字布局 如何設計?
61 li與li之間有看不見的空白間隔是什么原因引起的?有什么解決辦法
62 請列舉幾種隱藏元素的方法
63 rgba() 和 opacity 的透明效果有什么不同
64 css 屬性 content 有什么作用
65 請解釋一下 CSS3 的 Flexbox(彈性盒布局模型)以及適用場景
66 經常遇到的瀏覽器的JS兼容性有哪些?解決方法是什么
67 請寫出多種等高布局
68 浮動元素引起的問題
69 CSS優化、提高性能的方法有哪些
70 瀏覽器是怎樣解析CSS選擇器的
71 在網頁中的應該使用奇數還是偶數的字體
72 margin和padding分別適合什么場景使用
73 抽離樣式模塊怎么寫,說出思路
74 元素豎向的百分比設定是相對于容器的高度嗎
75 全屏滾動的原理是什么? 用到了CSS的那些屬性
76 什么是響應式設計?響應式設計的基本原理是什么?如何兼容低版本的IE
77 什么是視差滾動效果,如何給每頁做不同的動畫
78 a標簽上四個偽類的執行順序是怎么樣的
79 偽元素和偽類的區別和作用
80 ::before 和 :after 中雙冒號和單冒號有什么區別
81 如何修改Chrome記住密碼后自動填充表單的黃色背景
82 網站圖片文件,如何點擊下載?而非點擊預覽
83 你對 line-height 是如何理解的
84 line-height 三種賦值方式有何區別?(帶單位、純數字、百分比)
85 設置元素浮動后,該元素的 display 值會如何變化
86 讓頁面里的字體變清晰,變細用CSS怎么做?(IOS手機瀏覽器字體齒輪設置)
87 font-style 屬性 oblique 是什么意思
88 display:inline-block 什么時候會顯示間隙
89 一個高度自適應的div,里面有兩個div,一個高度100px,希望另一個填滿剩下的高度
90 css 的渲染層合成是什么 瀏覽器如何創建新的渲染層
三、JavaScript相關
1 閉包
2 說說你對作用域鏈的理解
3 JavaScript原型,原型鏈 ? 有什么特點?
4 請解釋什么是事件代理
5 Javascript如何實現繼承?
6 談談This對象的理解
7 事件模型
8 new操作符具體干了什么呢?
9 Ajax原理
10 如何解決跨域問題?
11 模塊化開發怎么做?
12 異步加載JS的方式有哪些?
13 那些操作會造成內存泄漏?
14 XML和JSON的區別?
15 談談你對webpack的看法
16 說說你對AMD和Commonjs的理解
17 常見web安全及防護原理
18 用過哪些設計模式?
19 為什么要有同源限制?
20 offsetWidth/offsetHeight,clientWidth/clientHeight與scrollWidth/scrollHeight的區別
21 javascript有哪些方法定義對象
22 常見兼容性問題?
23 說說你對promise的了解
24 你覺得jQuery源碼有哪些寫的好的地方
25 談談你對vue、react、angular的理解
26 Node的應用場景
27 談談你對AMD、CMD的理解
28 那些操作會造成內存泄漏
29 web開發中會話跟蹤的方法有哪些
30 JS的基本數據類型和引用數據類型
31 介紹js有哪些內置對象
32 說幾條寫JavaScript的基本規范
33 JavaScript有幾種類型的值
34 eval是做什么的
35 null,undefined 的區別
36 ["1 ", "2 ", "3 "].map(parseInt) 答案是多少
37 javascript 代碼中的 "use strict ";是什么意思
38 JSON 的了解
39 js延遲加載的方式有哪些
40 同步和異步的區別
41 defer和async
42 說說嚴格模式的限制
43 attribute和property的區別是什么
44 談談你對ES6的理解
45 什么是面向對象編程及面向過程編程,它們的異同和優缺點
46 面向對象編程思想
47 對web標準、可用性、可訪問性的理解
48 如何通過JS判斷一個數組
49 談一談let與var的區別
50 map與forEach的區別
51 談一談你理解的函數式編程
52 談一談箭頭函數與普通函數的區別?
53 談一談函數中this的指向
54 異步編程的實現方式
56 談談你對原生Javascript了解程度
57 Js動畫與CSS動畫區別及相應實現
58 JS 數組和對象的遍歷方式,以及幾種方式的比較
-
一、HTML、HTTP、WEB綜合問題
-
1 前端需要注意哪些SEO
-
- 合理的
title、description、keywords:搜索引擎對這些標簽的權重逐漸減小。在title中,強調重點即可,重要關鍵詞不要超過2次,并且要靠前。每個頁面的title應該有所不同。description應該高度概括頁面內容,長度適當,避免過度堆砌關鍵詞。每個頁面的description也應該有所不同。keywords標簽應列舉出重要關鍵詞即可。
- 針對
title標簽,可以使用重要關鍵詞、品牌詞或描述頁面內容的短語。確保標題簡潔、準確地概括頁面的主題,并吸引用戶點擊。- 在編寫
description標簽時,應盡量使用簡潔、具有吸引力的語句來概括頁面的內容,吸引用戶點擊搜索結果。避免堆砌關鍵詞,以自然流暢的方式描述頁面keywords標簽已經不再是搜索引擎排名的重要因素,但仍然可以列舉出與頁面內容相關的幾個重要關鍵詞,以便搜索引擎了解頁面的主題。- 語義化的
HTML代碼,符合W3C規范:使用語義化的HTML代碼可以讓搜索引擎更容易理解網頁的結構和內容。遵循W3C規范可以提高網頁的可讀性和可訪問性,對SEO也有好處。- 重要內容
HTML代碼放在最前:搜索引擎抓取HTML的順序是從上到下,有些搜索引擎對抓取長度有限制。因此,將重要的內容放在HTML的前面,確保重要內容一定會被抓取。- 重要內容不要用
js輸出:爬蟲不會執行JavaScript,所以重要的內容不應該依賴于通過JavaScript動態生成。確保重要內容在HTML中靜態存在。- 少用
iframe:搜索引擎通常不會抓取iframe中的內容,因此應該盡量減少iframe的使用,特別是對于重要的內容。- 非裝飾性圖片必須加
alt:為非裝飾性圖片添加alt屬性,可以為搜索引擎提供關于圖片內容的描述,同時也有助于可訪問性。- 提高網站速度:網站速度是搜索引擎排序的一個重要指標
-
-
2 <img >的title和alt有什么區別
-
title屬性:title屬性是HTML元素通用的屬性,適用于各種元素,不僅僅是<img >標簽。當鼠標滑動到元素上時,瀏覽器會顯示title屬性的內容,提供額外的信息或解釋,幫助用戶了解元素的用途或含義。對于<img >標簽,鼠標懸停在圖片上時會顯示title屬性的內容。
alt屬性:alt屬性是<img >標簽的特有屬性,用于提供圖片的替代文本描述。當圖片無法加載時,瀏覽器會顯示alt屬性的內容,或者在可訪問性場景中,讀屏器會讀取alt屬性的內容。alt屬性的主要目的是提高圖片的可訪問性,使無法查看圖片的用戶也能了解圖片的內容或含義。除了純裝飾性圖片外,所有<img >標簽都應該設置有意義的alt屬性值。補充答案:
title屬性主要用于提供額外的信息或提示,是對圖片的補充描述,可以用于提供更詳細的說明,如圖片的來源、作者、相關信息等。它不是必需的,但可以增強用戶體驗,特別是在需要顯示更多信息時。alt屬性是圖片內容的等價描述,應該簡潔明了地描述圖片所表達的信息。它對于可訪問性至關重要,確保無障礙用戶能夠理解圖片的含義,同時也是搜索引擎重點分析的內容。在設置alt屬性時,應該避免過度堆砌關鍵詞,而是提供準確、有意義的描述。
-
-
3 HTTP的幾種請求方法用途
-
GET方法:
- 用途:發送一個請求來獲取服務器上的某一資源。
- 面試可能涉及的問題:
- GET方法的特點是什么?
- GET方法是HTTP的一種請求方法,用于從服務器獲取資源。
- 它是一種冪等的方法,多次發送相同的GET請求會返回相同的結果。
- GET請求和POST請求的區別是什么?
- GET請求將參數附加在URL的查詢字符串中,而POST請求將參數放在請求體中。
- GET請求的數據會顯示在URL中,而POST請求的數據不會顯示在URL中。
- GET請求一般用于獲取數據,而POST請求一般用于提交數據。
- GET請求可以有請求體嗎?
- 根據HTTP規范,GET請求不應該有請求體,參數應該通過URL的查詢字符串傳遞。
- GET請求的參數如何傳遞?
- GET請求的參數可以通過URL的查詢字符串傳遞,例如:
/api/users?id=123 &name=poetry。- GET請求的安全性和冪等性如何保證?
- GET請求不會對服務器端的資源產生副作用,因此被視為安全的。
- GET請求是冪等的,多次發送相同的GET請求不會對服務器端產生影響。
POST方法:
- 用途:向
URL指定的資源提交數據或附加新的數據。- 面試可能涉及的問題:
- POST方法的特點是什么?
- POST方法是HTTP的一種請求方法,用于向服務器提交數據。
- 它不是冪等的,多次發送相同的POST請求可能會產生不同的結果。
- POST請求和GET請求的區別是什么?
- POST請求將參數放在請求體中,而GET請求將參數附加在URL的查詢字符串中。
- POST請求的數據不會顯示在URL中,而GET請求的數據會顯示在URL中。
- POST請求一般用于提交數據,而GET請求一般用于獲取數據。
- POST請求的請求體如何傳遞數據?
- POST請求的數據可以通過請求體以表單形式傳遞,或者以JSON等格式傳遞。
- POST請求的安全性和冪等性如何保證?
- POST請求可能對服務器端的資源產生副作用,因此被視為不安全的。
- POST請求不是冪等的,多次發送相同的POST請求可能會對服務器端產生影響。
- PUT方法:
- 用途:將數據發送給服務器,并將其存儲在指定的URL位置。與POST方法不同的是,PUT方法指定了資源在服務器上的位置。
- 面試可能涉及的問題:
- PUT方法的特點是什么?
- PUT方法是HTTP的一種請求方法,用于將數據發送給服務器并存儲在指定的URL位置。
- 它是一種冪等的方法,多次發送相同的PUT請求會對服務器端產生相同的結果。
- PUT請求和POST請求有什么區別?
- PUT請求用于指定資源在服務器上的位置,而POST請求沒有指定位置。
- PUT請求一般用于更新或替換資源,而POST請求一般用于新增資源或提交數據。
- PUT請求的冪等性如何保證?
- PUT請求的冪等性保證是由服務器端實現的。
- 服務器端應該根據請求中的資源位置來處理請求,多次發送相同的PUT請求會對該位置上的資源進行相同的更新或替換操作。
HEAD方法
- 只請求頁面的首部
DELETE方法
- 刪除服務器上的某資源
OPTIONS方法
- 它用于獲取當前
URL所支持的方法。如果請求成功,會有一個Allow的頭包含類似“GET,POST”這樣的信息TRACE方法
TRACE方法被用于激發一個遠程的,應用層的請求消息回路CONNECT方法
- 把請求連接轉換到透明的
TCP/IP通道
-
-
4 從瀏覽器地址欄輸入url到顯示頁面的步驟
-
基礎版本
- 瀏覽器根據請求的
URL交給DNS域名解析,找到真實IP,向服務器發起請求;- 服務器交給后臺處理完成后返回數據,瀏覽器接收文件(
HTML、JS、CSS、圖象等);- 瀏覽器對加載到的資源(
HTML、JS、CSS等)進行語法解析,建立相應的內部數據結構(如HTML的DOM);- 載入解析到的資源文件,渲染頁面,完成。
普通版
1.輸入url地址后,首先進行DNS解析,將相應的域名解析為IP地址;
2.客戶端根據IP地址去尋找相應的服務器;
3.與服務器簡歷TCP鏈接(與服務器進行TCP的三次握手);
所謂三次握手就是客戶端在請求與服務器相連接時,彼此共計發送了三次數據包,就好比以下的對話:
首先,需要明確的是,三次握手是客戶端先發起請求。
(第一次)客戶端:hi,服務器,在嗎?我想和你建立連接,你能收到我的消息嗎?(此時客戶端給服務端發送了一個數據包和發送序號,即SYN=1,Seq=X)
(第二次)服務器:hi,客戶端,我在呢,我收到你的消息了,我們可以建立連接,你能收到我答復的消息嗎?(此時服務端發送syn+ack報文,并置發送序號為Y,再確認序號為X+1)
(第三次)客戶端:我收到你的答復了,很開心能和你建立連接。(此時客戶端發送ack報文,并置發送序號為Z,再確認序號為Y+1)
以上就是tcp三次握手的簡化版
3.發送HTTP請求:
4.服務器得到并處理請求,返回HTTP報文:
5.瀏覽器解析渲染:
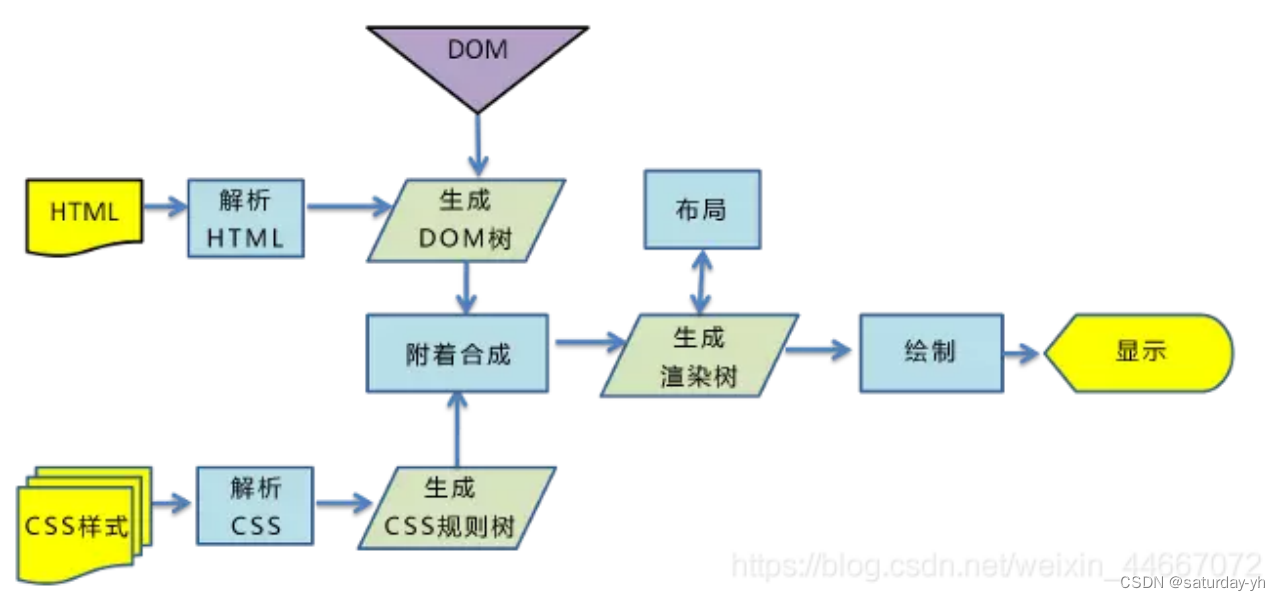
所以瀏覽器的渲染過程主要包括以下幾步:
解析HTML生成DOM樹。
解析CSS生成CSSOM規則樹。
將DOM樹與CSSOM規則樹合并在一起生成渲染樹。(render tree)
遍歷渲染樹開始布局,計算每個節點的位置大小信息。
將渲染樹每個節點繪制到屏幕。
6.斷開連接(四次揮手):
當數據傳送完畢,需要斷開 TCP連接,此時發起 TCP 四次揮手。
1、第一次揮手:由瀏覽器發起,發送給服務器,我請求報文發送完了,你準備關閉吧;
2、第二次揮手:由服務器發起,告訴瀏覽器,我接收完請求報文,我準備關閉,你也準備吧;
3、第三次揮手:由服務器發起,告訴瀏覽器,我響應報文發送完畢,你準備關閉吧;
4、第四次揮手:由瀏覽器發起,告訴服務器,我響應報文接收完畢,我準備關閉,你也準備吧;
詳細版
- 在瀏覽器地址欄輸入URL
- 瀏覽器查看緩存 ,如果請求資源在緩存中并且新鮮,跳轉到轉碼步驟
- 如果資源未緩存,發起新請求
- 如果已緩存,檢驗是否足夠新鮮,足夠新鮮直接提供給客戶端,否則與服務器進行驗證。
- 檢驗新鮮通常有兩個HTTP頭進行控制
Expires和Cache-Control:
- HTTP1.0提供Expires,值為一個絕對時間表示緩存新鮮日期
- HTTP1.1增加了Cache-Control: max-age=,值為以秒為單位的最大新鮮時間
- 瀏覽器解析URL 獲取協議,主機,端口,path
- 瀏覽器組裝一個HTTP(GET)請求報文
- 瀏覽器獲取主機ip地址 ,過程如下:
- 瀏覽器緩存
- 本機緩存
- hosts文件
- 路由器緩存
- ISP DNS緩存
- DNS遞歸查詢(可能存在負載均衡導致每次IP不一樣)
- 打開一個socket與目標IP地址,端口建立TCP鏈接 ,三次握手如下:
- 客戶端發送一個TCP的SYN=1,Seq=X 的包到服務器端口
- 服務器發回SYN=1, ACK=X+1, Seq=Y 的響應包
- 客戶端發送ACK=Y+1, Seq=Z
- TCP鏈接建立后發送HTTP請求
- 服務器接受請求并解析,將請求轉發到服務程序,如虛擬主機使用HTTP Host頭部判斷請求的服務程序
- 服務器檢查HTTP請求頭是否包含緩存驗證信息 如果驗證緩存新鮮,返回304 等對應狀態碼
- 處理程序讀取完整請求并準備HTTP響應,可能需要查詢數據庫等操作
- 服務器將響應報文通過TCP連接發送回瀏覽器
- 瀏覽器接收HTTP響應,然后根據情況選擇關閉TCP連接或者保留重用,關閉TCP連接的四次握手如下 :
- 主動方發送Fin=1, Ack=Z, Seq= X 報文
- 被動方發送ACK=X+1, Seq=Z 報文
- 被動方發送Fin=1, ACK=X, Seq=Y 報文
- 主動方發送ACK=Y, Seq=X 報文
- 瀏覽器檢查響應狀態嗎:是否為1XX,3XX, 4XX, 5XX,這些情況處理與2XX不同
- 如果資源可緩存,進行緩存
- 對響應進行解碼 (例如gzip壓縮)
- 根據資源類型決定如何處理(假設資源為HTML文檔)
- 解析HTML文檔,構件DOM樹,下載資源,構造CSSOM樹,執行js腳本 ,這些操作沒有嚴格的先后順序,以下分別解釋
- 構建DOM樹 :
- Tokenizing :根據HTML規范將字符流解析為標記
- Lexing :詞法分析將標記轉換為對象并定義屬性和規則
- DOM construction :根據HTML標記關系將對象組成DOM樹
- 解析過程中遇到圖片、樣式表、js文件,啟動下載
- 構建CSSOM樹 :
- Tokenizing :字符流轉換為標記流
- Node :根據標記創建節點
- CSSOM :節點創建CSSOM樹
- 根據DOM樹和CSSOM樹構建渲染樹 (opens new window) :
- 從DOM樹的根節點遍歷所有可見節點 ,不可見節點包括:1)
script,meta這樣本身不可見的標簽。2)被css隱藏的節點,如display: none- 對每一個可見節點,找到恰當的CSSOM規則并應用
- 發布可視節點的內容和計算樣式
- js解析如下 :
- 瀏覽器創建Document對象并解析HTML,將解析到的元素和文本節點添加到文檔中,此時document.readystate為loading
- HTML解析器遇到沒有async和defer的script時 ,將他們添加到文檔中,然后執行行內或外部腳本。這些腳本會同步執行,并且在腳本下載和執行時解析器會暫停。這樣就可以用document.write()把文本插入到輸入流中。同步腳本經常簡單定義函數和注冊事件處理程序,他們可以遍歷和操作script和他們之前的文檔內容
- 當解析器遇到設置了async 屬性的script時,開始下載腳本并繼續解析文檔。腳本會在它下載完成后盡快執行 ,但是解析器不會停下來等它下載 。異步腳本禁止使用document.write() ,它們可以訪問自己script和之前的文檔元素
- 當文檔完成解析,document.readState變成interactive
- 所有defer 腳本會按照在文檔出現的順序執行 ,延遲腳本能訪問完整文檔樹 ,禁止使用document.write()
- 瀏覽器在Document對象上觸發DOMContentLoaded事件
- 此時文檔完全解析完成,瀏覽器可能還在等待如圖片等內容加載,等這些內容完成載入并且所有異步腳本完成載入和執行 ,document.readState變為complete,window觸發load事件
- 顯示頁面 (HTML解析過程中會逐步顯示頁面)
詳細簡版
- 從瀏覽器接收
url到開啟網絡請求線程(這一部分可以展開瀏覽器的機制以及進程與線程之間的關系)- 開啟網絡線程到發出一個完整的
HTTP請求(這一部分涉及到dns查詢,TCP/IP請求,五層因特網協議棧等知識)- 從服務器接收到請求到對應后臺接收到請求(這一部分可能涉及到負載均衡,安全攔截以及后臺內部的處理等等)
- 后臺和前臺的
HTTP交互(這一部分包括HTTP頭部、響應碼、報文結構、cookie等知識,可以提下靜態資源的cookie優化,以及編碼解碼,如gzip壓縮等)- 單獨拎出來的緩存問題,
HTTP的緩存(這部分包括http緩存頭部,ETag,catch-control等)- 瀏覽器接收到
HTTP數據包后的解析流程(解析html-詞法分析然后解析成dom樹、解析css生成css規則樹、合并成render樹,然后layout、painting渲染、復合圖層的合成、GPU繪制、外鏈資源的處理、loaded和DOMContentLoaded等)CSS的可視化格式模型(元素的渲染規則,如包含塊,控制框,BFC,IFC等概念)JS引擎解析過程(JS的解釋階段,預處理階段,執行階段生成執行上下文,VO,作用域鏈、回收機制等等)- 其它(可以拓展不同的知識模塊,如跨域,web安全,
hybrid模式等等內容)
-
-
5 如何進行網站性能優化
-
content方面
- 減少
HTTP請求:合并文件、CSS精靈、inline Image- 減少
DNS查詢:DNS緩存、將資源分布到恰當數量的主機名- 減少
DOM元素數量Server方面
- 使用
CDN- 配置
ETag- 對組件使用
Gzip壓縮Cookie方面
- 減小
cookie大小css方面
- 將樣式表放到頁面頂部
- 不使用
CSS表達式- 使用
<link >不使用@importJavascript方面
- 將腳本放到頁面底部
- 將
javascript和css從外部引入- 壓縮
javascript和css- 刪除不需要的腳本
- 減少
DOM訪問- 圖片方面
- 優化圖片:根據實際顏色需要選擇色深、壓縮
- 優化
css精靈- 不要在
HTML中拉伸圖片
你有用過哪些前端性能優化的方法?
- 減少
http請求次數:CSS Sprites,JS、CSS源碼壓縮、圖片大小控制合適;網頁Gzip,CDN托管,data緩存 ,圖片服務器。- 前端模板 JS+數據,減少由于HTML標簽導致的帶寬浪費,前端用變量保存
AJAX請求結果,每次操作本地變量,不用請求,減少請求次數- 用
innerHTML代替DOM操作,減少DOM操作次數,優化javascript性能。- 當需要設置的樣式很多時設置
className而不是直接操作style- 少用全局變量、緩存DOM節點查找的結果。減少IO讀取操作
- 避免使用
CSS Expression(css表達式)又稱Dynamic properties(動態屬性)- 圖片預加載,將樣式表放在頂部,將腳本放在底部 加上時間戳
- 避免在頁面的主體布局中使用
table,table要等其中的內容完全下載之后才會顯示出來,顯示比div+css布局慢談談性能優化問題
- 代碼層面:避免使用
css表達式,避免使用高級選擇器,通配選擇器- 緩存利用:緩存
Ajax,使用CDN,使用外部js和css文件以便緩存,添加Expires頭,服務端配置Etag,減少DNS查找等- 請求數量:合并樣式和腳本,使用
css圖片精靈,初始首屏之外的圖片資源按需加載,靜態資源延遲加載- 請求帶寬:壓縮文件,開啟
GZIP前端性能優化最佳實踐?
- 性能評級工具(
PageSpeed或YSlow)- 合理設置
HTTP緩存:Expires與Cache-control- 靜態資源打包,開啟 Gzip 壓縮(節省響應流量)
CSS3模擬圖像,圖標base64(降低請求數)- 模塊延遲(defer)加載/異步(
async)加載Cookie隔離(節省請求流量)localStorage(本地存儲)- 使用
CDN加速(訪問最近服務器)- 啟用
HTTP/2(多路復用,并行加載)- 前端自動化(
gulp/webpack)
-
-
6 HTTP狀態碼及其含義
-
1XX:信息狀態碼
100 Continue繼續,一般在發送post請求時,已發送了http header之后服務端將返回此信息,表示確認,之后發送具體參數信息2XX:成功狀態碼
200 OK正常返回信息201 Created請求成功并且服務器創建了新的資源202 Accepted服務器已接受請求,但尚未處理3XX:重定向
301 Moved Permanently請求的網頁已永久移動到新位置。302 Found臨時性重定向。303 See Other臨時性重定向,且總是使用GET請求新的URI。304 Not Modified自從上次請求后,請求的網頁未修改過。4XX:客戶端錯誤
400 Bad Request服務器無法理解請求的格式,客戶端不應當嘗試再次使用相同的內容發起請求。401 Unauthorized請求未授權。403 Forbidden禁止訪問。404 Not Found找不到如何與URI相匹配的資源。5XX:服務器錯誤
500 Internal Server Error最常見的服務器端錯誤。503 Service Unavailable服務器端暫時無法處理請求(可能是過載或維護)
-
-
7 語義化的理解
-
語義化是指在編寫HTML和CSS代碼時,通過恰當的選擇標簽和屬性,使得代碼更具有語義性和可讀性,使得頁面結構和內容更加清晰明了。語義化的目的是讓頁面具備良好的可訪問性、可維護性和可擴展性。
語義化的重要性體現在以下幾個方面:
- 可訪問性(Accessibility) :通過使用恰當的標簽和屬性,可以提高頁面的可訪問性,使得輔助技術(如屏幕閱讀器)能夠更好地理解和解析頁面內容,使得殘障用戶能夠正常瀏覽和使用網頁。
- 搜索引擎優化(SEO) :搜索引擎更喜歡能夠理解和解析的頁面內容,語義化的HTML結構可以提高頁面在搜索引擎結果中的排名,增加網頁的曝光和訪問量。
- 代碼可讀性和可維護性 :使用語義化的標簽和屬性,可以讓代碼更易于閱讀和理解,提高代碼的可維護性。開發人員可以更快速地定位和修改特定功能或內容。
- 設備兼容性 :不同設備和平臺對于網頁的渲染和解析方式有所不同,語義化的代碼可以增加網頁在各種設備上的兼容性,確保頁面在不同環境中的正確顯示和使用。
語義化在前端開發中的具體表現和實踐包括以下幾個方面:
- 選擇合適的HTML標簽 :在構建頁面結構時,選擇恰當的HTML標簽來描述內容的含義。例如,使用
<header >表示頁面的頁眉,<nav >表示導航欄,<article >表示獨立的文章內容等。 - 使用有意義的標簽和屬性 :避免濫用
<div >標簽,而是選擇更具語義的標簽來表達內容的含義。同時,合理使用標簽的屬性,如alt屬性用于圖像的替代文本,title屬性用于提供額外的信息等。 - 結構和層次化 :通過正確嵌套和組織HTML元素,構建清晰的頁面結構和層次關系。使用語義化的父子關系,讓內容的層級關系更加明確,便于樣式和腳本的編寫和維護。
- 文本格式化 :使用合適的標簽和屬性來標記文本的格式和語義。例如,使用
<strong >標簽表示重要文本,<em >標簽表示強調文





)
)






)





