

🌈個人主頁: 鑫寶Code
🔥熱門專欄: 閑話雜談| 炫酷HTML | JavaScript基礎
?💫個人格言: "如無必要,勿增實體"

文章目錄
- Adaboost: 強化弱學習器的自適應提升方法
- 引言
- Adaboost基礎概念
- 弱學習器與強學習器
- Adaboost核心思想
- Adaboost算法流程
- 1. 初始化樣本權重
- 2. 迭代訓練弱學習器
- 3. 組合弱學習器
- 4. 停止準則
- Adaboost的關鍵特性
- 應用場景
- 實現步驟簡述
- 結語
Adaboost: 強化弱學習器的自適應提升方法
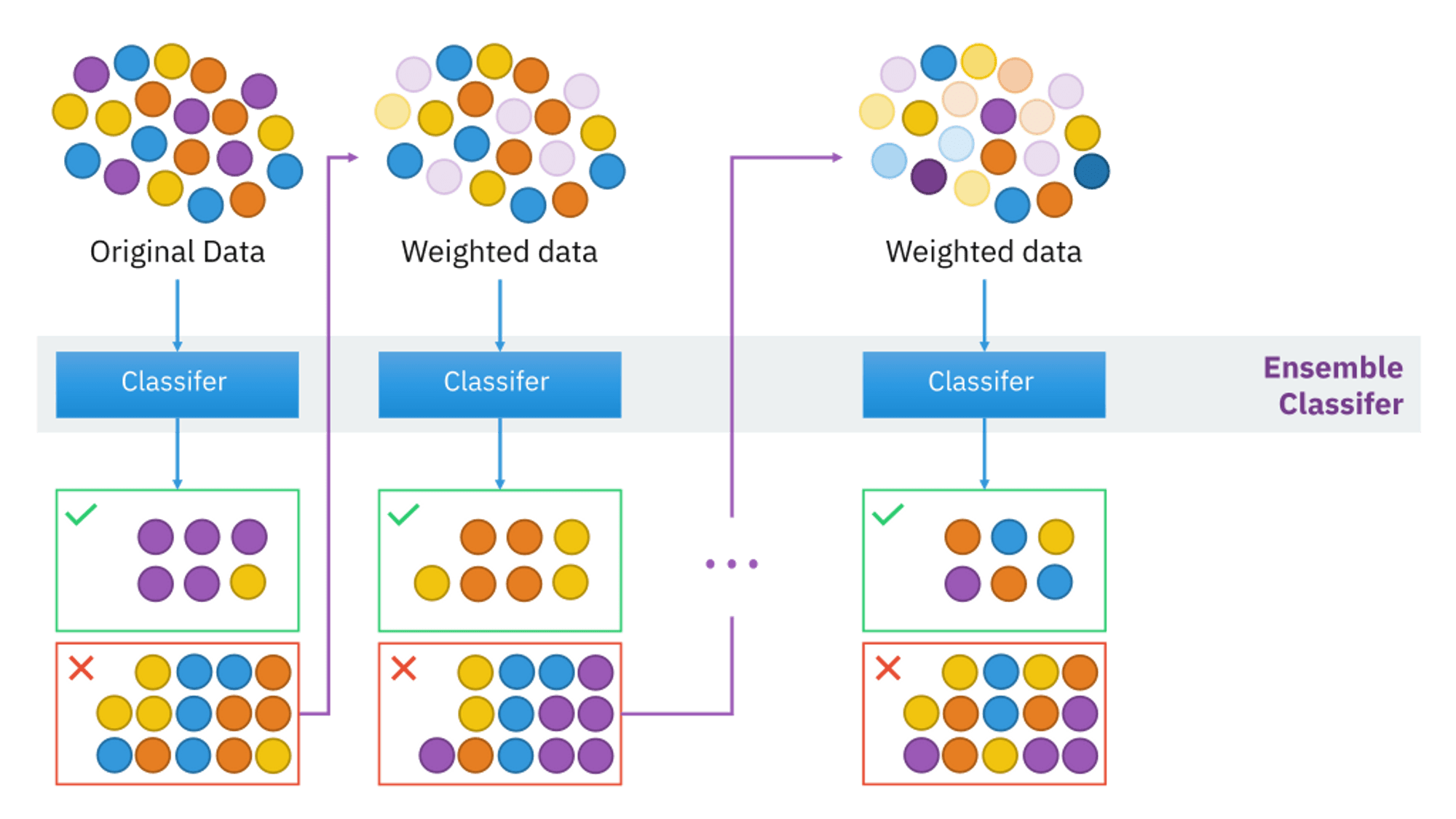
引言
在機器學習領域,集成學習是一種通過結合多個弱模型以構建更強大預測模型的技術。Adaptive Boosting,簡稱Adaboost,是集成學習中的一種經典算法,由Yoav Freund和Robert Schapire于1996年提出。Adaboost通過迭代方式,自適應地調整數據樣本的權重,使得每個后續的弱學習器更加關注前序學習器表現不佳的樣本,以此逐步提高整體預測性能。本文將深入探討Adaboost的工作原理、算法流程、關鍵特性、優勢及應用場景,并簡要介紹其實現步驟。

Adaboost基礎概念
弱學習器與強學習器
- 弱學習器:指那些僅比隨機猜測略好一點的學習算法,如決策樹的淺層版本。
- 強學習器:通過組合多個弱學習器,達到超越任何單個弱學習器性能的算法。
Adaboost核心思想
Adaboost的核心思想是通過改變訓練數據的權重分布來不斷聚焦于那些難以被正確分類的樣本。每一輪迭代中,算法會根據上一輪的錯誤率調整樣本的權重,使得錯誤分類的樣本在下一輪中獲得更高的權重,從而引導新生成的弱學習器重點關注這些“困難”樣本。
Adaboost算法流程
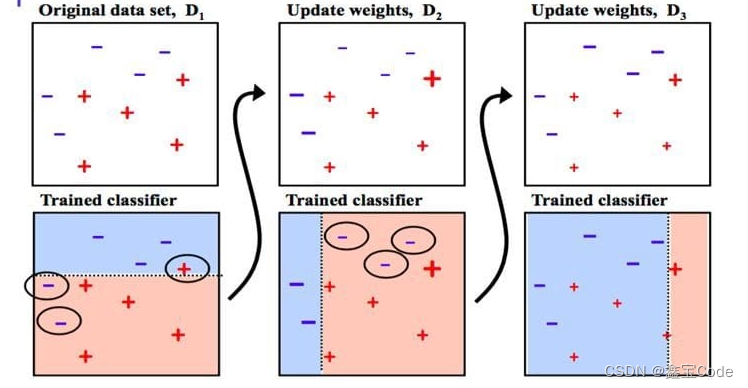
Adaboost算法可以分為以下幾個步驟:
1. 初始化樣本權重
- 所有訓練樣本初始權重相等,通常設為 w i ( 1 ) = 1 N w_i^{(1)} = \frac{1}{N} wi(1)?=N1?,其中 N N N 是樣本總數。
2. 迭代訓練弱學習器
對于每一輪 t = 1 , 2 , . . . , T t=1,2,...,T t=1,2,...,T:
- 使用當前樣本權重分布訓練弱學習器 h t h_t ht?。弱學習器的目標是最小化加權錯誤率 ? t = ∑ i = 1 N w i ( t ) I ( y i ≠ h t ( x i ) ) \epsilon_t = \sum_{i=1}^{N} w_i^{(t)} I(y_i \neq h_t(x_i)) ?t?=∑i=1N?wi(t)?I(yi?=ht?(xi?)),其中 I I I是指示函數,當條件滿足時返回1,否則返回0。
- 計算弱學習器的權重 α t = 1 2 ln ? ( 1 ? ? t ? t ) \alpha_t = \frac{1}{2} \ln\left(\frac{1-\epsilon_t}{\epsilon_t}\right) αt?=21?ln(?t?1??t??),反映了該學習器的重要性。
- 更新樣本權重:對分類正確的樣本減小其權重,錯誤分類的樣本增加其權重。具體為 w i ( t + 1 ) = w i ( t ) exp ? ( ? α t y i h t ( x i ) ) w_i^{(t+1)} = w_i^{(t)} \exp(-\alpha_t y_i h_t(x_i)) wi(t+1)?=wi(t)?exp(?αt?yi?ht?(xi?)),然后重新歸一化以確保所有權重之和為1。
3. 組合弱學習器
經過T輪迭代后,最終的強學習器為所有弱學習器的加權投票結果: H ( x ) = sign ( ∑ t = 1 T α t h t ( x ) ) H(x) = \text{sign}\left(\sum_{t=1}^{T} \alpha_t h_t(x)\right) H(x)=sign(∑t=1T?αt?ht?(x))。
4. 停止準則
設定最大迭代次數 T T T作為停止條件,或直到達到預定的性能閾值。
Adaboost的關鍵特性
- 自適應性:自動調整數據權重,使算法能夠專注于較難分類的樣本。
- 弱學習器的多樣性:由于每一輪學習器都針對不同的樣本分布進行訓練,這促進了弱學習器之間的多樣性,有助于提升整體模型的泛化能力。
- 異常值魯棒性:通過調整權重,Adaboost能夠減少異常值對模型的影響。
- 過擬合控制:隨著迭代增加,若學習器對新數據不再提供顯著增益,則權重更新趨于平緩,自然停止學習過程,有助于防止過擬合。
應用場景
Adaboost因其高效和靈活,在多種機器學習任務中展現出廣泛的應用潛力,包括但不限于:
- 分類問題:如手寫數字識別、醫學圖像診斷。
- 異常檢測:通過構建正常行為的強分類器,識別偏離此模型的行為。
- 特征選擇:在預處理階段,Adaboost可用于評估特征重要性,輔助篩選最有效的特征集。
實現步驟簡述
實現Adaboost算法主要包括以下Python偽代碼:
# 初始化
weights = np.ones(N) / N
alphas = []
models = []# 迭代T輪
for t in range(T):# 使用當前權重訓練弱學習器model = train_weak_learner(X, y, weights)models.append(model)# 計算加權錯誤率errors = compute_errors(model.predict(X), y)weighted_error = np.sum(weights[errors != 0])# 計算弱學習器權重alpha = 0.5 * np.log((1 - weighted_error) / weighted_error)alphas.append(alpha)# 更新樣本權重Z = np.sum(weights * np.exp(-alpha * y * errors))weights *= np.exp(-alpha * y * errors) / Z# 構建最終強學習器
def predict(X):scores = np.sum([alpha * model.predict(X) for alpha, model in zip(alphas, models)], axis=0)return np.sign(scores)結語
Adaboost算法以其獨特的方式展示了如何通過集成弱學習器來構建出強大且魯棒的預測模型。它不僅在理論上優雅,在實踐中也極其有效,成為機器學習領域的一個基石。隨著技術的發展,Adaboost及其變體在復雜數據集上的應用持續擴展,持續推動著人工智能的進步。理解并掌握Adaboost的工作機制,對于每一位致力于機器學習研究和應用的開發者來說,都是不可或缺的。







)













