Trie,又稱前綴樹或字典樹,是一種有序樹,用于保存關聯數組,其中的鍵通常是字符串。
目錄
前言?
一、Trie字符串統計?
二、算法思路?
1.Trie樹定義🌙
2.變量解釋🌙
3.插入操作🌙
4.Trie樹查找操作?🌙
三、代碼如下?
1.代碼如下:🌙
2.讀入數據🌙
3.代碼運行結果🌙
?4.運行結果解釋🌙
總結?
前言?
Trie,又稱前綴樹或字典樹,是一種有序樹,用于保存關聯數組,其中的鍵通常是字符串。
提示:以下是本篇文章正文內容,下面案例可供參考
一、Trie字符串統計?
維護一個字符串集合,支持兩種操作:
I x?向集合中插入一個字符串?x;Q x?詢問一個字符串在集合中出現了多少次。
共有?N?個操作,所有輸入的字符串總長度不超過?100000,字符串僅包含小寫英文字母。
輸入格式
第一行包含整數?N,表示操作數。
接下來?N行,每行包含一個操作指令,指令為?I x?或?Q x?中的一種。
輸出格式
對于每個詢問指令?Q x,都要輸出一個整數作為結果,表示?x?在集合中出現的次數。
每個結果占一行。
數據范圍
1≤N≤2?10000
二、算法思路?
1.Trie樹定義🌙
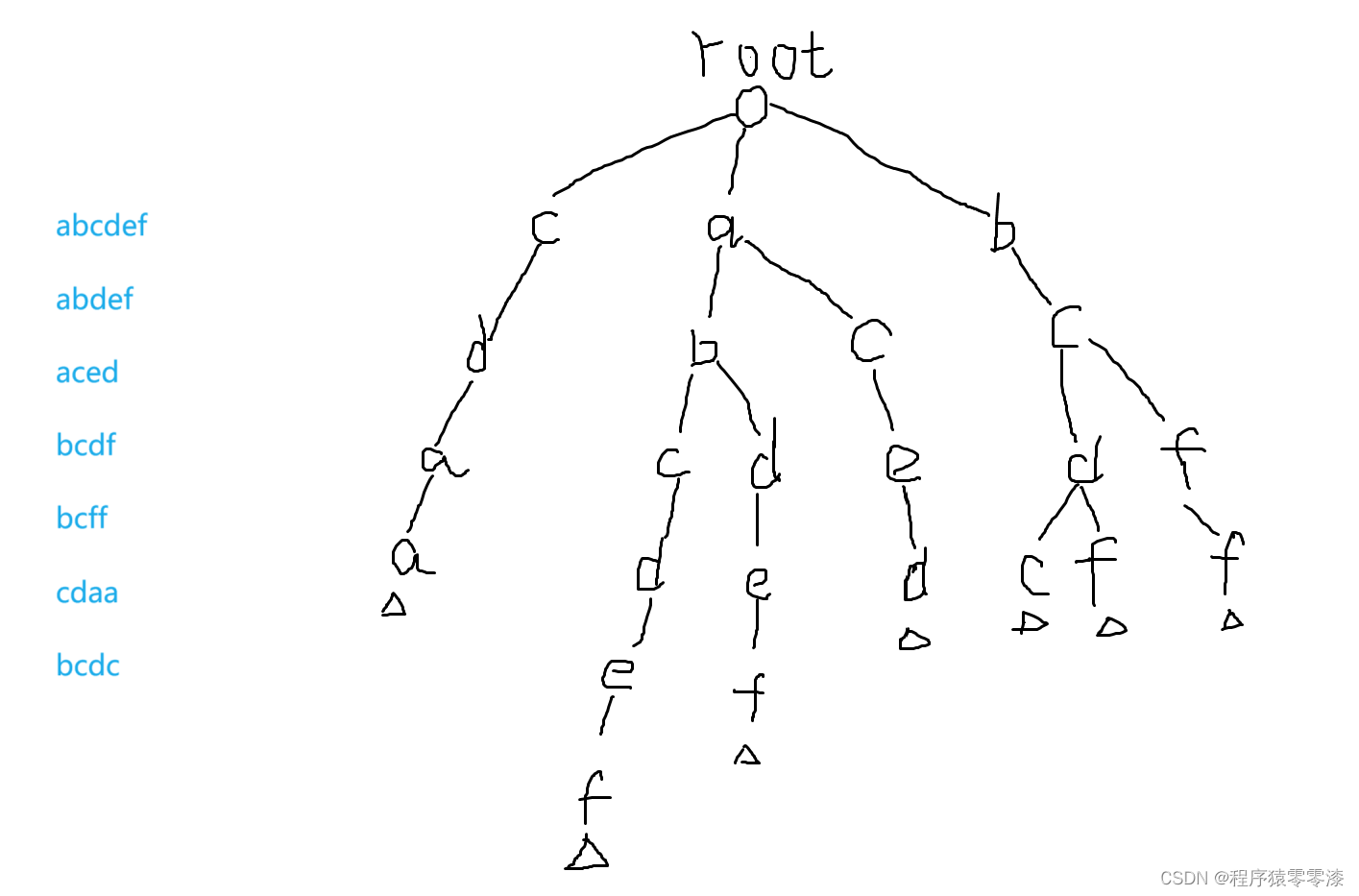
圖1.1Trie樹示例?
?Trie,又稱前綴樹或字典樹,是一種有序樹,用于保存關聯數組,其中的鍵通常是字符串。
Trie樹是用來高效的存儲和查找字符串的集合的數據結構。
基本性質:
1、根節點不包含字符,除根節點意外每個節點只包含一個字符。
2、從根節點到某一個節點,路徑上經過的字符連接起來,為該節點對應的字符串。
3、每個節點的所有子節點包含的字符串不相同。
圖1.1中我們用trie樹存儲了abcdef、abdef、aced、bcdf、bcff、cdaa、bcdc字符串。
我們會在一個單詞的結尾來做一個標記,來表示到這里有一個完整的單詞。
2.變量解釋🌙
我們引入整型變量N為100010,用來表示樹深最高100000個結;然后有因為字符串中只有小寫字母,那么一個結點最多有26個分支,那么我們用一個二維整型數組son來存儲,共有N行26列;用一維整型數組cnt來存儲以某節點結束的字符串的個數,同時起到字符串結束的作用,引入一個整型變量index,初始化為0,用來表示空節點。
3.插入操作🌙
插入操作我們按照一個字符串的字母順序第一個字符是根節點的分支,然后下一個字母是上一個字母的分支,直到單詞的結束;遇到相同前綴的單詞在相同單詞的前綴后的不同分支接著串連字母,當然每個單詞的最后一個字母都會有一個結束標志。具體模擬過程可以看圖1.1.
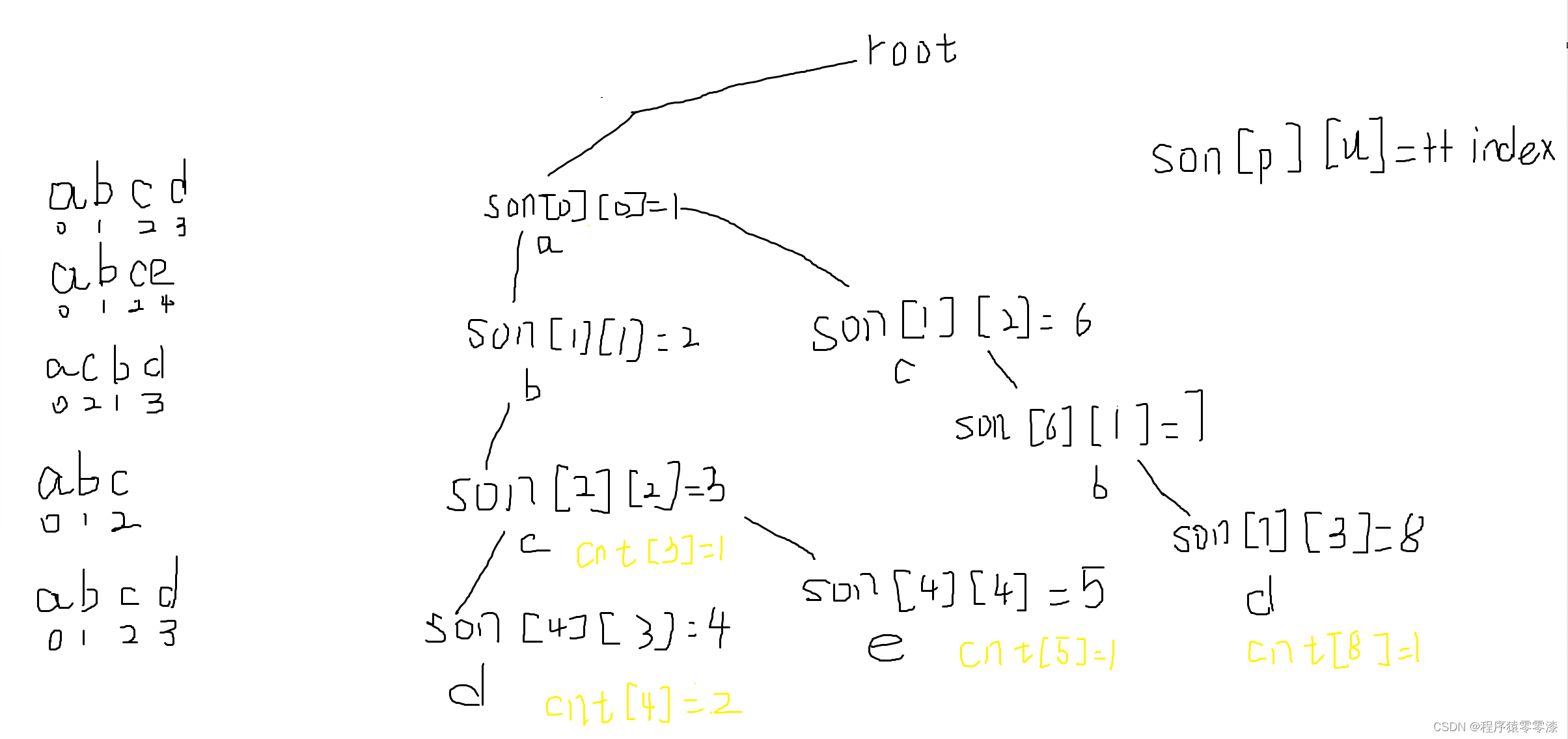
圖3.1模擬過程
對于一個字符串str,獲取對應的字符數組arr,建立一個整型變量p初始化為0,相當于一個指針變量指向當前節點,我們遍歷每個字符arr[i]?,然后用u = arr[i] - 'a',將每個字符轉換成數字關系,當該字符未被放入Trie樹中時即(son[p][u] == 0),將son[p][u] = ++index;意思是當該節點不存在的時候,我們創建出來,然后數組中的值是下一個節點的位置;然后將當前節點的指針p指向下一個節點的位置即 p = son[p][u];當該字符串的所有字符遍歷結束后,將cnt[p]++;此時p的值就是當前節點的位置,還因為index的值是隨著我們沒新創建一個節點增加的,是唯一的,它可以用來表示字符串結束的標識。
public static void insert(String str){char[] arr = str.toCharArray();int p = 0;for(int i = 0;i < arr.length;i++){int u = arr[i] - 'a';//字符不在Trie樹中if(son[p][u] == 0){//創建一個節點,數組中的值為下一個節點的位置son[p][u] = ++index;}//使指針指向下一個節點的位置p = son[p][u];}//結束時標記,記錄以此節點為結尾的字符串的個數cnt[p]++;}4.Trie樹查找操作?🌙
我們還用圖1.1來看,當我們查找字符串acf的時候。從root-> a -> c - > e,此時a的后面沒有f,就說明Trie樹中不存在acf字符串;當我們字符串cda的時候,從root - > c - > d - > a,但是字符a沒有單詞結束標志,那么說明Trie樹中同樣也沒有字符串cda。
我們傳入一個字符串str,然后利用對應的字符數組arr,建立一個整型變量p初始化為0,相當于一個指針變量指向當前節點,我們遍歷每個字符arr[i]?,然后用u = arr[i] - 'a',將每個字符轉換成數字關系,當我們發現該字符不在Trie樹中時即son[p][u] == 0,即該字符串不存在直接返回0即可;當該字符存在,那么就將p指針指向該節點的下一個節點位置 p = son[p][u],將該字符數組遍歷完畢后,最后返回該字符串的個數就是以最后一個節點的位置對應的cnt數組中的值即cnt[p]。
public static int query(String str){char[] arr = str.toCharArray();int p = 0;for(int i = 0;i < arr.length;i++){int u = arr[i] - 'a';//不存在if(son[p][u] == 0){return 0;}p = son[p][u];}//返回字符串出現的次數return cnt[p];}三、代碼如下?
1.代碼如下:🌙
import java.io.*;
import java.util.*;public class Trie字符串統計 {static PrintWriter pw = new PrintWriter(new OutputStreamWriter(System.out));static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));//一個字符串最多100000個字符static int N = 100010;//存儲子節點后面的分支,因為只有小寫字母,故只有26個分支static int[][] son = new int[N][26];//存儲以某節點結束的字符串的個數,同時起到字符串結束的標志作用static int[] cnt = new int[N];//下標是0的點既是根節點static int index = 0;public static void main(String[] args) throws Exception {Scanner sc = new Scanner(br);int m = sc.nextInt();while (m-- > 0){String cmd = sc.next();String str = sc.next();if (cmd.equals("I")){insert(str);}else if (cmd.equals("Q")){pw.println(query(str));}}pw.flush();}public static void insert(String str){char[] arr = str.toCharArray();int p = 0;for(int i = 0;i < arr.length;i++){int u = arr[i] - 'a';//字符不在Trie樹中if(son[p][u] == 0){//創建一個節點,數組中的值為下一個節點的位置son[p][u] = ++index;}//使指針指向下一個節點的位置p = son[p][u];}//結束時標記,記錄以此節點為結尾的字符串的個數cnt[p]++;}public static int query(String str){char[] arr = str.toCharArray();int p = 0;for(int i = 0;i < arr.length;i++){int u = arr[i] - 'a';//不存在if(son[p][u] == 0){return 0;}p = son[p][u];}//返回字符串出現的次數return cnt[p];}
}
2.讀入數據🌙
5
I abc
Q abc
Q ab
I ab
Q ab3.代碼運行結果🌙
1
0
1?4.運行結果解釋🌙
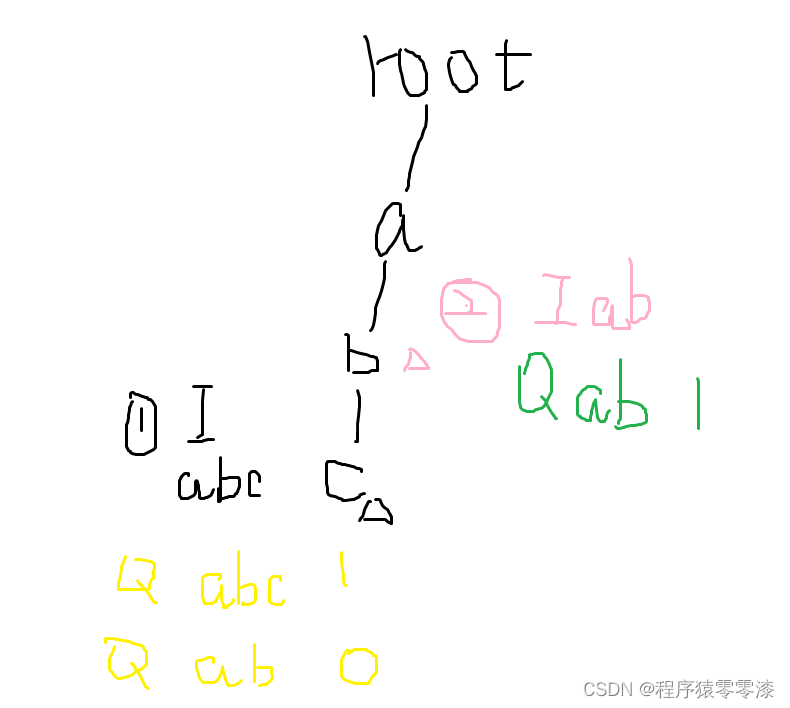
圖4.1?
插入abc后查詢abc為1;查詢ab不存在為0;?插入ab;查詢ab存在為1。
總結?
主要了解Trie樹的構造性質后,直到如何插入字符串,如何查詢字符串;了解代碼中各個變量的含義,直到每一步是干什么,可以跟著圖示自己手動模擬一下,體驗一下過程,加深自己的理解。


)

)
)

`函數)



.newInstance())







