背景
? ? ? ?基于 LangChain 0.3集成 Milvus 2.5向量數據庫構建的 NFRA(National Financial Regulatory Administration,國家金融監督管理總局)政策法規智能問答系統,第一個版本的檢索召回率是 79.52%,尚未達到良好、甚至是優秀的水平,有待優化、提升。
具體的代碼版本(可見);檢索評估召回率詳細說明(可見)
目標
? ? ? ? 檢索召回率 >= 85%
實現方法
? ? ? ?本次探究:把文件按法條逐條分塊,不考慮塊的大小,能否會提高分塊文本的檢索召回率。而本次探究實現的方法,則對應于 RAG系統整體優化思路圖(見下圖)的“文檔分塊”。
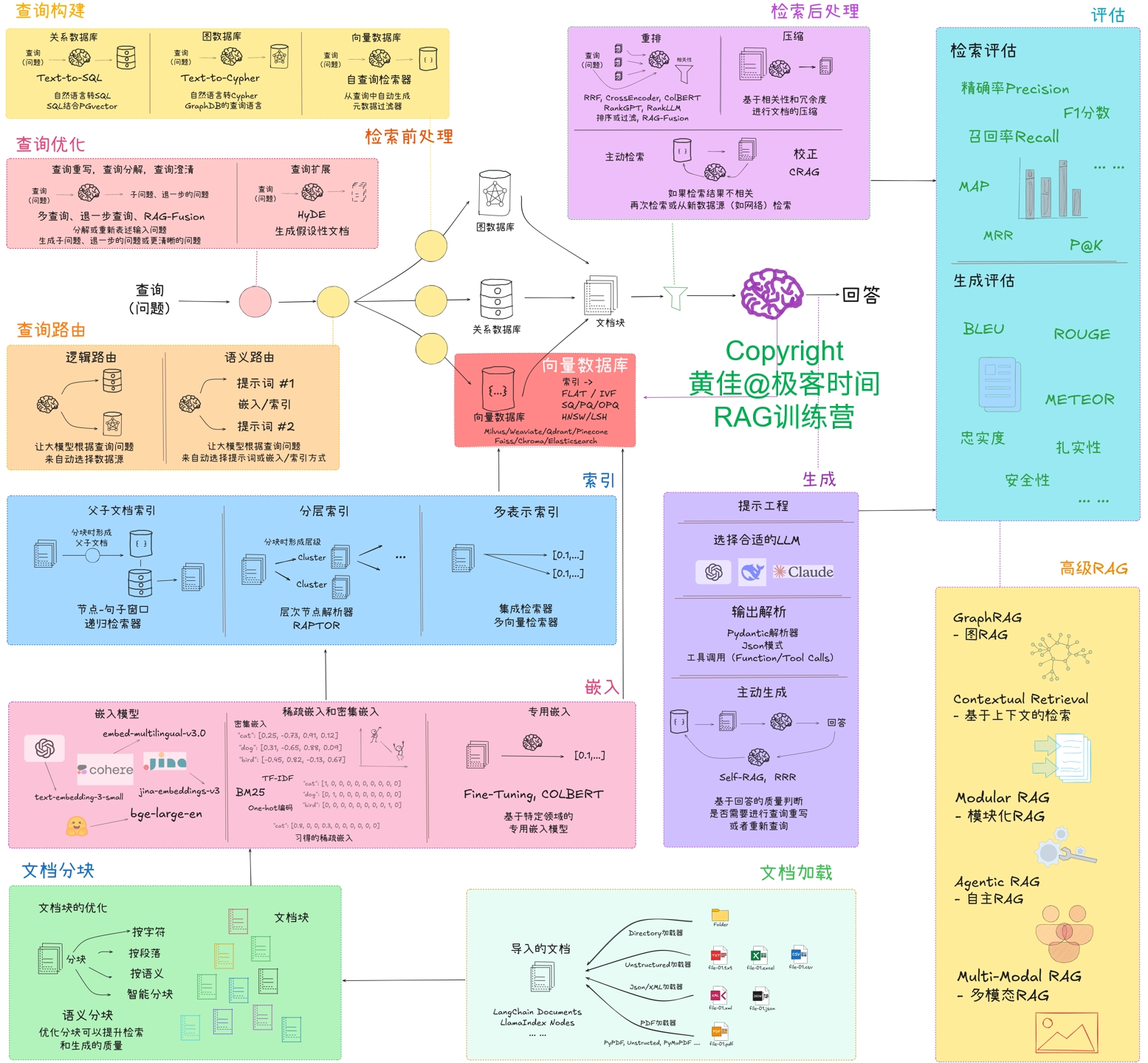
RAG系統整體優化思路圖
實現思路:
- 了解 LangChain 的文本切分器是否支持不考慮塊的大小,且使用正則表達式來分塊的;
- 若上述方法行不通,就考慮不使用 LangChain 的切分器,通過常規的 Python編碼來實現文件內容的分塊。
執行過程
LangChain 文本切分器
? ? ? ?一開始,嘗試看官網的文檔,發現它也不像平常看過的 Java幫助文檔那樣,具體介紹每一個類以及類中的方法等,它寫的更加簡單與實用。見下圖:
圖片來源:Text splitters | 🦜?🔗 LangChain
從圖中的右側可知,LangChain 文本切分器的實現分類有:
- 基于長度的切分;
- 基于文本結構的切分;
- 基于文件結構的切分;
- 基于語義的切分。
???????從上述分類來看,第一類基于長度,就不用考慮了;基于文本結構的切分,是可以考慮的,這類應該就有關于正則表達式。而至于其他兩類,顯然不符合本次探究的內容,也是不用考慮的。
而進一步了解基于文本結構切分實現,可見下圖:
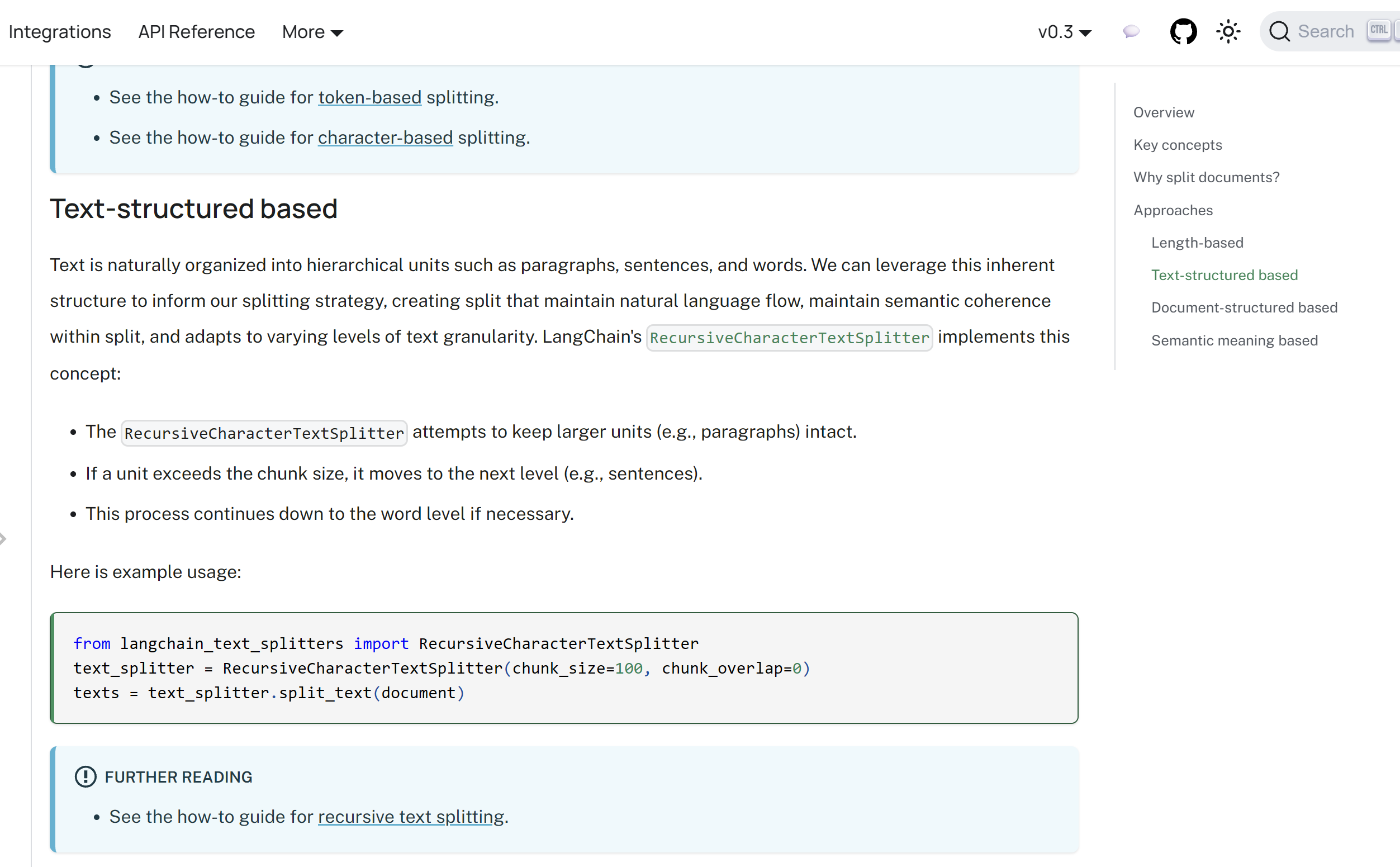
圖片來源:Text splitters | 🦜?🔗 LangChain
(大家看這種英文技術文檔,不要畏懼,剛開始不熟悉時,可以使用瀏覽器翻譯插件來輔助,等熟悉其中的關鍵內容,不用翻譯也大致能看懂了,也是一種“熟能生巧”)
從上圖,可知實現文本結構分類的主要實現類是:RecursiveCharacterTextSplitter。
接著,再進一步了解這個類(具體內容可見)之后,大致上就覺得方法1(考慮基于 LangChain的文本切分器來實現)是行不通了。
? ? ? ?不過,還想看看源代碼,萬一項目所使用的版本是支持的呢?但是,當看到下圖的內容,方法1 就徹底放棄了。
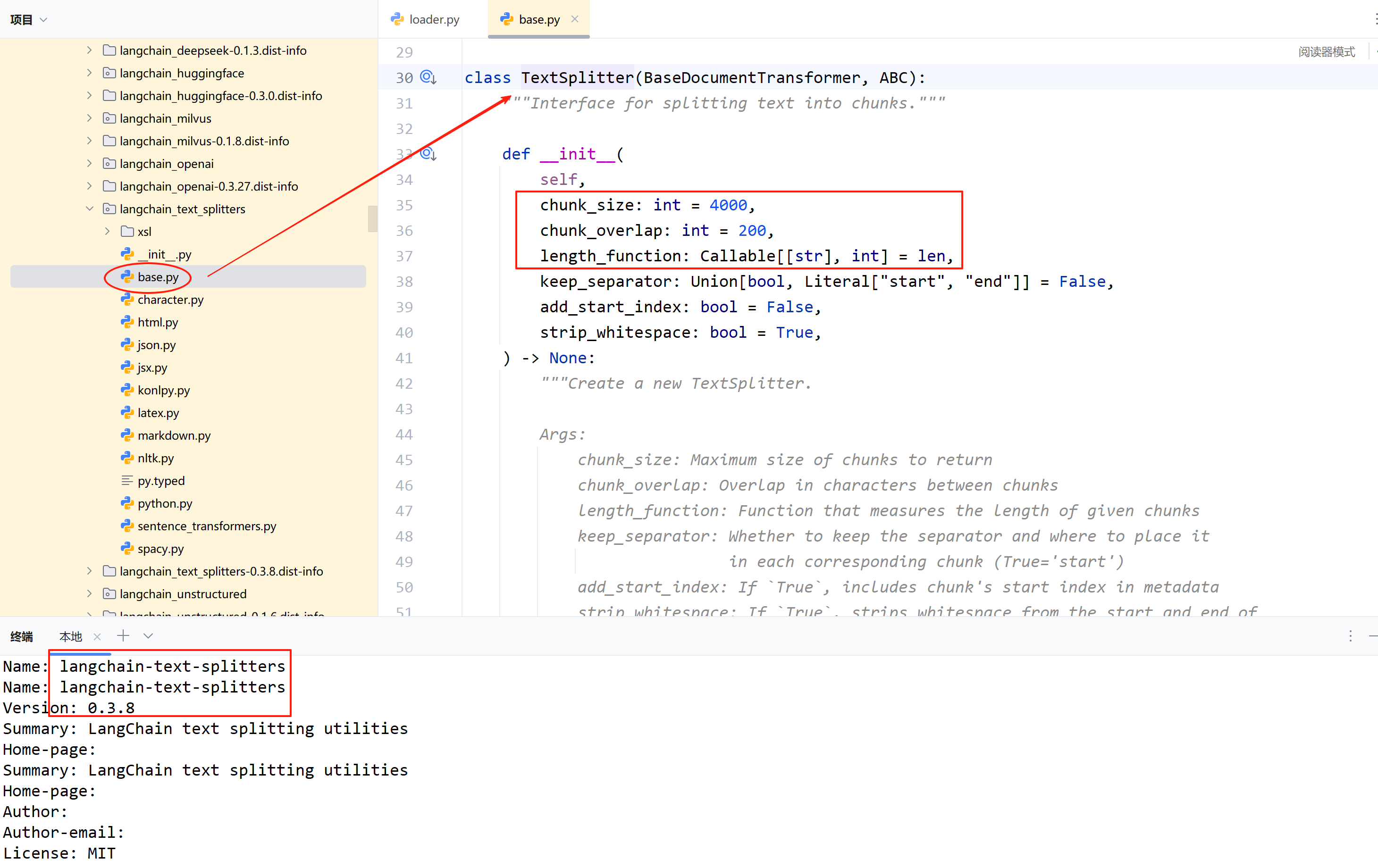
???????TextSplitter 類是?RecursiveCharacterTextSplitter 的基類,后者是繼承前者實現的。因此,不考慮分塊大小是不可行的。
Python 編碼實現
? ? ? ? Python編碼實現,其實并不難,畢竟實現思路已比較明確。把從文件中讀取的文本內容,根據法條的形式逐條分塊。技術實現上,使用的是正則表達式。實現的過程,主要是在測試驗證中寫出合適的正則表達式來分塊處理。
主要代碼實現如下:
1. 根據文本內容按法條分塊:
def split_by_pattern(content: str, pattern: str = r"第\S*條") -> List[str]:"""根據正則表達式切分內容:param content: 文本內容:param pattern: 正則表達式,默認是:r"第\S*條""""# 匹配所有以“第X條”開頭的位置matches = list(re.finditer(rf"^{pattern}", content, re.MULTILINE))if not matches:return [content.strip()]result = []for i, match in enumerate(matches):start = match.start()end = matches[i + 1].start() if i + 1 < len(matches) else len(content)part = content[start:end].strip()if part:result.append(part)return result2. 從目錄讀取文件并分塊:
class CustomDocument:def __init__(self, content, metadata):self.content = contentself.metadata = metadatadef load_and_split(directory: str) -> List[CustomDocument]:"""從指定文件目錄加載 PDF 文件并提取、切分文本內容:param directory: 文件目錄:return: 返回包含提取、切分后的文本、元數據的 CustomDocument 列表"""result = []# 從目錄讀取 pdf 文件pdf_file_list = get_pdf_files(directory)# 提取文本for pdf_file in pdf_file_list:document = fitz.open(pdf_file)text_content = ""for page_num in range(len(document)):page = document.load_page(page_num)text_content += page.get_text()# 去除無用的字符text_content = rm_useless_content(text_content)# 把文本保存為 txt 文件,便于優化output_path = os.path.join(config.FILE_OUTPUT_PATH, os.path.basename(pdf_file).replace('.pdf', '.txt'))save_text_to_file(text_content, output_path)# 切分文本內容split_list = split_by_pattern(text_content)# 元數據metadata = {"source": "《" + os.path.basename(pdf_file).replace('.pdf', '') + "》"}for split_content in split_list:result.append(CustomDocument(split_content, metadata))return result代碼編寫完成之后,實現方法也就完成了。
???????接下來對所有的文件進行讀取分塊、嵌入、存儲到一個新的 Milvus 向量數據庫集合(Collection)中,用于檢索評估。(具體過程就不在這里展開了,感興趣的朋友,可以基于第一版項目代碼,再結合上述代碼實現,修改 config 配置類的集合名稱參數,就可以跑起來了。本次的代碼會在后續更新到 Gitee項目上,具體時間暫時無法確定)
這里通過 Milvus 向量數據庫可視化工具 Attu,可以看到分塊嵌入向量化存儲后的數據,如下圖:
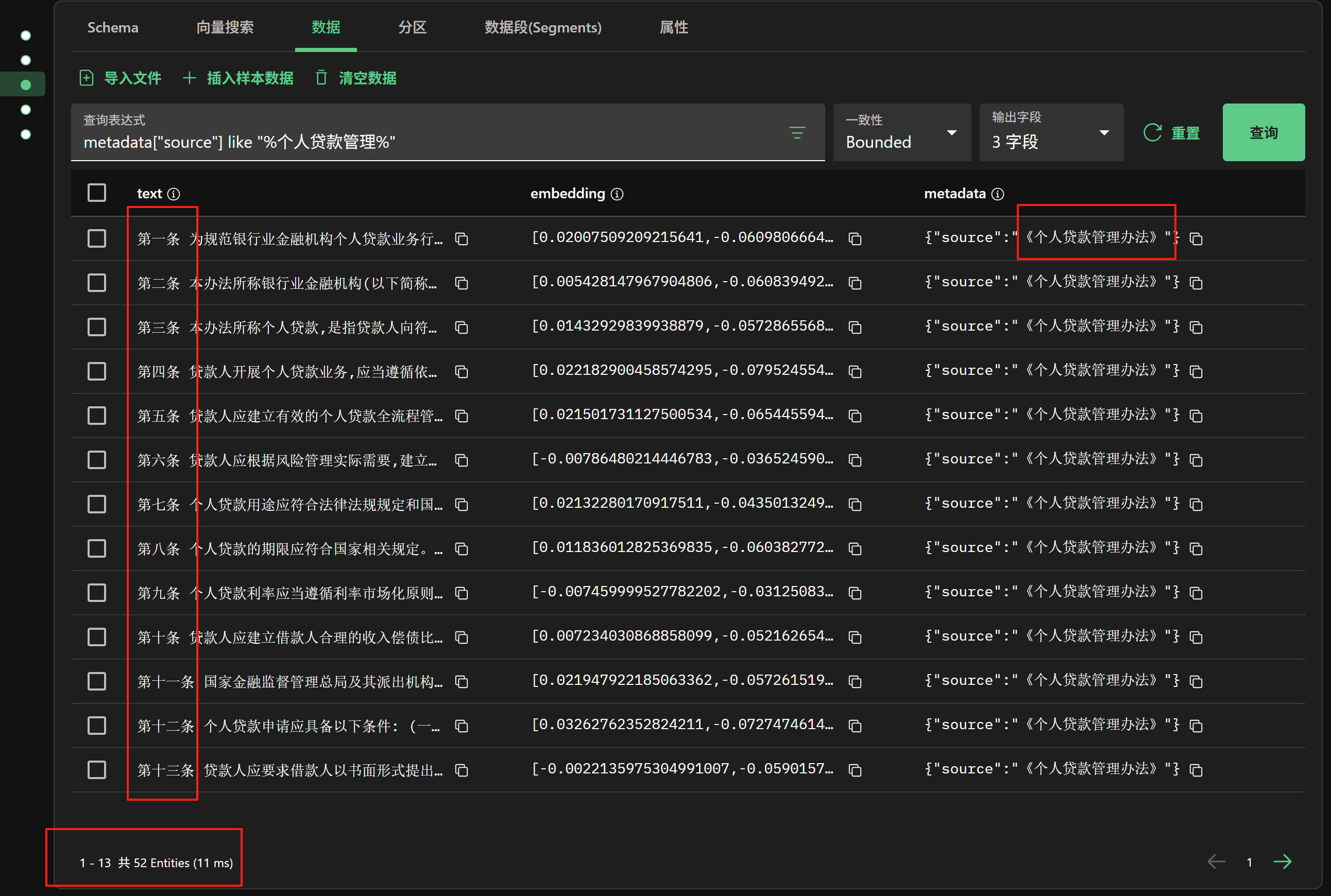
看到這個圖,搞過開發的,應該有一種莫名的熟悉感吧…
安裝 Attu,直接到官網 github 倉庫下載下來,點擊安裝即可。
注意和自己代碼中所使用的版本要一致。
安裝成功后,運行如下圖:
檢索評估(召回率)
? ? ? ? 為了確定檢索召回率是否真的提高了,采用的對比評估。因此,就要控制好變量與不變量。本次變的是文件文本的分塊方式,其他的均保持不變,尤其是評估數據集,和上一版本檢索召回率統計所使用的數據集是一致的。評估數據集和檢索結果處理文件,均已上傳到項目中。
RAG 相關處理說明
變量是:切分策略。
切分策略:直接使用(Python)正則表達式,[r"第\S*條 "],不區分塊大小
嵌入模型:模型名稱: BAAI/bge-base-zh-v1.5 (使用歸一化)
向量存儲:向量索引類型:IVF_FLAT (倒排文件索引+精確搜索);向量度量標準類型:IP(內積); 聚類數目: 100; 存儲數據庫: Milvus
向量檢索:查詢時聚類數目: 10; 檢索返回最相似向量數目: 2
檢索評估結果
| 數據表單 | 有效 問題個數 | TOP1 個數 | TOP1 平均相似度 | TOP1 召回率 | TOP2 個數 | TOP2?平均相似度 | TOP2 召回率 | TOP N策略個數 | TOP N策略召回率 |
| 通義 | 29 | 20 | 0.7305 | 68.97% | 2 | 0.6551 | 6.90% | 22 | 75.86% |
| 元寶 | 33 | 14 | 0.7121 | 42.42% | 9 | 0.7011 | 27.27% | 23 | 69.70% |
| 文心 | 21 | 18 | 0.6997 | 85.71% | 2 | 0.6622 | 9.52% | 20 | 95.24% |
| 總計 | 83 | 52 | 0.7141 | 62.65% | 13 | 0.6728 | 15.66% | 65 | 78.31% |
???????從表格數據來看,顯然TOP N 策略召回率:78.31%?小于目標檢索召回率:85%,而且它還比上一個版本的召回率 79.52%低。
???????為何檢索召回率,會出現不升反而還下降呢?
以下是在核對檢索結果的過程中發現的現象:
- 原來檢索不到的法條,現在可以 top 1檢索出來(見下圖)。問題一樣,分塊變小,語義更集中,從而檢索相似度會越高;

- 原來檢索出來的法條,現在檢索不出來(見下圖)。問題一樣,分塊變小,語義更集中,并不只是問題與真正所需的法條相似度提高,其他法條的相似度可能會更高。這是因為在某個章節中,里面的法條主題是比較集中的。

- 原來檢索不出來的,現在還是未能檢索出來(見下圖)。單個問題檢索,不可避免會出現這樣子的問題——雙語義差(問題嵌入,語義損失;分塊嵌入,語義損失)。

檢索評估結論
???????本次實現方法檢索召回率:78.31% 小于目標檢索召回率:85%,同時小于上一次的檢索召回率:79.52%,按法條逐條分塊并不是一個能提升檢索召回率的好方法。
(上述檢索評估結論,僅代表文中提到的評估數據集,在文中提及的項目代碼的處理方式下得到的對比結果,遠不具備廣泛性。)
總結
? ? ? ? 盡管結果未達到預期的目標,但整個過程下來,也是有收獲的,至少知道把文件按條文分塊并不是自己所預期的那樣,會讓檢索召回率明顯提升。而重要的收獲應是:基于現有條件 -> 提出設想 -> 尋找實現方法 -> 實現并驗證設想 -> 在驗證中得出結論,這一整個流程下來所獲得的。
? ? ? ?接下來,會繼續按 RAG系統整體優化思路圖進行優化,提升檢索召回率。根據本次檢索結果所觀察到的現象,接下來會進行檢索前處理。
?
文中基于的項目代碼地址:https://gitee.com/qiuyf180712/rag_nfra/tree/master
本文關聯項目的文章:RAG項目實戰:LangChain 0.3集成 Milvus 2.5向量數據庫,構建大模型智能應用-CSDN博客
?


)
命令詳解:sz)


 Scrcpy+按鍵映射(推薦))









)

 基礎知識點)
