前言:在醫學領域,科技的進步一直是改變人類生活的關鍵驅動力之一。隨著深度學習技術的不斷發展,其在醫學影像診斷領域的應用正日益受到關注。結直腸癌是一種常見但危害極大的惡性腫瘤,在早期發現和及時治療方面具有重要意義。然而,傳統的結直腸癌檢測方法往往受限于操作復雜、依賴經驗和易產生誤診等問題,因此急需一種準確、快速、非侵入性的檢測方法。雙深度學習模型的出現為解決這一難題帶來了新的希望。通過結合不同深度學習技術,這些模型能夠從結直腸癌醫學影像中提取豐富的特征信息,實現對癌變組織的精準識別和定位。本文將探討雙深度學習模型在結直腸癌檢測中的應用,剖析其原理和技術實現,并展望其在臨床實踐中的潛在價值。隨著技術的不斷演進,相信這些創新性的方法將為結直腸癌的早期篩查和診斷帶來革命性的變革,為患者提供更加及時有效的醫療服務,實現醫學與人工智能的完美融合。
本文所涉及所有資源均在傳知代碼平臺可獲取
目錄
概述
演示效果
核心代碼
寫在最后
概述
????????結直腸癌是一種全球范圍內常見的惡性腫瘤,其發病率和死亡率呈上升趨勢,早期發現對提高治療效果和患者生存率至關重要,但傳統診斷方法存在主觀性和時間成本高的問題,結直腸癌組織切片圖像具有復雜結構,需要精確的圖像處理技術來輔助診斷,開發基于深度學習的結直腸癌識別系統,旨在提高診斷效率,減少傳統方法的局限性。利用深度學習技術自動分類結直腸癌圖像,為醫生提供可靠的輔助工具,提升臨床決策質量。該系統通過自動化圖像識別,有助于改善患者的治療結果,提高生存率,同時為醫學圖像處理和深度學習在腫瘤診斷領域的應用提供新思路和實踐基礎。
ResNet34是殘差網絡(Residual Networks)的一個變種,由微軟研究院提出,屬于深度卷積神經網絡(CNN)的一種。殘差網絡的設計初衷是為了解決深度網絡訓練中的退化問題,即隨著網絡層數的增加,網絡的性能反而下降。ResNet通過引入“殘差學習”來解決這個問題,允許訓練更深的網絡。ResNet34包含34個殘差塊,每個殘差塊由兩個卷積層組成,中間通過跳躍連接(skip connection)連接。這種結構允許網絡中的信號繞過一些層直接傳遞,從而緩解了梯度消失和梯度爆炸的問題,如下圖所示:
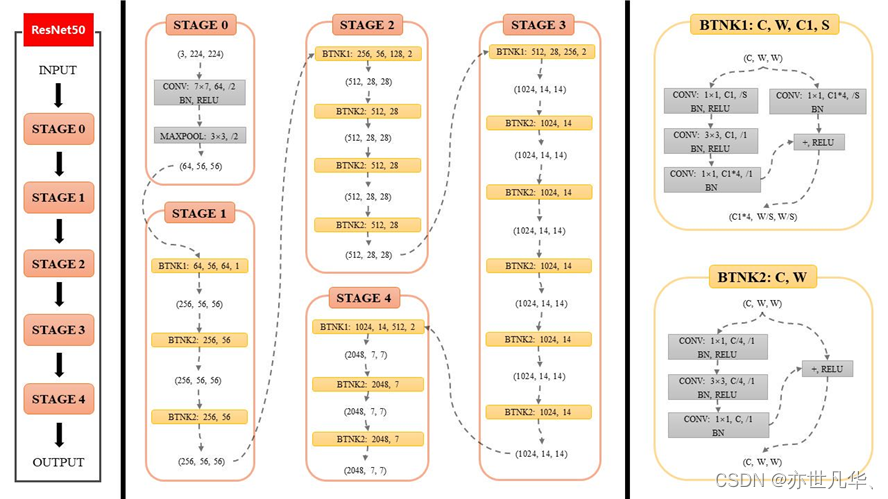
ResNet34的關鍵特性有以下特性:
1)殘差學習:每個殘差塊學習的是層間的差異(即殘差),而不是直接學習未加工的特征。這使得網絡可以通過跳躍連接直接傳遞信息,即使網絡非常深。
2)跳躍連接:跳躍連接允許網絡中的信號繞過一些層直接傳遞,有助于梯度在訓練過程中更有效地反向傳播。
3)批量歸一化:ResNet34在每個殘差塊的卷積層之后使用批量歸一化,有助于加快訓練速度并提高訓練穩定性。
4)ReLU激活函數:在卷積層之后使用ReLU激活函數,引入非線性,增強網絡的表達能力。
5)初始卷積層:在輸入圖像進入第一個殘差塊之前,首先通過一個7x7的卷積層進行特征提取,然后通過一個最大池化層進行下采樣。
6)分類層:在網絡的最后,使用一個全連接層(通常稱為分類層)來進行圖像分類。
????????Vision Transformer(ViT)是一種用于圖像識別任務的深度學習模型,由Google Research在2017年提出。ViT模型是Transformer模型在計算機視覺領域的應用,它與傳統的卷積神經網絡(CNN)不同,主要依賴于自注意力機制來處理圖像數據,ViT有以下特性:
自注意力機制:ViT模型的核心是自注意力機制,它允許模型在處理圖像時考慮全局依賴關系,而不是僅依賴局部感受野。
無卷積操作:與CNN不同,ViT模型不使用卷積層。它將圖像分割成大小相同的小塊(patches),然后將這些小塊線性嵌入到一個序列中,再應用標準的Transformer結構。
位置編碼:由于Transformer模型本身不具備捕捉序列順序的能力,ViT為圖像塊添加了位置編碼,以保持圖像的空間結構信息。
分類任務的頭部:ViT模型通常在Transformer結構的頂部添加一個全連接層,用于圖像分類任務。
對于ViT模型的工作流程如下:
1)圖像分割:將輸入圖像分割成大小為(16x16)像素的小塊,例如,對于一個(224x224)像素的圖像,會得到(14x14)個小塊。
2)線性嵌入:每個小塊通過一個線性層進行嵌入,將小塊的像素值映射到一個高維空間。
3)位置編碼:為每個嵌入后的小塊添加位置編碼,以保持其在原始圖像中的位置信息。
4)Transformer編碼器:將編碼后的序列輸入到一個或多個Transformer編碼器層中,每層都包括自注意力機制和前饋網絡。
5)分類頭部:在Transformer編碼器的輸出上應用一個全連接層,將特征映射到類別標簽上。
演示效果
對于準確率(Accuracy)的可視化,可以通過不同的方式呈現模型的性能情況。以下是呈現出來的結果:
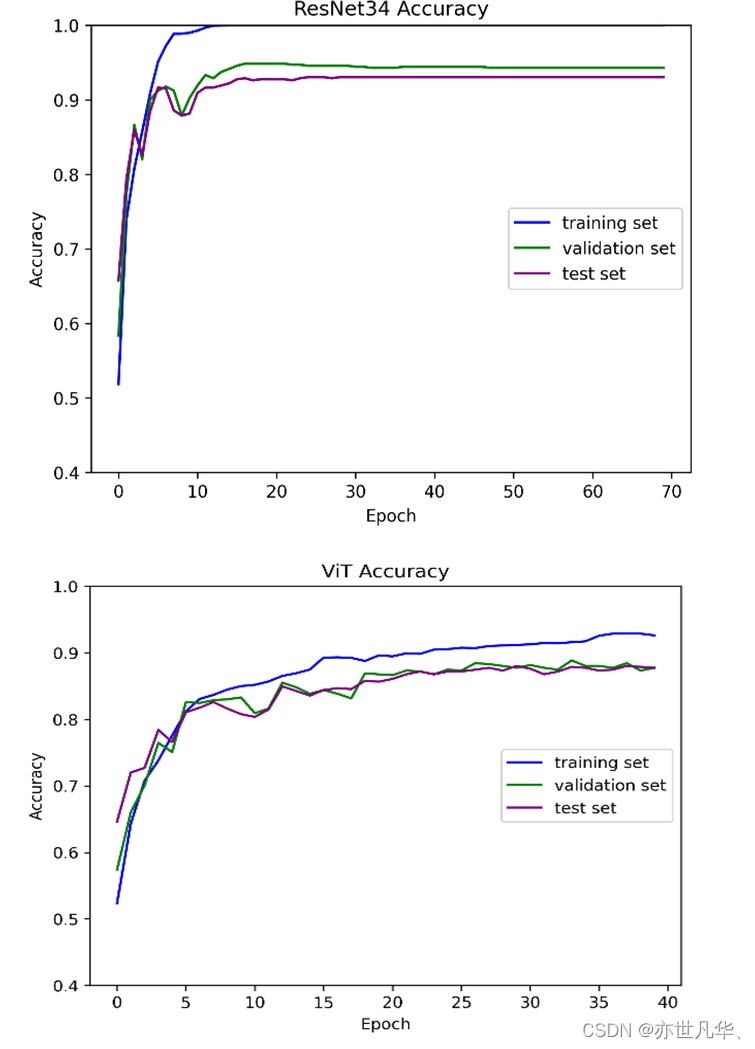
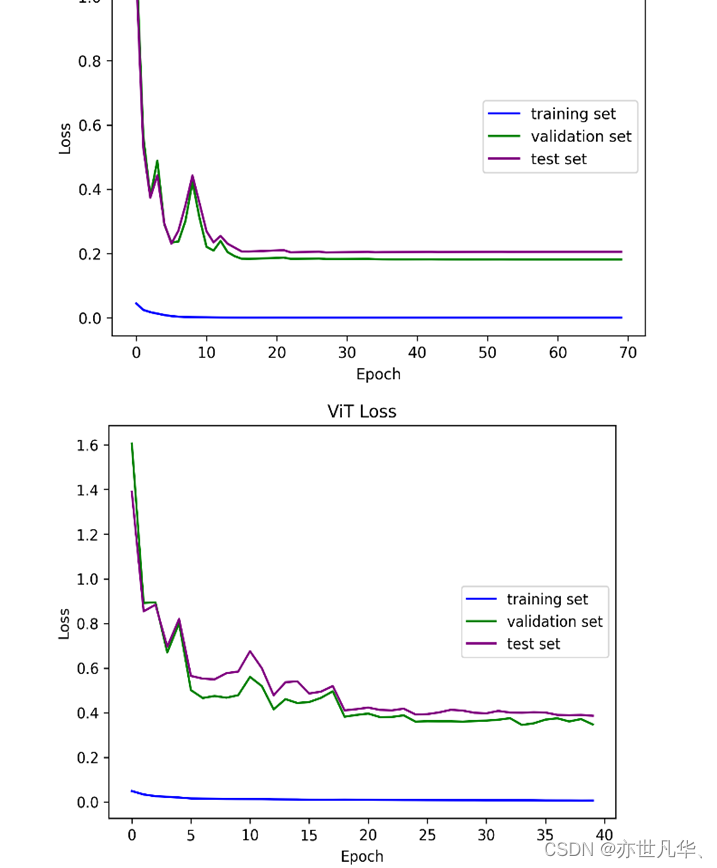
Loss(損失)的可視化是指將模型在訓練過程中的損失值隨著訓練迭代次數的增加而變化的趨勢進行可視化展示。損失值通常是用來衡量模型在訓練過程中預測結果與真實標簽之間的差異程度的指標,即模型預測的結果與真實標簽之間的誤差大小,如下圖所示:
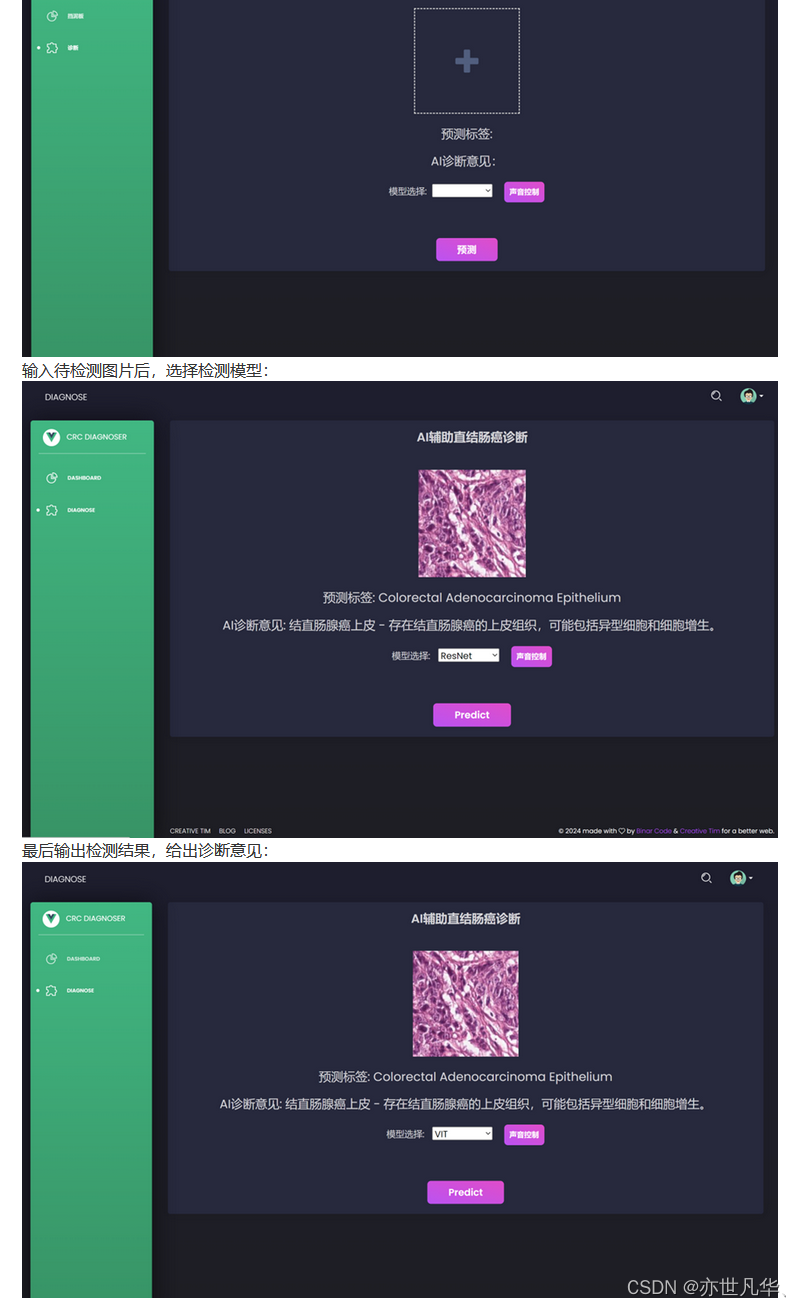
最終系統展示如下所示:
核心代碼
下面這段代碼定義了一個 ResNet 模型的類 ResNet,它用于構建 ResNet 網絡結構,該方法定義了數據在網絡中的正向傳播過程,即輸入數據經過各層的處理最終得到輸出結果。通常會調用已經定義好的組件,如卷積層、殘差塊序列等,以完成整個網絡的前向傳播過程,通過這個類,可以創建并使用 ResNet 模型來進行圖像分類任務:
class ResNet(nn.Module):def __init__(self, block, layers, nums, num_classes, type) -> None:super(ResNet,self).__init__()self.arch = typeself.conv1 = nn.Conv2d(in_channels=3, out_channels=layers[0], kernel_size=7, stride=2, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(layers[0])self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.in_channels = layers[0]self.layers = torch.nn.Sequential(self._make_layers(block, layers[0], nums[0]),self._make_layers(block, layers[1], nums[1], stride=2),self._make_layers(block, layers[2], nums[2], stride=2),self._make_layers(block, layers[3], nums[3], stride=2))self.size = layersself.avg = nn.AvgPool2d(kernel_size=7)self.linear = nn.Linear(layers[3]*block.expension, num_classes)self.relu = nn.ReLU(inplace=True)下面這段代碼定義了一個名為 ViT(Vision Transformer)的模型類,用于實現圖像分類任務,定義了 ViT 模型的基本參數,包括嵌入維度(embed_dim)、注意力頭數(n_head)、類別數量(num_classes)、層數(depth)、輸入通道數(in_chans)、輸入圖像尺寸(input_size)、圖像分塊大小(patch_size)、dropout 比率(drop_rate)等,作用是定義了一個 ViT 模型的結構,包括網絡的初始化和前向傳播過程。通過這個類,可以創建并使用 ViT 模型來進行圖像分類任務:
class ViT(nn.Module):def __init__(self, embed_dim=768, n_head=12, num_classes=9, depth=6,in_chans=3, input_size=224, patch_size=16, drop_rate=0.2,ffn_radio=4) -> None:super().__init__()self.encoder = nn.ModuleList([EncoderLayer(embed_dim=embed_dim, n_head=n_head, ffn_radio=ffn_radio, dropout=drop_rate) for _ in range(depth)])self.norm = nn.LayerNorm(embed_dim)self.cls = nn.Linear(embed_dim, num_classes)self.patch = PatchEmbedded(in_chans, input_size, patch_size, drop_rate)def forward(self, x):x = self.patch(x)for layer in self.encoder:x = layer(x)x = self.norm(x)x = self.cls(x[:,0])return x寫在最后
????????在深入探討雙深度學習模型在結直腸癌檢測中的創新應用后,我們不禁為這一領域的飛速發展而贊嘆。雙深度學習模型以其獨特的優勢,不僅提高了診斷的準確性和效率,更為結直腸癌的早期發現和治療開辟了新的道路,回顧我們的研究,雙深度學習模型通過結合不同神經網絡架構的優勢,實現了對復雜醫學圖像數據的深度解析。這種模型能夠捕捉到細微的圖像特征,從而更準確地識別出結直腸癌的病變區域。同時,通過大量的數據訓練和優化,模型逐漸學會了從海量信息中篩選出關鍵信息,為醫生提供了更為可靠的診斷依據。
????????我們期待雙深度學習模型能夠在更多方面發揮其獨特優勢,為人類的健康事業貢獻更多力量。同時,我們也呼吁更多的科研工作者和醫學專家加入到這一領域中來,共同推動雙深度學習模型的研究與應用取得更大的突破。讓我們攜手并進,為人類的健康事業譜寫新的篇章!
詳細復現過程的項目源碼、數據和預訓練好的模型可從該文章下方附件獲取。
【傳知科技】關注有禮???? 公眾號、抖音號、視頻號


值得一看)


:DISTINCT)

)
—— memmove()函數 (內含memmove的講解和模擬實現))











