數據庫用的pgsql,在表數據超過100w條的時候執行定時任務進行了分表,分表后表名命名為原的表名后面拼接時間,如原表名是card_device_trajectory_info,分表后拼接時間后得到card_device_trajectory_info_20240503,然后分表后把原來的表重置為空。這樣就把100w條數據放到了card_device_trajectory_info_20240503里面,card_device_trajectory_info重置空,以此類推。但是我在java業務代碼中,我想查詢之前的那條數據就查不到了,要怎么關聯上之前分出去的表去查詢呢?
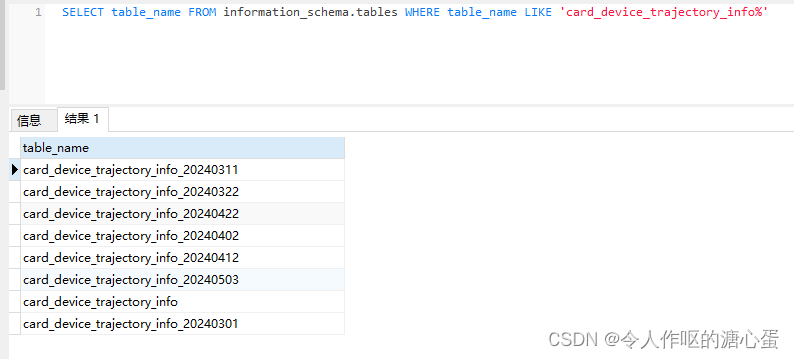
首先,我們要獲取到表名,因為表名是不明確的,所以要通過模糊查詢的方式獲取表名
可以用List<String>去存儲表明,然后獲取列表的大小去做一個循環,從每一張表中查詢,直到循環結束。但是這種方式極可能影響性能消耗,所以。。。
下面是代碼示例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;public class Main {public static void main(String[] args) {String baseTableName = "card_device_trajectory_info"; // 基礎表名String url = "jdbc:postgresql://localhost:5432/your_database";String user = "your_username";String password = "your_password";try (Connection conn = DriverManager.getConnection(url, user, password);Statement stmt = conn.createStatement()) {String sql = "SELECT table_name FROM information_schema.tables WHERE table_name LIKE '" + baseTableName + "%'";ResultSet rs = stmt.executeQuery(sql);// 處理查詢結果,獲取所有分表名稱while (rs.next()) {String tableName = rs.getString("table_name");// 根據業務邏輯處理分表名稱,比如存入集合或者數組中}// 根據業務邏輯構建查詢語句來查詢特定的分表for (String tableName : yourTableCollection) { // 替換yourTableCollection為你保存分表名稱的集合或數組String querySql = "SELECT * FROM " + tableName + " WHERE your_condition_here";// 執行查詢操作并處理結果}} catch (SQLException e) {e.printStackTrace();}}
}如果數據量很大且分表很多,那么逐個查詢并遍歷所有分表的方式可能會影響性能并消耗大量時間和資源。針對這種情況,可以考慮以下一些優化方案來減少性能消耗:
- 分頁查詢:可以考慮對每張分表進行分頁查詢,以減少單次查詢返回的數據量,從而降低查詢的性能消耗。
- 并發查詢:可以考慮使用多線程或異步方式,并發地查詢多張分表,以縮短整體查詢所需的時間。
- 數據預處理:如果業務允許,可以考慮在數據寫入時進行預處理,將需要頻繁查詢的數據進行匯總或者合并存儲,以減少查詢時的分表數量和數據量。
- 數據庫分區:考慮根據業務需求對數據庫進行分區,將數據分散存儲到不同的物理存儲中,從而減少單個查詢涉及的數據量。
- 數據緩存:對查詢結果進行緩存,避免重復查詢相同的數據,提高查詢效率。




)




)

)
)

`函數)



.newInstance())
