大家好。我們知道MySQL在執行一個查詢時,經常會有多個執行方案,然后從中選取成本最低或者說代價最低的方案去真正的執行查詢。今天我們來聊一聊單表查詢的成本。
那么到底什么是成本呢?這里我們說的成本或者代價是由兩方面組成的:
I/O成本: 我們的表經常使用的MyISAM、InnoDB存儲引擎都是將數據和索引都存儲到磁盤上的,當我們想查詢表中的記錄時,需要先把數據或者索引加載到內存中然后再操作。這個從磁盤到內存這個加載的過程損耗的時間稱之為I/O 成本。
CPU成本: 取以及檢測記錄是否滿足對應的搜索條件、對結果集進行排序等這些操作損耗的時間稱之為CPU成本。
對于InnoDB存儲引擎來說,頁是磁盤和內存之間交互的基本單位。MySQL 規定讀取一個頁面花費的成本默認是1.0 ,讀取以及檢測一條記錄是否符合搜索條件的成本默認是0.2。1.0、0.2這些數字稱之為成本常數,這兩個成本常數我們最常用到,其余的成本常數今天先不談。 注意:不管讀取記錄時需不需要檢測是否滿足搜索條件,其成本都算是0.2。
一、單表查詢的成本
為了方便講解,我們先創建下面這個表:
CREATE TABLE single_table ( id INT NOT NULL AUTO_INCREMENT, key1 VARCHAR(100), key2 INT, key3 VARCHAR(100), key_part1 VARCHAR(100), key_part2 VARCHAR(100), key_part3 VARCHAR(100), common_field VARCHAR(100), PRIMARY KEY (id), KEY idx_key1 (key1), UNIQUE KEY idx_key2 (key2), KEY idx_key3 (key3), KEY idx_key_part(key_part1, key_part2, key_part3)
);
在這張表中我們默認插入了10000條數據,下面我們就以這個表來探討一下如何基于成本進行優化。
1、基于成本的優化步驟
在一條單表查詢語句真正執行之前,MySQL的查詢優化器會找出執行該語句所有可能使用的方案,對比之后找出成本最低的方案,這個成本最低的方案就是所謂的執行計劃,之后才會調用存儲引擎提供的接口真正的執行查詢,這個過程總結一下就是這樣:
- 根據搜索條件,找出所有可能使用的索引。
- 計算全表掃描的代價。
- 計算使用不同索引執行查詢的代價。
- 對比各種執行方案的代價,找出成本最低的那一個。
下邊我們通過這個sql語句來一步一步分析一下這四步:
SELECT * FROM single_table WHERE key1 IN ('a', 'b', 'c') AND key2 > 10 AND key2 < 1000 AND key3 > key2 AND key_part1 LIKE '%hello%' AND common_field = '123';
1、根據搜索條件,找出所有可能使用的索引。
對于B+樹索引來說,只要索引列和常數使用=、<=>、IN、NOT IN、IS NULL 、IS NOT NULL 、> 、< 、>= 、<= 、BETWEEN、!= (不等于也可以寫成 <> )或者 LIKE 操作符連接起來,就可以產生一個所謂的范圍區間(LIKE匹配字符串前綴也行),也就是說這些搜索條件都可能使用到索引。一個查詢中可能使用到的索引稱之為possible keys。
我們分析一下上邊查詢中涉及到的幾個搜索條件:
key1 IN (‘a’, ‘b’, ‘c’) 可以使用二級索引 idx_key1 。
key2 > 10 AND key2 < 1000可以使用二級索引 idx_key2 。
key3 > key2 這個搜索條件的索引列由于沒有和常數比較,所以并不能使用到索引。
key_part1 LIKE ‘%hello%’ , key_part1 通過 LIKE 操作符和以通配符開頭的字符串做比較,不可以使用索引。
common_field = ‘123’,由于該列沒有索引,所以不會用到索引。
綜上所述,上邊的查詢語句可能用到的索引,也就是possible keys 只有 idx_key1 和 idx_key2 。
2、計算全表掃描的代價。
對于InnoDB 存儲引擎來說,全表掃描的意思就是把聚簇索引中的記錄都依次和給定的搜索條件做一下比較,把符合搜索條件的記錄加入到結果集,所以需要將聚簇索引對應的頁面加載到內存中,然后再檢測記錄是否符合搜索條件。由于查詢成本=I/O 成本+CPU 成本,所以計算全表掃描的代價需要兩個信息:聚簇索引占用的頁面數和該表中的記錄數。
MySQL每個表維護了一系列的統計信息,我們可以通過SHOW TABLE STATUS語句來查看表的統計信息,如果要看指定的某個表的統計信息,在該語句后加對應的 LIKE 語句就 好了,比方說我們要查看single_table 這個表的統計信息可以這么寫:
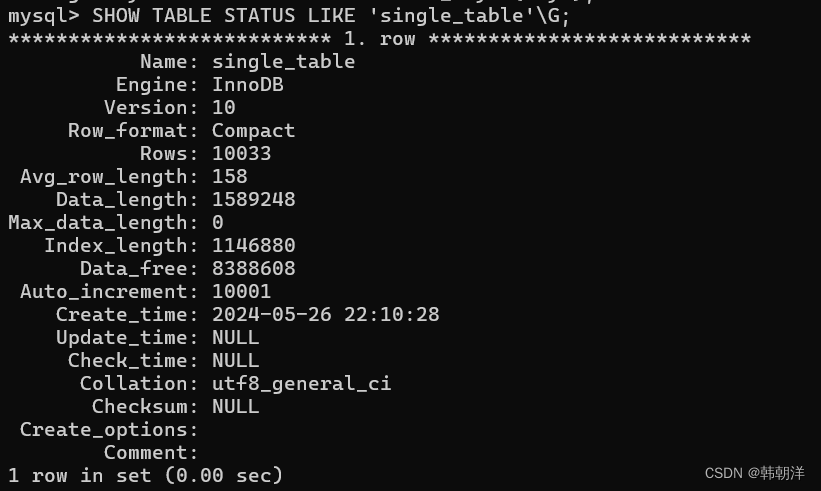
雖然出現了很多統計選項,但我們目前只關心兩個:
Rows(本選項表示表中的記錄條數): 對于使用MyISAM 存儲引擎的表來說該值是準確的,對于使用InnoDB存儲引擎的表來說,該值是一個估計值。從查詢結果我們也可以看出來,由于我們的single_table 表是使用 InnoDB 存儲引擎的,所以雖然實際上表中有10000條記錄,但是SHOW TABLE STATUS 顯示的 Rows 值是10033條記錄。
Data_length(本選項表示表占用的存儲空間字節數): 使用MyISAM存儲引擎的表來說,該值就是數據文件的大小,對于使用InnoDB 存儲引擎的表來說,該值就相當于聚簇索引占用的存儲空間大小,也就是說可以這樣計算該值的大小:
Data_length = 聚簇索引的頁面數量 x 每個頁面的大小。
single_table 使用默認16KB 的頁面大小,而上邊查詢結果顯示 Data_length 的值是1589248 ,所以我們可以反向來推導出聚簇索引的頁面數量: 聚簇索引的頁面數量 = 1589248 ÷ 16 ÷ 1024 = 97。
我們現在已經得到了聚簇索引占用的頁面數量以及該表記錄數的估計值,所以就可以計算全表掃描成本了。但是MySQL在真實計算成本時會進行一些微調,但是由于這些微調的值十分的小,并不影響我們分析。
現在可以看一下全表掃描成本的計算過程:
I/O 成本 97 x 1.0 + 1.1 = 98.1
97 指的是聚簇索引占用的頁面數,1.0指的是加載一個頁面的成本常數,后邊的1.1是一個微調值,我們不用在意。
CPU 成本: 10033x 0.2 + 1.0 = 2007.6
10033指的是統計數據中表的記錄數,對于InnoDB 存儲引擎來說是一個估計值,0.2指的是訪問一條記錄所需的成本常數,后邊的1.0是一個微調值,我們不用在意。
總成本: 98.1 + 2007.6 = 2105.7 綜上所述,對于single_table 的全表掃描所需的總成本就是 2105.7 。
注意:我們前邊說過表中的記錄其實都存儲在聚簇索引對應B+樹的葉子節點中,所以只要我們通過根節點獲得了最左邊的葉子節點,就可以沿著葉子節點組成的雙向鏈表把所有記錄都查看一遍。也就是說全表掃描這個過程其實有的B+樹內節點是不需要訪問的,但是MySQL在計算全表掃描成本時直接使用聚簇索引占用的頁面數作為計算I/O成本的依據,是不區分內節點和葉子節點的。
3、 計算使用不同索引執行查詢的代價。
從第1步分析我們得到,查詢可能使用到idx_key1 和 idx_key2 這兩個索引,我們需要分別分析單獨使用這些索引執行查詢的成本,最后還要分析是否可能使用到索引合并。這里需要注意的是,MySQL查詢優化器先分析使用唯一二級索引的成本,再分析使用普通索引的成本,所以我們也先分析idx_key2的成本,然后再看使用 idx_key1 的成本。
1. 使用 idx_key2 執行查詢的成本分析: idx_key2 對應的搜索條件是:key2 > 10 AND key2 < 1000,對應的范圍區間就是:(10, 1000) , 所以使用idx_key2 搜索的示意圖如下所示:
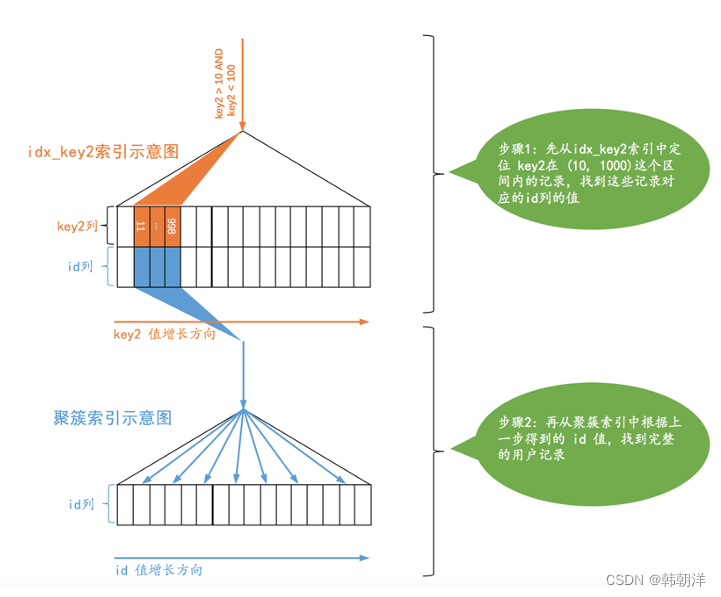
對于使用二級索引 + 回表方式的查詢,MySQL計算這種查詢的成本依賴兩個方面的數據:
范圍區間數量: 不論某個范圍區間的二級索引到底占用了多少頁面,查詢優化器都認為讀取索引的一個范圍區間的I/O 成本和讀取一個頁面是相同的。
本例中使用idx_key2 的范圍區間只有一個:(10, 1000) ,所以相當于訪問這個范圍區間的二級索引付出的I/O成本就是:1 x 1.0 = 1.0。
需要回表的記錄數: 優化器需要計算二級索引的某個范圍區間到底包含多少條記錄,對于本例來說就是計算idx_key2在(10, 1000) 這個范圍區間中包含多少二級索引記錄,計算過程是這樣的:
步驟1:先根據key2 > 10這個條件訪問一下idx_key2對應的B+ 樹索引,找到滿足 key2 > 10 這個條件的第一條記錄,我們把這條記錄稱之為區間最左記錄。
步驟2:然后再根據key2 < 1000這個條件繼續從 idx_key2 對應的 B+ 樹索引中找出第一條滿足這個條件的記錄,我們把這條記錄稱之為區間最右記錄。
步驟3:如果區間最左記錄和區間最右記錄相隔不太遠,那就可以精確統計出滿足key2 > 10 AND key2 < 1000 條件的二級索引記錄條數。否則只沿著區間最左記錄向右讀10個頁面,計算平均每個頁面中包含多少記錄,然后用這個平均值乘以區間最左記錄和區間最右記錄之間的頁面數量就可以了。
那么問題又來了,怎么估計區間最左記錄和區間最右記錄之間有多少個頁面呢?解決這個問題還得回到B+樹索引的結構中來:
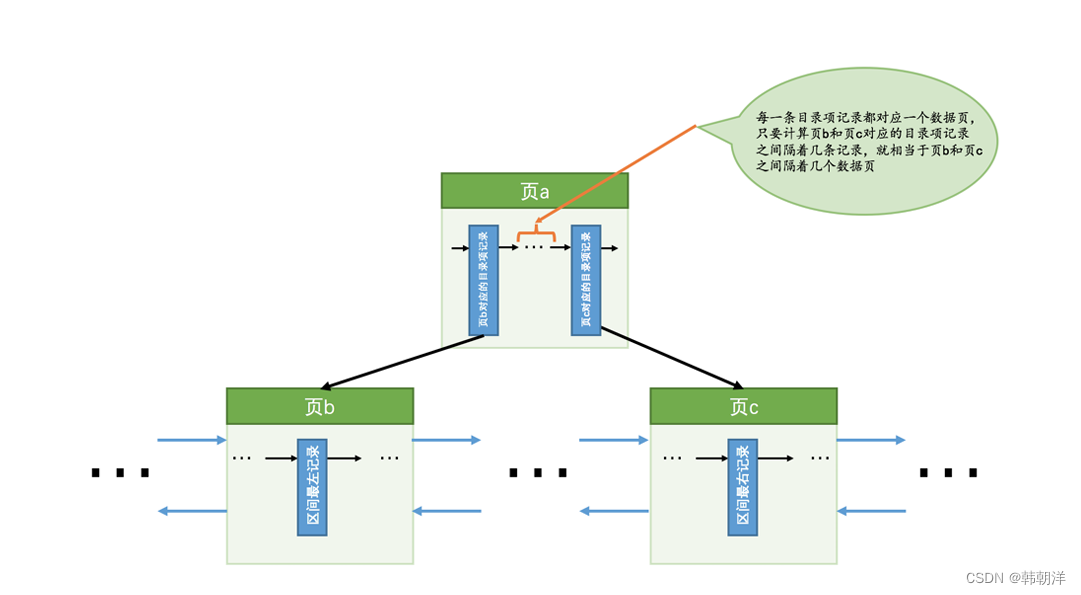
如圖,我們假設區間最左記錄在頁b中,區間最右記錄在頁c中,那么我們想計算區間最左記錄和區間最右記錄之間的頁面數量就相當于計算頁b和頁c之間有多少頁面,而每一條目錄項記錄都對應一個數據頁,所以計算頁b和頁c之間有多少頁面就相當于計算它們父節點(也就是 頁a)中對應的目錄項記錄之間隔著幾條記錄。
如果頁b和頁c之間的頁面非常多,以至于頁b和頁c對應的目錄項記錄都不在一個頁面中時,就再統計頁b和頁c對應的目錄項記錄所在頁之間有多少個頁面,依次類推。
根據上述算法測得 idx_key2 在區間 (10, 1000) 之間大約有 95 條記錄。讀取這95條二級索引記錄需要付出的CPU成本就是:95 x 0.2 + 0.01 = 19.01 其中95是需要讀取的二級索引記錄條數,0.2是讀取一條記錄成本常數,0.01是微調。
在通過二級索引獲取到記錄之后,還需要干兩件事兒:
根據這些記錄里的主鍵值到聚簇索引中做回表操作: MySQL認為每次回表操作都相當于訪問一個頁面,也就是說二級索引范圍區間有多少記 錄,就需要進行多少次回表操作,也就是需要進行多少次頁面I/O。
我們上邊統計了使用 idx_key2 二級索引執行查詢時,預計有95條二級索引記錄需要進行回表操作,所以回表操作帶來的I/O成本就是:95 x 1.0 = 95.0。其中95是預計的二級索引記錄數,1.0是一個頁面的I/O成本常數。
回表操作后得到的完整用戶記錄,然后再檢測其他搜索條件是否成立: 回表操作的本質就是通過二級索引記錄的主鍵值到聚簇索引中找到完整的用戶記錄,然后再檢測除 key2 > 10 AND key2 < 1000 這個搜索條件以外的搜索條件是否成立。
因為我們通過范圍區間獲取到二級索引記錄共95條,也就對應著聚簇索引中95條完整的用戶記錄,讀取并檢測這些完整的用戶記錄是否符合其余的搜索條件的CPU成本就是: 95 x 0.2 = 19.0。其中95是待檢測記錄的條數,0.2是檢測一條記錄是否符合給定的搜索條件的成本常數。
所以本例中使用idx_key2 執行查詢的成本就如下所示:
I/O 成本: 1.0 + 95 x 1.0 = 96.0 (范圍區間的數量 + 預估的二級索引記錄條數)
CPU 成本: 95 x 0.2 + 0.01 + 95 x 0.2 = 38.01 (讀取二級索引記錄的成本 + 讀取并檢測回表后聚簇索 引記錄的成本)
綜上所述,使用idx_key2 執行查詢的總成本就是:96.0 + 38.01 = 134.01。
2. 使用 idx_key1 執行查詢的成本分析: idx_key1 對應的搜索條件是:key1 IN (‘a’, ‘b’, ‘c’) ,也就是說相當于3個單點區間:[‘a’, ‘a’]、[‘b’, ‘b’]和[‘c’, ‘c’]。使用idx_key1 搜索的示意圖如下:
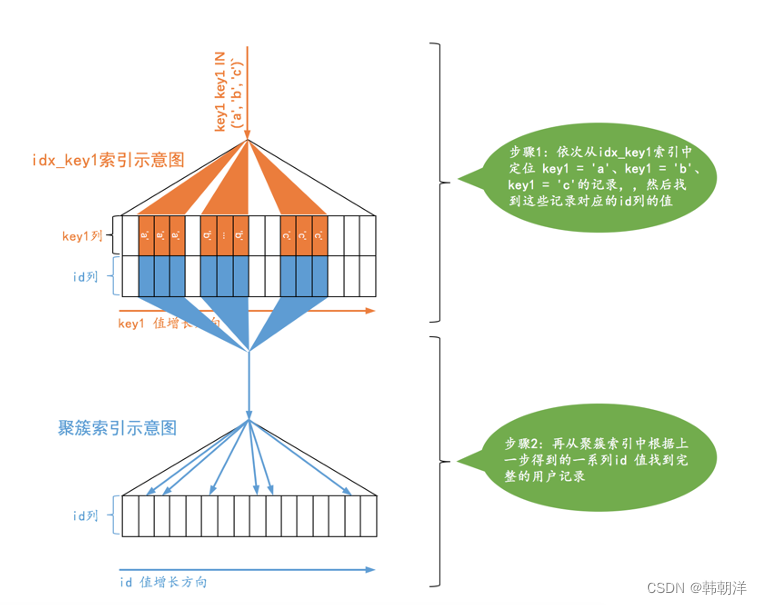
與使用idx_key2 的情況類似,我們也需要計算使用 idx_key1 時需要訪問的范圍區間數量以及需要回表的記錄數:
范圍區間數量: 使用idx_key1 執行查詢時很顯然有3個單點區間,所以訪問這3個范圍區間的二級索引付出的I/O成本就是:3 x 1.0 = 3.0。
需要回表的記錄數: 由于使用idx_key1 時有3個單點區間,所以每個單點區間都需要查找一遍對應的二級索引記錄數:
查找單點區間[‘a’, ‘a’] 對應的二級索引記錄數:計算單點區間對應的二級索引記錄數和計算連續范圍區間對應的二級索引記錄數是一樣的,都是先計算區間最左記錄和區間最右記錄,然后再計算它們之間的記錄數。最后計算得到單點區間[‘a’, ‘a’] 對應的二級索引記錄數是:35 。
查找單點區間[‘b’, ‘b’] 對應的二級索引記錄數:與上同理,計算得到本單點區間對應的記錄數是:44。
查找單點區間[‘c’, ‘c’] 對應的二級索引記錄數:與上同理,計算得到本單點區間對應的記錄數是:39。
所以,這三個單點區間總共需要回表的記錄數就是:35 + 44 + 39 = 118,讀取這些二級索引記錄的CPU成本就是:118 x 0.2 + 0.01 = 23.61。
得到總共需要回表的記錄數之后,我們還要考慮以下幾點:
根據這些記錄里的主鍵值到聚簇索引中做回表操作:所需的I/O成本就是:118 x 1.0 = 118.0。
回表操作后得到的完整用戶記錄,然后再比較其他搜索條件是否成立:此步驟對應的CPU 成本就是:118 x 0.2 = 23.6
所以本例中使用idx_key1 執行查詢的成本就如下所示:
I/O 成本:3.0 + 118 x 1.0 = 121.0 (范圍區間的數量 + 預估的二級索引記錄條數)
CPU 成本:118 x 0.2 + 0.01 + 118 x 0.2 = 47.21 (讀取二級索引記錄的成本 + 讀取并檢測回表后聚簇 索引記錄的成本)
綜上所述,使用idx_key1 執行查詢的總成本就是:121.0 + 47.21 = 168.21
3. 是否有可能使用索引合并( Index Merge ): 本例中有關key1 和 key2 的搜索條件是使用 AND 連接起來的,而對于idx_key1 和 idx_key2 都是范圍查詢,也就是說查找到的二級索引記錄并不是按照主鍵值進行排序的,并不滿足使用Intersection 索引合并的條件,所以并不會使用索引合并。
4、對比各種執行方案的代價,找出成本最低的那一個
下邊把執行本例中的查詢的各種可執行方案以及它們對應的成本列出來:
全表掃描的成本:2105.7
使用idx_key2 的成本:134.01
使用idx_key1 的成本:168.21
很顯然,使用idx_key2 的成本最低,所以當然選擇 idx_key2 來執行查詢。
2、基于索引統計數據的成本計算
有時候使用索引執行查詢時會有許多單點區間,比如使用IN語句就很容易產生非常多的單點區間,比如下邊這個查詢(語句中的…表示還有很多參數):
SELECT * FROM single_table WHERE key1 IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
很顯然,這個查詢可能使用到的索引就是idx_key1 ,由于這個索引并不是唯一二級索引,所以并不能確定一個單點區間對應的二級索引記錄的條數有多少,需要我們去計算。計算方式我們上邊已經介紹過了,就是先獲取索 引對應的B+樹的區間最左記錄和區間最右記錄,然后再計算這兩條記錄之間有多少記錄(記錄條數少的時候可以做到精確計算,多的時候只能估算)。這種通過直接訪問索引對應的B+樹來計算某個范圍區間對應的索引記錄條數的方式稱之為index dive。
有零星幾個單點區間的話,使用index dive 的方式去計算這些單點區間對應的記錄數也不是什么問題,但是如果單點區間多的話,比如IN語句里有20000個參數,這就意味著MySQL 的查詢優化器為了計算這些單點區間對應的索引記錄條數,要進行20000次index dive 操作,這性能損耗會很大。
為了防止這種情況, MySQL提供了一個系統變量 eq_range_index_dive_limit ,如果我們的IN語句中的參數個數小于eq_range_index_dive_limit 的話,將使用index dive的方式計算各個單點區間對應的記錄條數,如果大于或等于eq_range_index_dive_limit 個的話,可就不能使用index dive了,要使用所謂的索引統計數據來進行估算。
像會為每個表維護一份統計數據一樣,MySQL也會為表中的每一個索引維護一份統計數據,查看某個表中索引的統計數據可以使用SHOW INDEX FROM 表名的語法,比如我們查看一下 single_table 的各個索引的統計數據:
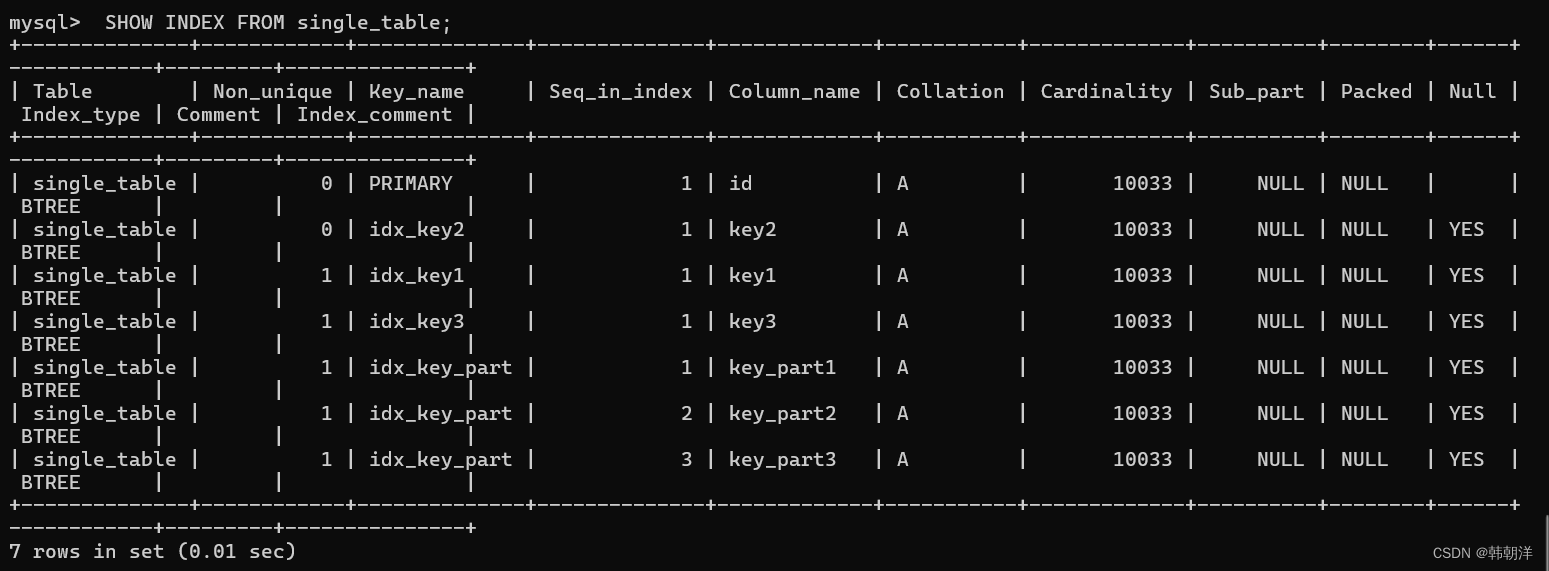
下面我們介紹一下這些屬性:
| 屬性名 | 描述 |
|---|---|
| Table | 索引所屬表的名稱。 |
| Non_unique | 索引列的值是否是唯一的,聚簇索引和唯一二級索引的該列值為0,普通二級索引該列值為1。 |
| Key_name | 索引的名稱。 |
| Seq_in_index | 索引列在索引中的位置,從1開始計數。比如對于聯合索引idx_key_part來說,key_part1、key_part2和key_part3 對應的位置分別是1、2、3。 |
| Column_name | 索引列的名稱。 |
| Collation | 索引列中的值是按照何種排序方式存放的,值為A時代表升序存放,為NULL時代表降序存放。 |
| Cardinality | 索引列中不重復值的數量。 |
| Sub_part | 對于存儲字符串或者字節串的列來說,有時候我們只想對這些串的前n個字符或字節建立索引,這個屬性表示的就是那個n值。如果對完整的列建立索引的話,該屬性的值就是NULL。 |
| Packed | 索引列如何被壓縮,NULL值表示未被壓縮。 |
| Null | 這個屬性我們暫時不了解,可以先忽略掉。 |
| Index_type | 該索引列是否允許存儲NULL值。 |
| Comment | 使用索引的類型,我們最常見的就是BTREE,其實也就是B+樹索引。 |
| Index_comment | 索引列注釋信息。 索引注釋信息。 |
上述屬性中我們現在最在意的是Cardinality 屬性, Cardinality 直譯過來就是基數的意思,表示索引列中不重復值的個數。比如對于一個一萬行記錄的表來說,某個索引列的Cardinality屬性是10000,那意味著該列中沒有重復的值,如果Cardinality屬性是1的話,就意味著該列的值全部是重復的。
注意:對于InnoDB存儲引擎來說,使用SHOW INDEX語句展示出來的某個索引列的Cardinality屬性是一個估計值,并不是精確的。
前邊說道,當IN語句中的參數個數大于或等于系統變量eq_range_index_dive_limit 的值的話,就不會使用index dive的方式計算各個單點區間對應的索引記錄條數,而是使用索引統計數據,這里所指的索引統計數據指的是這兩個值:
使用SHOW TABLE STATUS 展示出的 Rows 值,也就是一個表中有多少條記錄。
使用SHOW INDEX 語句展示出的 Cardinality 屬性。
結合上一個Rows 統計數據,我們可以針對索引列,計算出平均一個值重復多少次。一個值的重復次數 ≈ Rows ÷ Cardinality。
以single_table 表的 idx_key1 索引為例,它的 Rows 值是 10033,它對應索引列 key1 的 Cardinality 值也是 10033,所以我們可以計算key1 列平均單個值的重復次數就是:10033÷ 10033=1(條)。
此時再看上邊那條查詢語句:
SELECT * FROM single_table WHERE key1 IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
假設IN 語句中有20000個參數的話,就直接使用統計數據來估算這些參數需要單點區間對應的記錄條數了,每個參數對應1條記錄,所以總共需要回表的記錄數就是:20000 x 1 = 20000 使用統計數據來計算單點區間對應的索引記錄條數可比index dive 的方式簡單多了,但是它的致命弱點就是:不精確!使用統計數據算出來的查詢成本與實際所需的成本可能相差非常大。
好了,到這里我們就講完了,今天我們主要講了成本是什么以及單表查詢如何計算成本,歡迎大家在評論區留言討論,也希望大家能給作者點個關注,謝謝大家!最后依舊是請各位老板有錢的捧個人場,沒錢的也捧個人場,謝謝各位老板!
 python2.7改為python3)


















