
?🏻記錄學習過程中的輸出,堅持每天學習一點點~
??希望能給大家提供幫助~歡迎點贊👍🏻+收藏?+評論?🏻+指點🙏
1.5.4 Cache替換算法
Cache的頁面淘汰算法
常用替換算法有:
? 隨機替換算法RAND (Random):隨機地選擇Cache塊進行替換
分析:沒有考慮到局部性原理,運氣不好的話剛調入的Cache塊有會被馬上替換出來
? 先進先出FIFO (first-in-first-out):顧名思義就是替換最先被使用的Cache塊
分析:同樣沒有考慮到局部性原理,如果最先被使用的先被調出,而后又頻繁使用1234塊,就會發生【抖動現象】
? 最近最少用LRU ( least-recently used):每個Cache都設置一個【計數器】,代表每個Cache塊有多久沒被訪問,當Cache滿的時候替換【計數器】最大的Cache塊
分析:該算法比較好的利用了局部性原理(近期被訪問的主存塊可能在不就還會被訪問到),因此該算法很不錯
? 最不經常用LFU ( least-frequently used):每個Cache都設置一個【計數器】,用于記錄每個Cache塊被訪問的次數,當Cache滿的時候替換【計數器】最小的Cache塊
分析:沒有很好的利用局部性原理,因為已知經常用到的主存塊在未來不一定要用到,其命中率相比LRU較低,且CPU訪問主存的次數極高,代表計數器將會占用較多的空間
LRU和LFU比較:
LRU會替換最近最少訪問的Cache塊,而LFU會替換訪問次數最小的Cache塊
雖然算法不一樣,但從說明上這么一看似乎LRU也可以理解成LFU,最近最少訪問不就等于訪問次數最小嗎?
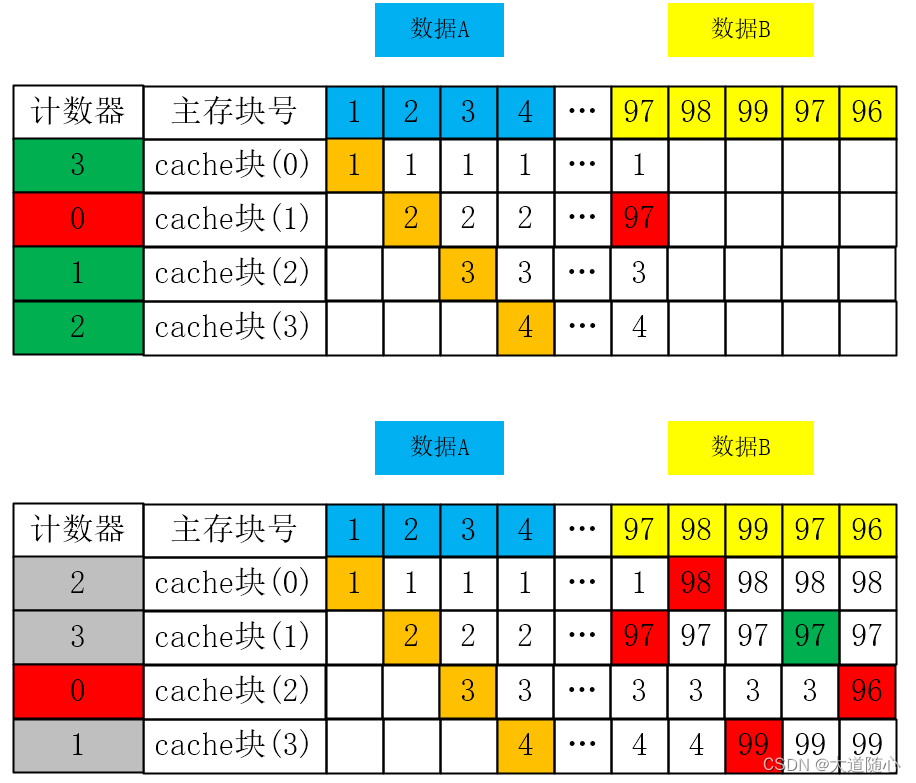
假設我們先頻繁訪問了某程序的主存數據A【主存塊號為1、2、3、4】,將其全部裝入Cache,如果未來需要頻繁訪問程序的主存數據B【97、98、99】
(1)對LFU算法而言,就會出現頻繁調入調出計數器最小的【Cache塊(1)】,即抖動現象
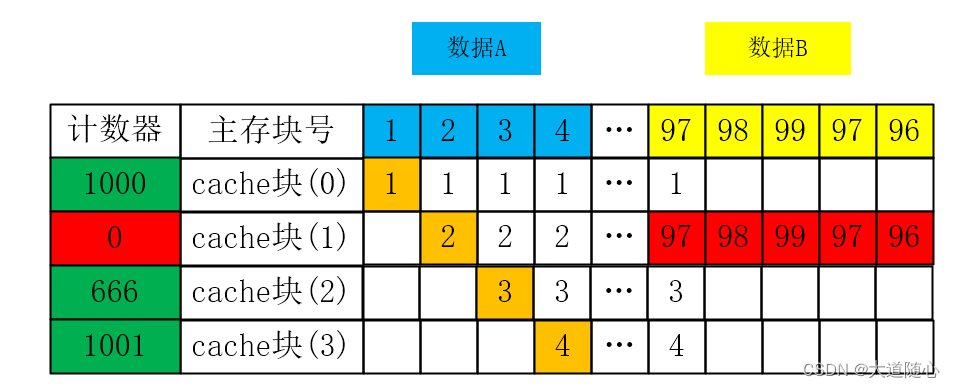
(2)但對于LRU算法的影響較小,LRU算法能更快的把數據A的Cache塊全部替換成數據B的主存塊
Cache的讀寫過程
寫直達:同時寫Cache與內存
寫回:只寫Cache,淘汰頁面時,寫回內存
標記法:只寫入內存,并將標志位清零,若用到此數據,只需要再次調取
練習題
Cache的替換算法中,( B )算法計數器位數多,實現困難。
A.FIFO
B. LFU
C. LRU
D. RAND
1.5.5 磁盤(外存儲器)
● 機械磁盤存在兩組運動:
◎ 磁盤的旋轉運動
◎ 機械臂控制磁頭沿半經方向的直線運動
● 存取時間=尋道時間+等待時間
◎ 尋道時間:指磁頭移動到磁道所需的時間
◎ 等待時間:等待讀寫的扇區轉到磁頭下方所用的時間
分 磁道和扇區
練習題
在磁盤調度管理中,通常( C )(2019下半年試題)
A.先進行旋轉調度,再進行移臂調度
B.在訪問不同柱面的信息時,只需要進行旋轉調度
C.先進行移臂調度,再進行旋轉調度
D.在訪問同一磁道的信息時,只需要進行移臂調度
1.6.1 輸入/輸出技術
● 直接程序控制
◎ 分為無條件傳送和程序查詢方式
◎ 降低了CPU的效率
◎ 對外部的突發事件無法做出實時響應
● 程序中斷方式
◎ 利用中斷方式完成數據的輸入/輸出
◎ CPU接到中斷請求信號后,保存正在執行程序的現場
◎ 與程序控制方式相比,因為CPU無須等待而提高了效率
● DMA
◎ 在主存與I/O設備(外設)之間建立數據通路進行數據的交換處理
◎ 在DMA傳送過程中無須CPU的干預
◎ DMA傳送數據時要占用系統總線,此時,CPU不能使用總線
◎ DMA傳送結束為中斷
● 輸入/輸出處理機(IOP)
◎ 分擔了CPU的一部分功能,可以實現對外圍設備的統一管理,完成外圍設備與主存之間的數據傳送
◎ 大大提高了CPU的工作效率,這種效率的提高是以增加更多的硬件為代價的
練習題
DMA控制方式是在( C )之間直接建立數據通路進行數據的交換處理。(2019年上半年試題軟設)
A.CPU與主存
B.CPU與外設
C.主存與外設
D.外設與外設
計算機運行過程中,CPU需要與外設進行數據交換。采用( B )控制技術時,CPU與外設可并行工作。
(2017年下半年)
A.程序查詢方式和中斷方式
B.中斷方式和DMA方式
C.程序查詢方式和DMA方式
D.程序查詢方式、中斷方式和DMA方式
1.7.1 flynn分類法
計算機系統結構的分類方法之一
1966年M.J.Flynn提出了如下定義:
指令流(Instruction Stream)——機器執行的指令序列。
數據流 (Data Stream)——指令調用的數據序列,包括輸入數據和中間結果。
多倍性(Multiplicity)——在系統最受限制的元件上同時處于同一執行階段指令或數據執行的最大可能個數。
按照指令和數據流不同的組織方式,計算機系統可分為四類:
單指令單數據流(Single Instruction stream and Single Data stream,SISD):SISD其實就是傳統的順序執行的單處理器計算機,其指令部件每次只對一條指令進行譯碼,并只對一個操作部件分配數據。流水線方式的單處理機有時也被當成SISD。
單指令多數據流(SIMD) 特性:各處理機以同步的形式執行同一條指令
多指令單數據流(MISD) 特性:被證明不可能,至少是不實際
多指令多數據流(MIMD) 特性:能夠實現作業,任務,指令等各級全面并行
| Single | Multiple | |
|---|---|---|
| Single | SISD | MISD |
| Multiple | SIMD | MIMD |
練習題
Flymn分類法根據計算機在執行程序的過程中( A )的不同組合,將計算機分為4類。當前主流的多核計算機屬于( D )計算機。
A.指令流和數據流
B.數據流和控制流
C.指令流和控制流
D.數據流和總線帶寬
A.SISD
B.SIMD
C.MISD
D.MIMD
1.7.2 CISC和RISC
CISC,全稱為Complex Instruction Set Computing,意為復雜指令集計算。它是一種指令集設計理念,其特點是指令數量多、格式多樣、長度不一、功能強大。CISC可以用較少的指令完成較復雜的操作,典型的代表是X86架構。這種架構的處理器芯片被廣泛應用于Windows操作系統的服務器,是目前主流的服務器架構。
CISC架構的主要優點有:
指令執行效率高,可以用較少的指令周期完成較復雜的任務,提高CPU利用率。
編譯器設計簡單,因為指令功能強大,編譯器可以用較少的指令生成目標代碼,降低編譯難度和時間。
程序可移植性好,由于指令集兼容性高,程序可以在不同的平臺上運行,提高軟件開發效率。
然而,CISC架構也存在一些缺點:
指令譯碼復雜,由于指令格式多樣、長度不一,CPU需要更多的硬件電路和時間來譯碼執行指令,這增加了芯片面積和功耗。
指令執行速度慢,因為每條指令需要更多的時鐘周期來完成,這降低了程序運行速度。
指令集臃腫,指令數量多,有些指令很少使用或者功能重復,造成了指令集的浪費和冗余。
RISC,全稱為Reduced Instruction Set Computer,意為精簡指令系統計算機。RISC的特點包括選取使用頻率較高的一些簡單指令以及一些很有用但不復雜的指令,讓復雜指令的功能由頻率較高的簡單指令的組合完成。此外,RISC的指令長度固定,指令格式種類少,尋址方式種類少,并且大部分指令在一個時鐘周期內完成。
RISC架構的主要優點有:
指令執行時間短,因為90%的指令是由硬件直接完成,只有10%的指令是由軟件以組合的方式完成。
適合采用流水線處理架構的設計,平均一周期可以完成一指令。
然而,RISC架構也存在一些缺點,如指令精簡化后造成應用程序碼變大,需要較大的存儲器空間。
總的來說,CISC和RISC各有其特點和優缺點,適用于不同的場景和需求。在實際應用中,需要根據具體的應用場景和需求來選擇適合的指令集架構。
| 指令系統類型 | 指令 | 尋址方式 | 實現方式 | 其他 | 代表 |
|---|---|---|---|---|---|
| CISC(復雜) | 數量多,使用頻率差別大,可變長格式 | 支持多種 | 微程序控制技術(微碼) | 研制周期長 | X86 |
| RISC(精簡) | 數量少,使用頻率接近,定長格式,大部分為單周期指令,操作寄存器,只有Load/Store操作內存 | 支持方式少 | 增加了通用寄存器;硬布線邏輯控制為主;更適合采用流水線 | 優化編譯,有效支持高級語言(如java) | RISC-V、ARM |
練習題
(2022年上半年)以下關于RISC和CISC的敘述中,不正確的是(B )
A.RISC的大多指令在一個時鐘周期內完成
B.RISC普遍采用微程序控制器,CISC則普遍采用硬布線控制器
C.RISC的指令種類和尋指方式相對于CISC更少
D.RISC和CISC都采用流水線技術






)
)


 _Mysql (8.0.X)設置密碼強度)








