目錄
- 背景
- 當前大模型訓練和應用面臨的問題
- 訓練Token耗盡
- 訓練語料質量要求高
- LLM文檔問答應用中文檔解析不精準
- 合合信息的文檔解析技術
- 1. 具備多文檔元素識別能力
- 2. 具備版面分析能力
- 3. 高性能的文檔解析
- 4. 高精準、高效率的文檔解析
- 文檔多板式部分示例
- 文檔解析典型技術難點
- 元素重疊、本身多樣性、復雜板式示例
- 單行、行內、表格內公式示例
- 合合信息提出的文檔解析技術解決方案
- 文檔圖像預處理算法框架
- 圖像文檔彎曲矯正算法
- 圖像文檔干擾去除算法
- 版面分析算法框架
- 物理版面分析 - 文檔布局分析
- 邏輯版面分析 - 語義結構分析
- 版面分析算法的發展
- Textln 文檔解析效果
- 總結
背景
2024年5月24日-26日于西安召開中國圖象圖形大會(CCIG 2024),此次大會由中國圖象圖形學學會主辦,空軍軍醫大學、西安交通大學和西北工業大學承辦,南京理工大學、陜西省圖象圖形學學會、陜西省生物醫學工程學會協辦,陜西省科學技術協會支持。包括于起峰院士、鄭海榮院士、焦李成教授、王大軼研究員和虞晶怡教授在內的多位知名學者將作主旨報告,帶來前沿的學術分享。大會期間將舉辦25場學術論壇、7場特色論壇和2場企業論壇,匯聚2000余名專家學者,構建開放創新、交叉融合的交流平臺。
在此盛會上,合合信息的智能創新事業部研發總監常揚發表演講。常揚老師分享了合合信息在文檔解析技術方面的最新研究成果,探討如何利用這些技術加速大模型的訓練和應用。文檔解析技術在大模型發展中扮演著至關重要的角色,尤其是在應對訓練Token耗盡、語料質量要求高和解析不精準等挑戰,高效獲取高質量數據的方法,包括文檔元素識別、版面正確解析和轉化速度快等關鍵技術。本文將對常揚老師的演講進行詳細展開。
當前大模型訓練和應用面臨的問題
訓練Token耗盡
大模型(如GPT-4、BERT等)在訓練過程中需要處理大量的文本數據,這些數據被分解成更小的單位,稱為Tokens。每個Token代表一個詞、詞的一部分或一個標點符號。隨著模型變得越來越復雜,對數據的需求也隨之增加,訓練Token的耗盡成為一個主要問題。這意味著模型在訓練過程中會消耗大量的Tokens,如果Tokens不足,模型的訓練效果會受到限制。
訓練語料質量要求高
高質量的訓練語料是確保大模型性能的關鍵。低質量或噪聲數據可能會導致模型學習到錯誤的信息,從而影響其性能。高質量語料需要具備準確性、豐富性和多樣性,確保模型能夠理解和生成高質量的語言。
LLM文檔問答應用中文檔解析不精準
在大模型的應用中,如文檔問答(Document QA)系統,文檔解析的精準度至關重要。文檔解析不精準會導致模型無法正確理解文檔內容,影響問答的準確性和用戶體驗。例如,當文檔中的表格、公式、圖表等復雜元素不能被正確解析時,模型可能會提供錯誤或不完整的答案。
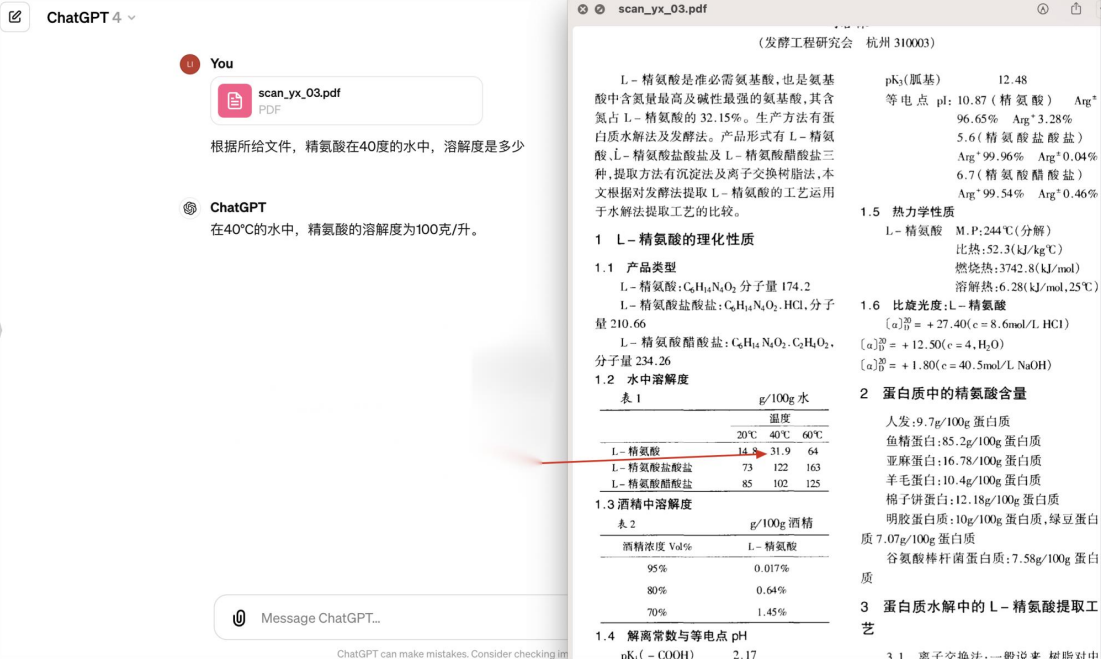

合合信息的文檔解析技術
合合信息在文檔解析技術方面進行了深入的研究和開發,其核心研究方向包括多文檔元素識別、版面分析和高性能的文檔解析技術。這些技術不僅提高了文檔解析的精度和效率,還為大模型的訓練和應用提供了有力的支持。
1. 具備多文檔元素識別能力
多文檔元素識別能力是指系統能夠識別并區分文檔中不同類型的元素,如表格、段落、公式、標題等。每種元素在文檔中都有其特定的結構和語義,準確識別這些元素是文檔解析的基礎。
技術實現:
- 深度學習模型:利用卷積神經網絡(CNN)和循環神經網絡(RNN)等深度學習模型,訓練系統識別不同的文檔元素。
- 特征提取:通過圖像處理技術提取表格線條、段落邊界、公式符號等特征,以提高識別的準確性。
- 標注數據集:構建大型標注數據集,包含多種文檔元素的標注信息,用于模型訓練和驗證。
應用場景: - 文檔自動化處理:在辦公自動化、電子檔案管理等場景中,實現自動化的文檔分類和元素提取。
- 教育和科研:識別學術論文中的圖表和公式,輔助科研數據的整理和分析。
2. 具備版面分析能力
版面分析能力是指系統能夠正確解析文檔的版式布局,識別文檔中的欄、節、段等布局結構。復雜的文檔版式,如雙欄、三欄和文表混合布局,給解析帶來極大挑戰。
技術實現:
- 物理版面分析:使用基于回歸的單階段檢測模型(如Faster R-CNN、YOLO)檢測文檔中的物理布局元素(如欄、節)。
- 邏輯版面分析:通過語義分析技術,理解文檔的語義結構和層次關系,將不同的文字塊組織成段落、列表等語義單元。
- 混合方法:結合物理和邏輯版面分析方法,提升對復雜文檔版式的解析能力。
應用場景: - 出版和印刷:解析書籍、報紙、雜志等出版物的版面結構,優化排版和印刷流程。
- 檔案數字化:對紙質檔案進行數字化處理,保持原始版面布局,提高數字檔案的可讀性和可用性。
3. 高性能的文檔解析
高性能的文檔解析技術能夠快速處理和轉化大規模文檔,尤其是上百頁的PDF文檔,確保還原正確的閱讀順序,避免混亂的語序。
技術實現:
- 并行處理技術:利用多線程和分布式計算技術,加快大規模文檔的解析速度。
- 優化算法:優化文檔解析算法,提高處理效率,減少時間消耗。
- 硬件加速:借助GPU加速技術,進一步提升文檔解析的性能。
應用場景: - 大數據處理:在金融、法律、醫療等領域,快速解析和處理大量文檔,提高數據處理效率。
- 實時應用:在實時文檔問答和即時信息提取等應用中,提供快速、準確的文檔解析服務。
4. 高精準、高效率的文檔解析
文檔解析的精準度和效率是衡量技術性能的重要指標。合合信息的文檔解析技術能夠提供高精準、高效率的解析結果,適用于大模型的訓練和應用場景。
技術實現:
- 精細化模型訓練:通過精細化的模型訓練和調優,提高文檔解析的準確性。
- 錯誤糾正機制:引入錯誤檢測和糾正機制,自動識別和修正解析過程中的錯誤。
- 用戶反饋系統:利用用戶反饋信息,持續優化和改進解析算法。
應用場景: - 大模型訓練:在大模型訓練過程中,提供高質量的訓練數據,提升模型性能。
- 知識庫問答:在知識庫問答系統中,快速準確地解析文檔內容,提供高質量的問答服務。
文檔多板式部分示例

文檔解析典型技術難點
在文檔解析過程中,技術難點眾多,涉及文檔元素的遮蓋重疊、復雜版式、多樣的文檔元素、頁眉頁腳、多欄布局與表格、無線表格與合并單元格,以及各種公式的識別和處理。以下是對這些技術難點的詳細列舉。
- 元素遮蓋重疊:文檔中的各種元素(如文字、表格、公式等)可能會相互遮擋或重疊,給解析帶來挑戰。
- 復雜版式:文檔可能采用雙欄、跨頁、三欄等復雜的版式布局,需要準確識別和分析這些版式結構。
- 元素本身的多樣性:不同類型的文檔元素(如標題、段落、表格、公式等)具有不同的特點,需要針對性地進行識別和分析。
- 頁眉頁腳的復雜形式:頁眉頁腳的形式可能多種多樣,需要準確識別并區分。
- 多欄布局及其與表格的影響:多欄布局以及多欄中插入表格會對文檔解析帶來額外的挑戰。
- 無線表格與合并單元格:無線表格與合并單元格的識別。
- 各種公式:單行公式、行內公式、表格內公式等
元素重疊、本身多樣性、復雜板式示例
元素重疊、本身多樣性、復雜板式示例

單行、行內、表格內公式示例

合合信息提出的文檔解析技術解決方案
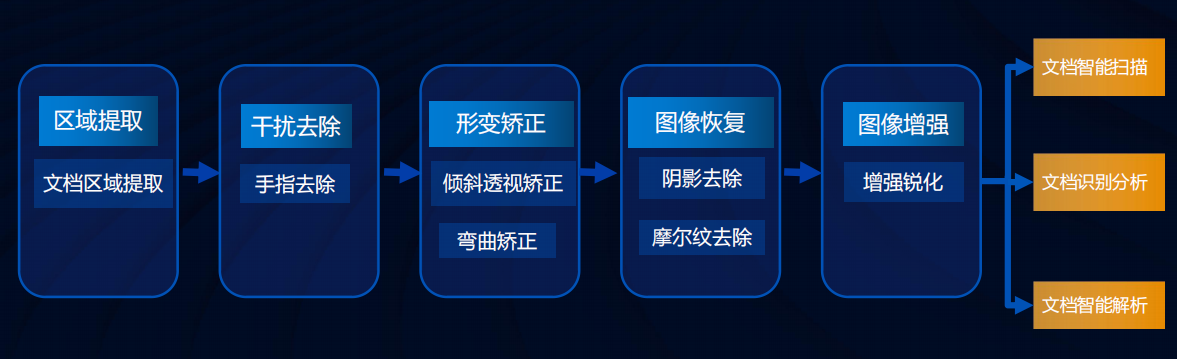
文檔圖像預處理算法框架
主要包括以下幾點
- 區域提取: 提取文檔區域
- 干擾去除: 去除手指、陰影、摩爾紋等干擾
- 形變矯正: 包括傾斜透視矯正、彎曲矯正等
- 圖像恢復: 陰影去除、摩爾紋去除
- 圖像增強: 增強銳化等操作
圖像文檔彎曲矯正算法
- 形變文檔圖像建模
- 使用偏移場來建模形變文檔圖像
- 通過DocUNet網絡進行形變矯正
- 空間變換
- 根據偏移場信息對圖像進行空間變換,完成彎曲矯正
- 邊緣填充
- 使用Inpainting技術對矯正后的圖像進行邊緣填充

圖像文檔干擾去除算法
- 文檔圖像預處理
- 使用U2net卷積網絡進行背景提取
- 通過信息融合和干擾去除模塊去除摩爾紋、光照影響等干擾
- 干擾去除算法效果
- 可以有效去除手指、陰影等干擾,提高文檔圖像的質量
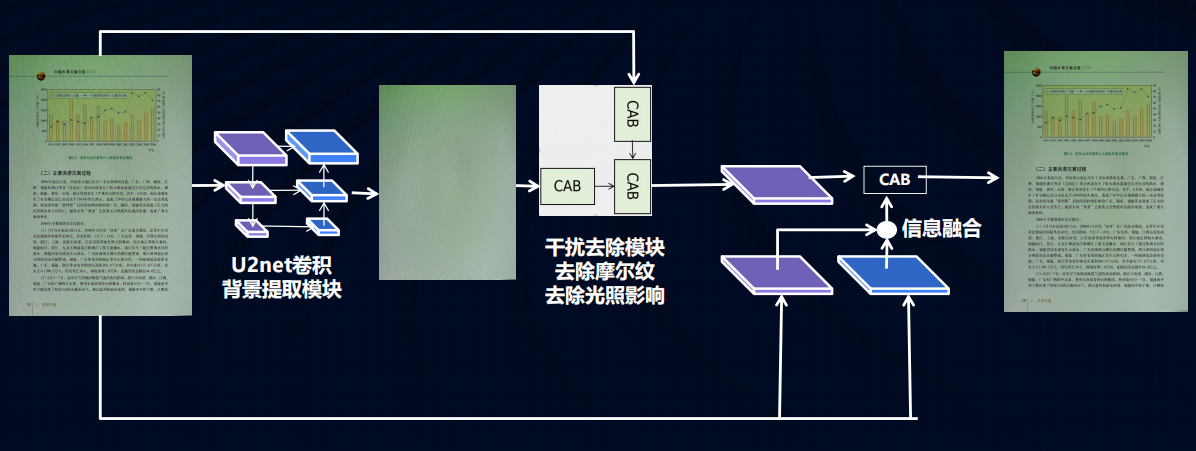
文檔圖像預處理算法整體效果如下

版面分析算法框架

物理版面分析 - 文檔布局分析
- 使用基于回歸的單階段檢測模型,如FasterRCNN、YOLO等,對文檔中的各種布局元素進行檢測和定位。
- 檢測模型可以對文檔中的欄(column)、節(section)等布局要素進行識別。
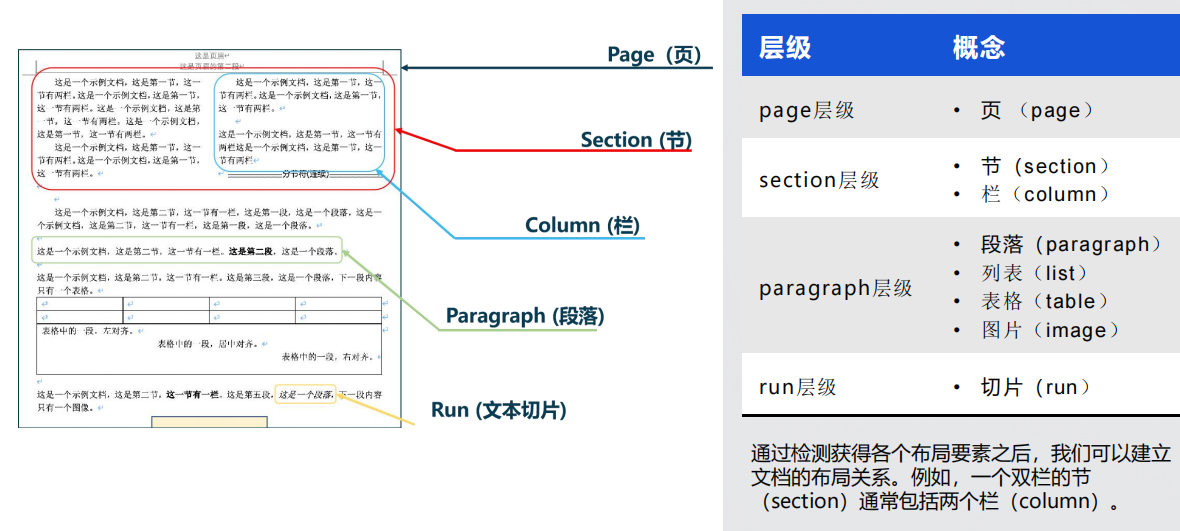
邏輯版面分析 - 語義結構分析
邏輯版面分析算法主要關注文檔的語義結構和布局關系,通過建立層級概念和建模布局關系,實現對文檔邏輯結構的分析和理解。將不同的文字塊根據語義關系建模,形成文檔的層次結構,如頁(page)、段落(paragraph)、列表(list)等。
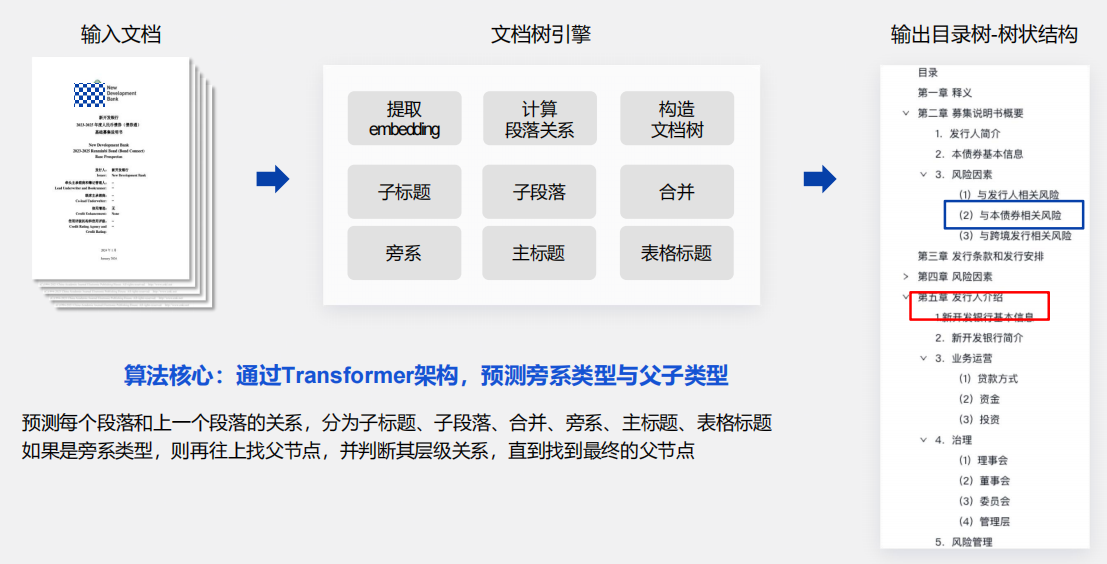
版面分析算法的發展
合合信息在近期的研究發現,真實世界的文檔布局類型非常豐富,無法簡單地用單欄、雙欄等類別來定義。
例如下面列舉的,目錄,報紙,試卷等。所以判別式的技術路線,可以處理好大部分的文檔,還無法真正對真實世界中各式各樣的文檔進行良好的版面分析。

近年來的開放詞匯目標檢測(OVD),視覺語義對齊(Alignment)等工作,以及生成式模型等前沿進展,都會給版面分析帶來新的研究思路。
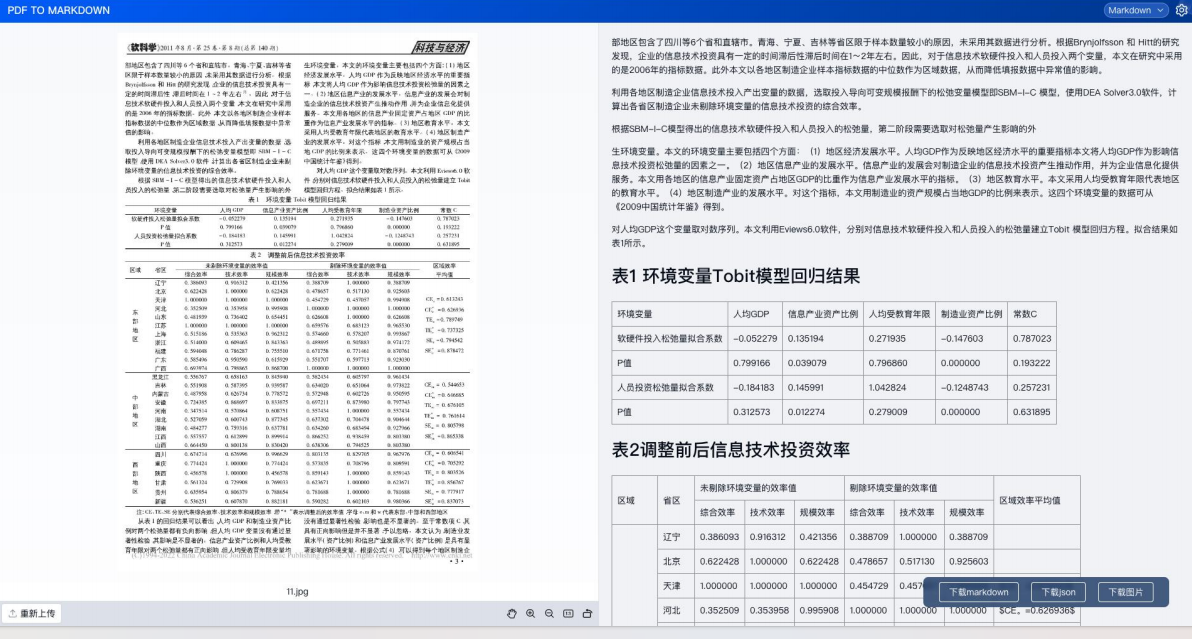
Textln 文檔解析效果

總結
常揚老師在CCIG 2024大會上的演講深入探討了合合信息在文檔解析技術方面的突破性進展。這些技術不僅解決了大模型訓練和應用中的諸多挑戰,還大大提升了文檔解析的效率和精度。通過先進的圖像預處理、版面分析和語義結構分析,合合信息為大模型在文檔問答、知識庫問答等應用場景中的表現提供了堅實的技術支持。期待這些創新技術能夠為未來的研究和產業應用帶來更多可能性。


)
















