大家好,從我開始分享到現在,收到很多朋友的反饋說配置很低玩不了AI。本篇是一個云端部署AI項目的指南,幫助大家在云端進行AI項目的部署。我會從云平臺的選擇、代碼部署、保存鏡像幾個方面進行詳細的介紹。沒有代碼基礎的小白也不用擔心,我已經制作好了鏡像,你們可以一鍵部署就可以在云端使用啦。
視頻教程:
【FaceFusion云端部署指南(保姆級)】 https://www.bilibili.com/video/BV1es421g77P/?share_source=copy_web&vd_source=09316244e4ff3a9793930d67cf748288
選擇云平臺
國內外有許多GPU算力平臺提供服務,例如國內的阿里云、騰訊云、百度飛槳、AutoDL、仙宮云,以及國外的kaggle Kernel、Google Colaboratory、亞馬遜AWS等。
盡管這些平臺的部署流程大體相似,但具體細節各有不同。
在準備本期內容時,我嘗試了AutoDL和仙宮云這兩個GPU平臺來部署AI項目。最終選擇使用仙宮云部署。
在過去的項目中,我也使用過阿里云、Google Colaboratory和亞馬遜AWS的服務來部署AI項目。
?
有兩種方法:
第一種是使用我已經制作好的鏡像包,直接使用。(適合小白、想快速使用的朋友)
第二種是自行部署。(適合有代碼基礎,想嘗試的朋友)
使用鏡像包
第一種方法,使用我已經制作完成的云端鏡像包。
登錄注冊仙宮云
官網
直接找到我公開的鏡像鏈接,點擊部署。一鍵鏡像
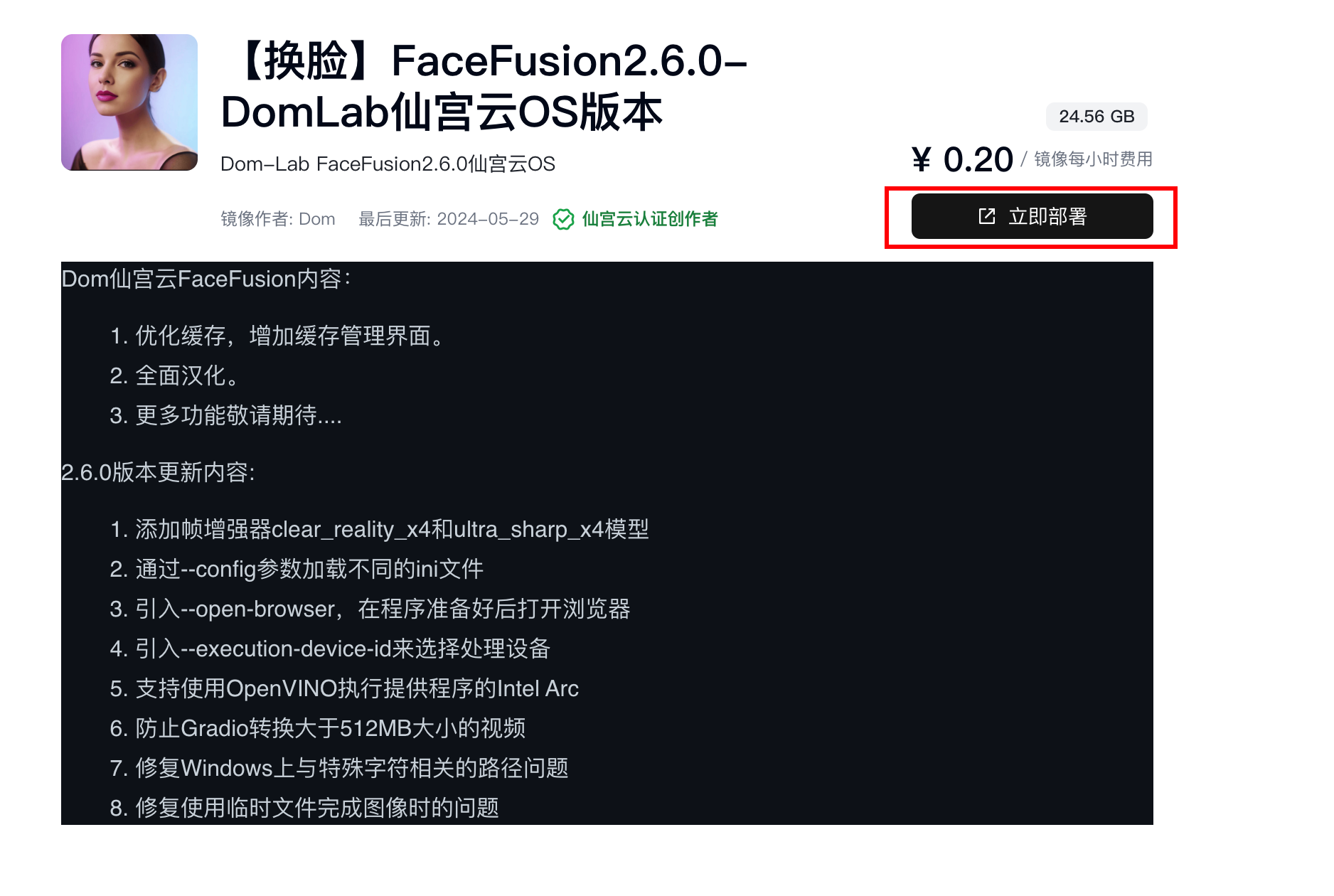
選擇4090這個配置。
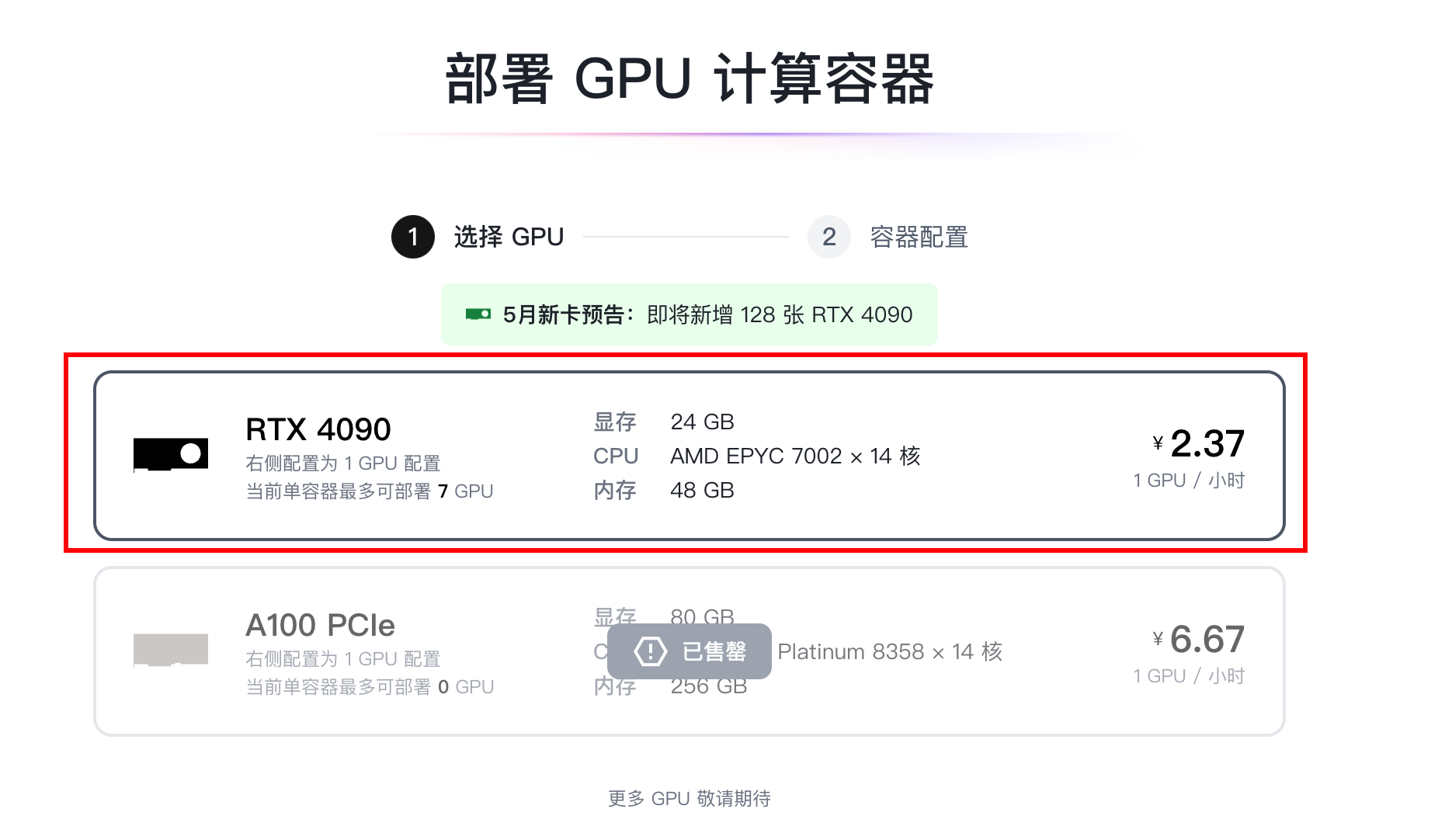
確認鏡像,點擊確認部署。
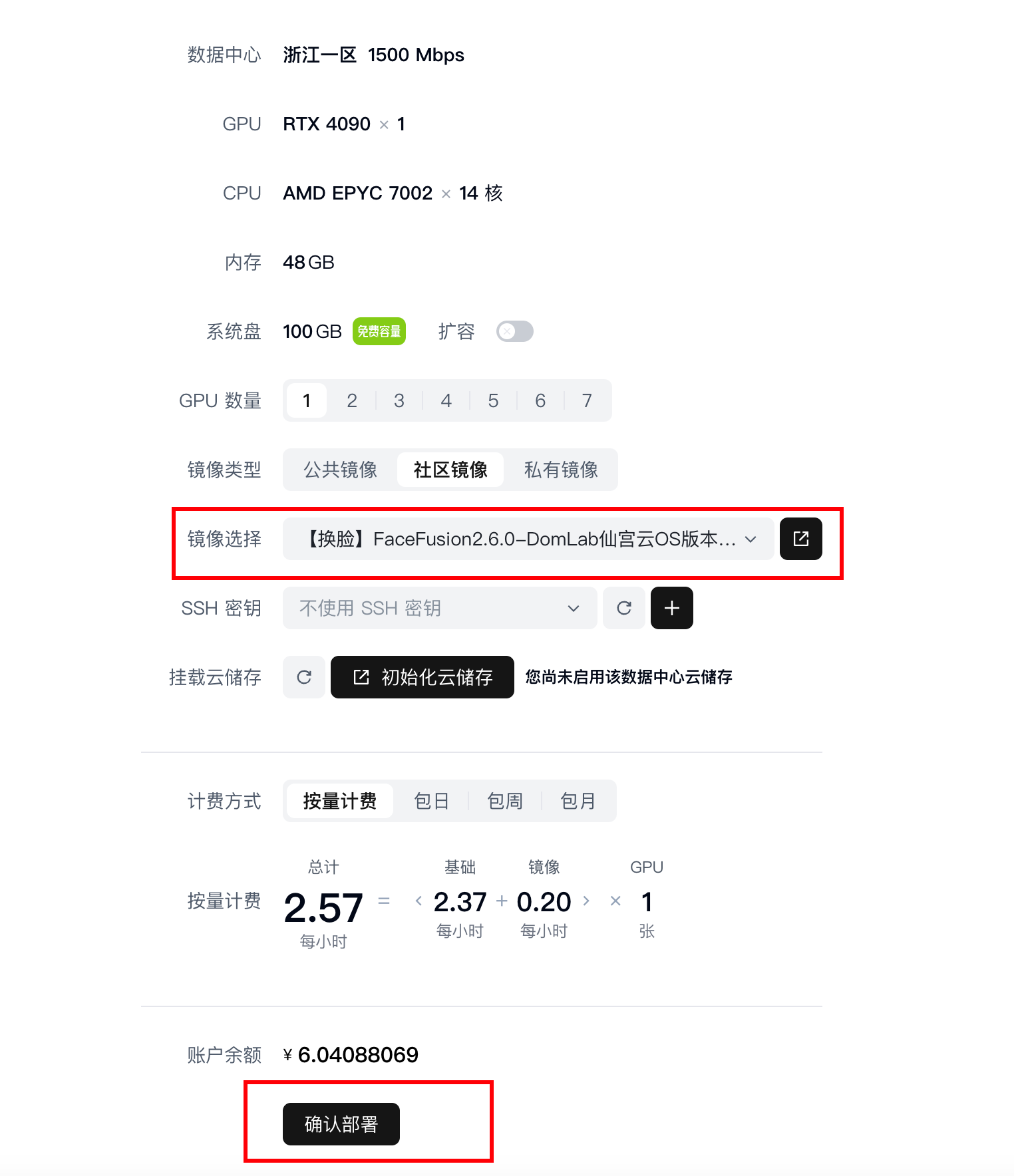
可以看到正在部署。耐心等待

部署完畢,點擊仙宮云OS

進入主界面,默認FaceFusion服務已經啟動好了。

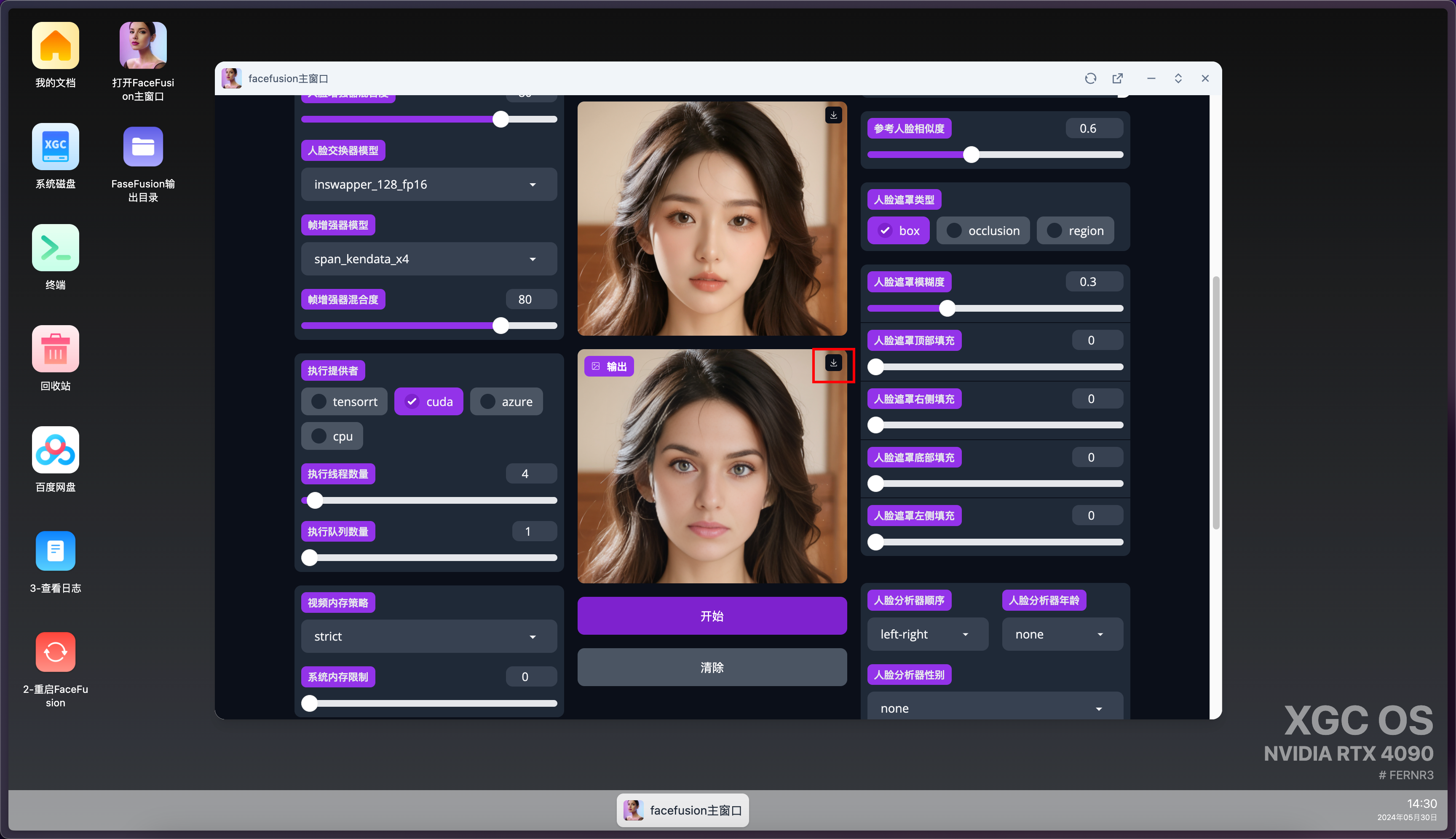
直接雙擊桌面上的這個文件,打開FaceFusion的主窗口。
FaceFusion主窗口
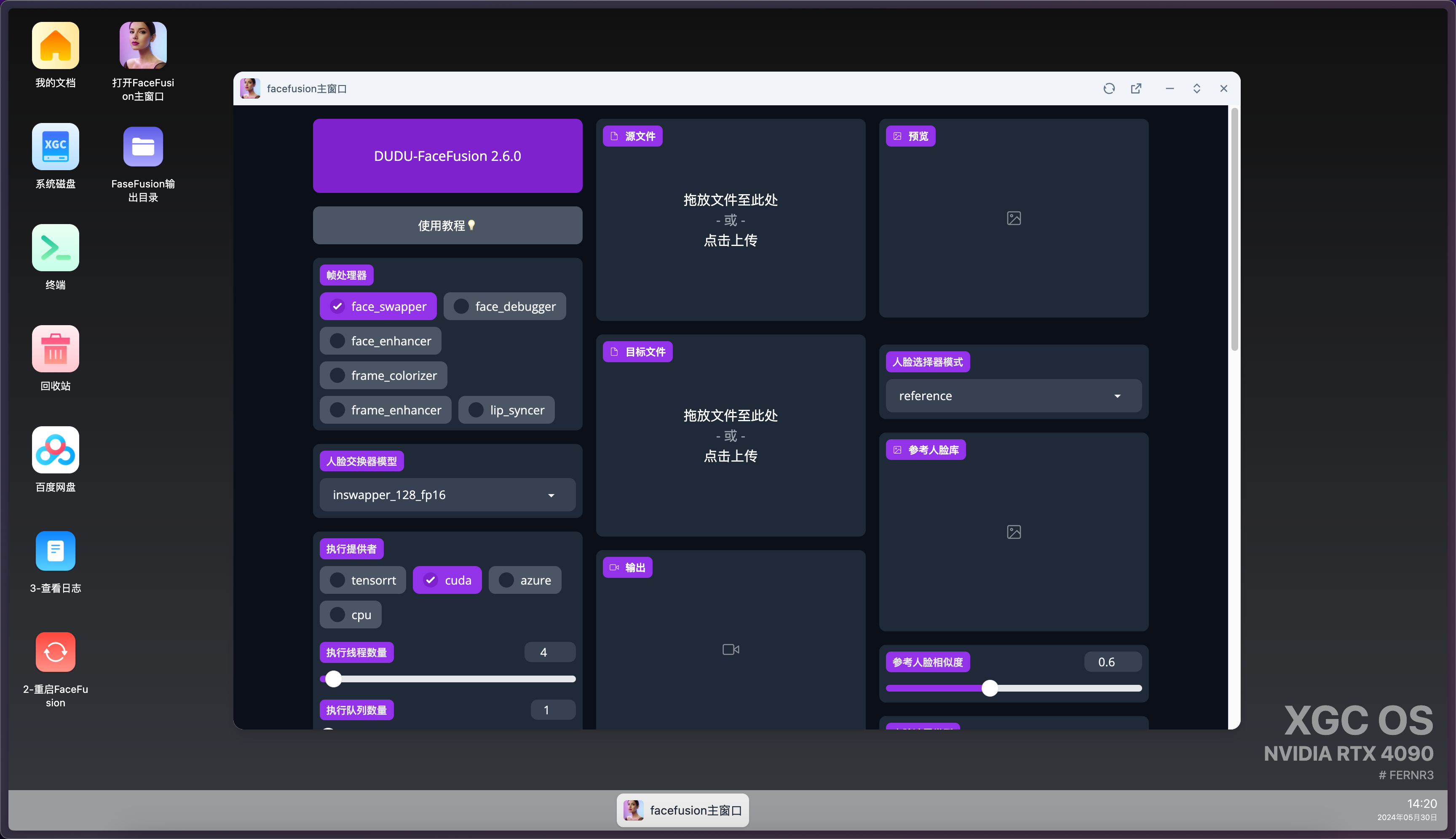
這是打開FaceFusion的界面,關掉該界面后,程序還會執行。
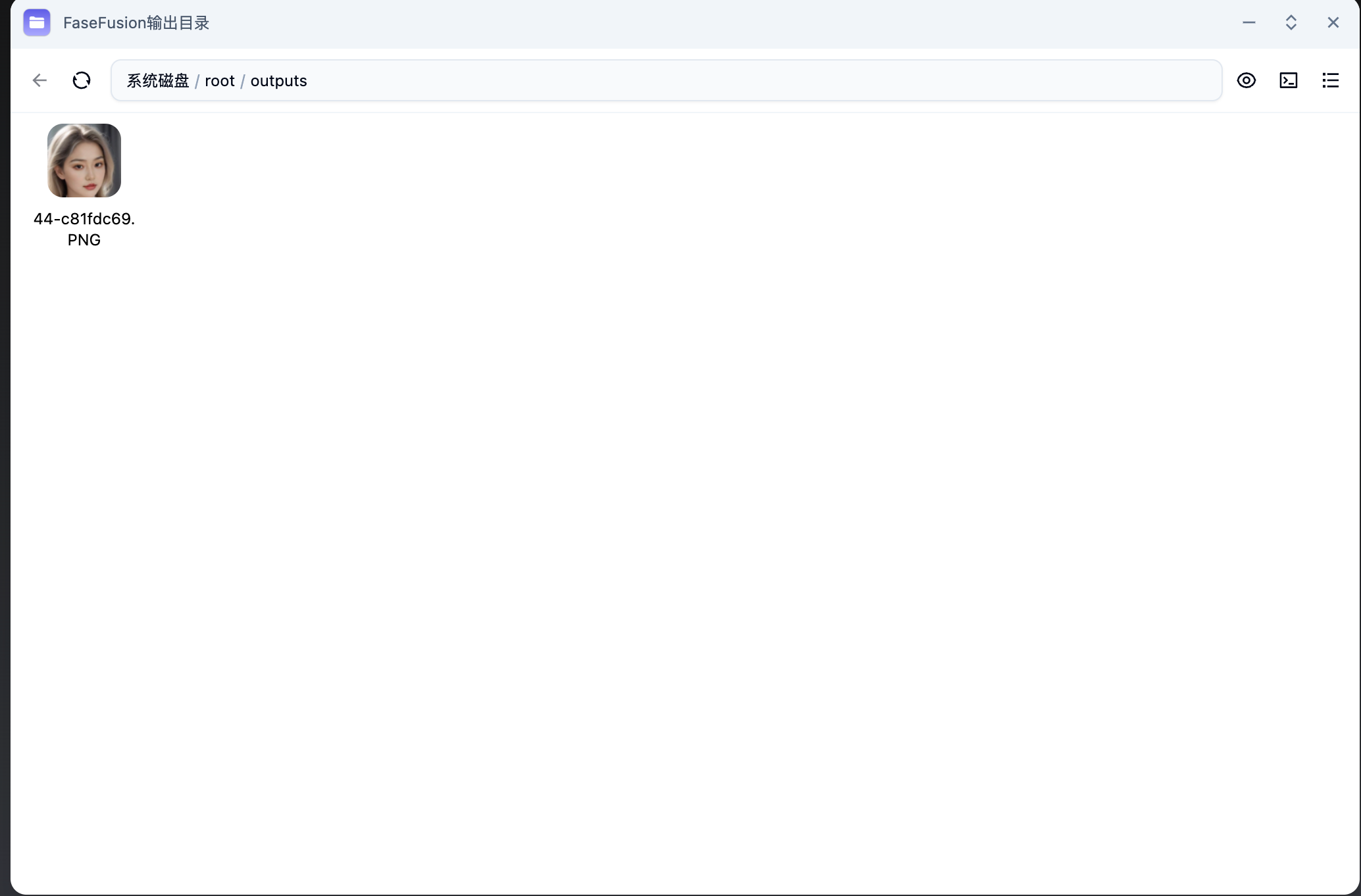
輸出目錄

雙擊打開FaceFusion的輸出目錄
日志

點擊桌面上的日志查看執行時的信息。
重啟

雙擊重啟FaceFusion程序,當你清除緩存后記得重啟下FaceFusion才能執行。
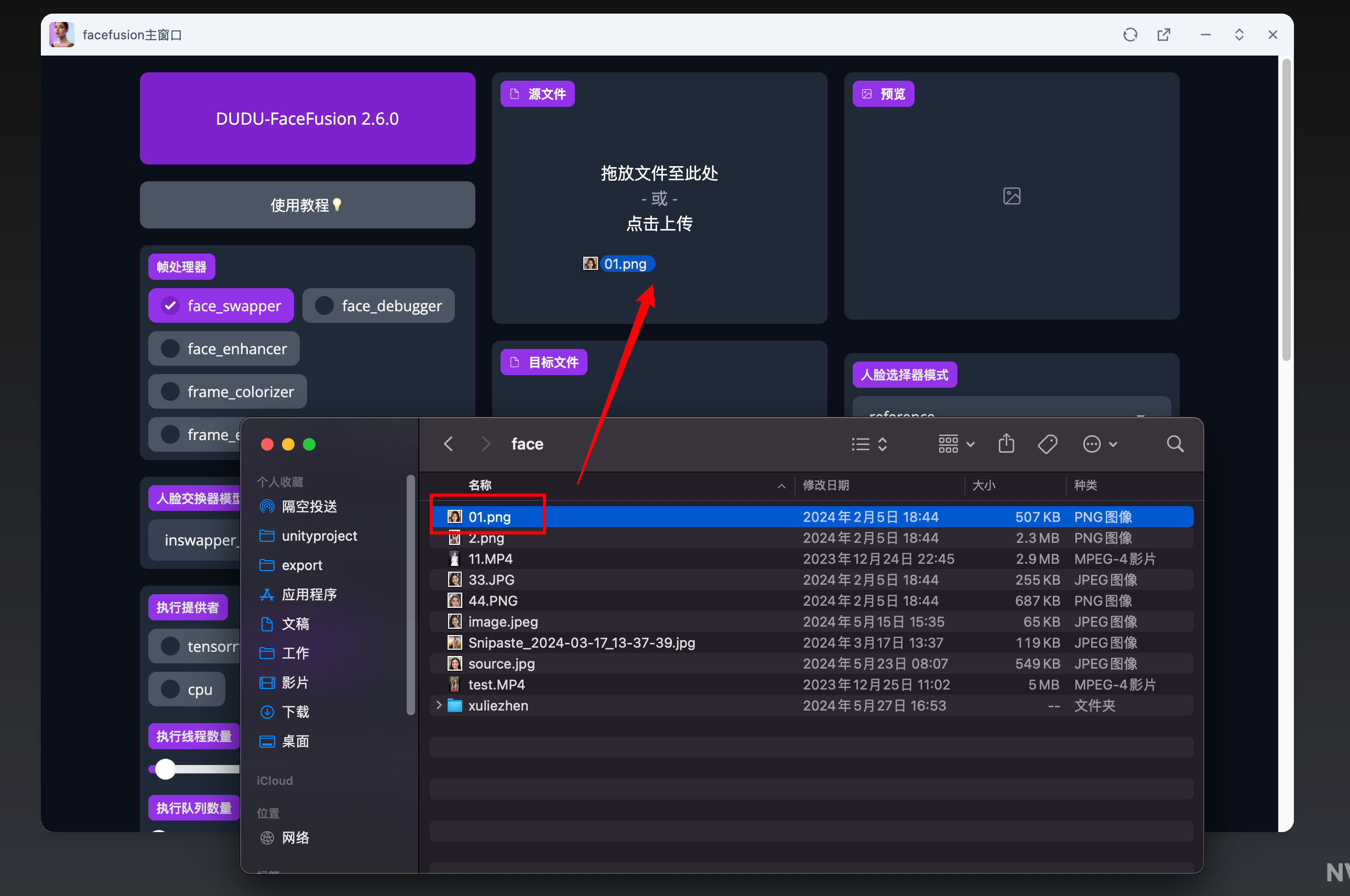
上傳圖片/視頻
關于上傳,你可以將本地的圖片或者視頻直接拖拽到該界面上,非常方便。
下載
生成好的視頻/圖片點擊下載按鈕下載到本地。
自行部署鏡像
官網
首先進入仙宮云的官網,點擊部署GPU計算容器
這里選擇你想要部署的機器配置。
配置服務
這里需要對GPU服務器進行一些配置。
系統盤:GPU服務器儲存空間大小。默認100G,這里對于我們部署的AI項目已經夠用。可擴容,會更貴些。
GPU數量:服務器的顯卡數量,默認一個顯卡,最高可選3張4090進行渲染,速度會更快。關于多卡渲染這里我不過多描述,感興趣的話我后面可以出一篇教程。
鏡像類型:
這里有三種鏡像。
公共鏡像:仙宮云官方提供的鏡像。
社區鏡像:其他用戶制作并上傳 的鏡像。
私有鏡像:自己制作的鏡像。
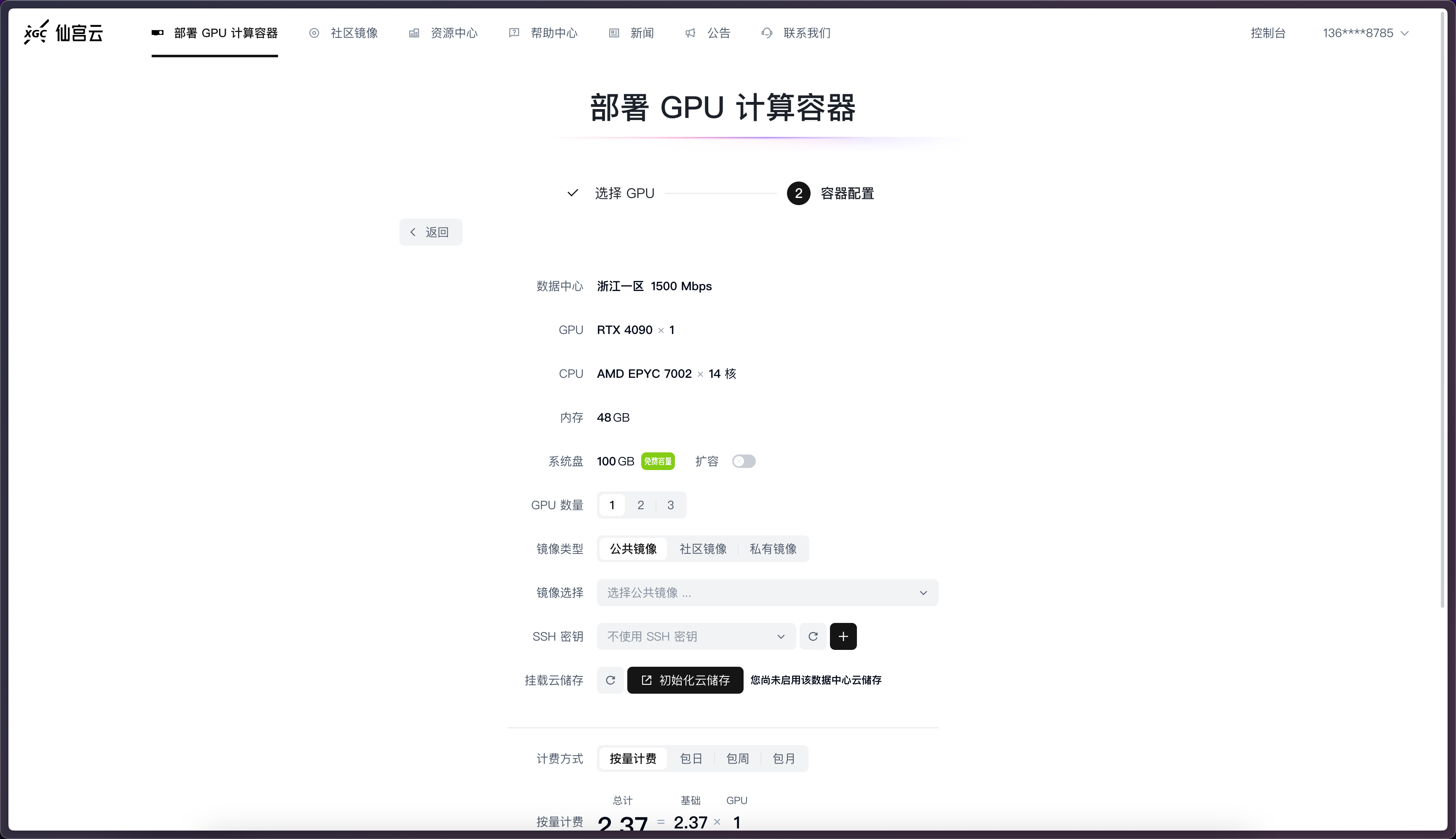
由于我們是從零開始部署,所以選擇公共鏡像。
基礎鏡像選擇Miniconda3,python版本選擇3.10,CUDA版本選擇11.8
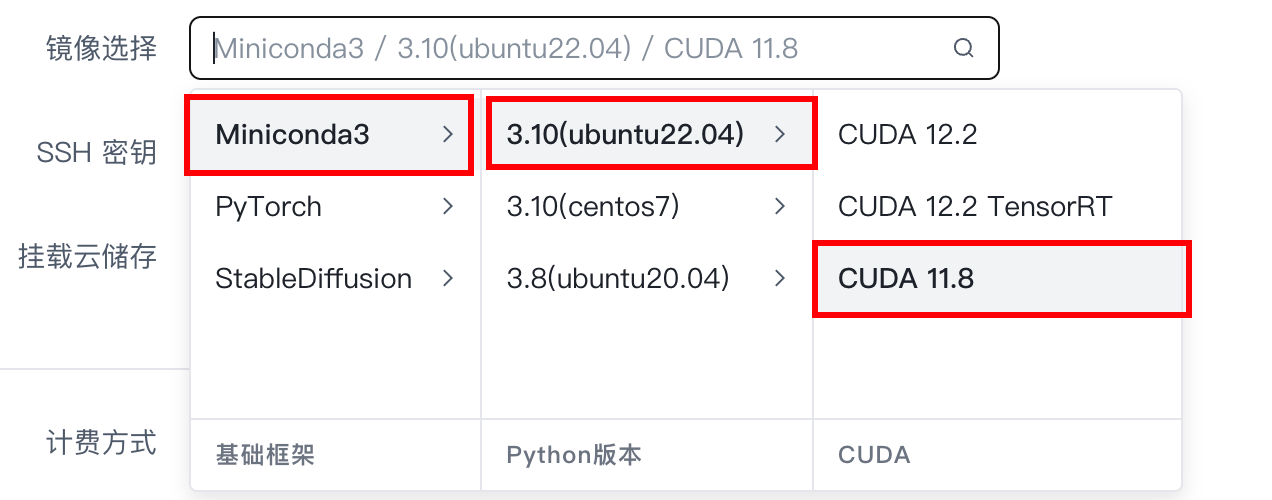
剩下的SSH密鑰和掛載云儲存我們這里用不到,保持默認即可。
計費方式根據自己的需求來。

以上都設置完畢后,點擊確認部署

拉取源碼
來到控制臺可以看到服務正在創建
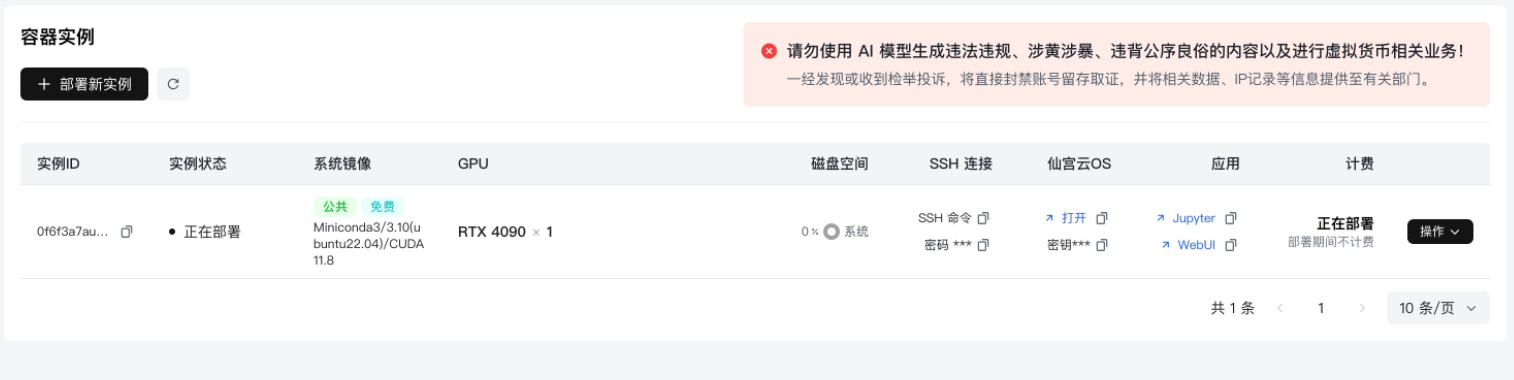
等待實例創建完畢后

點擊應用這一欄的Jupyter
點擊后會跳轉到Jupyter的操作面板,我們在這里進行部署
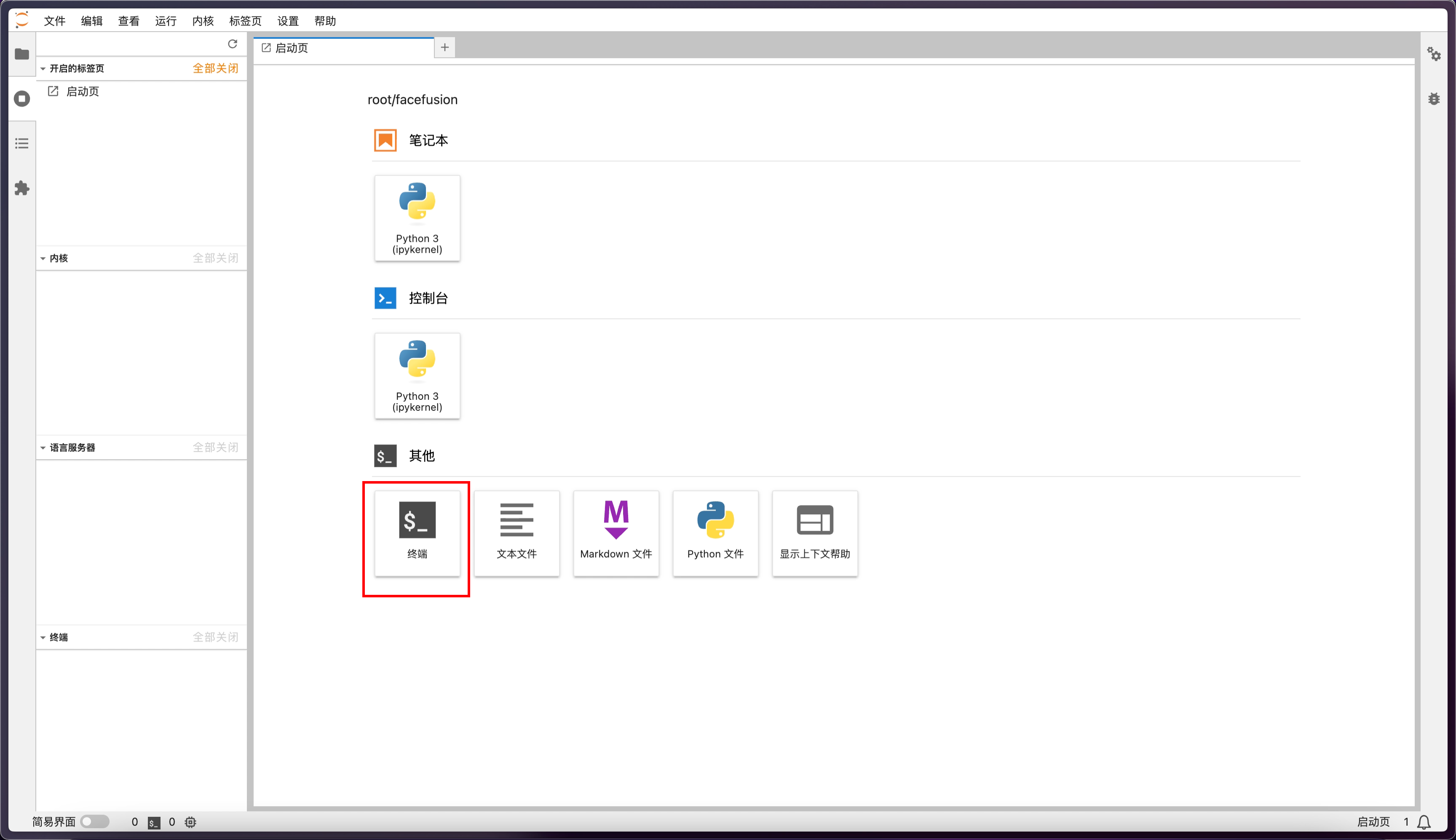
啟動頁中選擇終端
進入到終端命令行中
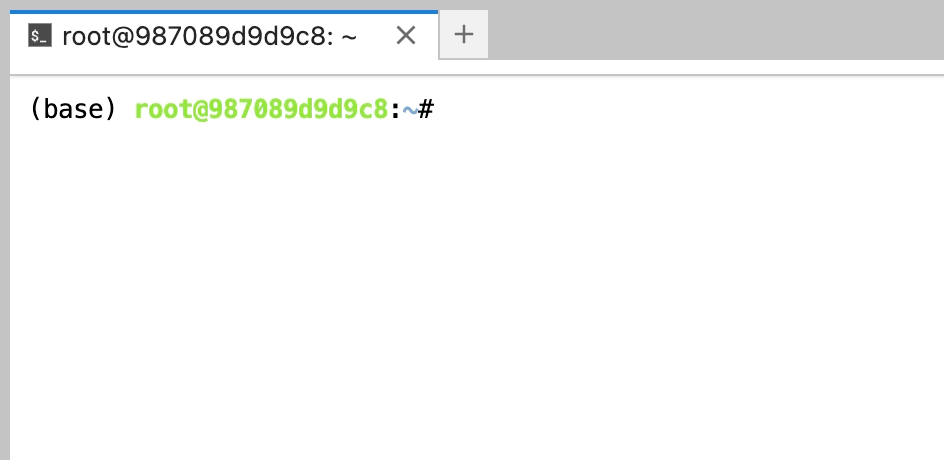
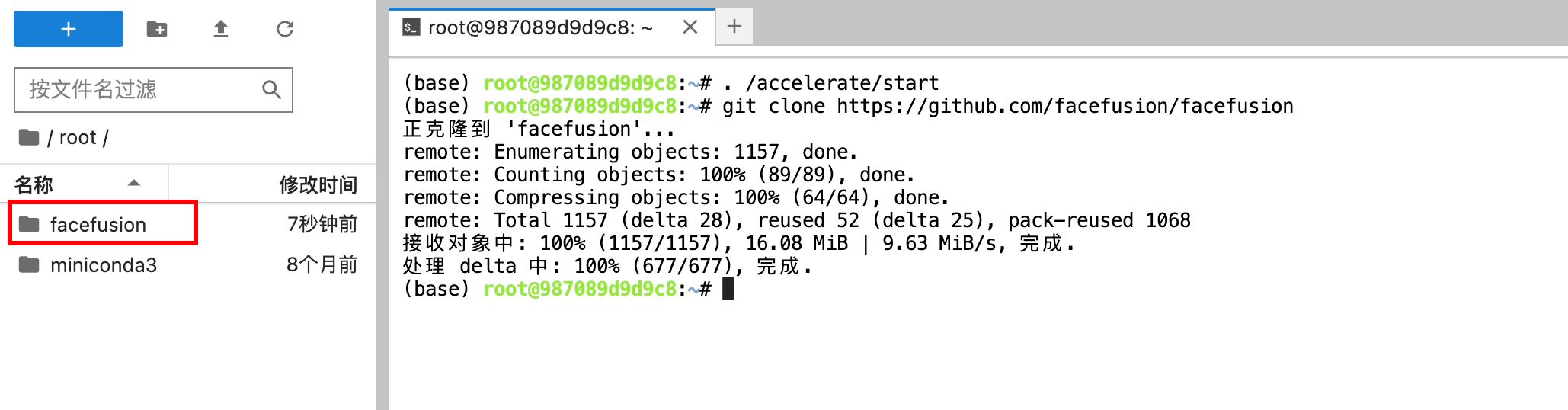
第一步需要拉取FaceFusion在Github上的源代碼。由于你懂的的網絡原因,需要為當前終端開啟學術加速。
開啟學術加速
. /accelerate/start
接下來從Git上拉取代碼
git clone https://github.com/facefusion/facefusion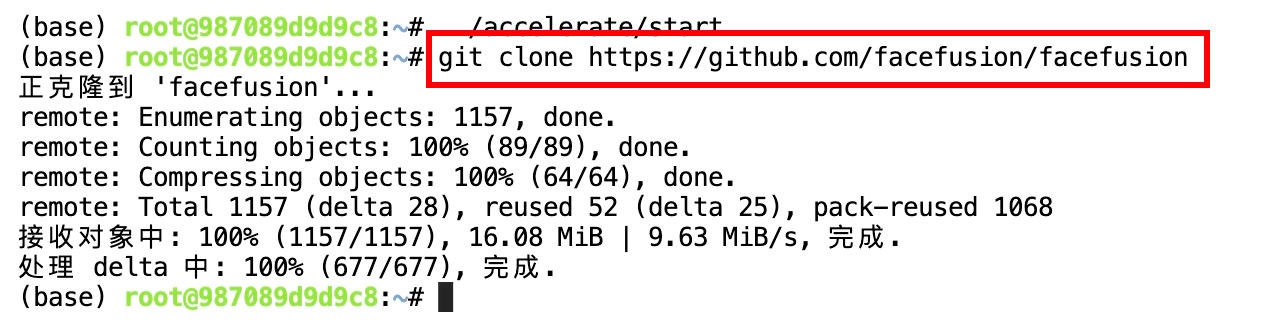
拉取完我們可以在左側看到FaceFusion的文件夾
創建虛擬環境
輸入cd facefusion進入這個目錄
cd facefusion
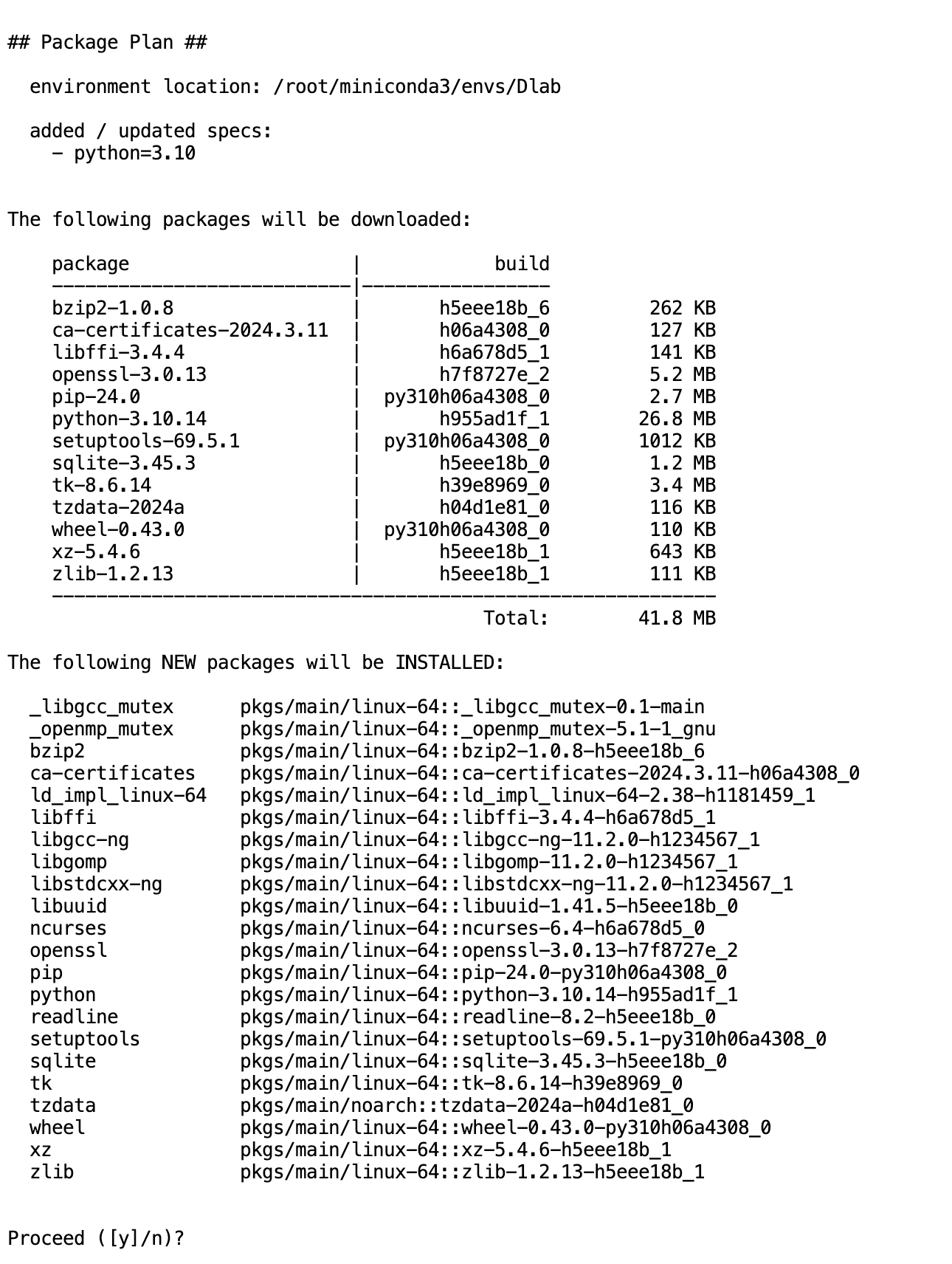
使用conda創建python虛擬環境
conda create --name Dlab python=3.10會彈出確認選項
輸入y按回車
創建完畢,一個基礎的虛擬環境就創建好了。

激活剛才創建的虛擬環境。
conda activate Dlab激活后可以看到之前的base變為了Dlab

安裝依賴
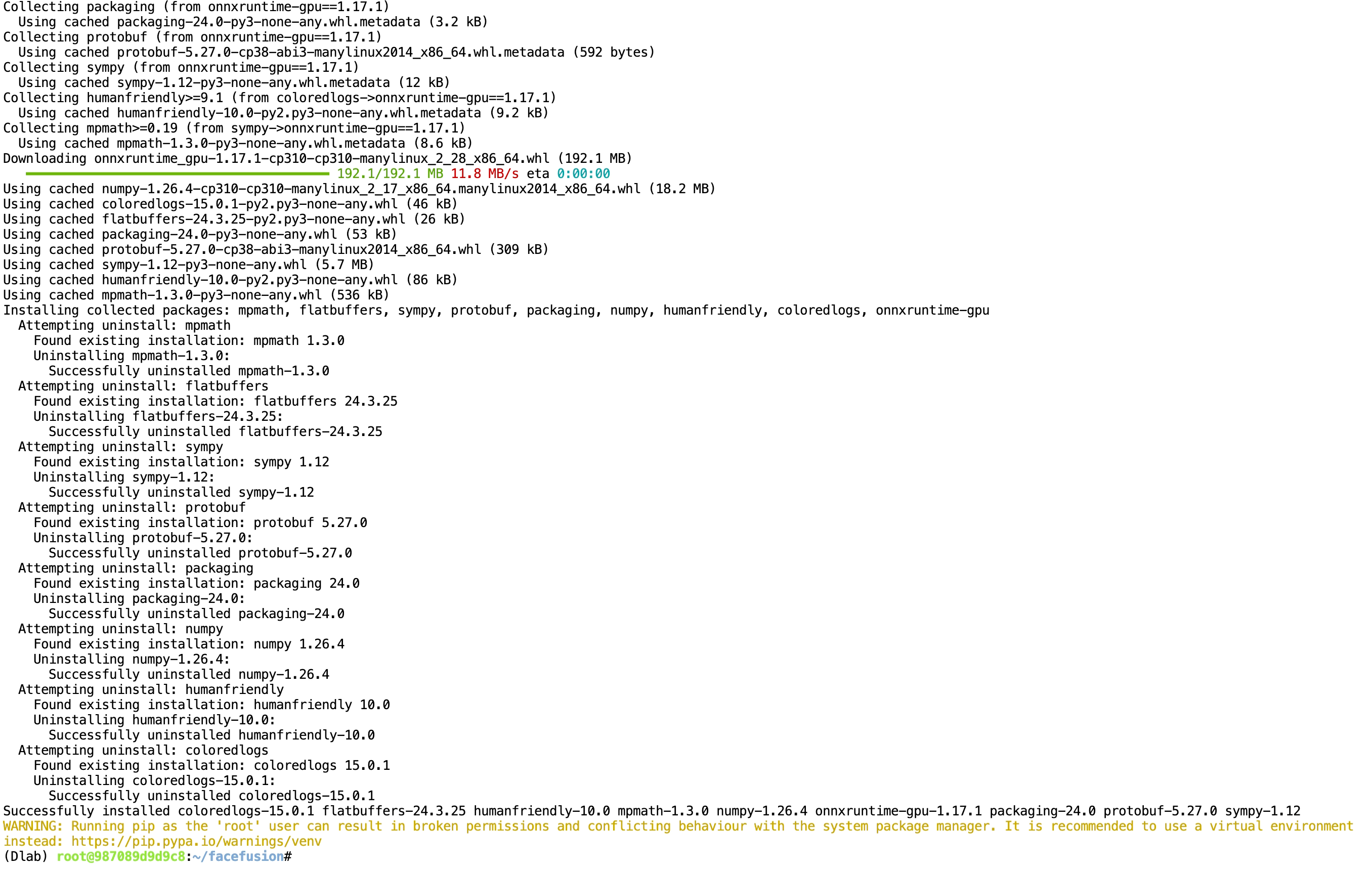
運行install.py腳本
python install.py這里會出現選項框,選擇要安裝的onnxruntime版本

我們剛才創建服務時選擇的是cuda版本是11.8,所以這里也選擇對應的版本。鍵盤方向鍵上下進行選擇,按回車確認。

耐心等待會兒
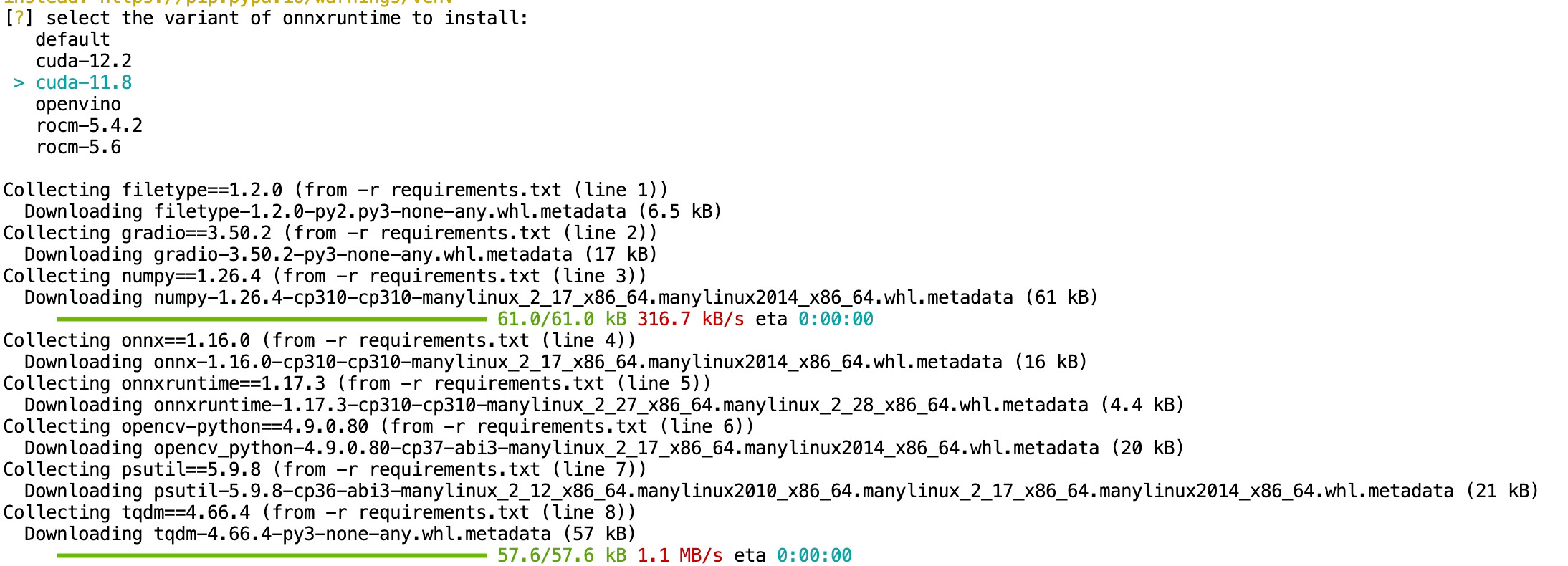
安裝完畢
問題解決
libgl1問題
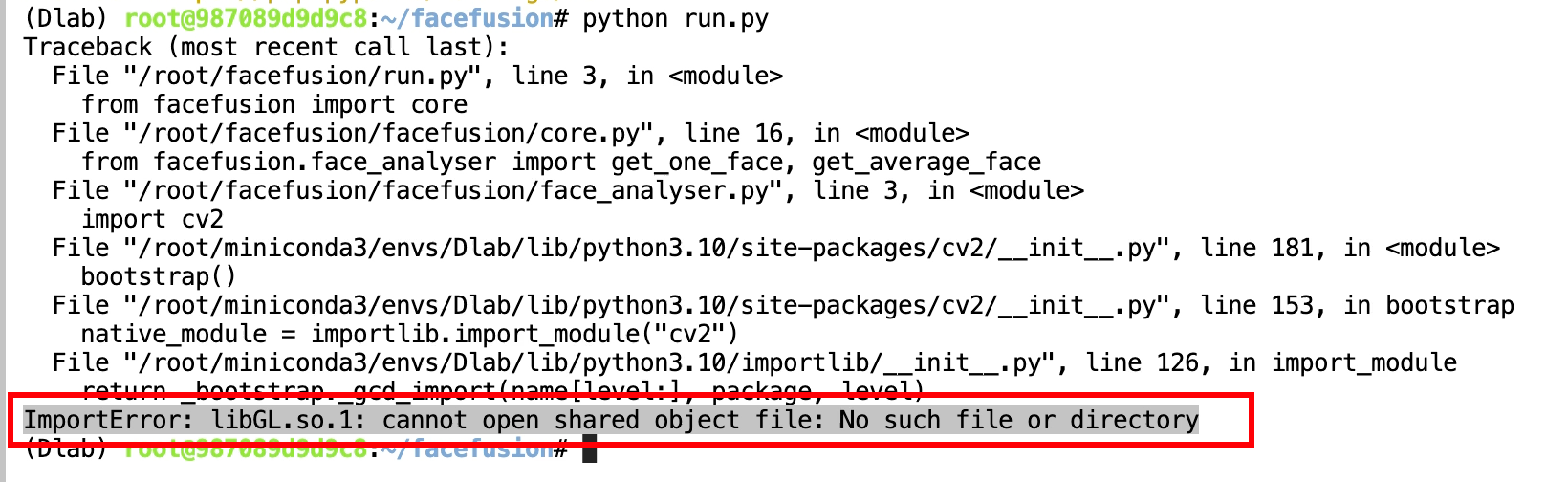
接下來運行看下
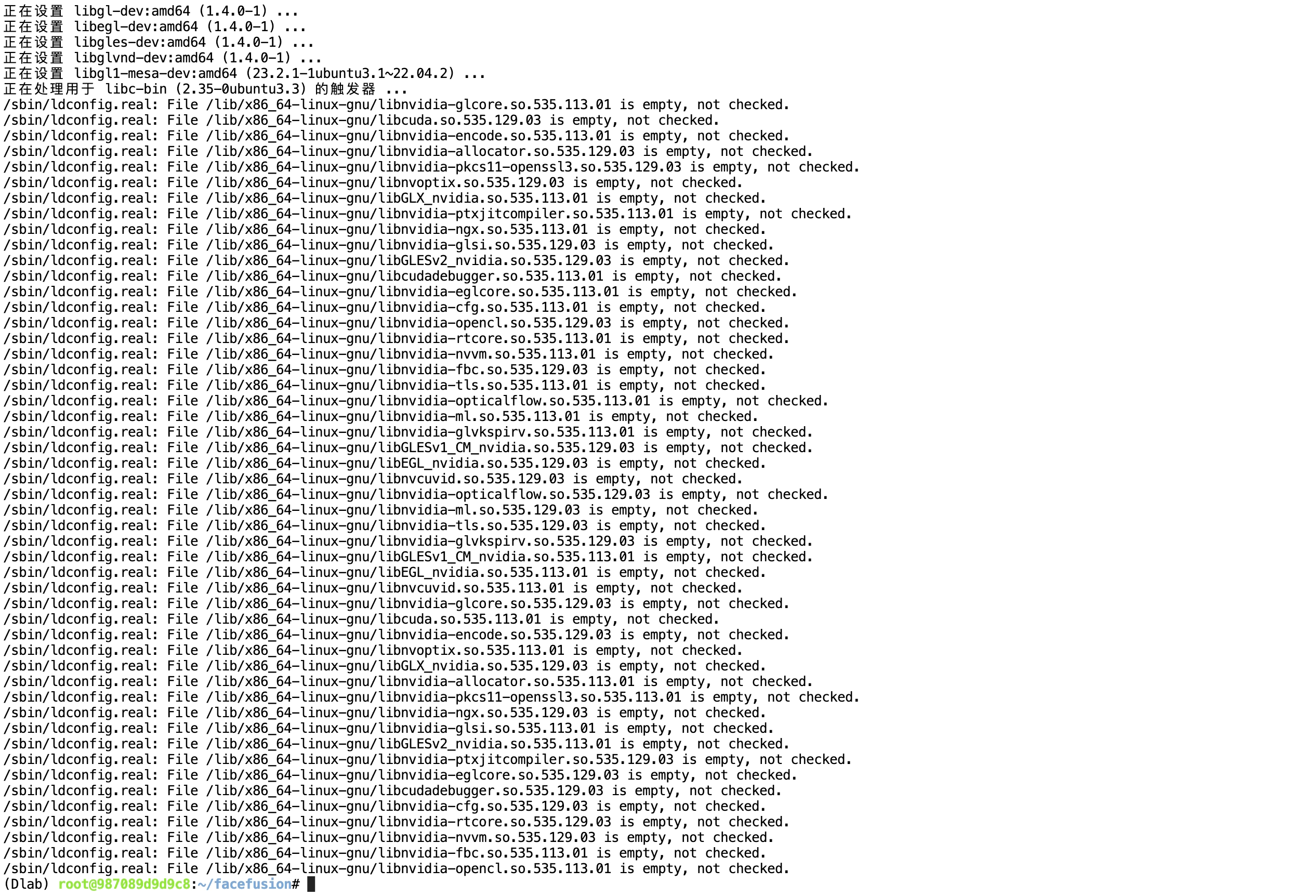
python run.py出現libGL.so.1錯誤,這是因為我們的鏡像中默認是不包含libgl1這個庫的。
解決方法,手動安裝,接著輸入
apt-get install libgl1-mesa-dev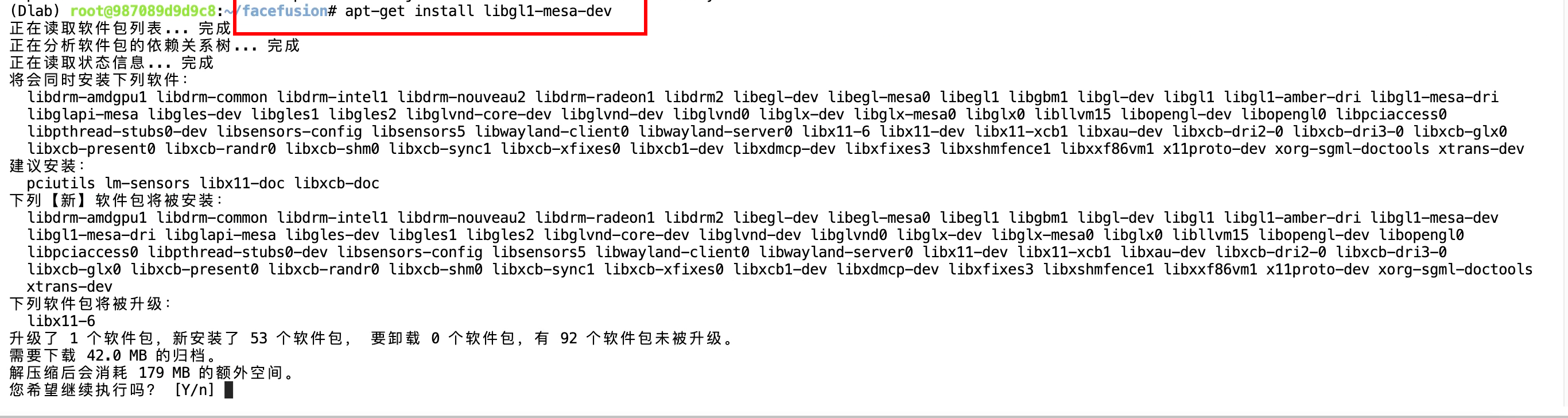
輸入y后按回車繼續執行

等待....
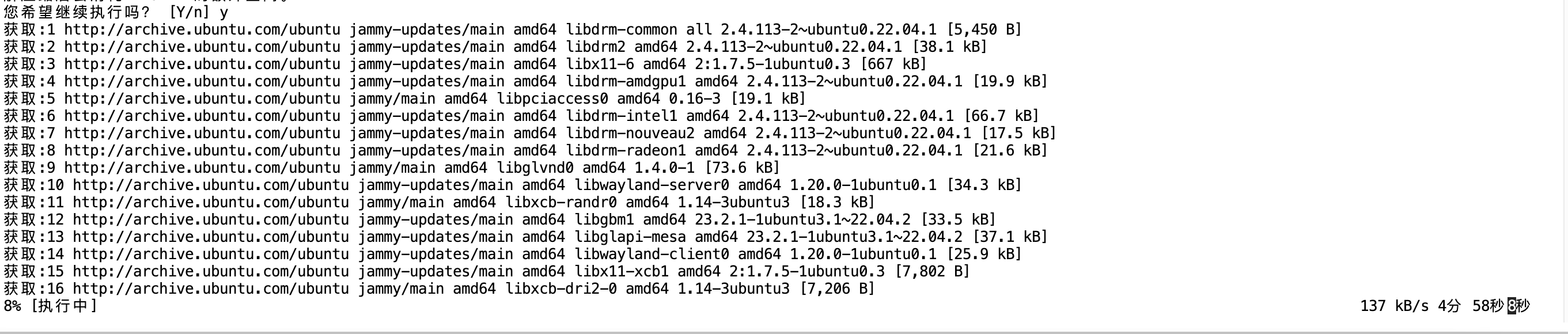
安裝完畢
FFmpeg問題
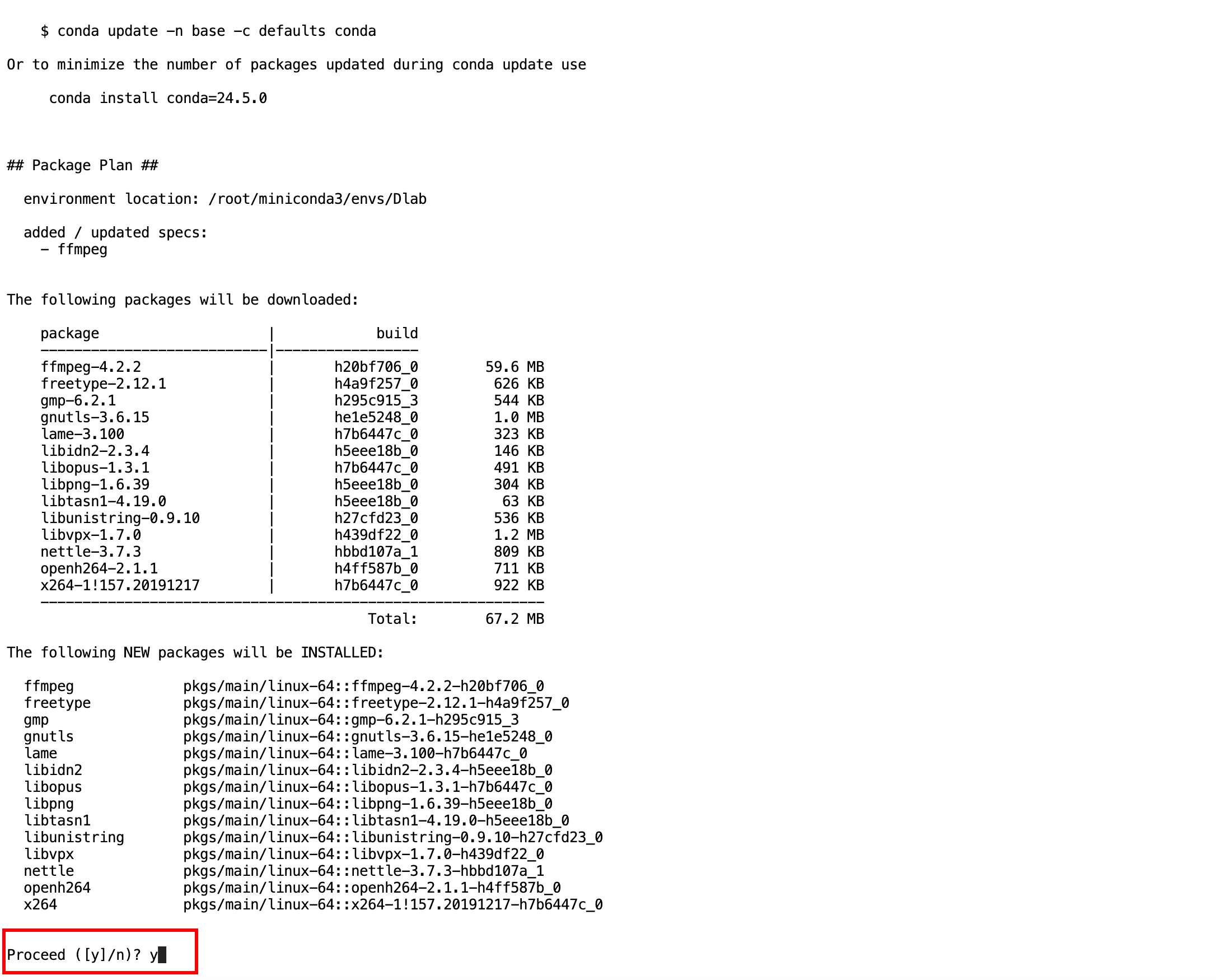
再次輸入運行命令,發現還有個報錯,這個原因是FFMpeg庫未安裝。
python run.py
直接在conda內安裝
conda install ffmpeg
輸入y后按回車
安裝完畢
成功運行
再再再再次輸入運行命令
python run.py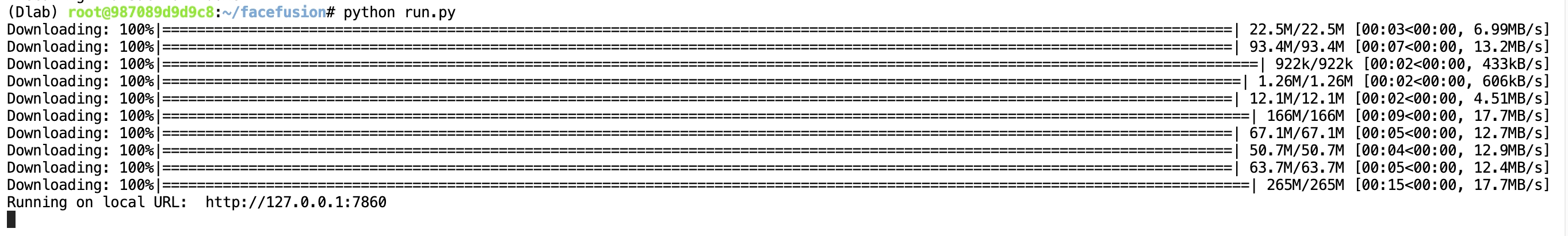
成功執行!
現在我們直接訪問這個網址是打不開的,因為這是一個本地鏈接,我們需要訪問仙宮云上映射的網址。

來到容器管理頁面,點擊WebUI
會跳轉到一個錯誤的網頁,顯示無法進入,不要慌,這是正常現象,因為我們的服務啟動的端口不一樣,仙宮云默認是80端口。
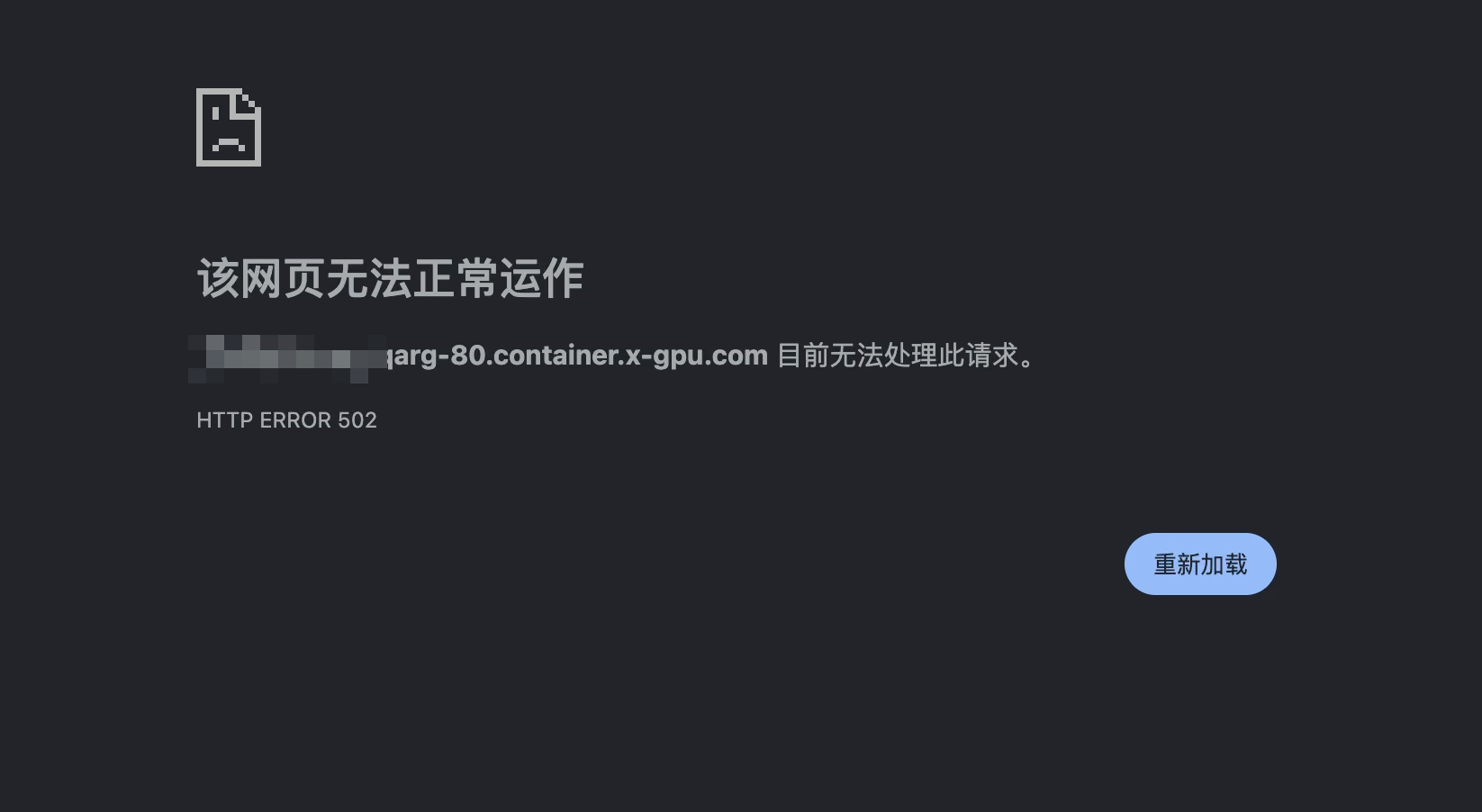
在瀏覽器中找到當前打開的網頁鏈接。

把這個80改為7860,再次訪問。

訪問成功
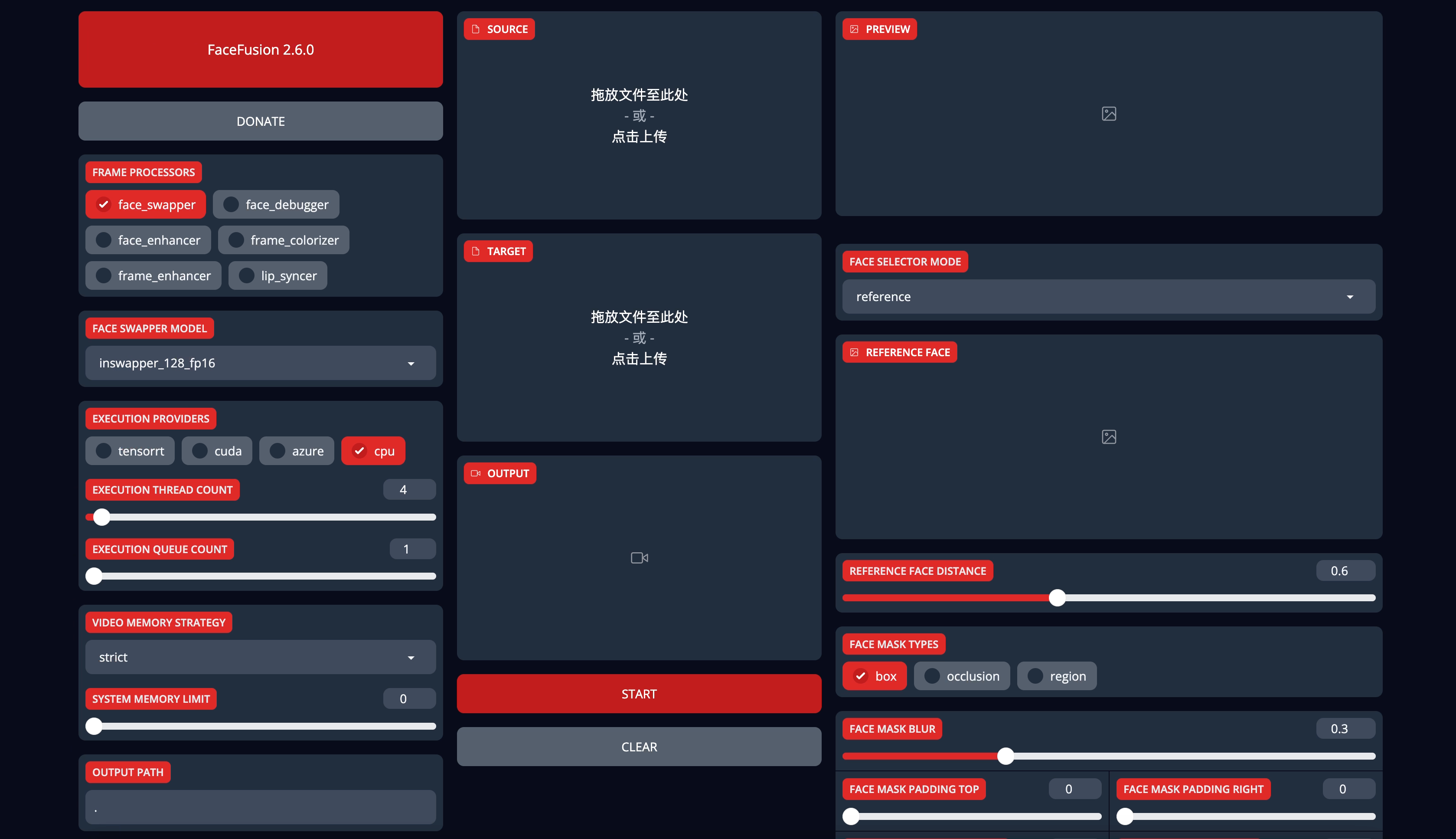
用圖片進行了測試,可以換臉。
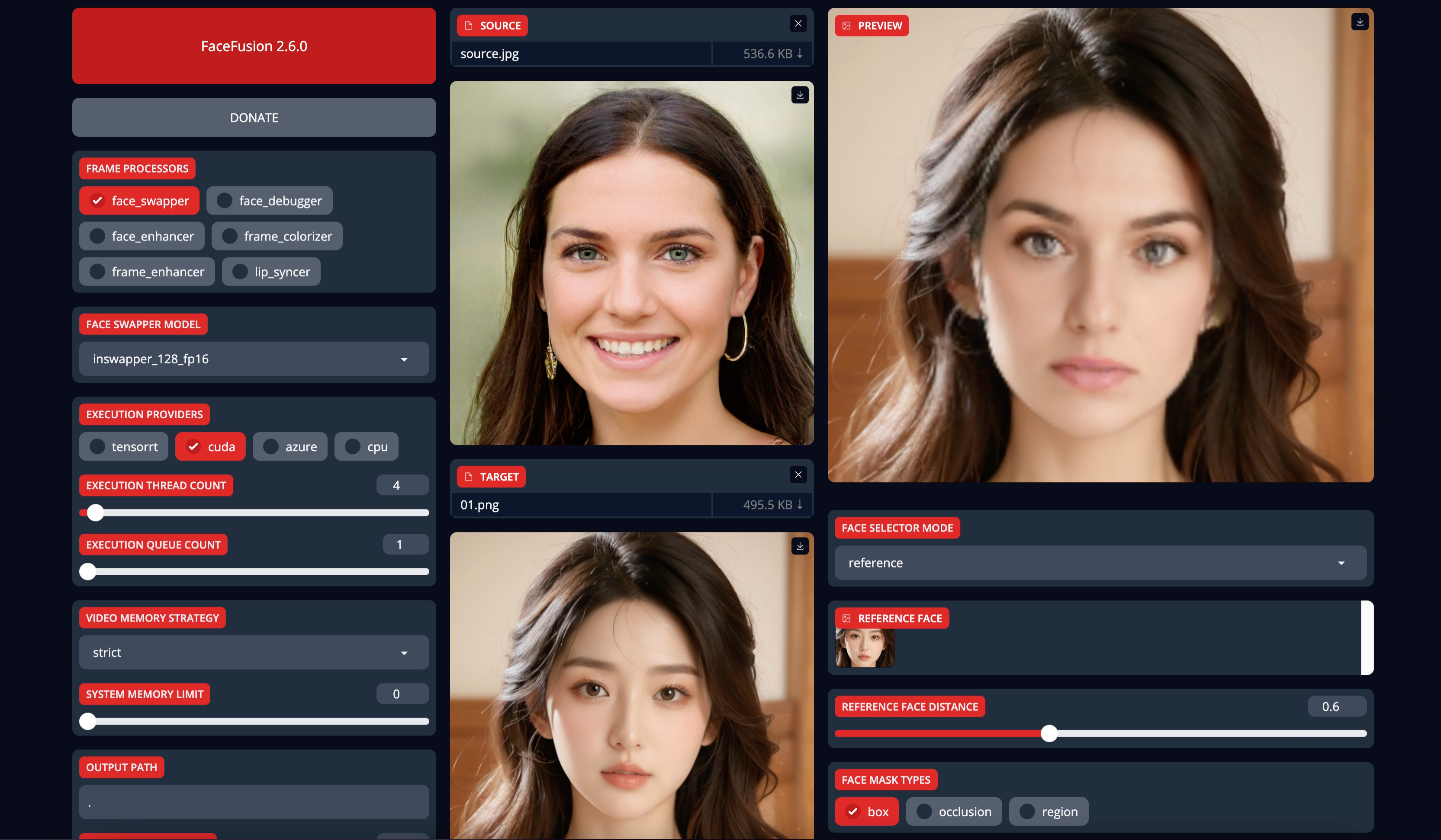
上傳模型
恭喜你!到這里已經成功了一大半了!接下來需要將FaceFusion所需要的所有模型都下載下來。
FaceFusion官方提供的腳本中即使是開了學術加速,下載模型的速度也不如人意。為了節約寶貴的時間,這里我們使用網盤的方式進行下載。(我已經將所有資料都放入網盤鏈接內)
來到仙宮云容器實例這里,選擇仙宮云OS,點擊打開。

可以看到我們進入了類似電腦桌面的界面。

進入桌面的百度網盤

這里需要授權下。
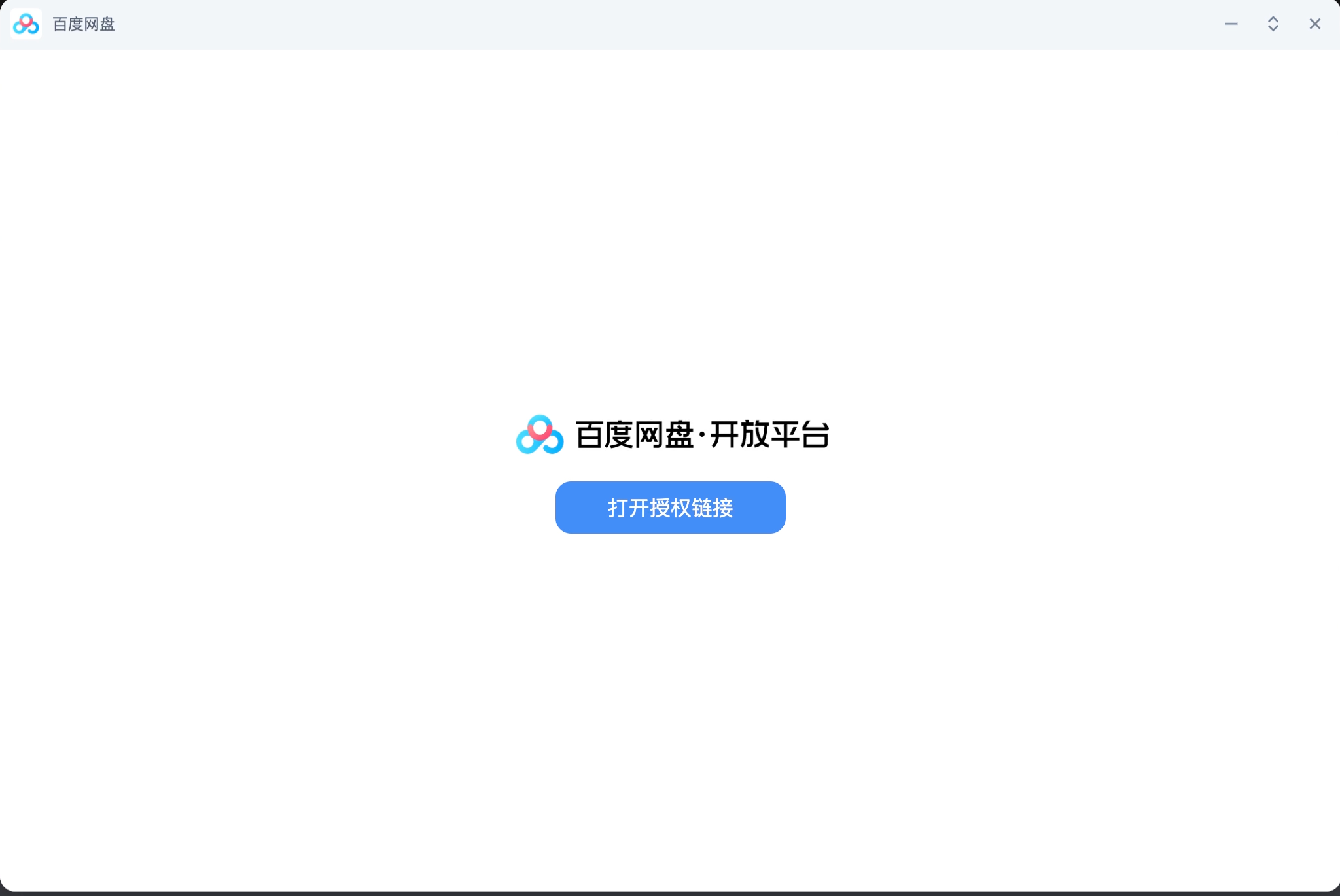
授權成功后找到我們網盤內存儲的壓縮包
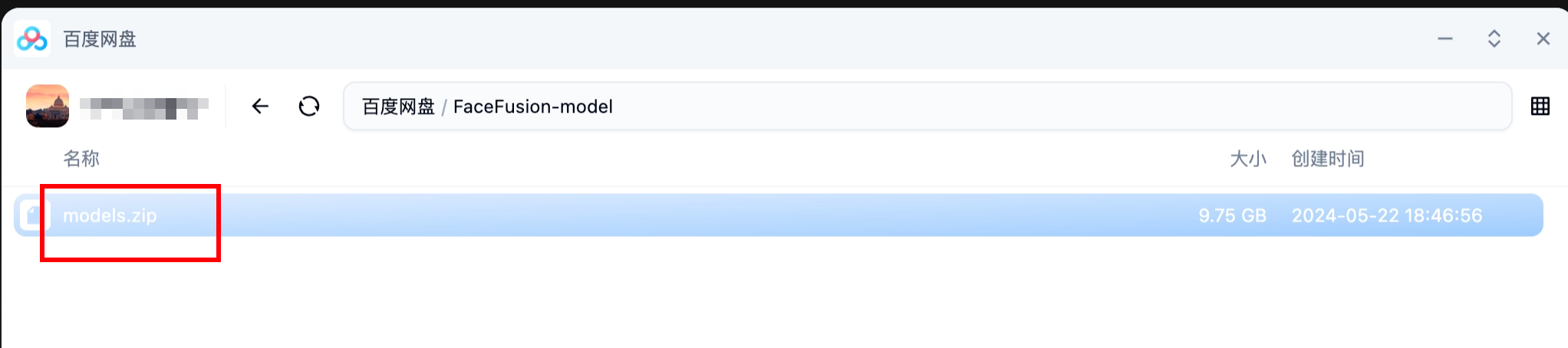
右鍵復制

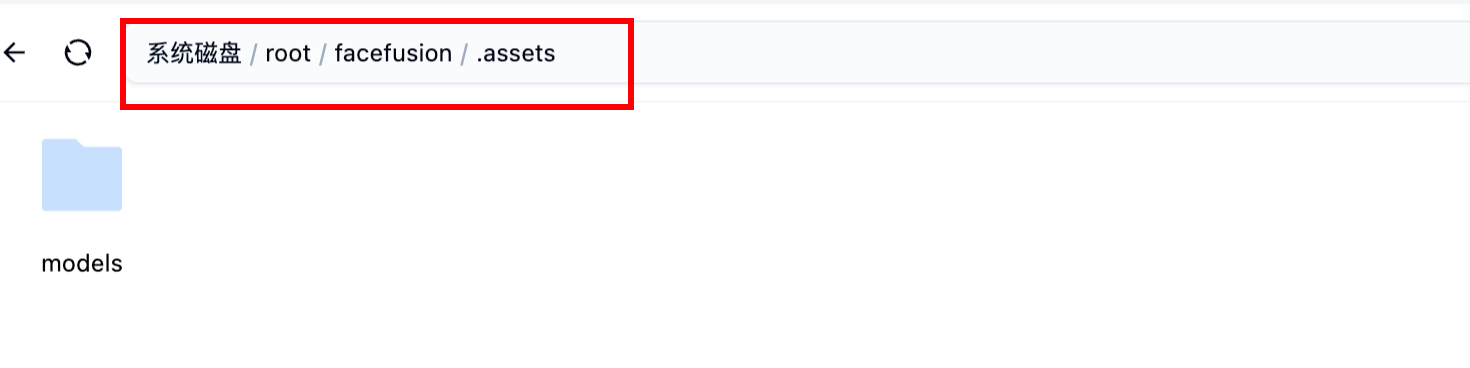
打開系統磁盤,進入系統磁盤/root/facefusion/.assets這個目錄

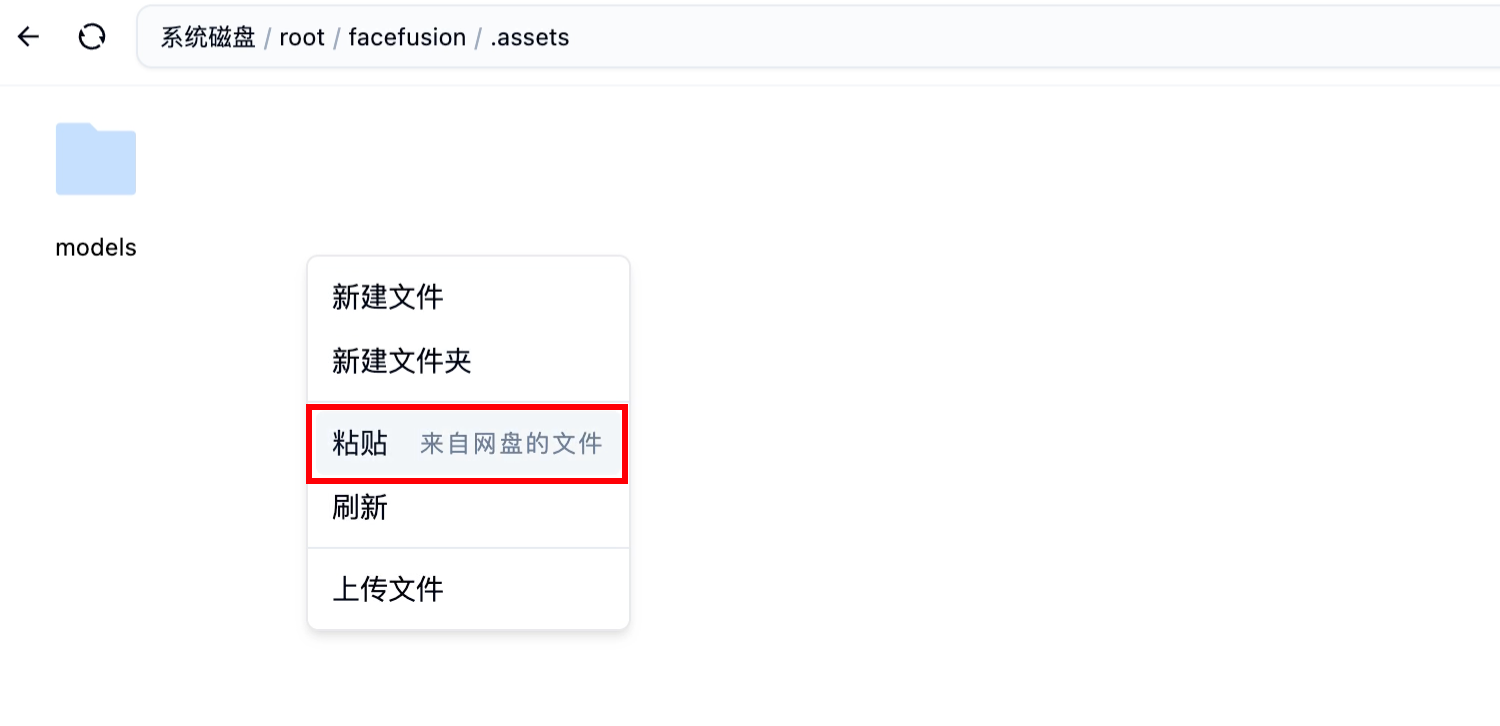
粘貼網盤文件
右下角是進度條,耐心等待
完畢后文件夾內如下
將models文件夾右鍵--移至回收站(這個models文件夾是剛才我們部署好后下載的基礎換臉模型,從網盤下載的壓縮包內已經包含這些基礎模型,所以將這個文件夾刪除)

雙擊models.zip進行解壓

等待解壓

解壓完畢
新解壓的models文件夾里包含了所有的模型
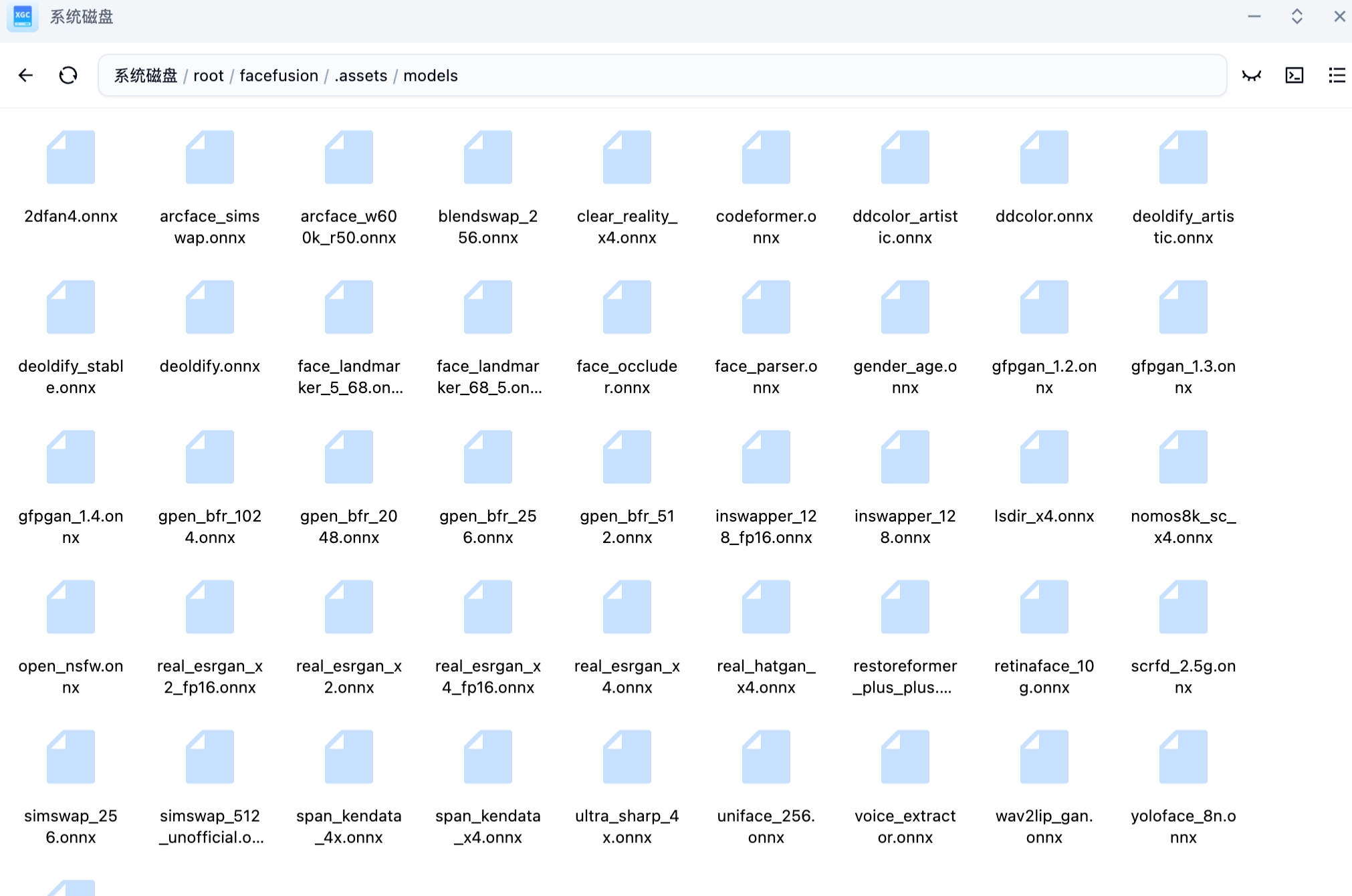
最后你可以把models.zip壓縮包刪除了,因為這會占用你的空間,后面會說到。

重啟服務
由于我們現在FaceFusion已經啟動,我們模型上傳后需要重新啟動下FaceFusion。
回到Jupyter頁面
點擊這個圖標進入管理頁面。
可以看到當前運行的終端。
點擊全部關閉。
然后我們重新打開終端頁面
重新激活conda環境
conda activate Dlab
然后運行run腳本,這里與之前不一樣的是,我加了--skip-download(跳過下載)參數。因為我們模型都已經安裝完畢,不需要再走一遍下載。
python run.py --skip-download
啟動完畢后還是進入剛才的7860網頁查看,成功運行。
完美運行
再次測試,這次多勾選了高清修復、臉部修復。(如果你沒有執行上面的模型安裝步驟,是不能開啟臉部修復和高清修復的,會提示沒找到模型)
可以看到預覽里的效果完美。
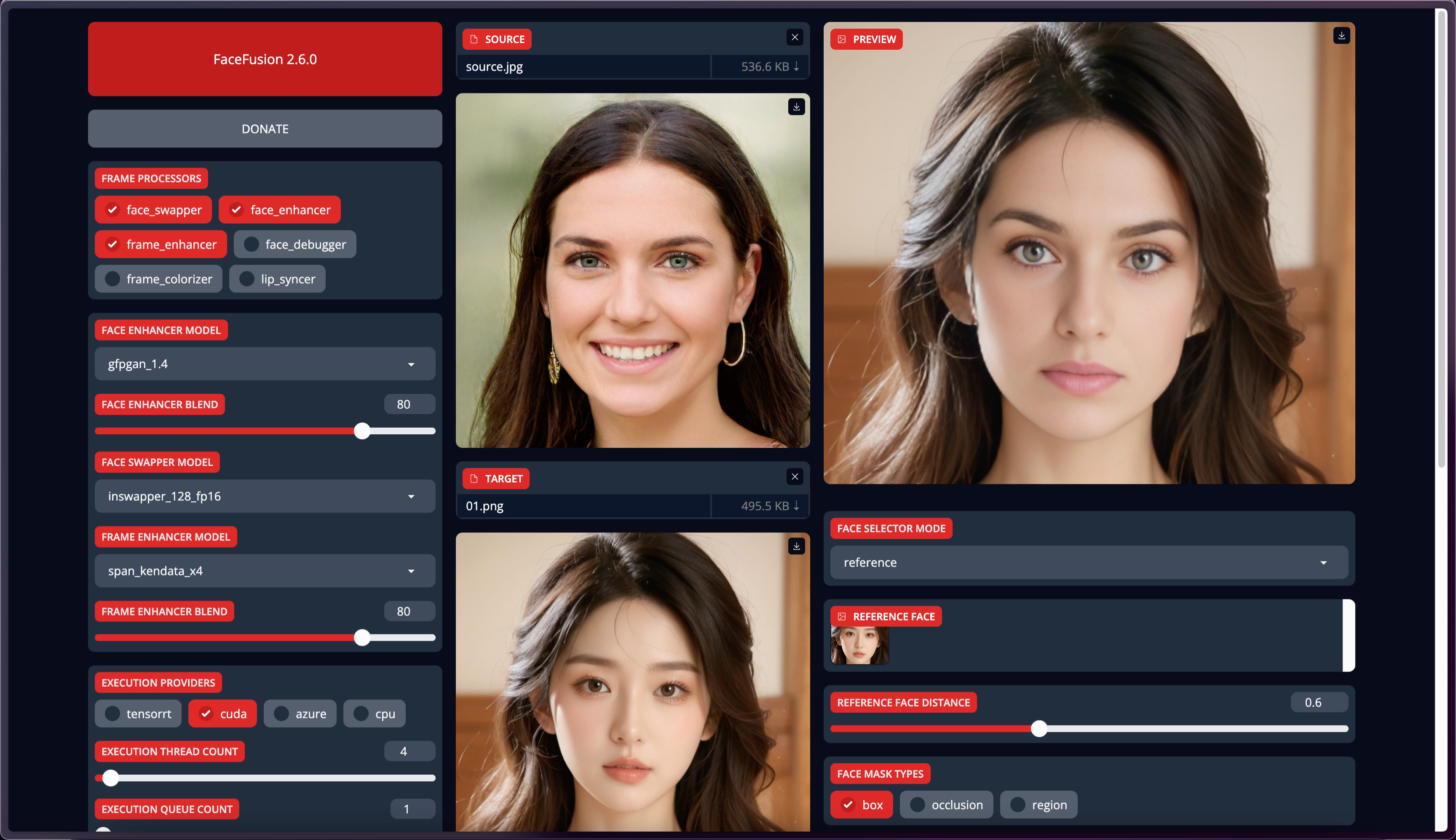
其他的操作方法跟本地版本的是一樣的。如果你想對這個FaceFusion進行更多修改,請往下看。
其他修改
修改中文界面
進入系統磁盤/root/facefusion中
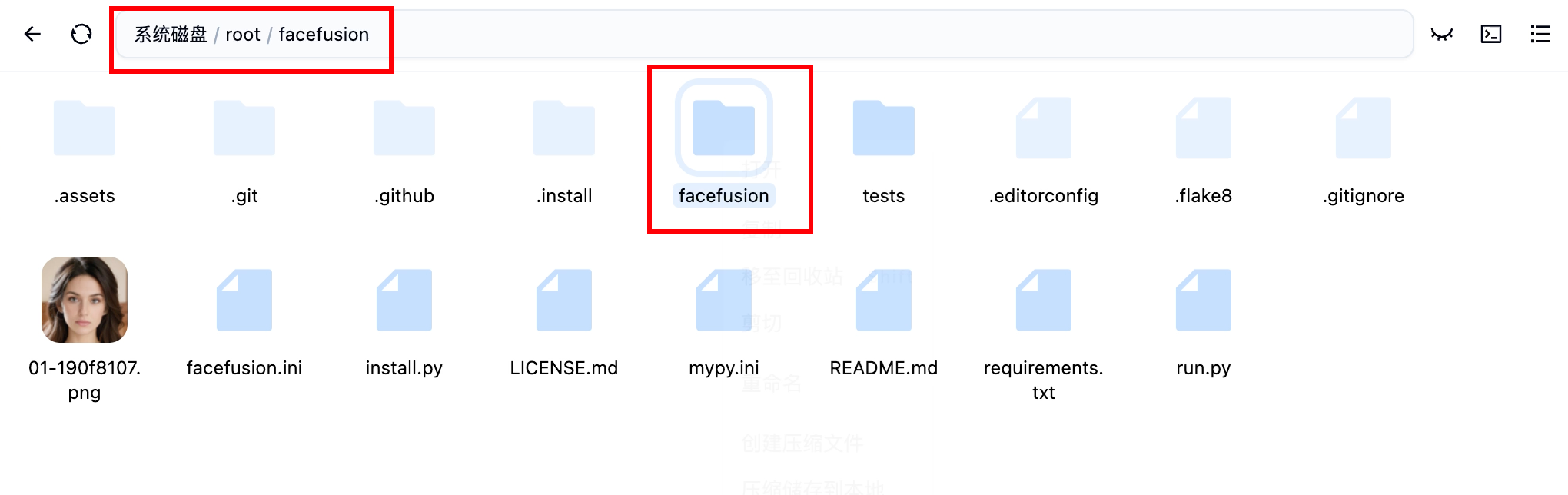
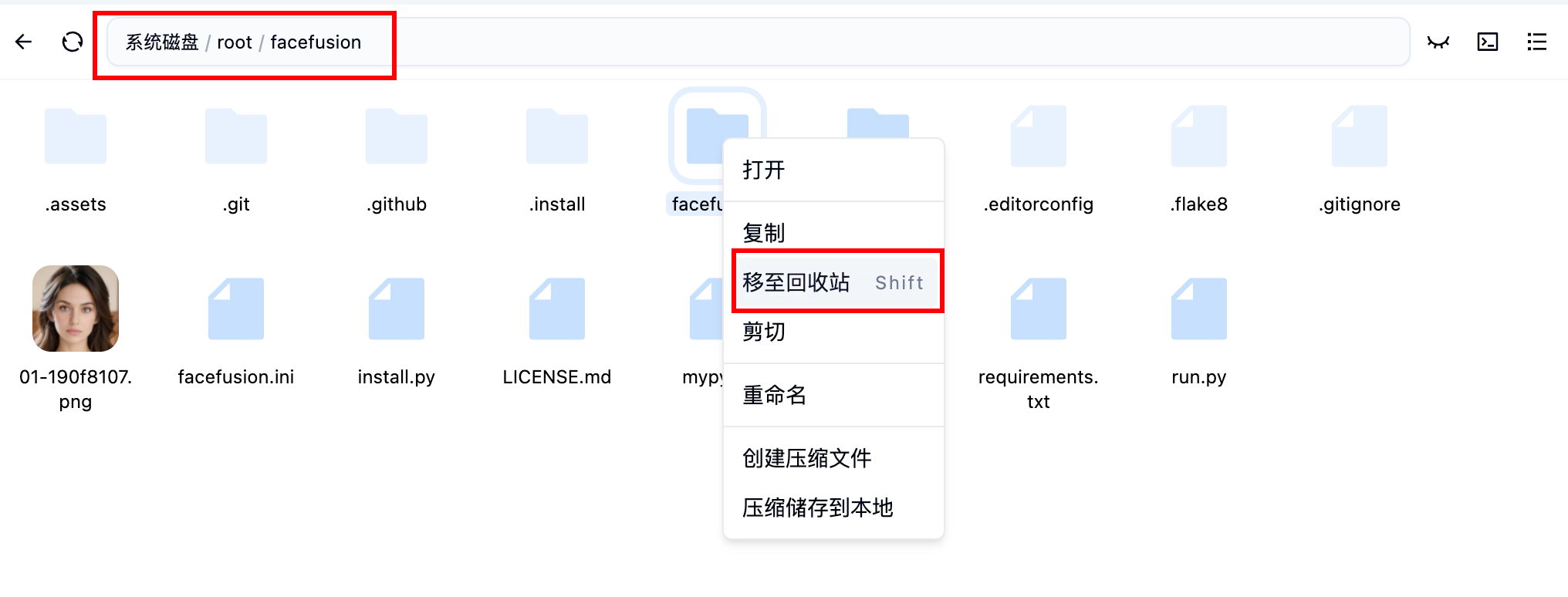
刪除facefusion文件夾
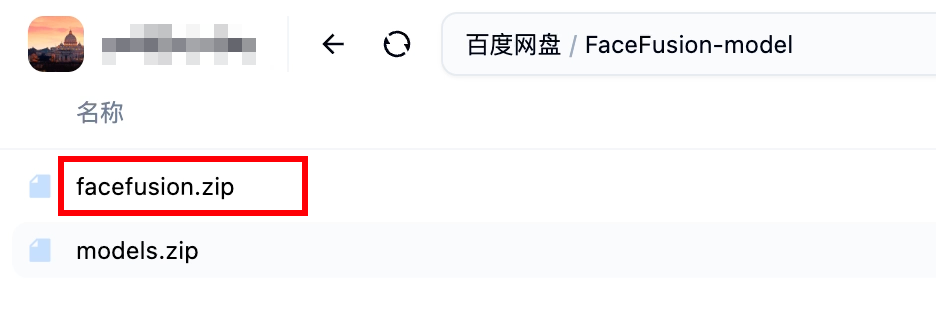
將網盤內的facefusion.zip拷貝到這里,并解壓
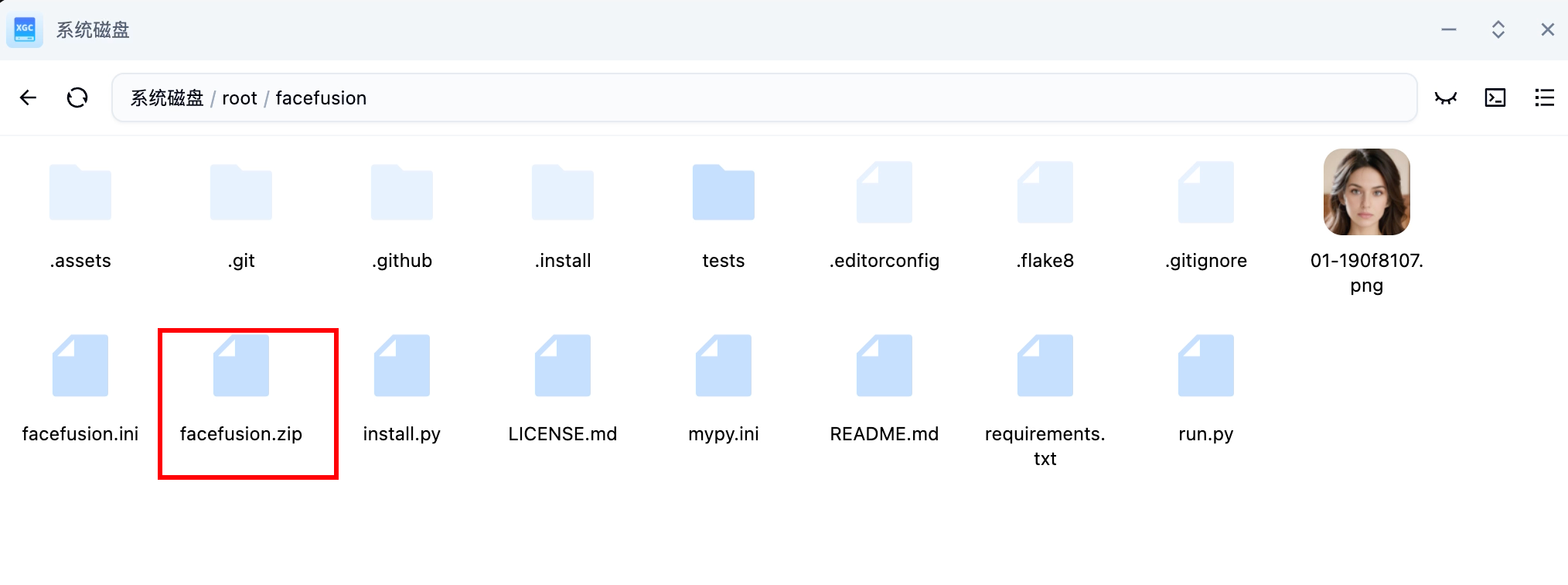
解壓后再次重啟FaceFusion服務即可。

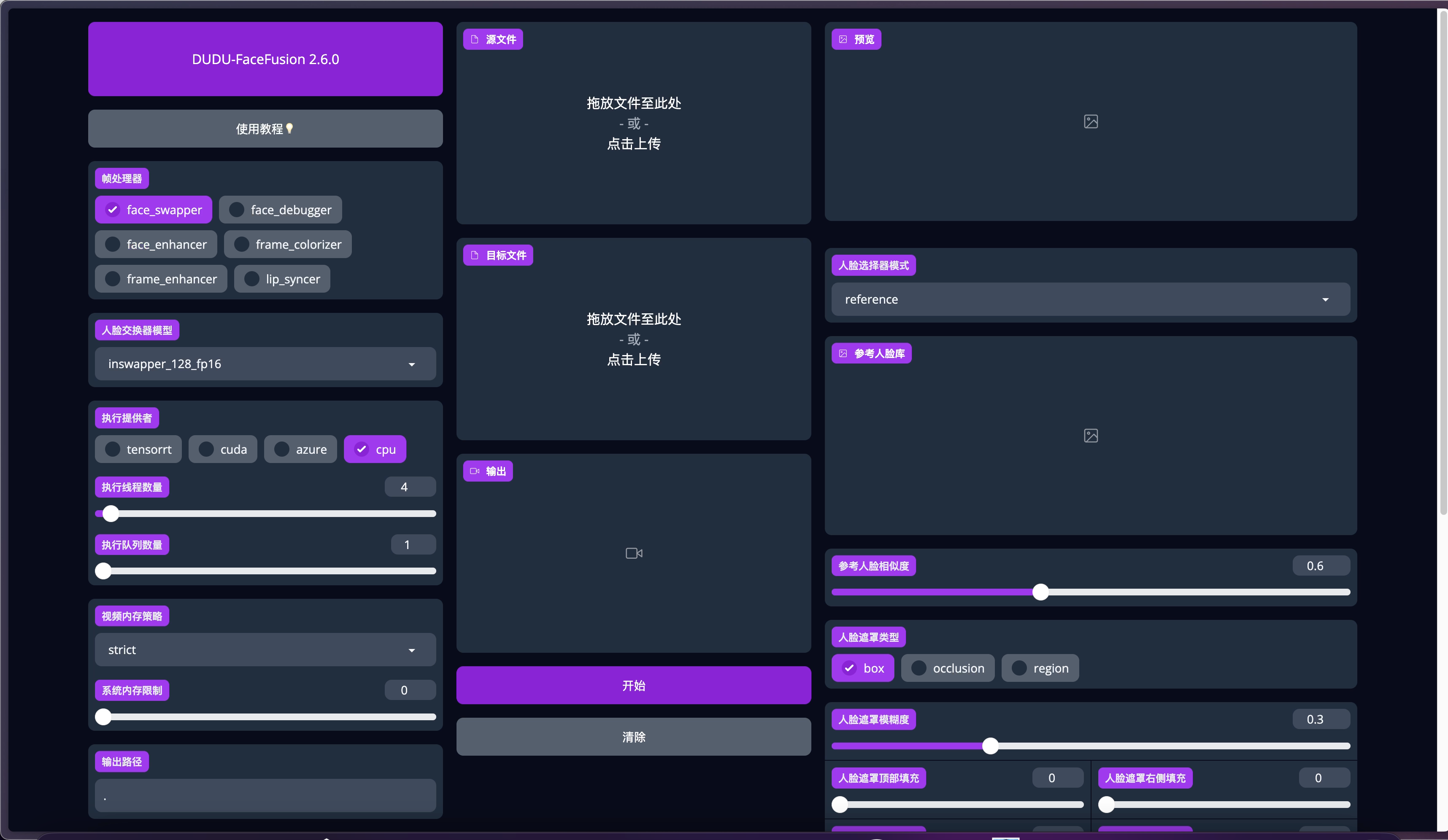
再次進入到頁面,界面已經全部變成中文的啦。
寫在最后
恭喜你,看到這里,已經可以自己在云端部署FaceFusion了!記得用的時候關閉實例,保存鏡像!
總結下,本篇教程我使用的是仙宮云服務,部署的時候會有個小“坑”——libgl1問題。在使用仙宮云之前我在AutoDL上也部署過,不會出現像libgl1問題這個“坑”,所以不同的GPU服務平臺的問題有可能會不一樣,但是流程都相同。
關于本篇用到的模型與命令可在公眾號內回復【臉資料】獲取。無套路!

最后希望這篇文章對你有幫助!感謝你的閱讀!













)

)

![錯誤 0x80070570:文件或目錄損壞且無法讀取/無法訪問[拒絕訪問]-解決方法](http://pic.xiahunao.cn/錯誤 0x80070570:文件或目錄損壞且無法讀取/無法訪問[拒絕訪問]-解決方法)

