【class17】
上節課,我們學習了:?????? ?語音端點檢測的相關概念,并通過代碼切分和保存了音頻。
本節課,我們將學習這些知識點:
1.?序列到序列模型
2.?循環神經網絡
3.?調用短語音識別接口
?????????????????????? 
知其然,知其所以然
在調用語音識別接口前,我們先來學習語音識別系統最核心的部分:強大的黑盒子——語音識別模型。
通過學習黑盒子的內部,幫助我們進一步了解語音識別的前因后果。
強大的黑盒子
在一個典型的深度學習語音識別系統中,其模型由兩部分組成:
1.編碼器?????????????????????????????????????????????????????? 2.解碼器
?????????? 
編碼和譯碼的目的
1.為了對輸入數據進行分析并編寫成機器能夠處理的信息,就需要編碼。
2.為了將編碼器編寫的信息翻譯成人類理解的信息,就需要譯碼。
????????? 通俗的說,編碼器就是讓機器讀得懂,解碼器就是讓人讀的懂。
編碼器解碼器模型又叫做seq2seq模型——序列到序列模型。序列到序列也就是說,輸入和輸出都是序列。
序列到序列模型
定義
序列到序列模型(seq2seq )包括編碼器 (Encoder) 和解碼器 (Decoder) 兩部分。
seq2seq 是自然語言處理中的一種重要模型,可以用于語音識別、機器翻譯、對話系統以及自動文摘等。
隱喻
把這個過程想象成諜戰片里的情報截獲和翻譯,編碼器為敵方,解碼器為我方。我方情報員截獲了敵方編碼好的情報,為了讀懂情報,就需要進行解碼。
語音識別的輸入和輸出都是不定長序列,換句話說,就是每次輸入的語音和輸出的文字長度不定。比如,時長不一樣的語音,采樣后所得的數字序列是不一樣長的。
像語音識別這種輸入輸出都是不定長序列時,我們就使用seq2seq模型。
seq2seq模型由編碼器和解碼器組成,而編碼器和解碼器都是利用了循環神經網絡 — RNN來實現的。基本思想就是利用兩個RNN,一個RNN作為編碼器,另一個RNN作為解碼器。
循環神經網絡
定義
循環神經網絡 (Recurrent Neural Network,RNN) 是一類用于處理序列數據的神經網絡。在近些年,人們利用RNN解決了各種各樣的問題:語音識別、語言模型、機器翻譯和圖像描述等。
對于序列數據來說,順序排列非常重要! 比如,這樣一句話「我要給手( )充電」。 我們就可以根據前后文字猜測,( )可能是機、表等單字。
??????????????????????? 
當話變成「電充( )手要我」時,( )里該填什么?是不是滿臉問號???顯然,針對有關于序列的問題,我們需要一個神經網絡來進行專門的處理。于是RNN出來了。
????????????????????????????? 
在學習RNN結構之前,我們看其他網絡(如CNN)是如何處理數據的:每個網絡處理數據是單獨進行的。
每個數據通過隱含層(A)處理,都會得到一個對應的結果。
???????????????????????? 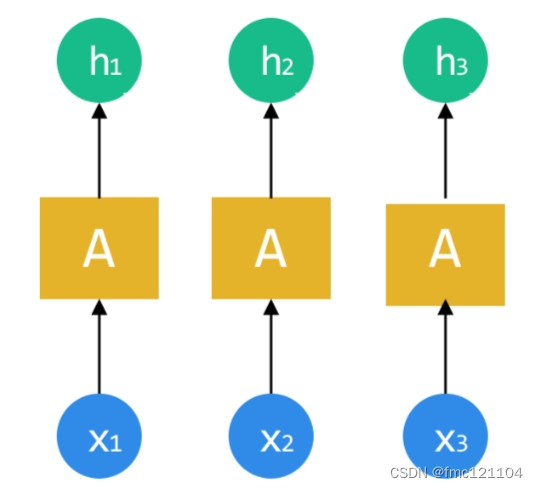
如果待處理的數據之間(x1、x2、x3)有關聯順序,也就是為序列數據時:對于神經網絡來說,并沒有辦法知道數據之間的關聯。怎么讓網絡知道這些數據順序關聯,比如圖中的護膚順序,并能進一步分析呢?
科學家們腦袋一轉,不怕不怕,我們把前一個網絡的中間狀態作為后一個的輸入就好啦!這樣就能形成一個所有記憶循環分析的網絡,處理序列數據剛剛好!
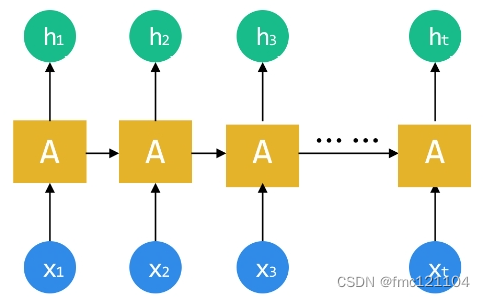
RNN結構
循環神經網絡和卷積神經網絡一樣,它包含三個結構:
1.?輸入層????????????????? 2.?隱含層?????????????????????????? 3.?輸出層

為了更好理解,將RNN按照序列順序將其展開:
RNN 的順序鏈式結構讓它看起來就像是為序列數據而生!(圖中的輸入x1-xt就可以是我們采樣所得的序列數據)

輸入層、輸出層比較容易理解。
在語音識別中,輸入層輸入的是語音,輸出層輸出的是識別結果。
那么,隱含層呢?
循環神經網絡的隱含層前后順序相連,前后相互依賴,前一個的輸出為后一個的輸入。 這與語音的前一個字依賴后一個字或者前一句話依賴后一句話非常契合。
RNN VS? CNN
RNN 與CNN相比,RNN的特別之處在于:
1. 處理序列數據效果好
2. 允許控制輸入或輸出向量序列的長度
第1點我們已經學習了,接下來,我們通過兩個結構模型來理解第2點。
???????????????????????????? 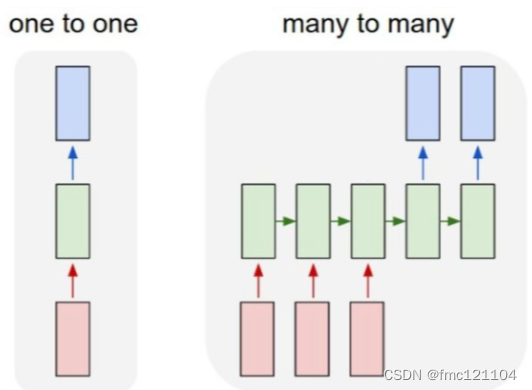
CNN:
1->1?結構,固定長的輸入和輸出 (應用:比如圖像分類)
???????????????????????????????????? RNN
N->M?結構,不定長的序列輸入和序列輸出 (應用:比如語音識別)
seq2seq模型輸入輸出序列的長度是不固定的,對應的就是N->M結構。
學習完seq2seq模型與RNN的原理和概念之后,該如何實現語音識別呢?接下來,我們完成“調用接口實現語音識別”的第一步——單段音頻的語音識別。
通過代碼調用短語音識別接口,實現對單段音頻文件的語音識別。
讓我們一起嘗試一下吧~
1. 首先,我們開始打開并讀取音頻。
使用?with...as?配合open()函數以rb 方式,打開路徑為filePath的音頻,并賦值給 fp;
使用read()函數讀取音頻,輸出結果為二進制的編碼數據。
代碼示例:
調用短語音識別接口
代碼的作用
利用短語音識別接口,對一段音頻文件識別,返回值為字典類型。
第20行,通過asr接口識別輸入的音頻wavsample,并將結果存儲在rejson變量中。

分析代碼:
語音識別客戶端
使用變量client,即創建好的語音識別客戶端,可對其調用。
短語音識別接口
對創建的AipSpeech客戶端,使用asr()函數調用短語音識別接口。
注意:該接口只能將60秒以下的音頻識別為文字,若音頻時長超過限制,可切分為多段音頻進行識別。
待識別語音
必選參數wavsample,語音內容的Buffer對象,文件格式支持pcm 或者 wav 或者 amr。
文件格式
必選參數,傳入字符串"wav"設置音頻文件格式為wav文件。
采樣率
必選參數,傳入參數16000聲明音頻文件的采樣率為16000Hz。常用的音頻采樣率有:8000Hz、16000Hz和32000Hz等。
可選參數
asr()函數中傳入可選參數{"dev_pid": 參數}設置待識別音頻的語音類型。
參數為1537表示可識別的語言:普通話(純中文識別)。
其余參數和解釋如下:
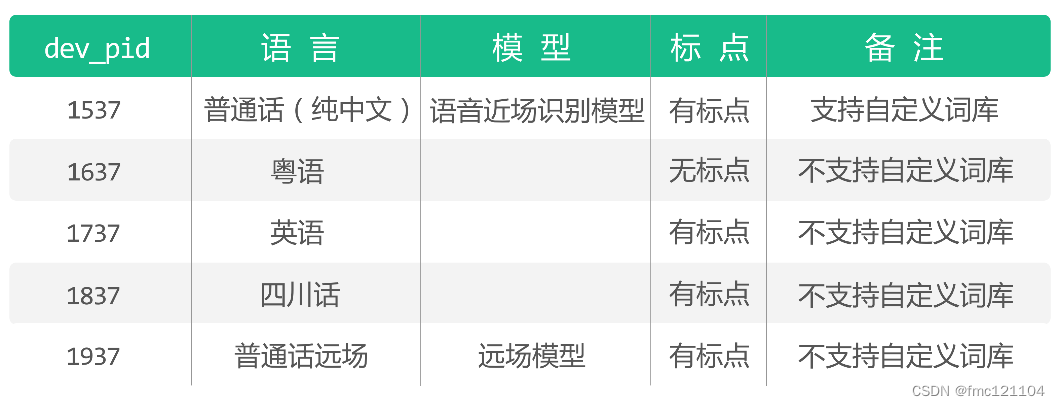
總結:
調用接口----使用asr()函數調用短語音識別接口。將待識別的音頻必選參數wavsample,"wav",16000傳入到該函數中。輸出調用接口返回的結果rejson。
????????????????? 
從輸出結果可以看到,調用接口返回的是一個字典。 該字典包含多個參數:
corpus_no:語料庫碼????????????????? err_msg:錯誤碼描述???????????????????????? err_no:錯誤碼
result:識別結果??????????????????????? sn:語音數據唯一標識
成功返回
成功返回時rejson字典中的參數err_msg和err_no內容為:
1.?err_msg:錯誤碼描述,rejson["err_msg"]為"success."
2.?err_no:錯誤碼,rejson["err_no"]為0
成功返回時rejson字典中的參數result為列表結構:rejson["result"]中保存了單段音頻語音識別的文字信息。
獲取識別結果
查看輸出結果,我們從rejson字典中的鍵result就能得到識別結果。
調用接口返回的是一個復雜的字典結構,我們將它賦值給了變量rejson。
從字典rejson中取出參數"result"的值,可以用rejson["result"];
再從rejson["result"]中取出列表內的元素,可以用rejson["result"][0]。
代碼示例:
# 獲取語音識別結果
# 從返回結果中提取出參數result中的唯一值并賦值給變量msg
msg = rejson["result"][0]
完善代碼:
-
- if-else語句判定
使用if-else語句,若錯誤碼為0,則得到語音識別結果;否則給出"語音識別錯誤!"提示。
以防出現語音識別無結果或者出現其他錯誤情況,而導致代碼報錯不能正常運行!
- if-else語句判定
代碼:
# if—else語句判定
# 若錯誤碼為0,則得到語音識別結果
if rejson["err_no"] == 0:
??? # 獲取語音識別結果
??? # 從返回結果中提取出參數result中的唯一值并賦值給變量msg
??? msg = rejson["result"][0]
# 否則給出"語音識別錯誤!"提示
else:
msg = "語音識別錯誤!"
-
- 語音識別函數
將調用接口實現語音識別封裝為函數,方便后面的調用。
最后通過參數wavsample調用函數,并輸出結果。
修改后的代碼:
# 定義語音識別函數audio2text()
def audio2text(wav):
??? # 調用短語音識別接口把結果賦值給rejson變量
??? rejson = client.asr(wav,"wav",16000,{"dev_pid": 1537})
??? # if—else語句判定
??? # 若錯誤碼為0,則得到語音識別結果
??? if rejson["err_no"] == 0:
??????? # 獲取語音識別結果
??????? # 從返回結果中提取出參數result中的唯一值并賦值給變量msg
??????? msg = rejson["result"][0]
??? # 否則給出"語音識別錯誤!"提示
??? else:
??????? msg = "語音識別錯誤!"
??? # 返回語音識別結果msg
return msg
調用短語音識別接口實現了單個音頻的語音識別。接下來我們對上節課獲得的音頻片段做批量處理,批量讀取音頻文件,實現多段音頻文件的批量識別。
我們先完成第一步——批量讀取音頻。
代碼復習
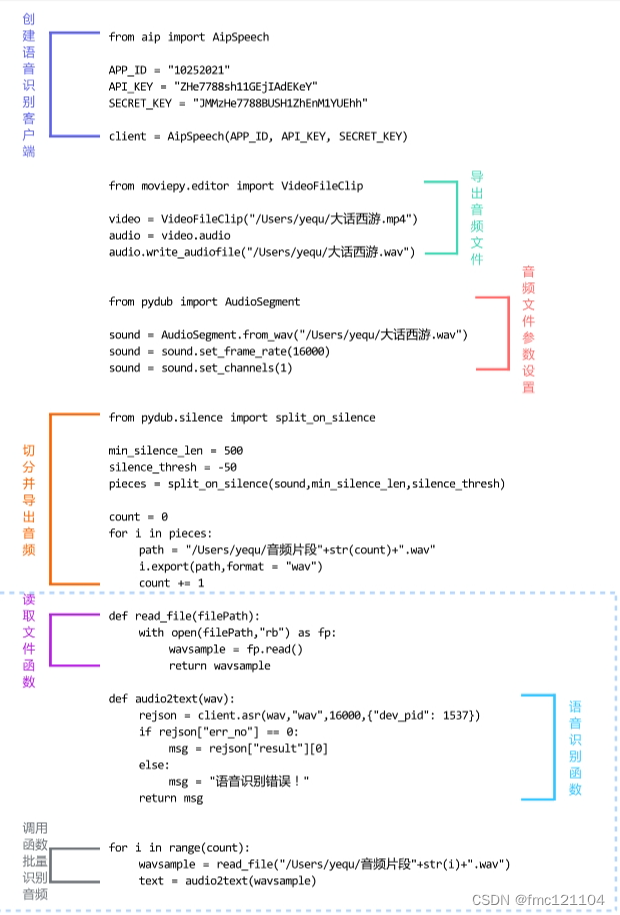
批量處理之前,復習一下前面課程從視頻中獲取音頻文件,并切分和保存為wav文件的完整代碼。
"""獲取音頻文件"""
from moviepy.editor import VideoFileClip
video = VideoFileClip("/Users/yequ/大話西游.mp4")
audio = video.audio
audio.write_audiofile("/Users/yequ/大話西游.wav")
"""音頻文件參數設置"""
from pydub import AudioSegment
sound = AudioSegment.from_wav("/Users/yequ/大話西游.wav")
sound = sound.set_frame_rate(16000)
sound = sound.set_channels(1)
"""切分音頻"""
from pydub.silence import split_on_silence
min_silence_len = 500
silence_thresh = -50
pieces = split_on_silence(sound,min_silence_len,silence_thresh)
"""導出音頻片段"""
count = 0
for i in pieces:
??? path = "/Users/yequ/音頻片段"+str(count)+".wav"
??? i.export(path,format = "wav")
count += 1
step1.批量讀取音頻
將文件讀取部分代碼封裝為函數:定義文件讀取函數read_file(),傳入參數文件地址filePath,返回音頻對象wavsample。
再通過for循環批量讀取切分完的音頻文件,共12個音頻文件,循環范圍為0-11,即range(count)。
代碼:
# 定義文件讀取函數read_file(),傳入參數文件地址filePath
def read_file(filePath):
??? # 使用 with...as 配合open函數以rb 方式,打開路徑為filePath的音頻
??? with open(filePath,"rb") as fp:
??????? # 使用read()函數讀取音頻賦值給wavsample
??????? wavsample = fp.read()
??????? # 返回音頻對象
??????? return wavsample
# 通過for循環批量讀取切分完的音頻文件
for i in range(count):##
??? wavsample = read_file("/Users/yequ/音頻片段"+str(i)+".wav")
??? # 輸出查看wavsample結果
print(wavsample)
step2批量讀取完音頻之后:
我們將實現“多段音頻文件的批量識別”的第二步——批量調用接口識別音頻。
批量調用接口識別音頻:在for循環結果的循環體內,調用語音識別函數audio2text(),獲取語音識別結果,并輸出識別結果,實現批量調用接口識別音頻。
代碼:
# 通過for循環調用批量讀取切分完的音頻文件
for i in range(count):
??? # 調用文件讀取函數read_file(),讀取所有音頻片段文件
??? wavsample = read_file("/Users/yequ/音頻片段"+str(i)+".wav")
??? # 調用語音識別函數audio2text(),獲取語音識別結果
??? text = audio2text(wavsample)
??? # 輸出查看text
print(text)
代碼整理
將今日學習的代碼分為三個部分:
part1. 讀取文件函數
part2. 語音識別函數
part3. 調用函數批量識別音頻
本節課,我們學習了語音識別模型的結構和原理,同時調用創建好的AipSpeech客戶端實現了語音轉文字功能。
下節課,我們將學習視頻文件字幕格式,并通過代碼生成標準格式字幕文件。

)
)

`函數)



.newInstance())










