論文title:https://arxiv.org/pdf/2205.12035RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder
論文鏈接:https://arxiv.org/pdf/2205.12035
摘要
1.一種新的MAE工作流,編碼器和解器輸入進行了不同的掩碼。編碼器編碼的句子向量和解碼器的掩碼輸入通過語言模型進行重構問句。
2.非對稱的模型結構,編碼器擁有像BERT一樣全尺寸的transformer,解碼器只有一層的transformer。
3.非對稱的掩碼比例,編碼器:15%-30%,解碼器:50%-70%。
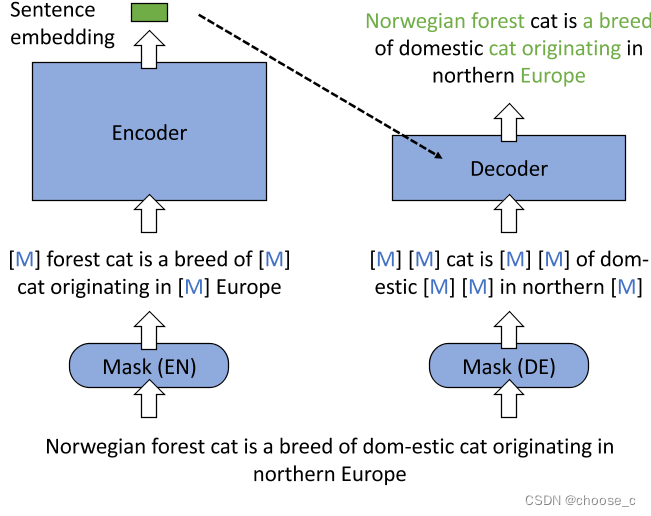
retroMAE這樣設計的原因:
1.auto-encoding對于編碼質量的要求更高,傳統的自回歸更關注前綴,傳統的MLM只掩蓋一小部(15%)的輸入。retroMAE掩蓋了更多的輸入用于解碼,因此重構不僅依賴解碼器的輸入,更加取決于句子嵌入,所以它迫使編碼器捕捉更深層次的句子語義。
2.保證了訓練信號來自于大多數的句子輸入。另外解碼器只有一層transformer,所以使用了雙流注意力和特定位置注意掩碼的增強解碼。這樣所有token都被用于了重建。
方法
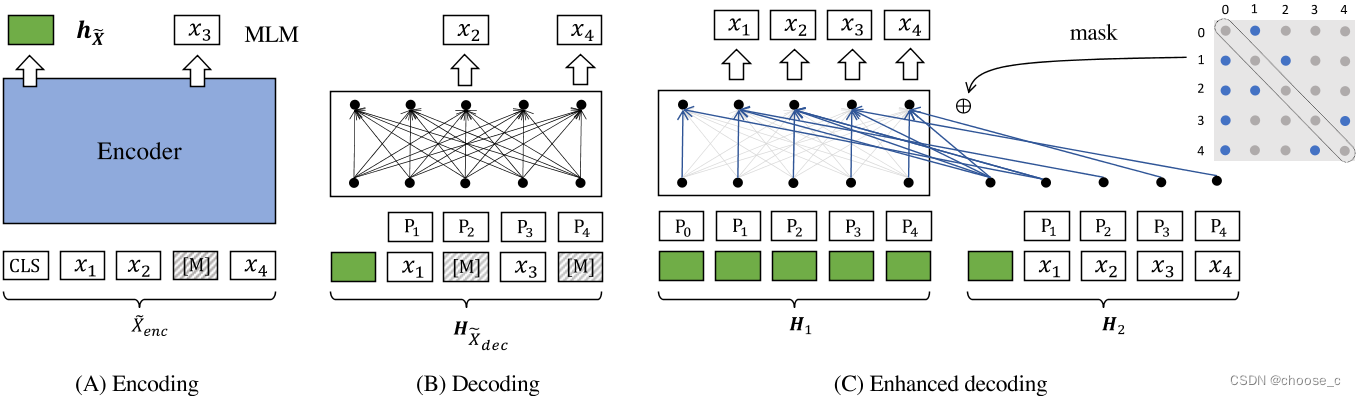
編碼器
? ? ? ? 編碼器使用像bert一樣12層transformer和768維度的向量輸出,能夠很好地捕捉句子的深層語義。問句輸入中token的掩碼比例為15%-30%,最終使用 [CLS]token的向量作為句子的嵌入表示。
解碼器
? ? ? ? 解碼器的結構為一層transformer,它的句子輸入中token的掩碼比例為50%-70%,會將編碼器生成的嵌入向量和掩碼token(位置編碼)連接輸入解碼器。由于解碼器的transformer層數較淺,句子掩碼比例又高,所以重構任務更加依賴于編碼器生成高質量的嵌入向量。
增強解碼
????????解碼過程的一個限制是訓練信號,即交叉熵損失,只能從掩碼標記導出。此外,每個掩碼標記總是基于相同的上下文重構。所以解碼增強希望1.從句子中獲得更多的訓練信號。2.重建任務可以基于更多樣的上下文。所以提出了雙流注意力和特定位置注意掩碼的增強解碼。
(100分))



)














