個人博客
Java GC問題排查的一些個人總結和問題復盤 | iwts’s blog
是否存在GC問題判斷指標
有的比較明顯,比如發布上線后內存直接就起飛了,這種也是比較好排查的,也是最多的。如果單純從優化角度,看當前應用是否需要優化,有一些指標判斷:
- 延遲(Latency):也可以理解為最大停頓時間,即STW最長時間。
- 吞吐量(Throughput):例如系統運行了 100 min,GC 耗時 1 min,則系統吞吐量為 99%。
兩者是結合的,延遲越低越好,而吞吐量一般有各個業務指標,例如TP999,即99.9%的吞吐量,TP9999則是99.99%。
一般來說尤其是技術還不錯的大廠,除了發布是很難碰到相關問題的。。尤其是阿里這種比較卷比的,早就優化甚至為了ppt而優化給整完了,確實沒啥優化空間。
包括JVM在內,這種東西能不碰就不碰,真的性價比不高。不過日常代碼還是要注意,比如內存泄露這種代碼就別寫出來了。
這里主要還是聊聊如果真碰到了問題,或者性能不是很行,想要分析是否是GC的話,有一些我個人工作的經驗總結以及之前看到的解決方案的分析。
通用排查流程
GC日志分析
有一些網站,dump下來GC日志后上傳上去,各種可視化信息。例如:Universal JVM GC analyzer - Java Garbage collection log analysis made easy
分析JVM內存配置
jmap -heap {pid}
先看看JVM啟動參數&各代內存分配情況:


先看看分代參數不合理是否會影響本次GC問題。
堆內存對象大小分析
查看存活對象中的實例數量&具體占用內存大小:
jmap -histo 7276 | head -n20
后面的可以忽略,只看前面一部分就ok。
或者直接>重定向寫到log中,慢慢看。

主要看是否有哪個對象占用量非常的大,遠超過其他對象,如果有,那說明該對象的生成可能是不合理的。
堆文件dump分析
確定有比較異常的對象,才考慮dump下來看。
JProfile之類的比較高端,能直接遠程監控VM,但是需要線上配置。自己負責的業務能線上直接操作,或者基建比較nb已經有相關內部工具,那么可以代替dump。
dump命令:
jmap -dump:format=b,file={文件名} {pid}
然后利用可視化工具裝載,例如JProfile、JVisualVM。JProfile要破解,JDK自帶JVisualVM。
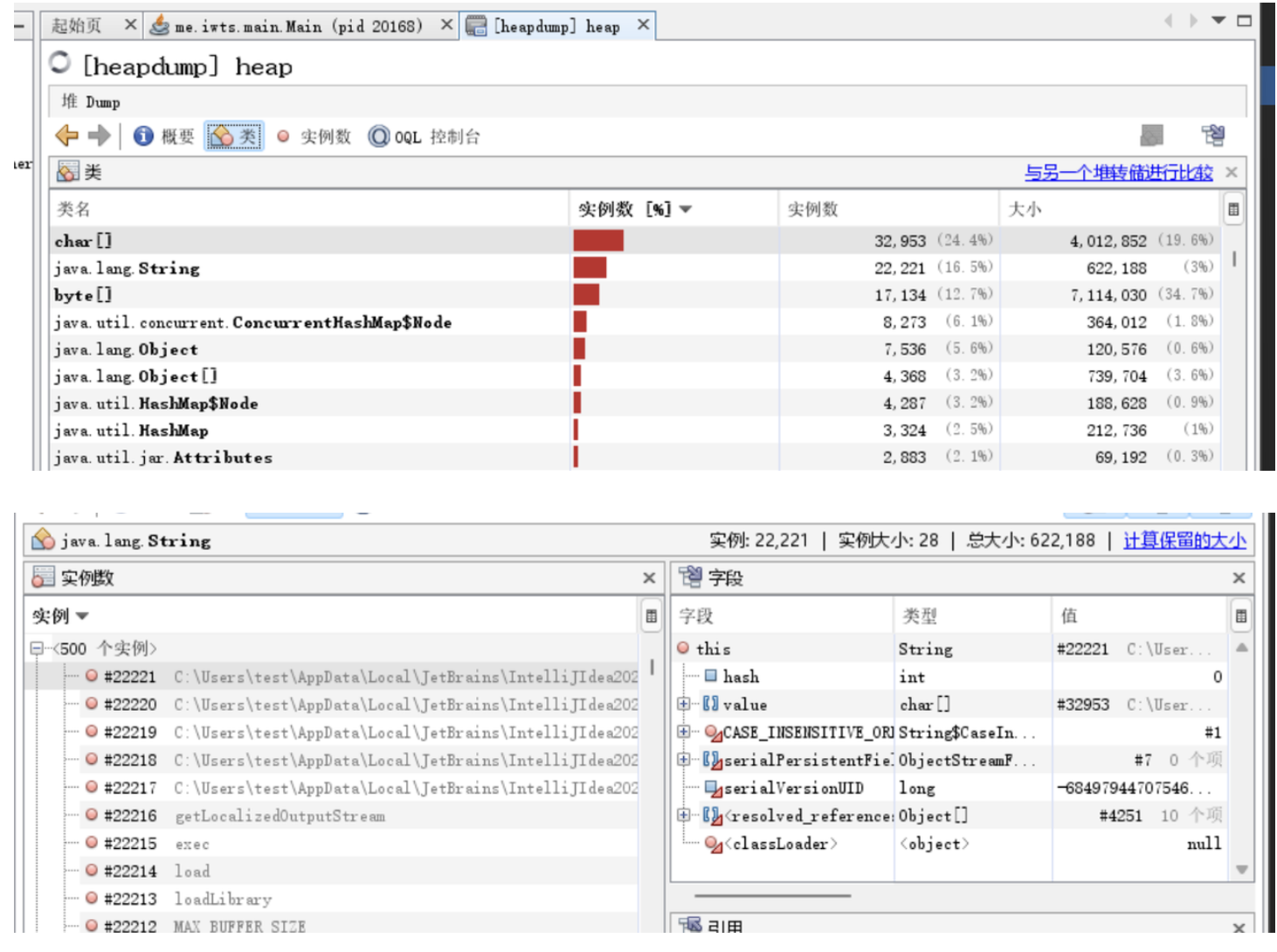
可以具體分析對象到底是哪些實例。
JVisualVM
JDK自帶可視化分析工具。
路徑JAVA_HOME/bin/jvisualvm.exe
Idea可以下載插件:VisualVM,配置后可以直接拉起比較方便。
本質上是監控,但是一般公司基建都不錯,不在乎這種。主要還是快,直接打開exe文件,省的再去JDK下找。
類加載情況
JVM啟動參數,增加內容:
-verbose:class # 查看類加載情況
-verbose:gc # 查看虛擬機中內存回收情況
-verbose:jni # 查看本地方法調用的情況
一般是class,啟動后java -verbose:class,可以看到當前程序的加載情況。
代碼分析
總歸是要回歸代碼的。尤其是上線后導致的問題,更容易排查出問題的到底是在哪,必然是因為上線后更新的代碼導致的。
不管怎么調優,最終還是要回歸代碼的。
頻繁Full GC
內存空間角度
- 先看JVM內存配置,是不是老年代太小,實在沒啥空間,頻繁觸發閾值開啟Full GC。
- 是否有內存泄漏,老年代增長速度非常快,回收后跟沒回收一樣,可能是內存泄漏。
大對象
例如單SQL未分頁,同時刻大對象裝載進入內存,此時由于超過了Eden區大小,會直接裝載進老年代,從而導致Full GC頻繁。
這樣在觀察heap的時候就能看出來,是否會出現某些對象實例少,占用空間大。
內存泄漏
比較經典了,每次Full GC只能回收一點,機器重啟后解決問題。標準的內存泄漏。主要看看IO之類的是不是哪里沒有close。
Minor GC角度
會不會是Minor GC頻率太高導致的。高頻次的Minor GC會導致大量的對象年齡增加以進入老年代。
晉升代數設置不合理-調整代數設置
如果Minor GC的頻率確實這么高,那么考慮是不是晉升代數設置的太低導致的。例如對象A生命周期60秒,Minor GC 10s一次,而晉升代數設置的是3。
那么A對象30s就會晉升一次,導致大量A對象進入老年代。
如果設置成晉升代數為7,那么在60s后,A對象生命周期結束,年齡為6,Minor GC直接清除,不再丟入老年代。
OOM
一般伴隨著Full GC的問題。場景不多,給一些比較常見的。
內存泄漏
同上,一般先是大量Full GC,老年代遲早要被完全填滿的,填滿后就是OOM。
ThreadLocal內存泄漏
比較經典,可以參考:詳解Java ThreadLocal
new大量新類
比較少見,仍然是先高頻率Full GC,最終填滿導致OOM
內存空間不合理
可能有很多,哪個空間都有可能OOM,此時異常一般也說明了是哪個區OOM了,一般很少見,真碰見一般就是非常低的情況。比如之前CRM不知道誰給設置的,Heap 100MB還是多少,Full GC的🐎都不認識,但是最后只有少量OOM。(大對象還是少)
堆外內存泄漏
感覺還是相當少了,之前吃交易P0的瓜,好像是這個問題。
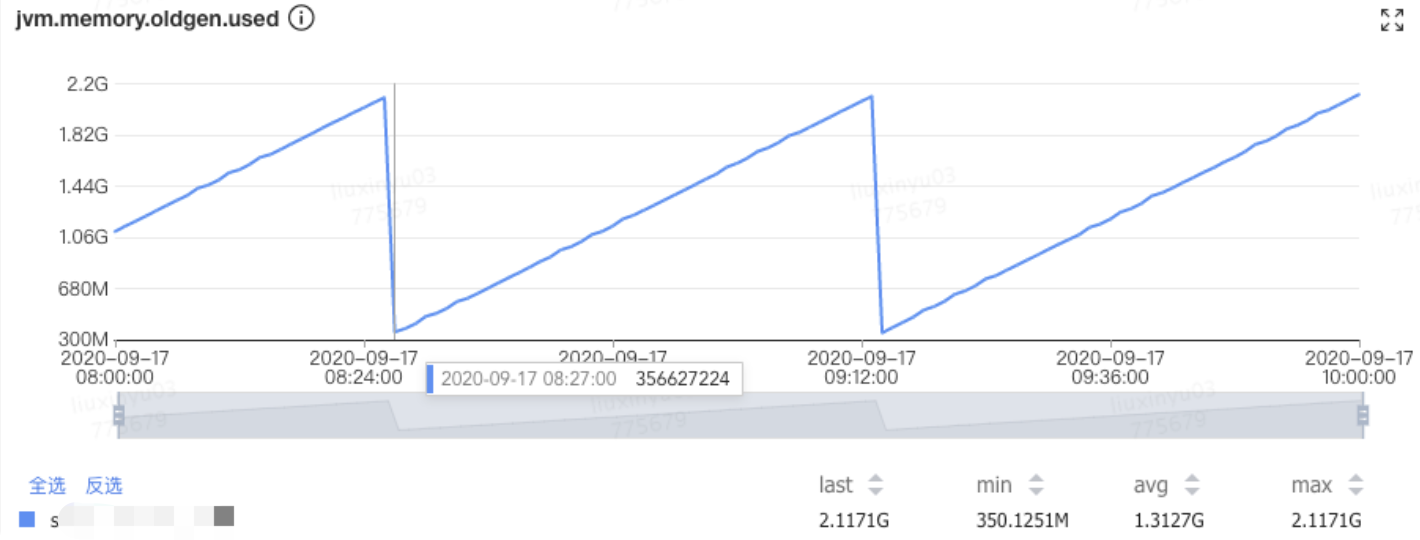
首先回顧以下堆外內存,JVM分為堆和非堆,堆之外的,包括本地內存、棧等。一般JVM控制的內存大小是固定的,反映在監控上,在內存占用這里基本就是一條直線。
蘑菇街這邊基本就是75%這樣。
出現時的表現:
- 內存使用率不斷上升,甚至開始使用 SWAP 內存。
- GC 時間飆升。
- 線程被 Block。
- 通過 top 命令發現 Java 進程的 RES 甚至超過了 -Xmx 的大小。
例如:

結合上次交易的P0事故。一般發生堆外內存泄漏,都跟我們自己的代碼關系不太大。因為大量調用棧這種情況一般不出現,出現也是OOM,不會產生對機器內存大量讀寫的場景。那么有那種情況下會對內存大量讀寫?native方法。
那么有個最重要的點:IO通信框架一般是會大量操作本地內存的。
大家都是RPC,內部可能是Netty或者NIO框架,所以RPC框架是很有可能導致堆外內存泄漏的,通信過程中大量使用JNI方法調用本地線程,這樣指向了一個非常常見的問題:瞬時大量長時間請求。
比如接口日常請求100QPS,并發量也就10這樣,如果跑任務之類的,瞬間QPS達到5000,直接堆外內存就打滿了。
交易上次P0基本確定是這個問題。緩存擊穿之后大量請求讀寫接口,Tesla接口QPS達到了萬級,瞬間OOM機器開始掛。后續多次沒起來也是,機器剛啟動,Tesla線程拉起后直接OOM,繼續掛。
給個云總的blog:netty oom
這里也有個小知識點:堆外內存是不由JVM管理的,所以大量占用的時候,GC不會被觸發,同時JVM基本上也不限制本地內存大小。所以這塊很難防止。
Metaspace OOM
具體分析可以看一下這個 深入JVM元空間以及彈性伸縮機制
已經聊了一些Metaspace OOM問題了。本質上就是一般設定都是固定大小不擴容,然后大量新class被load進去,導致OOM。
所以除了RPC框架,也有可能是跟IO相關的其他框架導致的,例如fastjson就有可能會在序列化中利用ASM技術執行字節碼增強,產生大量的class對象。
這種情況本質上是類的內部方法建立的對象,存儲在Metaspace的klass空間中。那么此時大量請求時就會不斷創建,由于沒有GC導致OOM。
此時兩種方案:
- 設置Metaspace大小。默認情況下一般是非常大的,所以沒有上限,設置一個大小觸發卸載,可能會緩解這個問題。
- 本質上還是要看代碼。一般這種情況還是代碼有問題,能頻繁不在堆上創建對象,說明該方法一般可以通過static固定到運行時常量池中,全部類只存一份。
Minor GC時間長
晉升代數不合理
和上面的Full GC恰好相反,有可能是晉升代數設置的太高了。那么此時的表現可能是:From區和To區Minor GC一次只能GC掉很少的數據,導致剩余空間小,每次Minor GC后,From/To區進行復制,這個時間花費太長了。
存在大量長生命周期對象
這個跟晉升代數類似,都是高齡對象堆滿From/To區,但是不同點在于:此時晉升代數的設置是比較合理的。
那么這種情況就是高齡對象太多,導致的。還是要從heap 文件中找思路。很有可能是某個集合里面對象太多。比如一個list里面存幾十萬的對象。
那么主要就是先去找大對象,找到大對象后分析大對象的屬性,看為什么能這么大。
頻繁Minor GC
Eden擴容
一般來說可以對Eden區進行擴容來減少Minor GC次數,也就是說,增加了Minor GC的時間間隔,一次GC可以回收更多的對象。這里需要聊下新生代的GC算法:
- 新生代掃描。
- 復制Eden存活對象到Survivor。
這兩步都存在時間消耗,但是復制要比掃描需要的時間多很多。
所以,對于Eden分區的擴容需要根據實際對象生命周期來計算,有這樣的場景:
-
對象生命周期<擴容后Minor GC時間間隔。
a. 此時對象只會被掃描,掃描后標記清除,不進行復制。
-
對象生命周期>=擴容后Minor GC時間間隔。
a. 此時對象跟擴容前一樣,先掃描后復制。
再結合上面掃描和復制的性能損耗:如果能保證擴容后Minor GC能將原來不能回收的對象給回收掉,那么收益是很大的。
反之,如果對象生命周期長,那么由于Eden區的擴大,會導致掃描時間變長,所以Minor GC時間也會增加。所以,有可能實際工作時間會降低。
所以Eden擴容并不是完美解決方案,依然要先分析對象存活時間之類的參數,然后再考慮擴容。
簡而言之:如果對象平均代數低,那么擴容是有效的。
高峰期CMS Full GC時間突刺
CMS Full GC只有在Remark階段會進行長時間STW,初始標記只是遍歷GC Roots,STW很快。例如下面,Remark階段STW時間為1.39s:

這里可能是Full GC慢的一個很重要的問題:跨代引用。具體可以看下:JVM CMS 在Full GC時針對跨代引用的優化
那么在高峰期可以看,在Full GC發生Remark的時候,新生代對象數量是否有很多,所以會出現這種突刺類型的問題:
-
如果Full GC前已經Minor GC一次。
a. 那么跨代引用掃描很少數據,Full GC快。
-
如果Full GC時恰好新生代很滿,例如75%。
a. 那么跨代引用掃描大量數據,Full GC慢。
為了解決這個問題,CMS本身就有一些優化,上面link的文章已經聊到了。
那么同樣是上圖,發現CMS-concurrent-abortable-preclean階段執行時間5.35s,超過了默認5s的等待,所以可以認為Remark時是沒有進行Minor GC的。
這種情況下可以調高CMSMaxAbortablePrecleanTime(不推薦),或者設置CMSMaxAbortablePrecleanTime(推薦),在Remark前強制執行一次Minor GC。
啟動時大量GC后趨于正常(空間震蕩)

表現還是比較經典的:
- 啟動后頻繁GC。
- 每次GC時占用內存空間都很小,但是每次GC后都會增加。
JVM配置中,各個空間一般都是配置兩個:一個正常,一個最大。而在JVM初始化的時候,是按正常的分配的。
所以說這種問題就是初始空間配置小了,很快就需要執行GC,調大即可。
顯式調用
When you have eliminated the impossibles, whatever remains, however improbable, must be the truth.
如果確實排查不出來問題,全局搜一下
System.gc()
說不定確實有那個sb上傳了測試代碼,真的在調用。。。











)



:QStyle和自定義樣式)


數據庫的設計規范)
